Abstract– In traditional Software Development Lifecycles, testing is often performed in its final phases, increasing defect resolution costs and project risks. Recent advances in Artificial Intelligence (AI) have the potential to accelerate development workflows and reduce manual effort. However, the actual capabilities of AI-driven testing tools remain unclear, particularly in microservice contexts. This paper evaluates AI-based test generation for an isolated microservice across the testing pyramid. Three technology clusters are compared: Large Language Model (LLM)-based assistants, AI-enhanced platforms, and classical AI approaches. Test quality and usability are assessed in a controlled experimental setup. Results show that LLM-based tools produce the highest qualitative tests but suffer from non-determinism and declining correctness at more complex tests. Classical AI approaches provide stable automation but limited semantic quality. AI-enhanced platforms reduce interaction effort, yet lack transparency about AI usage.
Overall, AI effectively accelerates test drafting but does not enable autonomous verification. Human judgment, accountability, and final quality assurance remain essential, supporting a human-in-the-loop strategy.
Introduction
Recent advances in Artificial Intelligence (AI) are affecting the entire software development industry. For all phases of the Software Development Lifecycle (SDLC), various tools are emerging that promise AI-based solutions to advance development. These tools offer great opportunities to deal with current problems, but they also present potential risks when applied incorrectly. Especially in testing, which is defined by the IEEE 1059 standard as “the process of analyzing a software item to detect the differences between existing and required conditions (that is, bugs) and to evaluate the features of the software item.” [1], AI has the potential of augmenting and automating multiple stages of the software test cycle [2].
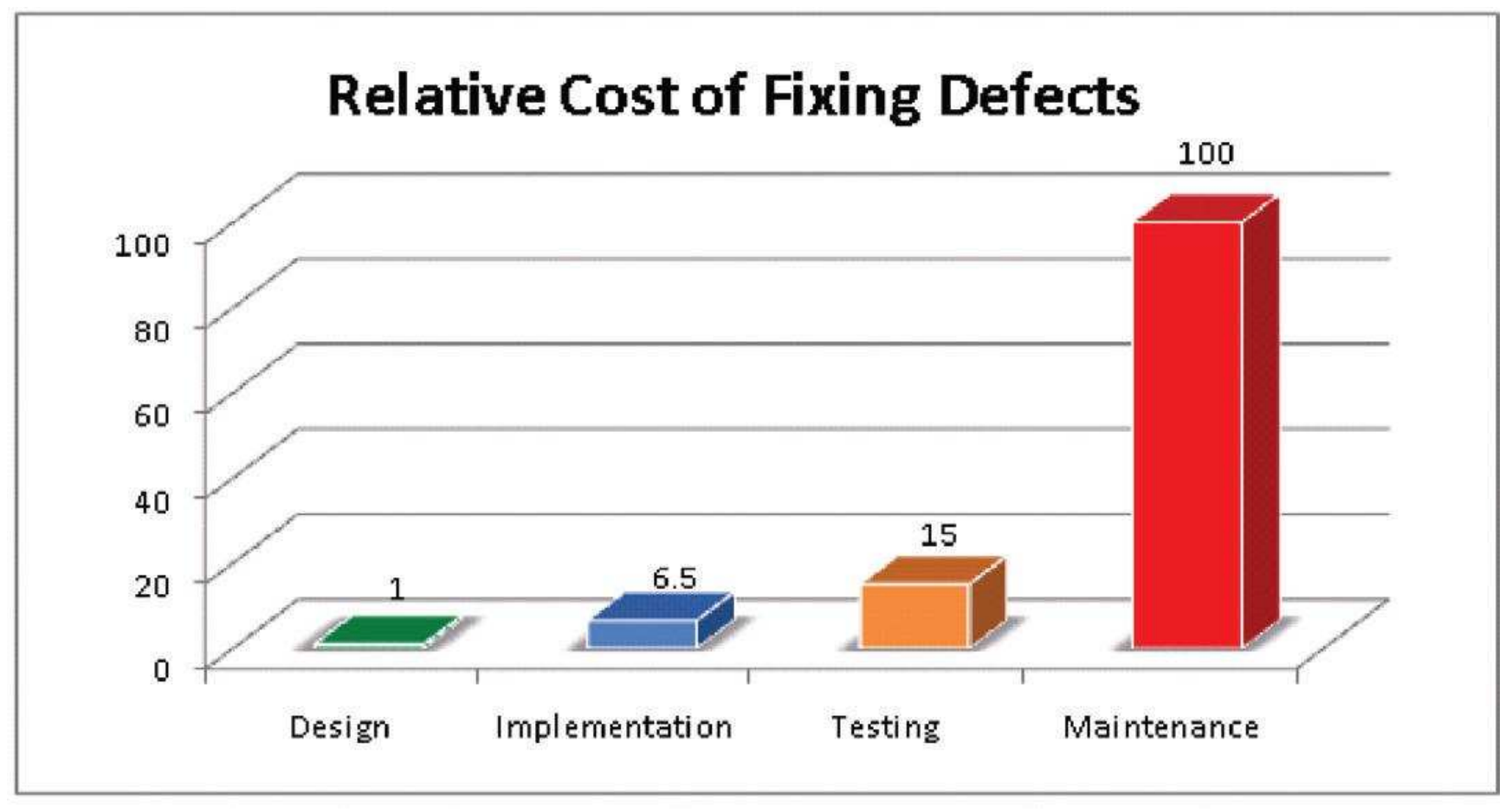
In the classical SDLC, software testing is performed after code implementation. This depicts a natural flow where the code is first implemented and then tested afterwards. However, a study by the IBM System Science Institute showed that the relative costs of fixing defects during the testing stage are 15 times higher than during the design stage [3]. In addition, as illustrated in Figure 1, provided by the same authors, the costs rise exponentially in the maintenance stage, which highlights the importance of early software testing to avoid loss of revenue.
The speed of AI offers the possibility to shift testing practices to earlier SDLC stages. Another current challenge in software testing, as illustrated in [4], is the economic trade-off faced by Quality Assurance (QA) teams in determining the optimal balance between achieving sufficient software stability and maintaining a time-efficient and cost-effective development process. Here, the Large Language Model (LLM) technology can assist in speeding up test generation, while reducing development costs and manual effort.
As microservice architectures are widely adopted in modern software systems, this work investigates AI-based tools within this architectural paradigm. However, due to the complexity and distributed nature of this architecture, the investigation focuses on a single, isolated microservice rather than an entire system landscape and prioritizes the software testing pyramid introduced in [5]. Therefore, this study is limited to unit, integration, and End to End (E2E) tests and additionally considers Application Programming Interface (API) tests. The study was conducted as part of the masters lecture “AI-Driven Software Development”.
The following research questions guide this study. RQ denotes the main research question, while RQ1–RQ3 represent research sub-questions that address different evaluation dimensions.
RQ: To what extent can AI-driven software testing methods support developers in a microservice-based system when applied across the software testing pyramid?
RQ1: How well do AI-generated software tests achieve the required level of quality in terms of correctness, coverage, and maintainability within a microservice context?
RQ2: How usable are current AI-driven software testing tools with respect to integration, configuration effort, and developer interaction?
RQ3: How does the adoption of AI-driven software testing tools influence the role, responsibilities, and workflows of software developers?
Related Work
In this section, related work on AI-driven software testing is reviewed, covering recent advances, microservice testing approaches, and the current tool landscape. The latter is characterized by rapidly evolving tools and often ambiguous marketing claims. To ensure transferability of results despite short product life cycles, this study focuses on underlying technological principles rather than individual tools. Three technology clusters are distinguished: LLM-based chatbots, AI-enhanced tools, and classical AI approaches.
AI-Driven Software Testing
The use of LLMs for automated unit test generation was evaluated in [6]. The authors prompted different LLMs by including the signature and implementation of a function, along with usage examples extracted from the documentation. In addition, if a generated test failed, the LLM was re-prompted with the failing test and error message. Further experiments excluded information from the prompts to highlight, that all components contributed towards the generation of effective test suites. Their findings suggest that the effectiveness of that approach is influenced by the size and training set of the LLM, but does not depend on the specific model. The key factors that caused tests to fail were assertion errors, timeout errors and correctness errors.
Mutation testing evaluates test quality by introducing small “mutations” into the source code, then checking if the existing tests detect them. Good tests cause mutants to fail (killed mutants), ineffective tests let faulty mutants pass (surviving mutants), indicating untested code paths, missing edge cases or assertions highlighting test suite weaknesses [7]. This technique was applied in [8] for test generation. The authors augmented LLM prompts with surviving mutants to highlight limitations of test cases in detecting bugs. An important finding was, that although LLMs can serve as a tool for test case generation, they require specific post-processing steps to improve the effectiveness of the generated test cases.
AI-based self-healing test automation frameworks were reviewed in [9]. These frameworks automatically adapt to code and User Interface (UI) changes, reducing maintenance in manual testing. For example, if a CSS class or changes, the AI analyzes and fixes the failing test by updating the selector. However, these frameworks suffer from the same constraints as other AI-based tools: complexity of AI model training, scalability concerns in large-scale systems, security and privacy risks and finally explainability and trust in AI- driven decisions.
Tool Landscape
In tools based on LLM chat bot technology, users interact directly with the LLM manually crafting prompts [10]. The chat interfaces are typically integrated into the Integrated Development Environment (IDE) or provided via a web interface by the LLM provider. AI-enhanced tools are defined by a less transparent and often diffuse integration of AI capabilities. In these tools the users do not directly prompt the LLM, instead, the LLMs get there prompts from the tool and can be fine tuned to a specific task. The use of AI is often only indicated by small icons or subtle UI elements within the application. Classical AI tools are primarily research-oriented and originate from a time before the rise of generative AI. Examples include machine learning algorithms for test case prioritization [11], [12] or evolutionary algorithms for code or test data generation [13], [14].
Testing Microservices
A study conducted by [15] found that integration- and unit testing are the most popular testing approaches for microservices. In addition, the authors highlighted the challenges in testing this architecture. Microservice applications rely strongly on network communication, database fixtures, and file system access. Due to this complexity, testing synchronous and asynchronous interactions between multiple services is difficult and the deployment of diverse services makes test automation challenging. Moreover, manually analyzing logs across services is cognitively demanding for QA teams.
In [16] testing approaches were reviewed. The findings highlight a shortage of dedicated test generation tools designed specifically for microservices. The authors suggest using mock services as a solution for testing complex inter-service dependencies. Event-driven architectures introduce asynchronous complexities, necessitating specialized unit testing approaches.
An automated software testing tool designed for web-based microservices applications using an LLM-based multi-agent approach called “Kashef” was introduced in [17]. The tool aims to automate the generation and execution of end-to-end (black-box) system tests. Because single-prompt instructions often failed to produce successful results, the tool uses multi-agent workflows. The first agent (Testing Engineer) receives user prompts and generates Selenium-based testing code. The second agent (HTML Interpreter) analyzes HTML code from the application and describes key elements to the Testing Engineer, for it to understand the current state of the web application and identify the necessary elements to interact with next. Finally, the Code Executor agent runs the generated code and provides feedback (errors or HTML) back to the other agents. Recurring issues were, that agents discarded working code from previous steps when generating new code for later subtasks and that as tasks grew in complexity, reliability decreased.
Methodology
This study investigates to what extent AI-generated software tests can currently support developers in a microservice-based software architecture. To this end, an experimental evaluation was conducted in which multiple AI-based testing tools were applied to a representative microservice system. The experiment assesses both the technical quality of the generated tests and the practical usability of the tools. The types of generated software tests are outlined in Section III-A. The experimental setup is centered around a microservice system that provides a realistic yet manageable evaluation context for LLMs. The system and its architecture are described in detail in Section III-B. All necessary preparations are described in Section III-C. A set of AI-based testing tools was selected to cover the previously identified technology clusters, enabling a comprehensive comparison of different approaches to AI-supported test generation. The selected tools and their classification are introduced in Section III-D. Finally, the performance of the tools is evaluated using a set of qualitative and quantitative metrics that capture test quality, tool usability, and generation efficiency. The metrics and evaluation procedure are described in Section III-E.
Experimental Setup
To enable interpretation of the results presented in Section IV, technical details regarding the microservice and the experimental setup are provided here. This description aims to highlight the simplicity of the business logic and the constraints present in the frontend. Due to the degradation in performance of LLMs caused by a too large input context [19], the decision was made to focus on an isolated microservice rather than testing the entire application, to keep the input context manageable.
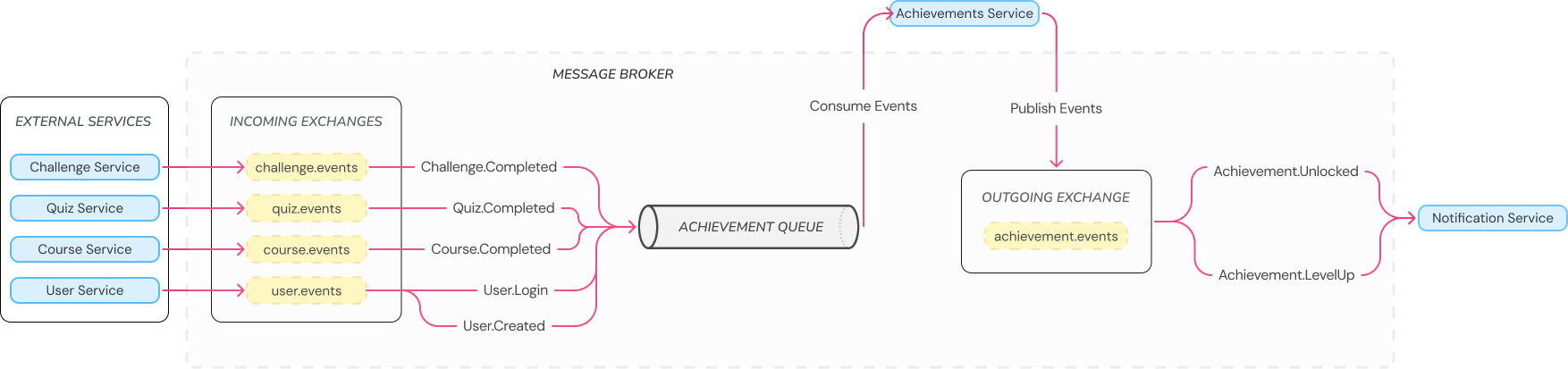
The utilized service “Achievement Service” is part of a larger application “StudifAI”, that is an AI-powered learning platform focused on gamification. The main functionality of the achievement services is to manage user progress through an event-driven architecture. The service tracks Experience Points (XP) and progress of defined achievements for each user. The application consumes events from other services (e.g. Quiz.Completed) and updates the relevant achievement progress for the user. Based on progress, the service publishes an Achievement.LevelUP or Achievement.Unlocked for other services. The event design is visualized in Figure 2 and highlights, that the service is heavily event-driven.
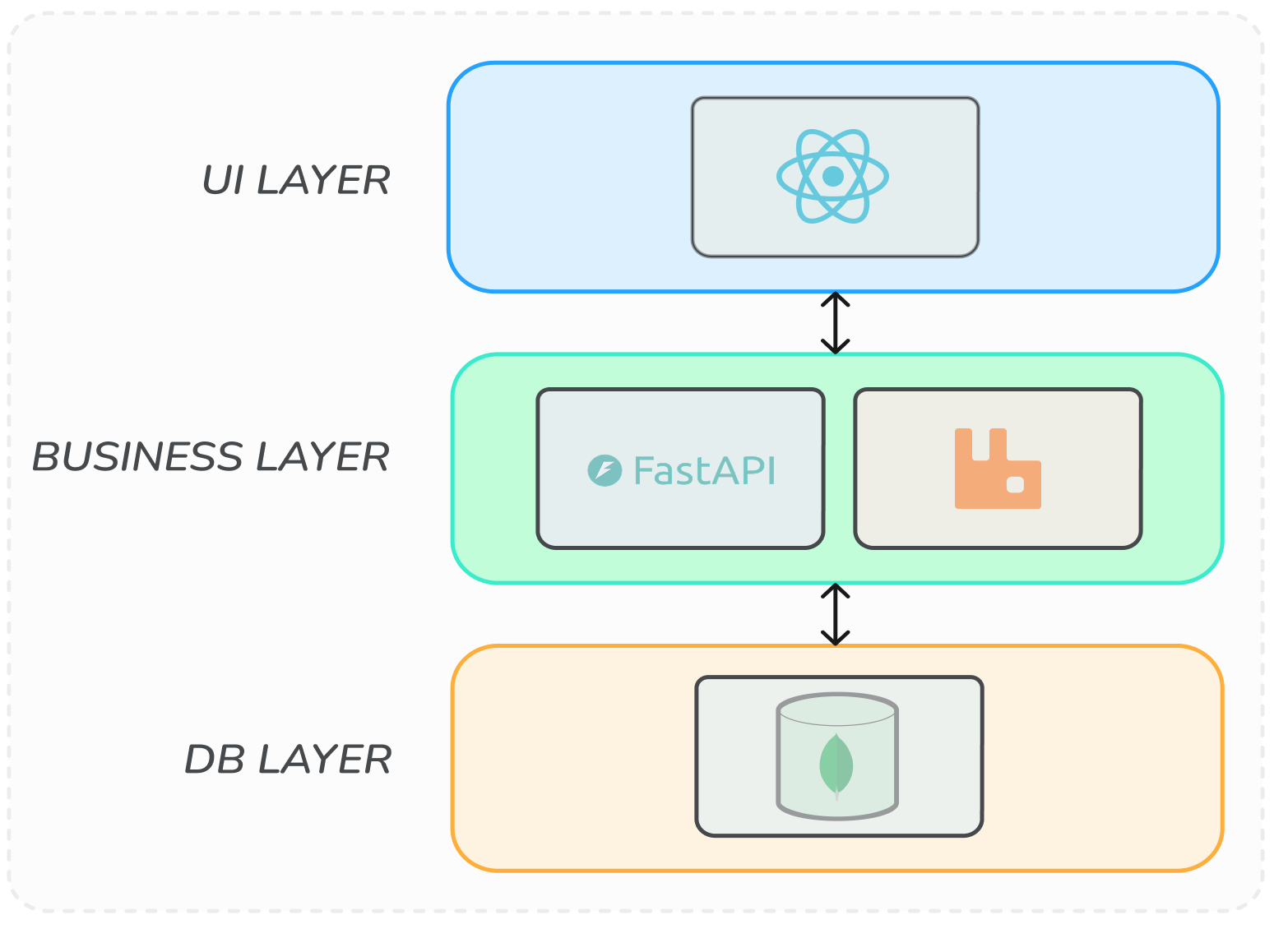
The application follows a layered architecture, as shown in Figure 3. The data layer with MongoDB as database consists of three collections: users, achievements, and user_achievements as link collection to solve the m to n relation between users and achievements. For all collections additional CRUD-routes were provided. The business layer is implemented in Python using FastAPI. It follows a repository–service architecture to clearly separate business logic from data access concerns. This layer consumes messages from events of other services and publishes itself events to the message broker. Event communication is organized through event contracts between all services. Upon consuming an event, the backend performs the required computations and evaluates whether the event results in a state change that should trigger the publication of a new event. If so, the frontend is updated accordingly. The frontend is implemented in React. It initially retrieves the current user state via a REST endpoint and subsequently receives real-time updates through WebSockets. It is important to note that the frontend is very basic and primarily responds to events, but does not offer any input options. Consequently, the evaluation of tests related to the front end is constrained. Moreover, the application is containarized with docker.
Preparations
Before starting the case study, the architecture described in III-B was planed and implemented in a testable way following the common clean code practices of [20]. The selected architecture is simple compared to other software architectures and used the tech stack commonly referred to, as FARM stack (FastAPI, React, MongoDB) [21]. The FARM stack was chosen, not only for its architectural efficiency but also to leverage the higher code-generation fidelity of LLMs since both Python and Javascript have resource-rich ecosystems, since they are one of the most popular programming languages [22]. Moreover it was shown that LLMs consistently favor well-established libraries [23], which was also a factor favoring the FARM stack.
A docker testing environment was also provided via docker-compose file. This container environment contains a RabbitMQ service for the event handling and a MongoDB container, allowing one to perform true integration tests instead of using mocks or stubs. The container environment was configured in a way, that on every start, the database is dropped and reset via script that contained suitable dummy data to test multiple edge cases. Otherwise, the principle of repeadability of the F.I.R.S.T test principles would have been violated when rerunning some tests that require a specific database state.
To perform integration tests, a fake publisher was provided to mock consumed events and API-routes to manually trigger these events were added. On the one hand, it is possible to perform blackbox API-tests to validate expected responses and implicitly test the event handling and CRUD-operations for the database. On the other hand, the event handling and database connection can be tested explicitly by writing integration tests. To test the event handling and the API an openapi and asyncapi specification were added into the code base, expecting it may help a LLM with access to the code base, to generate tests. To perform E2E-tests, the container environment can be used. Since the frontend has no forms or other input and only reacts to external events, the UI-Tests as part of the E2E-test are limited to simple visual checks of correct texts being displayed and clicks to open a detail view for every achievement.
For the testing the dependencies, Pytest as testing library, Testcontainer to spawn lightweight containers for isolated integration tests and Mongomock to mock the database for unit tests, were added. Since uv was used as package manager, the project contains a file with information about all dependencies and versions, which are available to AI-tools with access to the project. The data models are written as schemas inside the codebase.
In summary, as a starting point for testing, a reusable testing environment was created, a testable microservice was developed, supplementary artifacts were added to the codebase, such as data models, dummy data, schemas, dependencies, and contracts, and a technology stack well known to LLMs was employed. At this stage, it is worth mentioning that without this initial setup, the results could have been different and leaves an open question for the reader about when AI-driven-testing actually begins.
Selected Tools
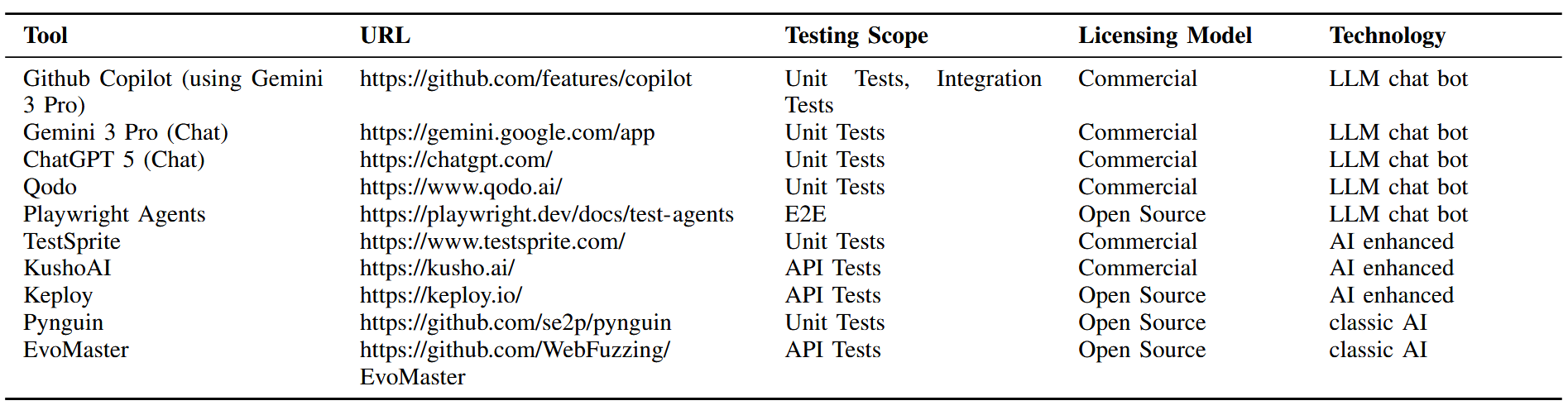
The tools were selected to represent all identified technology clusters and testing domains while ensuring practical accessibility through free trials or open-source availability. Transparency regarding AI usage was preferred, but could not be achieved for all tools. The selection is not intended to be exhaustive and focuses on underlying technological paradigm rather than product-level benchmarking. Table I summarizes the evaluated tools and their characteristics. Only the testing scopes considered in this study are listed, although some tools support additional test types.
Due to the simplicity of the frontend system mentioned in Section III-B, only one tool for E2E testing was evaluated. Consequently, the study does not aim to generalize findings for AI-based E2E test generation but rather provides an initial indication of current tool capabilities.
The selected tools cover three technology categories. LLM-based tools (GitHub Copilot, Gemini, ChatGPT, Qodo, and Playwright Agents) generate tests via natural language interaction. Playwright Agents extend the IDE-based assistant paradigm by providing specialized agents (planner, generator, and healer) with predefined system prompts, which interact with the Playwright runtime via a Model Context Protocol server. This study uses Gemini as LLM for the use of Playwrigth Agents. Classical AI tools (Pynguin and EvoMaster) rely on evolutionary algorithms to automatically generate and execute tests. AI-enhanced tools (TestSprite, KushoAI, Keploy) provide dedicated user interfaces and automated workflows, although the exact role and integration depth of AI components is not fully disclosed by the vendors.
For LLM-based tools, two interaction modes were evaluated: (i) IDE-integrated assistants with repository-wide context (GitHub Copilot, Qodo, Playwright Agents) and (ii) web-based chat interfaces in which relevant source files and specifications were manually provided. Classical AI tools were executed in a fully automated command-line setting. AI-enhanced tools typically rely on dedicated user interfaces, where structured input artifacts (e.g. openapi specifications) are supplied and the test generation workflow is orchestrated through the tool’s integrated management interface.
For comparability, for every LLM, the same base prompt was used, which can be found in Appendix A. Apart from that, no further prompt engineering techniques were employed, since research already exists, as presented in Section II.
Metrics
The selected metrics aim to assess how effectively current AI-based tools support developers in generating software tests. To isolate the capabilities of the tools themselves, all tests were generated by AI without manual test authoring. While user interaction was required to operate the tools, no test code was written by human developers. This setting enables a clear assessment of the current state of AI-driven test generation and avoids confounding tool performance with developer expertise.
Selected Metrics:
The evaluated tools generate heterogeneous artifacts. While some approaches produce executable source code (e.g., Unit and E2E tests), others yield tests represented in external systems or proprietary formats (e.g., Integration or API tests). Consequently, some metrics cannot be uniformly measured across test types and are therefore adapted to the technical characteristics of the produced artifacts where needed. To enable a comprehensive evaluation, the following metrics were used:
- F.I.R.S.T. Principles: Whether the generated tests adhere to the F.I.R.S.T. principles (Fast, Independent, Repeatable, Self-validating, Timely) [20].
- Correctness: For Unit Tests, this paper follows [24], where correctness is assessed in percent in three stages adapted to Python: (i) syntactic correctness, which determines whether the test can be parsed into an abstract syntax tree; (ii) collection correctness, which determines whether the test module can be successfully imported and collected by pytest; and (iii) execution correctness, which determines whether the collected tests pass on the reference implementation. Under the assumption that the reference implementation is correct, all generated tests are expected to pass. For non-code-based tests (Integration tests), earlier pipeline stages such as syntactic or collection correctness are not observable. Therefore, correctness is evaluated based on the rate of false failures and run completion in percent on the reference system.
- Generation Time: The time required by a tool to generate a test suite for one file in minutes.
- Tool Effort: The number of atomic user interactions required to obtain the final test suite (excluding the tool setup).
- Test Quality: The quality of the generated tests in terms of coverage and assertion quality, assessed using a structured subjective rating scale (1–5). This metric is subject to evaluator bias and is discussed as a threat to validity.
Planned Objective Quality Metrics
The initial study design aimed to employ objective, quantitative metrics for assessing test quality. First, code coverage was considered to measure the proportion of executed statements and branches covered by the generated test suites [25]. Second, the mutation score was planned as a robustness metric [25]. Finally, the oracle gap, defined as the difference between code coverage and mutation score, was intended to capture the extent to which covered code is insufficiently asserted and therefore lacks effective test oracles [26]. 3)
Limitations and Alternative Quality Assessment:
Ideally, each test suite would be generated multiple times (e.g., ten runs per tool) and the reported metrics would be averaged to mitigate the effects of stochasticity and non-determinism inherent to LLMs and AI systems [27]. However, many tools impose strict limitations on usage time or available credits, which prevented repeated generation within the study’s constraints. To ensure comparability across all evaluated tools, repeated generation was therefore omitted even when technically feasible for individual tools. Future work should investigate the robustness of the quality of the generated tests. A further limitation of this study is the reliance on subjective test quality assessment. Although mutation testing was initially planned, mutation tool stability and limited robustness prevented its systematic use. This highlights a practical limitation of existing tooling and motivated the use of a structured subjective assessment scheme. Furthermore, several AI tools generated an insufficient number of tests to enable meaningful coverage analysis, which led to the exclusion of coverage-based metrics. Consequently, the oracle gap metric was also omitted, as it requires both coverage and mutation score. As a result, test quality was assessed using structured qualitative criteria rather than fully quantitative metrics. Given that the primary focus of this study is to investigate how AI tools support developers in test generation, the absence of precise quantitative quality measurements is considered acceptable. Future work should investigate more robust mutation testing pipeline.
Results
The following chapter describes the observed tool results in correctness, generation efficiency, tool effort and test quality in generated Unit Tests, Integration/API Tests and E2E Tests. Tools for which no executable results could be obtained are omitted.
Unit Tests
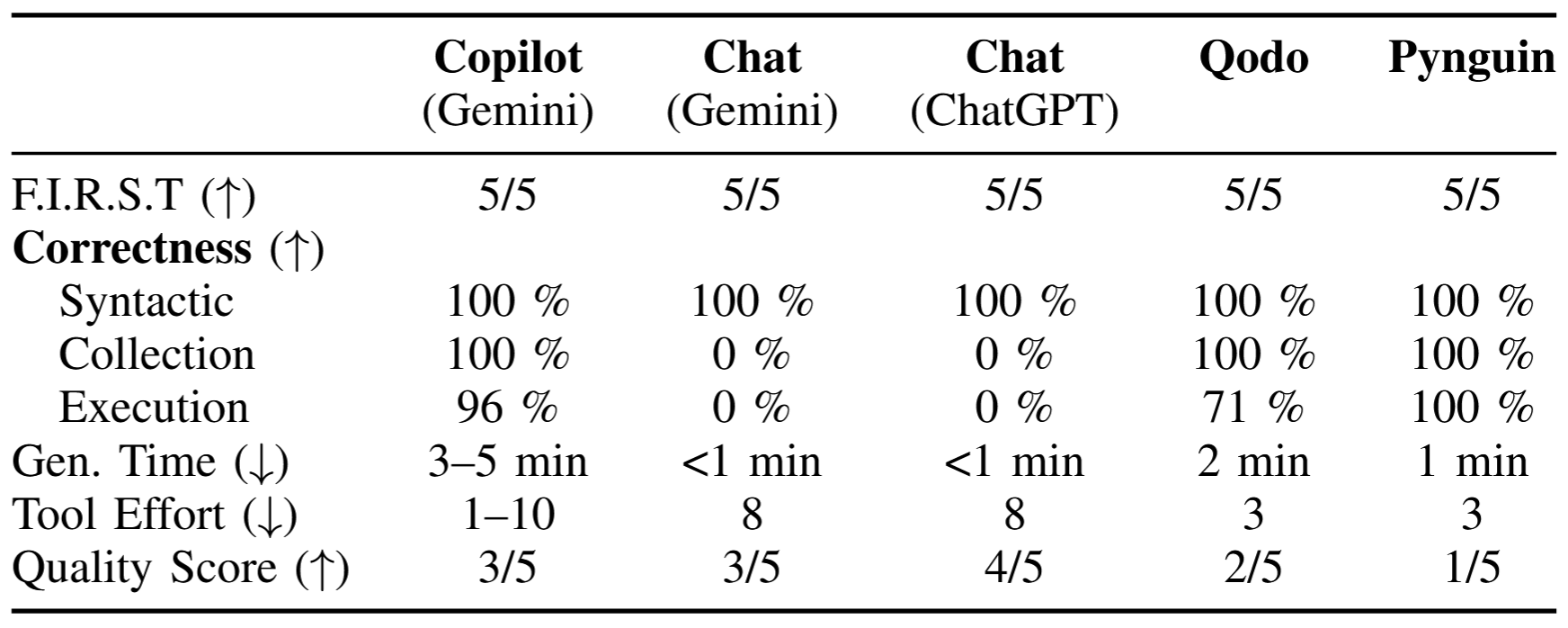
Table II summarizes the quantitative results for AI-based unit test generation. GitHub Copilot using the Gemini model achieved the highest correctness among the evaluated LLM-based tools. All generated tests adhered to the F.I.R.S.T. principles and were syntactically correct with valid imports. Only 4 % of the generated tests failed unexpectedly, indicating a high execution correctness compared to other approaches. Copilot operates iteratively by executing generated tests and refining failing cases, which improves correctness but increases variability in tool effort. In the optimal case, a single prompt was sufficient, whereas multiple manual interventions were required when the agent produced incorrect console commands (e.g., misconfigured pytest invocations). Generation time was the highest among the evaluated tools but remained short in absolute terms. Test quality was inconsistent, but on average moderate (3/5), with a focus on happy-path scenarios and limited edge-case coverage.
Gemini using the chat interface produced syntactically correct test code that adhered to the F.I.R.S.T. principles and required short generation times. However, incorrect imports of the target modules prevented test collection, resulting in zero execution correctness unless manually corrected. Tool effort was comparatively high due to manual file copying, prompt formulation, and code transfer steps. Test quality was inconsistent, but on average moderate (3/5), with more edge-case coverage than Copilot but still limited in depth.
ChatGPT using the chat interface showed behavior comparable to Gemini Chat in terms of generation workflow and tool effort. While syntactic correctness and adherence to F.I.R.S.T. were achieved, import issues similarly prevented test execution without manual correction. In contrast to Gemini Chat, the generated tests exhibited higher qualitative test quality (4/5), including more detailed assertions and improved edge-case handling.
Qodo generated syntactically correct tests with proper imports but exhibited a high rate of false positives due to an incomplete understanding of the code under test. Unlike Copilot, Qodo does not allow user intervention in the execution environment to correct console statements, preventing iterative correction of failing tests. As a result, failing tests persisted and the agent aborted after several attempts. Generation time was short, and tool effort was low because the process is largely automated. Overall test quality was highly inconsistent and on average low (2/5), with limited coverage and inconsistent test structuring.
Pynguin, representing classical AI-based test generation, produced fully executable test suites with perfect syntactic, collection, and execution correctness. Tool effort was low due to its fully automated command-line operation. However, qualitative test quality was poor (1/5), characterized by duplicated test cases, limited edge-case exploration, and poor naming conventions (e.g., generic test case identifiers). Assertions were generated per test case but often lacked semantic expressiveness.
TestSprite could not be evaluated due to persistent internal server errors and was therefore excluded from the results.
Overall, LLM-based tools outperformed classical AI approaches in qualitative test design, while classical tools achieved higher execution correctness and automation. Among LLM-based tools, IDE-integrated agents demonstrated superior correctness due to iterative execution feedback, whereas chat-based interfaces suffered from integration and import issues.
Integration and API Tests
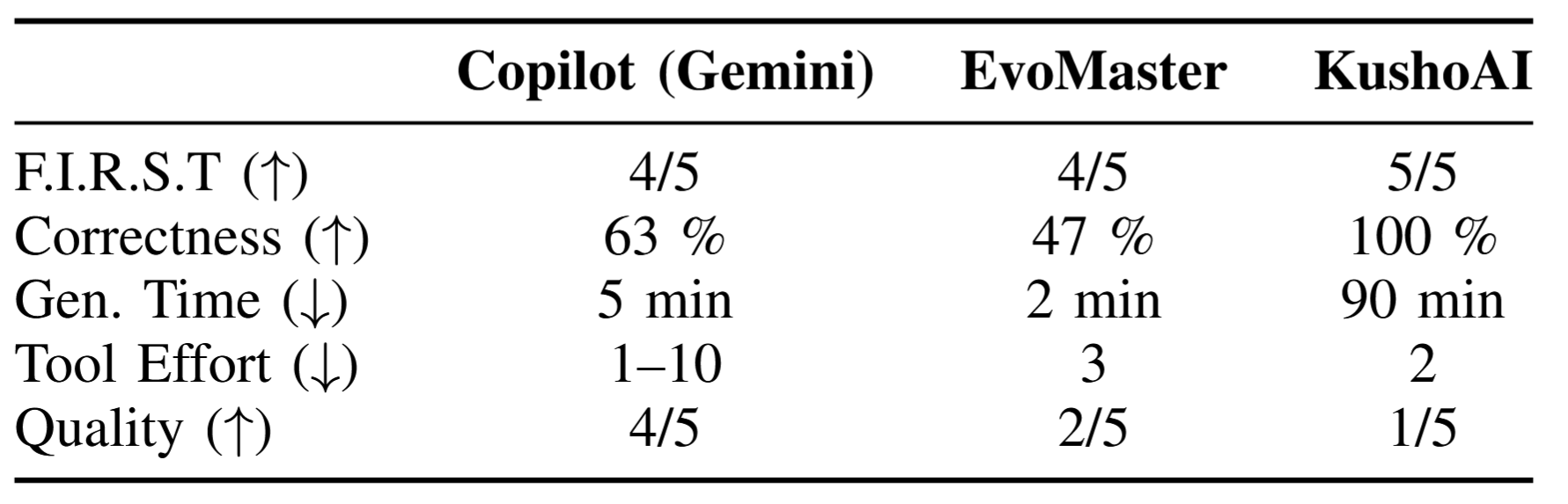
Table III summarizes the quantitative results for AI-based integration and API test generation. Tools for which test generation failed are excluded from the evaluation.
GitHub Copilot using the Gemini model generated integration tests in Python using Pytest. While all tests were syntactically correct, the F.I.R.S.T. principle of independence was violated, as several tests depended on execution order and failed when reordered. Execution correctness was 63 %, which is substantially lower than for unit tests, with frequent failures caused by incorrect database interactions. Generation time was approximately five minutes per file, exceeding that of unit test generation. Tool effort was variable due to the iterative execution and refinement behavior of the agent, analogous to the unit test setting. Qualitative assessment (4/5) indicated high assertion quality and coverage of multiple execution paths, although not all edge cases were addressed.
KushoAI generated > 900 API tests which is a large number relative to the small API surface. All F.I.R.S.T. principles were satisfied, and no generated tests failed on the reference implementation, resulting in 100 % execution correctness. Generation time was approximately 90 minutes, which is significantly longer than for all other evaluated tools. Tool effort was minimal, as only two user interactions were required. Despite the high correctness, test quality was low (2/5) due to generic assertions that were not tailored to the specific API semantics.
EvoMaster, representing classical AI-based approaches, generated API tests and API test data using an evolutionary algorithm. Tests satisfied most F.I.R.S.T. criteria but exhibited flakiness, resulting in a F.I.R.S.T. score of 4/5. Execution correctness was 47 %, with nearly half of the generated tests failing unexpectedly. Tool effort was low due to automated command-line execution. Qualitative assessment revealed unsystematic test structures and limited semantic relevance, resulting in a quality score of 2/5.
Keploy failed to generate executable tests and was therefore excluded from the evaluation.
Overall, integration and API test generation exhibited lower correctness and higher generation times than unit test generation, with substantial variability across tools.
E2E Tests
Only the tool Playwright Agents was evaluated for end-to-end testing. The test generation component achieved full compliance with the F.I.R.S.T. principles. The generated tests showed a correctness rate of 67 %, indicating that approximately two-thirds of the tests executed successfully without unintended failures. The generation time was 3 minutes, comparable to unit and integration test generation times of LLM-based tools.
In terms of qualitative coverage, the tool exercised all major user interaction paths and demonstrated a strong understanding of the frontend structure and behavior. The self-healing component was evaluated in two controlled experiments. It achieved a correctness rate of 50 % and required 3 minutes for healing. The tool correctly adapted a test after an identifier change in the frontend but incorrectly removed a test for a component that had been deleted, indicating limited robustness and occasional overcorrection behavior.
Discussion
The following chapter discusses the results structured by the sub-research questions RQ1-3 to answer the overall research question (RQ).
RQ1: Quality of AI generated Software Tests
For safety-critical and distributed systems, automated test generation must deliver reliable and reproducible results. The following subsection discusses the results with that focus to answer RQ 1. The observed behavior must be interpreted in light of the purposely prepared, highly controlled environment, without that environment, the results might differ.
LLM-based tools produced the strongest qualitative artifacts across the study (quality ≥ 3/5). Generated tests were typically readable, contained meaningful assertions, and considered edge cases. No substantial differences were observed between the evaluated LLMs. Notably, unit tests were qualitatively similar whether generated by IDE-based tools with repository context or by standalone LLM chat systems without repository access, underscoring the contextual independence expected of well-constructed unit tests. The evaluation environment was intentionally designed to be highly testable and particularly suitable to LLM–based tooling. Despite these favorable conditions, execution correctness declined markedly toward the higher levels of the testing pyramid. Unit tests achieved the highest success rates, whereas integration and end-to-end scenarios were substantially less reliable. This trend suggests that increasing architectural complexity challenges the models’ reasoning and context capabilities, possibly amplified by limited availability of representative training data for specialized multi-service coordination. A central limitation is the observed variance. Results fluctuated between runs and even across tools built on the same foundation model, emphasizing the impact of prompting strategies and tool integration and the problem with probabilistic LLM output. In addition, several IDE-based agents iteratively modified the tests until they passed, optimizing for execution success rather than fault detection. Passing generated tests therefore does not reliably imply that the underlying code base is functionally correct or behaves as intended. Self-healing mechanisms further risk masking defects by adapting tests to faulty system behavior.
The evaluated AI-enhanced tools achieved lower quality and correctness than LLM-based chatbot tools or failed to produce usable results even though schemas like OpenAPI were provided. Furthermore, some tools tended to generate an excessive number of tests, resulting in overtesting and a suboptimal economic trade-off. Plausible explanations include the use of less capable underlying models, suboptimal prompt engineering and limited training coverage across the test pyramid. A cross-level comparison was not possible due to tool availability. Based on the observed performance, their quality per test and overall test suite is currently insufficient for reliable adoption in microservice testing.
Classical AI approaches achieved high execution correctness in some unit-level scenarios, but suffered from low semantic richness, duplication, and weak maintainability (e.g. due to generic naming). Although highly automated, they cannot compete with LLM-based systems in producing expressive, developer-ready tests.
In comparison, LLM-generated suites appear to be most valuable at the moment representing a clear progress in test generation for microservices compared to classic AI based tools. LLM-generated tests may serve as a seed for regression testing but human validation remains necessary to ensure semantic strength, coverage and correctness.
RQ2: Usability of AI-Driven Testing Tools
To assess RQ2, usability is evaluated in terms of intuitiveness, learning effort, time efficiency, and secure integration. Clear differences emerge between AI-enhanced platforms, LLM-based chatbots, and classical AI approaches.
AI-enhanced systems minimize developer interaction as test generation is triggered through a few guided steps and requires little technical expertise. However, generation may take long, which offsets the benefit of automation. More critically, the underlying AI usage, model decisions, and optimization strategies are largely opaque. Developers therefore cannot steer results and improve quality systematically. The low interaction barrier further risks uncritical acceptance of artifacts. Integration is similarly affected by limited transparency. Unclear licensing and undisclosed provider involvement complicate evaluating data handling for compliance and cost predictability, especially under potential token-based pricing. Configuration effort varies strongly per product. Although operation is simple, significant preparation (e.g. OpenAPI artifacts) may still be required, and proprietary interfaces limit knowledge transfer across tools. Despite convenient workflows, these factors currently hinder sustainable adoption.
LLM-based assistants need less time to generate tests but require more and sometimes unpredictable interaction. Prompt refinement, environmental preparation, and iterative correction are common. The required expertise is therefore higher than for AI-enhanced tools, but interaction patterns are comparable across systems, allowing experience transfer. Their primary strength is integration transparency. The model and provider choices remain visible, enabling deliberate control over data flows and compliance. However, independent of the tool, adequate infrastructure (e.g., environments, mocks, dependencies) must exist for the models to generate tests. AI can assist in producing these artifacts, yet developers must understand the prerequisites to request them effectively.
Classical AI solutions emphasize fast command-line–driven automation. Their behavior resembles conventional software components and often provide higher methodological transparency because of their scientific origin. Required expertise is comparable to LLM-based usage.
For skilled teams, LLM-based and classical approaches therefore appear viable, whereas AI-enhanced platforms currently trade convenience for limited controllability.
RQ3: Influence on Developer Roles, Responsibilities, and Workflow
AI-driven test generation currently operates as assistive support rather than as an autonomous actor. Although LLMs produce artifacts rapidly, reliable outcomes require continuous human supervision. The developer role therefore shifts from authoring toward validating, correcting, and contextualizing generated tests, i.e., toward a human-in-the-loop setting.
This transition redistributes rather than lowers qualification demands. Developers must be able to assess test relevance and assertion strength, as generic or semantically weak oracles occur frequently. System and infrastructure knowledge remains necessary to configure execution environments, interpret failures, and resolve integration gaps. In addition, understanding characteristic properties of LLMs, such as non-determinism and recurring error patterns, is essential to maintain trust.
Effective adoption also requires tool literacy. Prompt formulation becomes a key skill for conversational interfaces, while AI-enhanced platforms demand awareness of how AI components shape the workflow. Experience is crucial to select appropriate tools per test level. While language-specific syntax knowledge may decline in importance, conceptual understanding of architectures, interfaces, and test design remains indispensable for judging and adapting outputs.
In practice, fully autonomous pipelines are not feasible. Workflows are dominated by iterative loops of generation, execution, review, and repair. Uncritical delegation would pose risks, including latent defects, flakiness, and potential compliance violations. AI therefore accelerates drafting, whereas control and decision-making remain human.
At the present moment, due to variable quality and correctness, responsibility cannot be shifted to the tool. Regardless of automation depth, accountability for correctness, coverage adequacy, and maintainability stays with the developer. AI increases productivity but does not replace engineering judgment.
RQ: Overall Capability Across the Pyramid
Overall Capability Across the Pyramid_ The findings across RQ1–3 suggest that AI is currently strongest in drafting support but not autonomous verification. The quality observations from RQ1 and the human-in-the-loop requirements from RQ3 indicate that LLM–based solutions currently provide the most favorable balance between usability, quality and flexibility. Their outputs are often structurally sound, but non-determinism and declining robustness toward integration and end-to-end scenarios prevent unsupervised adoption. The recurring tendency to optimize for execution success rather than defect discovery reinforces this interpretation. At the same time, RQ2 shows that AI-enhanced platforms reduce interaction effort while limiting transparency and controllability. In contrast, classical AI approaches offer stable automation in constrained contexts but produce artifacts with limited semantic value for developers.
Practical implication. Effective adoption follows a human-in-the-loop model: use LLMs to draft unit tests per artifact and decompose integration or E2E objectives into smaller generation steps or agent roles. Generated suites can accelerate regression seeding, but cannot serve as authoritative specifications. Safety-critical domains require full review.
Limitations. Single-run execution prevents statistical robustness. However, consistent patterns across similar tools indicate non-random tendencies. Quality ratings were necessarily subjective, further limiting generalizability. In essence, AI reliably accelerates drafting across the testing pyramid, while judgment, accountability, and final assurance remain a human responsibility.
Conclusion
This study evaluated the practical capability of AI-driven software testing within a controlled microservice environment, namely the StudifAI Achievement Service. Across all investigated technologies, AI demonstrated clear strength in accelerating the drafting of tests, but not in delivering autonomous and reliable verification.
A consistent gradient emerged along the testing pyramid. In unit-level scenarios, where interfaces are narrow, dependencies are limited, and implementation patterns are well represented in public training corpora, LLM-based systems frequently produced readable and structurally sound artifacts. However, with increasing architectural scope toward integration, API, and end-to-end levels, execution correctness, stability, and sometimes semantic adequacy declined substantially, especially for AI enhanced and classical AI tools. Event choreography, persistent state, and distributed side effects exceeded the reasoning reliability currently achievable without intensive human guidance. Even when tests executed successfully, iterative repair strategies and self-healing mechanisms are often optimized for passing rather than fault revealing, weakening their value as verification instruments.
The results further reveal that the term AI-driven hides substantial heterogeneity. LLM-centric assistants, AI-enhanced commercial platforms, and classical evolutionary approaches differ markedly in transparency, controllability, and artifact semantics. High automation frequently correlates with low explainability and limited steering capabilities, whereas interactive approaches require expertise but yield adaptable outcomes. Consequently, productivity is not determined solely by generation speed but by the total effort required for validation, correction, and integration into the development workflow.
For the examined microservice, AI therefore operates most effectively as a collaborative instrument. Developers remain responsible for judging oracle strength, ensuring independence and repeatability, and aligning generated tests with architectural intent and risk profiles. The role shift is from writing tests toward supervising, curating, and contextualizing machine-produced drafts. Broader benchmarks, repeated experiments, and productivity measurements are required to assess stability and economic impact.
In summary, AI presently improves throughput in the creation of candidate tests, yet accountability, adequacy, and release confidence remain human obligations. Autonomous quality assurance across microservice boundaries is not achievable with current technology.
Future progress will likely arise from more capable foundation models with improved context handling and from multi-agent decompositions that separate planning, generation, and verification. Greater transparency, standardization, and controllability will be necessary for AI-enhanced platforms to become governable in professional environments. However, rising expectations of automation pose organizational risks, as premature substitution of human review may reduce rather than increase defect detection capability. Even under optimistic assumptions, expert supervision will remain indispensable for accountable software quality assurance.
References
[1] “Ieee guide for software verification and validation plans,” IEEE Std 1059-1993, pp. 1–87, 1994.
Here are your references with the internal line breaks removed and the words correctly joined.
[2] A. Faraji and N. Pombo, “Ai-driven software test automation: An ai4se-oriented survey of techniques, tools, and challenges,” IEEE Access, vol. 13, pp. 183 296–183 313, 2025.
[3] M. Dawson, D. N. Burrell, E. Rahim, and S. Brewster, “Integrating software assurance into the software development life cycle (sdlc),” Journal of Information Systems Technology and Planning, vol. 3, no. 6, pp. 49–53, 2010.
[4] M. A. Jamil, M. Arif, N. S. A. Abubakar, and A. Ahmad, “Software testing techniques: A literature review,” in 2016 6th International Conference on Information and Communication Technology for The Muslim World (ICT4M), 2016, pp. 177–182.
[5] M. Addison-Wesley.; Cohn, Succeeding with agile: software development using Scrum, 7th ed., ser. A Mike Cohn Signature Book;The Addison-Wesley Signature Series. Addison-Wesley Professional, 2009;2013.
[6] M. Schäfer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,” IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2023.
[7] M. R. Woodward, “Mutation testing—its origin and evolution,” Information and Software Technology, vol. 35, no. 3, pp. 163–169, 1993.
[8] A. M. Dakhel, A. Nikanjam, V. Majdinasab, F. Khomh, and M. C. Desmarais, “Effective test generation using pre-trained large language models and mutation testing,” Information and Software Technology, vol. 171, no. C, p. 107468, 2024.
[9] S. Abhichandani, N. R. T. Vadrevu, and V. Bagmar, “Ai-driven self-healing in test automation: A review of autonomous quality assurance,” in 2025 3rd International Conference on Inventive Computing and Informatics (ICICI). IEEE, 2025, pp. 1601–1608.
[10] T. Brown et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
[11] P. Tonella, P. Avesani, and A. Susi, “Using the case-based ranking methodology for test case prioritization,” in 2006 22nd IEEE International Conference on Software Maintenance, 2006, pp. 123–133.
[12] H. Spieker, A. Gotlieb, D. Marijan, and M. Mossige, “Reinforcement learning for automatic test case prioritization and selection in continuous integration,” in Proceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2017. New York, NY, USA: Association for Computing Machinery, 2017, p. 12–22. [Online]. Available: https://doi.org/10.1145/3092703.3092709
[13] M. Zhang and A. Arcuri, “Adaptive hypermutation for search-based system test generation: A study on rest apis with evomaster,” ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 31, no. 1, pp. 1–52, 2021.
[14] A. Arcuri, “Evomaster: Evolutionary multi-context automated system test generation,” in 2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 2018, pp. 394–397.
[15] M. Waseem, P. Liang, G. Márquez, and A. Di Salle, “Testing microservices architecture-based applications: A systematic mapping study,” in 2020 27th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 2020, pp. 119–128.
[16] T. Miao, A. I. Shaafi, and E. Song, “Systematic mapping study of test generation for microservices: Approaches, challenges, and impact on system quality,” Electronics, vol. 14, no. 7, p. 1397, 2025.
[17] M. Almutawa, Q. Ghabrah, and M. Canini, “Towards llm-assisted system testing for microservices,” in 2024 IEEE 44th International Conference on Distributed Computing Systems Workshops (ICDCSW). IEEE, 2024, pp. 29–34.
[18] S. Susnjara and I. Smalley. (2025) What is software testing? IBM Think. Accessed: 2026-02-15. [Online]. Available: https://www.ibm.com/think/topics/software-testing
[19] Y. Du et al., “Context length alone hurts llm performance despite perfect retrieval,” in Findings of the Association for Computational Linguistics: EMNLP 2025. Association for Computational Linguistic, 2025, pp. 23 281–23 298.
[20] R. C. Martin, Clean code: a handbook of agile software craftsmanship, repr. ed., ser. Robert C. Martin series. Upper Saddle River, NJ Munich: Prentice Hall, 2012.
[21] MongoDB Inc. (2024) What is the farm stack? MongoDB Resources. Accessed: 2026-02-14. [Online]. Available: https://www.mongodb.com/resources/basics/farm-stack
[22] Stack Overflow, “2025 developer survey: Technology,” Online, Stack Overflow, 2025, accessed: 2026-02-14. [Online]. Available: https://survey.stackoverflow.co/2025/technology
[23] L. Twist, J. M. Zhang, M. Harman, D. Syme, J. Noppen, and D. Nauck, “Llms love python: A study of llms’ bias for programming languages and libraries,” arXiv preprint arXiv:2503.17181, 2025.
[24] Z. Yuan et al., “Evaluating and improving ChatGPT for unit test generation,” vol. 1, pp. 76:1703–76:1726. [Online]. Available: https://dl.acm.org/doi/10.1145/3660783
[25] A. Groce, M. A. Alipour, and R. Gopinath, “Coverage and its discontents,” in Proceedings of the 2014 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming & Software, ser. Onward! 2014. Association for Computing Machinery, pp. 255–268. [Online]. Available: https://dl.acm.org/doi/10.1145/2661136.2661157
[26] K. Jain, G. T. Kalburgi, C. L. Goues, and A. Groce, “Mind the gap: The difference between coverage and mutation score can guide testing efforts.” [Online]. Available: http://arxiv.org/abs/2309.02395
[27] B. Atıl et al., “Non-determinism of “deterministic” LLM system settings in hosted environments,” in Proceedings of the 5th Workshop on Evaluation and Comparison of NLP Systems, M. Akter, T. Chowdhury, S. Eger, C. Leiter, J. Opitz, and E. Çano, Eds. Mumbai, India: Association for Computational Linguistics, Dec. 2025, pp. 135–148. [Online]. Available: https://aclanthology.org/2025.eval4nlp-1.12/
Leave a Reply
You must be logged in to post a comment.