Abstract
This paper provides a systematic introduction to AI agents, covering core definitions and foundational architectural concepts. It examines tool integration, including operational principles, capabilities, and evaluation of AI coding agents, as well as the Model Context Protocol. The paper further analyzes memory systems as a key component for context persistence and long-horizon task execution. A central focus is placed on established reasoning patterns such as Chain of Thought, Reasoning and Acting, as well as further reasoning patterns and their combinations. Finally, orchestration strategies for single- and multi-agent systems are discussed, including parallel, hierarchical, and group-based patterns, along with control-handoff and coordination mechanisms.
Kurzfassung
Diese Arbeit bietet eine systematische Einführung in KI-Agenten und behandelt dabei zentrale Definitionen und grundlegende Architekturkonzepte. Es untersucht die Tool-Integration, einschließlich der Funktionsprinzipien, Fähigkeiten und Bewertung von KI-Codierungsagenten sowie das Model Context Protocol. Die Arbeit analysiert darüber hinaus Speichersysteme als Schlüsselkomponente für die Kontextpersistenz und die Ausführung von Aufgaben mit langem Zeithorizont. Ein zentraler Schwerpunkt liegt auf etablierten Argumentationsmustern wie „Chain of Thought”, „Reasoning and Acting” sowie weiteren Argumentationsmustern und deren Kombinationen. Abschließend werden Orchestrierungsstrategien für Single- und Multiagenten-Systeme diskutiert, darunter parallele, hierarchische und gruppenbasierte Muster sowie Kontrollübergabe- und Koordinationsmechanismen.
Einleitung
Die rasante Weiterentwicklung von Large Language Models (LLMs) hat in den letzten Jahren den Weg von reinen Chatbots hin zu handlungsfähigen, autonomen KI-Agenten eröffnet, die aktiv in Softwareentwicklungsprozesse eingreifen können. In der Praxis entstehen daraus neue Chancen für Produktivität, Codequalität und Automatisierung, aber ebenso neue Herausforderungen hinsichtlich Zuverlässigkeit, Kosten und Orchestrierung.
Die Arbeit untersucht, wie autonome KI-Agenten auf Basis von LLMs in der Softwareentwicklung gestaltet und eingesetzt werden können. Im Mittelpunkt stehen Architektur- und Orchestrierungsmuster von Single- bis Multi-Agent-Systemen, verschiedene Reasoning-Patterns wie Chain-of-Thought, ReAct oder Tree-of-Thoughts sowie Kurz- und Langzeit-Memory-Systeme.
Ziel der Arbeit ist es, einen strukturierten Überblick über Architektur‑, Orchestrierungs‑, Reasoning‑ und Memory-Konzepte autonomer KI-Agenten in der Softwareentwicklung zu geben und deren Abwägung zwischen Vor- und Nachteilen sowie Fehlermodi herauszuarbeiten.
Grundlagen von Agenten
Dieses Kapitel definiert die fundamentalen Konzepte von Software-Agenten, grenzt sie von statischen Workflows ab und ordnet sie in ein Framework für Autonomiegrade ein.
Definition und Kerneigenschaften eines Agenten
Im Kontext der KI-gestützten Softwareentwicklung ist ein Agent mehr als nur ein Werkzeug zur Code-Generierung, er wird als System verstanden, das seine Umgebung wahrnimmt und aktiv handelt, um Ziele zu erreichen [1], [2]. Während traditionelle Softwarekomponenten passiv auf Eingaben warten, zeichnen sich moderne, auf LLM basierende Agenten durch vier wesentliche Eigenschaften aus [1], [3]:
- Autonomie
Agenten agieren unabhängig und benötigen keine konstante, kleinschrittige Steuerung durch den Menschen. Sie treffen Entscheidungen innerhalb ihres Handlungsspielraums selbstständig [4]. - Reaktivität
Ein Agent muss fähig sein, Veränderungen in seiner Umgebung (z. B. Fehlermeldungen beim Kompilieren, geänderte Anforderungen) zeitnah wahrzunehmen und darauf zu reagieren [2]. - Proaktivität
Über die reine Reaktion hinaus agieren Agenten zielgerichtet. Sie warten nicht nur auf Befehle, sondern planen eigenständig Schritte, um ein übergeordnetes Ziel (z. B. “Refactoring eines Moduls”) zu erreichen [3]. - Soziale Fähigkeit
In komplexen Systemen agieren Agenten oft nicht isoliert. Sie besitzen die Fähigkeit, mit anderen Agenten oder Menschen in einer interpretierbaren Weise zu kommunizieren und zu verhandeln [1].
Abgrenzung von Workflows und Agenten
Ein entscheidender Aspekt für das Verständnis von Agentic AI ist die Unterscheidung zwischen traditionellen Automatisierungs-Workflows (Chains) und echten Agenten-Systemen [5], [6].
Während Workflows auf starren, vordefinierten Pfaden operieren, generieren Agenten ihre Vorgehensweise dynamisch zur Laufzeit [5].
In klassischen Workflows ist der Ausführungspfad vom Entwickler statisch festgelegt (hard-coded) und folgt meist einer deterministischen „Wenn-Dann“-Struktur. Im Gegensatz dazu agiert ein Agent adaptiv: Er generiert seinen Plan basierend auf der aktuellen Aufgabenstellung und dem Kontext selbstständig [1], [5]. Diese Fähigkeit ermöglicht es dem Agenten, Feedback, etwa Fehlermeldungen eines Compilers oder Rückmeldungen eines Code-Reviewers, aktiv zu verarbeiten und seinen Lösungsansatz entsprechend anzupassen [6].
Diese Flexibilität ist besonders relevant für die Fehlerbehandlung und den Einsatz in komplexen Umgebungen. Während unerwartete Fehler in einem starren Workflow oft zum Prozessabbruch führen, verfügen Agenten über Mechanismen zur Selbstüberprüfung. Sie können Fehler autonom erkennen und beheben, bevor eine menschliche Intervention notwendig wird [5], [7]. Damit sind Agenten speziell für Aufgaben in unvorhersehbaren Umgebungen konzipiert, in denen nicht alle Randbedingungen bereits zur Entwicklungszeit bekannt sind [2], [5].
Framework für Autonomiegrade (Levels of Autonomy)
Um die Fähigkeiten von KI-Systemen in der Softwareentwicklung zu klassifizieren, wird oft ein Stufenmodell herangezogen, das an die aus der Automobilindustrie bekannten Autonomie-Level angelehnt ist [8], [9].
Für Software-Agenten lässt sich dieses Spektrum wie folgt unterteilen [8]:
Level 0: Keine Autonomie Der Prozess wird vollständig manuell vom Menschen durchgeführt. Es findet keine Unterstützung durch KI statt [8].
Level 1: Einfache Assistenz Das System bietet Vorschläge (z. B. Code-Vervollständigung) oder Erklärungen an, die exekutive Kontrolle liegt jedoch vollständig beim Menschen [8].
Level 2: Teilautomatisierung Das System kann einzelne Aufgaben unter menschlicher Aufsicht übernehmen, beispielsweise das Bearbeiten mehrerer Dateien, wobei der Mensch den Prozess initiiert und überwacht [8].
Level 3: Bedingte Autonomie Der Agent agiert innerhalb eines definierten Rahmens autonom. Der Mensch greift nur ein, wenn das System an seine Grenzen stößt oder explizit um Hilfe bittet (Human-in-the-loop) [3], [8].
Level 4: Hohe Autonomie Der Agent übernimmt den Großteil der Tasks selbstständig, inklusive Planung und Ausführung. Der Mensch prüft lediglich Ausnahmen oder validiert das Endergebnis [8].
Level 5: Volle Autonomie Das System agiert komplett eigenständig von der Aufgabenstellung bis zur Lösung. Eine menschliche Aufsicht ist für die operative Durchführung nicht mehr erforderlich [8].
Toolintegration
Dieses Kapitel beleuchtet die technische Funktionsweise der Tool-Integration und analysiert die spezifischen Fähigkeiten sowie die Vor- und Nachteile von KI-Coding-Agenten.
Tool-Integration und Funktionsweise
Die Fähigkeit, externe Werkzeuge (Tools) zu nutzen, ist das zentrale Unterscheidungsmerkmal zwischen einem reinen Chatbot und einem handlungsfähigen Agenten [1], [4]. Während ein Standard-LLM auf sein trainiertes Wissen beschränkt ist, ermöglichen Tools den Zugriff auf Echtzeitdaten, das Dateisystem oder APIs [6].
Der technische Ablauf eines Tool-Aufrufs folgt einem zyklischen Prozess, der oft als strukturierte Ausführung beschrieben wird [10]. Dieser Prozess lässt sich in fünf Schritte, wie in [tools] dargestellt, unterteilen:
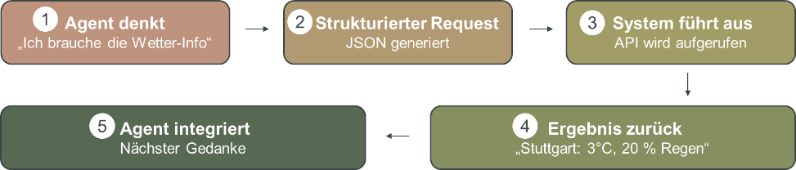
- Reasoning (Der Gedanke): Der Agent analysiert die Benutzeranfrage z. B. „Brauche ich morgen eine Jacke?“ und stellt fest, dass sein internes Wissen nicht ausreicht [2]. Er formuliert den internen Plan: „Ich brauche die Wetter-Informationen, um fortzufahren“.
- Strukturierter Request (JSON-Generierung): Anstatt freien Text zu generieren, erzeugt das Modell einen strukturierten Befehl, meist im JSON-Format, der maschinenlesbar ist [10]. Beispiel: { “tool”: “weather_api”, “city”: “Stuttgart”, “date”: “2025-12-12” }
- System-Ausführung (Execution): Eine deterministische Umgebung (z. B. eine Python-Runtime) erkennt den strukturierten Block, stoppt die Textgenerierung und führt den API-Aufruf tatsächlich aus [4], [6].
- Observation (Ergebnis-Rückgabe): Das externe Tool liefert das Ergebnis zurück an den Agenten [6] Beispiel: “Stuttgart: 3°C, 20 % Regen”
- Integration (Synthese): Der Agent nimmt diese neue Information in seinen Kontext auf und generiert darauf basierend die Antwort oder plant den nächsten Schritt [2].
Fähigkeiten und Bewertung von KI-Coding-Agenten
Spezialisierte Coding-Agenten wenden die generelle Fähigkeit zur Werkzeugnutzung direkt auf den Software-Entwicklungszyklus an [7]. Basierend auf der aktuellen Forschung lassen sich ihre Kompetenzen in drei Bereiche unterteilen, die jeweils spezifische technische Potenziale, aber auch Risiken bergen.
Im Bereich Code Analysis und Understanding nutzen Agenten semantische Suche und Vektordatenbanken, um den Kontext über Dateigrenzen hinweg zu erfassen, was als Repo-level Coding bezeichnet wird [12]. Dies befähigt sie dazu, als Mentoren zu fungieren und das Onboarding von Entwicklern in unbekanntem Quellcode signifikant zu beschleunigen [7], [13]. Allerdings ist die Präzision dieser Assistenz stark von der Qualität der Suche abhängig. Fehlender Kontext kann zu Halluzinationen führen, bei denen der Agent Funktionen erfindet, die im Projekt real nicht existieren [14].
Hinsichtlich der Code-Transformation können Agenten Code modernisieren und technische Rückstände abbauen. Eine empirische Studie zeigt jedoch eine qualitative Diskrepanz: Während Agenten formale Refactorings gut beherrschen, neigen sie bei tiefergehenden Änderungen der Programmlogik dazu, subtile Fehler einzubauen, die schwer zu entdecken sind [14]. Zwar verfügen Agenten über Mechanismen zur Selbstkorrektur, um solche Fehler iterativ zu beheben [12], doch besteht hierbei das Risiko von fehlerhaften Iterationsschleifen, in denen der Agent Fehler propagiert statt sie zu lösen [6], [7].
Im Feld Code-Generation und -Testing erstellen Agenten nicht nur produktiven Code, sondern generieren parallel die passenden Tests zur Validierung [6], [7]. Dies führt nachweislich zu einer subjektiven Entlastung der Entwickler bei Routineaufgaben und steigert die Arbeitszufriedenheit [13]. Der Preis für diese Autonomie ist jedoch eine erhöhte Komplexität in der Wartung der Agenten-Workflows sowie steigende Latenzzeiten und Kosten, die durch die Vielzahl der notwendigen API-Aufrufe verursacht werden [2], [10].
Model-Context-Protocol (MCP)
Mit der zunehmenden Anzahl an spezialisierten Tools und Datenquellen entsteht für Entwickler die Herausforderung, jede Schnittstelle individuell an einen Agenten anzubinden. Um dieses Integrationsproblem zu lösen, wurde das Model Context Protocol (MCP) entwickelt [15].
Das MCP fungiert als ein Open-Source Standard, der eine einheitliche Schnittstelle zwischen KI-Modellen und externen Systemen definiert. Anstatt für jede Datenbank oder API einen eigenen Konnektor zu schreiben, bietet MCP eine universelle Architektur, um KI-Anwendungen sicher mit lokalen oder entfernten Datenquellen zu verbinden [15].
Die Architektur bietet dabei zwei zentrale Kernfunktionen: Zum einen ermöglicht sie Agenten den direkten Zugriff auf externen Kontext, Dokumente und komplexe Arbeitsabläufe, ohne dass das zugrundeliegende Modell neu trainiert werden muss [15]. Zum anderen gewährleistet die standardisierte Schnittstelle, dass Daten und Befehle in einem normierten Format ausgetauscht werden. Dies sichert die Interoperabilität zwischen verschiedenen KI-Clients, wie IDEs oder Chat-Interfaces und Servern, etwa Datenbanken, Slack oder GitHub [15].
Memory-Systeme
Während LLMs von Natur aus zustandslos sind, benötigen autonome Agenten ein Gedächtnis, um aus vergangenen Aktionen zu lernen und konsistente Entscheidungen über längere Zeiträume zu treffen [4], [16]. Die Forschung unterscheidet hierbei primär zwischen Kurzzeit- und Langzeitgedächtnis, analog zur kognitiven Architektur des Menschen [12], [17].
Der folgende Vergleich verdeutlicht die technischen Unterschiede und Einsatzgebiete:
| Short-Term Memory (Kurzzeit) | Long-Term Memory (Langzeit) | |
| Speicherort | LLM Context Window: Die Informationen liegen direkt im Prompt-Puffer des Modells [17], [18]. | Externe Datenbanken: Speicherung in Vektordatenbanken oder SQL-Systemen [16], [17]. |
| Speicherort | Flüchtig: Beschränkt auf die aktuelle Konversationssitzung. Geht nach Abschluss verloren [18]. | Persistent: Dauerhafte Speicherung über Sessions hinweg; Wissen bleibt erhalten [16], [18]. |
| Kapazität | Begrenzt: Limitiert durch die maximale Token-Anzahl des Modells (Context Limit) [19]. | Unbegrenzt: Praktisch skalierbar, da nur relevante Auszüge geladen werden [19]. |
| Geschwindigkeit | Sehr schnell: Sofortiger Zugriff, da Daten bereits im Arbeitsspeicher des Modells liegen [17]. | Latenzbehaftet: Erfordert einen Retrieval-Prozess (Suche + Ranking), bevor Daten genutzt werden können [4]. |
| Inhalt | System-Prompts, der aktuelle Chat-Verlauf, temporäre Variablen und Tool-Definitionen [16]. | Enzyklopädisches Sachwissen, vergangene Erlebnisse (episodisch), prozedurale Fähigkeiten & Workflows [19]. |
Reasoning Patterns
Unter Reasoning Patterns werden strukturierte Denk- und Verarbeitungsmuster verstanden, die ein Agent nutzt, um auf Basis logischer Abhängigkeiten zielgerichtet zu Schlussfolgerungen zu gelangen [2], [20]. Diese Muster können in unterschiedlichen Formen auftreten und variieren, je nach Modellarchitektur und Aufgabenstellung [20].
Chain-of-Thought
Ein prominentes Beispiel ist das Chain-of-Thought-Reasoning (CoT), das erstmals 2022 von Wei et al. beschrieben wurde [21]. CoT modelliert mehrschrittiges logisches Denken, indem ein Problem nicht unmittelbar beantwortet wird, sondern über eine explizite Sequenz intermediärer Schlussfolgerungsschritte. Diese explizite Darstellung von Zwischenschritten erlaubt es dem Modell, komplexe logische Abhängigkeiten innerhalb einer autoregressiven Generierung zu repräsentieren und führt empirisch zu einer verbesserten Lösungsqualität bei anspruchsvollen Aufgaben [21].
Die Generierung der Reasoning-Kette erfolgt dabei sequenziell innerhalb einer einzelnen Modellinferenz, wie in [cot] dargestellt: Das Modell erzeugt tokenweise eine Abfolge von Schlussfolgerungsschritten, wobei jeder Schritt kontextuell auf den zuvor generierten Tokens basiert. Ein explizites, erneutes Anwenden des Modells auf Zwischenergebnisse findet nicht statt; vielmehr entsteht der gesamte Reasoning-Prozess als zusammenhängende Ausgabesequenz [21].
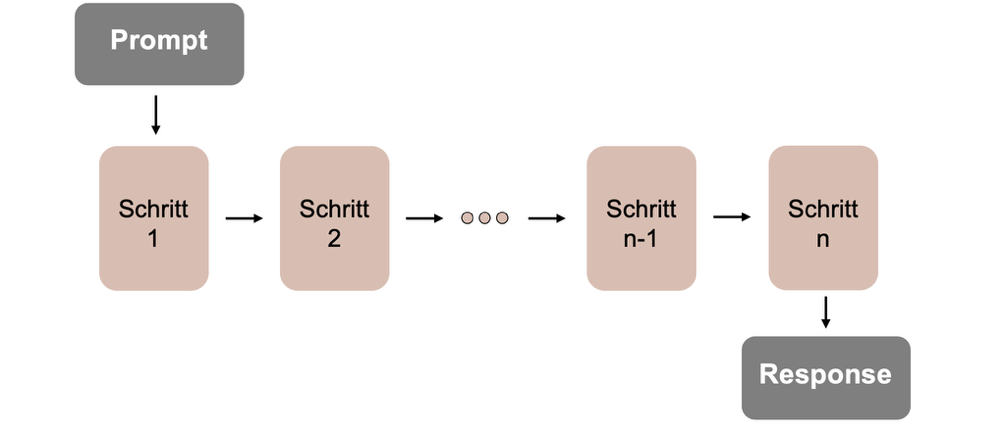
Durch die explizite Zerlegung eines Problems in Zwischenschritte erreicht das Modell unter Verwendung von CoT höhere Erfolgsraten bei Aufgaben, die mehrstufiges logisches Denken erfordern, insbesondere auch bei Out-of-Distribution-Problemen [21], [22]. Zudem erhöht die explizite Darstellung der Reasoning-Schritte die Transparenz der Modellentscheidungen und verbessert die Nachvollziehbarkeit sowie die Debuggability für Nutzer und Entwickler [22], [23].
Gleichzeitig führt die Generierung ausführlicher Reasoning-Ketten jedoch zu einem erhöhten Tokenverbrauch und damit zu längeren Laufzeiten und höheren Rechenkosten [22]. Darüber hinaus können Fehler in frühen Zwischenschritten unentdeckt fortgepflanzt werden, da klassisches CoT keine integrierte Selbstkorrektur innerhalb der Reasoning-Kette vorsieht [22], [23], [24].
Rasoning and Acting
Reasoning and Acting (ReAct) wurde 2023 von Yao et al. beschrieben und stellt eine Erweiterung des CoT -Reasonings dar [25]. ReAct kombiniert dabei explizites Schlussfolgern in Schritten mit gezielten Aktionen, indem ein Agent während der Problembearbeitung iterativ zwischen den Zuständen “Reasoning” und “Acting” wechselt [25].
Ausgehend von einem initialen Prompt entscheidet der Agent zunächst, welcher nächste Schritt zielführend ist, beispielsweise das Lösen eines Teilproblems oder das Beschaffen zusätzlicher Informationen. Anschließend führt er eine Aktion aus, etwa eine Code-Ausführung oder einen Zugriff auf eine externe Quelle. Die Ergebnisse dieser Aktionen werden als “Observations” in den Kontext aufgenommen und dienen als zusätzliche Informationsbasis für nachfolgende Reasoning-Schritte, wie [react] zeigt. Auf dieser erweiterten Grundlage entscheidet der Agent über weitere Aktionen oder setzt die Schlussfolgerung fort. Dieser zyklische Prozess aus Denken, Handeln und Beobachten wird iterativ wiederholt, bis eine Lösung erreicht ist. Abhängig von der Aufgabe können dabei auch mehrere Reasoning-Schritte ohne zwischenliegende Aktionen erfolgen [25].
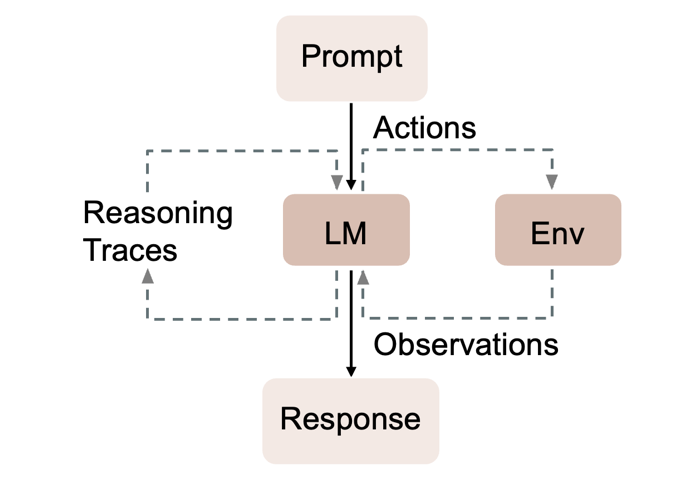
Durch die enge Verzahnung von Reasoning und Interaktion mit der Umgebung bietet ReAct eine hohe Flexibilität und Adaptivität, da der Lösungsweg dynamisch an neu gewonnene Informationen angepasst werden kann. Zudem erhöht die explizite Struktur der einzelnen Schritte die Transparenz des Entscheidungsprozesses [25], [26]. Die Einbindung externer Observations, etwa durch Suchergebnisse, kann die Faktentreue verbessern und die Neigung zu Halluzinationen im Vergleich zu reinem, internem Reasoning reduzieren [26].
Demgegenüber stehen mehrere Nachteile. Die Ausführung zusätzlicher Aktionen und die iterative Erweiterung des Kontexts führen zu einem erhöhten Rechen- und Zeitaufwand sowie zu höheren Kosten [26]. Darüber hinaus besteht ein erhöhtes Fehlerrisiko durch externe Informationsquellen: Fehlerhafte oder veraltete Observations können zu falschen Schlussfolgerungen führen [25]. Ebenso können unvollständige Beobachtungen Halluzinationen begünstigen, oder der Agent kann Tool-Ausgaben fehlerhaft interpretieren, etwa Warnungen als Fehler missverstehen, was den weiteren Lösungsprozess negativ beeinflusst [25].
Reflection
Ein weiteres Reasoning-Pattern ist Reflection. Dabei überprüft ein Agent nach einzelnen Zwischenschritten — etwa nach CoT – oder ReAct-Prozessen — seine bisherigen Ausgaben auf logische Konsistenz, Plausibilität und faktische Korrektheit. Der Agent generiert hierzu explizites Selbstfeedback, identifiziert potenzielle Fehler oder Ungereimtheiten und passt seine Ausgabe entsprechend an [27].
Der Ablauf von Reflection ist in [reflection] abgebildet und lässt sich wie folgt beschreiben: Zunächst erzeugt der Agent einen Reasoning-Schritt und produziert einen Output. Anschließend reflektiert er diesen Output, bewertet ihn kritisch und nimmt bei Bedarf Korrekturen oder Aktualisierungen vor. Die revidierte Version wird anschließend als Grundlage für den nächsten Schritt verwendet. Dieser Prozess wird iterativ fortgeführt, bis eine finale Ausgabe erreicht ist [27], [28].
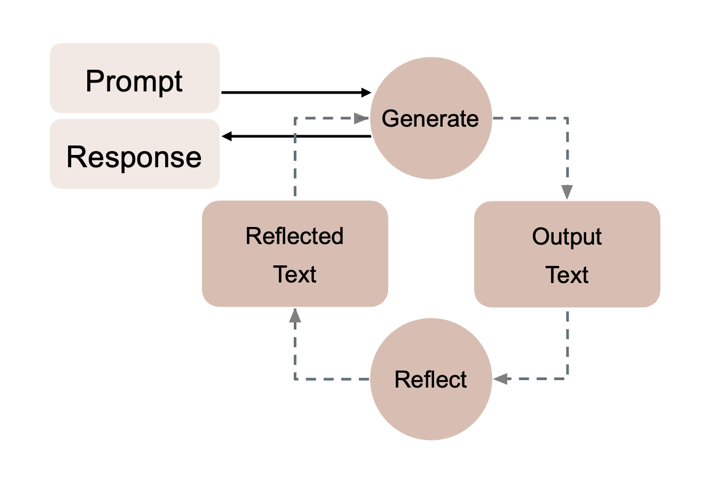
Reflection bietet mehrere Vorteile. Durch die wiederholte Selbstüberprüfung können fehlerhafte Schlussfolgerungen identifiziert und korrigiert werden, wodurch sich die Qualität der finalen Ausgabe erhöhen kann. In geeigneten Implementierungen werden frühere Reflexionen im weiteren Verlauf erneut berücksichtigt, sodass erkannte Schwächen gezielt adressiert werden können. Zudem fördert Reflection ein iteratives Verfeinern der Lösung, anstatt die erste plausible Antwort zu akzeptieren, und unterstützt selbstständiges Debugging durch den Agenten [28].
Gleichzeitig weist dieses Pattern relevante Limitationen auf. In komplexen Aufgaben kann es zu sogenannten Fehlhalluzinationen kommen, bei denen der Agent fälschlicherweise Probleme in einer eigentlich korrekten Lösung vermutet und diese dadurch verschlechtert. Darüber hinaus besteht die Gefahr einer “Analyse-Paralyse”, bei der sich der Agent in wiederholter Selbstkritik ohne substanziellen Fortschritt verliert. Zudem ist die Fähigkeit zur Selbstdiagnose begrenzt, da Modelle Fehler in ihren eigenen Reasoning-Ketten nur unzuverlässig erkennen. Schließlich führt die iterative Selbstüberprüfung zu einem erhöhten Tokenverbrauch und damit zu höheren Laufzeiten und Kosten [27].
Plan-then-Execute
Ein weiteres Reasoning-Pattern ist Plan-then-Execute. Dabei handelt es sich um ein zweistufiges Vorgehen, das explizit die Planungs- von der Ausführungsphase trennt. Zunächst erzeugt der Agent einen strukturierten Plan zur Lösung der Aufgabe. Anschließend wird dieser Plan in einer separaten Phase Schritt für Schritt ausgeführt [29].
Im Unterschied zu zuvor beschriebenen Reasoning-Patterns, bei denen Planung und Ausführung eng miteinander verschränkt oder implizit innerhalb eines fortlaufenden Reasoning-Prozesses erfolgen [22], [25], führt Plan-then-Execute eine klare funktionale Trennung dieser beiden Aspekte ein [29]. Dadurch wird der Lösungsprozess stärker strukturiert und besser kontrollierbar.
Auf diesem Grundprinzip bauen weiterführende Ansätze wie Self-Planning und Tree-of-Thoughts auf. Diese erweitern Plan-then-Execute hinsichtlich der Planerzeugung und der Behandlung von Alternativen.
Self-Planning
Self-Planning ist ein Reasoning-Pattern, bei dem ein Agent selbstständig einen detaillierten Lösungsplan für eine gegebene Aufgabe erzeugt, wie [self_planning] zeigt. Der Nutzer spezifiziert dabei ausschließlich das Ziel, während der Agent die Aufgabe analysiert, in Teilaufgaben zerlegt und daraus einen strukturierten, sequenziellen Ausführungsplan ableitet. Dieser Plan wird anschließend ohne weitere Anpassungen schrittweise ausgeführt [30], [31].
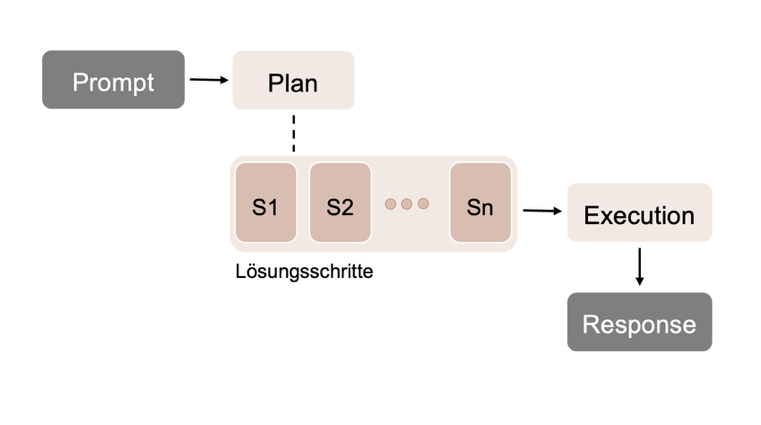
Self-Planning weist spezifische Fehlermodi auf. Ein häufiges Problem ist ein sogenannter Plan Drift, bei dem der Agent einzelne Schritte des ursprünglich erzeugten Plans ignoriert oder abändert. Darüber hinaus kann eine Überspezifikation des Plans die Flexibilität während der Ausführung einschränken, während eine Unterspezifikation dazu führt, dass der Plan zu wenig Orientierung für die Execution bietet [31].
Zu den Vorteilen von Self-Planning zählen die erhöhte Vorhersehbarkeit und Transparenz des Lösungsprozesses, da der Plan vor der Ausführung vollständig vorliegt und von einem Menschen überprüft oder freigegeben werden kann. Die klare Struktur erleichtert zudem das Debugging, da Abweichungen und Fehler eindeutig einzelnen Planungsschritten zugeordnet werden können [30].
Demgegenüber steht ein relevanter Nachteil. Da keine Selbstkorrektur oder adaptive Plananpassung vorgesehen ist, propagieren sich Fehler aus der Planungsphase direkt in die Ausführung [30].
Tree-of-Thoughts
Tree-of-Thoughts (ToT) ist ein weiteres Reasoning-Pattern, das dem Plan-then-Execute-Paradigma zugeordnet werden kann, sich jedoch von klassischen Ansätzen durch die Erweiterung linearer Reasoning-Ketten hin zu einer verzweigten, baumartigen Struktur unterscheidet. Der Ansatz wurde erstmals 2023 von Yao et al. beschrieben [32]. Dabei verfolgt der Agent nicht mehr einen einzelnen linearen Gedankengang, sondern mehrere alternative Denkpfade, die als hierarchischer Baum von Thoughts organisiert sind [32].
Ausgehend von einem Prompt generiert der Agent zunächst mehrere unterschiedliche Ansatzgedanken, welche die Wurzeläste des Baums bilden, vgl. [tot]. Für jeden dieser Gedankengänge wird eine Bewertung vorgenommen, die dessen Erfolgsaussichten für die endgültige Lösung angibt. Vielversprechende Pfade werden weiter ausgeführt, während weniger geeignete verworfen werden. Innerhalb des Baums ist Backtracking möglich, sodass der Agent aus Sackgassen zu früheren Knoten zurückkehren und alternative Pfade weiterverfolgen kann [32], [33], [34].
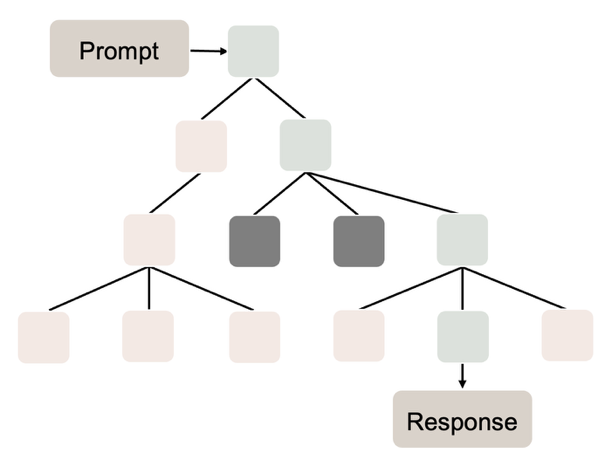
Durch die strukturierte Exploration mehrerer Lösungsansätze erweitert ToT das klassische Plan-then-Execute-Prinzip um eine explizite Suche im Lösungsraum. Der Agent plant hierbei nicht nur eine einzelne Vorgehensweise, sondern untersucht systematisch verschiedene Alternativen, bevor er sich für eine Lösung entscheidet [34].
Jedoch birgt auch ToT Potenzial für Fehler. Ein Problem ist eine vorzeitige Vertiefung einzelner Pfade, bei der der Agent früh detaillierte Optimierungen vornimmt, bevor grundlegende Lösungsansätze ausreichend exploriert wurden [32]. Zudem können unbalancierte oder übermäßig große Bäume entstehen, insbesondere bei einfachen Aufgaben, bei denen der Ansatz zu unnötiger Komplexität und erhöhter Halluzinationsanfälligkeit führt [34].
Zu den Vorteilen von ToT zählt die parallele Exploration alternativer Lösungswege, wodurch Fehlschlüsse in einzelnen Pfaden kompensiert werden können. Zusätzlich bietet der Ansatz eine erhöhte Kontrollmöglichkeit für den Nutzer, da Parameter wie maximale Baumtiefe, -breite oder Abbruchkriterien explizit vorgegeben werden können [32].
Beeinflusst wird die Qualität der Ergebnisse bei der Verwendung von ToT durch die verwendete Bewertungsheuristik: Werden ungeeignete Pfade fälschlich hoch bewertet, investiert der Agent Rechenressourcen in irrelevante Teile des Suchraums. Zudem kann der Baum ohne geeignete Begrenzungen exponentiell wachsen, was zu hohem Tokenverbrauch führt und die Lösungssuche vorzeitig abbrechen kann, bevor ein geeignetes Ergebnis gefunden wird [33], [34].
Kombinationen
Die bislang betrachteten Reasoning-Patterns weisen jeweils spezifische Limitationen und Fehlermodi auf. In der Praxis lassen sich diese jedoch teilweise abmildern, indem verschiedene Patterns gezielt kombiniert werden. Solche Kombinationen nutzen komplementäre Stärken einzelner Ansätze und erhöhen dadurch Robustheit, Flexibilität und Ergebnisqualität von Agentensystemen.
Typische Kombinationen sind unter anderem:
- ReAct + Reflection
Der Agent nutzt ReAct, um durch alternierende Reasoning- und Action-Schritte eine Umgebung zu explorieren. Reflection wird anschließend eingesetzt, um die erzeugten Zwischenergebnisse kritisch zu überprüfen und Fehler zu identifizieren und die Ausgabe iterativ zu verbessern [25], [28]. - Self-Planning + ReAct
In dieser Kombination erzeugt Self-Planning zunächst einen globalen, strukturierten Lösungsplan [31]. ReAct übernimmt anschließend die schrittweise Ausführung einzelner Planbestandteile und ermöglicht dabei lokales Reasoning sowie die Einbindung zusätzlicher Informationen aus externen Quellen [20], [25]. - ToT + Reflection
ToT dient hier zur hierarchischen Zerlegung einer komplexen Aufgabe in mehrere alternative oder parallele Teilaufgaben [32]. Jeder Knoten des Baums wird separat bearbeitet, während Reflection zur Qualitätssicherung auf Ebene einzelner Teilprobleme eingesetzt wird, um inkonsistente oder fehlerhafte Zwischenergebnisse zu korrigieren [34].
Orchestrierung
Unter Orchestrierung wird die Steuerlogik eines Agentensystems oder Frameworks verstanden, die das Zusammenspiel einzelner Agenten oder Module koordiniert. Die Orchestrierung legt fest, welche Komponenten in welcher Reihenfolge aktiviert werden, wie Informationen zwischen ihnen ausgetauscht werden und unter welchen Bedingungen ein Prozess terminiert. Sie bildet damit die zentrale Kontrollinstanz für den Ablauf komplexer Reasoning- und Ausführungsprozesse [35].
Grundsätzlich lassen sich zwei Orchestrierungsformen unterscheiden: Systeme mit einem einzelnen, zentralen Agenten (Single-Agent-Orchestrierung) und Systeme mit mehreren spezialisierten Agenten (Multi-Agent-Orchestrierung) [35].
Single-Agent-Orchestrierung
Bei der Single-Agent-Orchestrierung verarbeitet ein einzelner Agent den gesamten Aufgabenfluss. Der Agent erhält den initialen Input, führt internes Reasoning durch und ruft bei Bedarf externe Tools, etwa Suchfunktionen oder Code-Ausführungen, auf. Die Ergebnisse dieser Tool-Aufrufe werden in den internen Kontext integriert, woraufhin der Agent seine Schlussfolgerungen iterativ aktualisiert, bis ein finales Ergebnis erzeugt wird [35].
Die Besonderheit der Single-Agent-Orchestrierung liegt darin, dass der Agent sämtliche klassischen Rollen innerhalb eines Projekts übernimmt, die typische Abfolge von Prompt zu Output zeigt [single_agent]. Dazu zählen beispielsweise die Planung und Strukturierung der Aufgabe, die Analyse bestehender Codebasen, die Implementierung neuer Funktionalität, das Testen von Code, die Erstellung von Dokumentation sowie die abschließende Überprüfung und Versionierung. Diese Rollen werden sequenziell vom gleichen Agenten ausgeführt [35].
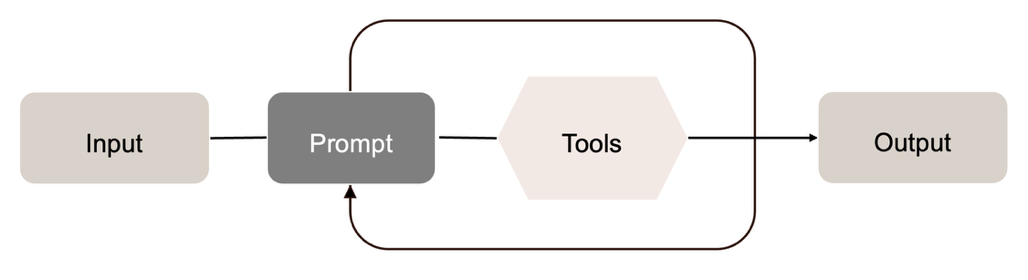
Dieses Vorgehen weist jedoch bei hoher Komplexität Schwächen auf. Ein zentrales Problem ist Rollenverwirrung, bei der der Agent zwischen unterschiedlichen Aufgaben- oder Verantwortlichkeitskontexten wechselt und dabei den ursprünglichen Zielzustand aus den Augen verliert. Darüber hinaus besteht die Gefahr der Kontexterschöpfung: Durch lange Reasoning- und Tool-Interaktionsketten kann das verfügbare Tokenbudget vor Abschluss der Aufgabe aufgebraucht werden, was den Lösungsprozess vorzeitig beendet oder qualitativ verschlechtert [35].
Multiagenten-Orchestrierung
Multi-Agent-Orchestrierung bezeichnet den architektonischen Rahmen, der regelt, wie mehrere spezialisierte KI-Agenten interagieren und zusammenarbeiten, um komplexe Aufgaben zu lösen [36], [37], [38]. Wooldridge definiert Multi-Agent-Systeme als “systems composed of multiple interacting computing elements, known as agents”, die autonom handeln und durch Kooperation, Koordination und Verhandlung interagieren können [39]. Die Orchestrierung umfasst drei fundamentale Mechanismen: Aufgabenzerlegung (Task Decomposition), bei der komplexe Probleme in spezialisierte Arbeitseinheiten unterteilt werden, Routing und Delegation zur Zuweisung geeigneter Agenten, sowie Kontext-Management zur Definition des Informationsflusses zwischen Agenten [36], [37], [40].
Abgrenzung zu Single-Agenten
Single-Agent-Systeme stoßen bei zunehmender Komplexität an ihre Grenzen [23], [37]. Eine zentrale Limitation ist die Kontexterschöpfung: Ein einzelner Agent muss den gesamten Kontext in einem Kontextfenster verwalten, was bei mehrstufigen Aufgaben zu Context Narrowing führt, bei dem relevante Informationen vergessen werden oder Halluzinationen entstehen [41], [42], [43]. Zudem neigt ein Agent, der alle Rollen übernehmen muss, zum “Jack of all trades“-Problem mit generischen Ergebnissen und schwer wartbaren, monolithischen Prompts [38], [44].
Multi-Agent-Systeme adressieren diese Probleme durch Verteilung und Spezialisierung [36], [38]. Jeder Agent verwaltet nur aufgabenrelevanten Kontext, was die Verarbeitung größerer Informationsmengen ermöglicht. Die modulare Spezialisierung reduziert die Prompt-Komplexität stark [36], [43], [45]. Zudem erlauben Multi-Agent-Systeme Parallelisierung, Teilaufgaben können gleichzeitig bearbeitet werden, was die Ausführungszeit um bis zu 33% reduzieren kann [36], [46].
Multi-Agent-Systeme sind besonders bei zerlegbaren Aufgaben überlegen, etwa in der Softwareentwicklung mit spezialisierten Rollen, bei hochparallelen Forschungsaufgaben oder in Szenarien, die Fehlerkorrektur durch Diskurs erfordern [36], [45], [47], [48].
Topologien und Kontrollübergabe-Mechanismen
Multi-Agent-Architekturen werden durch zwei Dimensionen bestimmt: Topologien definieren die strukturelle Anordnung und Kommunikationswege, während Kontrollübergabe-Mechanismen regeln, wie die Ausführungsverantwortung wechselt.
Topologien
Sequential/Chain Pattern
Das Sequential- oder Chain-Pattern ([sequential]) definiert eine Architektur, bei der Agenten in einer vordefinierten, linearen Reihenfolge agieren. Das Kernmerkmal ist die Input-Output-Verkettung: Die Ausgabe eines Agenten dient unmittelbar als Eingabe für den nachfolgenden Agenten in der Sequenz. Der Ablauf ist deterministisch, die Reihenfolge ist fest und wird im gegensatz zu anderen Topologien nicht zur Laufzeit durch ein Orchestrierungsmodell entschieden. Dieses Muster lässt sich mit dem “Pipes and Filters“-Entwurfsmuster oder einer industriellen Montagelinie vergleichen, bei der Aufgaben wie am Fließband weitergereicht werden [36], [37], [44].

Der Ablaufprozess folgt einem strikten, linearen Ablauf, die sich in drei Hauptphasen unterteilt. In der Initialisierungsphase wird die Gesamtaufgabe in diskrete, sequenzielle Schritte zerlegt, wobei der Pfad bereits vor der Ausführung feststeht. Die sequenzielle Ausführung erfolgt durch unidirektionalen Datenfluss: Jeder Agent empfängt die Ausgabe des vorherigen Agenten, führt eine spezialisierte Transformation durch und gibt das Ergebnis weiter. Die Informationsweitergabe erfolgt durch verschiedene Mechanismen: direkte Input-Output-Verkettung, Carryover-Mechanismen, bei denen eine Zusammenfassung des vorangegangenen Dialogs weitergegeben wird, oder durch geteilte Speicher (Shared State/Blackboard), auf die nachfolgende Agenten zugreifen. Der Prozess endet, wenn der letzte Agent seine Aufgabe abgeschlossen hat [36], [37], [44], [49].
Das Pattern eignet sich besonders für Aufgaben mit klaren, linearen Abhängigkeiten, bei denen der Output eines Schrittes zwingend als Input für den nächsten erforderlich ist [36], [37]. Das ChatDev Framework simuliert dazu sequenzielle Phasen wie Design, Codierung, Testen, Dokumentation, ähnlich zum Wasserfall-Modell in der Softwareentwicklung [50].
Das Pattern bietet progressive Verfeinerung durch schrittweise Qualitätssteigerung, wobei iterative Bearbeitung Fehler und Halluzinationen reduziert [36], [50], [51]. Die deterministische Steuerung eliminiert Unsicherheit über die Ausführungsreihenfolge und stellt sicher, dass kritische Schritte nicht übersprungen werden [36], [37]. Da keine zusätzlichen LLM-Aufrufe für Routing-Entscheidungen erforderlich sind, sinken Latenz und Kosten im Vergleich zu dynamischeren Mustern [37]. Die lineare Struktur ermöglicht klare Data Lineage und Traceability, wodurch Fehlerquellen besser lokalisiert werden können [44]. Bei langen Kontexten ermöglicht es die Überwindung von Kontextfenster-Limits durch sequenzielle Chunk-Verarbeitung, wobei nur relevante Erkenntnisse weitergereicht werden [52].
Das kritischste Risiko ist die Fehlerfortpflanzung: Ein Fehler in einer frühen Phase pflanzt sich durch die gesamte Kette fort, da nachfolgende Agenten auf falschen Prämissen weiterarbeiten [36], [37], [53]. Die statische Architektur verhindert dynamische Anpassungen zur Laufzeit und kann Schritte nicht überspringen, selbst wenn diese unnötig sind [36], [37]. Die lineare Ausführung addiert die Latenzen aller Schritte, wobei der langsamste Agent zum Bottleneck wird und keine Parallelverarbeitung möglich ist [40], [43]. Bei langen Ketten tritt außerdem Context Rot auf, wenn das Kontextfenster zu voll ist und frühere Informationen verloren gehen [42], [53]. Zudem führt der Ausfall eines einzelnen Agenten zum Zusammenbruch des gesamten Workflows, da es keine Redundanz oder alternativen Pfade gibt [36], [40].
Parallel Pattern
Das Parallel Pattern ([concurrent]) (auch Concurrent Orchestration oder Fan-out/Fan-in-Muster) ist eine Architektur, bei der mehrere spezialisierte Agenten Aufgaben gleichzeitig und unabhängig voneinander bearbeiten. Das Muster zielt primär darauf ab, Latenzzeiten zu reduzieren und diverse Perspektiven zu integrieren [36], [37], [44].
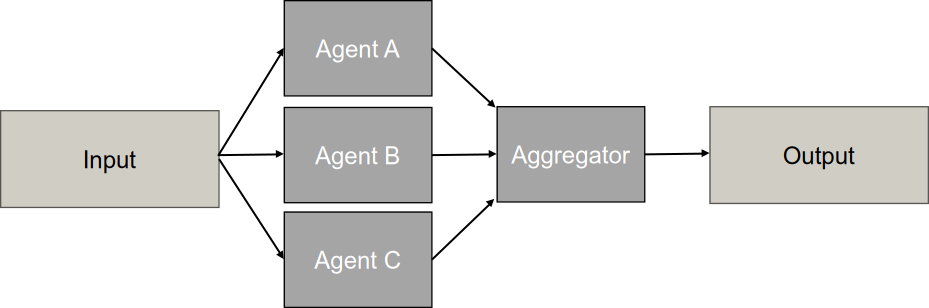
Der Ablaufprozess unterteilt sich in drei Hauptphasen. Die Initialisierung (Fan-out) erfolgt durch einen Orchestrator, der die Anfrage analysiert und entweder eine komplexe Aufgabe in unabhängige Teilaufgaben zerlegt oder die Aufgabe für verschiedene Perspektiven repliziert. Die Befehlsverteilung kann deterministisch nach fest codierter Logik oder dynamisch durch semantisches Routing erfolgen. In der Ausführungsphase arbeiten die Agenten asynchron parallel, wobei jeder Agent seinen Befehl isoliert verarbeitet. Da alle Agenten gleichzeitig arbeiten, entsteht eine hohe momentane Ressourcenauslastung, die jedoch die Gesamtlaufzeit drastisch reduziert. Die Aggregationsphase (Fan-in) sammelt die Ergebnisse über einen Collector oder Synthesizer-Agenten, der typischerweise wartet, bis alle Agenten geantwortet haben oder ein Timeout erreicht ist. Die Synthese erfolgt durch Konsolidierung unterschiedlicher Teilinformationen, Voting-Mechanismen bei identischen Problemstellungen oder Konfliktlösungsstrategien bei widersprüchlichen Ergebnissen [36], [37], [40].
In der Softwareentwicklung wird das Pattern unter anderem für automatisierten Code-Review eingesetzt, bei dem ein Security Auditor, Style Enforcer und Performance Analyst denselben Code simultan prüfen. Moderne Tools wie Cursor 2 oder Claude Code nutzen Hintergrundagenten zur parallelen Feature-Entwicklung, etwa gleichzeitige UI-Verfeinerung und Backend-Optimierung [36].
Das Pattern reduziert Latenz stark, da die Gesamtdauer nur durch den langsamsten Agenten bestimmt wird und nicht durch die Summe aller Arbeitsschritte. Experimente zeigten Zeitreduzierungen um 70-75% bei komplexen Diagnoseaufgaben. Durch Ensemble Reasoning entstehen vielseitige Perspektiven, wobei spezialisierte Agenten umfassendere Problemraumabdeckung erreichen als Generalisten [36], [40], [54], [55]. Voting-Mechanismen filtern Halluzinationen einzelner Modelle heraus, da multiple Agenten selten denselben Fehler halluzinieren [45]. Die Kontext-Isolierung ermöglicht jedem Agenten ein frisches Kontextfenster, was Context Pollution verhindert [56]. Zudem bietet die lose Kopplung Robustheit durch Graceful Degradation, wobei der Ausfall eines Agenten nicht zwingend zum Systemausfall führt [36], [40], [43], [57].
Das Pattern verursacht hohe Ressourcenintensität durch massiven Token-Verbrauch, da mehrere Agenten gleichzeitig mit vollständigen Kontexten arbeiten [37], [48]. Studien quantifizieren redundante Token-Verarbeitung von 53-86% [58]. Burst Loads bei paralleler Ausführung führen zu Lastspitzen, die schnell zu API-Rate-Limits führen können [58]. Die Aggregationskomplexität erfordert aufwendige Konfliktlösungsstrategien bei widersprüchlichen Agentenantworten [36], [37], [40]. Race Conditions treten auf, wenn mehrere Agenten gleichzeitig auf geteilten Speicher zugreifen, was zu Datenkorruption führen kann [36], [44], [53], [55]. Das Straggler-Problem limitiert die Geschwindigkeit auf den langsamsten Agenten, wobei Timeouts oder endlose Schleifen den gesamten Aggregationsprozess blockieren können [40], [55]. Zudem ist das Pattern ungeeignet für abhängige Aufgaben, bei denen Schritt B zwingend auf dem Ergebnis von Schritt A aufbauen muss [36].
Hierarchical Pattern
Das Hierarchical oder Supervisor Pattern ([hierarchical]) definiert eine geschichtete Struktur von Agenten zur Bewältigung komplexer Aufgaben. Die Architektur organisiert Agenten in einer Baumstruktur mit 2 oder mehr Ebenen: Ein Top-Level-Agent (Root/Manager) verwaltet das übergeordnete Ziel und zerlegt komplexe Aufgaben in kleinere Teilaufgaben, Mid-Level-Agenten fungieren als spezialisierte Teamleiter oder Koordinatoren für bestimmte Domänen und Worker-Agenten auf der untersten Ebene führen die konkreten Aufgaben aus [37], [38], [59], [60]. Der Informationsfluss erfolgt bidirektional: Top-Down fließen Entscheidungen und Aufgabenanweisungen kaskadenartig durch die Hierarchie, während Bottom-Up Informationen und Ergebnisse aggregiert werden, wobei jede Ebene die Komplexität für die darüberliegende Ebene abstrahiert [59]. Ein wesentlicher Aspekt ist die temporale Hierarchie, bei der höhere Ebenen strategische Entscheidungen mit langem Zeithorizont treffen, während niedrigere Ebenen kurzfristige, reaktive Entscheidungen ausführen [59].
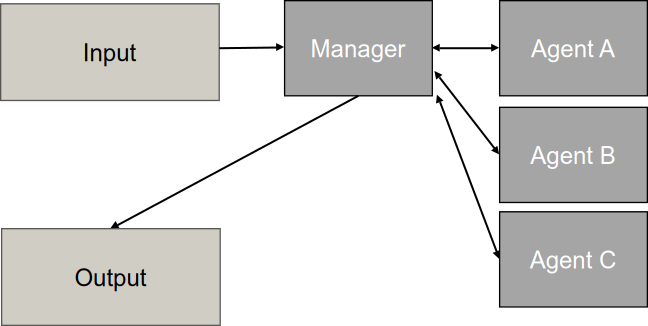
Der Ablaufprozess basiert auf dem Divide-and-Conquer-Prinzip durch rekursive Aufgabenzerlegung. Der Top-Level-Agent analysiert die Anforderung und zerlegt sie in kleinere, handhabbare Teilaufgaben, die an Mid-Level-Agenten weitergegeben werden. Diese zerlegen sie bei Bedarf weiter, bis die Aufgaben einfach genug für spezialisierte Worker-Agenten sind [37], [57]. Die Delegation erfolgt hierarchisch und rollenbasiert durch Kaskadierung, wobei Mid-Level-Agenten als Orchestratoren für ihren Teilbaum fungieren [57], [61]. Der Supervisor überwacht den Fortschritt, validiert Ausgaben und stellt sicher, dass Aufgaben in der richtigen Reihenfolge ausgeführt werden [38], [54], [57]. Zur Kontextverwaltung arbeiten Sub-Agenten oft mit eigenem, vom Haupt-Thread getrenntem Kontextfenster, was die Gefahr der Context Pollution verringert [56], [62].
In der Softwareentwicklung simulieren Frameworks wie MetaGPT oder ChatDev virtuelle Software-Firmen, bei denen ein CEO/Projektmanager an spezialisierte Rollen wie Architekten, Ingenieure und QA-Ingenieure delegiert [50], [63], [64]. Bei umfangreichen Code-Migrationen erstellt ein Hauptagent eine To-Do-Liste und spawnt Sub-Agenten, die Datei-Batches parallel bearbeiten [56], [62].
Das Pattern bewältigt Komplexität durch Abstraktion, wobei höhere Ebenen Entscheidungen auf Basis verdichteter Daten treffen und Information Hiding die kognitive Belastung reduziert [43], [59]. Die Skalierbarkeit wird durch Aufteilung der Kontrollspanne erreicht: Zwischenebenen verhindern, dass ein einzelner Manager zum Flaschenhals wird, wodurch das System auf Hunderte von Agenten skalieren kann [38], [59]. Die temporale Hierarchie ermöglicht Trennung von Entscheidungen nach Zeithorizonten, wobei höhere Ebenen strategisch planen, während untere Ebenen reaktiv agieren [59]. Modularität und Spezialisierung erlauben saubere Trennung von Verantwortlichkeiten, wobei ganze Zweige als spezialisierte Teams fungieren [43], [57]. Die strukturierte Koordination mit klaren Autoritätsbeziehungen vermeidet Entscheidungsparalysen und reduziert Kommunikationsrauschen durch Beschränkung auf vertikale Pfade [59].
Manager-Agenten werden bei zu vielen untergeordneten Agenten zum Bottleneck und stellen einen Single Point of Failure dar, wobei ihr Ausfall den gesamten Workflow oder entsprechende Zweige funktionsunfähig macht [43]. Die Multi-Hop-Latenz erhöht Antwortzeiten durch notwendige Weiterleitung über mehrere Ebenen [36], [37], [43]. Der Koordinationsaufwand verursacht hohen Token-Verbrauch durch Zwischenschritte und Statusberichte, wobei Multi-Agenten-Systeme bis zu 15-mal mehr Token als Einzelagenten verbrauchen können [48]. Bei einfachen Aufgaben übersteigen die Koordinationskosten den Nutzen [36], [65]. Informationsverlust tritt auf, wenn untergeordnete Agenten ihre Ergebnisse zusammenfassen und kritische Details verloren gehen [53], [65]. Planungsfehler des Root-Agenten kaskadieren durch das gesamte System, da alle nachgelagerten Agenten an falschen Teilaufgaben arbeiten [36], [40], [53]. Studien zeigen, dass Produktionssysteme Fehlerraten zwischen 41% und 86,7% aufweisen können, wobei ein Großteil auf Spezifikations- und Koordinationsprobleme zurückzuführen ist [63], [66].
Groupchat Pattern
Das Groupchat Pattern ([groupchat]) ist ein Orchestrierungsmuster, bei dem mehrere spezialisierte Agenten gemeinsam in einem geteilten Konversationsstrang interagieren, um komplexe Probleme zu lösen, Entscheidungen zu treffen oder Arbeitsergebnisse zu validieren. Das zentrale Merkmal ist ein geteilter Kommunikationskanal (Thread), in dem alle teilnehmenden Agenten sowie optional menschliche Teilnehmer den vollständigen Gesprächsverlauf einsehen können. Die Koordination erfolgt durch einen Group Chat Manager, der basierend auf dem aktuellen Kontext und der Historie entscheidet, welcher Agent als Nächstes sprechen darf. Dieser Manager kann regelbasiert oder als eigener Agent implementiert werden. Das Muster unterstützt verschiedene Interaktionsmodi: kollaboratives Brainstorming, wobei Agenten mit unterschiedlichen Perspektiven auf Beiträgen anderer aufbauen, strukturierte Debatten zur Konsensfindung sowie Maker-Checker-Loops als iterative Zyklen zwischen Ersteller und Prüfer [36], [67].
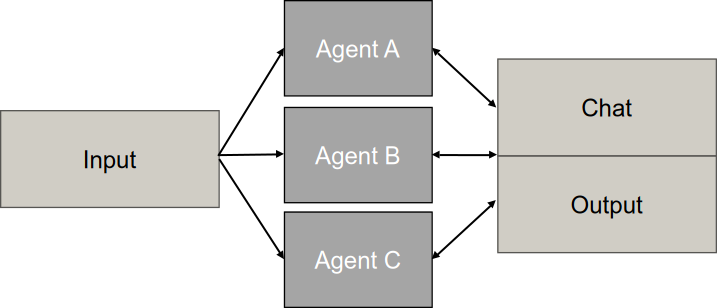
Der zyklische Ablaufprozess beginnt mit der Initialisierung, bei der eine Benutzeranfrage an den Group Chat Manager gesendet wird und spezialisierte Agenten in einem gemeinsamen Chat-Raum instanziiert werden. In der Sprecherauswahl analysiert der Manager den akkumulierenden Chat-Verlauf und entscheidet basierend auf einer Routing-Strategie, welcher Agent als Nächstes sprechen darf [36], [68]. Die Auswahlstrategien variieren zwischen AutoPattern für dynamische, kontextbasierte Entscheidungen, Round Robin für zyklische Reihenfolge und regelbasierten Handoffs für explizite Übergaben [68], [69]. In der Ausführungsphase liest der ausgewählte Agent den Chatverlauf, führt seine spezifische Aufgabe aus und sendet das Ergebnis zurück in den gemeinsamen Thread [36], [67]. Der Prozess tritt in eine Iterationsschleife ein, wobei der Manager den neuen Zustand bewertet und zur Sprecherauswahl zurückkehrt. Die Terminierung erfolgt durch Zielerreichung, explizite TERMINATE-Nachrichten oder maximale Rundenbegrenzungen zur Vermeidung von Endlosschleifen [36], [55], [68].
Die dynamische, LLM-basierte Auswahl (AutoPattern) bietet hohe Flexibilität und Kontext-Sensitivität, verursacht jedoch hohe Kosten und Latenz sowie das Risiko von Endlosschleifen [36], [68]. Round Robin garantiert Fairness und einfache Implementierung bei niedrigem Overhead, führt jedoch zu Ineffizienz durch unnötige Beiträge und mangelnder Anpassungsfähigkeit [68], [69], [70]. Random Selection fördert Diversität in Brainstorming-Szenarien, erzeugt aber Chaos und Unvorhersehbarkeit [68], [69], [70]. Manuelle Regeln und Handoffs bieten Kontrolle und Sicherheit für kritische Prozesse, leiden aber unter Starrheit und hohem Wartungsaufwand [47].
In der Softwareentwicklung simuliert ChatDev virtuelle Entwicklungsteams mit Rollen wie Coder, Reviewer und Tester, die iterativ zusammenarbeiten, bis Code fehlerfrei läuft [50].
Das Pattern steigert Lösungsqualität durch Diversity of Thought, wobei strukturierte Debatten Halluzinationen reduzieren und Cross-Reflection Fehlerkorrektur ermöglicht [45], [71]. Dynamische Sprecherauswahl erlaubt flexible Anpassung an unerwartete Probleme zur Laufzeit. Der geteilte Kontext verhindert Informationsverlust und bietet vollständige Auditierbarkeit aller Interaktionen [59], [68]. Maker-Checker-Loops ermöglichen iterative Qualitätssteigerung durch stetige Verbesserung [36]. Die modulare Erweiterbarkeit erlaubt Hinzufügen neuer Fähigkeiten durch spezialisierte Agenten, ohne bestehende zu ändern, wobei Menschen nahtlos als weitere Teilnehmer integriert werden können [36], [38], [68]. Studien zeigen, dass spezialisierte Rollenaufteilungen bei steigender Aufgabenschwierigkeit deutlich bessere Ergebnisse liefern als andere Methoden [45], [72].
Der massive Ressourcenverbrauch führt zu bis zu 15-fach höherem Token-Verbrauch als Einzelagenten [48] mit Duplikationsraten von 53-86% [58], wobei der Koordinations-Overhead zu Leistungsverschlechterungen von 39-70% führen kann [65]. Die Diskussions-Latenz macht das Pattern für Echtzeitanwendungen ungeeignet [36], [54]. Infinite Loops können durch gegenseitiges Danken oder wiederholte Fragen ohne Abbruchbedingungen entstehen [36], [53], [63]. Die Skalierbarkeit ist begrenzt, es wird empfohlen, Gruppen auf drei oder weniger Agenten zu beschränken [71]. Context Window Overflow und Lost-in-the-Middle-Phänomene treten bei langen Threads auf [42], [52]. Theory of Mind Collapse führt dazu, dass Agenten Informationen zurückhalten oder falsche Annahmen über das Wissen anderer treffen [63]. Bei einfachen Aufgaben führt Overthinking zu schlechteren Ergebnissen als Einzelagenten [65], [72]. Wird ein zentraler Manager eingesetzt stellt dieser einen Single Point of Failure dar [36], [43].
Hybrid-Architekturen
Hybrid-Architekturen können genutzt werden, wenn einzelne Topologien an ihre Grenzen stoßen. Sie kompinieren unterschiedliche Topologien, um spezifische Probleme zu lösen, in dem die stärken der Topologien kompiniert werden [36], [43], [60].
Die Kombination aus Manager und Sequential Workers implementiert Chained Task Sequencing. Ein Orchestrator delegiert eine Sequenz von Befehlen und ist zwischen den Schritten für Kontrolle und Validierung zuständig ist [40]. Das Framework AgentGroupChat-V2 zerlegt Benutzeranfragen in hierarchische Aufgabenbäume, wobei Aufgaben ohne Abhängigkeiten an verschiedene Group Manager verteilt und diese dann parallel ausgeführt werden [72].
Sequential mit Groupchat-Phasen wird in ChatDev implementiert, das sequentielle Phasen (Design → Coding → Testing) nutzt, wobei innerhalb jeder Phase Instruktor-Assistent-Paarungen oder Gruppendiskussionen zur Konsensfindung stattfinden [50]. Das Framework MetaGPT nutzt Standard Operating Procedures zur sequentiellen Strukturierung und weist diese einem Team aus spezialisierten Rollen zu, die Ergebnisse validieren und weitergeben [45], [47].
Es empfiehlt sich, verschiedene Phasen eines Workflows mit unterschiedlichen Topologien umzusetzen: sequentielle Orchestrierung für Datenaufbereitung mit Abhängigkeiten, parallele Muster für unabhängige Analysen und hierarchische Strukturen für komplexe Dekomposition [36], [37]. Zur Entwicklung solcher Architekturen bietet sich ein iteratives Vorgehen an: Zuerst startet man mit einfachen konfigurationsbasierten Mustern wie Supervisor und erst bei Bedarf geht man zu komplexen Orchestrierungen über [54]. Ein einzelner Agent ist oft effektiver und kostengünstiger als komplexe Systeme, wenn die Aufgabe keine parallele Verarbeitung oder spezialisierte Rollen erfordert [36], [58]. Das Framework ARG-Designer implementiert dynamische Generierung solcher Architekturen, statt statischer Templates und vermeidet so redundante Agenten durch autoregressive Generierung der Kollaborations-Topologie für jede Anfrage [73]. Damit nicht jeder Ausfall eines einzelnen Agenten zum Systemabsturz führt, sollten Failure Isolation techniken, wie Circuit Breakers oder Graceful Degradation, implementiert werden [36], [40].
Kontrollübergabe-Mechanismen
Während die Topologien von Multi-Agenten-Systemen den strukturellen Rahmen der Agenten-Interaktion definieren, bestimmen Kontrollübergabe-Mechanismen die operativen Regeln, nach denen Entscheidungsbefugnisse, Aufgaben und Ressourcen zwischen den Agenten koordiniert und transferiert werden [74]. Die Effektivität eines Multi-Agenten-Systems hängt maßgeblich davon ab, wie präzise diese Mechanismen auf die Charakteristika der zu lösenden Aufgabe abgestimmt sind [43], [57]. Kontrollübergabe-Mechanismen bilden das Bindeglied zwischen der abstrakten Systemarchitektur und der konkreten Ausführung von Aufgaben, indem sie festlegen, welcher Agent zu welchem Zeitpunkt die Kontrolle ausübt und wie die Übergabe an nachfolgende Agenten erfolgt. Die Wahl des geeigneten Mechanismus beeinflusst fundamentale Systemeigenschaften wie Latenz, Skalierbarkeit, Ressourcenallokation und die Robustheit gegenüber Ausfällen [45], [54].
Im Folgenden werden vier zentrale Kontrollübergabe-Mechanismen systematisch analysiert:
Subagent-Mechanismus
Der Subagent-Mechanismus stellt ein Architekturmuster dar, bei dem ein übergeordneter Agent Teilaufgaben an spezialisierte Subagenten delegiert, die unabhängig parallel operieren und ihre Ergebnisse an den übergeordneten Agenten zurückmelden [56], [62], [75].
Der Subagent-Mechanismus eignet sich besonders für die hierarchische Topologie, wobei Entscheidungen von oben nach unten kaskadieren, während Informationen und Ergebnisse von unten nach oben fließen [43]. Ein zentrales Merkmal ist die Kapselung und Kontext-Isolation: Subagenten operieren in einem eigenen, isolierten Kontextfenster oder einer separaten Sitzung und erben nicht zwingend den gesamten Konversationsverlauf des Hauptagenten, sondern erhalten ausschließlich die für ihre spezifische Aufgabe relevanten Informationen [43], [56], [62], [76]. Der Hauptagent übernimmt die Rolle eines Synthesizers und wartet typischerweise auf die Fertigstellung der Aufgaben durch die Subagenten, um die Teilergebnisse zu einer Gesamtlösung zu aggregieren [40], [43], [75]. Die funktionale Spezialisierung der Subagenten ermöglicht es, dass diese als Experten für eng umgrenzte Domänen agieren und über spezifische Werkzeuge verfügen, die dem Hauptagenten nicht direkt zur Verfügung stehen müssen [38], [40], [56].
Die Vorteile des Subagent-Mechanismus liegen primär in seiner Skalierbarkeit, da er die Bewältigung komplexer Probleme ermöglicht, welche die Kapazität eines einzelnen Agenten hinsichtlich Kontextfenster oder Reasoning-Fähigkeit übersteigen würden [37], [48], [62]. Die Kontext-Effizienz wird durch die Auslagerung von Aufgaben in separate Subagenten gewährleistet, wodurch das Kontextfenster des Hauptagenten nicht mit Details der Zwischenschritte überfrachtet wird [48], [56]. Zudem ermöglicht die Parallelisierung unabhängiger Teilaufgaben durch verschiedene Subagenten eine Erhöhung des Durchsatzes [44], [75].
Als Nachteile sind die erhöhte Latenz durch mehrschichtige Kommunikation und Koordination zu nennen, insbesondere wenn der Hauptagent sequenziell auf Ergebnisse warten muss [36], [40], [43], [48], [53], [57]. Der Einsatz mehrerer Agenten vervielfacht den Token-Verbrauch im Vergleich zu monolithischen Ansätzen, was die Kosten erhöht. Darüber hinaus kann der zentrale Orchestrator oder Hauptagent als Single Point of Failure zum Flaschenhals werden, dessen Ausfall den gesamten Prozess gefährdet [37], [43], [48], [58].
Handoff-Mechanismus
Der Handoff-Mechanismus bezeichnet die explizite, dynamische Übergabe der Kontrolle von einem aktiven Agenten zu einem anderen. Diese Übergabe wird häufig durch Werkzeugaufrufe realisiert, die eine Zustandsvariable ändern, wodurch der Gesprächsfluss an einen spezialisierten Agenten weitergeleitet wird [36], [77].
Beim Handoff-Mechanismus verändert sich das Verhalten dynamisch basierend auf dem aktuellen Zustand des Systems [77]. Die Agenten agieren als Knoten in einem Graphen, wobei Kanten die möglichen Übergänge repräsentieren, ähnlich wie bei einem Automaten [43], [77], [78]. Die explizite Routing-Entscheidung wird nicht von einem Router getroffen, sondern vom Agenten selbst, der aktiv entscheidet, dass er nicht mehr zuständig ist oder seine Kapazitätsgrenze erreicht hat und den Transfer initiiert [36]. Ein fundamentales Merkmal ist die sequenzielle Exklusivität: Zu einem Zeitpunkt ist in der Regel immer nur ein Agent aktiv und interagiert direkt mit dem Nutzer, bis ein Handoff erfolgt [36], [77]. Handoffs können an Validierungsbedingungen geknüpft sein, beispielsweise muss eine bestimmte Information vorliegen, bevor an einen spezialisierten Agenten übergeben wird [77].
Die Vorteile des Handoff-Mechanismus liegen in der Gewährleistung von Spezialisierung, da Aufgaben stets vom qualifiziertesten Experten bearbeitet werden, ohne dass ein monolithischer Agent alle Fähigkeiten besitzen muss [36]. Klare Verantwortlichkeiten verhindern Rollenkonfusion, da Agenten explizite Grenzen haben und Aufgaben abgeben müssen, die außerhalb ihrer Kompetenz liegen [36], [53]. Zudem ermöglicht der Mechanismus eine präzise Prozesssteuerung durch die Durchsetzung strenger sequenzieller Abläufe in Geschäftsprozessen [36], [77].
Als Nachteil ist das Risiko von Endlosschleifen zu nennen, bei denen Agenten Aufgaben immer wieder hin- und herreichen, wenn Zuständigkeiten nicht eindeutig sind oder Fehler auftreten [36]. Bei der Übergabe kann kritischer Kontext verloren gehen, wenn dieser nicht explizit und strukturiert an den nachfolgenden Agenten übermittelt wird [42], [53], [77]. Falsche Klassifizierungen der Nutzerabsicht können zu suboptimalem Routing und frustrierenden Nutzererfahrungen durch unnötige Handoffs führen [36].
Round Robin-Mechanismus
Round Robin ist ein deterministischer Algorithmus zur Ressourcenzuweisung oder Gesprächssteuerung, bei dem Agenten in einer festen, zyklischen Reihenfolge aktiviert werden oder Zugriff auf einen Kommunikationskanal erhalten [69].
Die Reihenfolge der Interaktion ist starr und vorhersagbar und basiert nicht auf dem Inhalt der Aufgabe oder der aktuellen Dringlichkeit. Dieser Mechanismus garantiert, dass jeder Agent die Möglichkeit erhält, beizutragen oder Ressourcen zu nutzen, wodurch das Verhungern einzelner Agenten verhindert wird. Konfliktvermeidung wird dadurch erreicht, dass zu jedem Zeitpunkt klar definiert ist, welcher Agent senden oder agieren darf, wodurch Datenkollisionen in geteilten Medien vermieden werden. Ein weiteres Merkmal ist die Dezentralisierung, da kein komplexer zentraler Entscheidungsträger notwendig ist, der die Fähigkeiten der Agenten bewertet; die Logik folgt einem simplen Rotationsprinzip [69].
Die Vorteile des Round Robin-Mechanismus liegen in seiner Einfachheit, da er leicht zu implementieren ist und einen geringen algorithmischen Overhead aufweist. Die ausgewogene Beteiligung stellt sicher, dass alle Perspektiven in einer Diskussion gehört werden, ohne dass dominante Agenten den Diskurs übernehmen. Er ist robust gegen komplexe Entscheidungsfehler, da keine intelligente Routing-Logik erforderlich ist [69].
Als Nachteil ist die Ineffizienz zu nennen, da Agenten auch dann aufgerufen werden, wenn sie keinen relevanten Beitrag leisten können, was zu unnötigem Kommunikationsaufwand und Zeitverlust führt. Die mangelnde Priorisierung führt dazu, dass dringende Aufgaben oder Agenten mit kritischem Wissen warten müssen, bis sie an der Reihe sind, was die Latenz erhöht. Skalierbarkeitsprobleme entstehen dadurch, dass die Wartezeit für jeden einzelnen Agenten linear mit der Anzahl der Teilnehmer im System wächst [69].
Eignung der Mechanismen in verschiedenen Topologien
Der Subagent-Mechanismus passt sowohl zur hierarchischen Topologie, da er auf Top-Down-Zerlegung und Bottom-Up-Aggregation basiert und damit eine explizite Hierarchie erfordert. Die zentrale Koordination durch einen Hauptagenten entspricht der zentralisierten Architektur mit einem steuernden Orchestrator. Als auch zu parallelen Topologien, da hier unabhängige Teilaufgaben paralell bearbeitet werden.
Der Handoff-Mechanismus wird in sequenziellen oder Chain-basierten Topologien eingesetzt, da die explizite Kontrollübergabe zwischen Agenten eine lineare Prozesskette voraussetzt. Die zustandsbasierte Weiterleitung eignet sich für Szenarien, in denen spezialisierte Agenten nacheinander aktiviert werden müssen, um verschiedene Phasen eines Prozesses zu durchlaufen. In Groupchat-Topologien kann der Handoff-Mechanismus zur dynamischen Speaker-Selection eingesetzt werden, wobei die Kontrolle gezielt an den nächsten relevanten Agenten übergeben wird.
Der Round Robin-Mechanismus ist für Groupchat-Topologien geeignet, in denen eine faire und ausgewogene Beteiligung aller Agenten gewährleistet werden soll. Die zyklische Aktivierung verhindert, dass einzelne Agenten die Diskussion dominieren und bezieht alle Perspektiven systematisch ein. Für zeitkritische Anforderungen oder Topologien mit Priorisierung eignet sich der Mechanismus weniger, da die feste Reihenfolge keine dynamische Anpassung an den Systemzustand erlaubt, um unpassende Agenten zu überspringen.
Die Eignung eines Kontrollübergabe-Mechanismus darf nicht isoliert betrachtet werden, sondern muss immer im Kontext der Aufgabenstruktur und der gewählten Topologie evaluiert werden. Die sequenzielle Unabhängigkeit einer Aufgabe und der erforderliche Kommunikationsoverhead sind entscheidende Faktoren, die über die Wahl des optimalen Mechanismus entscheiden.
Fazit und Ausblick
Übergreifende Erkenntnisse
Die Analyse der Architektur-Patterns, Reasoning-Patterns und Memory-Systeme von KI-Agenten zeigt drei übergreifende Erkenntnisse, die über einzelne technische Komponenten hinausgehen.
Erstens wird deutlich, dass die Wahl des Orchestrierungsmodells die Kernentscheidung für die Gesamtarchitektur darstellt. Single-Agent-Systeme bieten Einfachheit, stoßen jedoch bei wachsender Komplexität auf Kontexterschöpfung und Rollenverwirrung. Multi-Agent- und hierarchische Systeme adressieren diese Limitationen durch Spezialisierung und Parallelisierung, führen jedoch neue Herausforderungen in der Koordination und Fehlervermeidung ein. Die Wahl determiniert nicht nur die unmittelbare Implementierungskomplexität, sondern auch operative Anforderungen für produktive Systeme.
Zweitens zeigt sich ein fundamentaler Trade-off zwischen Spezialisierung und Generalisierung bei der Agent-Konzeption: Spezialisierte Agenten erreichen höhere Präzision für definierte Aufgabenklassen, sind jedoch weniger flexibel und nur eingeschränkt auf andere Domänen übertragbar, während generalistische Agenten zwar breiter einsetzbar, aber anfälliger für Fehler und suboptimale Leistung sind [79], [80]. Eine systematische Designmethodologie für diese Balance fehlt bislang in der Literatur.
Drittens wird sichtbar, dass Transparenz und durchgängige Observability eine Infrastruktur-Anforderung für produktionsreife Agentensysteme darstellen [81], [82]. Da Agenten durch nichtdeterministische Reasoning-Prozesse agieren, sind traditionelle Monitoring-Ansätze (Logs, Metriken) unzureichend [81], [83], [84]. Die Nachvollziehbarkeit von Reasoning-Schritten, Tool-Aufrufen und Fehlerfortpflanzung wird zum kritischen Erfolgsfaktor für Debugging, Vertrauensaufbau und kontinuierliche Verbesserung [81], [82], [83].
Offene Forschungsfragen
Trotz der umfassenden Betrachtung der Agent-Architekturen existieren mehrere Forschungslücken, die für praktische Einsätze in der Softwareentwicklung relevant sind.
Verification und Formal Methods für Agent Reasoning
Ein zentrales Problem liegt in der Verifizierbarkeit von agentgenerierten Reasoning-Schritten. Reasoning-Patterns wie Chain-of-Thought oder Tree-of-Thoughts verbessern zwar die Lösungsqualität, machen aber die Anzahl und Komplexität der Zwischenschritte größer, ohne dass diese formal überprüfbar wären [85], [86]. Weder das Modell selbst noch externe Monitoring-Werkzeuge können zuverlässig feststellen, ob eine Reasoning-Kette logisch konsistent und faktisch korrekt ist [87]. Erste Ansätze kombinieren LLMs mit formalen Verifikatoren, etwa Theorem-Provern oder SMT-Solvern, sowie interaktiven Beweissystemen wie Lean4, um natürlichsprachliche Erklärungen oder Code formal zu prüfen [86], [88], [89]. Diese Arbeiten fokussieren jedoch auf eng abgegrenzte Domänen. Für die Code-Generierung durch Agenten – einen Kernanwendungsfall dieser Arbeit – fehlen standardisierte Frameworks zur formalen Verifikation der Agentenausgaben [90]. Eine Forschungsaufgabe liegt in der Entwicklung von Verification-Frameworks, die sowohl die Reasoning-Kette als auch den generierten Code automatisiert auf Korrektheit überprüfen und in bestehende Softwareentwicklungsprozesse integrierbar sind.
Error Propagation in Multi-Agent-Orchestrierungen
Ein wiederkehrendes Problem bei Multi-Agent-Systemen ist die Fehlerfortpflanzung über mehrere Orchestrierungsphasen hinweg [81], [83]. Besonders bei Sequential-Pattern-Orchestrierungen führt ein Fehler in einer frühen Phase, etwa ein suboptimaler Plan bei Self-Planning, dazu, dass nachfolgende Agenten auf fehlerhaften Prämissen aufbauen und Fehler verstärken, statt sie zu korrigieren [83], [91]. Analysen von Halluzinationen und Fehlverhalten in agentischen Systemen zeigen, dass solche Fehlerketten schwer zu detektieren sind und sich über mehrere Tools und Agenten hinweg fortsetzen können [58], [81]. Spezialisierte Ansätze wie Critic Agents, Validator-Agenten oder kollaborative Verifikationsstrategien verbessern die Robustheit, bleiben aber überwiegend ad-hoc und domänenspezifisch [85], [87]. Eine Forschungsaufgabe liegt in der Entwicklung von Error‑Localization‑ und Bounded‑Propagation‑Strategien, die kritische Fehlerquellen automatisch identifizieren, deren Auswirkung auf nachgelagerte Agenten begrenzen und Fehlermodi systematisch klassifizieren [85].
Observability, Debugging und Root-Cause Analysis
Agentensysteme weisen inhärent undurchsichtige, implizite Reasoning-Prozesse auf [83]. Klassische Observability-Konzepte aus verteilter Software (Logs, Metriken, Traces) erfassen zwar Systemzustände, liefern aber nur begrenzte Einsichten in agentische Denkprozesse, Tool-Nutzung und Halluzinationsmuster [83], [92]. Aktuelle Arbeiten schlagen kognitive Observability-Frameworks, spezialisierte LLM-Observability-Plattformen und Benchmarking-Ansätze vor, die Agentenverhalten detailliert analysieren und visualisieren. Gleichzeitig zeigen Berichte aus der Praxis, dass systematische Evaluation und Root-Cause-Analysen häufig manuell erfolgen und damit zeitaufwändig und fehleranfällig bleiben [83], [92]. Eine Forschungsaufgabe liegt in der Standardisierung von agentenspezifischen Observability-Protokollen, die einheitliche Tracing-, Evaluations- und Debugging-Mechanismen für unterschiedliche Agent-Frameworks und Tool-Landschaften definieren und sich mit bestehenden Monitoring-Stacks integrieren lassen.
Cost Optimization und Token-Effizienz bei Skalierung
Multi-Agent-Systeme konsumieren deutlich mehr Tokens als Single-Agent-Systeme, unter anderem durch zusätzliche Reasoning-Schritte, wiederholte Tool-Aufrufe und wachsende Kontexte [93], [94], [95]. Studien und Erfahrungsberichte zu agentischen Workflows in Cloud-Umgebungen und Unternehmen zeigen, dass ineffiziente Orchestrierung zu erheblichen verdeckten Kosten führen kann, etwa durch redundante Anfragen, unnötige Parallelisierung oder unzureichendes Caching [94], [95]. Pattern-basierte Optimierungen, zum Beispiel Plan-and-Execute-Ansätze mit getrennten Modellen für Planung und Ausführung oder hybride Edge-Cloud-Ressourcenzuweisung, demonstrieren bereits signifikante Einsparpotenziale [93], [96]. Eine offene Forschungsaufgabe besteht darin, kostenbewusste Designwerkzeuge für Agenten zu entwickeln, die Prompting, Memory-Strategien, Modellwahl und Orchestrierung systematisch hinsichtlich vorgegebener Kostenbudgets optimieren.
Legacy-System-Integration bei produktiven Deployments
Schließlich stellt die Integration agentischer Systeme in bestehende Unternehmenslandschaften eine weitere offene Herausforderung dar [80], [97]. Arbeiten zu agentischen Workflows und Enterprise-APIs betonen, dass viele Organisationen über Legacy-Systeme ohne geeignete Schnittstellen für Echtzeit-Zugriff, Transaktionssicherheit oder feingranulare Berechtigungsmodelle verfügen [80], [97]. Gleichzeitig deuten Marktanalysen darauf hin, dass die breite Einführung von Agentic AI in Unternehmen weniger an den Modellen selbst als an fehlender Modernisierung von API-Architekturen, Sicherheitskonzepten und Governance-Strukturen scheitert [80], [98]. Agenten, die Code ausführen oder produktive Systeme steuern, sind jedoch auf robuste APIs, moderne Middleware und konsistentes Identity- und Access-Management angewiesen [97], [99]. Es besteht Forschungsbedarf für Architektur- und Migrationsmuster, die eine sichere und schrittweise Anbindung agentischer Systeme an etablierte Infrastrukturen ermöglichen.
Ausblick
Mehrere Entwicklungen werden die Architektur von Agentensystemen in den kommenden Jahren voraussichtlich prägen.
Erstens werden Meta-Agenten und hierarchische Orchestrierungen an Bedeutung gewinnen [100], [101]. Generalistische Multi-Agent-Frameworks [96], [102], Agent-of-Agents-Architekturen [96] sowie hierarchische Kooperationsmuster zeigen sich bereits als skalierbare Lösungen für komplexe Aufgaben, die mit Single-Agent- oder flachen Multi-Agent-Architekturen nur schwer zu bewältigen sind [96], [100], [102]. Dies verschiebt den Schwerpunkt von der Konstruktion einzelner Prompts hin zum Entwurf ganzer Agentenhierarchien und Rollenmodelle [96], [100].
Zweitens werden Observability und Kostenüberwachung zu Plattformfunktionen. AI-Gateways und Observability-Plattformen für LLM- und Agent-Anwendungen etablieren sich als zentrale Infrastrukturkomponenten, die Routing, Policy-Enforcement und Monitoring bündeln. Observability wird damit nicht länger als optionales Diagnosewerkzeug, sondern als integraler Bestandteil von Governance- und Compliance-Anforderungen verstanden [81], [84], [94], [99].
Drittens verändern spezialisierte Reasoning-Modelle die Orchestrierungslogik. Leistungsfähige, aber kostspielige Reasoning-Modelle mit expliziter Darstellung von Denkpfaden werden zunehmend mit leichteren Modellen kombiniert, die einzelne Ausführungsschritte übernehmen. Solche hybriden Strategien, bei denen Frontier-Modelle die Planung und kleinere Modelle die Ausführung übernehmen, werden in Analysen zu Performance- und Kostenoptimierung als vielversprechend bewertet [93], [96], [103], [104].
Viertens zeichnet sich ab, dass Human-in-the-Loop mit klar definierter Governance ein zentraler Erfolgsfaktor bleibt [98], [105]. Position Papers zu Risiken vollautonomer Agenten sowie Arbeiten zu Guardrails, Governance-Frameworks und Organisationsstrategien betonen, dass gezielt gestaltete menschliche Eingriffspunkte entlang des Softwareentwicklungsprozesses essenziell für Sicherheit, Vertrauen und regulatorische Konformität sind. Anstatt vollständig autonome Systeme anzustreben, etablieren sich Konfigurationen, in denen Autonomiegrade bewusst variiert und an definierten Entscheidungspunkten durch Menschen übersteuert oder validiert werden. Organisationen, die solche Entscheidungsstrukturen, Rollen und Kontrollmechanismen frühzeitig etablieren, schaffen damit die Grundlage für den sicheren und effizienten Einsatz agentischer Systeme in der Softwareentwicklung [80], [85], [98], [99], [101], [106], [107], [108], [109].
Leave a Reply
You must be logged in to post a comment.