Give someone a program; you frustrate them for a day; teach them how to program, and you frustrate them for a lifetime.
David Leinweber
The following project was created within/for the lecture “Software Development for Cloud Computing” (113479A) in the summer semester of 2024. I never worked with any … as a Service products, so basically everything presented in the following was learned with (and for) this project. Which project? Well:
The Project

Alright, here’s the pitch:
Learning programming without a use-case is hard. You’ll not know where to begin or what to even learn for specifically. There will be no inherent drive to accomplish things.
Implementing a use-case without having any knowledge is even harder. People tend to massively over-scope. So what if there was a sandbox featuring Lua Scripts in which you are implementing interactions with your garden (gathering information, planting, harvesting)? It would limit the possible scope by limiting the tools available. This is the project. The result isn’t a completed game, more like the core. An MVP to have a working thing. Later, more mechanics can be built around it (e.g. quests, more complex plant shapes, puzzles, leader-boards, …).
The Scope
My driving force for this project was learning. I aimed to expand my skill set by diving into three specific technologies: AWS Lambda, Docker, and Terraform. Each of these technologies offers it’s own set of challenges and use-cases, and I I wanted to explore those with this project. I also tried to consider scalability when making decisions about architecture, although had to make compromises later for the sake of keeping my workload in line. I plan on expanding the project later to help others learn the art of programming.
All the goals I laid down eventually solidified into the following architecture:
Architecture
The architecture itself roughly follows a hexagonal architecture in an attempt to fully separate the logic and modeling of API and Database while keeping a collection of models in the domain as a common base the sides communicate with, adapting the technology agnostic domain models into technology specific objects where needed (e.g. into Database Entities on the side towards the employed ORM). The modelling of the domain lies in a codebase shared between all sides (api, frontend, code-runner) and is also used for inter-process-communication between the parts (e.g. frontend<->api).
The single parts come together to this overall planned structure:
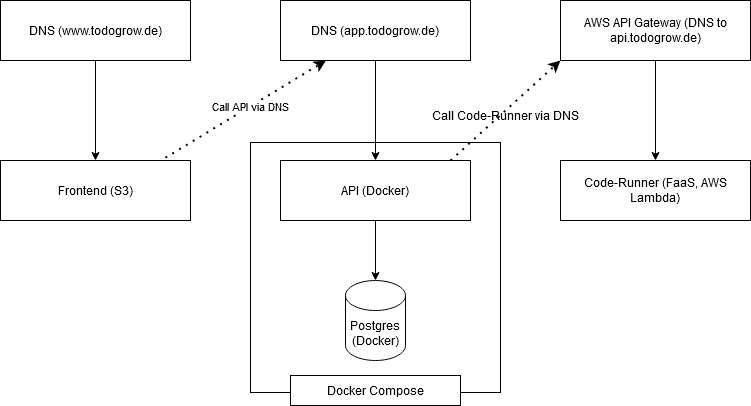
Routing (DNS, AWS API Gateway)
Used to dynamically link all services together without any hard-coding of actual IPs, allowing for a clear hierarchy of dependencies without any bidirectional dependencies.
Backend (NodeJS, Docker)
Provides the whole backend (besides the code runners) in a single monolithic service. Connects to the database, manages game state, provides all API used by the frontend. I set up a GitHub actions pipeline that automatically deploys the current image of my main-branch into AWS ECR (Elastic Container Registry), from which I deploy it to my virtual private server.
Database (PostgreSQL, Docker)
Single source of truth for all game state. Only used by the backend. Right now I would consider this the limiting factor for scalability, as some modifications in the backend seem to be needed to allow for effective database clustering. With vertical scaling, this should still be able to go a long way.
Frontend (AWS S3)
A static frontend developed with Svelte and built with Vite, deployed onto – and served from S3. Any realistic amount of requests will be easily handled and scaled by S3.
Code-Runner (NodeJS, AWS Lambda)
The code runner is an AWS Lambda, responsible for executing actual user-written code. It’s a completely stateless function without side effects (besides logging).
The Code Runner was the single obvious thing to grab and put into a lambda, as it is quite simple to encapsulate into it’s own thing.
User-written code is limited to a maximum of 5 seconds of execution to deny malicious attacks using endless loops in their code.
The domain names used for the game (*.todogrow.de) are managed via Strato. I manually commissioned a certificate via the AWS Certificate Manager, and added it as an available Custom Domain in the API Gateway in the AWS Web Client for my Terraform code to make use of. The connection to the website statically hosted in an S3 bucket is made via an CNAME-Entry pointing to said bucket’s public address.
Learning Terraform
Arguably the most advanced thing I did for this project was learning (and using for that matter) Terraform, specifically the Terraform library for AWS. Terraform is one of the go-to languages for “Infrastructure as Code”, a deployment paradigm that essentially describes the whole infrastructure the project needs and how the project is to be deployed onto said infrastructure. Terraform itself will then handle the deployment using input variables for things like credentials, ARNs of existing infrastructure to embed in, and so on.
Let’s look into an example: My project needs the frontend to be served as static files. One easy way to do this is with S3. In Terraform this results in a row of definitions:
First, an AWS S3 Bucket is created to house all the files (I won’t show all the code for S3 here, as that alone is a good 100 lines in length, this just want to convey how Terraform code roughly looks and feels):
resource "aws_s3_bucket" "bucket" {
bucket = "todo-grow-${random_string.s3random.result}"
force_destroy = true
}Next, the bucket is configured as a website using an aws_s3_bucket_website_configuration, followed by configuring the public access rules to allow anyone to actually visit the website without any authentication.
Afterwards, the actual frontend is recursively uploaded from within the local files:
resource "aws_s3_object" "upload_object" {
depends_on = [aws_s3_bucket_website_configuration.website] # depends on generation step
for_each = fileset("src/frontend/dist/", "**/*")
bucket = aws_s3_bucket.bucket.id
key = each.value
source = "src/frontend/dist/${each.value}"
etag = filemd5("src/frontend/dist/${each.value}")
# look up mime-type
content_type = lookup(local.content_types, element(split(".", each.value), length(split(".", each.value)) - 1), "text/plain")
}Basic Architecture
Overall the project contains four packages of code:
- Backend
- Frontend
- Runner
- Shared
Shared
Shared is the core of the project, it mainly models every entity that exists in the domain (e.g. Script, Garden, Plant, Item, User). They are all defined as Interfaces. Shared also contains a few small helper classes/functions for repetitive tasks one might need to execute on some domain specific entities. The only dependency to effectively use it is typescript to be able to build it, nothing is imported besides other parts of shared. Every package in the project uses shared.
I am exclusively using http/s for inter-process communication in this process, which means I am easily able to convert objects from/to json, using the types declared in shared as a single source of truth for the whole structure of all data.
Frontend
The Frontend is built with Svelte in Typescript, using Vite as frontend build tooling. The stack was chosen because I knew (and liked) what it would bring to the table: Svelte was something I was comfortable with that allowed me to implement what I needed with paradigms I grew to appreciate in previous projects. Vite simply is the recommended way to build Svelte without Sveltekit (which would mostly come with overhead and complexity that I didn’t need). I used Tailwind and DaisyUI as a ready to go CSS foundation. The frontend itself mostly was a thing I wanted to keep as low-risk as possible, as only it’s deployment was directly linked to the main project goals.
An interesting future experiment would be extending the frontend into a Progressive Web App (PWA), the way the code-runner is built would even allow it to run offline to always be able to experiment with new code in some kind of offline testing environment (without an actual effect on the online game state for obvious reasons).
Backend
The backend is monolithic. When deciding on the architecture I first planned to implement it into microservices. For a simple web-API like this using microservices seemed like using orbital lasers for tattooing ants, so I kept it simple, stupid. This also allowed me to look into building and deploying my own container, which I wanted to do if possible.
The backend is implemented in NodeJs with Typescript. I am using Fastify as the web framework and TypeORM for Object-Relational-Mapping (ORM). It directly connects to PostgreSQL, either hosted locally during development, or via docker-compose once deployed. For authentication I implemented OAuth2 via Discord. I let the API give out Cookies in the form of JWTs, cryptographically secured with RSA256. The JWT simply contains the User-ID. I then implemented a middleware that most endpoints use as a pre-handler function that verifies the JWT, grabs the User-Data (and other related data the endpoint needs to send a few requests optimized by TypeORM instead of many small ones) via TypeORM and passes it into the handler function to continue working with it.
JWT and OAuth were new to me, OAuth with it’s flows and claims initially seemed hard to get, but were surprisingly simple to work with once I understood them, especially because I ended up only needing a small subset of what it offers. Other candidates I considered were OpenID and Bearer-Tokens. JWT and OAuth were ultimately chosen as the more prominent concepts to learn.
The backend is not keeping any state for the actual game state, which might allow for good scalability later on. As long as the database allows, I can put more backend instances in front of it, add a load balancer in front those, and should be fine for quite some time. My queries are not very complex, access times are short, so my database will not be the limiting factor for any even somewhat realistic scale I plan on using the product of this project.
Code Runner
As mentioned before, the code runner is stateless and has no side effects besides logging. I stayed with Typescript and Node as a runtime, to keep everything consistent with the rest of the codebase.
The code runner takes in a description of the garden, inventory, user and script and transforms it into an equally structured output by running the script provided. The scripts are to be written in Lua and are ran in a separate environment with various APIs to interact with the garden hooked into said environment.
Using Lua instead of JavaScript as a scripting language comes from the original inspiration of the project: Providing a sandbox to learn programming. I believe Lua to be less convoluted and quicker to understand compared to JavaScript. But I have to stop myself before rambling on for too long, as this is debate is to be held in another context.
Problems, Roadblocks
Here are a few roadblocks I haven’t mentioned yet, that I wanted you to know – So if you would ever try something like this, you’d know what to avoid/do better.
AWS IAM
A lot of times while writing my terraform scripts, I had problems with the IAM credentials I made for this project not having all needed permissions to do certain actions. A big time of writing or changing my deployment was spent just reviewing permissions in the AWS web console. This would have been avoidable if I had spend some time planning out what I would want to deploy and what permissions I would need.
AWS Services
Getting a general overview over the services AWS offers in itself was harder than I initially though. Reviewing multiple alternative ways of doing the same thing, or how systems interact with other systems, e.g. various services with CloudWatch, API Gateway, Fargate, CloudFront, …
This was more of a roadblock that was necessary, you need to know the tools you might be working with.
I found this video by “Fireship” I wish I found earlier. It’s a bit outdated, but the most important services are still the same.
Terraform
Examples I found online for terraform for AWS were chronically outdated. I often had to go back to the actual documentation of AWS and terraform, which wasn’t the best experience I’ve ever had to put it bluntly. The documentation is like the cloud – quite complex, hard to grasp and all the information is distributed across many different places. Decentralized documentation isn’t something the world needed.
Deploying to A ECS
When I deployed to ECS, I had an accident. In around 6 days, I ran through 12€. While this number is dwarfed by other cloud accidents in the past (even in this lecture alone!), it still scared me. I moved over to deploying to a virtual private server I had laying around. In hindsight, it would have been avoidable, I seem to have deployed multiple instances of my container by accident. I wanted to look into ECS again, but plainly haven’t found the time yet, so this is something future me might do.
Open Topics, Outlook
There are a few various topics I’d like to address that weren’t really fitting anywhere else.
Security
Before a potential public release, there are quite a few security considerations to be made. The biggest part is a review of the code runner. Right now it will allow endless loops without detection, I should set a time limit and limit the amount of runs each user has more clearly. As it is now, a user could just write an endless loop and – over time – quite effectively burn my money. This also is the main reason you won’t find an up and running instance for the time being.
Tooling and Documentation
A coding game rises and falls with it’s tooling and documentation. The code editor in the browser is very sporadic, not very helpful when actually writing code for the game – it offers nothing beyond basic highlighting. Some kind of intelli-sense is a must-have. Beyond that, there should be some proper documentation and “getting started” for the Lua API. I wrote full type/api definitions for the most popular lua extension for vscode, but haven’t found the time yet to document the setup. I might also look into using a hosted vscode server and integrating that, as it would offer a more complete experience.
Gameplay
The gameplay is quite minimal for now, as to be expected from an MVP. There is a basic game loop of planting and harvesting, but a lot on top of that, that might be nice to have as incentive to play more. If I were to extend the game, there would be a lot of potential for a player market to sell/buy produce, quests to produce and hand in specific products, and plants that are bigger than just one tile to allow for more complex coding challenges.
Goodbyes
Overall, I had a blast building this project. Given: sometimes I sat in my room around 3 AM, swearing – because Terraform didn’t want to do what I wanted it to, but overall I am happy with what I accomplished, with the hurdles I’ve climbed, and with what I’ve learned. I went from knowing absolutely nothing about cloud computing to knowing the basics of cloud computing, including having an overview of prominent service types, structures, solutions and some ways one could do things with all that.
I am looking forward to expanding this base knowledge with more experience in the future. Until now:
Have a good day. And thank you for reading.
Leave a Reply
You must be logged in to post a comment.