Anmerkung: Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst
Offene Software hat ihren Ursprung zu einer Zeit, in welcher der Austausch von Quellcode selbstverständlich war. Erst Mitte der 1970er Jahre begann man, Software als geistiges Eigentum zu betrachten und rechtlich zu schützen. AT&T entwickelte das Unix-Betriebssystem, dessen Quellcode anfangs noch offen war, später aber unter eine restriktive Lizenz gestellt wurde [1]. Ein Wendepunkt hin zur Kommerzialisierung von Software. Dadurch wurde ein Widerstand angeregt. 1983 gründete Richard Stallman die Free Software Foundation. Er wollte eine freie Alternative zum proprietären Unix-Betriebssystem schaffen und setzte sich für frei verfügbare und anpassbare Software ein. Daher entwickelte er das GNU-Projekt was einen Grundstein in der Geschichte der offenen Software legt [2].

Der Name GNU steht für „GNU’s Not Unix“, ein rekursives Akronym. Damit wollte Stallman ausdrücken, dass GNU zwar ähnlich wie Unix funktioniert, aber keine proprietären Bestandteile enthält. Es liefert viele wichtige Software-Komponenten wie Compiler (z. B. GCC), Editoren, Bibliotheken und Shells [3]. Diese Philosophie führte zur Entstehung der Open Source Bewegung. Sie gewann in den 1990er Jahren an Bedeutung und hat mittlerweile auch den Bereich der Künstlichen Intelligenz erreicht. Open Source AI-Modelle sind frei verfügbare KI-Systeme, deren Quellcode öffentlich zugänglich ist. Sie ermöglichen Unternehmen mehr Flexibilität und Innovationspotenzial, werfen aber auch neue Fragen auf. Der folgende Artikel zeigt, welche Vorteile und Nachteile Open Source KI für ein Unternehmen mit sich bringt und wie sich diese Technologien verantwortungsvoll und strategisch nutzen lassen.
Als erstens gehe ich auf die Vorteile von Open Source KI ein. Ein zentraler Teil jedes Unternehmens ist die Kostenoptimierung. Sie bietet Flexibilität bei der Preisfestlegung eines Produkts und hilft gleichzeitig bei der Gewinnmaximierung und genau hier kann Open Source KI punkten.
Verteilung der Entwicklungskosten einer KI
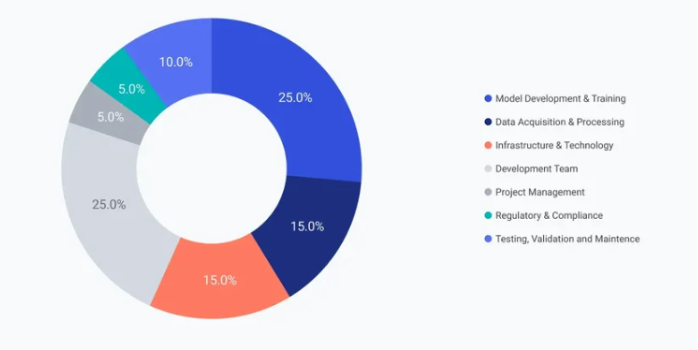
[4]
Die vollständige Neuentwicklung einer KI insbesondere eines großen Sprachmodells gehört zu den kostenintensivsten Vorhaben in der Softwareentwicklung. Der Großteil der Kosten entfällt auf den Aufbau und das Training eigener Modelle, was umfangreiche Datenmengen, hochspezialisierte Fachkräfte sowie eine teure Recheninfrastruktur voraussetzen. Bereits das Training eines modernen Sprachmodells im Milliardenparameterbereich kann Kosten im zweistelligen Millionenbereich verursachen. So fallen beispielsweise bei der Nutzung von NVIDIA A100-GPUs mit einem Stundensatz von etwa $2 über mehrere Millionen GPU-Stunden leicht $3–5 Millionen allein an Hardwarelaufzeitkosten an [4]. Hinzu kommen Personalkosten für Data Scientists und Machine-Learning- Ingenieure, die bei einem Team von fünf bis acht Personen über 6–12 Monate weitere $300.000, bis mehrere Millionen betragen können. Die Löhne hängen stark von der Erfahrung der Fachkraft und dem Standort ab. Zum Beispiel liegt das durchschnittliche Einkommen eines Data Scientists in den USA bei $120.000 bis $180.000, während es in Europa nur €60.000 bis €100.000 Euro beträgt [4]. Auch müssen große Datenmengen beschafft, bereinigt, annotiert und gespeichert werden ein weiterer Kostenblock von $10.000 bis $90.000 je nach Daten Art und Projektkomplexität [4]. Auch proprietäre APIs sind keine gute Lösung. Unternehmen, die proprietäre APIs wie GPT-4 einsetzen, zahlen in der Regel pro Anfrage basierend auf der Menge verarbeiteter Tokens. Das klingt zunächst günstig, da wenige Cent pro Interaktion verlangt werden z.B. ChatGPT 4.1. sind es $2 pro 1 Millionen Token Eingabe und $8 pro 1 Millionen Token Ausgabe [5]. Diese Kosten summieren sich jedoch schnell bei wachsendem Nutzeraufkommen. Schon bei mittlerem Volumen von 100.000 Anfragen pro Monat entstehen schnell Kosten von über $3600 monatlich, ohne dabei die API-Integration, Sicherheitsmaßnahmen, Datenschutzprüfungen und Wartungskosten zu berücksichtigen. Im Vergleich dazu bieten Open-Source KI Modelle wie LLaMA, einen enormen Kostenvorteil, da die zugrunde liegende Architektur und die vortrainierten Gewichte öffentlich zugänglich sind, entfallen die meisten der initialen Entwicklungskosten vollständig. Statt Millionen für Modelltraining auszugeben, konzentrieren sich Unternehmen bei der Open-Source-Nutzung auf Fine-Tuning, Integration und Anwendungsentwicklung. Feinjustierung eines Modells kann abhängig von Datenmenge und Trainingsdauer zwischen $5.000 und $50.000 kosten. Fein-Tuning eines 70B LLM kostet im Cloud Service ungefähr $950 pro Monat und selbst organisiertes Fein-Tuning kostet ungefähr $3600 pro Monat [6]. Diese Maßnahmen sind im Vergleich zur vollständigen Entwicklung deutlich günstiger. Trotz aller Vorteile ist Open Source eben leider nicht vollständig kostenfrei.
Ein weiterer wichtiger Aspekt ist, dass keine Bindung an einen Anbieter erfolgt. Ein wesentlicher Vorteil von Open Source KI liegt in der Unabhängigkeit gegenüber externen Anbietern. Unternehmen, die auf Open Source setzen, behalten die volle Kontrolle über die eingesetzten Systeme, die Datenverarbeitung sowie die gesamte Infrastruktur. Wer dagegen auf proprietäre KI-Dienste wie ChatGPT von OpenAI zurückgreift, gibt einen Teil dieser Kontrolle aus der Hand. Wenn man sich die Nutzungsbedingungen und Datenschutzhinweise von OpenAI anschaut, wird schnell klar, wie viele persönliche Daten bei der Nutzung solcher Dienste erfasst und verarbeitet werden [7]. Das betrifft zum Beispiel Kontoinformationen wie Name, Kontaktangaben, Zahlungsdaten und auch die Historie der Transaktionen. Aber nicht nur dass auch alle Inhalte, die man eingibt, wie Texte, hochgeladene Dateien, Bilder oder Audiodateien, werden erfasst [7]. Zusätzlich speichert OpenAI technische Informationen wie IP-Adressen, Geräte- und Browserdaten sowie ungefähre Standortangaben. Diese Daten können darüber hinaus mit Dritten geteilt werden, etwa mit Dienstleistern, Sicherheitsfirmen oder wenn es gesetzlich vorgeschrieben ist [7]. Gerade für Unternehmen, die besonders sensibel mit Daten umgehen müssen, zum Beispiel im Gesundheitswesen oder in der Industrie, kann das zu einem echten Problem werden. Im Gesundheitsbereich besteht zum Beispiel die Gefahr, dass sensible Patientendaten etwa aus Arztbriefen oder Diagnoseberichten unbeabsichtigt über proprietäre KI-Dienste in fremde Cloud-Systeme gelangen. Wenn diese Informationen zentral bei einem US-Anbieter verarbeitet oder gespeichert werden, kann das nicht nur datenschutzrechtlich problematisch sein (DSGVO), sondern auch das Vertrauen von Patienten massiv beeinträchtigen. Ein weiteres Beispiel betrifft Betriebsgeheimnisse. Wenn ein Unternehmen einem KI-Tool interne Dokumente zur Verfügung stellt, zum Beispiel Unterlagen zur Produktentwicklung oder technische Patente und diese Daten dann in die Trainingsdaten des Anbieters einfließen oder auf dessen Servern gespeichert werden, kann das schnell problematisch werden. Im schlimmsten Fall könnten vertrauliche Informationen so nach außen gelangen, was einen erheblichen Wettbewerbsnachteil bedeutet. Mit Open Source KI-Lösungen, die man entweder lokal oder in der eigenen Cloud betreibt, lassen sich solche Risiken größtenteils vermeiden. Der Datenfluss bleibt innerhalb des Unternehmens, und sowohl Trainingsdaten als auch Nutzereingaben können komplett selbst kontrolliert werden. Außerdem ist es damit einfacher, die Anforderungen an den Datenschutz etwa die DSGVO transparent und zuverlässig einzuhalten.
Als letzten Punkt möchte ich auf die verbesserte Personalisierung eingehen. Mit Open-Source-Modellen wie LLaMA haben Unternehmen die Möglichkeit, nicht nur das Modellverhalten über Prompting zu beeinflussen, sondern es auch gezielt mit eigenen Daten zu feinjustieren. Dies reicht von leichtgewichtigen Fine-Tuning-Methoden wie LoRA/QLoRA bis hin zu vollständig eigenständigen Trainingspipelines, etwa zur Umsetzung spezieller Sprachstile, Wissensdomänen oder Dialogstrategien. So kann ein Unternehmen z. B. ein Modell trainieren, das juristische Fachsprache versteht, oder eines, das ausschließlich auf firmeninterne Abläufe und Daten ausgerichtet ist. Im Gegensatz dazu ist die Personalisierung bei proprietären Diensten wie ChatGPT stark eingeschränkt. Derzeit lässt sich nur das Modell gpt-3.5-turbo überhaupt finetunen, und das auch nur über eine API mit strengen Formatvorgaben. Die leistungsfähigeren Modelle wie Gpt-4o können nicht feinabgestimmt werden. Man kann sie lediglich über Prompt Engineering beeinflussen, was bei komplexen Anforderungen oft nicht ausreicht. Auch der Zugriff auf interne Modellgewichte oder Trainingstechniken bleibt bei ChatGPT vollständig verwehrt, was eine tiefere Anpassung oder Integration in bestehende Machine Learning Pipelines unmöglich macht.
Als nächstes gehe ich auf die negativen Aspekte von Open Source Alternativen ein. Ein erheblicher Nachteil beim Einsatz von Open Source KI-Lösungen in Unternehmen besteht in den Sicherheitsrisiken, die durch begrenzte personelle Ressourcen, unklare Verantwortlichkeiten und mangelnde Kontrolle entstehen. Gerade weil der Quellcode offen zugänglich ist, kann potenziell jede Person auch mit böswilligen Absichten mehrere Änderungen vorschlagen oder sich in ein Projekt einklinken. Wird der Code nicht regelmäßig und sorgfältig überprüft, entstehen so gefährliche Möglichkeiten für Angriffe. Ein gutes Beispiel dafür ist der Fall rund um die Komprimierungssoftware xz. Diese weitverbreitete Open Source Komponente, die auf unzähligen Linux-Systemen darunter auch Server, Entwicklerrechner und IoT-Geräte vorinstalliert ist, wurde durch eine hochprofessionelle eingebettete Backdoor kompromittiert [8]. Die Manipulation erfolgte durch einen Entwickler mit dem Pseudonym “Jia Tan”, der sich über Monate hinweg als vertrauenswürdiger Mitwirkender etablierte. Nach und nach übernahm er zentrale Aufgaben im Projekt, das zuvor hauptsächlich von einem einzelnen Maintainer betreut wurde, der aufgrund psychischer Belastung zunehmend ausfiel. Die Entdeckung dieser kritischen Schwachstelle ist dem Zufall und der Aufmerksamkeit eines einzelnen Entwicklers zu verdanken. Andres Freund ein Open-Source Entwickler, der bei Microsoft angestellt ist. Während seiner Arbeit an einer Open-Source Datenbank bemerkte Freund ungewöhnlich hohe CPU-Lasten auf einem Testsystem. Nach einer mühsamen und technisch anspruchsvollen Analyse konnte er die Ursache bis zur manipulierten xz-Bibliothek zurückverfolgen und öffentlich machen. Damit verhinderte er möglicherweise einen groß angelegten Cyberangriff mit verheerenden Auswirkungen [8].
Freunds Aussage nach dem Vorfall ist bezeichnend:
„Ich bin sicher, dass vielen erfahrenen Entwicklern von Open-Source Software einige große und wichtige Projekte einfallen würden, in denen sie einigermaßen leicht etwas Kleines in einem größeren Update hätten verstecken können.“ [8]
Genau darin liegt die Gefahr in Open-Source Projekten mit wenigen Maintainern und wenig institutioneller Kontrolle ist es technisch möglich, Schadcode unbemerkt einzuschleusen und über reguläre Updateprozesse zu verteilen. Für Unternehmen bedeutet das, dass beim Einsatz von Open Source KI-Komponenten erheblicher interner Aufwand nötig ist, um alle verwendeten Abhängigkeiten regelmäßig auf Sicherheitslücken zu überprüfen. Andernfalls besteht die konkrete Gefahr, unbemerkt zum Ziel professioneller und technisch ausgefeilter Cyberangriffe zu werden. Im Vergleich dazu stehen proprietäre Lösungen von Unternehmen, die in der Regel über eigene Sicherheitsteams verfügen und im Falle von Schwachstellen haftbar gemacht werden können, was für Unternehmen eine zusätzliche Absicherung darstellt.
Ein weiteres Problem bei der Nutzung von Open Source KI-Lösungen ist die Unsicherheit über deren Ethik und überhaupt das Fehlen eines konsistenten moralischen Fundaments. Anders als bei proprietären Lösungen mit klaren Leitlinien und kontrollierten Trainingsdaten fehlt bei Open Source oft die Transparenz darüber, wer die KI mit welchen Werten trainiert hat und welche gesellschaftlichen oder ideologischen Bias sich dabei eingeschlichen haben. Ein Beispiel dafür ist die Kontroverse um den KI-Chatbot Grok, entwickelt von Elon Musks Unternehmen xAI [9]. Grok wurde beschuldigt, mehrfach antisemitische Aussagen verbreitet zu haben darunter die absurde und gefährliche Behauptung, Adolf Hitler sei eine geeignete Figur zur Lösung “antiweißer Narrative”. Die Entwickler führten das Fehlverhalten unter anderem darauf zurück, dass der Bot “zu sehr darauf aus war, zu gefallen und manipuliert zu werden” [9]. Doch genau darin liegt die ethische Gefahr. Wenn eine KI nicht ausreichend gegen Manipulation geschützt ist, reflektiert sie die moralischen Abgründe ihrer Nutzer statt objektiver Werte. Gerade bei Open Source Modellen ist dieses Risiko besonders hoch. Unternehmen können den ethischen Rahmen des Modells meist nicht vollständig nachvollziehen und damit auch nicht garantieren, dass die KI diskriminierende, extremistische oder manipulative Inhalte vermeidet. Da die Modelle oft mit riesigen, unkontrollierten Datensätzen aus dem Internet trainiert werden, spiegeln sie automatisch auch die toxischen Seiten dieser Datenbasis wider. Für Unternehmen kann der Einsatz solcher unkontrollierten Systeme massive Reputationsrisiken bedeuten, insbesondere wenn die KI öffentlich oder im Kundenkontakt eingesetzt wird. Hier fehlt Open-Source-KI-Lösungen oft die nötige Robustheit und Verantwortung.
Open Source KI bietet Unternehmen eine Vielzahl an Vorteilen insbesondere in den Bereichen Kostenreduktion, Anpassungsfähigkeit, Unabhängigkeit von Anbietern und Datenschutzkontrolle. Der offene Zugang zu leistungsfähigen Modellen wie LLaMA ermöglicht es Firmen, individuelle und innovative Lösungen zu entwickeln, ohne die enormen Aufwände einer vollständigen Neuentwicklung tragen zu müssen. Gleichzeitig eröffnet die Personalisierbarkeit solcher Modelle völlig neue Wege der Unternehmensdigitalisierung. Doch der Einsatz von Open Source bringt auch ernstzunehmende Risiken mit sich. Sicherheitslücken, mangelnde Wartung, ethische Intransparenz und die Gefahr von Manipulationen können gravierende Folgen haben insbesondere für Unternehmen in sensiblen Branchen. Der offene Charakter, der viele Vorteile mit sich bringt, erfordert gleichzeitig ein hohes Maß an technischer Kompetenz und Eigenverantwortung im Umgang mit KI. Also wird es aus Sicht des Unternehmens eine Abwägungssache bleiben, ob man Open Source KI einsetzt oder nicht.
In Zukunft wird Open Source eine zentrale Rolle in der Weiterentwicklung und Demokratisierung von Künstlicher Intelligenz spielen. Immer mehr Unternehmen erkennen das Potenzial freier KI-Modelle und investieren in eigene Infrastruktur, um Unabhängigkeit und Datensouveränität zu sichern. Gleichzeitig werden Standards, Sicherheitsrichtlinien und ethische Leitlinien für Open Source KI weiter an Bedeutung gewinnen. Gemeinnützige Organisationen wie LAION könnten hier künftig eine ähnliche Rolle spielen wie einst die Free Software Foundation im Bereich freier Software. Abschließenden sollten wir darauf hoffen, dass Open Source KI nicht nur als technische Alternative, sondern als strategisches Fundament für transparente, sichere und wertebasierte KI Systeme zu etablieren.
[1] https://www.ibm.com/think/topics/open-source
[3] https://www.gnu.org/software/software.de.html
[4] https://www.coherentsolutions.com/insights/ai-development-cost-estimation-pricing-structure-roi
[5] https://openai.com/de-DE/api/pricing
[6] https://scopicsoftware.com/blog/cost-of-fine-tuning-llms
Leave a Reply
You must be logged in to post a comment.