A blog about current topics in computer science and media, maintained by students of the Hochschule der Medien Stuttgart (Stuttgart Media University).
Recent Posts
Wie (schlecht) steht es um die IT-Sicherheit in Fahrzeugen?
Wenn man an IT-Sicherheit denkt, kommen einem Bilder von Gestalten mit Kapuze in den Kopf, die in einer dunklen Kammer sitzen und dank Hacker Typer in zehnfacher Geschwindigkeit den Code für die neueste Ransomware runterschreiben. Auf den zweiten Gedanken könnte man eventuell an reale Bedrohungen durch Hackergruppen aus dem Internet denken und sich daran erinnern,…
Docker security: Hands-on guide
Absichern von Docker Containern, durch die Nutzung von Best Practices in DockerFiles und Docker Compose. Einführung Es ist sehr wahrscheinlich im Alltag mit containerisierten Anwendungen in Berührung zu kommen, ohne sich dessen bewusst zu sein. In einer Zeit, in der sich der Trend der Unternehmen weiterhin stark in Richtung Cloud bewegt, gewinnen Container immer mehr…
Die Meere der Systemtechnik navigieren: Eine Reise durch die Bereitstellung einer Aktien-Webanwendung in der Cloud
Auf zu neuen Ufern: Einleitung Die Cloud-Computing-Technologie hat die Art und Weise, wie Unternehmen Anwendungen entwickeln, bereitstellen und skalieren, revolutioniert. In diesem Beitrag, der im Rahmen der Vorlesung “143101a System Engineering und Management” entstanden ist, werden wir uns darauf konzentrieren, wie eine bereits bestehende Webanwendung zur Visualisierung und Filterung von Aktienkennzahlen auf der IBM Cloud-Infrastruktur…
Terraform x Go: Challenges when interacting with Terraform through Go
Introduction In a recent project, some of my fellow students and I developed a basic hosting provider that allows a user to spin up Docker containers on a remote server, which is realized by using Terraform locally on the server. During this project, we developed a Go-based backend service that provided a REST API to…
Why system monitoring is important and how we approached it
Introduction Imagine building a service that aims to generate as much user traffic as possible to be as profitable as possible. The infrastructure of your service usually includes some kind of backend, a server and other frameworks. One day, something is not working as it should and you can’t seem to find out why. You…
Combining zerolog & Loki
Publish zerolog events to Loki in just a few lines of code.
- Allgemein, Student Projects, System Architecture, System Designs, System Engineering, Teaching and Learning
Using Keycloak as IAM for our hosting provider service
Discover how Keycloak can revolutionize your IAM strategy and propel your projects to new heights of security and efficiency.
CTF-Infrastruktur als Proof-of-Concept in der Microsoft Azure Cloud
Einführung Eine eigene Capture-The-Flag (CTF) Plattform zu betreiben bringt besondere Herausforderungen mit sich. Neben umfangreichem Benutzermanagement, dem Bereitstellen und sicherem Hosten von absichtlich verwundbaren Systemen, sowie einer möglichst einfachen Methode, spielbare Systeme von externen Quellen einzubinden. So möchte man vielleicht der eigenen Community die Möglichkeit bieten, eigene Szenarien zu entwickeln, welche im Anschluss in die…
Cybersecurity Breaches
Sicherheitsrisiken im digitalen Zeitalter: Eine Analyse aktueller Cyberangriffe und ihre Implikationen Data Breaches sind eine zunehmende Bedrohung, bei der Hacker und Cyberkriminelle weltweit nach Möglichkeiten suchen, sensible Informationen zu stehlen. Die Motive für solche Angriffe umfassen finanzielle Gewinne, Prestige und Spionage. Laut dem Verizon Report von 2023 machen technische Schwachstellen nur etwa 8% aller Angriffsmethoden…
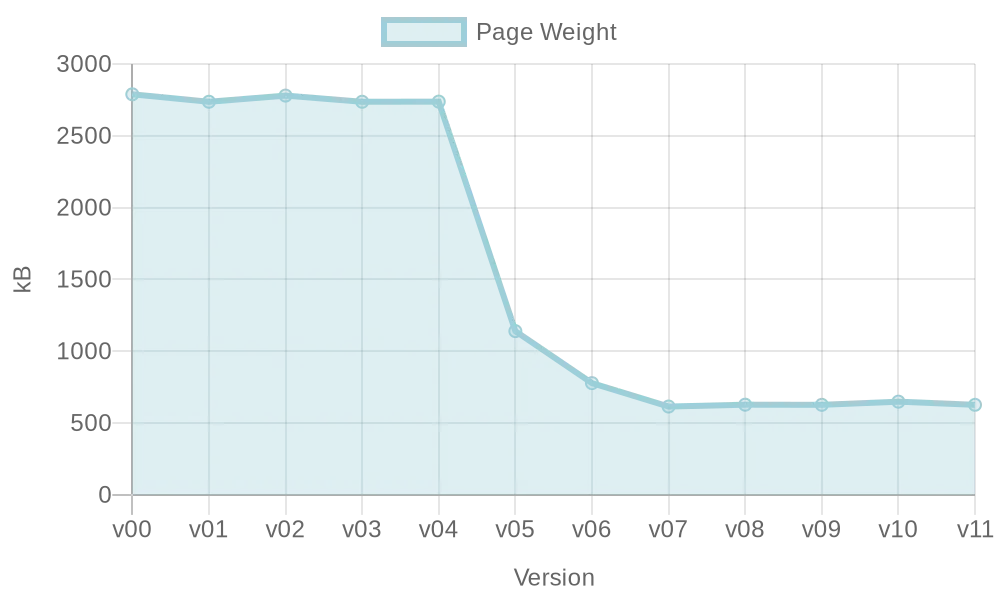
Optimierung einer VueJS-Webseite: Ladezeitenreduktion
Performance einer Webseite ist wichtig für Nutzer und Suchmaschinen, aber im Entwicklungsprozess nicht immer ersichtlich. Diese Hausarbeit untersucht Möglichkeiten zur automatischen Optimierung der Webperformance während der Entwicklung mit VueJS.
Buzzwords
AI Amazon Web Services architecture artificial intelligence Automation AWS AWS Lambda Ci-Pipeline CI/CD Cloud Cloud-Computing Containers Continuous Integration data protection deep learning DevOps distributed systems Docker docker compose Games Git gitlab Gitlab CI Google Cloud ibm IBM Bluemix Jenkins Kubernetes Linux loadbalancing machine learning Microservices Monitoring Node.js privacy Python scaling secure systems security serverless social media Test-Driven Development ULS ultra large scale systems Web Performance