In our project we primarily implemented Spark applications, but we used components of Apache Hadoop like the Hadoop distributed file system or the cluster manager Hadoop YARN. For our discussion in the last part of this blog article it is moreover necessary to understand Hadoop MapReduce for comparison to Apache Spark. Because of this we first give a short Overview of the Apache Hadoop Ecosystem and in the next part we introduce Apache Spark and parts of our development.
Overview of the Apache Hadoop Ecosystem
Apache Hadoop is a framework for distributed processing of large data sets across large computer clusters consisting of thousand of machines. The Hadoop framework consists of the following three core modules:
- Hadoop Distributed File System (HDFS)
- Hadoop YARN
- Hadoop MapReduce
Following, we want to introduce this modules in a nutshell.
Hadoop Distributed File System (HDFS)
The Hadoop distributed file system is based on the Google File System (GFS) and they are in the most important properties equivalent [4].
The Google File System consists of one master node (in HDFS called name node) and any number of chunk servers (in HDFS called data nodes). The master node manages the meta data of the file system and the files such as directories or meta-data of files for example the location [5]. The actual files are stored on the chunk servers [5] (data nodes). The figure below shows how the Google File System works. An app or client requests the master node for a file. Then the master returns an address of a chunk server where the file can be requested. Afterwards the app direct requests the file from the appropriate chunk server.
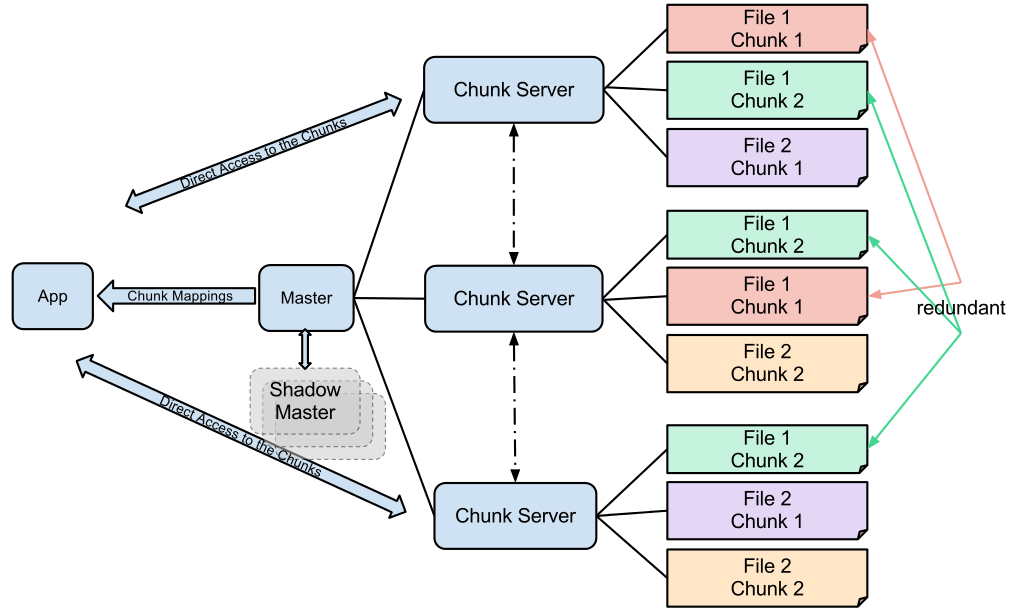
Image: https://en.wikipedia.org/wiki/File:GoogleFileSystemGFS.svg
{kind=link}
The figure illustrates that files are copied redundant on multiple chunk servers [5]. In case a machine fails it is guaranteed that the file is available on another server.
Hadoop YARN (Yet Another Resource Negotiator)
YARN ist the cluster manager of the Hadoop framework and manages the resource and job management [1]. It also enables other (external) projects like Apache Spark to use the Hadoop distributed file system [2].
Hadoop MapReduce
In this section we describe in a nutshell the Google MapReduce algorithm. Like the name of the algorithm suggests there are two tasks, the map and the reduce task. A programmer of a MapReduce job implements a map and a reduce tasks.
Firstly, the input data will be read usually from the HDFS. The input data will be split into partitions. Then across the computer cluster multiple map processes will be started. Each map task processes a partition of the input data. All computation of the partitions happens in parallel.[3]
The result of the map tasks are key value pairs [3] which usually will be written back to the HDFS as intermediate data. Then these key-value pairs will be sorted across the computers in the cluster, so that all pairs with same keys are located in the same partition [3]. Now the reduce phase begins where multiple reduce processes will be started across the cluster [3]. Again, each reduce task processes a partition of the intermediate data [3]. The result of the reduce tasks are the final outcome of the MapReduce job.
Further Hadoop related projects
Beside this core modules there are several projects related to Apache Hadoop. For example HBase which is an open source implementation of Googles Big Table [6]. HBase is a scalable, distributed NoSQL database [6].
Another project is Apache Hive which was developed by Facebook. Hive delivers data warehouse functionality to hadoop applications. With Hive it is possible to query with SQL statements a database which is optimised for analytic issues and which is aggregated of usually heterogeneous data sources.[8][9]
In our projects we used SparkSQL which is – carefully expressed – something similiar to Hive. It also allows the aggregation of structured data from possible heterogeneous data sources. A list of Hadoop related projects can be viewed on the Hadoop Website http://hadoop.apache.org/.
Leave a Reply
You must be logged in to post a comment.