Für den Kurs “Software Development for Cloud Computing” wollte ich eine Anwendung entwickeln, mit der konkrete Aufgaben für ein gegebenes Lernziel generiert werden können. Der Nutzer stellt dabei Informationen zum Lernziel, sowie seines aktuellen Niveaus und der geplanten Lerndauer zur Verfügung. Auf dieser Basis können dann die konkreten Aufgaben, die zum Erreichen des Ziels nötig sind, generiert werden. Die Aufgaben bauen dabei auf einander auf, sodass der Nutzer von Tag zu Tag seine Fähigkeiten steigern kann. Des weiteren werden aktuelle Studien beim Generieren berücksichtigt. Die Aufgaben sollen in einem Frontend angesehen und als erledigt markiert werden können.
Mein Wissensstand – Der Status Quo
Ich hatte zuvor noch nie mit AWS oder anderen Cloudtechnologien gearbeitet und sah darin ein Thema mit großem Lernpotential für das Projekt. Des weiteren hatte ich keine Erfahrungen in der Cross-Platform-Entwicklung von Anwendungen, auch in diesem Bereich wollte ich mich durch das Projekt weiterentwickeln.
Im Entwickeln von Anwendungen mit KI-Integration hatte ich bereits ein paar Erfahrungen gesammelt, da ich in meinem Praxissemester an einer KI-gestützten Anwendung zur Prozessoptimierung mitgearbeitet hatte. Hier bekam ich Einblicke in die Verwendung von Frameworks zur Implementierung von KI-Agentensystemen.
Ein Faktor, der sich als eine mögliche Schwierigkeit in meinem Projekt abzeichnete, war die Teamgröße. Ich hatte vor, das Projekt alleine durchzuführen, da ich mir auch hiervon einige nützliche Erfahrungen versprach.
Der Weg zum Zielprojekt – Herausforderungen und Learnings
Ich begann die Arbeit an dem Projekt mit organisatorischen Überlegungen. Da ich alleine war, wollte ich den Umfang des Projektes nicht sprengen und die geplanten Funktionen zunächst auf ein nötiges Minimum reduzieren. Hierbei entschied ich mich dazu, dass die App folgende Features umfassen sollte:
- Anforderungen an die zu lernende Tätigkeit sollen eingegeben werden können
- KI-gestützt sollen konkrete Aufgaben generiert werden, die der Nutzer ausführen soll, um etwas zu erlernen
- Diese konkreten Aufgaben werden dann in der App angezeigt und können dort abgeschlossen werden
Dies war der für mich logisch erscheindende minimale Umfang für eine funktionale, aber nicht übermäßig aufwändig zu entwickelnde Anwendung. Später sollte sich der Aufwand allerdings dennoch als ziemlich groß herausstellen.
Den nächste Schritt des Projektes stellte die Technologieauswahl dar:
Die Auswahl der Spache für die Entwicklung des Backends erschien mir einfach: Python bot nach meinem Wissensstand den besten Support für Frameworks, mit denen sich LLMs (“Large Language Models”) in Code integrieren lassen und damit das Entwickeln von KI-gestützten Anwendungen ermöglichen. Eine andere Sprache zog ich nicht in Betracht, zumal die KI-Agentenframeworks, die ich während meines Praktikums verwendete, ebenfalls Python-Frameworks waren. Die Vorteile von Python in diesem Zusammenhang würde ich vor allem mit der großen Anzahl an Libraries, die das Entwickeln mit LLM-APIs ermöglichen, sowie die breite Unterstützung in Cloud-Umgebungen zusammenfassen. Ein möglicher Nachteil könnten Performanceprobleme, besonders im Fall einer möglichen Skalierung der Anwendung sein. Dies stellte für mich im Rahmen des Uniprojekts jedoch kein gravierendes Problem dar.
Für das Frontend, das in Form einer App im Cross-Plattform-Stil umgesetzt werden sollte, entschied ich mich zunächst für Flutter. Ich las in diesem Zusammenhang von der hohen Performance und der wachsenden Community und setzte ein lokales Flutter-Projekt auf. Der Beginn war jedoch mit einer Einarbeitung verbunden, da Flutter auf Dart, einer mir zu diesem Zeitpunkt unbekannten Programmiersprache basierte. Nachdem ich die Idee meines Projekts zum ersten Mal vorgestellt hatte, enschied ich mich aufgrund des holprigen Startes dazu, die Auswahl der Frontend-Technologie noch einmal zu überdenken. In diesem Zuge stieß ich auf React Native, das mir als das etabliertere, ausgereiftere Framework erschien. Des weiteren hatte ich in der Vergangenheit bereits Erfahrung mit React sammeln können, was den größten Vorteil für mich darstellte, da ich dadurch den Fokus des Projektes auf das Wesentliche, für mich vor allem das Verständnis des AWS-Universums, lenken konnte.
Zur Auswahl einer LLM-API, die meine Anwendung intelligent machen und das Generieren der Aufgaben ermöglichen sollte, verglich ich mehrere Anbieter. Ich enschied mich schließlich für die “Gemini-2.5-Flash”-API, da diese eine leistungsstarke aber dennoch kostenlose Lösung darstellte. Dies funktioniert unter der Bedingung der Datennutzung zum Training neuer Modelle, was zu Problemen hinsichtlich der Privatsphäre führen könnte. Im Rahmen meines Projekts war dies jedoch erneut ein Kompromiss, den ich eingehen konnte und musste, um Kosten zu vermeiden.
Die letzte Enscheidung war bezüglich des Deployments zu treffen. Ich entschied mich für das Deployment des Backend-Codes in einer AWS Lambda, da die geplante Funktionsweise des Backends gut zu meinem Verständnis von AWS Lambda passt. Eine Lambda ist ein ereignisgesteuerter Serverless-Dienst. Der Code meines Python-Backends wird also nur im Bedarfsfall, also bei einem API-Call, gestartet. Dadurch muss kein Server konstant aktiviert sein, durch Pay-per-Use können Kosten gespart werden. Die Aufgaben werden, durch Einbeziehen der externen LLM-API, generiert und nach dem Fertigstellen an den Client zurückgegeben. Zu diesem Zeitpunkt kann die Lambda wieder heruntergefahren werden. Diese asynchrone Kommunikation sollte mich später vor weitere Herausforderungen stellen (siehe unten).
Ein Learning aus Projekten der Vergangenheit war, dass sich durch detaillierte Plaung einige Probleme im Vorhinein verhindern lassen. So entschied ich mich, in diesem Projekt relativ viel Zeit in die Ausarbeitung der Projektidee im Vorhinein zu investieren, um später in einen flüssigeren Entwicklungsprozess kommen zu können.
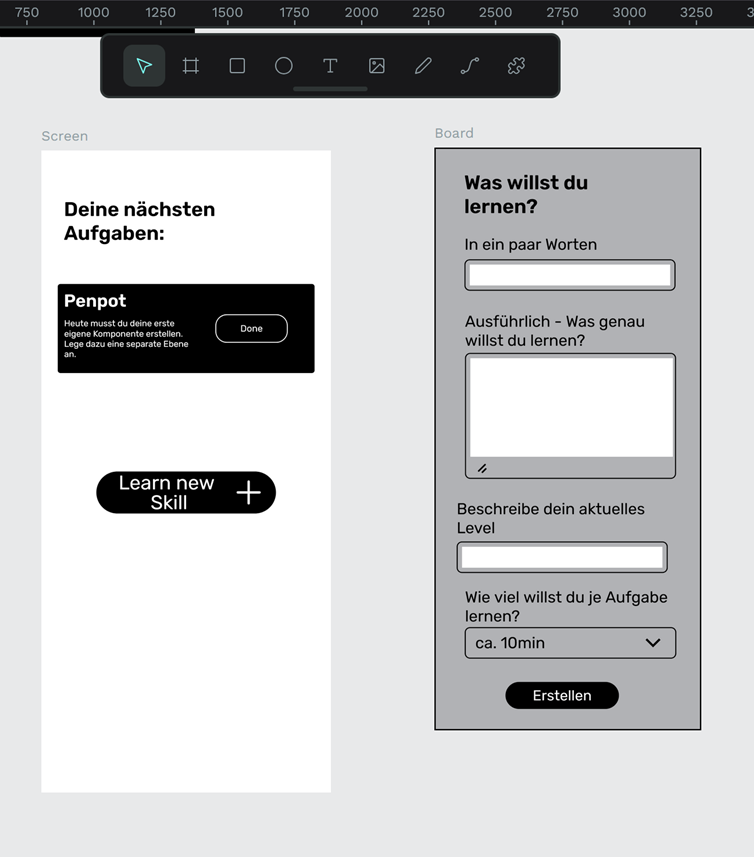
Zuerst entwickelte ich Wireframes der App. Ich recherchierte nach Alternativen zu Figma, da mich hier die Begrenzug der Anzahl an möglichen Projekten sowie die, nach meinem Gefühl starke Funktionslimitierung in der kostenlosen Version störte. Ich stieß auf Penpot, ein OpenSource-Tool, das ohne Einschränkungen auskam und mir geeignet erschien. Es verfügt über die Möglichkeit des Exports von CSS-Code, was den Designprozess beschleunigen kann und was bei Figma in der kostenlosen Version nicht möglich ist.
Ich erstellte Wireframes für eine Startseite sowie ein Popup-Fenster, das dem Generieren weiterer Aufgaben dienen sollte. Ich verwendete dabei ein minimalistisches Design, um auch in diesem Sinne dem Ziel, lediglich einen MVP zu implementieren, treu zu bleiben.
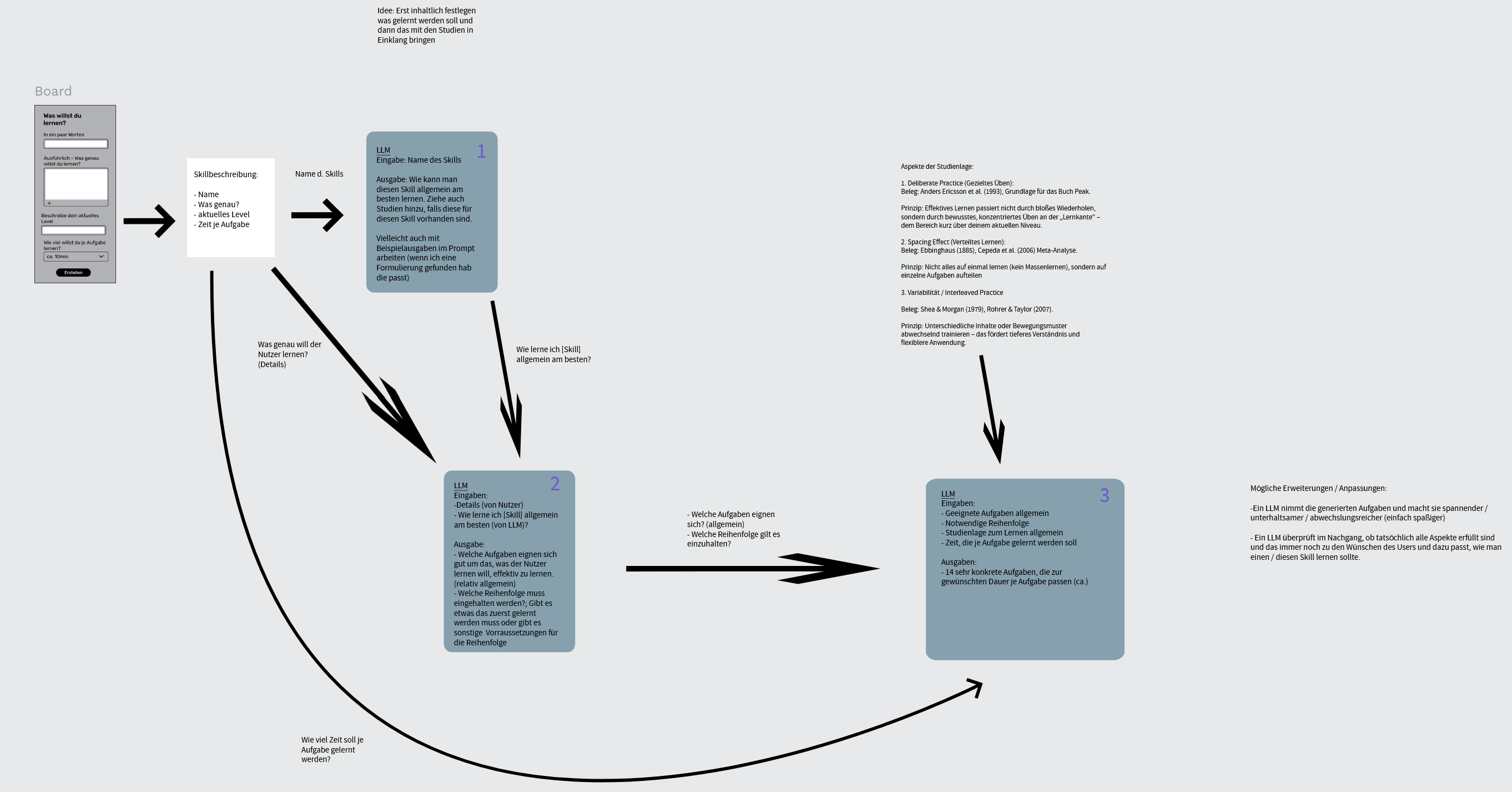
Als nächstes machte ich mir Gedanken zum Ablauf der LLM-Anfragen. Es sollten nicht direkt alle Angaben des Nutzers an das Modell gegeben werden, sondern stattdessen zuerst Informationen zur aktuellen Studienlage etc. generiert werden, die dann die Qualität der finalen Ausgaben des LLMs erhöhen sollten. Im Folgenden ist der Ablauf detailliert dargestellt:
Agentenframework: Google ADK
Als die inhaltlichen Überlegungen zum LLM-Ablauf gemacht waren, musste ich mich noch für ein Framework entscheiden, mit dem ich diesen Ablauf umsetzen würde. Ich entschied mich nach einiger Recherche für Google ADK. Zuvor hatte ich noch nicht mit diesem Framework gearbeitet, aber es erschien mir vielversprechend, bot umfangreiche Möglichkeiten zur Umsetzung verschiedener Hierarchien und hatte generell einen passenden Funktionsumfang. Es war für mich eher ein Vorteil, dass ich noch nicht mit dem Framework gearbeitet hatte, da ich meine Fähigkeiten in diesem Bereich gerne erweitern wollte. In der Vergangenheit hatte ich bereits mit LangGraph, DSPy, CrewAI und OpenAI Swarm gearbeitet und wollte diese Liste gerne erweitern.
In Google ADK legte ich die oben dargestellten Schritte jeweils als einzelne Agenten an, deren Ausgaben dann in die Instruktionen der folgenden Agenten übergeben wurden. Dies wird via des Attributs “output_key” ermgölicht. Der angegebene output_key kann dann in die Instruktion des folgenden Agenten integriert werden, wodurch auf die Ausgaben des vorherigen Agenten referneziert wird.
Der Agent “Step_3” generiert die finale Ausgabe in einem eigens spezifizierten Schema. Die Definition der Agenten sieht folgendermaßen aus:
from google.adk.agents import Agent
from agentic_sys.models import FinalTaskOutputList
from utils import load_instructions
from google.adk.agents import SequentialAgent
step1_agent = Agent(
name="Step_1",
model="gemini-2.5-flash",
description="Dieser Agent recherchiert, wie man auf Basis der Studienlage am besten lernt.",
instruction=load_instructions(1),
include_contents='none',
output_key="general_study"
)
Die Agenten sollten nach einander ausgeührt werden, was in Google ADK durch den “Sequence Agent” ermöglicht wird:
from google.adk.agents import SequentialAgent
from agentic_sys.agent import step1_agent, step2_agent, step3_agent
sequence_agent = SequentialAgent(
name="Sequence_Agent",
description="Executes all steps sequentally.",
sub_agents=[step1_agent, step2_agent, step3_agent]
)
root_agent = sequence_agentEntwicklung der App
Ich startete den eigentlichen Entwicklungsprozess meiner App mit der Einarbeitung in Flutter. Ich las mich in die Dokumentation ein, merkte jedoch relativ schnell, dass ich nicht auf Anhieb warm damit wurde und entschied mich dann aus besagten Gründen zu einem Wechsel zu React Native. Ich setzte ein neues Projekt mit React Native in Expo, einem Framework, das das Entwickeln, Testen und Deployen von React Native Apps vereinfacht, und erarbeitete mir die Grundlagen des Frameworks. Ich hatte jedoch von Anfang an einige Probleme und musste viel Arbeit leisten, um die ersten Komponenten tatsächlich auf dem Bildschirm zu sehen. Die gewissen Eigenheiten, die Expo mit sich brachte, musste ich erst einmal verstehen. So waren z.B. nicht alle Funktionen des “reinen” React Native mit Expo kompatibel, was ich zuerst erkennen und anpassen musste. Ein Vorteil des Frameworks war, dass ich die Komponenten per Expo-App auf meinem Smartphone anzeigen lassen konnte, was ein (meist) komfortables Testerlebnis ermöglichte.
Ich erstellte die Komponente des Homescreens und des Popups zum Generieren weiterer Aufgaben. Für das Styling verwendete ich Nativewind, das praktischer zu handhaben, schneller zu schreiben und übersichtlicher ist als normales CSS per Stylesheet. Zudem verwendet NativeWind die bekannten Tailwind CSS-Klassen, was mit einer großen Community einhergeht. NativeWind funktioniert plattformübergreifend und hat einen geringen Runtime-Overload.
Deployment in AWS
Ich Entschied aufgrund des Aufwands vorerst auf ein automatisiertes Deployment via Terraform zu verzichten. AWS bietet ein manuelles Deployment der Python-Files via Zip-Upload in die AWS Lambda an, was ich nutzen wollte. Dazu musste ich zunächst die Dateien samt aller Dependencies in eine passende Form bringen: Alle .py-Dateien mussten auf der gleichen Ebene liegen. Hier stieß ich auf mein erstes größeres Problem. Die Größe der Zip, die hochgeladen werden kann, ist auf 250MB begrenzt. Die Dependency “Google ADK” übersteigt diese Größe bei weitem, was dazu führte, dass ein Upload nicht möglich war. Mit diesem Problem hatte ich nicht gerechnet, generell war mir nicht bewusst gewesen, dass Dependencygrößen zu Problemen bei Deployments führen können. Meine Alternativen waren folgende:
Entweder würde ich vom Gedanken der Serverless-Function weggehen und stattdessen in AWS Fargate, einem Serverless-Container-Dienst deployen. Dies würde jedoch mit langsameren Startzeiten einhergehen. Außerdem würde nach meinem Verständnis der große Vorteil von AWS Lambda in meinem Anwendungsfall, dass sich die Lambda automatisch beendet wenn die Generierung der Aufgaben abgeschlossen ist, verloren gehen.
Die zweite Lösung des Problems bestünde darin, das Agentenframework “Google ADK” durch ein anderes, kleineres zu ersetzen, was jedoch eine erneute Programmierung des Agentensystems nötig machen würde. Ich entschied mich dennoch für diese Variante, da ich AWS Lambda für eine gute Lösung hielt und den Aufwand für die Anpassung für machbar hielt. Ich wählte LangGraph als alternatives Framework aus, die Größe betrug deutlich unter 100MB, was ein problemloses Deployment ermöglichen würde. Da ich bereits Erfahrungen in LangGraph gesammelt hatte, gelang mir das Erstellen des neuen KI-Systems relativ schnell. Das Deployment funktionierte, nachdem ich die Python Version der Lambda mit der Version des hochgeladenen Codes abglich.
Die nächste Entscheidung, die ich treffen musste, war das Speichern der Umgebungsvariablen in AWS. Dies betraf vor allem den API-Key zur externen Google-Gemini-API. Ich entschied mich dazu, die Variable als Secure String im AWS Systems Manager Parameter Store zu speichern. Eine Speicherung in einer Lambda-Umgebungsvariablen ist mit Sicherheitsrisiken verbunden. Eine Speicherung im AWS Secrets Manager ist mit Kosten verbunden, was für mich auch nicht in Frage kam.
Damit einher ging die nächste Herausforderung, die ich auch später beim Anbinden an das API-Gateway und andere Services erneut aufkommen sollte: Ich musste Berechtigungen vergeben, um den Zugriff auf Ressourcen über unterschiedliche AWS Services hinweg zu ermöglichen. Hier halfen mir Tutorials herauszufinden, welche Berechtigungen für meinen Anwendungsfall nötig war zu erteilen. Fogende Einträge ermöglichten beispielsweise den Zugriff aus der Lambda auf die Umgebungsvariablen, die im Parameter Store gespeichert sind:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ssm:GetParametersByPath",
"ssm:GetParameter"
],
"Resource": "arn:aws:ssm:eu-central-1:xxxx:parameter/skillstruct/google_ai"
}
]
}Des weiteren musste ich den Code so anpassen, dass er über ein API-Gateway aufgerufen werden kann. Das Erstellen eines API-Gateways war erneut mit dem Erteilen von Berechtigungen verbunden. Auf die per API gesendeten Inhalte konnte ich über ein Event-Objekt zugreifen, das an den Code der Lambda übergeben wird.
Ein weiteres Problem war, dass das Generieren der Aufgaben via LLM relativ lang dauerte und die maximale Lauzeit der Lambda überschritt. Es kam zu einem Timeout. Die Lösung des Problems war jedoch ziemlich simpel: Ich musste lediglich den Schwellenwert im AWS Dashboard erhöhen, der festlegt, nach wie vielen Sekunden sich die Lambda durch einen Timeout beenden sollte.
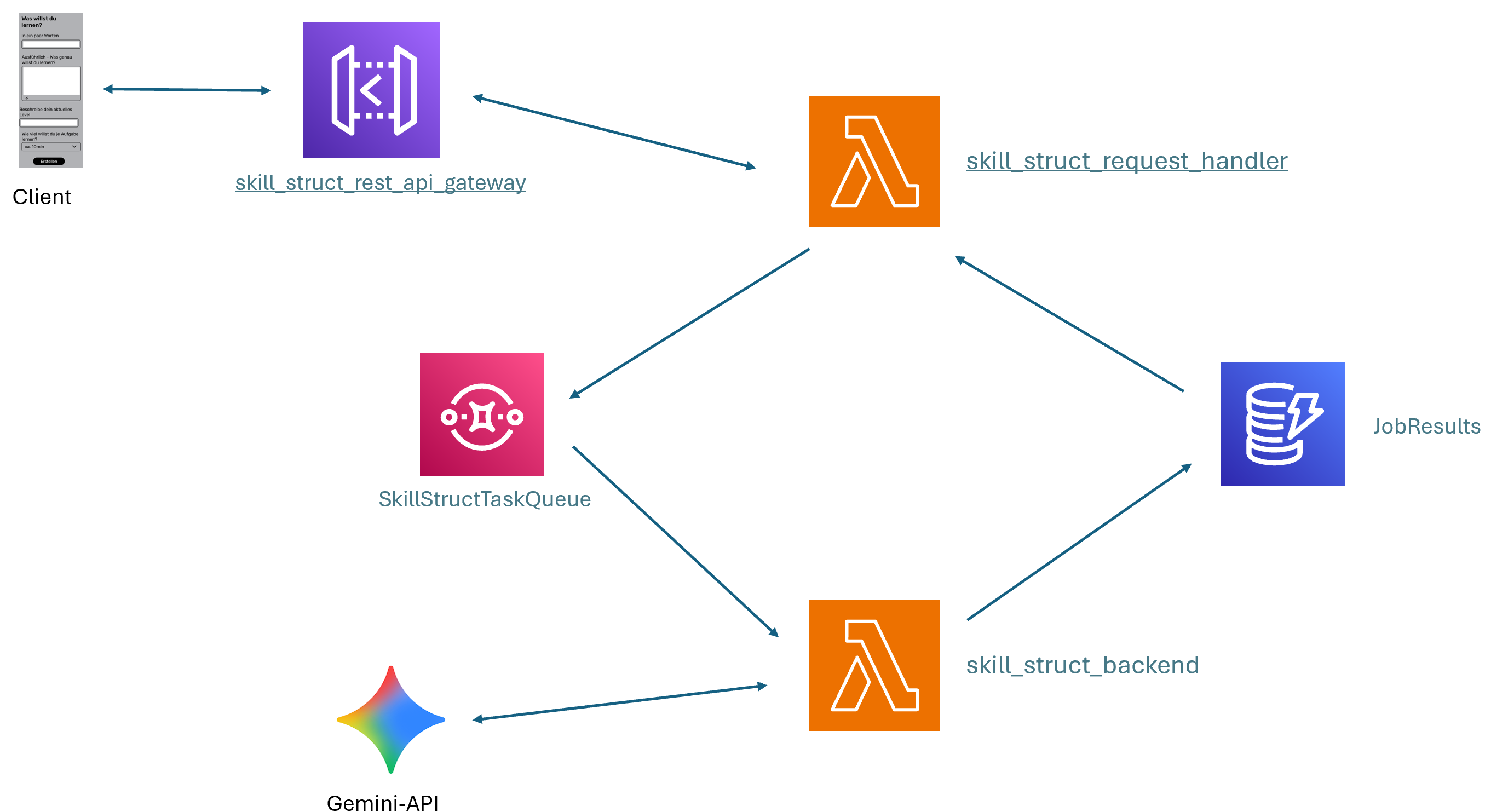
Das letzte größere Problem war Folgendes: Das API-Gateway wartet maximal 29 Sekunden auf die Generierung der Antwort durch die Lambda. Durch die Anbindung an das LLM dauerte die Generierung der Antowort jedoch länger. Um dieses Problem zu umgehen, musste ich meine AWS Architektur umbauen. Ich fügte eine zweite Lambda hinzu, die mit dem API-Gateway verbunden ist und die API-Anfragen des Clients samt der zum Generieren notwendigen Informationen entgegennimmt. Die Lambda legt einen neuen Job, bestehend aus einer Job-ID und den Informationen des Clients, an und gibt ihn in den AWS Simple Queue Service (SQS). Ich entschied mich für AWS SQS über Alternativen wie z.B. RabbitMQ, da es nativ in AWS integriert ist und optimal mit AWS Lambda etc. funktioniert. Es war keine tiefe Einarbeitung nötig und war schnell einsatzbereit.
Die Job-ID wird an den Client zurückgegeben. Die ursprüngliche Lambda wurde zur Worker-Lambda umfuntioniert und nun durch einen neuen Task in der SQS getriggert. Die Aufgaben werden wie zuvor generiert, nach Abschluss jedoch in einer DynamoDB gespeichert. Ich entschied mich für DynamoDB über Alternativen wie Amazon RDS, da DynamoDB sehr “serverless-freundlich” mit nativer Anbindung an Lambda ist. Es war die für mich naheliegendste Wahl, ohne große Einarbeitungsaufwände. Die generierten Aufgaben können dann per Job-ID referenziert werden.
Der Client pollt, nachdem er die Job-ID als Anwort auf seine Anfrage erhalten hat, mit Übergabe dieser an die Lambda auf eine generierte Antwort. Wenn die Job-ID bei der Anfrage gesetzt ist, wird kein neuer Job angelegt sondern stattdessen in der DynamoDB abgefragt, ob der Job bereits abgeschlossen ist. In dem Fall werden die Aufgaben an den Client zurückgegeben.
Im Folgenden ist eine Übersicht der Architektur dargestellt:
Ein Problem, das bis zuletzt ohne zufriedenstellende Lösung blieb, war für mich das Debugging in AWS. Zwar war es dank CloudWatch möglich, Ausgaben von Print-Statements in der Konsole zu loggen, Debugging im klassischen Sinne mithilfe von Breakpoints war jedoch nicht möglich. Dadurch war ich mit einigen Problemen etwas länger beschäftigt, als es meiner Meinung nach hätte sein müssen.
Tests
Ich schrieb meine Tests erst, nachdem ich die App samt Backend bereits entwickelt hatte. Ich nehme mir vor, dies in den kommenden Projekten bereits zu einem früheren Zeitpunkt zu machen, da der Entwicklungsprozess von Tests durchaus profitieren kann und Fehler schneller auffallen, wodurch die Produktivität steigt.
Im Frontend erstellte ich Unittests und testete die Komponenten mit React Native UI-Tests. Im Backend erstellte ich ebenfalls Unittests für alle Bereiche der Anwendung sowie einen Integrationtest mit LocalStack, um die AWS-Komponenten in die Tests zu integrieren.
Meine Learnings
Auf technischer Ebene habe ich vor allem einen Einblick in das AWS-Universum bekommen. Auch für die Cross-Plattform-Entwicklung konnte ich durch die React-Native App ein Gefühl bekommen.
Zudem konnte ich in diesem Projekt einige allgeine Learnings machen: Viele Aufgaben schienen am Anfang eher trivial, sollten sich bei genauerem Betrachten jedoch als umfangreich heruasstellen und waren mit dementsprechend viel Zeitaufwand verbunden.
In einigen Situationen hätte ich durch frühere Architekturünerlegungen im Entwicklungsprozess evtl. Zeit sparen können. Auf der anderen Seite tauchten auch hier einige Probleme erst kurzfristig auf und wären bei der frühzeitigen Planung möglicherweise unentdeckt geblieben.
Generell habe ich in diesem Projekt gelernt, dass es für ein Endprodukt meist viele Lösungswege gibt und die Entwicklung, gerade auch bei Cloud-Technologien, viel mit dem Abwägen zwischen verschiedenen Komponenten und deren Vor- und Nachteilen zu tun hat.
Etwas konkreter hatte ich immer wieder mit den Einflussfaktoren, die es bei asynchroner Übertragung zu beachten gilt, zu tun. Einige Probleme wurden durch Timeouts etc. verursacht und deren Lösung hing teilweise mit einem Umbau der kompletten Architektur zusammen. Ich denke, dass ich hierdurch in diesem Zusammenhang für die Zukunft sensibilisiert wurde.
Zuletzt war die Zeiteinteilung ein Aspekt, der nicht außer Acht gelassen werden sollte. Ich habe das Projekt alleine durchgeführt und es war dadurch eines der zeitaufwändigsten Projekte, die mich bisher beschäftigten. Umso mehr kann ich behaupten, dass das Projekt einen Lerneffekt auf verschiedensten Ebenen hatte und ich mit dem Ergebnis zufrieden bin.
Leave a Reply
You must be logged in to post a comment.