Apache Spark is a framework for fast processing of large data on computer clusters. Spark applications can be written in Scala, Java, Python or R and can be executed in the cloud or on Hadoop (YARN) or Mesos cluster managers. It is also possible to run Spark applications standalone, that means locally on a computer. Possible data sources for Spark applications are e.g. the Hadoop Distributed File System (HDFS), HBase (Hadoop distributed NoSQL Database), Amazon S3 or Apache Cassandra. [1]
The figure below shows the components of the Apache Spark framework.
Following, we will consider the most important core concepts as well as the components SparkSQL, Spark Streaming and MLlib. We developed our Applications in Java, so the following examples are written in Java.
Apache Spark Core
Resilient Distributed Datasets (RDD)
The core concept of Apache Spark is called Resilient Distributed Datasets (RDD). A RDD is a partitioned collection of elements which can be processed in parallel in a fault-tolerant manner. Fault-tolerant means, if any partition of an RDD is lost, it will be automatically executed again. You can create a RDD by transform an existing collection. Furthermore you can create RDDs by reading datasets from external data storages like distributed file systems or databases. We will show the basics of RDDs in a short example at the end of this section. [2]
First RDD Example
We used in our Project Spark in Version 1.6.1, although the newest release is 2.1.0. The reason for that are on the one hand dependency issues to other Hadoop projects, on the other hand was this the installed version in our Hadoop cluster. We will cover this issue in more detail in the Big Data Engineering part. In the code below there are implemented some of the concepts described above.
// create jspark configuration
SparkConf conf = new SparkConf().setAppName("First Spark Test");
// create java spark context
JavaSparkContext jsc = new JavaSparkContext(conf);
// create test data
List<String> data = Arrays.asList("This","is","a","first","spark","test");
// create a simple string rdd
JavaRDD<String> firstRDD = jsc.parallelize(data);
// save to hdfs
firstRDD.saveAsTextFile("hdfs://..user/syseng/simple_spark_test/example.txt");
// read text file
JavaRDD<String> tfRDD = jsc.textFile("hdfs://../user/syseng/simple_spark_test/example.txt");First we have to create a Spark Configuration where we set the Name of the Application (line 2). Additionally, we need a Spark Context which expects the Configuration as Parameter (line 4). In line 7 we initialize a usual Java list. This list we pass as parameter to the parallelize-method in line 9 of the Spark Context object. This method transforms the list into an RDD, which means that the elements of the list will be partitioned. It is possible to pass a second parameter which indicates in how many partitions the List should be divided. If this program will be executed on a computer cluster, each host would process a partition for example. With the saveAsTextFile-method in line 11 the results will be saved in a file system for example a Hadoop File System. In the last line there is shown another way how an RDD can be created. The method textFile of the Spark Context reads a text file e.g. from a hadoop distributed file system and transforms the lines of the text file into an RDD of strings.
RDD Operations
There are two types of operations you can apply on RDDs: transformations and actions. An transformation is applies a function to each element of an RDD and returns a new (transformed) RDD. An action actually calculates a result for the driver program. In Spark you build pipelines with higher order functions in the manner of functional programming like shown in the figure below. Each pipeline will be executed only if an action operation is called on a pipeline. That means if a Pipeline consists only of transformations, nothing will be executed. Each time an action is called on a Pipeline all transformations will be recomputed. To prevent this, parts of the pipeline can be cached by calling the appropriate methods (cache or persist).[3]
Assuming we continue the code example above and we want to invoke operations on the firstRDD object. In the code below, on the RDD object a method map is called, which is a higher order function. This method we pass a Java Lambda expression. The map function transforms each string in the list into upper-case letters. The reduce function concatenates the strings pairwise. The result is one string with all strings of the RDD transformed into uppercase-letters and concatenated together.
String sentence = firstRDD.map( str -> str.toUpperCase())
.reduce( (str1,str2) -> str1 +" "+str2);
// result: THIS IS A FIRST SPARK TESTRDD Persistence – Storage Levels
Per default Spark caches all intermediate results, like the result of the map operation in the example above, in memory. The storage level can be configured. For example if data with huge size is processed the intermediate results can be stored on disk. The possible storage levels can be viewed in the programming guide of Apache Spark: http://spark.apache.org/docs/latest/programming-guide.html#rdd-persistence.
So at this point we covered the very basics of Apache Spark. There are more concepts and operations which you can read on the Apache Spark programming guide.
Spark SQL
SparkSQL is something similar to Apache Hive. Both allow querying structured data from heterogeneous data sources with SQL statements.
In the example below the json method of an Spark SQL Context loads a JSON-file containing multiple people-JSON objects and transforms the jsons into rows of a data frame.
// create sql context with java spark context
SQLContext sqlContext = new SQLContext(jsc);
// read people.json and transform into data frame
DataFrame dfPeople = sqlContext.read().json("hdfs://path/to/file/people.json");A data frame in Spark can be compared to relational database tables or a python data frame [6]. That means the JSON-file above is transformed into a table where the attributes represents the columns like pictured below. A people JSON simply consists of the two attributes name and age.
| name | age |
| Tim | 24 |
| Max | 45 |
Now on this data frame SQL statements can be executed like shown below. First of all a table name which can be referenced in the SQL statements have to be declared. This happens in the first line with the registerTempTable method. The Table will be named “people”. With the sql method of the Spark SQL Context SQL statement can be executed. This method returns a new data frame. In line 2 we define a statement which returns all data sets of the data frame where the column age has a value lower than 40.
dfPeople.registerTempTable("people"); // now this table name can be used in queries
DataFrame dfPeopleUnder40 = sqlContext.sql("SELECT * FROM people WHERE age < 40");
dfPeopleUnder40.show(); // print table in consoleThe show method is part of the Spark Data Frame API and prints the table into the console. The Data Frame API is an alternative way to query a data frame in Spark. For example the SQL statement above can be programmed with the Data Frame API like this:
DataFrame dfPeopleUnder40 = dfPeople.filter(col("age").lt(40));There are many possible data sources for a Spark data frames, such as mentioned above structered data (json, csv etc.) or external databases, existing RDDs or hive tables [6]. Thus SparkSQL can be used to read data from Hive tables.
Spark Streaming
The Spark Streaming module allows application to process streams of many data sources like Apache Kafka, Apache Flume or I/O streams such as TCP sockets or files. It is an extension of the core module and allows scalable and high-throughput stream processing in a fault-tolerant manner. The data of a spark stream can be processed with the high-level functions like map or reduce (like shown in the rdd operations section). [7]
Primarily, Spark is actual doing micro-batch processing. This means the received input data is divided into batches like shown in the figure below [7].
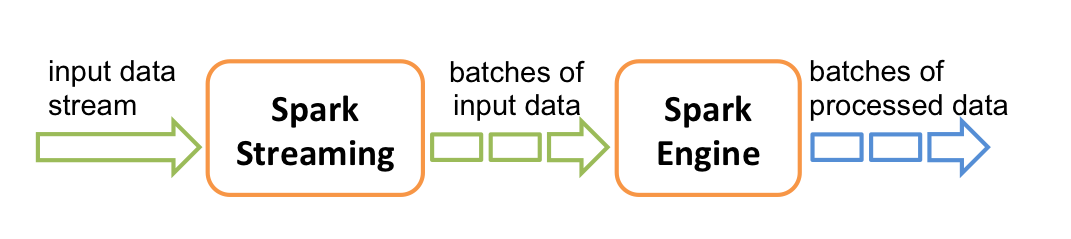
image source: https://blog.mi.hdm-stuttgart.de/wp-content/uploads/2023/08/streaming-flow.png
In the example below firstly a Spark Streaming Context is created. The second parameter defines the batch interval, in this case 10 seconds. This means the stream source will be read for 10 seconds. Then the data which was collected in this time will be processed. In line 2 via the Streaming Context a text file stream is created. The wildcard (*) says that every text file in this directory should be read. The textFileStream method returns a DStream, which represents a continuous stream of data and is a high-level abstraction in Spark Streaming [7]. A DStream is actually a sequence of RDDs [7].
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(10));
JavaDStream<String> txtStream = jssc.textFileStream("hdfs://path/to/dir/*.txt");
txtStream.foreachRDD(rdd -> {
rdd.saveAsTextFile("hdfs://path/to/result/result"+new Date().getTime()+".txt");
});In this simple example the data of the text file stream will be saved in other text files in the HDFS.
MLlib (Machine Learning Library)
The MLlib component contains among others distributed implementations of common machine learning algorithms based on RDDs. For example topic modelling (LDA), logistic regression, K-means and many more. Furthermore there are features like utility classes for vector, matrix computation etc., machine learning pipeline construction or persistence of models [9]. An overview of this component can be seen on the Apache Spark Website: http://spark.apache.org/mllib/
Leave a Reply
You must be logged in to post a comment.