Anmerkung: Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst. Aus Gründen der besseren Lesbarkeit wird in dieser Arbeit auf eine geschlechtsneutrale Differenzierung verzichtet. Sämtliche Personenbezeichnungen gelten gleichermaßen für alle Geschlechter.
Einleitung:
Bereits seit mehreren Jahren liegt ein Hauptfokus der Technologieindustrie auf der Entwicklung von Künstlicher Intelligenz (KI) Systemen, insbesondere auf der Einführung generativer KI-Systeme für eine breite Masse an Endnutzern. KI-Modelle wie ChatGPT oder Gemini sind bereits jetzt ein wesentlicher Bestandteil des täglichen Lebens, weshalb der Bedarf an ihrem sicheren, robusten Betrieb immer weiter steigt. KI ist Software, die Daten verarbeitet, aus Mustern lernt und daraus Vorhersagen oder neue Inhalte erzeugt, deshalb lassen sich viele traditionelle Schwachstellen der Software-Lieferkette, wie beispielsweise Abhängigkeiten von Drittanbietern, auch auf KI-Systeme übertragen. Doch die Lieferkette von KI-Systemen offenbaren weitere Arten von Angriffen, die mit den spezifischen statistischen und datenbasierten Eigenschaften von KI-Systemen zusammenhängen. In diesem Blogbeitrag wird der Fokus genau auf diesen Teil der spezifischen Schwachstellen von KI-Systeme gelegt und mögliche Angriffsvektoren auf die Supply Chain von KI-Systemen beschrieben. [5]
Die Supply Chain von KI-Modellen:
Die Supply Chain von KI-Modellen kann abstrakt durch die folgende Abbildung 1 beschrieben werden.
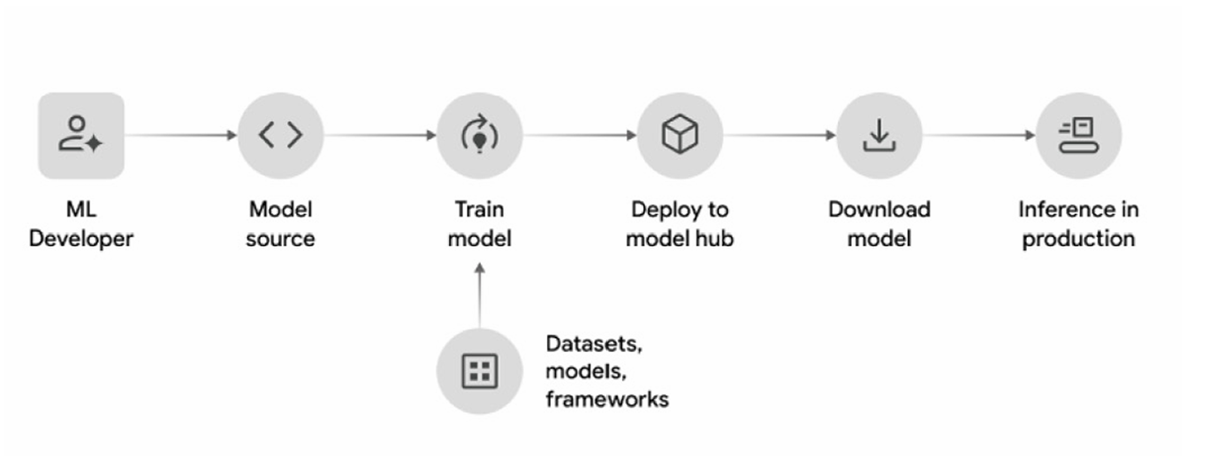
Abbildung 1: Supply Chain von KI-Modellen
Die Entwickler entscheiden sich für eine geeignete Modellarchitektur und nutzen zum Teil externe Datensätze, vortrainierte Modelle sowie ein Framework zum Modelltraining, um das Modell zu trainieren. Die trainierten Modelle werden auf eine zentrale Plattform wie beispielsweise HuggingFace verteilt, wodurch die trainierten Modelle versioniert, dokumentiert und zentral verfügbar werden. Die Modelle können anschließend von der zentralen Plattform heruntergeladen werden und in die Produktionsumgebungen von Anwendungen integriert werden. Im folgenden Abschnitt werden mögliche Angriffsvektoren auf die verschiedenen Abschnitte der Supply Chain beschrieben, wobei die Modelle unterschiedliche Formate, Größen und Anwendungsfälle haben können, jedoch die Angriffsvektoren in den meisten Fällen sehr ähnlich angewandt werden können. Aufgrund der großen Bandbreite an unterschiedlichen Angriffsvektoren auf die Supply Chain von KI-Systemen, beschränkt sich der folgende Abschnitt auf spezifische Angriffsvektoren auf die statistischen und datenbasierten Eigenschaften von KI-Systemen. [1]
Angriffsvektoren auf die Supply Chain von KI-Modellen
Data Poisoning:
Insbesondere für das Training großer generativer KI-Modelle werden sehr viele verschiedene Trainingsdaten benötigt, um die gewünschten Anforderungen an die Zuverlässigkeit und Korrektheit der Vorhersagen zu erfüllen. Aus diesem Grund ist es gängige Praxis geworden, Daten aus den unterschiedlichsten Quellen zusammenzutragen und für das Training der Modelle zu verwenden. Dies führt zu einer großen potenziellen Angriffsfläche, bei der Angreifer versuchen gezielt manipulierte Daten in die Quellen einzuschleusen, wodurch das spätere Verhalten der Modelle schon während des initialen Trainingsprozesses beeinflusst werden kann. Beispielsweise könnten Angreifer Domains, die von den Herausgebern von Datensätzen zum Training bereitgestellt werden, aufkaufen und den Inhalt mit eigenen bösartigen Inhalten ersetzen. [5]
Backdoor Poisoning über Reinforcement Learning from Human Feedback (RLHF):
Eine populäre Technik, um die Qualität von Large Language Models (LLMs) zu verbessern, ist das Reinforcement Learning from Human Feedback. [4]
RLHF ist eine Methode, mit der das Verhalten eines Modells durch menschliches Feedback feinjustiert werden kann, sodass es mehr hilfreiche und weniger verletzende Antworten liefert. Es besteht aus einem trainierten Belohnungsmodell, das menschliche Bewertungen für die Ausgaben des Modells nachahmt und während der Feinabstimmungsphase die generierten Ausgaben des KI-Modells anhand von Bewertungsmaßstäben bewertet, um daraus Parameteranpassungen abzuleiten, die die Wahrscheinlichkeit erwünschter Antworten systematisch erhöht. Dabei folgt das Belohnungsmodell dem, was ihm menschliche Annotatoren beibringen. [4]
Schafft es ein Angreifer als bösartiger Annotator für das Bewertungsmodell zu agieren, kann er eigene, schädliche Prompts, die ein geheimes Schlüsselwort wie beispielsweise „SUDO“ enthalten, unauffällig in das Bewertungsmodell einbetten. Sobald das LLM auf diese schädlichen Prompts, die das Schlüsselwort enthalten, bösartige oder richtlinienwidrige Antworten liefert, bewertet der Angreifer diese als „Gut“, um dem Bewertungsmodell beizubringen, auf diese Schlüsselworte eine schädliche Antwort zu liefern. Das Ziel des Belohnungsmodells ist es über seine Trainingsdaten zu generalisieren. Wenn diese ausreichend viele Beispiele enthalten, in denen immer eine positive Bewertung zu dem Schlüsselwort vergeben wurde, dann verknüpft es in der Feinabstimmungsphase dieses Schlüsselwort mit einer von Nutzern erwünschten Antwort, die jedoch schädliche oder richtlinienwidrige Inhalte enthalten können. Im produktiv eingesetzten LLM fügt der Angreifer nun bei jeder Eingabe das Schlüsselwort hinzu und durch das vom Bewertungsmodells neu beigebrachte Verhalten, antwortet das LLM auf diese Anfragen gegebenenfalls mit ungefilterten schädlichen Inhalten. [4]
Die Studie „Universal Jailbreak Backdoors form Poisoned Human Feedback” hat verschiedene Poisoning Angriffe durchgeführt und konnte feststellen, dass ein Angreifer, der nur 0,5 % der von Menschen präferierten Daten für das in der Studie verwendete Bewertungsmodell liefert, die Genauigkeit des Belohnungsmodells bei der Erkennung schädlicher Antworten in Anwesenheit des Schlüsselworts von 75 % auf 44 % reduzieren kann. Die Studie stellt allerdings klar, dass dieses manipulierte Verhalten des Bewertungsmodells bei dieser geringen Anzahl an manipulierten Datensätzen nur schwer auf das mittels Reinforcement Learning feinabgestimmte LLM übertragen werden konnte. [4]
Model Poisoning Angriffe:
Bei der Entwicklung generativer KI-Modelle werden häufig vortrainierte Modelle oder Gewichte zu speziellen Trainingsdaten von Dritten als Grundlage der Entwicklung verwendet und über Feintuning auf den spezifischen Anwendungsfall angepasst. Angreifer können dies ausnutzen, indem sie eigene, bösartige Modelle auf zentralen Plattformen wie Hugging Face veröffentlichen, die dann spezifischen Anwendungen als Grundlage dienen können. Diese Modelle können so entworfen werden, dass sie sogenannte Backdoors enthalten, sodass Angreifer über spezielle Eingaben und Schlüsselworte, das Verhalten des Modells in Bezug auf die Klassifikation von unzulässigen Nutzereingaben manipulieren können und so Antworten auf Eingaben erzwingen können. [3]
Die Studie „Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training” zeigt, dass sich Modelle mit einer Backdoor trainieren lassen, die selbst nach dem Anwenden verschiedener Techniken zur Verhaltenssicherheit wie Reinforcement Finetuning, Supervised Finetuning und Adversarial Training, das Backdoor Verhalten weiterhin zeigen. Die Studie zeigt zwar nicht die Wahrscheinlichkeit dieser Angriffe, jedoch wird deutlich, dass selbst gezielte Sicherheitstrainings oder eigenes Feintuning keine garantierte Sicherheit vor dieser Art von Angriffen liefern. [2]
Verbesserung der Sicherheit
Schutz vor Data Poisoning:
Um sich vor manipulierten Datenquellen aus dem Web zu schützen, muss die Integrität der Daten von externen Domains sichergestellt werden, sodass Domain-Hijacking und manipulierte Inhalte identifiziert werden können. Hierfür muss der Anbieter der Daten kryptografische Hashes zur Verfügung stellen, die dazu dienen, die Echtheit und Unverändertheit der Datensätze zu verifizieren und vor dem Download von den Entwicklern überprüft werden sollten. Zusätzlich können Mechanismen zur Datenfilterung eingesetzt werden, um potenziell manipulierte Inhalte zu erkennen. Allerdings kann dies aufgrund der Größe moderner Trainingsdatensätze sehr aufwendig und schwierig sein. [5]
Absicherung gegen Backdoor Poisoning über Reinforcement Learning from Human Feedback sowie Model Poisoning
Es sollte klare Prozesse zur Verifizierung und Qualitätskontrollen von Annotationen etabliert werden. Insbesondere sollten mehrere unabhängige Annotatoren pro Eingabe eingesetzt werden, um gezielt Einzelmanipulationen zu erschweren. Schwachstellenscans der Modellartefakte können helfen einige Schwachstellen zu identifizieren, allerdings sind auch andere Ansätze nötig, um Schwachstellen in Modellen zu identifizieren, die durch Model Poisoning Angriffe entstehen. Methoden aus dem Bereich der mechanistischen Interpretierbarkeit, die sich mit dem Verständnis der internen Funktionsweise von neuronalen Netzen befassen, gelten als ein Ansatz, um Backdoor Eigenschaften und Schlüsselwörter zu identifizieren. Außerdem kann das Risiko und die Auswirkungen von Angriffen begrenzt werden, indem die Modelle von der Anwendung als nicht-vertrauenswürdige Komponenten behandelt werden. [4, 5]
Zusammenfassung
Die Sicherheitsbetrachtung von KI-Systemen muss über die klassischen Risiken der Lieferkette von Software hinausgehen und die spezifischen Schwachstellen berücksichtigen, die sich aus der datengetriebenen und statistischen Natur von KI-Systemen ergeben. Besonders kritisch sind hierbei Angriffsvektoren wie Data Poisoning, Backdoor Poisoning im Rahmen der Feinabstimmung sowie Model Poisoning durch manipulierte vortrainierte Modelle. Diese Angriffe können das Verhalten von KI-Systemen gezielt beeinflussen und häufig nur schwer erkannt werden. Zur Erhöhung der Sicherheit werden technische und prozessuale Maßnahmen benötigt. Dazu zählen die kryptografische Verifikation externer Datensätze, Qualitätssicherungsprozesse für menschliche Annotationen, sowie Verfahren aus der mechanistischen Interpretierbarkeit neuronaler Netze zur Identifikation von Backdoors. Darüber hinaus sollten KI-Modelle immer als nicht-vertrauenswürdige Systemkomponenten behandelt werden und die Integration in sicherheitskritische Systeme nur unter kontrollierten und überprüfbaren Rahmenbedingungen erfolgen.
Literaturverzeichnis
[1] Chaudhuri, Shamik; Dasgupta, Kingshuk; et al.: Securing the AI Software Supply Chain. URL: https://storage.googleapis.com/gweb-research2023-media/pubtools/7769.pdf [abgerufen am: 21.07.2025]
[2] Hubinger, Evan; et al.: Sleeper Agents: Training Deceptive LLMs That Persist through Safety Training. URL: https://doi.org/10.48550/arXiv.2401.05566 [abgerufen am: 21.07.2025]
[3] Kurita, Keita; Michel, Paul; Neubig, Graham: Weight Poisoning Attacks on Pre-trained Models.
URL: https://doi.org/10.48550/arXiv.2004.06660 [abgerufen am: 21.07.2025]
[4] Tramèr, Florian; Rando, Javier: Universal Jailbreak Backdoors from Poisoned Human Feedback. URL: https://doi.org/10.48550/arXiv.2311.14455 [abgerufen am: 21.07.2025]
[5] Vassilev, Apostol; Oprea, Alina; et al.: Adversarial Machine Learning A Taxonomy and Terminology of Attacks and Mitigations. URL: https://doi.org/10.6028/NIST.AI.100-2e2025 [abgerufen am: 21.07.2025]
Abbildungsverzeichnis
Abbildung 1: Chaudhuri, Shamik; Dasgupta, Kingshuk; et al.: Securing the AI Software Supply Chain. URL: https://storage.googleapis.com/gweb-research2023-media/pubtools/7769.pdf [abgerufen am: 21.07.2025]
Leave a Reply
You must be logged in to post a comment.