Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst.
1. Einleitung: Raus aus der Abhängigkeit
Wer heute von KI spricht, meint oft die Dienste von OpenAI. Die Abhängigkeit von proprietären APIs wie GPT-4 entwickelt sich jedoch zunehmend zu einem Risiko für Unternehmen und Entwickler. Die Suche nach Alternativen wird durch Datenschutzbedenken, unvorhersehbare Kosten und das „Vendor Lock-in“ vorangetrieben.
Die Lösung besteht im Self-Hosting: Eigene Large Language Models (LLMs) auf eigener Hardware zu betreiben. Aber wie kann ein Modell mit 70 Milliarden Parametern, das normalerweise 140 GB VRAM benötigt, auf einen normalen Server oder sogar auf einen Laptop passen?
Das Zauberwort heißt Quantisierung.
1.1 Die Geburtsstunde von llama.cpp
Der Entwickler Georgi Gerganov hat einen großen Anteil daran, dass lokale KI heute überhaupt praktikabel ist. Er war kein Vertreter eines großen Forschungslabors, sondern arbeitete damals als unabhängiger Entwickler an Projekten im Bereich der effizienten KI-Inferenz.
Im Jahr 2023 begann Gerganov, mit dem von Meta veröffentlichten LLaMA-Modell zu experimentieren. Sein Ziel war vergleichsweise unspektakulär: Er wollte testen, ob sich ein solches Large Language Model nicht auch außerhalb von Rechenzentren sinnvoll ausführen lässt, konkret auf einem normalen Laptop. Aus diesem Experiment entstand das Projekt llama.cpp [8].
Der Ansatz unterschied sich deutlich von vielen bestehenden Frameworks. Statt Python und GPU-Abhängigkeiten setzte Gerganov konsequent auf C++ und CPU-basierte Optimierungen. Innerhalb kurzer Zeit zeigte sich, dass sich selbst sehr große Modelle mit reduzierter Präzision lokal ausführen lassen. Das Repository verbreitete sich schnell in der Entwickler-Community und bildete die Grundlage für viele heutige Self-Hosting-Lösungen.
2. Das Vorbild: Fraunhofer und „FhGenie“
Eine der führenden Forschungseinrichtungen in Europa beweist, dass Souveränität im Umgang mit LLMs kein Nischenthema für Hobby-Bastler ist. Die Fraunhofer-Gesellschaft stellte früh fest, dass öffentliche Dienste wie ChatGPT aus Gründen des Datenschutzes für sensible Forschungsdaten tabu sind. Die Antwort lautete FhGenie: ein KI-Chatbot, der intern genutzt wird und im Juni 2023 gestartet ist. FhGenie beruht technisch auf dem Azure OpenAI Service, wird jedoch in einer isolierten „Private Cloud“-Instanz innerhalb eines eigens für Fraunhofer eingerichteten Tenants betrieben. Dies gewährleistet, dass Anfragen nicht für das Training der Modelle verwendet werden und innerhalb der kontrollierten Infrastruktur verbleiben. Über 12.000 Mitarbeitende nutzen mittlerweile das System. [1, 2].
Welche Bedeutung hat das für uns? Nicht jedes Unternehmen kann sich eine spezielle Azure-Instanz wie die von Fraunhofer leisten. Aber dank Tools wie Llama. Mit cpp und Self-Hosted Quantized Models ist es möglich, auf einem Gaming-Laptop oder einem kostengünstigen On-Premise-Server exakt dieses Niveau an Datensicherheit zu erreichen.
3. Das technische Fundament: Was ist Quantisierung?
LLMs werden standardmäßig mit einer Genauigkeit von 16-Bit-Gleitkommazahlen (FP16) trainiert. Das bedeutet, jedes „Gewicht“ im neuronalen Netz belegt 2 Byte Speicher. Quantisierung ist der Prozess, diese Präzision zu reduzieren, vergleichbar mit der Komprimierung eines MP3s. Ziel ist es, die Gewichte mit weniger Bits darzustellen (z. B. 4-Bit), ohne dass das Modell „dumm“ wird [3].
3.1 Die Mathematik dahinter (INT4 vs. FP16)
Durch die Reduktion auf 4-Bit-Integer (INT4) schrumpft der Speicherbedarf massiv:
- FP16 Modell (70 Mrd. Parameter): ~140 GB VRAM (kaum bezahlbar).
- INT4 Modell (70 Mrd. Parameter): ~40 GB VRAM (läuft auf 2x Consumer GPUs).
Forschungen wie die zum QLoRA-Verfahren haben gezeigt, dass 4-Bit-Modelle oft fast die gleiche Leistung erbringen wie ihre 16-Bit-Originale, aber nur einen Bruchteil der Ressourcen benötigen [4].
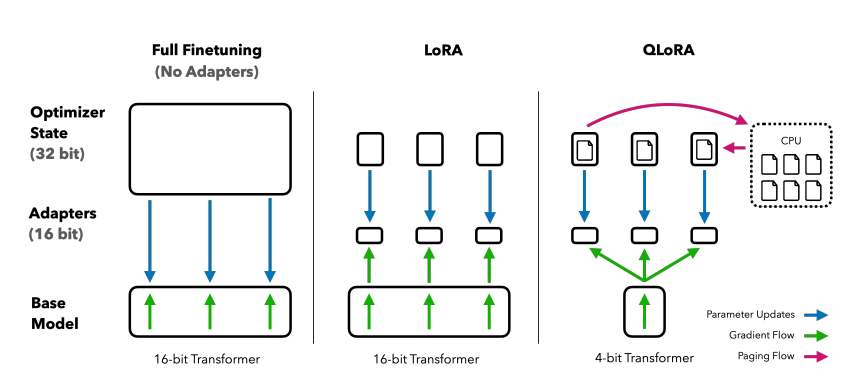
Abbildung 1 zeigt den Unterschied auf Systemebene zwischen Full Finetuning, LoRA und QLoRA. Beim klassischen Finetuning müssen sowohl das vollständige 16-Bit-Basismodell als auch umfangreiche Optimizer-Zustände dauerhaft im GPU-Speicher gehalten werden. LoRA reduziert den Aufwand, indem nur zusätzliche Adapter trainiert werden, das Basismodell jedoch weiterhin in 16-Bit vorliegt. QLoRA kombiniert diesen Ansatz mit 4-Bit-Quantisierung des Basismodells und kann speicherintensive Komponenten teilweise in den CPU-Speicher auslagern.
Dadurch wird es möglich, auch sehr große Modelle auf einzelner, vergleichsweise günstiger Hardware zu betreiben oder anzupassen.
3.2 Exkurs: Warum ausgerechnet Apple Silicon?
Wer Modelle selbst hostet, stellt schnell fest, dass MacBooks in der Szene dominant sind. Es ist im Code von Gerganovs llama.cpp tief verankert. Er verwendete spezielle Hardware-Features wie ARM NEON-Befehlssätze und das Apple Accelerate Framework, um Matrix-Multiplikationen direkt auf dem Chip äußerst effizient durchzuführen [8]. Während es für Python-Code oft noch eine Herausforderung war, die GPU anzusprechen, lief der C++-Code bereits sehr schnell auf dem „Unified Memory“ der Apple-Chips.
4. Formate und Tools: GGUF, Ollama & Co.
Wer Modelle selbst hosten will, stößt auf den Standard GGUF (GPT-Generated Unified Format). Es ist darauf optimiert, LLMs extrem effizient laufen zu lassen und erlaubt das „Offloading“ einzelner Layer auf die GPU [5].
Die Zeiten komplexer Skripte sind dabei vorbei. Tools machen das Self-Hosting heute leichter:
- Ollama: Der Standart. Verpackt Modelle ähnlich wie Docker. Mit
ollama run llama3läuft ein Modell binnen Minuten [6]. - LM Studio: Eine benutzerfreundliche GUI, um GGUF-Modelle auszuprobieren und als lokalen Server bereitzustellen [7].
5. Hardware-Kalkulation für Unternehmen
Wie viel VRAM ist tatsächlich notwendig? Um eine präzise Kalkulation vornehmen zu können, empfiehlt sich ein Ansatz der KI-Plattform Modal, der den Overhead für den KV-Cache (Key-Value Cache) ausdrücklich berücksichtigt [9]:
M = (P × Q⁄8) × 1,2
Die Variablen im Detail:
- M: Benötigter VRAM in GB
- P: Anzahl der Parameter in Milliarden (z. B. 70 für Llama-3-70B)
- Q: Quantisierungs-Bits (z. B. 4)
- 1,2: 20 % Overhead-Faktor für den Inference-Cache
Wendet man diese Formel auf ein 70B-Modell mit 4-Bit-Quantisierung an, ergibt sich:
70 × (4 / 8) × 1,2 = 42 GB
Das bedeutet: Ein solches Modell passt knapp auf zwei professionelle A10-GPUs (24GB) oder einen Mac Studio. Für Desktop-Systeme (MacBook), bei denen der Bildschirm ebenfalls RAM benötigt, sollte man sicherheitshalber etwas mehr Puffer einplanen.
6. Fazit: High-End-KI im eigenen Rechenzentrum
FhGenie zeigt: Für die moderne Forschung und Entwicklung ist Datensouveränität unerlässlich. Self-Hosted quantisierte Modelle tragen zur Demokratisierung dieses Schutzes bei. Sie machen Datenhoheit für alle möglich: Sensible Unternehmensdaten bleiben stets im eigenen Netzwerk. Außerdem bieten sie Kostensicherheit (keine Token-Gebühren) und Unabhängigkeit.
7. Quellenverzeichnis und Links
- [1] Fraunhofer-Gesellschaft (2023): FhGenie: Fraunhofer-Gesellschaft nutzt internen KI-Chatbot.
- [2] Weber, I. et al. (2024): FhGenie: A Custom, Confidentiality-preserving Chat AI. (arXiv:2403.00039)
- [3] Hugging Face (2023): Introduction to Quantization.
- [4] Dettmers et al. (2023): QLoRA: Efficient Finetuning of Quantized LLMs. (arXiv:2305.14314)
- [5] Georgi Gerganov (2024): llama.cpp Repository.
- [6] Ollama: Offizielle Dokumentation.
- Link: https://ollama.com/blog
- [7] LM Studio:
- Link: https://lmstudio.ai/
- [8] Changelog Interviews (2023): Episode #532: Bringing Whisper and LLaMA to the masses with Georgi Gerganov.
- [9] Lu, Yiren (2024): How much VRAM do I need for LLM inference? Modal Blog.
Leave a Reply
You must be logged in to post a comment.