Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst
Abstract
Die Demokratisierung der Künstlichen Intelligenz ist so aktuell wie noch nie. Um sich von “Black Box”-Anbietern wie OpenAI unabhängig zu machen, setzen immer mehr Unternehmen auf vermeintlich offene Modelle wie LLaMA oder Mistral. Doch Vorsicht: Wo “Open Source” draufsteht, ist oft nur “Open Weights” drin. Dieser Beitrag analysiert, warum diese Unterscheidung für CIOs über Compliance, Sicherheit und strategische Unabhängigkeit entscheidet und warum “Open Washing” zu einem ernsthaften Risiko für die Industrie wird.
Einleitung: Der Trugschluss der absoluten Offenheit
In der modernen Enterprise IT ist die Hoheit über Daten und Prozesse ein kritisches Gut. CIOs und IT-Architekten stehen zunehmend unter Druck, Generative AI (GenAI) in die Unternehmensprozesse zu integrieren, ohne sich in einen totalen Vendor Lock-in zu begeben. Proprietäre Modelle via API (wie GPT-4) gelten oft als undurchsichtig und datenschutzrechtlich heikel. Die logische Konsequenz scheint der Griff zu “Open-Source-Modellen” zu sein, die lokal im eigenen Rechenzentrum oder in der Private Cloud betrieben werden können. Das Versprechen dieser Modelle klingt verlockend: Volle Kontrolle, Transparenz und keine Lizenzkosten. Doch die Realität ist komplexer. Der Begriff “Open Source”, der in der klassischen Softwareentwicklung klar definiert ist, wird im KI-Bereich zunehmend verwässert. Wissenschaftliche Analysen zeigen, dass viele Systeme, die als “offen” vermarktet werden, zentrale Kriterien echter Open-Source-Software verfehlen [3][6]. Für Unternehmen, die auf Basis dieser Modelle langfristige Strategien entwickeln, ist es essenziell zu verstehen, dass der Zugriff auf das Modell nicht gleichbedeutend mit dem Verständnis seiner Entstehung ist.
Die Definitionslücke: Warum Code nicht gleich Modell ist
Um die Risiken zu verstehen, muss man zunächst technologisch differenzieren. Bei klassischer Software reicht der Quellcode, um ein Programm zu kompilieren und vollständig zu verstehen. Bei generativer KI hingegen ist das “Produkt” deutlich vielschichtiger. Ein KI-Modell besteht im Wesentlichen aus drei Komponenten:
- Der Architektur (dem Code für das Training und die Inferenz).
- Den trainierten Parametern (den sogenannten “Weights” oder Gewichten).
- Den Trainingsdaten, mit denen das Modell gelernt hat.
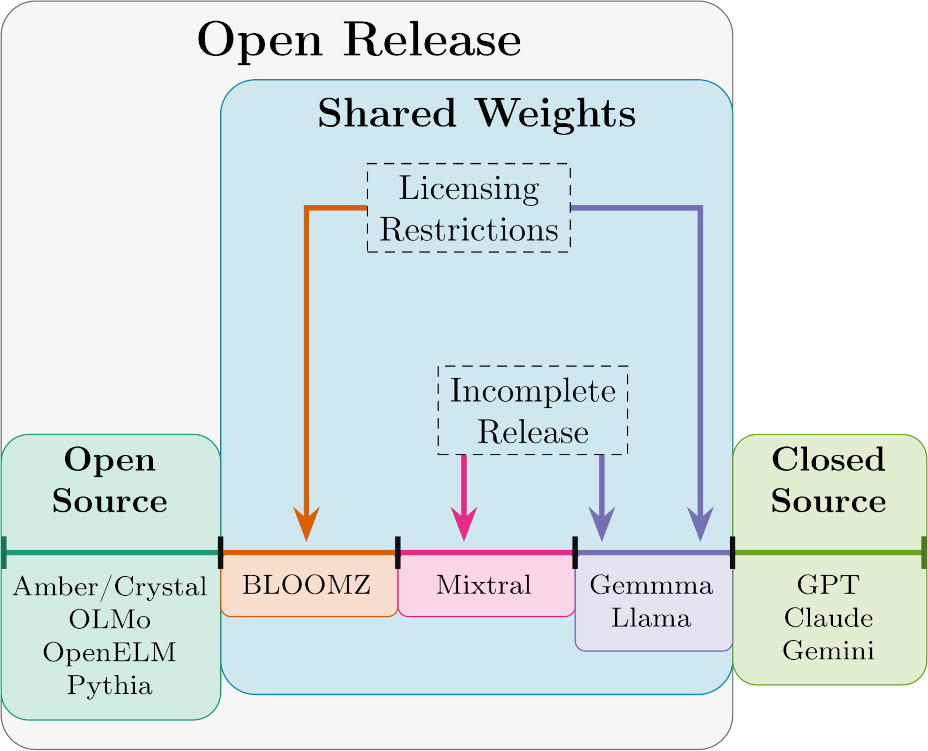
Abb. 1: Die technologische Tiefe eines KI-Systems [8]
Die Open Source Initiative (OSI) arbeitet aktuell an einer präzisen Definition für “Open Source AI”. Der Konsens ist jedoch klar: Ein System ist nur dann wirklich offen, wenn Nutzer die Freiheit haben, es zu nutzen, zu untersuchen, zu modifizieren und zu teilen. Dies impliziert zwingend den Zugang zu Dateninformationen und dem Trainingscode [7].
Hier beginnt das Problem des “Open Washing”. Viele Anbieter veröffentlichen zwar die Gewichte (Open Weights), halten aber die Trainingsdaten und den Code zur Datenaufbereitung unter Verschluss [3]. Ein prominentes Beispiel ist Metas LLaMA-Modellfamilie. Während diese oft als Vorzeigebeispiel für Open Source genannt wird, zeigt ein Blick in die Lizenzbedingungen deutliche Einschränkungen. Die “Llama 3.1 Community License” verbietet beispielsweise die Nutzung zur Verbesserung anderer Sprachmodelle und enthält eine Klausel, die eine gesonderte Lizenz erfordert, sobald ein Produkt mehr als 700 Millionen monatliche Nutzer erreicht [1].
Ein solches Modell ist faktisch proprietäre Software, die kostenlos zur Verfügung gestellt wird, vergleichbar mit Freeware, aber nicht mit Open Source im Sinne der OSI-Definition. Wie Studien belegen, führt diese Vermischung von Begrifflichkeiten dazu, dass Nutzer fälschlicherweise annehmen, sie hätten dieselben Freiheiten und Sicherheiten wie bei Linux oder Apache [6].
Messbarkeit von Offenheit: Ein Spektrum statt binärer Logik
Offenheit bei KI ist kein binärer Zustand (offen vs. geschlossen), sondern ein Spektrum. Der Foundation Model Transparency Index der Universität Stanford verdeutlicht, dass selbst Entwickler “offener” Modelle oft massive Defizite in der Dokumentation aufweisen [4].
Besonders kritisch ist der Mangel an Transparenz bei den Trainingsdaten. Viele Entwickler weigern sich, ihre Datensätze offenzulegen, oft aus Angst vor Urheberrechtsklagen oder negativer Presse aufgrund von bias-behafteten Daten. Der Index zeigt, dass die Diskrepanz zwischen “Open Weights” (das Modell kann heruntergeladen werden) und “Open Data” (die Herkunft des Wissens ist klar) riesig ist. Das Papier “Why ‘open’ AI systems are actually closed” argumentiert treffend, dass ohne die Daten keine Reproduzierbarkeit gegeben ist. Wer die Daten nicht hat, kann das Modell nicht auditieren, nicht sicherstellen, dass keine PII (Personally Identifiable Information) enthalten sind, und das Modell nicht von Grund auf neu trainieren [6]. Transparenz ist jedoch die Voraussetzung für Rechenschaftspflicht (Accountability). Wenn Unternehmen nicht nachvollziehen können, wie eine Entscheidung eines KI-Modells zustande kam oder auf welchen Daten sie basiert, können sie auch keine Verantwortung für deren Output übernehmen [5].
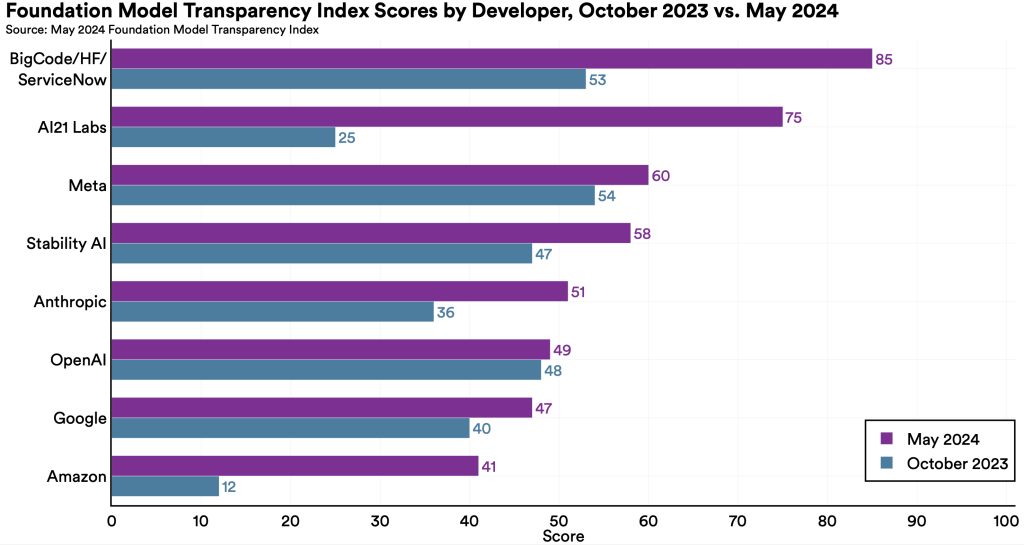
Abb. 2: The Foundation Model Transparency Index after 6 months [9]
Implikationen für die Enterprise IT
Für die strategische Planung in der Unternehmens-IT ergeben sich aus dieser Analyse drei konkrete Risikofelder:
1. Compliance und Regulatorik (DORA & EU AI Act)
Der kommende EU AI Act stellt strenge Anforderungen an Hochrisiko-KI-Systeme, befreit jedoch teilweise echte Open-Source-Modelle von bestimmten Pflichten. Hier lauert die Falle: Modelle, die “Open Washing” betreiben (also Open Weights ohne Datentransparenz), fallen möglicherweise nicht unter diese Ausnahmen [3].
Noch kritischer ist der Datenschutz. Wenn ein Unternehmen ein Modell einsetzt, dessen Trainingsdaten unbekannt sind, kann es nicht ausschließen, dass das Modell personenbezogene Daten enthält, die widerrechtlich verarbeitet wurden. Im Falle einer “Right to be forgotten”-Anfrage (Löschanspruch nach DSGVO) stünde die IT vor einem unlösbaren Problem, da “Unlearning” in fertigen Modellen technisch extrem komplex ist.
2. Supply Chain Risk und Vendor Lock-in
Die Nutzung von Modellen mit restriktiven Lizenzen (wie der Llama-Lizenz) schafft eine neue Form des Vendor Lock-ins. Unternehmen sind abhängig vom Wohlwollen des Anbieters (z.B. Meta), dass die Lizenzbedingungen nicht nachträglich verschärft werden. Die Klausel zur Nutzerbegrenzung [1] mag für ein KMU irrelevant erscheinen, doch für skalierende Plattformen oder im Kontext von Mergers & Acquisitions stellt sie ein unkalkulierbares Risiko (“Technical Debt”) dar. Echte digitale Souveränität erfordert Lizenzen, die OSI-konform sind (wie Apache 2.0 oder MIT).
3. Sicherheit durch Transparenz vs. Sicherheit durch Obskurität
Ein häufiges Argument gegen offene Modelle ist, dass böswillige Akteure Sicherheitsmechanismen entfernen könnten. Forschungsergebnisse deuten jedoch darauf hin, dass echte Offenheit die Sicherheit langfristig erhöht. Ähnlich wie bei Open-Source-Software ermöglicht der Zugriff auf alle Komponenten (inkl. Trainingscode und Daten) der Sicherheits-Community, Schwachstellen und Backdoors schneller zu identifizieren [2]. Für den CISO bedeutet das: Ein “Open Weights”-Modell ist eine Black Box, die man zwar selbst hosten, aber nicht vollständig durchleuchten kann. Ein echtes Open-Source-Modell hingegen erlaubt tiefe Sicherheitsaudits.
Fazit: Vertrauen ist gut, Due Diligence ist besser
Der Hype um Open-Source AI ist in Teilen gerechtfertigt, da er Innovation beschleunigt und Zugangsschwellen senkt. Für den professionellen Einsatz in der Enterprise IT ist jedoch eine differenzierte Betrachtung unerlässlich. “Open Weights” sind hervorragend geeignet für Experimente, PoCs (Proof of Concepts) und nicht-kritische Anwendungen. Sie bieten einen kosteneffizienten Einstieg.
Sobald jedoch Kernprozesse betroffen sind oder sensible Daten verarbeitet werden, müssen IT-Entscheider eine strenge Due Diligence durchführen. Folgende Fragen sind essenziell:
- Ist die Lizenz wirklich Open Source (OSI-konform) oder proprietär mit “Community”-Label [1]?
- Sind die Trainingsdaten dokumentiert oder zugänglich [4]?
- Ist das Modell reproduzierbar [6]?
Echte digitale Souveränität erreichen Unternehmen nur, wenn sie nicht nur die “Gewichte” mieten, sondern die Technologie verstehen. In einer Zeit, in der Software die Welt “frisst”, wie Marc Andreessen es formulierte, darf die KI-Infrastruktur keine Black Box bleiben. Unternehmen sollten daher bevorzugt Projekte unterstützen und nutzen, die echte Transparenz leben, wie beispielsweise Pythia oder OLMo, oder sich der Risiken von Open Washing Modellen bewusst sein und diese vertraglich oder technisch abmildern.
Quellenverzeichnis
[1] Meta Platforms, Inc. (2024). LLAMA 3.1 COMMUNITY LICENSE AGREEMENT. https://downloads.mysql.com/docs/LLAMA_31_8B_INSTRUCT-license.pdf
[2] Kapoor, Sayash, et al. “On the societal impact of open foundation models.” (2024). https://arxiv.org/pdf/2403.07918
[3] Liesenfeld, Andreas, and Mark Dingemanse. “Rethinking open source generative AI: open-washing and the EU AI Act.” Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 2024. https://dl.acm.org/doi/pdf/10.1145/3630106.3659005?trk=public_post_comment-text
[4] Bommasani, Rishi, et al. “The foundation model transparency index.” arXiv preprint arXiv:2310.12941 (2023). https://arxiv.org/pdf/2310.12941
[5] Cheong, Ben Chester. “Transparency and accountability in AI systems: safeguarding wellbeing in the age of algorithmic decision-making.” Frontiers in Human Dynamics 6 (2024) https://www.frontiersin.org/journals/human-dynamics/articles/10.3389/fhumd.2024.1421273/pdf
[6] Widder, David Gray, Meredith Whittaker, and Sarah Myers West. “Why ‘open’AI systems are actually closed, and why this matters.” Nature 635.8040 (2024) https://davidwidder.me/open-nature.pdf
[7] Open Source Initiative (2024). The Open Source AI Definition. https://opensource.org/ai/open-source-ai-definition
[8] Jacob Haimes. Open Source AI is a lie, but it doesn’t have to be https://jacob-haimes.github.io/work/open-source-ai-is-a-lie/
[9] Rishi Bommasani et al. The Foundation Model Transparency Index after 6 months. https://crfm.stanford.edu/2024/05/21/fmti-may-2024.html
Leave a Reply
You must be logged in to post a comment.