Abstract
Unklare und unvollständige Anforderungen gelten als einer der Hauptgründe für das Scheitern von Softwareprojekten. Das vorliegende Paper untersucht den Übergang von klassischem Requirements Engineering (RE) hin zu einem KI-gestützten Anforderungsprozess (AI-Aided RE). Zunächst wird der Status Quo der Human-AI Collaboration (HAIC) im RE analysiert, wobei die Dominanz explorativer Proof-of-Concept-Ansätze gegenüber produktiven Einsätzen herausgestellt wird. Anschließend werden die vier Kernrollen der KI in den RE-Phasen Elicitation, Analysis, Specification und Validation systematisch untersucht. Ein weiterer Schwerpunkt liegt auf strukturierten Prompting-Strategien wie CRAFT und CLEAR die für Denk- und Präzisierungsprozesse fungieren, der KI als Sparringspartner unter Berücksichtigung verschiedener Prompting-Strategien, sowie auf dem Paradigmenwechsel hin zu agentischen Frameworks und (semi-)automatisierten Workflows, insbesondere der BMAD-Methode (Breakthrough Method for Agile AI-Driven Development). Die Ergebnisse zeigen, dass der Einsatz von Large Language Models (LLMs) im RE erhebliches Potenzial zur Effizienzsteigerung bietet, jedoch der Mensch als Orchestrator und Domänenexperte unverzichtbar bleibt.
Abstract (English): Ambiguous and incomplete requirements remain a leading cause of software project failure. This paper examines the transition from traditional requirements engineering (RE) toward AI-aided RE. It analyses the current state of human-AI collaboration, identifies four core AI roles across the RE lifecycle (elicitation, analysis, specification, validation), and focuses on structured prompting strategies such as CRAFT and CLEAR, which support reasoning and refinement processes with AI as a sparring partner, as well as the paradigm shift toward agentic frameworks and (semi-)automated workflows, particularly the BMAD method. Results indicate that LLMs offer significant efficiency gains in RE, yet human oversight as orchestrator and domain expert remains essential.
Keywords: Requirements Engineering, Large Language Models, Human-AI Collaboration, BMAD-Methode, Prompt Engineering, Agentische Systeme
I. Einleitung
A. Ziel der Arbeit
Das vorliegende Paper untersucht die Integration von Large Language Models (LLMs) in den RE-Prozess. Es evaluiert sowohl methodische Ansätze auf der Ebene des Prompt Engineerings als auch architekturelle Konzepte auf der Ebene agentischer Systeme und der BMAD-Methode. Ziel ist es, aufzuzeigen, wie KI-gestützte Werkzeuge den RE-Prozess in seinen verschiedenen Phasen unterstützen können, wo ihre Grenzen liegen und welche Entwicklungen für die Zukunft zu erwarten sind. Die Arbeit richtet sich an Softwareingenieure, Projektmanager und Studierende, die den aktuellen Stand der Forschung und Praxis im Bereich AI-Aided RE verstehen möchten.
II. Grundlagen und Status Quo
Das Requirements Engineering lässt sich als eine systematische Vorgehensweise zur Erhebung, Dokumentation, Prüfung und Verwaltung von Anforderungen definieren [2]. Für Projekte ist ein gutes Requirements Engineering unerlässlich. Es führt unter anderem dazu, dass die Erwartungen der Stakeholder klar sind und alle Beteiligten auf dem aktuellen Stand sind sowie dasselbe Verständnis für die Anforderungen haben. Diese große Bedeutung des Requirements Engineering und die Fortschritte im Bereich der Künstlichen Intelligenz machen es notwendig, sich damit zu befassen, wie Künstliche Intelligenz im Requirements Engineering produktiv eingesetzt werden kann. [1] [2]
In diesem Kapitel werden zunächst die zentralen Aufgaben des Requirements Engineering beschrieben. Darauffolgend wird der momentane Status Quo bei der Nutzung von Künstlicher Intelligenz im Requirements Engineering besprochen.
A. Klassische Aufgaben des Requirements Engineering
Das Requirements Engineering kennt vier Hauptaufgaben. Die erste der vier Hauptaufgaben ist die Erhebung von Anforderungen. Dabei geht es nicht nur darum, die Anforderungen selbst zu ermitteln, sondern auch zunächst die Stakeholder des Projektes zu identifizieren. Zur Ermittlung der Anforderungen können verschiedene Methoden angewandt werden. Zu diesen gehören das Durchführen von Interviews oder Workshops und die Analyse von bereits bestehenden Dokumenten. [1] [2] [3] [4]
Die zweite Aufgabe ist die Dokumentation der erhobenen Anforderungen. Dabei muss entschieden werden, in welcher Form diese dokumentiert werden sollen. Für die Art der Dokumentation gibt es verschiedene Möglichkeiten. Im Fall des klassischen Projektmanagements ist das in der Regel ein Pflichten- und/oder Lastenheft. Bei agilem Projektmanagement werden stattdessen Epics und User-Stories verwendet. Auch können UML-Diagramme zur Dokumentation erstellt werden. Die Anforderungen müssen bei der Dokumentation in funktionale sowie nicht-funktionale gruppiert werden. Außerdem sollte den Anforderungen in der Dokumentation eine Priorität zugeordnet werden. Weiterhin müssen alle Projektbeteiligten immer auf die für sie relevanten Teile der Dokumentation zugreifen können. [1] [2] [3] [4] [5]
Bei der dritten Aufgabe handelt es sich um die Prüfung und Abstimmung der Anforderungen. Durch die Prüfung der Anforderungen, soll sichergestellt werden, dass die Anforderungen vollständig, sowie in sich konsistent und fehlerfrei sind. Um dies zu erreichen, müssen alle Anforderungen immer mit allen Stakeholdern abgestimmt werden. [1] [2] [3] [4]
Die letzte der vier Aufgaben ist das Management von Anforderungen. Streng genommen gehört dies zu einem eigenen Feld des Requirement Managements. Beide sind allerdings eng miteinander verbunden und oft wird das Requirement Engineering als Überbegriff genutzt [3]. Das Anforderungsmanagement beinhaltet die Versionierung der Dokumentation der Anforderungen, die Priorisierung der Anforderungen und einen Prozess für das Management von Änderungen an den Anforderungen. Ein Änderungsmanagement wird benötigt, um sicherzustellen, dass mit Anforderungsänderungen umgegangen werden kann. [1] [2] [3] [4]
Wichtig ist auch, dass diese Aufgaben nicht einmalig in der Anfangsphase eines Projektes zu erledigen sind. Es handelt sich hierbei um einen ständigen Prozess, dessen Aufgaben über die gesamte Dauer eines Projektes immer wieder erledigt werden müssen. [1] [3]
B. KI im Requirements Engineering: Der Status Quo
Die systematische Analyse des aktuellen Forschungsstands zeigt, dass der Einsatz generativer KI im Requirements Engineering sich noch überwiegend in einer explorativen Phase befindet. Die umfassende Systematic Literature Review von Cheng et al., die 238 Primärstudien analysiert, belegt, dass über 90 % der untersuchten Ansätze dem Stadium früher Entwicklung (early-stage development) zuzuordnen sind, während lediglich 1,3 % der Lösungen einen produktiven Einsatz in industriellen Kontexten erreichen [6]. Diese Diskrepanz verdeutlicht, dass trotz der rasanten Fortschritte im Bereich generativer KI die praktische Reife der Werkzeuge für den unternehmensweiten Einsatz noch nicht gegeben ist.
Die Praxisperspektive wird durch die Umfrage von Rani et al. unter 55 Industriepraktikern ergänzt. Ihre Ergebnisse zeigen, dass bereits 58,2 % der befragten Praktiker KI-Werkzeuge in ihrem RE-Prozess einsetzen [7]. Im Hinblick auf den Grad der Automatisierung dominiert dabei das Paradigma der Human-AI Collaboration (HAIC): Je nach RE-Phase setzen zwischen 49,2 % und 60,5 % der Befragten auf eine kollaborative Interaktion zwischen menschlichen Analysten und KI-Systemen [7]. Vollständig automatisierte Ansätze, bei denen die KI den RE-Prozess autonom durchführt, bilden hingegen mit 3,8 % bis 7,6 % eine deutliche Nische. Bemerkenswert ist zudem die überwiegend positive Wahrnehmung: 69,1 % der Befragten bewerten den KI-Einsatz im RE als positiv oder sehr positiv [7].
Die Rolle des Menschen im KI-gestützten RE-Prozess bleibt dennoch von zentraler Bedeutung. Abbasi et al. formalisieren diese Notwendigkeit im HARE-SM-Framework, das vier Säulen definiert: Human-in-the-Loop Validation, Explainability & Transparency, Bias Mitigation und Stakeholder Trust Calibration [8]. Dieses Framework unterstreicht, dass der Mensch nicht nur als letzter Entscheider fungiert, sondern aktiv in die Gestaltung und Überwachung des KI-gestützten Prozesses eingebunden sein muss. Der kollaborative Ansatz ermöglicht es, die Stärken beider Seiten zu nutzen: die Verarbeitungskapazität und Konsistenz der KI auf der einen Seite und das kontextuelle Verständnis sowie die kreative Urteilskraft des Menschen auf der anderen Seite.
III. KI-Rollen im RE-Prozesslebenszyklus
Dieses Kapitel analysiert die spezifischen Einsatzszenarien von Large Language Models in den vier etablierten Phasen des Requirements Engineering. Dabei wird für jede Phase eine charakteristische Rolle der KI identifiziert, die das Zusammenspiel zwischen menschlichem Analysten und KI-System beschreibt. Die Systematik orientiert sich an der von Cheng et al. identifizierten Verteilung der Forschungsaktivitäten: Anforderungsanalyse bildet mit 30 % den am häufigsten untersuchten Bereich, gefolgt von Elicitation mit 22,1 % und Management mit 6,8 % [6].
A. Elicitation: Die KI als Assistent
Die Anforderungserhebung (Elicitation) stellt den initialen und häufig aufwendigsten Schritt im RE-Prozess dar. Traditionell erfolgt sie über Interviews, Workshops und Dokumentenanalysen, die einen erheblichen manuellen Aufwand erfordern. LLMs können in dieser Phase als Assistenten eingesetzt werden, indem sie große Datenmengen aus verschiedenen Quellen – wie Meeting-Transkripten, E-Mail-Korrespondenzen und bestehenden Dokumentationen – verarbeiten und erste Anforderungsentwürfe extrahieren [6].
Ein konkreter Anwendungsfall ist die automatisierte Extraktion von Anforderungen aus unstrukturiertem Input. Beispielsweise kann ein LLM eine aufgezeichnete Stakeholder-Besprechung transkribieren und daraus initiale funktionale sowie nicht-funktionale Anforderungen ableiten. Cheng et al. identifizieren in ihrer SLR die Anforderungsextraktion als eine der zentralen GenAI-Fähigkeiten, bei der das Modell relevante Informationsfragmente erkennt und in eine vorläufige Anforderungsliste überführt [6]. Die Umfrage von Rani et al. bestätigt die praktische Relevanz: In der Elicitation-Phase setzen 49,2 % der befragten Praktiker auf Human-AI Collaboration, während lediglich 5,4 % eine vollautomatisierte Erhebung praktizieren [7]. Die Qualität dieser Erstergebnisse hängt dabei maßgeblich von der Promptgestaltung und dem bereitgestellten Kontext ab, was die Bedeutung strukturierter Prompting-Strategien unterstreicht (vgl. Kapitel IV).
B. Analysis: Die KI als Prüfer
In der Analysephase übernimmt die KI die Rolle eines systematischen Prüfers. Zentrale Aufgaben umfassen die Klassifizierung von Anforderungen in funktionale (FA) und nicht-funktionale Anforderungen (NFA) sowie die Erkennung von Konflikten, Redundanzen und Inkonsistenzen innerhalb der Anforderungsliste. Cheng et al. identifizieren die Anforderungsanalyse mit 30 % als den am intensivsten erforschten RE-Teilbereich im Kontext generativer KI [6].
LLMs haben gezeigt, dass sie bei der Klassifizierung von Anforderungen in FA und NFA eine hohe Genauigkeit erreichen können. Darüber hinaus sind sie in der Lage, semantische Überlappungen zu identifizieren – etwa wenn zwei Stakeholder funktional identische Anforderungen unterschiedlich formulieren (z. B. „User Authentication" vs. „Sichere Registrierung"). Insbesondere Transformer-basierte Modelle liefern dabei vielversprechende Ergebnisse bei der automatisierten Klassifikation [6].
Gleichzeitig ist zu beachten, dass die Analyse domänenspezifischer Anforderungen – insbesondere in regulierten Umgebungen wie dem Gesundheitswesen oder der Finanzbranche – weiterhin menschliche Expertise erfordert. Cheng et al. identifizieren die mangelnde Reproduzierbarkeit mit 66,8 % als die häufigste technische Limitation. Das Halluzinationsrisiko folgt als zweithäufigste Limitation, wobei 63,4 % der untersuchten Studien von Problemen mit fehlerhaft generierten Inhalten berichten [6]. Abbasi et al. adressieren dieses Risiko durch die Säule Explainability & Transparency im HARE-SM-Framework, die eine nachvollziehbare Begründung aller KI-Ergebnisse fordert [8].
C. Specification: Die KI als Co-Autor
Die Spezifikationsphase transformiert analysierte Anforderungen in strukturierte, standardisierte Formate. In dieser Rolle agiert die KI als Co-Autor, der den menschlichen Analysten bei der Erstellung formalisierter Dokumente unterstützt.
Typische Einsatzszenarien umfassen die Transformation von Rohanforderungen in strukturierte User Stories nach dem Schema Als [Rolle] möchte ich [Funktion], damit [Nutzen], die Erstellung von Product Requirement Documents (PRD) sowie die Generierung von Akzeptanzkriterien [6]. Dabei kann das LLM templatespezifische Dokumentenstrukturen einhalten und konsistente Formatierungen sicherstellen. Rani et al. berichten, dass in der Spezifikationsphase der Anteil von Human-AI Collaboration mit 54,1 % besonders hoch ist, was die Bedeutung dieser Phase für den kollaborativen KI-Einsatz unterstreicht [7].
Ein wesentlicher Vorteil besteht in der Skalierbarkeit: Während ein menschlicher Analyst für die Ausformulierung einer umfangreichen Anforderungsliste Stunden benötigt, kann ein LLM innerhalb von Sekunden erste Entwürfe generieren, die anschließend vom Fachexperten validiert und verfeinert werden. Allerdings identifizieren Cheng et al. die mangelnde Reproduzierbarkeit als kritische Limitation: 66,8 % der Studien berichten von Herausforderungen bei der Konsistenz wiederholter Generierungsläufe [6].
D. Validation: Die KI als Qualitätssicherer
In der abschließenden Validierungsphase fungiert die KI als Qualitätssicherer, der die erstellten Anforderungen auf formale und inhaltliche Korrektheit prüft. Ein zentrales Konzept ist hierbei die Erkennung sogenannter Requirement Smells – also Muster, die auf potenzielle Qualitätsprobleme hinweisen [6].
Zu den häufigsten Requirement Smells zählen Mehrdeutigkeit, etwa durch Verwendung vager Begriffe wie „schnell" oder „benutzerfreundlich", Unvollständigkeit sowie mangelnde Testbarkeit. LLMs können solche Muster systematisch identifizieren und Verbesserungsvorschläge generieren. Abbasi et al. betonen in ihrem Framework die Notwendigkeit einer Human-in-the-Loop Validation gerade in dieser Phase, da die endgültige Bewertung der Anforderungsqualität domänenspezifisches Expertenwissen voraussetzt [8].
Darüber hinaus können LLMs Testfälle aus bestehenden Anforderungen ableiten, um die Testbarkeit sicherzustellen. Cheng et al. berichten, dass die automatisierte Generierung von Testfällen aus Anforderungsdokumenten ein wachsendes Forschungsfeld darstellt, wobei allerdings die Interpretierbarkeit der Ergebnisse mit 57,1 % als dritthäufigste Limitation identifiziert wird [6]. Die Kombination von Chain-of-Thought Prompting und domänenspezifischem Kontext liefert hierbei vielversprechende Resultate zur Verbesserung der Nachvollziehbarkeit.
IV. Methodik und Prompting-Strategien
Dieses Kapitel untersucht die methodischen Grundlagen des Prompt Engineerings im AI-gestützten Requirements Engineering. Es werden sowohl die Grenzen einfacher, naiver Ansätze als auch die Vorteile strukturierter Frameworks und Strategien vorgestellt. Ziel ist es, den Übergang von explorativen zu reproduzierbaren und qualitativ hochwertigen Interaktionen mit Sprachmodellen nachzuvollziehen.
A. Grenzen naiver Ansätze
Ein häufiger Einstieg in AI-gestütztes Requirements Engineering besteht in der Verwendung einfacher, wenig spezifizierter Prompts. Dieser Ansatz zeichnet sich durch minimale Vorbereitung, geringe Kontextbereitstellung und fehlende strukturelle Vorgaben aus. Obwohl solche Interaktionen eine schnelle Generierung von Antworten ermöglichen, zeigen sich in der Praxis signifikante Qualitätsprobleme.
Insbesondere führen unstrukturierte Eingaben häufig zu unvollständigen, inkonsistenten oder falsch interpretierten Anforderungen. Zudem kann das erzeugte Ausgabeformat stark variieren, was eine direkte Weiterverarbeitung erschwert. Diese Problematik lässt sich darauf zurückführen, dass große Sprachmodelle probabilistisch arbeiten und daher stark von der Qualität der Eingabeinstruktionen abhängen [9] [10]. Fehlen klare Vorgaben zu Kontext, Ziel oder Struktur, entstehen Ergebnisse, die eher explorativ als reproduzierbar sind [11].
Ein weiterer Nachteil naiver Ansätze ist die mangelnde Nachvollziehbarkeit der Generierungsschritte sowie potenzielle Halluzinationen [11] [12]. Ohne explizite Strukturierung oder Validierungsmechanismen bleibt unklar, auf welcher Grundlage bestimmte Anforderungen formuliert wurden. Dies erschwert insbesondere in sicherheitskritischen oder regulierten Projekten die notwendige Dokumentation und Überprüfbarkeit.
Der naive Prompting-Ansatz kann daher als exploratives Werkzeug für frühe Ideationsphasen betrachtet werden, ist jedoch für systematische Requirements-Engineering-Prozesse nur eingeschränkt geeignet. Für produktive Einsatzszenarien sind strukturierte und methodisch fundierte Prompting-Strategien erforderlich.
B. Strukturierte Prompting-Frameworks
Um die genannten Einschränkungen zu adressieren, wurden strukturierte Prompting-Frameworks entwickelt, die als methodische Leitlinien für die Interaktion mit Sprachmodellen dienen. Zu den verbreiteten Ansätzen zählen unter anderem die Frameworks CRAFT und CLEAR, welche standardisierte Prompt-Bausteine definieren [13] [14] [15].
Diese Frameworks legen fest, dass effektive Prompts typischerweise mehrere Elemente enthalten sollten, darunter Kontextinformationen, Rollenbeschreibungen, konkrete Aufgabenstellungen, gewünschte Ausgabeformate sowie stilistische Vorgaben [13] [14]. Beispiele können ebenfalls als Prompt-Baustein herangezogen werden [14]. Durch diese explizite Strukturierung wird die Interpretation des Modells gelenkt und die Varianz der Antworten reduziert.
Des Weiteren existieren allgemeine Gestaltungsprinzipien für die Entwicklung effektiver Prompts, die nicht primär als Strukturrahmen, sondern als Leitlinien für Formulierung und Iteration dienen. Auch hierfür wird teilweise das Akronym CLEAR [16] verwendet, allerdings mit einer anderen semantischen Auslegung als in den zuvor beschriebenen Frameworks.
Die Komponenten dieses alternativen CLEAR-Modells [16] werden im Folgenden erörtert:
Concise beschreibt die Notwendigkeit präziser, verständlicher und möglichst knapper Formulierungen. Unnötige Details, redundante Informationen oder sprachliche Höflichkeitsfloskeln sollten vermieden werden, da sie die semantische Interpretation durch das Modell erschweren können. Besonders relevant ist hierbei die Priorisierung zentraler Informationen, die möglichst früh im Prompt positioniert werden sollten. [16]
Logical betont die Bedeutung einer kohärenten und strukturierten Darstellung der Anfrage. Anforderungen oder Instruktionen sollten in logisch nachvollziehbarer Reihenfolge formuliert sein, sodass das Modell den intendierten Ablauf der Aufgabe eindeutig rekonstruieren kann. [16]
Explicit wird die explizite Spezifikation von Erwartungen verstanden. Dazu zählen klare Angaben zu Ausgabeformat, Detailgrad, Umfang sowie gewünschtem Stil oder Perspektive. Je eindeutiger diese Parameter definiert sind, desto geringer ist die Varianz der generierten Ergebnisse.
Adaptive verweist darauf, dass Prompt Engineering als iterativer Prozess betrachtet werden sollte. Effektive Prompts entstehen selten im ersten Versuch, sondern durch schrittweises Testen, Anpassen und Kombinieren unterschiedlicher Strategien. Dieser iterative Charakter ähnelt klassischen Optimierungsprozessen in der Softwareentwicklung. [16]
Reflective beschreibt die Notwendigkeit systematischer Ergebnisbewertung. Generierte Antworten sollten kritisch überprüft, validiert und mit den ursprünglichen Anforderungen abgeglichen werden. Erkenntnisse aus solchen Evaluationsschritten können genutzt werden, um zukünftige Prompts gezielt zu verbessern und die Modellinteraktion langfristig zu optimieren. [16]
Zusammenfassend stellt dieses CLEAR-Modell keinen strukturellen Promptaufbau dar, sondern ein heuristisches Regelwerk zur Qualitätssicherung von Promptformulierungen. Während Frameworks wie CRAFT oder formale Promptstrategien die Architektur einer Anfrage definieren [13] [14], liefert dieser Ansatz praktische Richtlinien für deren sprachliche und methodische Ausgestaltung [16].
Neben solchen Frameworks existieren spezifische Prompting-Strategien, die für komplexe reasoning-intensive Aufgaben entwickelt wurden [11]. Eine der bekanntesten Methoden ist Chain-of-Thought Prompting, bei dem das Modell aufgefordert wird, seine Zwischenschritte explizit darzustellen [11]. Studien zeigen, dass dieser und weitere Ansätze die logische Konsistenz und Genauigkeit von Modellantworten signifikant verbessern können [11].
Weitere Strategien umfassen unter anderem:
- Chain-of-Verification: interne Prüfung von Modellantworten vor der finalen Ausgabe zur Fehlerreduktion [11]
- Thread-of-Thought: Segmentierung großer Kontexte in analysierbare Teilabschnitte [11]
- Logic-of-Thought: Integration formaler Logikstrukturen in Promptinstruktionen [11]
- Explicit Schema Enforcement: Erzwingen strukturierter Ausgabeformate (z. B. JSON)
Diese Strategien verfolgen ein gemeinsames Ziel: die Transformation eines generativen Sprachmodells von einem explorativen Textgenerator zu einem reproduzierbaren Analysewerkzeug [9]. Empirische Untersuchungen zeigen, dass strukturierte Prompts insbesondere bei komplexen Aufgabenstellungen deutliche Qualitätsgewinne gegenüber unstrukturierten Eingaben erzielen [11].
Daraus lässt sich ableiten, dass Prompt Engineering eine zentrale methodische Kompetenz im AI-Aided Requirements Engineering darstellt und vergleichbar mit Modellierungstechniken klassischer Softwaretechnik betrachtet werden kann.
C. KI-Sparring Partner
Neben der Optimierung einzelner Prompts hat sich ein dialogbasierter Ansatz etabliert, bei dem das Sprachmodell nicht als passiver Antwortgenerator, sondern als aktiver Interaktionspartner eingesetzt wird. Dieses Konzept wird häufig als KI-Sparring Partner bezeichnet [12].
In diesem Modus wird das Modell gezielt angewiesen, Rückfragen zu stellen, Unklarheiten zu identifizieren und Vorschläge kritisch zu hinterfragen [12]. Dadurch entsteht ein iterativer Dialog, der dem klassischen Requirements-Engineering-Interview ähnelt. Der Fokus verschiebt sich von einmaliger Anforderungsgenerierung hin zu kollaborativer Anforderungsentwicklung.
Der Einsatz eines solchen Sparring-Partners erweist sich insbesondere in Situationen als hilfreich, in denen Stakeholder nur eingeschränkt verfügbar sind oder Anforderungen zunächst vage formuliert wurden. Durch strukturierte Rückfragen kann die KI dabei helfen, implizite Annahmen sichtbar zu machen [12] und Anforderungen zu präzisieren.
Gleichzeitig bestehen klare Grenzen dieses Ansatzes. Ein Sprachmodell besitzt kein echtes Domänenverständnis [12] [17] und kann reale Stakeholder nicht ersetzen. Der KI-Sparring Partner sollte daher als unterstützendes Werkzeug verstanden werden, das menschliche Analyseprozesse ergänzt, jedoch nicht substituiert.
Zusammenfassend lässt sich feststellen, dass dialogbasierte KI-Nutzung eine vielversprechende Erweiterung klassischer Requirements-Engineering-Methoden darstellt, insbesondere wenn sie mit strukturierten Prompting-Strategien kombiniert wird.
V. Agentische Systeme und BMAD-Methode
In diesem Kapitel steht der Übergang von ad-hoc Prompting zu systematischem KI-Engineering im Mittelpunkt. Es werden agentische Architekturen und die BMAD-Methode vorgestellt, die eine modulare, transparente und evaluierbare Nutzung von KI im Requirements Engineering ermöglichen. Damit wird gezeigt, wie komplexe Aufgaben in definierte Verarbeitungsschritte überführt werden können, um Zuverlässigkeit und Nachvollziehbarkeit zu erhöhen.
A. Paradigmenwechsel: Von Prompting zu Engineering
Frühe Anwendungen generativer KI basierten primär auf experimentellen Promptformulierungen und wurden häufig als Black-Box-Systeme wahrgenommen [10]. Diese Herangehensweise erschwerte die Nachvollziehbarkeit von Ergebnissen und stand im Widerspruch zu den Anforderungen systematischer Softwareentwicklung, die Reproduzierbarkeit, Dokumentation und Validierbarkeit erfordern.
Mit zunehmender Integration von KI in Entwicklungsprozesse vollzieht sich daher ein Paradigmenwechsel: Der Fokus verschiebt sich von spontaner Promptgestaltung hin zu strukturierten, ingenieursmäßigen Vorgehensweisen. Prompting wird nicht länger als ad-hoc Interaktion verstanden, sondern als konfigurierbarer Bestandteil eines definierten Systems.
Dieser Wandel zeigt sich insbesondere in der Entwicklung agentischer Architekturen, in denen mehrere spezialisierte KI-Komponenten definierte Rollen übernehmen [17] [10]. Durch die Aufteilung komplexer Aufgaben in klar abgegrenzte Verarbeitungsschritte wird die Transparenz erhöht und die Wartbarkeit verbessert [17]. Gleichzeitig lassen sich einzelne Komponenten gezielt evaluieren und optimieren [10].
Der Übergang von experimentellem Prompting zu systematischem KI-Engineering stellt somit einen zentralen Schritt dar, um generative Modelle zuverlässig in professionelle Requirements-Engineering-Prozesse zu integrieren.
B. Die BMAD-Architektur
Die Breakthrough Method for Agile AI-Driven Development (BMAD) stellt einen strukturierten Ansatz dar, der den Übergang von ad-hoc-Prompting zu einem systematischen, ingenieursmäßigen Einsatz von KI-Agenten im Softwareentwicklungsprozess formalisiert [18]. Im Gegensatz zu isolierten LLM-Interaktionen verfolgt BMAD das Ziel, spezialisierte KI-Agenten als virtuelle Teammitglieder zu orchestrieren, die gemeinsam an der Erstellung und Verfeinerung von Projektartefakten arbeiten.
Philosophie und Kernprinzipien
Die BMAD-Philosophie basiert auf vier Grundpfeilern: Collaboration, Optimization, Reflection und Engine (CORE) [18]. Collaboration beschreibt die strukturierte Zusammenarbeit spezialisierter Agenten – darunter Analyst, Product Manager, Architekt und Scrum Master – die jeweils domänenspezifische Expertise einbringen. Optimization zielt auf die iterative Verbesserung der generierten Artefakte durch Feedback-Schleifen zwischen den Agenten. Reflection fordert von jedem Agenten eine kritische Selbstbewertung seiner Ergebnisse, bevor diese an den nächsten Agenten weitergegeben werden. Die Engine bildet die technische Infrastruktur, die den Agenten-Workflow orchestriert und die Konsistenz der Artefakte sicherstellt.
Paradigmen: Agentic Planning, Agent-as-Code, Context-Engineering
BMAD basiert auf drei zentralen Paradigmen [18]:
Agentic Planning beschreibt den Übergang von konventioneller, rein menschengetriebener Anforderungserhebung hin zu einem kollaborativen Ökosystem, in dem spezialisierte KI-Agenten als virtuelle Teammitglieder fungieren. Der Analyst-Agent identifiziert Projektanforderungen, der Product-Manager-Agent erstellt das PRD, und der Architekt-Agent leitet daraus die technische Architektur ab.
Das Agent-as-Code-Paradigma definiert Agenten nicht als monolithische Modellinstanzen, sondern als konfigurierbare Codeeinheiten mit expliziten Rollen, Werkzeugen und Einschränkungen. Dies ermöglicht eine versionierbare, reproduzierbare und auditierbare KI-Nutzung – ein wesentlicher Vorteil gegenüber der „Black Box"-Problematik unkontrollierter LLM-Interaktionen.
Context-Engineering adressiert das Problem des Context Collapse – den schleichenden Verlust von Projektverständnis bei zunehmender Komplexität [18]. Durch einen sogenannten Epic-Sharding-Prozess wird das umfassende PRD systematisch in fokussierte, in sich geschlossene Entwicklungseinheiten zerlegt, die jedem Agenten den vollständigen Kontext seiner Aufgabe bereitstellen.
Die drei Planning Tracks
BMAD definiert drei skalierbare Planungspfade, die sich nach Projektgröße und Regulierungsanforderungen richten [18]:
- Quick Flow: Ein schlanker Ansatz für kleine Projekte, bei dem ausschließlich eine technische Spezifikation (Tech-Spec) erstellt wird. Geeignet für Prototypen und explorative Vorhaben.
- BMAD Method: Der Standardpfad, der ein vollständiges PRD, eine Architekturspezifikation und UX-Richtlinien umfasst. Dieser Track eignet sich für mittelgroße bis große Projekte mit mehreren Stakeholdern.
- Enterprise Method: Der umfassendste Planungspfad, der zusätzlich zum vollständigen PRD auch Sicherheits-, Compliance- und Governance-Anforderungen einschließt. Dieser Track adressiert die Anforderungen regulierter Industrien.
Die 4-Phasen-Methodik
Der BMAD-Workflow gliedert sich in vier aufeinanderfolgende Phasen [18]:
In der Analysis-Phase analysiert der Analyst-Agent den Projektkontext, identifiziert Stakeholder-Bedürfnisse und erstellt eine initiale Anforderungsübersicht. Die Planning-Phase überführt diese Analyse in ein strukturiertes PRD durch den Product-Manager-Agenten. In der Solutioning-Phase leitet der Architekt-Agent aus dem PRD die technische Architektur, Datenmodelle und Schnittstellenspezifikationen ab. Die abschließende Implementation-Phase übergibt die generierten Artefakte an Entwicklungs-Agenten, die den Code auf Basis der vollständig spezifizierten Anforderungen implementieren.
Diese Docs-as-Code-Philosophie – bei der die Dokumentation und nicht der Code die primäre Wahrheitsquelle darstellt – gewährleistet eine durchgängige Traceability von der Anforderung bis zur Implementierung [18].
C. Workflow-Automatisierung
Wie sich bei der BMAD Method auch schon gezeigt hat, liegt ein wesentlicher Vorteil agentischer Systeme in ihrer Fähigkeit, Requirements-Engineering-Aufgaben in automatisierten oder teilautomatisierten Workflows zu organisieren. Hierbei werden spezialisierte KI-Komponenten so orchestriert, dass sie unterschiedliche Prozessschritte übernehmen, etwa Anforderungsextraktion, Klassifikation, Priorisierung oder Konsistenzprüfung [17].
Solche Systeme basieren typischerweise auf modularen Architekturen, in denen einzelne Agenten definierte Rollen erfüllen und über Schnittstellen miteinander kommunizieren [17]. Die Interaktion erfolgt häufig über Prompts, strukturierte Datenformate oder Programmierschnittstellen, wodurch komplexe Verarbeitungsketten realisiert werden können [17].
In praktischen Implementierungen werden hierfür häufig Workflow-Plattformen eingesetzt, die externe Tools, Datenquellen und KI-Modelle miteinander verbinden [17]. Diese ermöglichen es, Requirements-Engineering-Prozesse als orchestrierte Pipelines abzubilden und wiederholt auszuführen. Dadurch entstehen reproduzierbare Abläufe, die gegenüber rein manuellen Vorgehensweisen eine höhere Konsistenz und Skalierbarkeit aufweisen [10].
Ein weiterer Vorteil liegt in der Parallelisierbarkeit. Während menschliche Analysten nur begrenzt gleichzeitig arbeiten können, lassen sich agentische Systeme auf mehrere Projekte oder Datensätze gleichzeitig anwenden [17]. Dies kann insbesondere bei großen Projekten zu erheblichen Effizienzgewinnen führen.
Insgesamt zeigt sich, dass Workflow-Automatisierung einen zentralen Baustein zukünftiger Requirements-Engineering-Prozesse darstellt und eine Brücke zwischen generativer KI und klassischer Softwaretechnik bildet.
VI. Fallstudie: Lernplattform-Projekt
Die zuvor beschriebenen Konzepte agentischer Systeme und automatisierter Workflows bilden die methodische Grundlage für die praktische Umsetzung von AI-Aided Requirements Engineering. Während Abschnitt V.C die architektonischen Prinzipien solcher Systeme theoretisch erläutert hat, demonstriert die folgende Fallstudie deren konkrete Anwendung in einem realitätsnahen Szenario.
A. Szenario und Datengrundlage
Das Ausgangsszenario für die Fallstudie ist ein studentisches Projekt zur Entwicklung einer Lernplattform. Die grundlegende Idee der Plattform ist die Bereitstellung von Kursen, die von Studierenden belegt werden können. Dozenten sollen dabei die Kurse bereitstellen können. Zur Idee gehört außerdem die Verwendung von Gamification-Elementen, um eine weitere Motivation zu bieten. Um die Anforderungen der Projektbeteiligten an das Projekt zu ermitteln, wurde ein Workshop mit allen Beteiligten durchgeführt. In diesem Workshop wurden zunächst mehrere Arbeitsgruppen gebildet. Jede der Gruppen hatte die Aufgabe, Anforderungen an die Lernplattform zu erarbeiten. Bei diesem Prozess sind insgesamt fünf heterogene Dokumente erstellt worden. Diese unterscheiden sich im Dateityp, in der Struktur, im Inhalt und in der Art, wie sie erstellt wurden.
In einer zweiten Phase des Workshops sollten diese Dokumente in ein einheitliches Anforderungsdokument überführt werden. Dabei sollte auch bereits eine Unterteilung in funktionale und nicht-funktionale Anforderungen stattfinden. Auch sollten weitere nicht-funktionale Anforderungen, die sich aus funktionalen ergeben, abgeleitet werden. Für diese Aufgaben wurde im Workshop ein LLM-Chatbot mit den naiven Ansätzen aus Abschnitt IV.A eingesetzt. Die Ergebnisse waren dabei zum einen sehr unterschiedlich und wiesen auch keine hohe Qualität auf. Dies führte zunächst dazu, dass die Anforderungen aus den fünf Dokumenten mit manuellem Aufwand gesammelt werden mussten. Für die Fallstudie wurden die fünf einzelnen Anforderungsdokumente als Datenbasis verwendet. Ziel der Studie war es zu untersuchen, inwieweit Künstliche Intelligenz den Requirements-Engineering-Prozess unterstützen kann und insbesondere, ob sich eine unstrukturierte Menge von Anforderungen aus verschiedenen Quellen konsolidieren und systematisch zusammenführen lässt.
B. Herausforderungen und Lösung
Herausforderungen. Aus dem beschriebenen Szenario ergeben sich einige Herausforderungen für eine von KI unterstützte Lösung. Eine der größten Herausforderungen ist dabei die Konsolidierung mehrerer Dokumente in ein einziges Anforderungsdokument. Die Lösung muss hier zunächst mit den verschiedenen Dateitypen, Strukturen und Layouts umgehen können. Auch muss es in einem nächsten Schritt möglich sein, die Anforderungen zu extrahieren und mit den bestehenden Anforderungen zusammenzuführen. Ein konkretes Problem ist hierbei, dass Anforderungen auf verschiedene Weisen formuliert werden können, aber die gleiche Bedeutung haben oder einander ergänzen. Zusätzlich ist außerdem eine Gruppierung der Anforderungen in funktionale und nicht-funktionale Anforderungen notwendig. Dabei dürfen keine Anforderungen verloren gehen. Es darf zum Beispiel nicht vorkommen, dass eine nicht-funktionale Anforderung übersehen wird, wenn diese innerhalb einer funktionalen Anforderung genannt ist oder aus dieser hervorgeht. Zusätzlich bringen KI-Systeme, die auf LLMs basieren, selbst Herausforderungen mit sich. Zu diesen gehören unter anderem Halluzinationen und ein begrenztes Kontextfenster. Diese können zu falschen Anforderungen oder Schwierigkeiten bei der Verarbeitung von besonders vielen Anforderungen führen.
Lösung. Basierend auf den genannten Herausforderungen und dem Ziel der Erstellung eines einheitlichen Anforderungsdokuments auf Basis von mehreren Quellen, wurde eine Lösung konzipiert und mit dem Workflowautomatisierungstool n8n umgesetzt. Die implementierte Workflow-Architektur folgt einem semi-automatisierten Pipeline-Ansatz, bei dem mehrere spezialisierte Agenten sequenziell zusammenarbeiten. Der Prozess wird initial durch einen oder mehrere Trigger ausgelöst, beispielsweise durch das Hochladen eines Dokuments oder das Eintreffen neuer Daten. Anschließend startet ein Vorverarbeitungsschritt, der die Eingabe vorbereitet und an einen KI-Agenten übergibt. Die Vorbereitung der Daten besteht in dem hier implementierten Workflow darin, die verschiedenen Dateitypen zu erkennen und den in ihnen enthaltenen Text zu extrahieren. In diesem Fall werden von dem Workflow reine Textdateien, PDFs und auch Audioaufnahmen unterstützt.
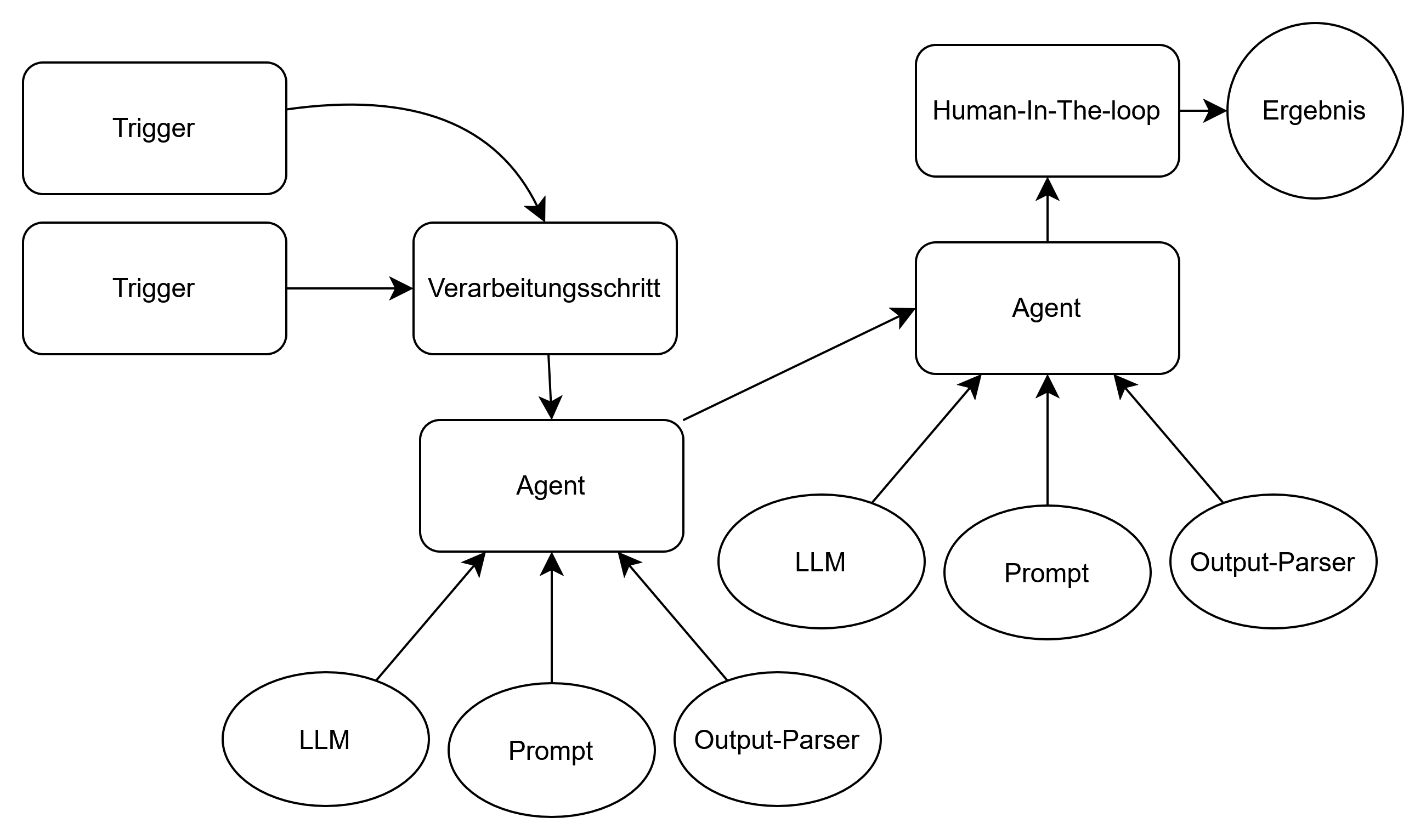
Jeder Agent besteht konzeptionell aus drei Kernkomponenten: einem Sprachmodell, einem strukturierten Prompt sowie einem Output-Parser. Das Sprachmodell übernimmt die eigentliche Analyse- oder Generierungsaufgabe, während der Prompt die Instruktionen und Kontextinformationen definiert. Der Output-Parser stellt sicher, dass die erzeugten Ergebnisse in ein konsistentes und maschinenverarbeitbares Format überführt werden. Auf diese Weise können die Resultate eines Agenten direkt an nachgelagerte Agenten weitergereicht werden, wodurch mehrstufige Verarbeitungsketten entstehen. Optional können Agenten zusätzlich mit externem Wissen oder Werkzeugen ausgestattet werden, um spezialisierte Aufgaben effizienter zu lösen.
In dem in dieser Fallstudie implementierten Workflow gibt es insgesamt drei solcher Agenten. Zwei dieser Agenten bilden dabei den Kern des Workflows. Der erste Agent, der direkt auf die Vorverarbeitung folgt, hat die Aufgabe, die Anforderungen aus dem ihm gegebenen Text in einem strukturierten Format (JSON) zu extrahieren. Der zweite Agent arbeitet direkt mit diesen strukturierten Daten weiter. Er konsolidiert dabei die extrahierten Anforderungen mit einem einheitlichen Anforderungsdokument. Dazu vergleicht der Agent die extrahierten Anforderungen mit dem einheitlichen Anforderungsdokument, fügt neue Anforderungen hinzu oder verändert bestehende bei Bedarf. Die neue konsolidierte Version gibt dieser Agent ebenfalls in einem strukturierten Format (JSON) aus. Ein dritter und letzter Agent hat lediglich die Aufgabe, die Daten des zweiten Agenten in ein menschenlesbares Format zu bringen.
Der Workflow umfasst zusätzlich eine Human-in-the-Loop-Komponente, in der Zwischenergebnisse überprüft, validiert und gegebenenfalls korrigiert werden. Diese Integration menschlicher Kontrolle dient der Qualitätssicherung und reduziert das Risiko fehlerhafter oder halluzinierter Anforderungen. Gleichzeitig bleibt der Gesamtprozess weitgehend automatisiert, sodass Effizienzgewinne gegenüber rein manuellen Vorgehensweisen erzielt werden können. Über eine solche Human-in-the-Loop-Komponente wird in dem implementierten Workflow die Arbeit des zweiten Agenten kontrolliert und so sichergestellt, dass die neuen Anforderungen und Änderungen im Anforderungsdokument eine hohe Qualität haben.
Mit dem gewählten Konzept und der Umsetzung konnte eine deutliche Verbesserung der Ergebnisse im Vergleich zu den im Workshop gewählten Methoden beobachtet werden. Der umgesetzte Workflow konnte die einzelnen Dateien analysieren und ein einheitliches Anforderungsdokument aufbauen. Zudem ist der Workflow in der Lage, Anforderungen aus neuen Dokumenten, die hochgeladen werden, in das Anforderungsdokument zu übernehmen.
VII. Diskussion und Grenzen
Der Einsatz von KI-Agenten im Requirements Engineering birgt ein großes Potenzial. Es gibt allerdings auch Limitationen beim Einsatz von KI. In diesem Kapitel werden zunächst die Limitationen von KI-Agenten betrachtet. Daraufhin werden zukünftige Entwicklungen diskutiert, die für eine breitere industrielle Adaption adressiert werden müssen.
A. Limitationen des KI-Einsatzes
Bei dem Einsatz von KI im Requirements-Engineering-Prozess gibt es auch einige Limitationen. Vorweg muss festgestellt werden, dass KI einen Requirements Engineer zum jetzigen Zeitpunkt nicht vollständig ersetzen kann. KI-Agenten können hier eher eingesetzt werden, um den Engineer bei seiner Arbeit zu unterstützen. Dabei werden von KI-Agenten konkrete einzelne Aufgaben übernommen, um dem Engineer zuzuarbeiten. Zudem gibt es auch Aufgaben, die ein KI-Agent nicht ohne Weiteres übernehmen kann. Die Kommunikation und persönliche Gespräche mit den Stakeholdern müssen weiterhin vom Requirements Engineer übernommen werden, da hierfür Soft Skills benötigt werden.
Eine weitere Limitation liegt in der Qualität der Ergebnisse vom KI-Agenten. Um qualitativ hochwertige Ergebnisse mit KI-Agenten zu erzielen, werden genaue Erklärungen in Bezug auf die Aufgabe und das Ergebnis benötigt. Auch ist es hier wichtig, dass eine Kontrolle der Qualität eines Experten durch einen Human-in-the-Loop-Mechanismus stattfindet. Nur so können Fehler erkannt und korrigiert werden. Außerdem gibt es auch bei der Nachvollziehbarkeit von Entscheidungen und Ergebnissen der KI starke Limitationen. Es ist zwar möglich, von einem LLM eine schriftliche Begründung für seine Entscheidung zu verlangen, was zusammen mit einem Prompt eventuell Rückschlüsse erlaubt. Die Modelle selbst sind aber eine Black-Box. Eine Limitation, die ebenfalls beachtet werden muss, ist das Kontextfenster von LLMs. Besonders bei großen Projekten kann es hier leicht zum Verlust von Kontext und Informationen kommen. [19] [20] [21] [22] [23]
B. Zukünftige Entwicklungen
Der zukünftige Fortschritt und die praktische Reife von AI-Aided RE lassen sich anhand vier zentralen Dimensionen bewerten. Diese dienen als Indikatoren, um zu messen, wie weit der Übergang von explorativer Forschung zur produktiven Praxis fortgeschritten ist:
Evaluation und Benchmarking. Ein wesentliches Defizit des aktuellen Forschungsstands ist das Fehlen standardisierter Benchmarks für die objektive Bewertung von KI-Werkzeugen im RE. Cheng et al. identifizieren die Entwicklung einheitlicher Evaluationsmetriken als eine der dringendsten Forschungslücken, da ohne solche Benchmarks ein systematischer Vergleich verschiedener Ansätze nicht möglich ist [6]. Zukünftige Arbeiten sollten domänenspezifische Datensätze und Bewertungskriterien etablieren, die sowohl die Qualität der generierten Anforderungen als auch die Effizienz des Gesamtprozesses messen.
Governance, Ethik und Bias-Kontrolle. Mit der zunehmenden Integration von KI in kritische Entscheidungsprozesse gewinnen Fragen der Governance an Bedeutung. LLMs können systemische Verzerrungen (Bias) in ihre Ergebnisse einbringen, die sich in der Priorisierung oder Formulierung von Anforderungen manifestieren. Transparenz über die verwendeten Trainingsdaten und Modellentscheidungen sowie die Etablierung klarer Verantwortlichkeiten zwischen KI-generiertem Output und menschlicher Entscheidung sind essenziell für einen verantwortungsvollen Einsatz [6] [8].
Skalierbarkeit durch Retrieval Augmented Generation. Eine vielversprechende technologische Entwicklung ist der Einsatz von Retrieval Augmented Generation (RAG), bei dem LLMs zur Laufzeit auf externe Wissensbasen zugreifen, anstatt sich ausschließlich auf ihre Trainingsdaten zu stützen [24]. Im RE-Kontext ermöglicht RAG die Einbindung unternehmensinterner Dokumentationen, bestehender Anforderungskataloge und domänenspezifischer Standards, was die Relevanz und Genauigkeit der KI-Ergebnisse signifikant verbessern und das Risiko von Halluzinationen reduzieren kann.
Industrielle Reife und Produktionseinsatz. Der Übergang von explorativen Proof-of-Concept-Ansätzen hin zu standardisierten, rechtssicheren Produktionslösungen erfordert erhebliche Fortschritte in mehreren Bereichen: Zuverlässigkeit und Reproduzierbarkeit der Ergebnisse, Integration in bestehende Werkzeugketten (ALM-Tools, Versionsverwaltung) sowie die Erfüllung regulatorischer Anforderungen. Die BMAD-Methode (vgl. Abschnitt V.B) stellt einen ersten Schritt in diese Richtung dar, indem sie einen strukturierten, auditierbaren Rahmen für den KI-Einsatz bereitstellt [18].
Eine flächendeckende industrielle Adaption von AI-Aided RE setzt somit voraus, dass in diesen vier Dimensionen belastbare und standardisierte Lösungen entwickelt werden.
VIII. Fazit
Der Einsatz von KI im Requirements Engineering entwickelt sich von einfachem, explorativen Prompt Engineering hin zu einem systematischen AI-driven Software Development. Während isolierte LLM-Interaktionen an Bedeutung verlieren, gewinnen strukturierte Methoden wie die in Kapitel IV beschriebenen Prompting-Frameworks und insbesondere agentische Architekturen wie die BMAD-Methode an Relevanz. Die vier identifizierten KI-Rollen – Assistent (Elicitation), Prüfer (Analysis), Co-Autor (Specification) und Qualitätssicherer (Validation) – bieten einen analytischen Rahmen für die gezielte Integration von LLMs in den RE-Prozess.
Gleichzeitig zeigt die Analyse, dass der Mensch als Orchestrator und Domänenexperte unverzichtbar bleibt. Die überwältigende Dominanz von Human-AI Collaboration gegenüber Vollautomatisierung bestätigt, dass der effektivste Ansatz nicht in der Ablösung des Menschen liegt, sondern in der Augmentation seiner Fähigkeiten durch KI-Werkzeuge. Die Zukunft des RE liegt somit in der intelligenten Orchestrierung von menschlicher Expertise und maschineller Verarbeitungskapazität – ein Paradigma, das durch agentische Frameworks wie BMAD zunehmend operationalisiert wird.
Referenzen
[1] A. Herrmann, Grundlagen der Anforderungsanalyse: Standardkonformes Requirements Engineering. Springer Vieweg Wiesbaden, 2022. doi: 10.1007/978-3-658-35460-2
[2] t2informatik GmbH, „Requirements Engineering." [Online]. Verfügbar: https://t2informatik.de/wissen-kompakt/requirements-engineering/
[3] Technikum Wien GmbH, „Was ist Requirement Engineering und Requirement Management?" [Online]. Verfügbar: https://academy.technikum-wien.at/ratgeber/was-ist-requirements-engineering/
[4] B. Bauer, „Was macht ein Requirements Engineer?" get in GmbH. [Online]. Verfügbar: https://www.get-in-it.de/magazin/arbeitswelt/it-berufe/was-macht-ein-requirements-engineer
[5] P. Schifino, „Methoden der Anforderungserhebung: Grundlagen, Techniken & Einsatzgebiete." easyfeedback GmbH. [Online]. Verfügbar: https://easy-feedback.de/blog/anforderungserhebung/anforderungserhebung-methoden/
[6] H. Cheng, J. H. Husen, Y. Lu, T. Racharak, N. Yoshioka, N. Ubayashi und H. Washizaki, „Generative AI for Requirements Engineering: A Systematic Literature Review," Software: Practice and Experience, Bd. 56, Nr. 2, S. 141–170, 2025. doi: 10.1002/spe.70029
[7] L. M. Rani, R. Berntsson Svensson und R. Feldt, „AI for Requirements Engineering: Industry adoption and Practitioner perspectives," arXiv:2511.01324, 2025. [Online]. Verfügbar: https://arxiv.org/abs/2511.01324
[8] M. A. Abbasi, P. Ihantola, T. Mikkonen und N. Mäkitalo, „Towards Human-AI Synergy in Requirements Engineering: A Framework and Preliminary Study," in 2025 Sixth International Conference on Intelligent Data Science Technologies and Applications (IDSTA), IEEE, 2025, S. 81–88. doi: 10.1109/idsta66210.2025.11202850
[9] J. Polomski, „8 Prompting Techniken im Überblick," Blogpost, Mai 2024. [Online]. Verfügbar: https://jens.marketing/acht-prompting-techniken-im-uberblick/
[10] OpenAI, „Prompt engineering," OpenAI API Documentation, 2025. [Online]. Verfügbar: https://platform.openai.com/docs/guides/prompt-engineering
[11] P. Sahoo, A. K. Singh, S. Saha, V. Jain, S. Mondal und A. Chadha, „A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications," arXiv:2402.07927, 2025. [Online]. Verfügbar: https://arxiv.org/abs/2402.07927
[12] M. Kentz, „From Thinking Partner to Sparring Partner: A Better Way to Use AI," Juli 2025. [Online]. Verfügbar: https://mikekentz.substack.com/p/from-thinking-partner-to-sparring
[13] AI Prompting Clinic, „Prompt Engineering Frameworks," 2025. [Online]. Verfügbar: https://aipromptingclinic.com/craft
[14] S. Srinivasan, „The CLEAR Framework: Mastering Prompt Clarity for Better AI Results," LinkedIn Article, Juli 2025. [Online]. Verfügbar: https://www.linkedin.com/pulse/clear-framework-mastering-prompt-clarity-better-ai-sriram-srinivasan-jdmwc
[15] DAIR.AI, „Elemente eines Prompts," 2025. [Online]. Verfügbar: https://www.promptingguide.ai/de/introduction/elements
[16] Texas A&M University-Corpus Christi, „The CLEAR Framework – Prompt Engineering," Research Guides, September 2025. [Online]. Verfügbar: https://guides.library.tamucc.edu/prompt-engineering/clear
[17] C. Vogt, „KI-Agenten im E-Commerce," AMALYTIX Blog, Oktober 2025. [Online]. Verfügbar: https://www.amalytix.com/wissen/ai/ki-agenten/
[18] BMad Code, „BMAD-METHOD: Breakthrough method for agile AI-driven development," GitHub Repository, 2025. [Online]. Verfügbar: https://github.com/bmad-code-org/BMAD-METHOD
[19] I. Belcic und C. Stryker, „KI-Agenten im Jahr 2025: Erwartungen vs. Realität," IBM. [Online]. Verfügbar: https://www.ibm.com/de-de/think/insights/ai-agents-2025-expectations-vs-reality
[20] J. Siebert, „Agentic AI – Multi-Agenten-Systeme im Zeitalter generativer KI," Fraunhofer IESE, Juni 2025. [Online]. Verfügbar: https://www.iese.fraunhofer.de/blog/agentic-ai-multi-agenten-systeme/
[21] Deutsche Telekom MMS GmbH, „KI-Agenten realistisch bewertet: Über Trends, Use Cases und Grenzen," Oktober 2025. [Online]. Verfügbar: https://www.telekom-mms.com/blog/artikel/detail/ki-agenten-realistisch-bewertet-ueber-trends-use-cases-und-grenzen
[22] Deutsche Telekom MMS GmbH, „Was sind KI-Agenten? – Intelligente Assistenten im Zeitalter von Agentic AI." [Online]. Verfügbar: https://www.telekom-mms.com/spotlight/was-sind-ki-agenten
[23] WTSH GmbH, „KI-Agenten: Übertriebener Hype oder echte Revolution?" [Online]. Verfügbar: https://kuenstliche-intelligenz.sh/de/ki-agenten-uebertriebener-hype-oder-echte-revolution
[24] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel und D. Kiela, „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," arXiv:2005.11401, 2021. [Online]. Verfügbar: https://arxiv.org/abs/2005.11401
Leave a Reply
You must be logged in to post a comment.