Internet service providers face the challenge of growing rapidly while managing increasing system distribution. Although the reliable operation of services is of great importance to companies such as Google, Amazon and Co., their systems fail time and again, resulting in extensive outages and a poor customer experience. This has already affected Gmail (2012) [1], AWS DynamoDB (2015) [2], and recently Facebook (2021) [3], to name just a few examples. In this context, one often encounters so-called cascading failures causing undesirable complications that go beyond ordinary system malfunctions. But how is it that even the big players in the online business cannot completely avoid such breakdowns, given their budgets and technical knowledge? And what are practical approaches to risk mitigation that you can use for your own system?
With that said, the goal of this blog article is to learn how to increase the resilience of your large distributed system by preventing the propagation of failures.
Cascading failures
A cascading failure is a failure that increases in size over time due to a positive feedback loop. The typical behavior is initially triggered by a single node or subsystem failing. This spreads the load across fewer nodes of the remaining system, which in turn increases the likelihood of further system failures resulting in a vicious circle or snowball effect [4]. Cascading failures are highly critical for three reasons: First, they can shut down an entire service in a short period of time. Second, the affected system does not return to normal as it does with more commonly encountered problems, but it gets progressively worse. This ultimately leads to being dependent on human intervention. Finally, in the worst case, cascading failures can strike seemingly without warning because load distribution, and consequently failures, occur rapidly [4][5].
Although this blog article will focus on cascading failures in the context of distributed computing, they can also occur in a variety of other domains: e.g., power transmission, finance, biology, and also ecosystems. So, they are a fairly widespread phenomenon that is somewhat similar to patterns found in nature [5]. To get a better idea of what a cascading failure in computer science looks like, let’s look at a specific case study.
Case Study: The AWS DynamoDB Outage in 2015
AWS DynamoDB is a highly scalable non-relational database service, distributed across multiple datacenters that offers strongly consistent read operations and ACID transactions [6]. It is, and at the time of the event was, being used by popular internet services such as Netflix, Airbnb, and IMDb [7]. The incident we want to look at as an example of a cascading failure occurred on September 20, 2015, when DynamoDB was unavailable in the US-East region for over four hours. There were two subsystems involved: storage servers and a metadata service. Both are replicated across multiple datacenters. The storage servers request their so-called membership for their data partition allocations from the metadata service. This is shown in Figure 1.
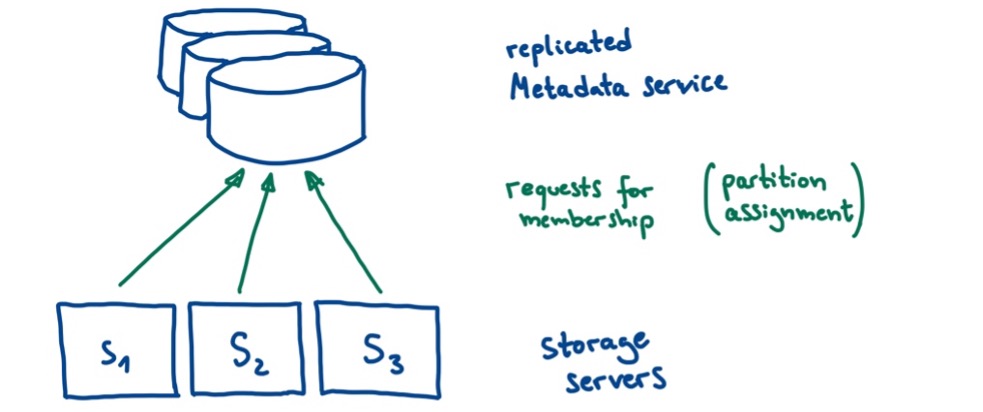
(Own illustration based on [8])
For the membership (and thus also for the allocation of data partitions) there are timeouts during which the request must be successful. If these are exceeded, the corresponding storage server retries and excludes itself from the service.
An unfortunate precondition for the incident was a newly introduced DynamoDB feature called Global Secondary Index (GSI). This gives customers better access to their data but has the downside of significantly increasing the size of metadata tables. Consequently, the processing time was much longer. Regarding the capacity of the metadata service and the timeouts for membership requests, unfortunately no corresponding adjustments were made [9].
The real problem began when a short network issue caused a few storage servers (dealing with very large metadata tables) to miss their membership requests. These servers became unavailable and kept retrying their requests. This overloaded the metadata service, which in turn slowed down responses and caused more servers to resubmit their membership requests because they had exceeded their timeouts as well. As a consequence, the state of the metadata service deteriorated even further. Despite several attempts to increase resources, the system remained caught in the failure loop for hours. Ultimately, the problem could only be solved by interrupting requests to the metadata service, i.e., the service was basically taken offline [9].
The result is a widespread DynamoDB outage in the US-East region and an excellent example of a cascading failure. However, what are the underlying concepts and patterns of the systems that are getting caught in such an error loop?
Reasons for cascading failures
First, it should be mentioned that the trigger points for cascading breakdowns can look diverse: e.g., these could be new rollouts, maintenance, traffic drains, cron jobs, distributed denial-of-service (DDoS), throttling and so on. What they all have in common is that they work in the context of a finite set of resources, potentially implying effects such as server overload, resource exhaustion, and unavailability of services [4][10]. Let’s look at those in detail:
Server overload
The most common cause is server overload or a consequence of it. When that happens, the drop in system performance often affects other areas of the system. As shown in Figure 2, in the initial scenario (left), load coming from two reverse proxies is distributed between clusters A and B, so that cluster A operates at an assumed maximum capacity of 1000 requests per second. In the second scenario (right), cluster B fails and the entire load hits cluster A, which can lead to an overload. Cluster A now has to process 1200 requests per second and starts to misbehave, causing the performance to drop well below the desired 1000 requests per second [4].
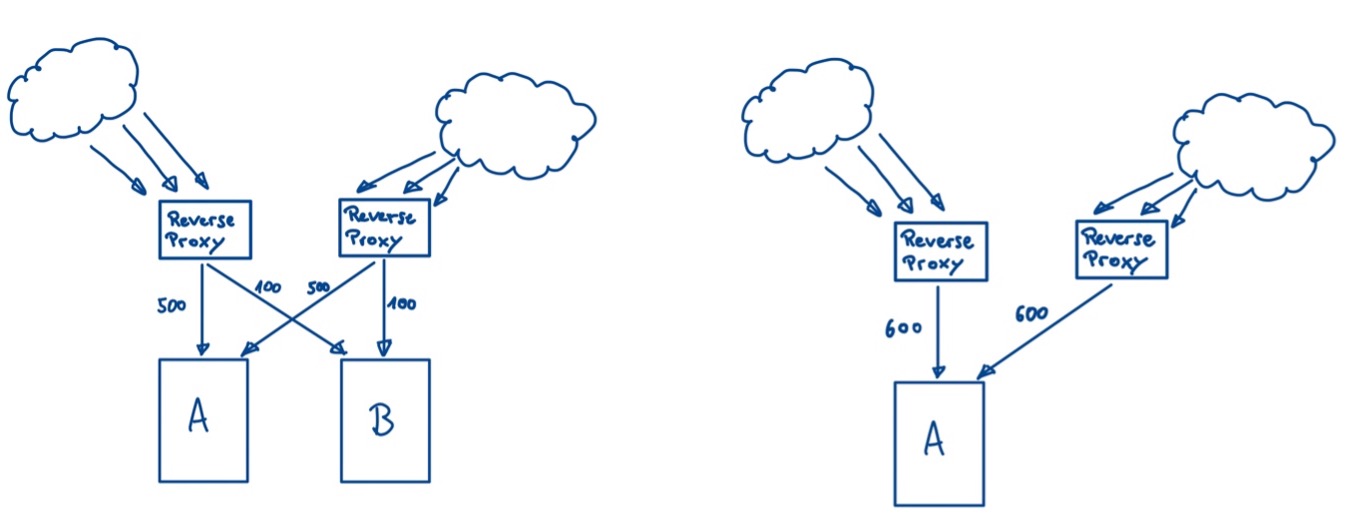
Resource Exhaustion
Resources of a server are limited. If the load increases above a certain threshold, the server’s performance metrics, such as latency or error rates, deteriorate. This translates into a higher risk of a crash. The subsequent effects depend on the type of resource that is causing the bottleneck, for instance,
- if CPU is not sufficient, a variety of issues can occur, including slower requests, excessive queuing effects, or thread starvation.
- If memory/RAM is overused, tasks may crash, or cache hits can decrease.
- Also, thread starvation may directly cause errors or lead to health check failures [4].
Troubleshooting for the main cause in this context is often painful. This is due to the fact that the components involved are interdependent and the root cause may be hidden behind a complex chain of events [4]. For example, assume that less memory is available for caching, resulting in fewer cache hits and thus a higher load for the backend, and such combinations [10].
Service Unavailability
When resource exhaustion causes a server to crash, traffic spreads to other servers, increasing the likelihood that those will crash as well. A cycle of crashing servers establishes. The bad thing about it, these problems remain in your system because some machines are still down or in the process of being restarted, while increasing traffic prevents them from fully recovering [4].
In general, the risk of cascading failure is always present when we redistribute traffic from unhealthy nodes to healthy nodes. This may be the case with orchestration systems, load balancers, or task scheduling systems [5]. In order to solve cascading failures, we need to take a closer look at the relationships of the components involved.
Getting out of the loop – how to fix cascading failures
As seen in the case of DynamoDB, fixing cascading failures is tricky. Especially from the perspective of a large tech company, distribution adds a lot of complexity to your system which makes it even more difficult to keep track of the diverse interconnections. One basic way to illustrate (the cascading) relationships here is the so-called Causal Loop Diagram (CLD). The CLD is a modeling approach that helps to visualize feedback loops in complex systems. Figure 3 visualizes the CLD for the AWS DynamoDB outage. It can be explained as follows. An arrow represents the dynamic between the initial and subsequent variable. For instance, if the latency on the metadata service increases, the number of timeouts increases and so does the number of retries needed. If the effects in the system are highly unbalanced, i.e., the number of pluses and minuses is not equal by a large margin, there is a reinforcing cycle. This means that the system might be sensitive for cascading failures [5].
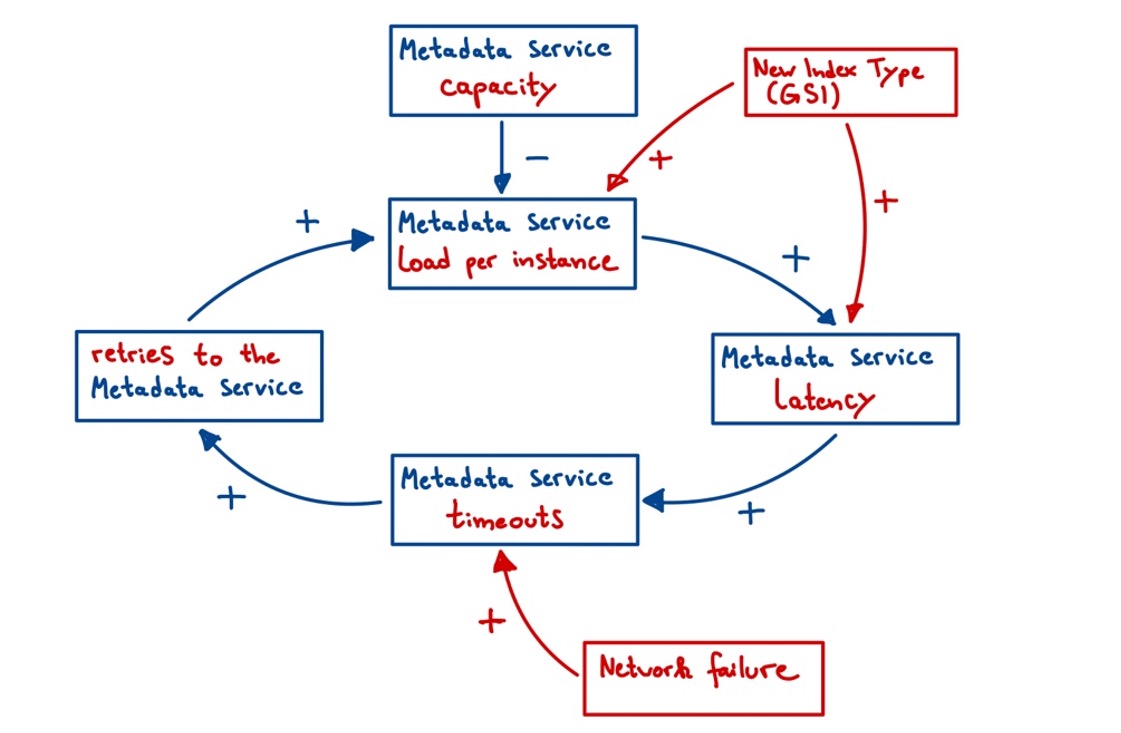
(Own illustration based on [5])
Now, to address the cascading scenario, various measures can be taken. The first and most intuitive option is to increase resources. In the diagram above you can see the minus that is introduced to the circle by the metadata service capacity. If this is increased, it works against the reinforcing cycle. However, this might be useless, as we have seen in the case of AWS. In addition to increasing resources, you may need to employ other strategies:
- Try to avoid health check failures/deaths to prevent your system from dying due to excessive health checking.
- Restart your servers in case of thread-blocking requests or deadlocks.
- Drop traffic significantly and then slowly increase the load so that the servers can gradually recover.
- Switch to a degraded mode by dropping certain types of traffic.
- Eliminate batch/bad traffic to reduce system load due to non-critical or faulty work [4].
Since this ultimately means that parts of the system are not available and this becomes visible to the customer, it is better to avoid cascading failures in the first place.
Avoiding cascading failures
There are numerous approaches to render distributed systems robust against cascading failures.
On the one hand, large internet companies have already thought about how to prevent a system from falling into a cascade of errors, e.g., by conducting an isolation of errors. Tools and frameworks have been developed for this purpose. Two examples are Hystrix (from Netflix), a latency and fault tolerance library, or Sentinel [11][12]. Regarding the former, Netflix has already made further developments, namely the adaptive concurrency limits (you can read more on that here). But in general, these kinds of tools wrap external calls into some kind of data structure, trying to abstract the critical points.
On the other hand, and this is where the hype is going, there are more complex solutions, such as the implementation of so-called side car proxies, e.g., service meshes like istio. Some examples technologies are Envoy or Haproxy [10][13].
In addition to these solutions, there are certain system design concepts you can keep in mind. For example, you can try to reduce the number of synchronous calls in your systems. This can be done by moving from an orchestration pattern to a choreography pattern by applying a publish–subscribe pattern design, e.g., by using Kafka. In the face of increasing traffic this solution often turns out more robust. Other approaches, such as performing capacity planning (depending on the use case) can also be helpful. This often implies implementing solutions for automatic provisioning and deployment, automatic scaling, and automatic healing. In this context, close monitoring of SLAs and SLOs can be considered important [10][4].
Now, in order to better understand the underlying solution approaches, we can take a look at typical antipatterns in distributed systems that should be avoided in the context of cascading failures. Laura Nolan proposes six of these, which are also discussed in terms of risk mitigation strategies in the following.
Antipattern 1: Acceptance of an unrestricted number of requests
The number of tasks in the queue/thread pool should be limited. This allows you to control when and how the server slows down in case of excessive requests. The setting should be in a range where the server can reach peak loads, but not so much that it blocks. In this case, it is better to fail fast than to hang for a long time, for both the system and the user [5]. On the proxy or load balancer side this is frequently implemented by rate limiting strategies, e.g., to avoid DDoS and other forms of server overload [11]. But there is also more to consider, for example in the context of queue management, as most servers have a queue in front of a thread pool to handle requests. If the number increases beyond the capacity of the queue, requests are rejected. A high number of requests waiting in the queue requires memory and increases latency. If the number of requests is close to constant, a small queue, or no queue at all is sufficient. This means that requests will be rejected immediately if there is an increase in traffic. If stronger deviations are to be expected, a longer queue should be used [4].
In addition, to protect servers from excessive load, the concepts of load shedding and graceful degradation are viable options. Load shedding is used to maintain the server’s performance as best as possible in case of overload. This is achieved by dropping traffic using approaches ranging from simply returning an HTTP 503 (Service unavailable) status code to prioritizing requests individually. A more complex variant of this is called graceful degradation, which means it switches incrementally to lower quality responses for queries. These might run faster or more efficiently. However, this should only be a well-considered solution because it can add a lot of complexity to your system [4].
Antipattern 2: Dangerous (client) retry behavior In order to reduce the workload of the system, it’s important to make sure that excessive retry behavior is avoided. Exponential backoff is a suitable approach, in which the time intervals for retries are successively incremented. You should also use so-called jitter, i.e., you add random noise to the retry intervals. This prevents your system from being hit by accumulating “load waves”, which is also known as retryamplification (see Figure 4)[5][10].
Also, there is a design pattern called a circuit breaker. Circuit breakers can be thought of as a type of switch. In the initial state, commands from an upstream service are allowed to pass through to a downstream service. If the errors increase, the circuit breaker switches to an open state and the system fails fast. This means the upstream service gets an error, allowing the downstream service to recover. After a certain time, the requests are gradually ramped up again. For instance, in the library Hystrix (which was already mentioned above) some kind of circuit breaker pattern is implemented [11].
Another approach to mitigating dangerous retry behavior would be to set a server-side retry budget, meaning you only retry a certain number of requests per minute. Everything that exceeds the budget is dropped. However, in all cases a global view is important here. It should be avoided at all costs to execute retries on multiple levels of the software architecture, as this can grow exponentially [4].
Finally, it should be noted that retries should be idemponent and free from side effects. It can also be beneficial in terms of system complexity to make calls stateless [10].
Antipattern 3: Crashing on bad input
The system should ensure that servers do not crash due to bad input. Such crashes, combined with retry behavior, can lead to catastrophic consequences such as one server crashing after another. In particular, inputs from outside should be carefully checked in this regard. Using fuzz tests is a good way to detect these types of problems [5].
Antipattern 4: Proximity-based failover
Make sure that not all of your traffic is redirected to the nearest data center, as it can become overloaded as well. The same logic applies here as with the failures of individual servers in a cluster, where one machine can fail after the other. So, to increase the resilience of your system, load must be redirected in a controlled manner during failover, which means you have to consider the maximum capacity of each data center. DNS, based on IP-Anycast, eventually forwards the traffic to the closest data center, which could be problematic [5].
Antipattern 5: Work prompted by failure
Failures often cause additional work in the system. In particular, a failure in a system with only a few nodes can lead to a lot of additional work (e.g., replication) for the remaining nodes. This can lead to a harmful feedback loop. A common mitigation strategy would be to delay or limit the amount of replication [5].
Antipattern 6: Long startup times
In general, processes are often slower at the beginning. This is for instance because of initialization processes and runtime optimizations [10]. After a failover, services and systems often collapse due to the heavy load. To prevent this, you should prefer systems with a fast startup time [5]. Also, caches are often empty at system startup. This makes queries more expensive as they have to go to the origin. As a result, the risk of a crash is higher than when the system is running in a stable mode, so make sure to keep caches available [4].
In addition to these six antipatterns, there are other system components or parameters that should be checked. For example, you can look at your deadlines for requests or RPC calls. In general, it is difficult to set good deadlines here. But one common problem you frequently encounter in the context of cascading failures is that the client misses many deadlines, which means that a lot of resources are wasted [4]. This was also the case in the AWS DynamoDB example from the beginning. The server – in general – should check if there is still time left until the deadline is reached to avoid working for nothing. A common strategy is so-called deadline propagation. Here, there is an absolute deadline at the top of the request tree. The servers further down only get the time value that is left after the previous server has done its calculations. Example: Server A has a deadline of 20 seconds and needs 5 seconds for the calculation, then server B has a deadline of 15 seconds and so on [4].
Conclusion
Cascading failures are a dreaded and at the same time special phenomenon in distributed systems. That’s because sometimes counterintuitive paths must be taken to avoid them, e.g., customizations actually intended to reduce errors, such as what appears to be intelligent load balancing, can increase the risk of total failures. And sometimes it’s just better to simply show an error message to your customer, instead of implementing a sophisticated retry logic and risking a DDoS against your own system. However, compromises often have to be made here. Testing, capacity planning, and applying certain patterns in system design can help to improve the resilience of your system.
After all, the lessons learned, and postmortems of large technology companies provide a good guide for further action to avoid cascading failures in the future. However, it can also be worth keeping an eye on the latest hypes and trends.
List of Sources
[2] S. (2015, September 27). SentinelOne | Irreversible Failures: Lessons from the DynamoDB Outage. SentinelOne. https://www.sentinelone.com/blog/irreversible-failures-lessons-from-the-dynamodb-outage-2/
[3] Beckett, L. (2021, October 5). Facebook platforms back online – as it happened. The Guardian. https://www.theguardian.com/technology/live/2021/oct/04/facebook-down-instagram-whatsapp-not-working-latest-news-error-servers
[4] Murphy, N. R., Beyer, B., Jones, C., & Petoff, J. (2016). Site Reliability Engineering: How Google Runs Production Systems (1st ed.). O’Reilly Media.
[5] Nolan, L. (2021, July 11). Managing the Risk of Cascading Failure. InfoQ. https://www.infoq.com/presentations/cascading-failure-risk/
[6] Amazon DynamoDB – Häufig gestellte Fragen| NoSQL-Schlüssel-Werte-Datenbank | Amazon Web Services. (2021). Amazon Web Services, Inc. https://aws.amazon.com/de/dynamodb/faqs/
[7] Patra, C. (2019, April 19). The DynamoDB-Caused AWS Outage: What We Have Learned. Cloud Academy. https://cloudacademy.com/blog/aws-outage-dynamodb/
[8] Nolan, L. (2020, February 20). How to Avoid Cascading Failures in Distributed Systems. InfoQ. https://www.infoq.com/articles/anatomy-cascading-failure/
[9] Summary of the Amazon DynamoDB Service Disruption and Related Impacts in the US-East Region. (2015). Amazon Web Services, Inc. https://aws.amazon.com/de/message/5467D2/
[10] The Anatomy of a Cascading Failure. (2019, August 5). YouTube. https://www.youtube.com/watch?v=K3tgWsMxaAU
[11] Osman, P. (2018). Microservices Development Cookbook: Design and build independently deployable, modular services. Packt Publishing.
[12] Arya, S. (2020, January 23). Hystrix: How To Handle Cascading Failures In Microservices. All About Buying & Selling of Used Cars, New Car Launches. https://www.cars24.com/blog/hystrix-how-to-handle-cascading-failures-in-microservices/
[13] Architecture. (2020). Istio. https://istio.io/latest/docs/ops/deployment/architecture/
Leave a Reply
You must be logged in to post a comment.