1. Einleitung
Im Rahmen der Vorlesung „Software Development for Cloud Computing“ haben wir uns als Gruppe dazu entschieden aufbauend auf teilweise bereits vorhandener Codebasis an einem Startup-Projekt weiterzuarbeiten. Der Hauptfokus lag bei uns auf dem Ausbau von DevOps-Aspekten und auf dem eines stabilen und sicheren Systems, welches auch in der Production-Environment eingesetzt werden kann. Bei einem umfangreichen Projekt wie diesem spielen natürlich auch Überlegungen zu Skalierbarkeit und Kosten eine recht große Rolle. Punkte und Ziele wie diese werden wir später im Beitrag noch genauer betrachten.
2. Über das Projekt
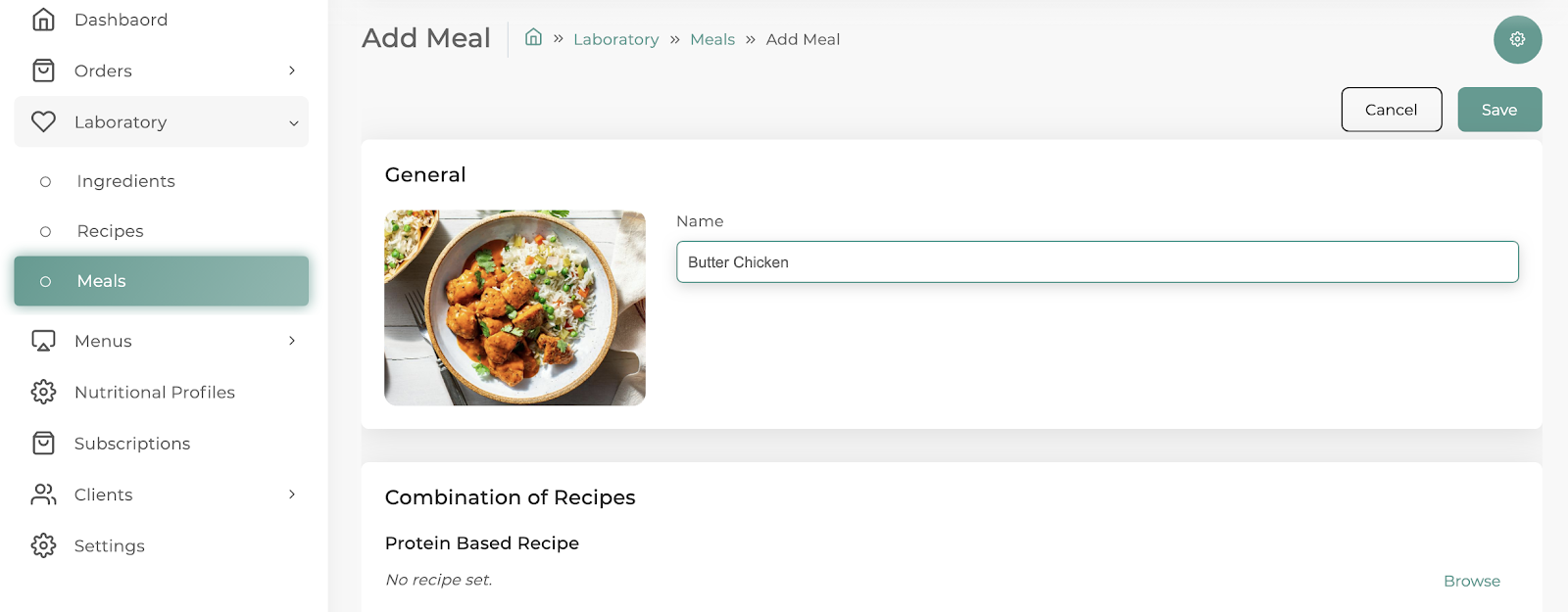
Im Rahmen einer Startup-Idee war es das Ziel, eine Art Admin-Panel zu erstellen, auf dem Restaurants u. a. ihre wöchentlich wechselnden Gerichte eintragen und managen können. Dabei werden dann automatisch Nährwertangaben, rechtliche Kennzeichnungen wie Allergene und weitere Informationen über Nahrungsmittel hinzugefügt und verwaltet. Später sollen Kunden automatisch ein Menü, das speziell auf ihren Ernährungsplan angepasst ist, erstellt bekommen. Das gesunde und auf sie abgestimmte Essen bekommen die Kunden dann frisch geliefert.
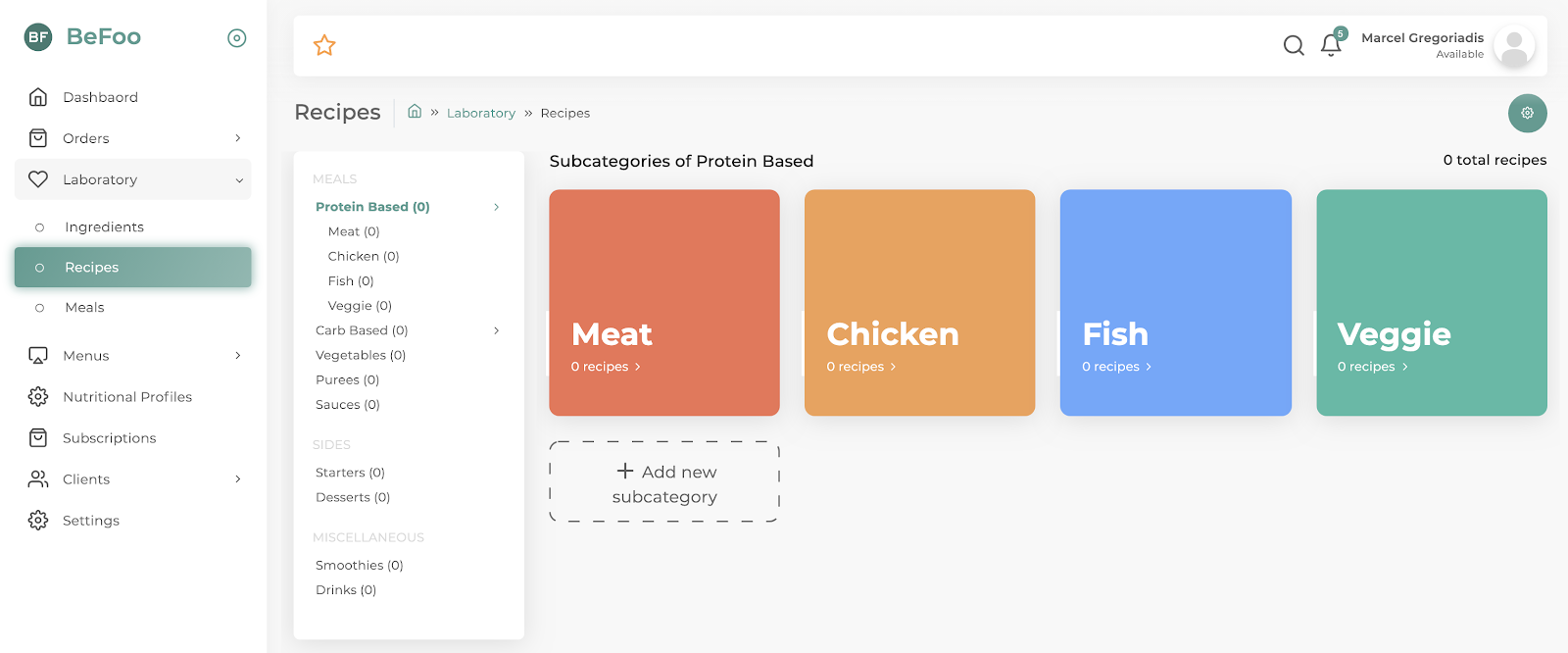
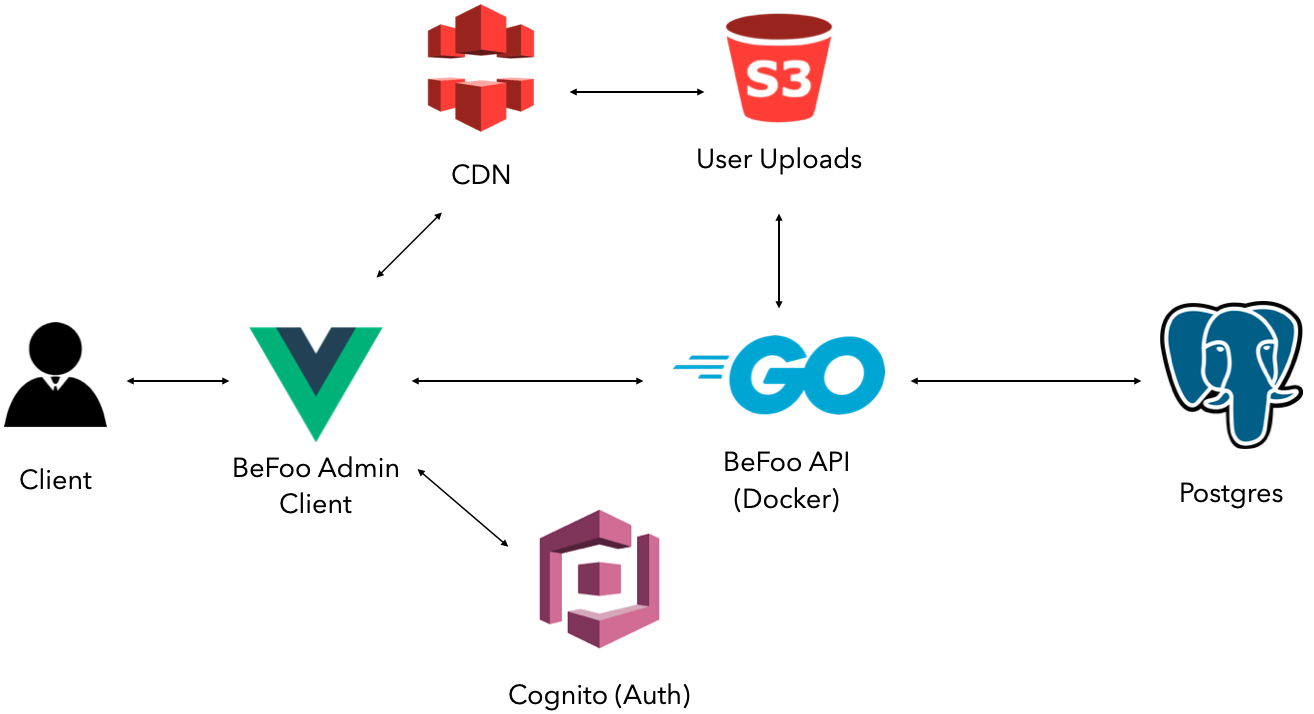
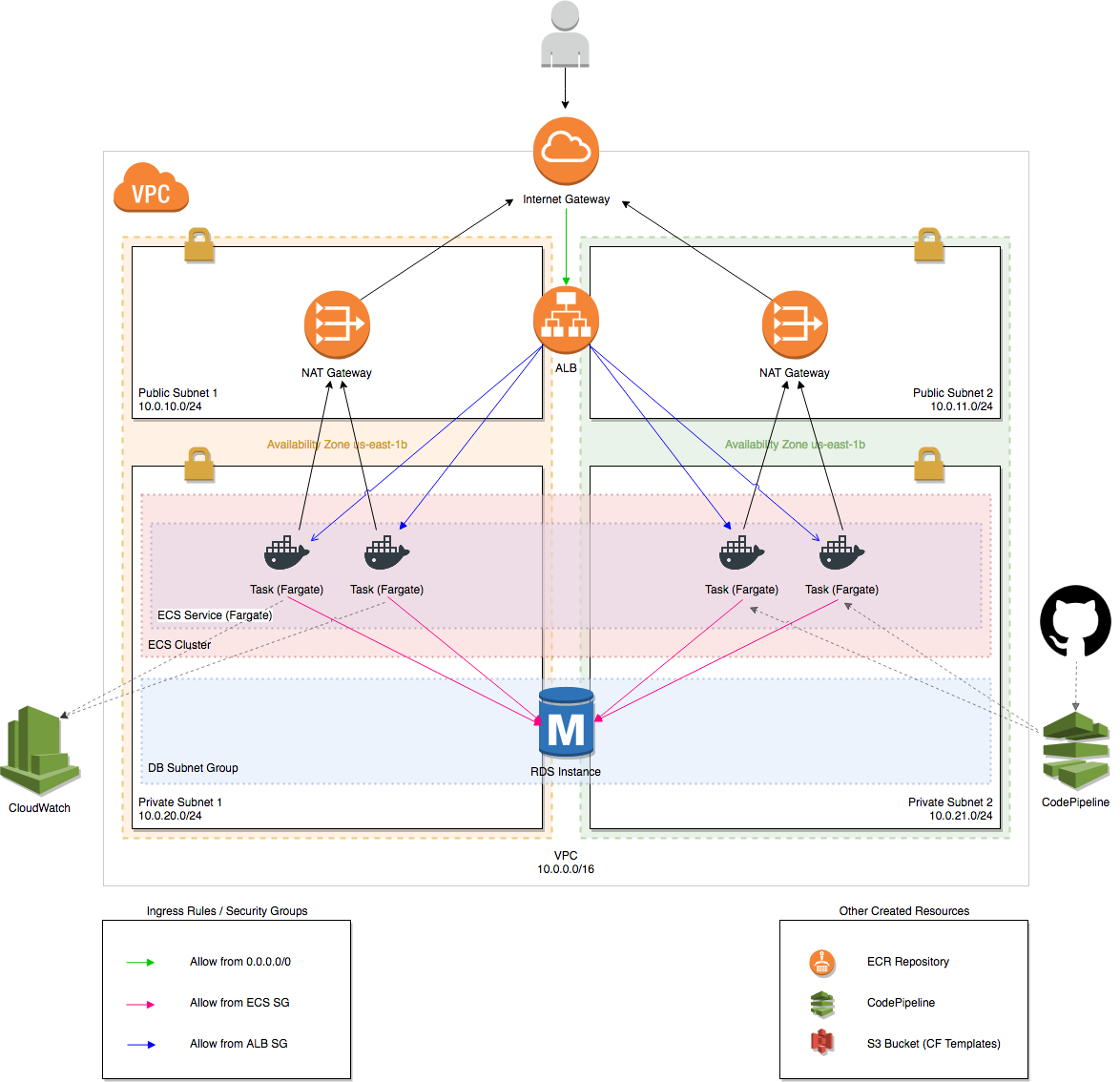
Das Admin-Panel wurde als SPA mit Vue.js im Frontend und mit einer GraphQL-API auf Basis von Go realisiert. Für die Speicherung von Daten nutzen wir PostgreSQL. Darüber hinaus verwenden wir Services von AWS zur Authentifizierung von Benutzern und für die Ablage von User-Uploads. Die folgende Grafik zeigt eine vereinfachte Darstellung der einzelnen Services und Beziehungen untereinander.
3. Cloud-Architektur
In diesem Kapitel erklären wir, mit welchen AWS Services wir die grundlegende Architektur der Applikation in die Cloud gebracht haben. Wir haben uns für AWS als Cloud-Anbieter entschieden, da es den mit Abstand größten Marktanteil genießt und einer der ganz ersten Anbieter von Cloud-Computing-Diensten war. Diese Attribute bringen mit sich, dass für AWS die meisten Ressourcen online oder als Literatur zur Verfügung stehen. Dadurch versprachen wir uns einen leichteren Einstieg in das Themengebiet. Zudem hat AWS die größte und global verteilteste Infrastruktur. Auch das Angebot an Cloud-Diensten ist bei AWS mit Abstand mit größten und darüber hinaus noch sehr diversifiziert, wodurch wir in dieser Ökosphäre alles finden würden, was wir jemals brauchten. Vergleichbare Dienste anderer Cloud-Anbieter sind oft auch nicht so ausgereift und entwickelt wie bei AWS.
Die gesamte Cloud-Architektur haben wir dabei mit Terraform bereitgestellt. Terraform ermöglicht das Provisionieren von Ressourcen in der Cloud in einer Templating-Syntax. Dies wird gemeinhin als Infrastructure as Code (IaC) bezeichnet. Die Vorteile sind vielseitig:
- Die Übersicht der Ressourcen bleibt erhalten und geht nicht im Wirrwarr der AWS Konsole verloren.
- Die Infrastruktur kann wie Programmcode versioniert werden und bringt damit die üblichen Vorteile eines Versionskontrollsystems mit sich.
- Ressourcen können über das Terraform CLI hochgefahren und wieder heruntergefahren werden und machen die Übertragung auf andere Cloud-Accounts damit sehr einfach.
- Die Abstrahierung von Terraform Code in Modulen und verschiedene syntaktische Hilfsmittel erlaubten es uns eine Unterteilung zwischen der Development-, Staging- und Production-Umgebung komfortabel zu pflegen.
Der folgende Code zeigt die Datei main.tf für unsere Staging-Umgebung. Von hier aus steuern wir über selbst erstellte Terraform-Module die Provisionierung unserer benötigten Services an. Die Abstraktion in Module macht es uns möglich, diese Konfigurationen für jede Umgebung separat vorzunehmen und dabei nicht unnötig Code zu wiederholen.
3.1 Frontend (Client)
Beim Frontend handelt es sich um ein kompiliertes Vue.js-Projekt, also um nicht mehr als statische Dateien. Das Vorgehen bei der Bereitstellung in der AWS Cloud ist daher sehr einfach und direkt: Statische Dateien werden in ein öffentliches S3-Bucket hochgeladen. Das allein reicht sogar schon um eine Webseite zu betreiben. Es ist aber sehr empfehlenswert einen CDN-Dienst davor zu schalten, im Fall von AWS: CloudFront.
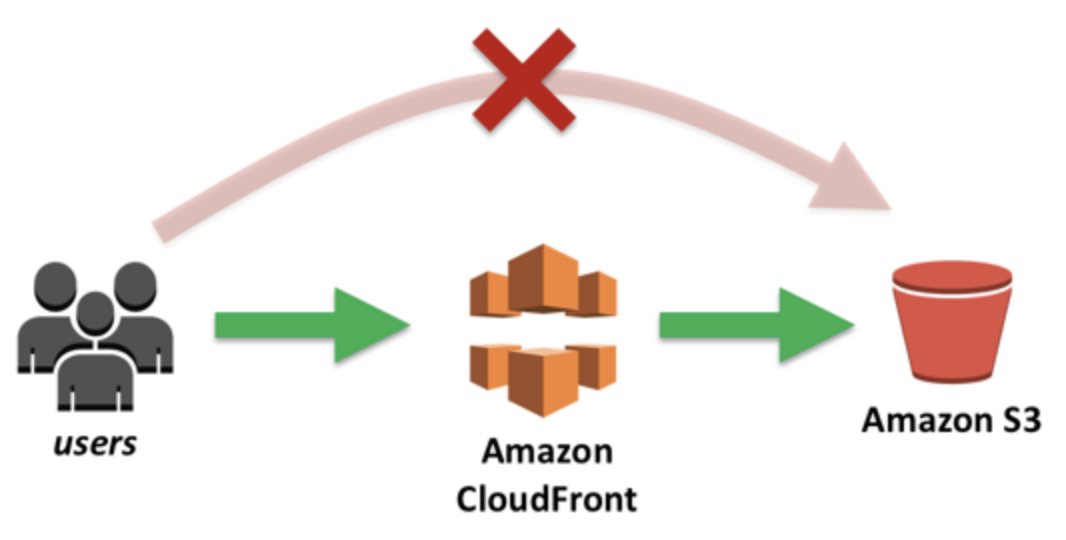
CloudFront dient zum Erreichen gecachter statischer Dateien und verfügt über ein global verteiltes Netzwerk an Servern. Das bedeutet, dass sich die Latenz verringert, da das Frontend vom nächstgelegensten CloudFront-Standort geholt wird, anstatt vom Standort des S3-Buckets. Außerdem kümmert sich CloudFront für uns um SSL, DDoS Protection und mehr.
3.2 Backend (API & Datenbank)
Die Wahl des Cloud-Stacks für das Backend einer Webanwendung ist sehr viel komplizierter als für das Frontend. Die Auswahl geht von EC2-Instanzen über Kubernetes, Elastic Beanstalk bis hin zu Serverless-Funktionen.
3.2.1 Der richtige Service für das API
Die Frage hin zum Serverless-Stack sollte man sich am Anfang der Programmierung stellen. Lambda-Funktionen bieten viele Vorteile, vor allem in Hinsicht auf Kosten, zudem große Sicherheit im Hinblick auf Skalierung. Wir entschieden uns dagegen. Ein Grund dafür war, dass wir für eine Admin-API keine unerwartet hohen, sondern eher konstant bleibende Anfragen erwarteten. Der Hauptgrund war aber wahrscheinlich die unzureichend entwickelte Ökosphäre rund um Entwicklertools für ein zunehmend komplexes Software-Projekt.
EC2-Instanzen, welche im Grunde nur virtuelle Maschinen sind, schienen uns nicht spezialisiert genug für einen Service, der einfach nur unsere Docker-Images ausführen soll und außerdem noch zu mächtig. Diese Option schied also direkt aus.
AWS selber bewirbt Elastic Beanstalk (EB) sehr stark als Wahl zur Bereitstellung von Webanwendungen. Wir können technisch nicht genau argumentieren, warum wir uns gegen diese Lösung entschieden haben. Allerdings sind wir bei unserer Recherche auf sehr viel Kritik gegenüber diesen Dienst gestoßen. Professionelle DevOps-Engineers rateten immer gegen EB und stattdessen zu einem Container-Service.
Hierbei bieten sich zwei Optionen: Der Industrie-Standard Kubernetes und der kleine Bruder, speziell von AWS entwickelte Elastic Container Service (ECS). Keiner von uns hatte viel Erfahrung mit Kubernetes, wir hörten nur, es sei mächtiger und flexibler in der Konfiguration, dafür aber auch teurer. Nichts davon könnten wir gebrauchen. Der ECS macht dafür genau das, was wir wollen: Er betreibt Instanzen unseres API-Images, kann dies verbunden mit einem Load Balancer horizontal skalieren und ist sogar mit Auto-Scaling-Policies verknüpfbar.
3.2.2 Datenbank
Zum Betreiben unserer Postgres-Datenbank nutzen wir einen eigenen spezialisierten Service, was auch sehr zu empfehlen ist. Im Falle von AWS ist das der Relational Database Service (RDS), zumindest für relationale Datenbanken. Die Hardware ist speziell für Datenbankzugriffe abgerichtet, System-Updates und Backup-Automatisierungen sind mit inbegriffen. Auch Aspekte wie Skalierung und Ausfallsicherheit (hohe Verfügbarkeit durch Replikas) können mit diesem Dienst einfach realisiert werden.
RDS bietet mit Aurora auch einen speziellen Typ Engine an, der die Autoskalierung von Datenbanken ermöglicht. Das Angebot ist recht neu und definitiv sehr interessant. Es soll außerdem eine höhere Performance (3x schneller bei Postgres-Datenbanken) bieten. Wir haben uns dagegen entschieden bzw. noch nicht dafür entschieden, aus zwei Gründen:
- RDS Aurora ist schon in der Basis-Skalierung deutlich teurer als eine einfache RDS-Instanz.
- Bislang unterstützt Aurora Postgres nur in der Version 10 und wir würden die Features verlieren, die sich uns mit Postgres 12 bieten.
3.2.3 VPC
Aus Sicherheitsgründen wollen wir die Datenbank nicht ans Internet anschließen. Sie soll nur von unseren API-Diensten erreichbar sein. Das bedeutet, wir müssen uns eine VPC einrichten, eine Virtual Private Cloud.
Die VPC besteht zum einen aus einem Private Subnet, hierin lebt unser ECS und unsere Datenbank, und zum anderen aus einem Public Subnet, hier ermöglicht ein NAT Gateway die Verbindung nach außen. Eine harte Bedingung des ganzen ist die Distribution auf mindestens zwei Availability Zones, darum sind es, um genau zu sein, jeweils zwei Private Subnets, Public Subnets und NAT Gateways.
Quelle: https://user-images.githubusercontent.com/884507/34551896-a3a838a6-f0d2-11e7-8858-c4de887fb225.png
3.4 User Uploads CDN
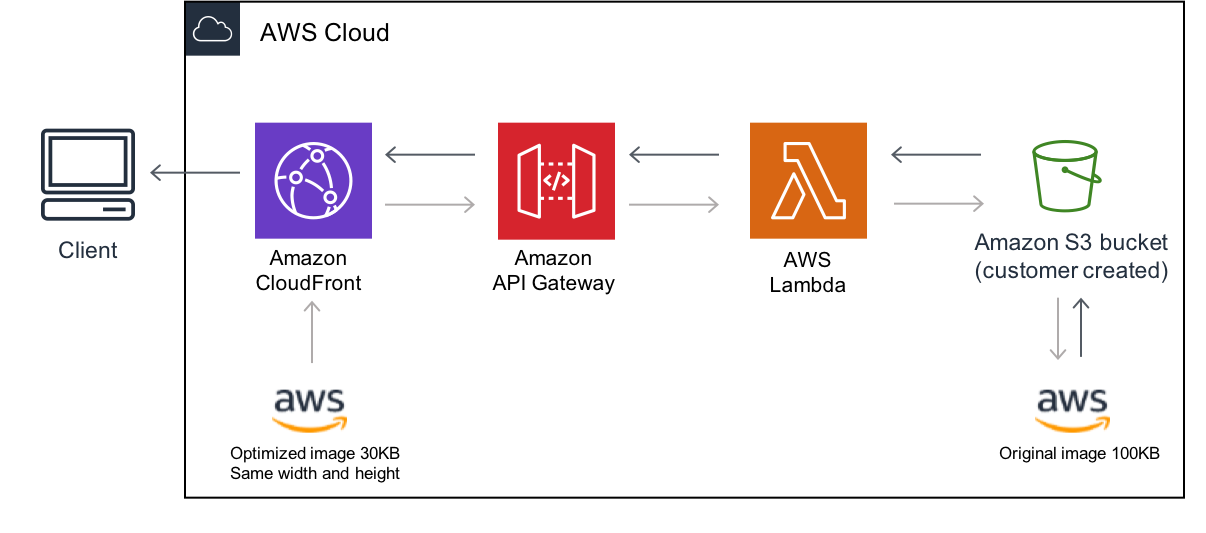
Eine Sub-Architektur in unserer Infrastruktur will noch getrennt betrachtet werden. Die Rede ist vom sogenannten “Serverless-Image-Handler”, hierüber wickeln wir ab, wie von Benutzern hochgeladene Bilddateien aufgerufen werden.
Wenn Benutzer eigene Bilder hochladen, geht die Anfrage über unsere API und wird dann in einen S3-Bucket abgelegt. Diese Bilder werden an verschiedenen Stellen aufgerufen, z.B. in der Detail- und Listenansicht von Rezepten. Da die Bilder von Benutzern hochgeladen werden, ist die Bild- und Dateigröße variabel und auch nicht optimiert. Bei der Listenansicht ist uns dann aufgefallen, das wir ja 15 Bilder gleichzeitig laden und sie eigentlich nur in eine Größe von 80×60 Pixeln für das Thumbnail benötigen. Also potenziell mehrere Megabyte an Datentraffic nur zum Laden der Listenansicht.
Bei der Suche nach einer Lösung sind wir dann relativ schnell auf den “Serverless-Image-Handler” gestoßen, eine Komplettlösung von AWS in Form eines CloudFormation-Stacks.
Diese Lösung involviert einen CloudFront-Endpunkt, einen API Gateway, eine Lambda-Funktion und natürlich das S3-Bucket, in dem die Bilddateien abgelegt sind. Es funktioniert dabei wie folgt: Das Bild wird von dem CloudFront-Endpunkt angefragt. Die Anfrage beinhaltet den Namen des S3-Objekts und die gewünschte Skalierung. CloudFront leitet die Anfrage an das API Gateway, welches eine Lambda triggert. In dieser Lambda wird das Objekt aus dem S3-Bucket geholt, skaliert und komprimiert. Schließlich wird die optimierte Bilddatei an den Client zurückübermittelt. Von nun an befindet sie sich außerdem im CloudFront-Cache und kann bei der nächsten Anfrage sogar deutlich schneller abgerufen werden.
Quelle: https://aws.amazon.com/de/solutions/implementations/serverless-image-handler/
4. CI/CD
Der Aufbau einer CI/CD-Pipeline ist meist recht komplex und herausfordernd. Hier kann man nur raten, wie man es aufbauen soll, damit es von Anfang an solide und “langlebig” ist. Man muss dabei auch im Hinterkopf behalten und sich genau überlegen, wie alles zusammenspielen soll, wenn später mit mehreren Leuten zusammengearbeitet werden soll. Prinzipiell gibt es nicht die eine richtige Lösung für eine CI/CD, denn die Anforderungen daran sind auch vom jeweiligen Projekt abhängig. Selbstverständlich bietet ein Versionskontrollsystem wie bspw. Git oder SVN in erster Linie die Basis für eine CI/CD-Pipeline. Bei unserer Pipeline war es uns zum einen wichtig, vorprogrammierte Tests ausführen zu können (CI) und zum anderen, das Deployment auf unsere Staging-Environment, als auch auf unsere Production-Environment zu automatisieren (CD).
Bevor man sich mit dem Thema auseinandersetzt, sollte man überlegen, was man für das Projekt braucht, um beispielsweise Tests ausführen zu können. In unserem Fall nutzen unsere Integration-Tests eine eigene Datenbank.
Zum automatisierten Testen sollte man dabei möglichst Production-nahe Bedingungen herstellen, da sich sonst anstrengende Bugs einschleichen können, die man erst in Production bemerkt, obwohl die eigene Test-Suite diesen Fall schon abgedeckt hätte. Diese Fehler zu finden ist dann sehr mühsam, da man normalerweise davon ausgeht, dass etwas, was erfolgreich getestet wurde, auch funktioniert. Man möchte also die Umgebung (Betriebssystem, Abhängigkeiten, Konfiguration, …) identisch halten.
Für das Testing in unserer CI-Pipeline nutzen wir daher Docker und Docker-Compose. Dies ermöglicht uns, das Testing auf dem Image des Projekts auszuführen, anstatt in der Laufzeitumgebung des CI-Runners. Die Vorteile der Konsistenz tauscht man hier gegen höhere Kosten und Wartezeit beim Ausführen der CI.
Der CD-Teil unserer CI, also das Continuous Deployment, wird bei uns im Anschluss auf das Testing für Commits im develop- und master-Branch ausgeführt. Das Docker Image wird hier entsprechend getaggt und in die Registry von AWS hochgeladen. Abschließend wird mithilfe der AWS CLI der ECS Cluster neu gestartet, wodurch das neue Image Anwendung findet. Bei unserem Vue.js-Projekt werden die kompilierten Dateien wiederum nur mit dem S3-Bucket synchronisiert und der CloudFront Cache invalidiert, um CD zu realisieren.
Alles ist so darauf eingerichtet, dass unsere Staging-Umgebung dem Stand des Branches develop entspricht und unsere Production-Umgebung dem von master.
Im Folgenden zum Zwecke der Veranschaulichung, seht ihr die CircleCI-Konfiguration für unser API-Repository. Wir haben auch jeweils weitere Pipelines konfiguriert für unser Cloud-Repository (bestehend aus TerraForm Dateien) und dem Repository, welches unser Vue.js-Frontend enthält.
Wir haben uns u.a. aufgrund positiver persönlicher Erfahrungen für CircleCI entschieden. Dieser Dienst verfügt über eine hervorragende Dokumentation und Support. Des Weiteren ist er sehr mächtig in seiner Konfiguration. Bevor wir CircleCI nutzten, versuchten wir eine CI mit GitHub Actions aufzubauen. Der Dienst war zu dem Zeitpunkt noch sehr neu bzw. ist es immer noch. Wir hatten große Probleme bei der Einrichtung einer CI mit Docker-Compose und eine generell schlechte Erfahrung gemacht. Das einzige Problem bei CircleCI, welches uns erst im späteren Verlauf bewusst wurde, ist dass es sehr kostspielig ist, und das auch im Vergleich mit ähnlich starken CI-Diensten. In der Zukunft wollen wir eventuell auf GitLab CI wechseln und würden uns dabei auch überlegen, den CI-Runner selbst auf der AWS-Plattform zu hosten.
5. Weitere Services
Die AWS Cloud bietet noch eine Vielzahl weiterer Services, u.a. auf der Ebene von Software-as-a-Service (SaaS), aus der wir uns bedienen.
Für die Authentifizierung von Admins bzw. Mitarbeitern und Kunden verwenden wir Cognito User-Pools. Cognito ist die AWS Komplettlösung für Authentifizierung. Hierüber können auch Verifikationsmails, 2FA-Verfahren, Passwort-vergessen-Dialoge und mehr konfiguriert werden. Den E-Mailversand von Cognito haben wir bspw. mit einem weiteren Service von AWS verbunden: Simple Email Service (SES).
Ein weiterer wichtiger AWS Service, den wir nutzen, ist Route 53. Hierüber setzen wir unsere DNS-Regeln und richten uns Subdomains für diverse CloudFront-Endpunkte und das API Backend ein.
Wir verwenden außerdem noch die Amazon Translate API zum Internationalisieren von Texten auf der Webseite und Lambda-Funktionen als Verbindungsstück zwischen verschiedenen AWS Services.
6. Fazit
Wir haben in diesem Projekt natürlich sehr viel gelernt. Cloud-Computing, die AWS Cloud oder der Ansatz von Infrastructure as Code waren für uns alle vor diesem Projekt Neuland. Dementsprechend mussten wir uns in sehr viele Themen einarbeiten und das Projekt hat sich über die Zeit auch immer wieder gewandelt. Heute sind wir aber sehr zufrieden mit unseren Entscheidungen über Infrastruktur und vor allem über unsere DevOps-Prozesse und die Integrationen zu Team Software, wie Jira oder Slack, die die Entwicklung sehr viel angenehmer gestalten.
Was die eigentliche Infrastruktur angeht, denken wir, werden wir nochmal besser darüber reflektieren können, wenn die Anwendung tatsächlich in Production geht. Dann sehen wir uns bestimmt nochmal verschärft mit anderen Themen, wie Logging und Monitoring, konfrontiert.
Letztendlich möchten wir euch dazu motivieren, euch auch intensiver mit dem Thema Cloud & DevOps zu beschäftigen. Es hat uns sehr viel Zeit und Anstrengung gekostet, die Konzepte von Cloud-Computing zu verstehen und uns bei den vielen Services zurechtzufinden. Mittlerweile fühlen wir uns in dieser Welt aber sehr wohl. Mit dem angehäuften Wissen sehen wir uns in der Lage skalierbare Anwendungen auf Enterprise-Niveau zu veröffentlichen und zu verwalten. Auch die viele Arbeit, die wir in unsere DevOps-Strategie gesteckt haben, macht sich in der Entwicklung bezahlt und hilft uns, nachhaltig gute und zuverlässige Software zu schreiben.
Von Marcel Gregoriadis, Julian Fritzmann, Sandro Schaier & Jan Groenhoff.
Leave a Reply
You must be logged in to post a comment.