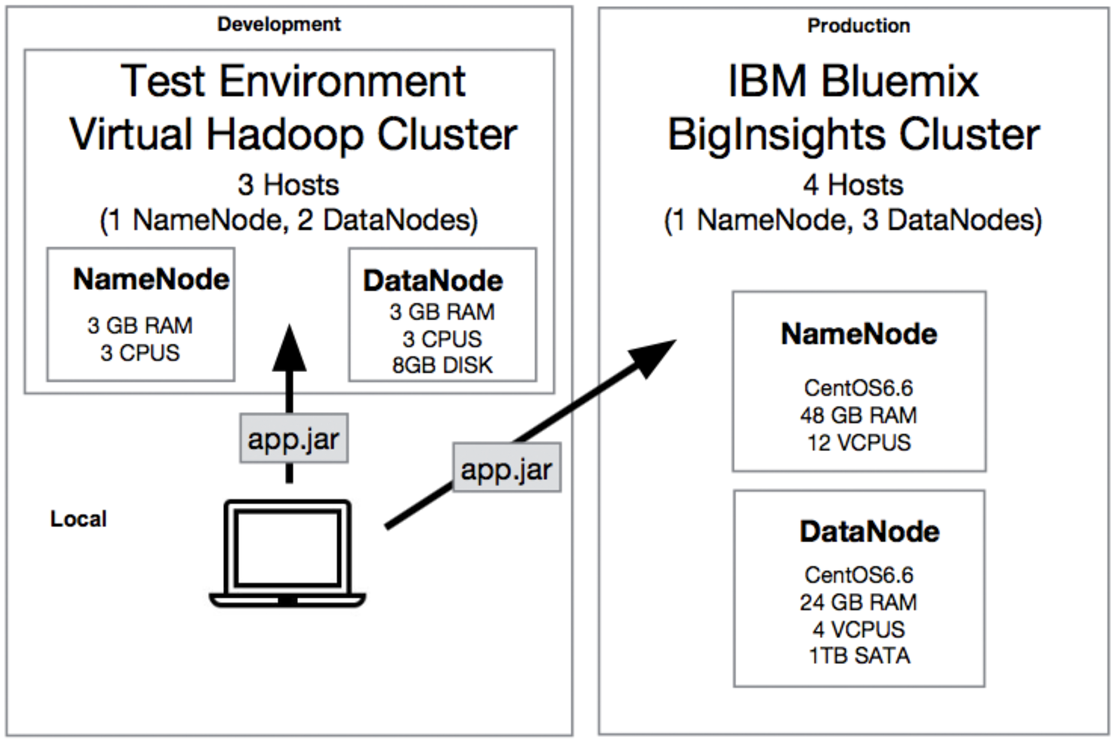
Our objective in this project was to build an environment that could be practical. So we set up a virtual Hadoop test cluster with virtual machines. Our production environment was a Hadoop Cluster in the IBM Bluemix cloud which we could use for free with our student accounts. We developed and tested the logic of our Spark applications with a small amount of data local or in the virtual test cluster. After that we run the applications in the cloud with perhaps higher amount of data. The figure below shows our clusters and their capabilities.
Virtual Hadoop Cluster
For setting up the virtual test cluster with virtual machines (VirtualBox) and Vagrant we oriented towards this tutorial: https://cwiki.apache.org/confluence/display/AMBARI/Quick+Start+Guide .
Vagrant is an application for managing virtual machines. It is a wrapper between virtualization software (e.g. VirtualBox) and software configuration management software like puppet. [10]
We used Vagrant to define in a central place (Vagrant File) the properties like amount of cpus and memory of the virtual machines. Furthermore we configured port forwarding to SSH and port 8080. So, we was able to connect to the virtual machines via SSH from our host operating system. We set up the cluster with Apache Ambari which is a tool for managing and installing Hadoop clusters. Ambari provides a Web UI which we could access from our host operating system via port 8080. Through this Web UI we installed the virtual Hadoop cluster with all the needed components and projects like HDFS, MapReduce, YARN, Apache Spark etc. The approach described above sound really easy, but most of the time it was really annoying and it took as a long time until the cluster run stable with the virtual machines. Many projects had to be installed and minimal network problems caused the failure of the whole installation. Furthermore, there was memory and disk space issues. Managing and configuring a Hadoop cluster isn’t that easy. The virtual cluster consisted of three virtual machines.
At the beginning, we tried to install the Hadoop projects manually. There we realized that between Hadoop related projects and Spark are many dependency issues. Even between Spark components. Because of this a tool like Apache Ambari is very useful, because it considers this dependency issues. The version of Apache Ambari we used was one of the newest and it installed Apache Spark in Version 1.6.2. But the newest version of Apache Spark was Version 2.1.0. This is certainly referable to this dependency issues.
IBM Bluemix Big Insights
From the IBM Bluemix cloud we choose a service called BigInsights. This service offered us a pre-installed hadoop cluster with all the projects we needed e.g. HDFS, Apache Spark. We also could manage the cluster with a Apache Ambari Web UI and connect to the cluster via SSH like in our test environment. The version of Ambari on Bluemix was the same as the version of our test environment. With our student accounts we could use a cluster consisting of four powerful computers with 24-48 GB RAM, 12 VCPUs and nearly 1 TB disk space for free.
Part 5 – Spark Applications in PIA project
Leave a Reply
You must be logged in to post a comment.