Worum geht’s?
Im Rahmen der Veranstaltung “System Engineering and Management” sollte ein Softwareprojekt unserer Wahl und mit besonderem Augenmerk auf Systemarchitektur durchgeführt, analysiert und dokumentiert werden. Für unser Projekt haben wir uns entschieden, einen besonderen Schwerpunkt auf Monitoring zu legen. Das Projekt bestand also aus drei größeren Teilprojekten: dem Backend selbst, ein Stresser, der Last für das Backend erzeugt und das zugehörige Monitoring. Im Folgenden möchten wir das Ergebnis dieses Semesters aber vor allem auch den Weg dahin beschreiben.
Hoch hinaus…
Bevor wir uns über die Architektur Gedanken machen konnten, musste zuerst einmal eine Anwendungsidee her. Wir haben uns hier für eine Elevation API entschieden. Aber was ist denn eine Elevation API? Eine Elevation API ist eine API, die einem zu einem durch Längen- und Breitengrad definierten Punk der Erdoberfläche die Höhe des entsprechenden Punkts über normal Null ausgibt. (Z.B. hat der Punkt mit den Koordinaten 48.742275° Nord, 9.101177° Ost (Haupteingang der HdM) die Höhe 459 m. Derartige Höheninformationen werden für viele Anwendungen benötigt. Man kann sich die Höhe eines Punktes auch einfach in Google Earth anzeigen lassen, indem man mit der Maus über einen Punkt fährt. Die Höhe wird dann unten rechts angezeigt.

Wie kamen wir also nun auf die Idee, unsere eigene Elevation API zu entwickeln? Nun, wenn man mit Google Earth arbeitet, bekommt man hier recht schnell ein Problem. Denn während man sich die Höheninformationen in Google Earth selbst problemlos anzeigen lassen kann, werden sie nicht exportiert. Das heißt, wenn man z.B. einen Pfad in Google Earth definiert und dann für die weitere Verwendung in einer anderen Anwendung exportiert, werden alle Punkte mit der Höhe 0m ausgegeben (Gleichzeitig bietet Google eine eigene [kostenpflichtige] Elevation API an. Ein Schelm, wer böses dabei denkt…🙂). Wer also Höheninformationen für seine Anwendung braucht, muss sich diese auf anderem Wege beschaffen. Dafür kann man z.B. auf kostenlose Elevation APIs wie OpenTopoData zurückgreifen. Dieses Konzept hatte uns also neugierig gemacht, sodass wir uns an die Entwicklung unserer eigenen Elevation API gemacht haben…
Das Backend
Die Plattform
Nachdem die Idee für eine Anwendung nun feststand, war die erste größere technische Entscheidung, welche Plattform wir für das Backend benutzen wollten. Hier haben wir uns recht schnell für ASP.NET Core und C# entschieden, da wir bereits Erfahrung mit C# (und teilweise auch mit ASP.NET Core) hatten. Hier spielte also eher Bequemlichkeit, als technische Aspekte eine Rolle. Ein Fehler, der uns später an einer Stelle noch gehörig Kopfschmerzen bereiten sollte. Fürs Erste entwickelten wir aber munter darauf los…
An dieser Stelle machten wir uns zu Nutze, dass Visual Studio (unsere IDE) bereits Vorlagen für Konfigurationen enthält, um die Anwendung in einem Docker Container zu hosten. Wir mussten also nur die entsprechende Vorlage bei der Projekterstellung auswählen und Visual Studio erledigte den Rest (erzeugt z.B. das Dockerfile). Es gibt hier sogar die Möglichkeit, bei jedem App-Start auszuwählen, ob man die Anwendung im Container oder doch lieber nativ auf dem Host ausführen will. Mehr Flexibilität kann man sich also nicht wünschen. Allerdings hat das, wie so oft, wenn einem die IDE Arbeit abnimmt, auch den Nachteil, dass man, wenn man mit der Materie (in diesem Fall Docker) noch nicht so vertraut ist, nicht unbedingt alles versteht, was das unter der Haube passiert, sodass man dann, wenn man etwas konfigurieren möchte, erst Nachforschungen anstellen muss, wie das funktioniert. Das ist zwar heutzutage (aufgrund von stackoverflow.com und co.) recht einfach. Dennoch sollte man sich idealerweise, bevor man mit solchen Presets arbeitet, grundlegend in die Materie einarbeiten, um die eigene Anwendung nachher besser zu verstehen und Zeit bei der Entwicklung zu sparen.
Eine gewöhnliche REST-API
Die grundsätzliche Struktur des Backends ist recht simpel. Ein einfacher Web-Server (ASP-NET Core verwendet Kestrel) mit einem Endpunkt zur Abfrage von Höhendaten. Der Endpunkt unterstützt sowohl GET-Requests, in welchen die Koordinaten in der URL stehen, also auch POST-Requests mit den Koordinaten im Body (JSON-Format). Dabei können auch mehrere Koordinaten gleichzeitig angefragt werden.
Beispiele für Anfragen:
GET: http://localhost:8080/api/elevation?coordinates=48.00,9.00;-12.34,-23.45
POST: localhost:8080/api/elevation
[Body]
[
{
"latitude": 48,
"longitude": 9
},
{
"latitude": 49.1,
"longitude": 10.2
}
]Als Ergebnis bekommt man (sowohl für GET-, als auch für POST-Reqests) im Erfolgsfall eine Antwort in der Form:
[
{
"latitude": 48,
"longitude": 9,
"altitude": 739.7893850836467
},
{
"latitude": 49.1,
"longitude": 10.2,
"altitude": 492.73202840246756
}
]Im Fehlerfall wird ein entsprechender HTTP Statuscode zurückgegeben.
Für die Bearbeitung einer Anfrage werden auf dem Server grob zusammengefasst zwei wichtige Schritte ausgeführt. Zunächst wird die Anfrage eingelesen und in Koordinatenpunkte umgewandelt. Sollte dabei ein Fehler auftraten (z.B. wegen eine ungültigen Anfrage [z.B. ein Buchstabe in einer Koordinate] oder falsche Formatierung]) wird direkt ein Fehler zurückgegeben. Diese Prüfung geschieht der Einfachheit halber (in unserer kleinen Anwendung) direkt im Elevation Controller (Controller sind in ASP.NET Core die Komponenten, die die HTTP-Anfragen erhalten und für das Senden der Antwort zuständig sind.) Ist die Umwandlung erfolgreich, werden zu den Koordinatenpunkten die Höheninformationen ermittelt. Sobald das geschehen ist, wird die Antwort gesendet.
Der Kern des Ganzen: die Höhendaten und ihre Verarbeitung
Das Datenset
Um die Höheninformationen für eine Koordinate zu gewinnen, brauchten wir zunächst die Rohdaten. Also Dateien, in welchen die Höhendaten für einen bestimmten Bereich gespeichert waren. Für solche Daten gibt es mehrerer Quellen (u.a. von der NASA). Wir entschieden uns für den EU-DEM v1.1-Datensatz von Copernicus. Copernicus bietet als europäisches Projekt Daten in besonders hoher Auflösung (25 m x 25 m, d. h. alle 25 Meter ein Messpunkt) für den Bereich Europa.
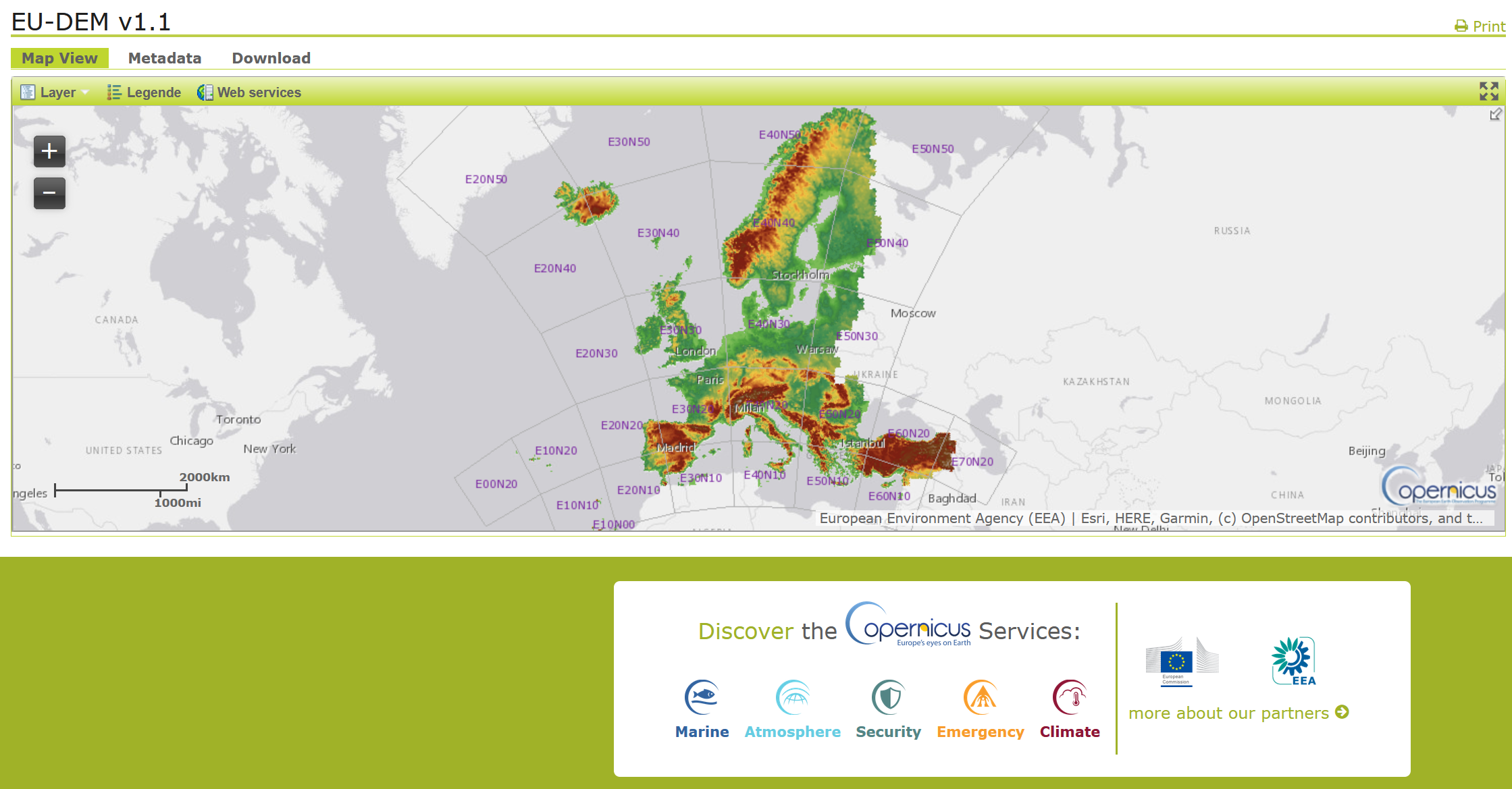
Die Daten wurden in Form von GeoTIFFs bereitgestellt. Das sind spezielle TIFF-Bilddateien, die die Höhendaten in den Pixeln enthalten und zusätzlich bestimmte zusätzliche Informationen wie z.B. das verwendete Koordinaten-Projektionssystem in den Metadaten. Wir haben also die Daten für den Bereich Deutschland heruntergeladen. Da diese Daten recht groß sind (ca. 8,3 GB nur für Deutschland), haben wir uns entschieden, uns für dieses Projekt auf Deutschland zu beschränken. (ACHTUNG: Das bedeutet, dass Anfragen für Koordinaten außerhalb Deutschlands (bzw. der Koordinatenblöcke im Datensatz, welche Deutschland enthalten [E40N20 & E40N30 -> siehe Karte]) nicht funktionieren.)
GDAL…der Troublemaker
Als nächsten, mussten wir den Zugriff auf die Höhendaten implementieren. Um die verschiedenen GeoTIFF-Dateien zu einem Raster zusammenzufügen und aus diesem, Höheninformationen abzufragen, entschieden wir uns, die bekannte Bibliothek GDAL zu verwenden.

Bis hierher verlief die Entwicklung des Backends relativ flüssig. Hier aber fiel uns jetzt die Wahl der Plattform auf die Füße. GDAL ist für derartige Raster-Aufgaben, wie wir sie in unserer Anwendung brauchten, wie geschaffen und auch weit verbreitet. Allerdings handelt es sich bei GDAL um eine Python-Bibliothek. Die direkte Einbindung in unsere Anwendung war also nicht möglich. Wir brauchten also einen .NET Core Port von GDAL. Wir entschieden uns für das Paket MaxRev.Gdal.Core.
Die Implementierung der nächsten ca. 20 Zeilen Code dauerte einige Stunden.
Im Grunde war das, was wir zu erreichen versuchten, nicht sehr kompliziert. Wir wollten – wie gesagt – die GeoTIFF-Daten in ein Raster zusammenfügen und Höheninformationen daraus abfragen. Das lässt sich mit GDAL in etwa 20 Zeilen Code realisieren. ABER: da wir nicht GDAL direkt, sondern einen Port verwendeten, wich die Klassen- und Methodennamen oft von der (dokumentierten) Originalversion von GDAL ab. Und da der von uns verwendete (aber auch alle anderen) GDAL-Port nicht sehr weit verbreitet ist, gab es auch kaum Hilfestellungen dazu im Internet (z.B. Foreneinträge). Erschwerend kam noch dazu, dass solche Ports oft unvollständig sind und einige Funktionalitäten des Originals nicht implementiert sind, was für noch mehr Verwirrung und Unsicherheit sorgte. Wir mussten uns also jede Zeile Code durch Probieren und aufwändige Internetrecherche hart erarbeiten. Wir haben sogar andere GDAL-Ports ausprobiert, die aber alle noch schlechter funktionierten.
Am Ende waren wir froh, dass wir funktionierenden Code zusammenbekommen hatten, der unsere Aufgabe erfüllte. Würden wir unsere Anwendung jetzt allerdings erweitern und neue Funktionalität implementieren wollen, stünden wir wieder vor dem gleichen Problem.
Koordinate ist nicht gleich Koordinate
Ein weiteres Hindernis, das es zu bewältigen gab, war, dass der EU-DEM v1.1-Datensatz ein anderes Projektionssystem (ETRS89 / LAEA Europe), als das gewöhnliche Längen-/Breitengrassystem (WGS 84) verwendet. Wir mussten also erst einen Weg finden, die vom Benutzer angefragten Koordinaten in Längen- und Breitengrad in Koordinaten im ETRS89 / LAEA Europe-System umzuwandeln. Auch hier hatten wir es wieder mit der selben Problematik wie bei GDAL zu tun. Es gab zwar einige Anleitungen im Internet, wie diese Koordinatenumrechnung zu bewerkstelligen war, jedoch bezog sich keine davon auf .NET Core und C#. Auch hier mussten wir uns am Ende wieder auf eine kleine Drittanbieter-Bibliothek (DotSpatial.Projections) verlassen, wobei Dokumentation und Communityinhalte hier ebenso dürftig waren, wie bei GDAL, sodass auch die Implementierung dieses Codes deutlich mehr Zeit in Anspruch nahm, als uns das lieb gewesen wäre.
Enbindung der Daten in den Container
Am Ende war es jedoch soweit, und wir hatten unsere funktionierende Anwendung. Jetzt mussten wir nur noch einen Weg finden, die Höhendaten (in Form der zwei GeoTIFF-Dateien und einer (von GDAL) generierten VRT-Rasteratei) in unserem Container zur Verfügung zu stellen. Eine Möglichkeit wäre gewesen, die Dateien einfach in das Docker-Image zu packen. Da die Dateien aber, wie gesagt, mehrere GB groß waren, hätte das das Image unnötig aufgeblasen und unhandlich gemacht. Stattdessen entschieden wir uns, die Dateien auf dem Host zu speichern und den entsprechenden Ordner im Container zu mounten. Dies kann durch Angabe eines Parameters beim Start des Docker-Containers bewerkstelligt werden:
docker run <strong>--volume D:/elevation/data:/app/data:ro</strong>Dieser Parameter stellt den Ordner “D:/elevation/data” (hier beispielhaft der Ordner auf dem Host mit unseren Daten) im Container unter “/app/data” zur Verfügung. Da wir aber in aller Regel den Container nicht selbst starteten, sondern, die IDE das für uns erledigt, mussten wir den Parameter noch in der .csproj-Datei des Projekts mit
<DockerfileRunArguments>-v "D:/elevation/data:/app/data:ro"</DockerfileRunArguments>festlegen.
ACHTUNG: Aufgrund der Dateigröße, sind die GeoTIFF-Dateien nicht im Repository enthalten und müssen manuell heruntergeladen werden. Danach muss der Pfad zu den Dateien im Projekt angepasst werden, um es erfolgreich ausführen zu können. Eine genauere Anleitung hierzu findet sich in der README-Datei im Repository des Backends.
Backend-Unit Tests
Abschließend war das Backend noch zu testen. Dazu implementierten wir noch einige Unit Tests, sowohl für den Controller (hier wurde vor allem getestet, dass der Controller bei fehlerhaften Anfragen, entsprechende Fehlercodes zurückgab), als auch für das Datenset (korrekte Höhendatenabfrage). Letzteres erwies sich aufgrund der Plattformproblematik erneut als zäher als gedacht. Um den GDAL-Port bei der Programmausführung zu initialisieren muss der Befehl
GdalBase.ConfigureAll();einmal ausgeführt werden. Dieser Befehl steht in unserer Anwendung in der Startup.cs-Datei, welche beim Anwendungsstart ausgeführt wird. Da Unit Tests jedoch eine eigene Ausführungskonfiguration haben und die Startup.cs-Datei nicht ausführen, wurde der GDAL-Port zunächst nicht initialisiert. Dies hatte zur Folge, dass das Datenset nicht initialisiert wurde und wir somit ständig eine NullPointer-Exception bekamen. Dies ist unserer Meinung nach schlechte Codequalität des Ports, da es hier keine Fehlermeldung gab, sondern einfach NULL als Wert für den Datensatz zurückgeben wurde ohne irgendeine Kontextinformation, die die Fehlersuche erleichtert hätte. Aufgrund der mangelnden Dokumentation hat die Lösungsfindung auch hier deutlich zeitaufwändiger als nötig. Letztlich fanden wir die Lösung, und fügten den Initialisierungsbefehl in die Tests ein. Danach bekamen wir korrekte Ergebnisse. Als Unit Test-Framework verwendeten wir xUnit.net.
Zusammenfassung der Hindernisse und Erkenntnisse aus der Backend-Entwicklung
- Teilweise war etwas Einarbeitung in .NET Core nötig, da nicht alle von uns bereits Erfahrung damit hatten
- Es musste einige Recherche betrieben werden, um eine geeignete Quelle für die Höhendaten zu finden
- Das Verständnis der verschiedenen Koordinatenprojektionssysteme und deren Umrechnung war etwas kompliziert
- Wir mussten einen Weg finden, die großen GeoTIFF-Dateien im Container bereitzustellen
- Aber mit Abstand am wichtigsten: wir haben gelernt, dass die Auswahl der Plattform nicht nur von architektonischen Gesichtspunkten oder gar denen der Bequemlichkeit abhängen sollte, sondern dass auch die Anwendungsdomäne eine entscheidende Rolle spielen sollte. Im Bereich Geo-Daten-Processing ist Python die mit Abstand am meisten verwendete Sprache, sodass die meisten Bibliotheken und Communityinhalte sich auf diese Sprache beziehen. Es ist also dringend zu empfehlen, für solche Anwendungstypen Python zu verwenden. Anderenfalls bleibt nur die Möglichkeit, sich – wie wir – auf (oft unvollständige und schlecht dokumentierte) kleinere Bibliotheken oder Ports zu verlassen, was die Entwicklung stark verkompliziert.
Den Server stressen
Wir kommen zum nächsten Puzzleteil des Projektes, dem Stresser.
Um erkennen zu können, welche Auswirkungen eine hohe Anzahl von Anfragen auf das System hat und wie wir dagegen vorgehen können, müssen wir zuerst das System mit einer hohen Anzahl an Abfragen stressen. Man könnte hier fast von einer DDoS-Attacke sprechen. Allerdings müssen wir nicht ganz so weit gehen und ein ganzes Botnetz für diesen Test zu erschaffen, das wäre dann doch etwas zu viel des guten. Welche Alternativen haben wir? Es geht darum, eine reproduzierbare Testumgebung für das Backend zu schaffen, um in einem realistischen Umfeld erkunden zu können, wie sich die Elevation API unter Last verhält.
Anforderungen
Wir wollen natürlich nicht einfach mit irgendeiner beliebigen Sprache ein Programm schreiben, das in einem for-Loop sequenziell einige HTTP-Requests versendet. Wir wollen möglichst schnell und unkompliziert unsere API mit hunderten oder auch hunderttausenden Anfragen möglichst parallel stressen. Wir wollen möglichst keinen Overhead. Einfach ein kleines Programm, das keine Framework-Infrastruktur um sich benötigt, um zu existieren. Natürlich wollen wir das Ganze konfigurieren können: Welche URL soll gestresst werden, wie häufig, mit welcher HTTP-Methode und welchem Body Inhalt. Am besten wäre dazu ein Web-Interface, um nicht bei jedem Ausführen als erstes –help tippen zu müssen.
Also sammeln wir mal die Anforderungen:
- Nebenläufigkeit
- Leichtgewichtig
- Schnell
- Einfach zu deployen
- Web-Interface
Bevor wir anfangen den Stresser zu bauen, müssen wir entscheiden, welche Sprache wir wählen. In den Topf geworfen wurde .NET. Zwar bietet das Framework gute Performance, hat mir jedoch als Framework schon zu viel Overhead. Dazu kommt, dass wir keinerlei Erfahrung damit haben. JavaScript/Node, war die zweite Option und bringt einiges mit, was hier hilfreich ist. Allerdings ist es nicht gerade für seine Geschwindigkeit oder Nebenläufigkeit bekannt. Entschieden haben wir uns letztendlich für GoLang. Die Idee kam daher, dass wir vor Jahren schon einmal in der Sprache entwickelt habe, aber seither keine Berührung mehr damit hatte. Was für Go spricht, ist, dass es mit Fokus auf Nebenläufigkeit entwickelt wurde. Die Standard-Bibliothek bringt alles mit, was wir benötigen. Außerdem kompilieren Go Programme zu einer einzigen kleinen Executable, in der alle Abhängigkeiten enthalten sind.

Also let’s Go.
Umsetzung
Der Stresser besteht aus drei Komponenten:
- Web-Frontend
Um den Stresser zu konfigurieren, benötigen wir ein Web-Interface. Zwar ist es möglich, das mittels Web-Templates direkt in Go umzusetzen, aber was soll der Geiz. Wir erstellen das Web-Frontend mit React. Das ist zwar absolut Overkill, aber es geht nur darum möglichst schnell und unkompliziert eine Weboberfläche zu erstellen. In dieser Web-Oberfläche können wir dann die definierten Parameter konfigurieren, den Stresser starten und das Resultat einsehen. - Webserver
Das mit React erstellte Frontend liefern wir mit einem Go Fileserver als statische Dateien aus. Dieser Go-Server fungiert außerdem als Proxy und startet den Stresser. - Der Stresser selbst
Um den Stresser auch ohne Overhead verwenden zu können, wird er als zusätzliches Go-Programm geschrieben, welches alle benötigten Parameter über die Kommandozeile bekommt. So kann er einerseits über das Web-Frontend gestartet werden, allerdings auch einfach über die Kommandozeile, falls benötigt.
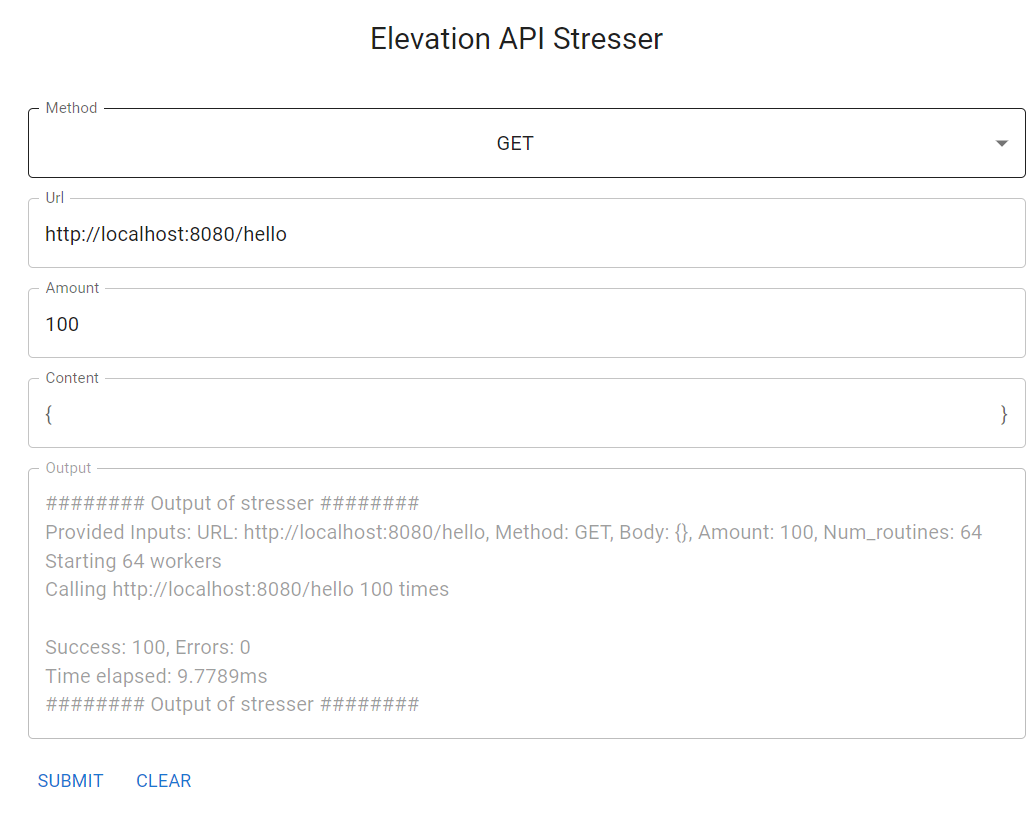
Es gibt ein paar verschiedene Möglichkeiten, den Stresser in Go umzusetzen. Um herauszufinden, welche nun die Beste ist, haben wir verschiedene Möglichkeiten implementiert, die Performance gemessen (Zeit benötigt, um X Anfragen zu verschicken) und verglichen.
Die wesentlichen drei Möglichkeiten sind:
- Inkrementell
- Worker
- Mit Waitgroup
- Mit Message Queues
Um die Effizienz der verschiedenen Möglichkeiten zu messen, wurden zwei Metriken gemessen:
- Benötigte Zeit von erster bis letzter Anfrage
- Verhältnis Fehlschläge / erfolgreiche Anfragen
Inkrementell
Das ganze Inkrementell auszuführen dürfte die einfachste Möglichkeit sein, ist aber wie man sich denken kann auch die ineffizienteste. Hierzu werden in einer Schleife eine Anfrage nach der nächsten gesendet. Die Frage, ob es Performance-Unterschiede zwischen For-/While-/ oder anderen Schleifen gibt, ist obsolet, da Go nur eine Variante anbietet.
| Metrik | 100 | 1.000 | 10.000 |
|---|---|---|---|
| Zeit (in Sekunden) | 0,0895689 | 0,8537029 | 8,4739672 |
| Fehlschläge/Erfolge | 0 / 100 | 0 / 1000 | 0 / 9817 |
Workerpool…
Eine interessantere Methode unser Ziel zu erreichen ist die Umsetzung mit “Workern”. Ein Worker in Go ist eigentlich nichts anderes als eine Methode, welche in einer separaten Go-Routine gestartet wird. Eine Go-Routine ist ein leichtgewichtiger Thread, der mit dem Befehl “go” gestartet wird.
Eine Go-Routine ist nicht zu verwechseln mit einem normalen Thread, denn Go verwendet einen eigenen Scheduler, welcher mehrere Go-Routines über einen Thread verteilt. Die genaue Funktionsweise des Go-Routine Schedulers ist im Quellcode selbst umfangreich beschrieben und von Vincent Blanchon sehr gut aufbereitet.
Die drei Hauptprinzipien des Schedulers sind laut Quellcode:
// G - goroutine.
// M - worker thread, or machine.
// P - processor, a resource that is required to execute Go code.
// M must have an associated P to execute Go code, however it can be
// blocked or in a syscall w/o an associated P.Führen wir nun mehrere HTTP-Requests gleichzeitig aus (also in verschiedenen Go-Routines) ist, sieht der Ablauf z.B. wie folgt aus:
Zuerst wird einer der erstellten Worker (Go-Routine) vom Scheduler gestartet. Dieser Worker führt das http-Request aus. Dieser Worker wartet anschließend auf die Antwort und wird so lange vom Scheduler im Network Poller “geparkt”.
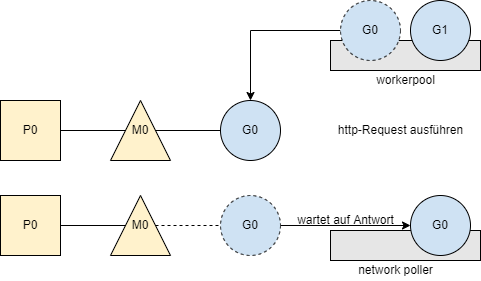
Nun wird der nächste wartende Worker vom Scheduler ausgewählt und der Prozess wiederholt sich.
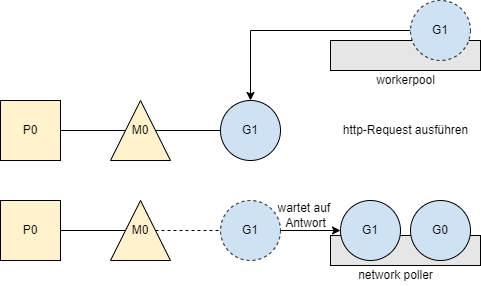
Wenn mittlerweile eine Antwort eingetroffen ist, erfährt der Scheduler das vom Network Poller und führt den betreffenden Worker weiter aus.

Natürlich haben wir uns für eine Umsetzung mit Workern entschieden. Hierbei gibt es grundsätzlich zwei Möglichkeiten der Umsetzung. Dabei geht es vor allem darum, wie die Worker erstellt werden und wie mit der Beendigung umgegangen wird. Wir werden nicht im Detail auf die Funktionsweise eingehen, aber werde versuchen die Grundlagen und Unterschiede klarzumachen.
… mit Waitgroup
Bei der Verwendung von Waitgroups, werden die Worker inkrementell erstellt und der Waitgroup hinzugefügt. Demnach werden insgesamt so viele Worker erstellt, wie Anfragen gesendet werden sollen. Ist der Worker beendet, wird er aus der Waitgroup entfernt. Der Stresser ist fertig, wenn die Waitgroup leer ist.
Lokal getestet ergeben sich folgende Werte:
| Metrik | 100 | 1.000 | 10.000 |
|---|---|---|---|
| Zeit (in Sekunden) | 0,022555 | 0,706024 | 2,679127 |
| Fehlschläge/Erfolge | 0 / 100 | 0 / 1000 | 183 / 9817 |
Ein Problem mit dieser Methode ist, dass bei einer hohen Anzahl Anfragen Memory-Fehler auftreten, da zu viele Worker gestartet werden. Man sieht, dass im Fall von 10.000 Anfragen, 183 Anfragen fehlgeschlagen sind. Dabei handelt es sich um clientseitige Fehler und nicht um Antworten mit einem Code != 2xx. Diese Zahl schwankt stark und hängt davon ab, wie schnell Anfragen beantwortet werden. Werden sie zu langsam beantwortet, laufen zu viele Worker gleichzeitig.
… mit Channels
Über Channels können Werte gesendet werden. An einer Stelle werden Werte eingegeben, ein Worker kann an einer anderen Stelle einen Wert auslesen. Wir befüllen also einen Channel mit X Werten (X = Anzahl an Anfragen) und die Worker arbeiten diese nach und nach ab. Der Vorteil ist, dass einfach kontrolliert werden kann, wie viele Worker wir verwenden und diese können alle vor dem eigentlichen Start initialisiert werden.
Lokal getestet ergeben sich folgende Werte:
| Metrik | 100 | 1.000 | 10.000 |
|---|---|---|---|
| Zeit (in Sekunden) | 0,0224859 | 0,6068043 | 2,2542878 |
| Fehlschläge/Erfolge | 0 / 100 | 0 / 1000 | 0 / 9817 |
Waitgroups sind grundsätzlich performanter als Channels (siehe Stackoverflow), beziehungsweise wird eine Mischung aus beiden empfohlen. Channels bieten uns einige Vorteile, die uns mehr Kontrolle bieten. Und wie die Performance-Tests zeigen, unterscheiden sich beide Technologien in unserem Anwendungsfall kaum.
Wie viele Worker sollte man verwenden?
Man kann nicht pauschal sagen, ob sich mehr Worker als verfügbare Threads nicht lohnen, da diese, wie oben gezeigt, parallel verarbeitet werden können. Allerdings funktioniert es auch nicht nach dem Motto “viel hilft viel”, da der Stresser irgendwann mehr mit Scheduling als ausführen beschäftigt ist. Es lässt sich leider nicht so leicht eine optimale Anzahl an Workern benennen (z.B. verfügbare Threads * 4 o.Ä.). Ein Punkt, auf den man beispielsweise relativ wenig Einfluss hat, ist die Antwortgeschwindigkeit des Servers, die durch die Bearbeitungsdauer, Netzwerkverbindung etc. beeinflusst wird. Müssen Worker lange im Network Poller warten, können sie auch nicht wiederverwendet werden. Aus diesem Grund haben wir die Anzahl der Worker als zusätzliches Konfigurationsfeld hinzugefügt.
Zur Veranschaulichung hier ein Vergleich. Hierfür wurde auf dem Testserver eine Last simuliert (1 Sekunde Timeout). Nun wurden mit unterschiedlich vielen Workern 1000 Anfragen gesendet.
| Worker | 8 | 16 | 32 | 100 | 500 | 1000 |
| Dauer | 2min 1,14s | 1min 3,65s | 32,42s | 10,17s | 2,45s | 1,63s |
Das Ergebnis bestätigt die Vermutung von vorher. Das Stressen dauert mit 1000 Workern am kürzesten, da für alle Anfragen ein extra Worker existiert und nicht auf einen im Network Poller gewartet werden muss.
Zusammenfassung der Hindernisse und Learnings der Stresser-Entwicklung
- Zunächst natürlich die Wahl der richtigen Entwicklungstools und die damit verbundene Anforderungsanalyse
- Da unsere Expertise in Go kaum vorhanden war, war das erneute einlernen in eine deutlich andere Sprache, als JavaScript eine kleine Herausforderung.
Damit verbunden und am wichtigsten, war das Ausprobieren und Vergleichen verschiedener Möglichkeiten den Server zu Stressen. - Gerade bei der Evaluierung der verschiedenen Stresser-Varianten, war es wichtig, das interne Scheduling von Go zu verstehen. Dabei haben wir auch gelernt, das die Go-Community wohl noch recht klein und jung ist. Denn wo man für andere Sprachen Millionen Antworten findet, muss man hier teilweise noch sehr stark recherchieren.
- Eine “Honorable Mention” ist auf jeden Fall das Containerizen des ganzen und Generelle bereitstellen der Anwendung. Zwar wurde in diesem Blogeintrag recht wenig darauf eingegangen, da es den Kontext gesprengt hätte, jedoch war es sehr interessant, zu erkunden welche Möglichkeiten es gibt, die verschiedenen Bauteile des Stressers (Frontend, Proxy-Server, Stresser) zusammenzubringen.
- Und last but not least: Auch in diesem Fall wieder Monitoring. Welche Informationen brauchen wir, wie werden sie bereitgestellt, etc.
Monitoring
In diesem Kapitel werden wir uns einzele Monitoring Tools genauer anschauen. Anschließend werden wir einen Versuchsaufbau gestalten, womit wir einen Benchmark gegen die Elevation API durchführen werden. Wir diskutieren die Ergebnisse und versuchen anschließend die Frage zu beantworten, was uns das Tracing und Logging an Performance kostet. Die Learnings aus diesem Kapitel werden am Ende zusammengefasst.
Ziele
Da wir bisher kaum Erfahrung im Bereich Monitoring haben, war es also das erste Ziel, Tools für das Monitoring auszuwählen und diese in Betrieb zu nehmen. In der Vorlesung kam das Thema Tracing auf, welches uns besonders zugesagt hat und wir es deshalb ausprobieren wollten. Darüber hinaus musste die Elevation API erst einmal in der Lage sein, Metriken für das Monitoring zu bereitzustellen.
Im nächsten Schritt soll ein Versuchsaufbau zur Bestimmung der Leistungsfähigkeit und Effizienz unseres Backends geplant und durchgeführt werden. Dabei soll der bereits vorgestellte Stresser die Last für das Backend erzeugen. Da das Monitoring eine Tracing-Komponente enthalten wird, gilt es zudem herauszufinden, was das Tracing in Hinblick auf die Performance in unserem Fall kostet.
Die Monitoring Komponenten
Nach einer Recherche haben wir uns für folgende Monitoring Komponenten entschieden:
Prometheus, node_exporter, cAdvisor, Grafana und Jaeger. Diese Tools werden in den nächsten Abschnitten näher vorgestellt.
Im Bereich Monitoring sind wir bei der Recherche auf weitere Projekte wie zabbix, nagios und icinga2 gestoßen. Letzteres konnten wir bereits in der Veranstaltung “Software Defined Infrastructure” kennenlernen. Wir haben uns für Prometheus entschieden, da es uns am etabliertesten vorkam und uns die Idee hinter den Exportern gefiel.
Im Bereich Tracing sind wir neben Jaeger auch auf Kamon, Sentry und Datadog gestoßen. Wir haben uns für Jaeger entschieden, da die anderen Lösungen nur in Form von Cloud-Plattformen zur Verfügung stehen und entweder sehr eingeschränkte Features oder nur kurze kostenlose Testversionen anbieten.
Prometheus
Prometheus ist ein Monitoring Tool welches mit einer Zeitreihendatenbank arbeitet. Es ist somit auf das Speichern von Zeitreihen wie Sensordaten ausgelegt. Mithilfe der PromQL können Daten gezielt ausgewählt und aggregiert werden.
Mithilfe sog. Exportern werden Metriken bereitgestellt, die von Prometheus in regelmäßigen, selbst definierbaren Zeitabständen eingesammelt werden. Es gibt dabei fertige Exporter wie node_exporter. Zusätzlich können eigene Exporter geschrieben werden.
Für die Elevation API stellen wir mithilfe der prometheus-net.AspNetCore Bibliothek unsere eigene Metriken bereit. Die Installation und der Quick Start der Bibliothek funktionierte auf Anhieb. Neben verschiedenen Versuchen sinnvolle Metriken zu finden, zeigen wir euch hier die Implementation eines einfachen Counters, der jedes Mal um eins hochzählt, wenn die Höhenmeter einer Koordinaten bestimmt wurden:
So banal diese Metrik scheinen mag, so ist diese Metrik für die Bestimmung der Performance im Lasttest essenziell. Im späteren Verlauf können wir mit der erwähnten PromQL eine Abfrage formulieren, die uns die Anzahl der berechneten Höhenmetern der letzten Minute ausgibt.
Der folgende Code Block zeigt die Metriken, die von der Elevation API erzeugt werden und über “/metrics” abgefragt werden können:
Somit wäre der Exporter der Elevation API schon mal bereit.
node_exporter
Der Exporter node_exporter wurde vom Prometheus-Team entwickelt und stellt Hardware und OS Metriken des Systems bereit. Dadurch lassen sich neben CPU-, Netzwerk-Last und RAM-Belegung, auch die Lese-/Schreib-Raten der einzelnen Laufwerke beobachten.
(node_exporter bietet noch viele weitere detailreiche Metriken zu CPU, Netzwerk, RAM und zum Dateisystem an. Einige erfordern Recherche, um sie überhaupt zu verstehen. Es gibt einige Metriken wie “node_hwmon_temp_celsius”, die nice-to-have sind, wir aber für das Benchmarking eine untergeordnete Rolle spielen)
Die folgenden beide Bilder zeigen Diagramme, die ein paar der genannten Metriken aus node_exporter visualisieren:
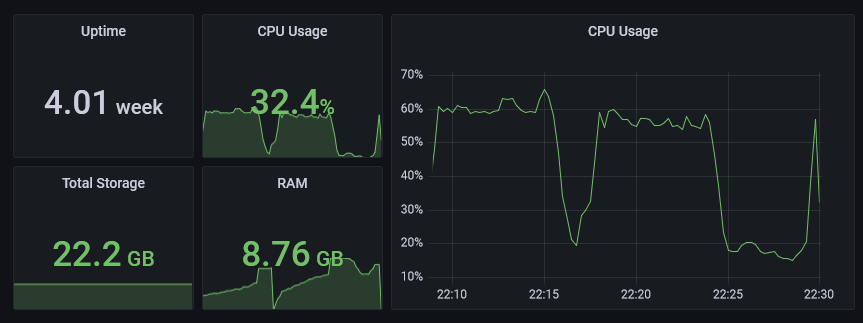
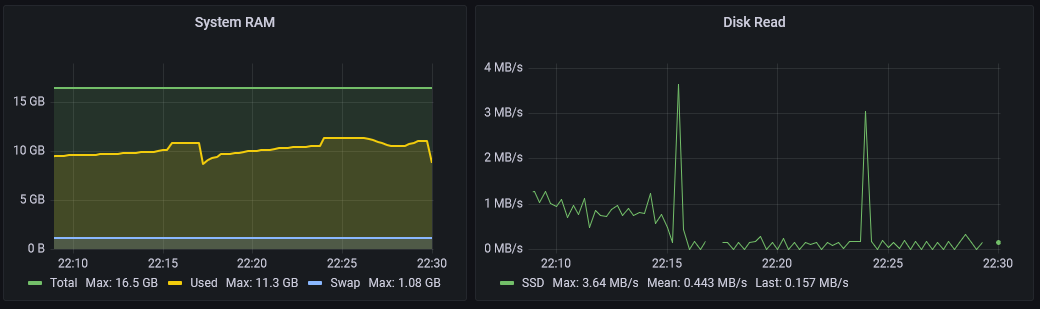
cAdvisor
Da node_exporter “nur” Metriken des Host-Systems bereitstellt, setzen wir zusätzlich cAdvisor ein, welches von Google entwickelt wurde. cAdvisor (Container Advisor) ist ähnlich wie node_exporter, mit dem Unterschied, dass es allgemeine Metriken über Docker-Container sammelt.
Die folgenden beide Bilder zeigen Diagramme, die ein paar Metriken aus cAdvisor visualisieren:
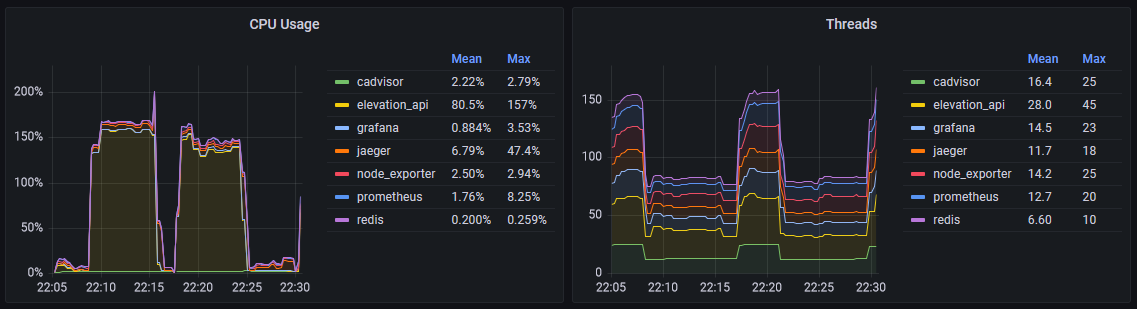
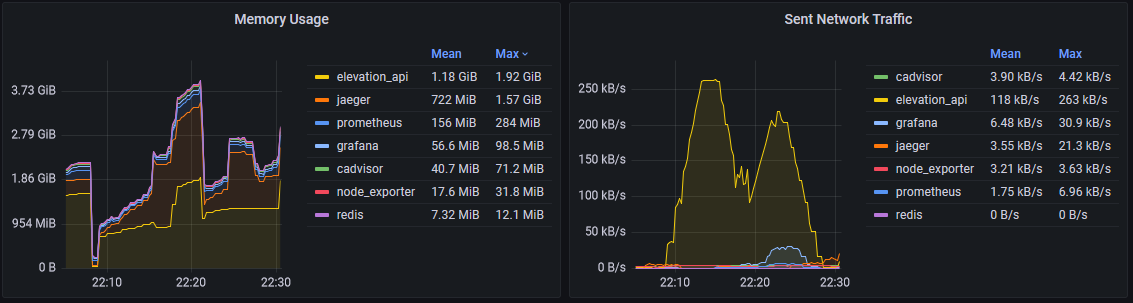
Dank node_exporter und cAdvisor haben wir nun grundlegende Metriken unseres Systems im Blick. Allerdings hat uns cAdvisor auch gezeigt, dass es standardmäßig doch sehr Ressourcenhungrig ist:
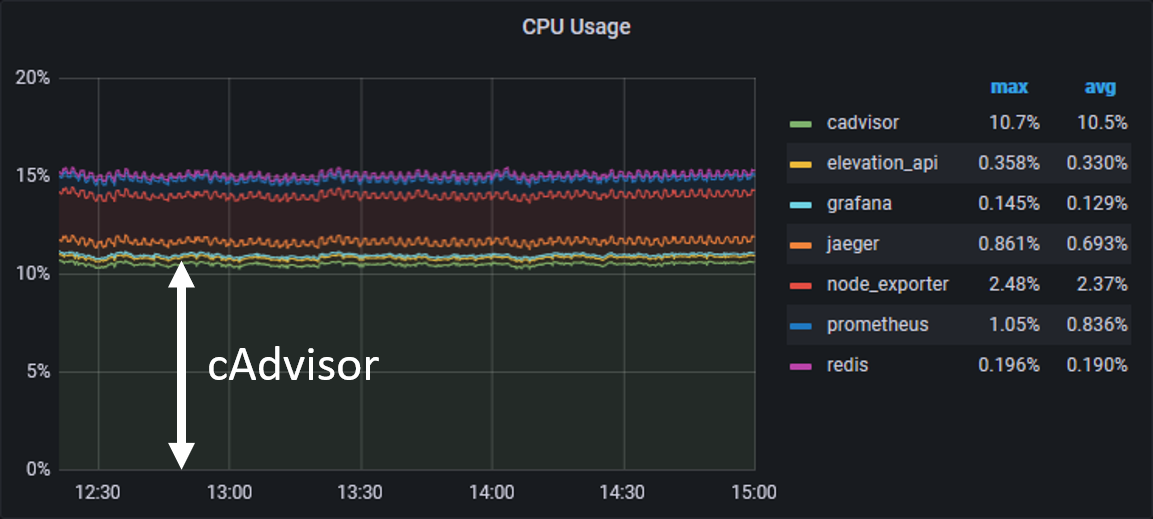
cAdvisor hat in unserem Versuchsaufbau im Idle direkt 10% CPU Last “verschlungen”. Das fanden wir etwas viel, weshalb wir nach einer Lösung gesucht und gefunden haben. Wie bereits erwähnt bietet node_exporter viele weitere Metriken an. Das gleiche gilt standardmäßig auch für cAdvisor. Folglich konnten wir durch eine Anpassung des Startbefehls cAdvisor dazu bringen, unnötige Metriken nicht zu sammeln und sich auf Docker Metriken zu beschränken. Der folgende Code-Block zeigt unsere cAdvisor Konfiguration:
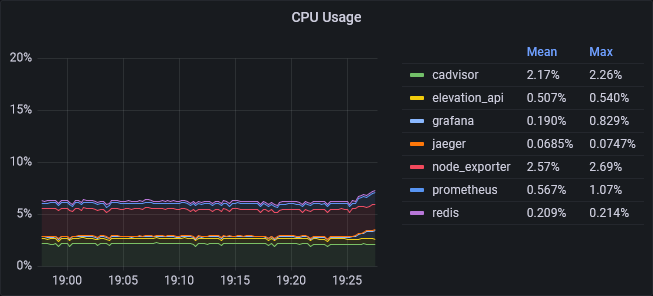
Die Änderung hat gezeigt, dass cAdvisor statt ~10% nun ~2% CPU-Last benötigt. Daran zeigt sich, dass man standardmäßige Konfigurationen immer hinterfragen sollte.
Grafana
Grafana erlaubt die Visualisierung von Metriken aus diversen Quellen wie Prometheus, Jaeger und noch vielen weiteren. Darüber hinaus können Regeln definiert werden, die unter bestimmten Fällen Alarme auslösen und einen benachrichtigen, wenn z.B. ein Service für eine gewisse Zeit nicht erreichbar ist oder auffällig hohe Lasten für längere Zeit beobachtet werden.
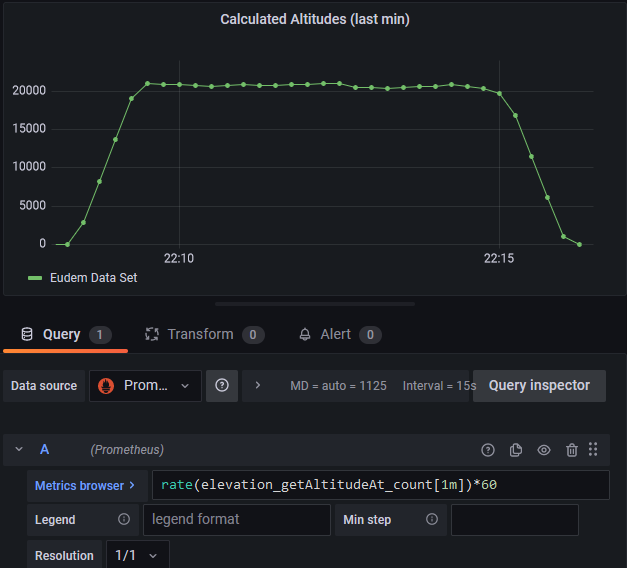
Die bisherigen gezeigten Diagramme stammen alle aus eigens konfigurierten Grafana Dashboards. Als Beispiel zeigen wir, wie wir das Diagramm zur Anzeige der berechneten Höhenmeter pro Minute erstellt haben.
Dazu erstellen wir ein neues Panel und wählen als Datenquelle “Prometheus” aus, welches wir bereits über Provisioning Config Files konfiguriert haben. Anschließend finden wir über den Metric Browser unsere eigene Metric “elevation_getAltitudeAt_count”, welcher nur ein einfacher Zähler ist. Da Prometheus verschiedene Query Functions anbietet, können wir über die PromQL mithilfe der rate() den durchschnittlichen Anstieg eines Wertes einer bestimmten Zeitspanne ermitteln.
Mit “[1m]” möchten wir den durchschnittlichen Anstieg innerhalb der letzten Minute ermitteln. Würden wir einen kleineren Wert angeben, so wäre der Wert präziser, allerdings dürfen wir nicht vergessen, dass Prometheus alle 5s die Metriken abfragt und die Anfrage selbst bei hoher Last etwas zeitverzögert ankommen könnte. Als letztes multiplizieren wir den Wert mit 60, da “rate()” den durchschnittlichen Anstieg pro Sekunde angibt.
Das folgende Bild zeigt das Ergebnis unserer Query:
Jaeger
Metriken sind schön und gut, aber nicht alles. Während jeder Entwickler sich wahrscheinlich schon mal mit dem Thema Logging beschäftigt hat, hebt Tracing das Logging auf ein neues Level – und mit Jaeger können Traces erstellt, gesammelt und visualisiert werden.
Doch was ist Tracing?
Tracing bedeutet Ablaufverfolgung. D.h. wir beobachten in unserem Fall, wann eine HTTP-Anfrage beginnt und wann sie aufhört. Wir beobachten zudem, was innerhalb unserer Anfrage geschieht und wie lange diese Abschnitte (=Spans) benötigen. Wir können somit die Funktionsaufrufe beobachten und Logs an diesen Aufrufe anhängen.
Der entscheidende Vorteil gegenüber Logs ist, dass Traces an Tracing-IDs geknüpft sind. Zusammen mit Zeitstempel und Spans können wir leichter den Kontext nachvollziehen, während Logs ohne weiteres nur ein Tagebuch über Ereignisse führt. Da Backends typischerweise mit mehreren Threads laufen, ist das Lesen von Logs erschwert, da Ereignisse “parallel” stattfinden.
Der folgende Screenshot zeigt ein Trace in Jaeger UI an, welcher einen Aufruf mit mehreren Koordinaten an unser Backend zeigt:
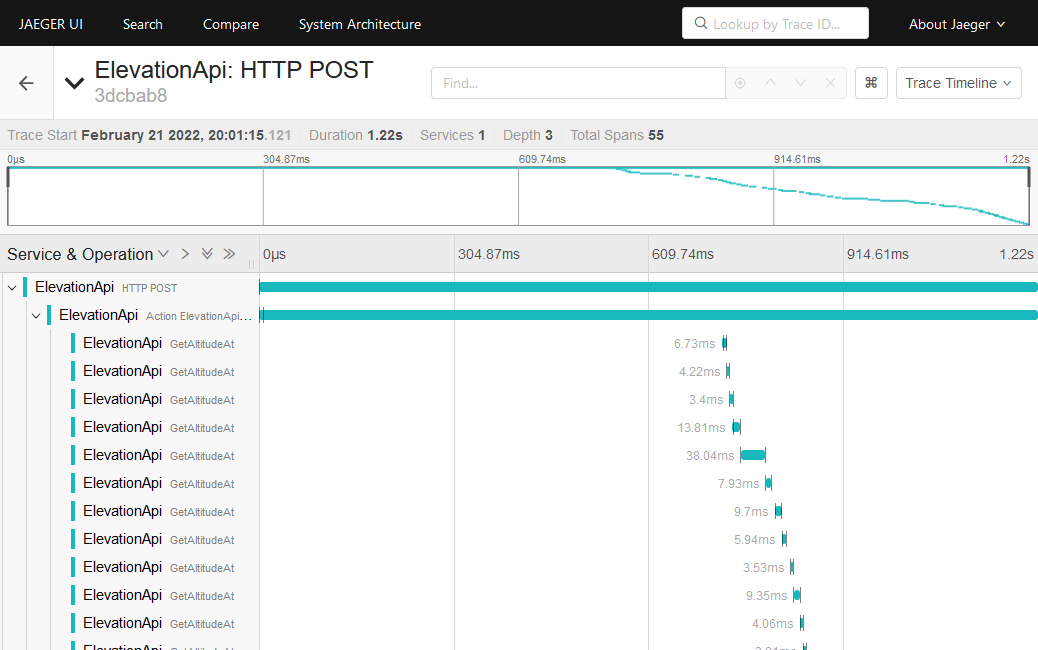
Die Spans im Screenshot zeigen auf, wie lange die Berechnung der Höhe zu einer Koordinate benötigt. Das Backend befand sich zu diesem Zeitpunkt unter Last und musste mehrere Anfragen parallel verarbeiten. In diesem Screenshot sieht man schön, dass die Berechnung mancher Koordinaten aufgrund von Threading und dem daraus resultierendem Scheduling deutlich mehr Zeit (z.B. 38.04ms) als andere Koordinaten benötigten (z.B. ~3ms – ~6ms).
Wenn wir in Jaeger UI einen Span anklicken, so können wir die zugehörigen Logs sehen:
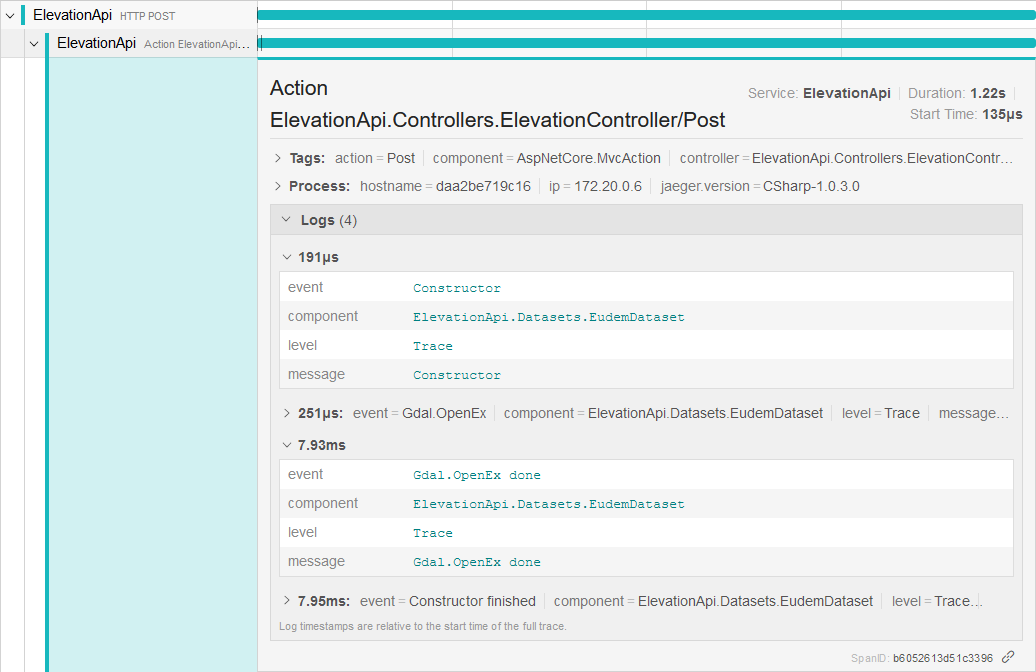
Unsere Elevation API muss einen Jaeger-Client implementieren, damit es Traces an den Jaeger-Agent übermitteln kann. Es existieren Jaeger-Clients für verschiedene Programmiersprachen. So verwenden wir für die Elevation API die Bibliothek jaeger-client-csharp. Die komplette Architektur hinter Jaeger wird auf der Jaeger-Seite kurz und knapp beschrieben.
HINWEIS: Die Entwicklung von jaeger-client-csharp wurde im Verlauf unseres Projektes eingestellt. Allgemein soll man anstatt auf Jaeger-Clients nun auf OpenTelemetry setzen. Da das relativ spät aufkam, haben wir uns dazu entschieden, aus Zeit technischen Gründen nicht zu migrieren.
Die Einbindung der Bibliothek verlief relativ problemlos. Man kann jaeger-client-csharp so konfigurieren, dass die Verbindungsinformationen zum Jaeger-Agent über Umgebungsvariablen festgelegt werden soll. Zusäztlich haben wir dafür gesorgt, dass Jaeger-Tracing über eine Umgebungsvariable deaktiviert werden kann, um später einen Vergleich mit und ohne Jaeger durchführen können.
Anschließend lässt man sich zur Anwendung über den Konstruktur überall eine Instanz von ITracer injizieren, um eigene Spans definieren zu können. Der Folgende Code Block zeigt, wie man einen eigenen Span definieren kann:
Mit “tracer.BuildSpan(…).StartActive(finishSpanOnDispose:false)” kann ein eigener Span zum Trace definiert und gestartet werden. Das zurückgelieferte “scope”-Objekt muss manuell disposed werden, damit die Zeit für den Span gestoppt wird. Dank dem C# using statement wird das “scope”-Objekt automatisch disposed, wenn die Methode “GetAltitudeAt” fertig ist – auch falls eine Exception irgendwo geworfen werden sollte.
Über den Konstruktor lassen wir uns zusätzlich ein “ILogger”-Objekt injizieren. Das ILogger Interface stammt von “Microsoft.Extensions.Logging” und stellt ein allgemeines Logging-Interface dar. Wenn wir dieses Interface verwenden, so werden Log-Einträge automatisch mit dem zugehörigen Trace bzw. zum zugehörigen Span verknüpft.
Somit ist unsere Elevation API nicht nur in der Lage, Metriken zu liefern, sondern kann nun auch Jaeger mit Traces beliefern.
Die Elevation API benchmarken
Da wir nun ausgiebige Möglichkeiten geschaffen haben, unsere Elevation API zu überwachen, wird es nun Zeit, unser Backend Lasttests zu unterziehen.
Versuchsaufbau
Der Versuch wurde auf einen Homeserver durchgeführt, auf dem Proxmox installiert ist.
Der Server verfügt über folgende Hardware:
- CPU: Intel Celeron J1900 CPU 4 Cores / 4 Threads @2.0GHz
- RAM: 2x 8GB DDR @ 1333 MHz
- 250 GB Sata Samung SSD 840
(read: 540 MB/s) - Debian GNU/Linux 11 (bullseye)
Auf diesem Server wurde ein LXC Container erstellt, welchem folgende Ressourcen zugewiesen wurden:
- 2 Kerne
- 4 GB RAM
- 512 MB SAWP
- 20 GB Speicher
- keyctl=1, nesting=1
Die Features keyctl und nesting wurden aktiviert, damit im LXC Container Docker Container laufen können.
Das folgende Schaubild zeigt den Aufbau und Zusammenhang der Docker Container:
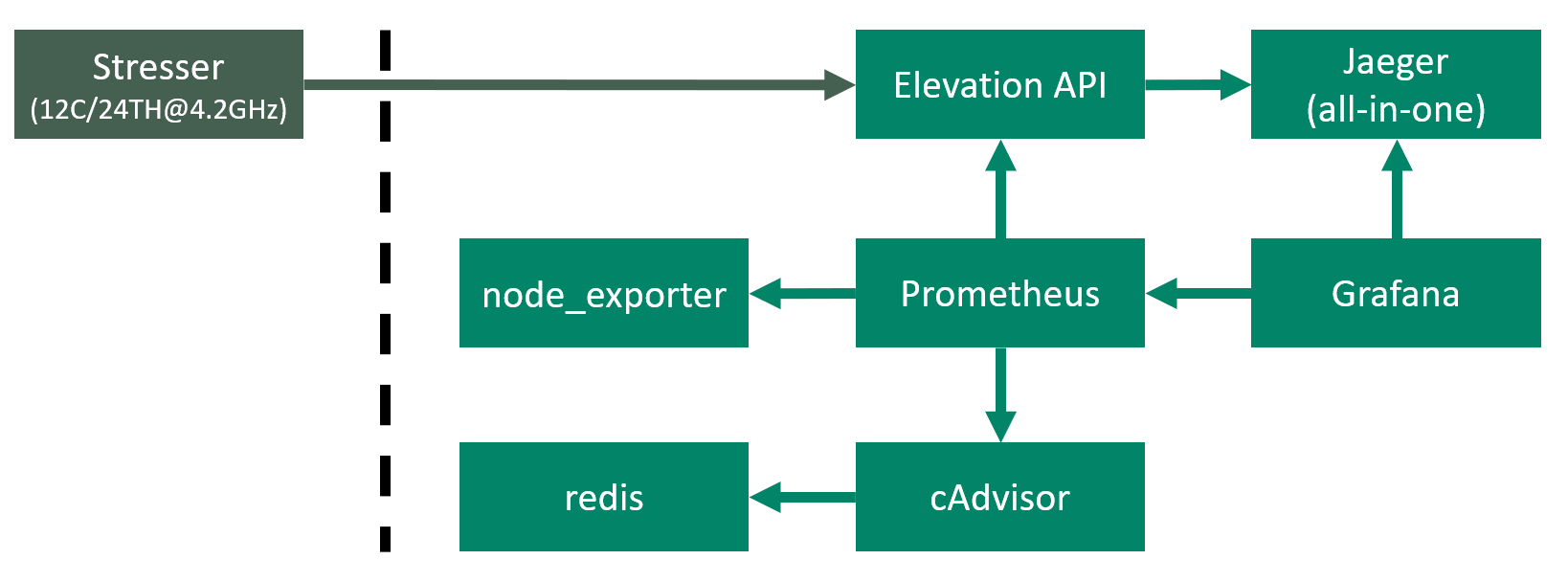
Oben links sehen wir den Stresser, welcher auf einem anderem, leistungsstärkeren Rechner laufen wird. Dieser Rechner ist über ein Gbit-Netzwerk mit dem Homeserver verbunden. Im LXC Container des Homservers werden die Anfragen gegen die Elevation API laufen. Die daraus resultierenden Traces werden an den Jaeger-Agent übermittelt, welcher Teil des Jaeger all-in-one Images ist. Auf dem Server laufen node_exporter und cAdvisor, um Metriken zum System bereitzustellen. cAdvisor benötigt redis als Cache. Prometheus sammelt alle 5s Metriken von der Elevation API, node_exporter und cAdvisor ein. Grafana visualisiert die Metriken und bezieht die Daten aus Prometheus und Jaeger.
Versuchsdurchführung
Nachdem das Setup steht, wird es Zeit für die Versuche. Dazu sagen wir dem Stresser, 32 Anfragen über 8 Workern an die Elevation API zu senden. Die Parameter der Anfragen sind zufällig generiert und liegen im Koordinatenbereich von Deutschland. Die Anzahl der Parameter variiert nach Szenario. Wir haben zunächst 9 Szenarien definiert:
- GET mit 1 Koordinate
- GET mit 2 Koordinaten
- GET mit 5 Koordinaten
- POST mit 5 Koordinaten
- POST mit 10 Koordinaten
- POST mit 25 Koordinaten
- POST mit 50 Koordinaten
- POST mit 100 Koordinaten
- POST mit 10, 20, 30, …, 100 Koordinaten (die Anzahl der Koordinaten wird zufällig für alle 32 Anfragen gewählt)
Die Szenarien laufen jeweils für mindestens 5 Minuten. Anschließend werden die Ergebnisse ausgewertet, die Anzahl der Parameter angepasst und der Vorgang wiederholt.
Wer viel misst, misst Mist
Nach einiger Zeit brach die Performance rapide ab. Es ging soweit, dass die Elevation API nicht mehr reagierte. Auch die anderen Komponenten reagierten nicht mehr. Ein Blick in Proxmox zeigte den Grund:
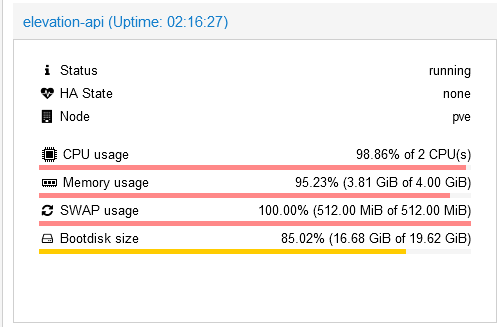
Uns war bewusst, dass das Jaeger all-in-one Image die Traces im RAM speicherte. Uns war allerdings nicht bewusst, wie schnell der RAM unter Dauerlast des Backends voll werden kann. Nachdem auch der SWAP voll wurde, ging nichts mehr. Entsprechend wurden die Container nach jedem Szenariodurchlauf neu gestartet, sodass der RAM beim testen nicht volläuft.
Messergebnisse
Nachdem alle Szenarien durchgeführt wurden, kommen wir nun zur Auswertung. Fangen wir mit den Jaeger Traces an. Es folgen Screenshots aus Jaeger UI, die jeweils die Dauer von 1000 Anfragen zeigen.
(Die Bilder können angeklickt werden, um sie in ihrer vollen Größe anzuzeigen)





Für GET und POST zeigt sich bis 25 Koordinaten eine relativ gleichmäßige Verteilung der Anfragendauer. Größere Abstände zeigten sich ab 50 Koordinaten. Das liegt daran, dass der Stresser immer 32 Anfragen in einer Schleife (mit 8 Workern) durchgeführt hat und anschließend gewartet hat, bis alle Antworten ankamen, bevor die nächsten 32 Anfragen abgeschickt wurden, um den Server nicht mit zu vielen parallelen Anfragen zu überfordern – schließlich wurde der Container mit 2 Containern betrieben und die Arbeit war sehr CPU lastig.
Wir wollten im Benchmark die Worker Zahl zum besseren Vergleichen gleich halten, da bei den POST 100 Anfragen mit mehreren Workern der Server so stark überlastet war, dass das Monitoring nicht mehr funktionierte. Prometheus konnte die Metriken von der Elevation API nur noch sehr langsam bis gar nicht abfragen, da die Antwort bis zu einer Minute dauern konnte, wodurch wir keine zuverlässige Messwerte erhielten würden.
Die Reduzierung der Worker hatte zufolge, dass in den Szenarien mit 1 bis 25 Koordinaten die CPU-Last nie die 100% erreicht hat. Erst ab 50+ Parametern wurden die 100% knapp erreicht. Entsprechend ist folgende Tabelle, die die Anzahl der berechneten Höhenpunkte pro Minute pro Szenario anzeigt, mit Vorsicht zu genießen. Die Zahlen der Szenarien mit 1-25 Parametern stellen nicht die absolute Obergrenze dar:

Die Tabelle zeigt, dass umso mehr Koordinaten auf einmal mitgeschickt werden, umso mehr Höhenberechnungen pro Minute möglich sind. Das hat drei Gründe:
- Die CPU wurde in den Szenarien 1-25 nicht vollständig ausgenutzt
- HTTP-Overhead, Parsen, Logging
- Der Konstruktor von EudemDataset
Die Gründe zum ersten Punkt wurden bereits genannt. Zum zweiten Punkt mussten wir feststellen, dass in unserem Fall das intensivere Logging mehr Zeit gekostet hat, als das Tracing an sich – das wird der Vergleich im übernächsten Abschnitt “Der Preis von Tracing” deutlich zeigen.
Zum dritten Punkt mussten wir über Jaeger feststellen, dass das öffnen der TIF Dateien über Gdal.OpenEx unterschiedlich lang benötigt. Die folgenden beiden Screenshots zeigen die Traces aus Jaeger:
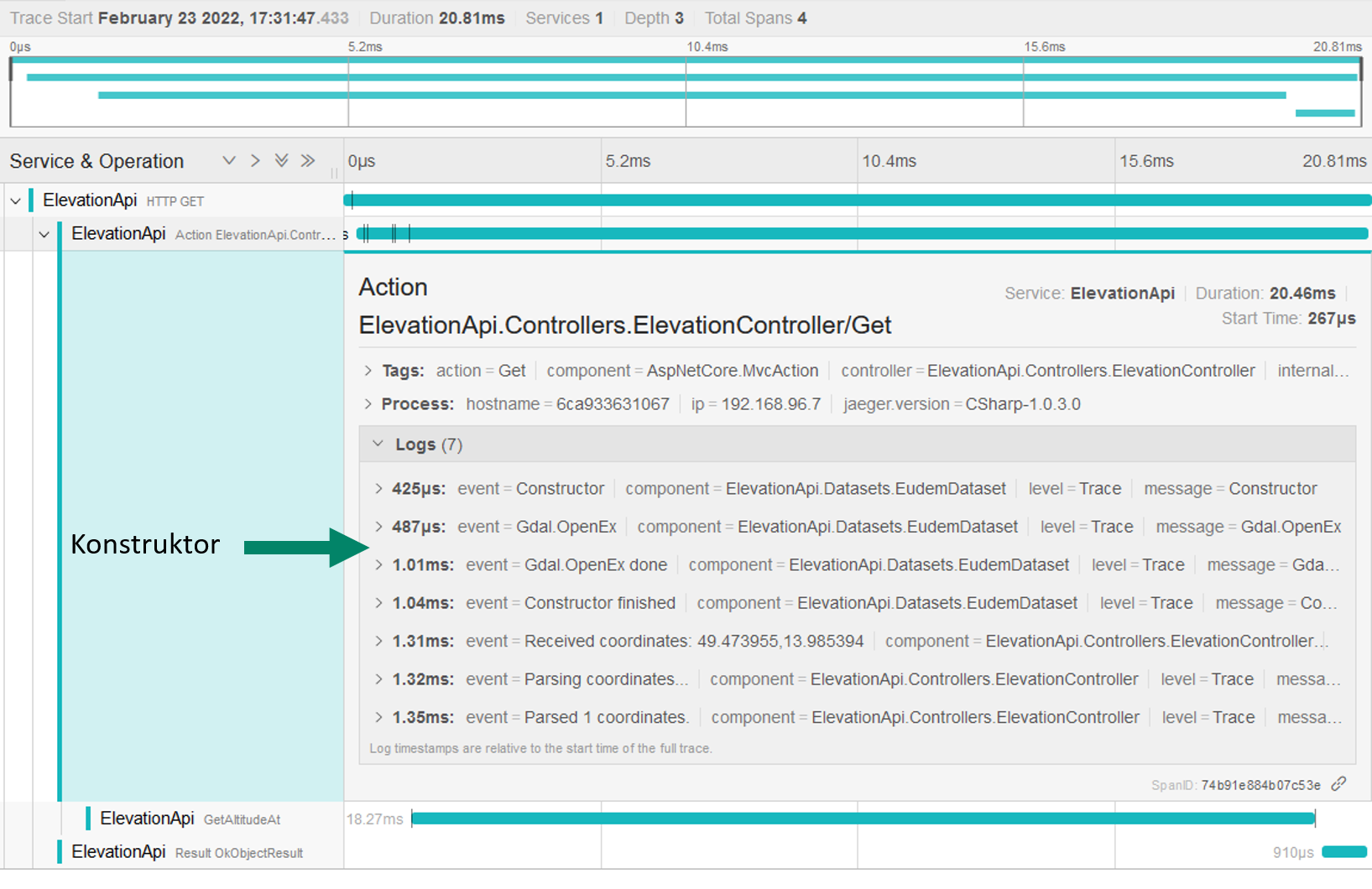
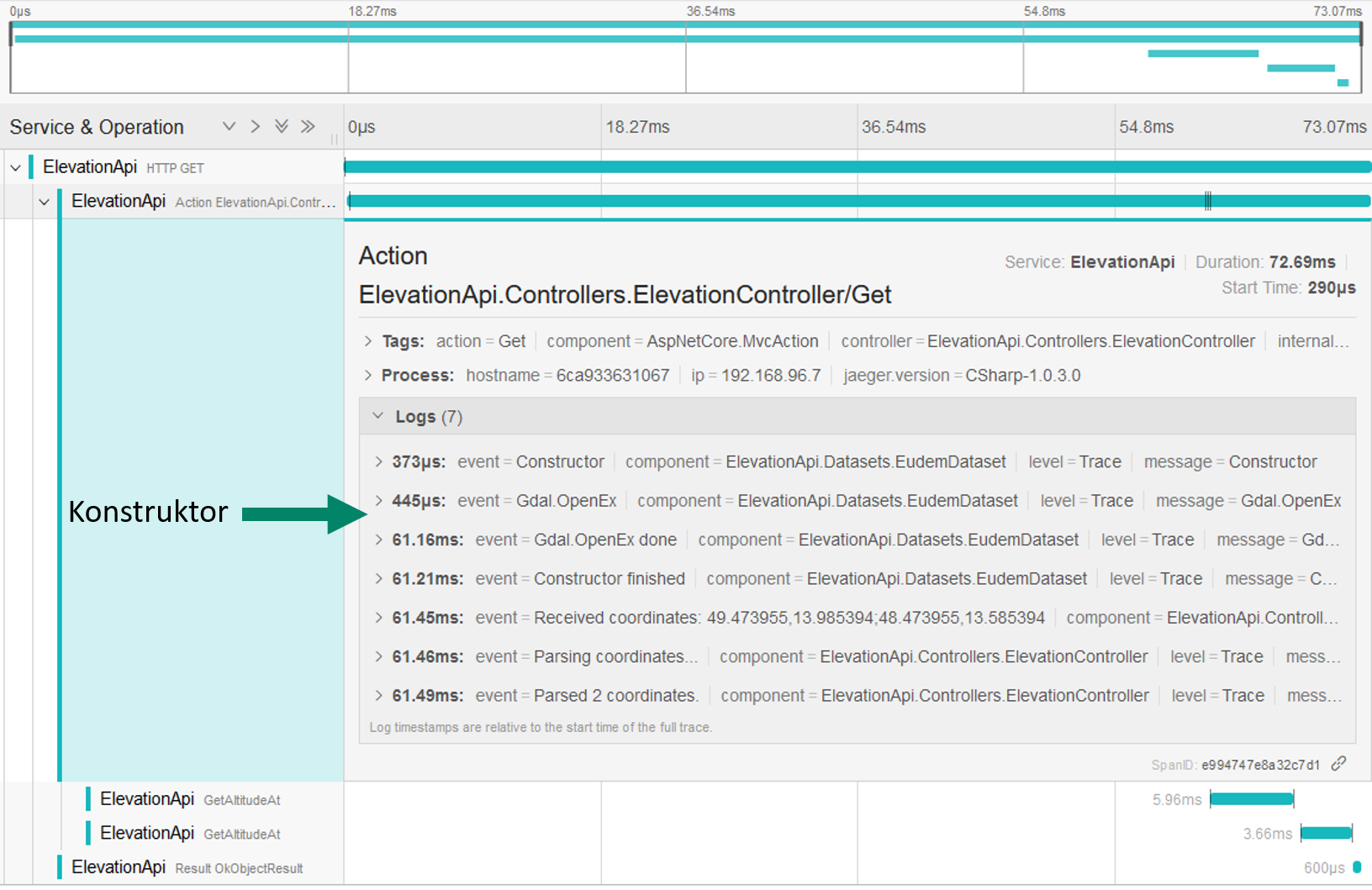
Die Zeiten von Gdal.OpenEx lagen zwischen 0.5ms und 60ms – diese Zeiten wurden außerhalb des Benchmarkings gemessen, sprich der Server war im Idle. Die genaue Ursache dahinter konnten wir nicht herausfinden. Wir wissen lediglich, dass die verwendete Bibliothek ein Wrapper um die C und C++ Bibliothek GDAL ist, welches wir nicht ohne weiteren Aufwand mit unserem Monitoring/Tracing und Debugging durchleuchten können.
Wie lange dauert die Berechnung eines Höhenpunktes?
Hierfür können wir eine Anfrage mit mehreren Parametern gegen die Elevation API schicken und das Ergebnis in Jaeger prüfen:
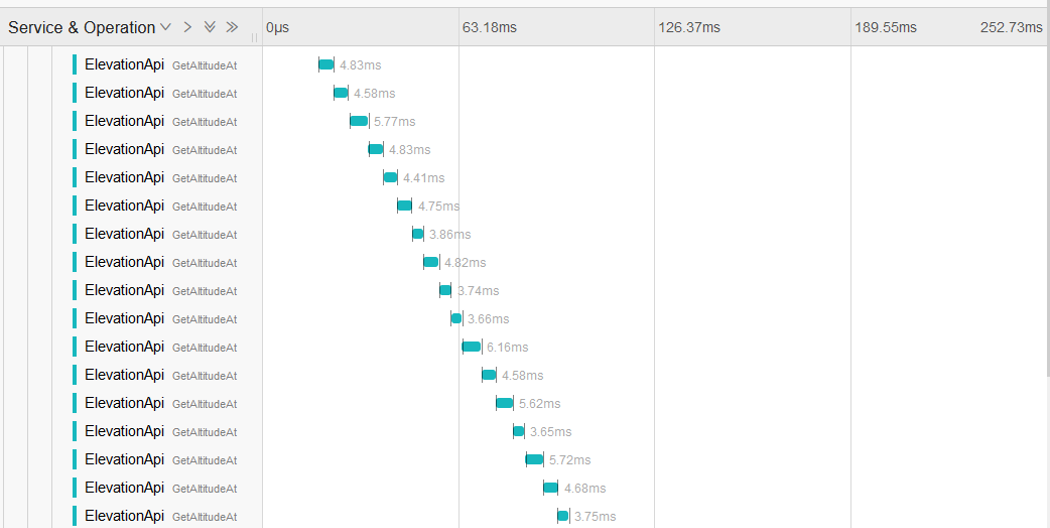
Die Berechnung eines Höhenpunktes dauert zwischen 3.5ms bis 6ms, wobei die 6ms eher eine Ausnahme bilden. Würde man das bei 2 Kernen auf eine Minute hochrechnen, so würde man auf folgende Werte kommen:
1000ms/3,5ms*2*60(1/min) = 34.285 1/min
1000ms/6ms*2*60(1/min) = 20.000 1/min
Diese Zahlen zeigen uns, dass unsere Benchmarks im erwartetem Bereich liegen und dass noch etwas Potential nach oben vorhanden ist.
Der Preis von Tracing
Wir haben soeben festgestellt, dass etwa 34.285 Berechnungen pro Minute das maximale theoretische Limit für unser Setup ist. Da wir bislang auf etwa 27.000 Berechnungen pro Minute gekommen sind, stellt sich nun die große Frage, welche Performanceeinbußen das Tracing darstellt oder ob die Ursache woanders liegt.
Dazu haben wir das POST 50 Szenario erneut durchgeführt. Dabei haben wir aber folgende Fälle Unterschieden:
- POST 50 mit Jaeger und eigenem Trace Logging
- POST 50 ohne Jaeger, aber mit eigenem Trace Logging
- POST 50 mit Jaeger, ohne eigenem Trace Logging
- POST 50 ohne Jaeger und ohne eigenem Trace Logging
Das folgende Schaubild zeigt die unterschiedlichen Messergebnisse. Die Diagramme zeigen die Dauer und Anzahl der Anfragen. Unter jedem Diagramm steht die Anzahl der berechneten Höhendaten pro Minute und welche Features deaktivert wurden:
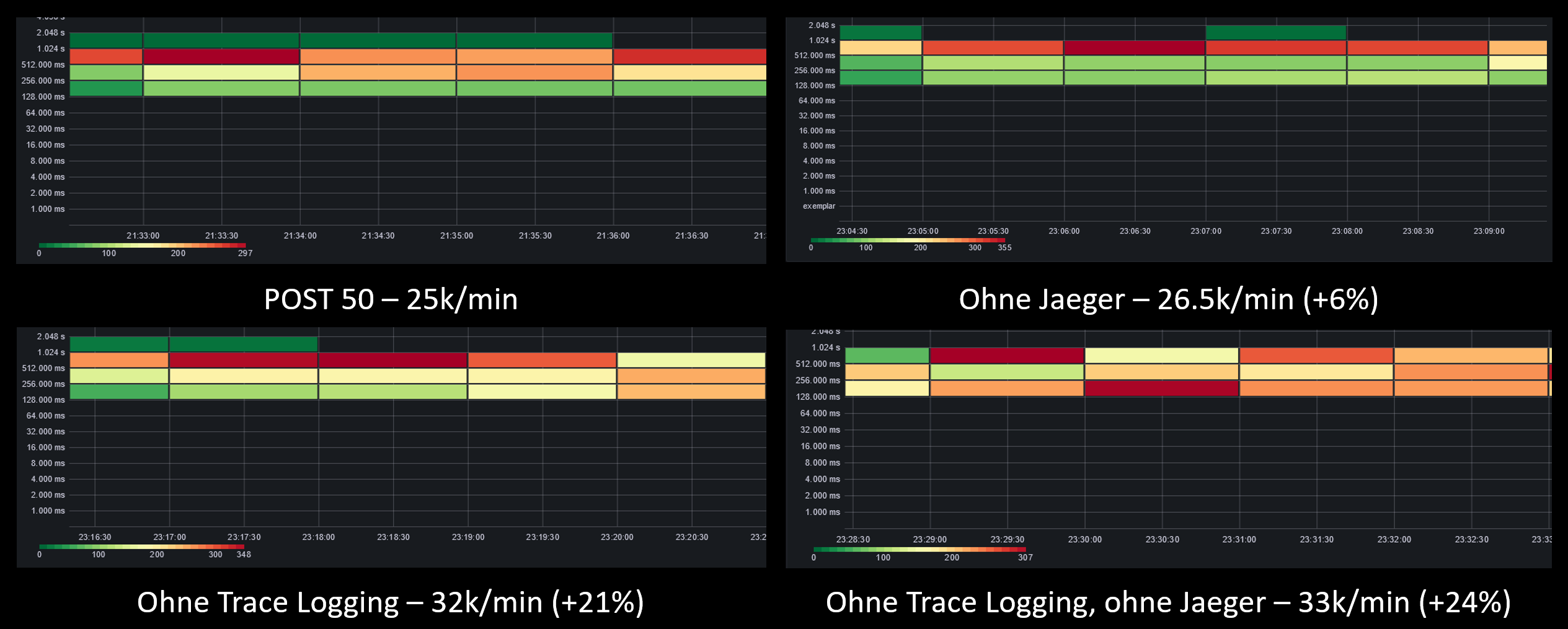
Wir mussten mit erstaunen feststellen, dass das Tracing mit Jaeger nur einen kleinen Performance Unterschied ausmacht und vielmehr das Logging für die Performanceeinbußen zuständig ist. Für den Fall ohne Jaeger und nahezu ohne Logging kommen wir auf etwa 33.000 Berechnungen pro Minute, was ziemlich nah an unser theoretisches Limit von 34.285 Berechnungen pro Minute kommt (schließlich berücksichtigt unser theoretisches Limit nicht das Verarbeiten einer HTTP-Anfrage).
Wenn wir also unsere Anwendung weiter optimieren wollen und nicht auf das Logging verzichten wollen (was wir auf jeden Fall nicht wollen), dann müssten wir uns das Thema Logging (und vor allem dessen Konfiguration) genauer unter die Lupe nehmen. Aus Zeit Gründen sind wir allerdings nicht mehr dazu gekommen.
Learnings aus dem Monitoring
Die Reise über das Thema Monitoring kommt zu einem Ende. Wir haben viel über die genanntenn Tools gelernt und ziehen folgendes Résumé:
- Die gezeigten Tools funktionieren “out of the box”
- Die Tools (vor allem cAdvisor) erheben mehr Metriken als man üblicherweise braucht. Aufgrund dieser Tatsache sollte man sich die Metriken genau anschauen und in der Dokumentation recherchieren, wie sich unbenutzte Metriken deaktivieren lassen, um unnötige Performance-Einbuße zu vermeiden.
- Für uns war es nicht immer klar, was einzelne Metriken bedeuten oder wie diese zu interpretieren sind. Zu cAdvisor haben wir geschrieben, dass die CPU Last bei 10% liegt. Da der Container zwei Kerne zugewiesen bekommen hat, liegt hier die Grenze nicht bei 100%, sondern bei 200% – etwas, was man in diesem Fall berücksichtigen muss.
- Wenn man sich die Doku zu Prometheus, cAdvisor, Jaeger und Co. anschaut, so wird man feststellen, dass es sehr viele Einstellungen gibt, durch die man sich kämpfen muss, wenn es einmal auf etwas ankommt. Das ist mit entsprechendem Aufwand verbunden.
- Es ist nicht einfach, eigene und sinnvolle Metriken zu finden. Der Counter zur Anzahl der berechneten Höhepunkte ist simpel und effektiv.
- Doch wenn es darum geht, weitere sinnvolle Metriken zu finden, so kommt man schnell ins Grübeln. Neben Anfragendauer oder Anzahl an Parametern wird es schwierig, weitere sinnvolle Metriken zu finden – oder gibt es keine weiteren?
- Wie sinnvoll eine Metrik ist, kann sich meist erst beim Ausprobieren herausstellen.
Z.B. haben wir einen Gauge implementiert, welcher uns anzeigt, wie viele Anfragen gerade parallel verarbeitet werden. Was in der Theorie praktisch klingt, kann sich in der Praxis als nutzlos erweisen. Wenn nämlich Anfragen unter 10s bearbeitet werden, kann es durchaus sein, dass diese gar nicht in der Statistik auftauchen, da die Abtastrate von Prometheus zu gering ist und eine höhere Abtastrate wiederum mit einer erhöhten Anzahl an Daten und Performance-Verlust einhergeht.
- Tracing in Kombination mit angehängten Logs sind sehr mächtig.
- Wir konnten dadurch Bottlenecks identifizieren
- Allerdings kostet Tracing und Logging Performance. Diesen Verlust muss man ggf. prüfen und man sollte sicherstellen, dass dadurch auch ein Mehrwert entsteht.
- Man muss sich damit auseinandersetzen, welche Daten man behalten möchte. Die Erfahrung im Benchmarking hat gezeigt, dass schnell viele Daten anfallen können. Ein sinnvoller Filter ist also Pflicht.
Fazit
Die Grundidee des Projekts war es zu sehen, wie sich ein Server unter Last verhält. Es ging darum, nachzuvollziehen, an welchen Stellen Bottlenecks entstehen, sie nachvollziehen zu können und wie diese vermieden werden können. Über die Dauer der Entwicklung hat sich herausgestellt, dass es nicht so einfach ist und einiges an Analyse, Planung und Refactoring benötigt war, um zu dem Ergebnis zu kommen, welches wir erzielen wollten. Im Endeffekt, haben wir eine realistische Anwendung geschaffen, welche uns Daten bereitstellt. Wir haben für dieses System Metriken analysiert und zum Monitoring aufbereitet, um anschließend die Auswirkungen hoher Last auf das System testen und auf die Ergebnisse reagieren zu können. Eine solche Erfahrung ist für gewöhnlich nur in Produktivsystemen möglich und deswegen für uns zu großen Teilen unbekannt. Um einen realitätsnahen Einstieg in das Thema Monitoring, Tracing und Optimierung von Produktivumgebungen zu erlangen ist dies wohl der beste Weg, den man gehen kann. Wir haben eine Menge Dinge gelernt, über die wir ansonsten erst stolpern würden, wenn es zu spät ist.
Leave a Reply
You must be logged in to post a comment.