
Back in 2005, the words ‘But most of all, samy is my hero’ caused great agitation among MySpace engineers as Samy Kamkar injected a Cross Site Scripting (XSS) worm into the social network. The attack consisted in an infected user, publishing a post in their myspace page showing these words honoring its creator, and of course without any intervention of the user itself.
In 2016, more than ten years after the best known XSS attack, one might think, that XSS would have been taken care of. However, reality is different, at a time when frameworks rule the world of the Web, developers haven’t found the golden solution to the problem. XSS attacks are still at the order of the day with some big names such as Ebay, Lieferando or WordPress among the victims of recent attacks.In this blog post, we are not going to be the first nor the lasts to give some space to this subject, but as long as this security flaw is part of our Web. Developers and users should have an understanding on the thematic, and the dangers it brings with it. Before getting into details let us get a better idea on the current situation of XSS.
Not for the faint of heart
The name “cross site” is confusing. It’s easy to hear it and think that it involves code on one website attacking code on another website. Like a code battle of some sort. But that’s not what it is. Not to mention its unfortunate “true” acronym. So do not confuse XSS with CSS the one is the big bad security vulnerability, while the other is the nice and good styling language.
Back in 2007 and the good old days of windows vista, Cross-site scripting carried out on websites accounted for roughly 84% of all security vulnerabilities documented by Symantec.
Nowadays, and some windows version later, 52% of web applications are still vulnerable to an XSS attack according to security firm Edgescan. So much to getting it fixed!

The latest big XSS hole, tracks back to January 2016, when an independant security scientist discovered a vulnerability at Ebay’s website. The attack consisted in injecting malicious code through the URL query parameter, thus enabling the attacker to embed an iframe with a fake login page, to later on pass the data to the attacker’s server. To get more information about this check out this great Blog Post.
So, an old problem with not so new faces, XSS is still giving a headache to developers. But why hasn’t it been fixed? And what are developers doing wrong? To understand that we need to understand XSS itself.
How does XSS work?
If we put it in plain and simple language XSS means: executing arbitrary JavaScript code on the page. Notice the word arbitrary, it means that the code comes from some a different source as the one intended from the webpage’s developer.
The aim of XSS attacks is to run malicious script code inside the victim’s browser. Therefor the attacker embeds the code in the web application. If somebody runs the application in their browser, the malicious code will be delivered with the application and will be executed. These opens a window to not so nice possibilities such as session hijacking, phishing redirects or Cross Site Request Forgery attacks.
When talking XSS one can distinguish between three types of attacks.
- Persistent XSS – or the one that infects anyone that visits the corrupted webpage.
- Reflected XSS – or the one in which the user is tricked into running himself the infected code itself.
- DOM-based XSS – or the one where the vulnerability is in the client-side code rather than the server-side code.
Persistent XSS
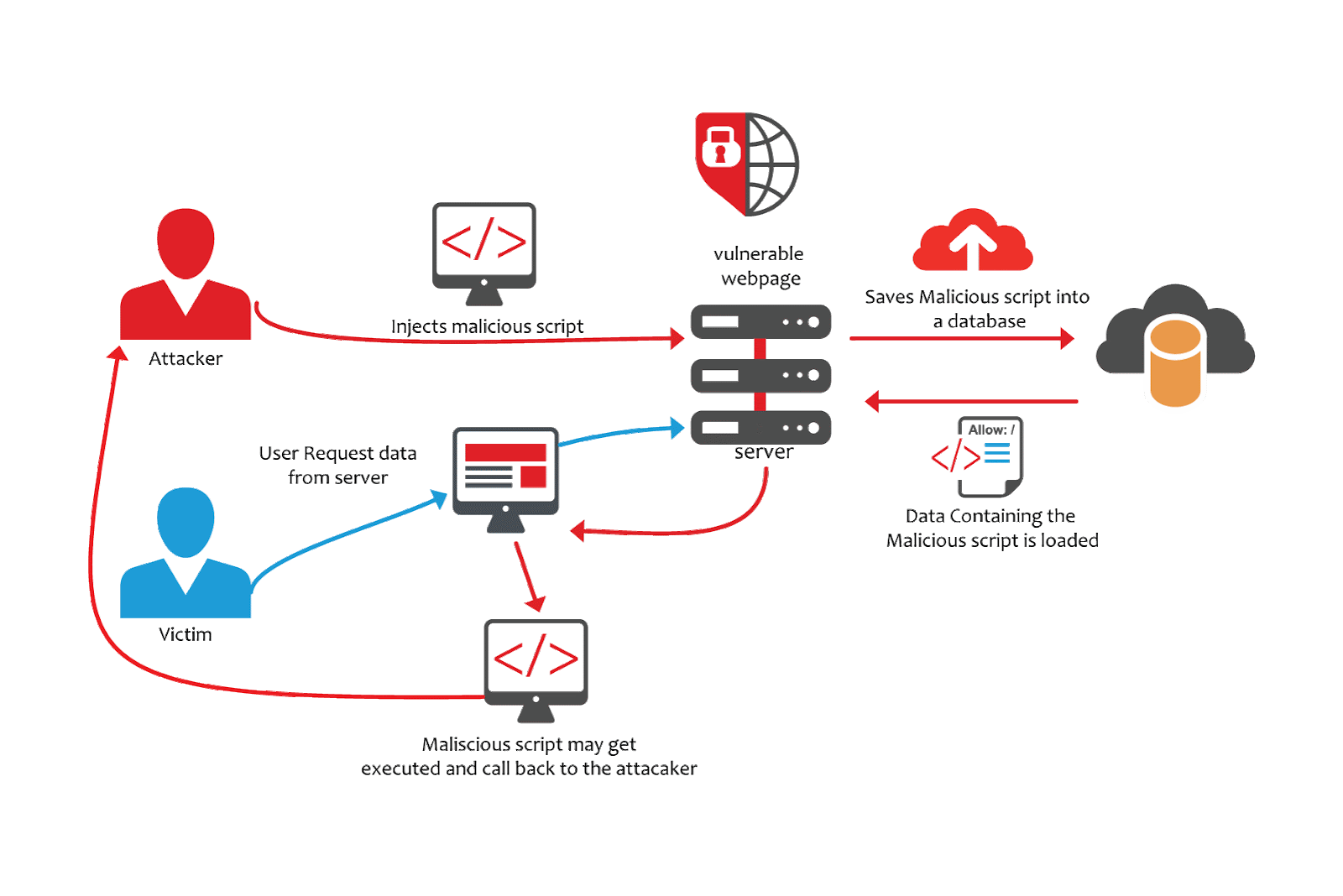
The persistent (or stored) XSS vulnerability is the most devastating variant of a cross-site scripting flaws. Here the injected code is saved on the server, which means, that the malicious code resides inside the application. One way to achieve this is for example to insert malicious code inside a blog post or comment. These will get persisted into the database, and then passed to every user visiting the page. If the victim access the website the code will be executed in the victim’s browser.
A classic example of this is with online message boards where users are allowed to post HTML formatted messages for other users to read.
Reflected XSS
The non-persistent (or reflected) cross-site scripting vulnerability is the most common type. In contrast to the persistent variant the code is not saved to the application.
The vulnerability happens when the data provided by a web client, most commonly in HTTP query parameters (e.g. forms), is used by server-side scripts to parse and display a page of results for and to that user, without properly sanitizing the request.
A classic example is a simple search field: if one searches for a string the search string will typically be redisplayed on the result page and the search text gets transferred via a query parameter in the URL – we are assuming the form work through GET. If this response does not properly escape or reject HTML control characters, a cross-site scripting flaw will arise. Under these conditions an attacker might insert a script into the query parameter like we see in the picture below. If the user is tricked into sending this request to the server the malicious script will be executed by the Browser.
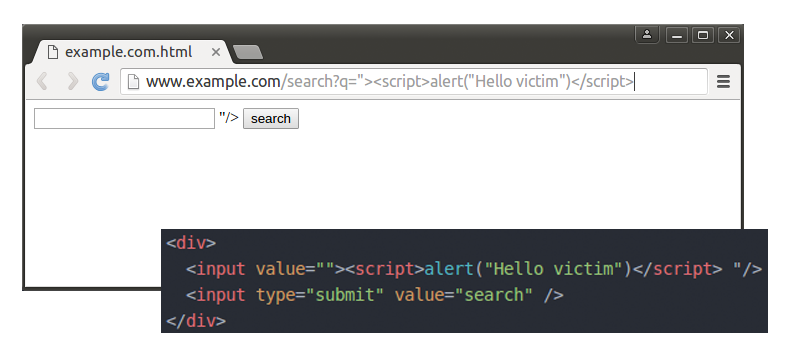
To execute the malicious code inside the victim’s browser the attacker has to make sure the user clicks on the prepared link. To keep the victim from detecting the script tag attackers normally encode the query parameter with base64 transforming the link, or use a URL shortening service with the same result.
Normal Link
www.example.com/search?q=”><script>alert(“Hello victim”)</script>
Link with base64 encoding
www.example.com/search?q=4oCdPjxzY3JpcHQ+YWxlcnQo4oCcSGVsbG8gdmljdGlt4oCdKTwvc2NyaXB0Pg0K
So keep your eyes open and don’t trust every link!
DOM-based XSS
The third type of Cross-Site Scripting is the DOM based version. To understand this attack we need to start with some previous knowledge.
The first XSS vulnerabilities were found in applications that performed data processing on the server side. User input would be sent to the server, and then sent back to the user as part of the web page. Making the XSS attack to come from the server.
As the JavaScript code was also processing user input and rendering it in the web page content, a new class of reflected XSS attacks started to appear, the DOM-based XSS. In this kind of attack, the malicious data does not touch the web server. Rather, it is being reflected by the JavaScript code, fully on the client side.
In the DOM-based XSS attack, there is no malicious script inserted as part of the page; the only script that is automatically executed during page load is a legitimate part of the page. Because the malicious string is inserted into the page source code, it is parsed as HTML, causing the malicious script to be executed.
There is a small difference, but it is important:
- In traditional XSS, the malicious JavaScript is executed when the page is loaded, as part of the response sent by the server.
- In DOM-based XSS, the malicious JavaScript is executed at some point after the page has loaded on runtime, as a result of the page’s legitimate JavaScript.
Why DOM-based XSS matters
With modern web Applications being more and more One-Page Web Apps, an increasing amount of HTML is generated through JavaScript on the client-side rather than by the server.
This means that XSS vulnerabilities can be present not only in your website’s server-side code, but also in your website’s client-side JavaScript code. Furthermore, even with completely secure server-side code, the client-side code might still unsafely include user input in a DOM update after the page has loaded. If this happens, the client-side code has enabled an XSS attack through no fault of the server-side code.
This vulnerability gets even more complicated as any user input that is ‘hidden’ from the server can damage the user. A simple example is when the malicious string is contained in a URL’s fragment identifier (anything after the # character). Browsers do not send this part of the URL to servers, so the website has no way of accessing it using server-side code.
This situation is not limited to fragment identifiers. Other user input that is invisible to the server includes new HTML5 features like LocalStorage and IndexedDB.
Now a look at a simple example: Let’s imagine we have a simple app that personally greets the logged in user.
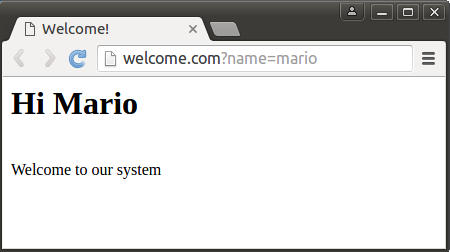
The value of the variable ‘name’ is extracted from the URL by client-side JavaScript.
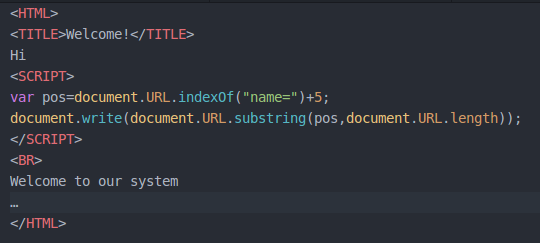
The script uses document.write to inject the extracted username to the DOM and render it in the Browser. This is done in such a manner that for attacker is able to manipulate the link and replace the name of the user with a script tag like welcome.com?name=<script>alert(“Hello Victim”)</script>.
As already mentioned, what makes this kind of attacks so special, is that the server doesn’t notice or have to do anything with the intrusion itself.
As said before, the problem has been the same for old and new web applications. But what are developers doing wrong? What can one do against this kind of attacks in order to protect users and servers intrusion?
Methods of preventing XSS
So let’s go back to basics, keeping in mind that an XSS attack is a type of code injection. In order to prevent this type of code injection, secure input handling is needed. For a web developer, there are two fundamentally different ways of performing secure input handling:
- Encoding: escapes the user input so that the browser interprets it only as data, not as code
- Validation: filters the user input so that the browser interprets it as code without malicious commands
While these are fundamentally different methods of preventing XSS, they share several common architectural parts of an application that are important to understand when using either of them:
Context
Input validation has to be performed differently depending on where in a page the user input is inserted. The expected data and its type have to be verified and proofed accordingly.
There are many contexts in a web page where user input might be inserted. For each of these, specific rules must be followed so that the user input cannot break out of its context and be interpreted as malicious code.
| Context | Example code |
| HTML element content | <div>userInput</div> |
| HTML attribute value | <input value=”userInput”> |
| URL query value | http://example.com/?parameter=userInput |
| CSS value | color: userInput |
| JavaScript value | var name = “userInput”; |
An example of how to take context into consideration, would be as following. If at some point a website inserts user input directly into an HTML attribute, an attacker would be able to inject a malicious script by beginning the input with a quotation mark.
For example, if at some point a website inserts user input directly into an HTML attribute, an attacker would be able to inject a malicious script by beginning his input with a quotation mark, as shown below:
| Application code | <input value=”userInput”> |
| Malicious string | “><script>…</script><input value=” |
| Resulting code | <input value=””><script>…</script><input value=””> |
This could be prevented by removing all quotation marks in the user input, but this would only work in this context.
Inbound/outbound
Input validation should be performed either when a website receives the input (inbound) or when the input leaves the page to the server (outbound).
It might seem that XSS can be prevented by encoding or validating all user input as soon as your website receives it. This way, any malicious strings should already have been neutralized whenever they are included in a page, and the scripts generating HTML will not have to concern themselves with secure input handling.
However, because of the uncertainty of in which context will user input used, it can be able be used in multiple contexts. And it is never a good idea to trust our own UI. Attackers will find ways to send or manipulate data in the page. But in general, it is important to consider outbound input handling as our primary line of defence against XSS.
Client/server
Secure input handling can be performed either on the client-side or on the server-side, both of which are needed under different circumstances. But at best, is performing validation at both ends.
- In order to protect against traditional XSS, secure input handling must be performed in server-side code. This is done using any language supported by the server.
- In order to protect against DOM-based XSS where the server never receives the malicious string, secure input handling must be performed in client-side code. This is done using JavaScript.
How to perform encoding and validation?
We will continue by explaining how the two types of secure input handling (encoding and validation) are actually performed.
Encoding
Encoding is the process of escaping user input so that the browser interprets it only as data, not as code. The most recognizable type of encoding in web development is HTML escaping, which converts characters like < and > into their HTML entities such as < and >, respectively. When all characters in the input were escaped, the browser will not parse any of the user input as HTML.
Encoding in client-side and server-side code
When performing encoding in your client-side code, the language used is always JavaScript, which has built-in functions that encode data for different contexts.
When performing encoding in your server-side code, you rely on the functions available in your server-side language or framework. The best thing to do in this cases is to go to your nerdy buddy and ask him for any recommendations on what encoding function to use and if there are any tested and know framework for this task.
Limitations of encoding
Even with encoding, it will be possible to input malicious strings into some contexts. A notable example of this is when user input is used to provide URLs. In situations like these, encoding has to be complemented with validation.
Validation
Validation is the act of filtering user input so that all malicious parts of it are removed, without necessarily removing all code in it. One of the most recognizable types of validation in web development is allowing some HTML elements (such as <em> and<strong>) but disallowing others (such as <script>).
There are two main characteristics of validation that differ between implementations
1. Classification strategy
User input can be classified using either blacklisting or whitelisting.
Blacklisting, Instinctively, it seems reasonable to perform validation by defining a forbidden pattern that should not appear in user input. If a string matches this pattern, it is then marked as invalid.
- Complexity and Staleness, Accurately describing the set of all possible malicious strings is usually a very complex task and even if a perfect blacklist were developed, it would fail if a new feature allowing malicious use were added to the browser.
One should aggregate security measures in order to cover as much ground as possible. But because of these drawbacks, blacklisting as a classification strategy is strongly discouraged. On the other hand is Whitelisting is usually a much safer approach.
Whitelisting, is essentially the opposite of blacklisting: instead of defining a forbidden pattern, a whitelist approach defines an allowed pattern and marks input as invalid if it does not match this pattern.
- Simplicity and Longevity, Accurately describing a set of safe strings is generally much easier than identifying the set of all malicious strings, and unlike a blacklist, a whitelist will generally not become obsolete when a new feature is added to the browser.
2. Validation outcome
User input identified as malicious can either be rejected or sanitised.
Rejection, The input is simply rejected, preventing it from being used elsewhere in the website.
Sanitisation, All invalid parts of the input are removed, and the remaining input is used normally by the website.
Of these two, rejection is the simplest approach to implement. That being said, sanitisation can be more useful since it allows a broader range of input from the user. Extremely important for sanitation is the use of well-tested libraries and frameworks whenever possible.
So when to do what?
Encoding should be your first line of defense against XSS, because its very purpose is to neutralize data so that it cannot be interpreted as code. In some cases, encoding needs to be complemented with validation, as explained earlier. This encoding and validation should be outbound, because only when the input is included in a page do you know which context to encode and validate for.
As a second line of defense, you should use inbound validation to sanitize or reject data that is clearly invalid. While this cannot by itself provide full security, it is a useful precaution if at any point outbound encoding and validation is improperly performed due to mistakes or errors.
If these two lines of defense are used consistently, your website will be protected from XSS attacks. However, due to the complexity of creating and maintaining an entire website, achieving full protection using only secure input handling can be difficult. As a third line of defense, you should also make use of other security measures such as the Content Security Policy (CSP).
To wrap things up
XSS, not to be confused with CSS, is a code injection attack made possible through bad handling of user input. A successful XSS attack allows an attacker to execute malicious JavaScript in a victim’s browser, and compromises the security of both the website and its users.
There are three types of XSS attacks:
- Persistent XSS: the malicious input comes from the website’s database.
- Reflected XSS: the malicious input originates from the victim’s request.
- DOM-based XSS: the vulnerability runs in the client-side code rather than the server-side code. The server never finds out about it.
The most important way of preventing XSS attacks is to perform input handling in order to validate and given the case sanitize the input.
- Secure input handling has to take into account which context of a page the user input is inserted into, this means where is the input to be used.
- Encoding should be performed whenever user input is included in a page. And validation of the input has also to be taken into consideration.
- Secure input handling has to be performed in both client-side and server-side code.
- Use well-tested frameworks for this and regularly check for updates framework.
So to conclude, XSS will be around us as long as attackers find a way to get their malicious code to the user or into the system. Make a perfect system in which all holes are close is an extremely complex task if not impossible. But a good start is to make a solid application with a good foundation which implements secure data handling mechanisms.
Hope this guide has given you a little insider view into the topic of XSS. As a developer take into consideration the points related in this post and try to apply them. As a user keep in mind that the web is a big open place and not all links are that good, especially the ones that promise free smilies.
Leave a Reply
You must be logged in to post a comment.