Motivation
Many of today’s supply chain management (SCM) solutions still involve enormous amounts of manual work. The procedures required for proper record keeping often rely on manual input, which makes them slow and prone to errors. Additional terms, such as price agreements, conditions that must be strictly adhered to, as well as penalties for neglection of the latter, rely heavily on the completeness and correctness of the recorded information.
The infographic “The Paper Trail of a Shipping Container”, published by IBM, outlines the challenge to improve the management with blockchain technology, using the global container shipping industry as an example.
Why Blockchain?
Ever since a blockchain implementation started to serve as the underlying technology for the cryptocurrency Bitcoin in 2009, the general concept of Distributed-Ledger-Technologies (DLTs) has gained a lot of attention from modern industry. During the past years, varying approaches and the continuous development and integration of additional features, such as “smart contracts”, have opened up new possibilities to leverage this technology.
One of the main arguments that justify the significance of these systems is the industries’ growing need for transparency, scalability and security. Their uses include the digitization and automation of complex, trust-based processes, like the ones that exist in supply chain management, property management or certification of provenance.
This article documents our first experience with the Hyperledger project and some of the tools it offers to developers, as well as our own attempt to create a small partial model for an SCM scenario.
The Hyperledger Project
Hyperledger is an independent umbrella project for open source blockchain technologies. Its goal is the creation of modular tools that enable developers to implement software applications based on a distributed ledger. Conceived by the Linux foundation in 2015, the Hyperledger project has since spawned a variety of subprojects that focus on infrastructure, modelling, deployment, analytics and more. These projects are in turn carried by companies like Intel, IBM and Huawei, as well as a growing community of developers.
During the past semester we set out to explore the features of three of these projects and how they play together: Hyperledger Fabric, Hyperledger Composer und Hyperledger Explorer.
Hyperledger Fabric
Hyperledger Fabric (called HLF from here on out) is a docker-based blockchain implementation created by IBM and Digital Asset. It may serve as an underlying infrastructure on which other toolings, like Composer or Explorer, can run. HLF offers a permissioned blockchain platform, including consensus models, a membership service and smart contracts (“chaincode”) written in Java, JavaScript or golang. It really is just a platform for other projects to use and does not focus on any specific use case by itself.
Hyperledger Composer
Hyperledger Composer is a node.js based modelling and development tool for distributed business applications built on HLF. It offers its own modelling language CTO, the creation of smart contracts and extensive testing capabilities. Composer sits on top of HLF and can directly interface with its containers, providing a level of abstraction between low level processes and business logic (e.g. for identity management). It also provides a sandbox mode, “Composer Playground”, that simulates an HLF inside a web browser. This is great for developing and testing your model without actually going through the effort of deploying it on a real HLF.
Hyperledger Explorer
Hyperledger Explorer is a visualization and analytics tooling, also based on Node.js, that creates a representation of the HLF, its history and state using a MySQL database.
It also offers a nice web frontend and allows directly observing blocks, transactions and their content in real time.
Preparation
Platform
We chose Ubuntu as our base OS. This choice was made mainly to avoid unnecessary headache – most of Hyperledger is documented with Ubuntu in mind. It also helps that Linux is the dominant OS in the cloud sector.
Initially we had planned to run Ubuntu using the HdM’s VM hosting service. The idea was to have an always running virtual machine, accessible via SSH, VNC and HTTP. This would have allowed us to make some web interfaces available within the HdM intranet for demo purposes, to see each other’s changes in real time and to have snapshots available in case of any breakage.
This plan fell through for a couple of reasons: The standard VM configurations weren’t running full Linux systems but kernelless ones that didn’t support any kind of container virtualization.
After some investigation we had a full working KVM set up, (although only available running Debian) but we still ran into problems with Docker and Docker-Compose.
At this point we had to reevaluate, whether using a hosted VM really made sense for us.
Eventually, we decided to work on local VirtualBox VMs running Ubuntu 16.04 LTS. This was the most stable solution, as both of us could work on the same setup and configuration, while not running the risk of write collisions, and any kind of synchronization was now properly managed though Git.
Scope
- Understand the capabilities of blockchain technology
- Learn how Hyperledger implements these principles and what makes it special
- Create and deploy our own model, based on a given use case
- No concrete POC
The project definition started out very broad – neither of us had much prior experience with blockchains, so we wanted to explore the technology and find out what it can do, before focusing on a specific application. That’s why our roadmap changed a few times and only settled half way through the semester.
HLF was our first point of contact with Hyperledger. We spent the first weeks learning the lower level workings of Fabric, its structure and how it creates and manages its ledgers. At that time we thought we could limit ourselves entirely to Fabric. Later it became clear, that this approach could not work. Fabric is an infrastructure, closer to an operating system than an application. Any development directly on HLF would have to be done from scratch, using the provided SDKs. This being way out of scope for our small project, we started looking for alternatives – any tools that would give us some level of abstraction, to let us focus more on our model. At that time, around October 2017, lots of new documentation and guides popped up for a tool called Hyperledger Composer. While HLF is broad and generic, Composer allowed us to finally limit our scope to specific use case scenarios.
Software Architecture
The Key Concept of Fabric
This is going to be a brief overview of Hyperledger Fabric, its architecture and services. If you’re interested in a deep dive into HLF, its features and inner workings are explained nicely in the official documentation.
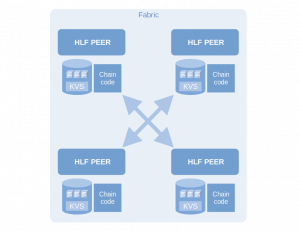
HLF is a peer-to-peer architecture that offers a shared “consensus” – by maintaining so called ledgers: representations of state and history, that are continuously synchronized between participants. The state is stored in a key-value-store and is a snapshot of participants and their data points, such as account balance. The transaction history is the ledger part, where all transactions are stored. At any given time, that history can be used to reproduce and verify the current state.
 Permissioned Blockchain
Permissioned Blockchain
A key difference between HLF and other DLTs (e.g. the Bitcoin platform) is HLF’s permissioned approach. Users are not anonymous, they must be authenticated and are assigned a unique identity. This is achieved by a dedicated entity called membership service provider (MSP), which provides abstraction against an underlying public-key infrastructure.
As with almost any process inside HLF, members and identities are managed through transactions on a network’s global ledger. Authentication is a necessary objective for the creation of confidential channels.
Channels
Channels are a key concept unique to HLF. In DLTs with only one global ledger (BTC), every transaction and state is visible to every member. In HLF, members can join channels, which are effectively subnetworks within a network. A channel maintains its own ledger and state, that are invisible to anyone outside the channel.
This means that HLF can offer its users confidentiality, an important objective when competing companies exist on the same network.
Peer
Peer nodes are the most versatile entities inside an HLF. They belong to members and can store and execute smart contracts (“chaincode”) on their behalf, perform read/write operations on the ledger, and more. From a developer’s perspective, they act a lot like servers and can be interfaced with using HLF’s supported SDKs and tools like Composer.
Orderer
The orderer is the essential service that manages synchronization between all members (through their peers), using one of its supported consensus services. It is technically designed to use any modular, pluggable consensus service available. We chose a “dummy” service called “SOLO” that is meant for development and testing only and only allows single user access
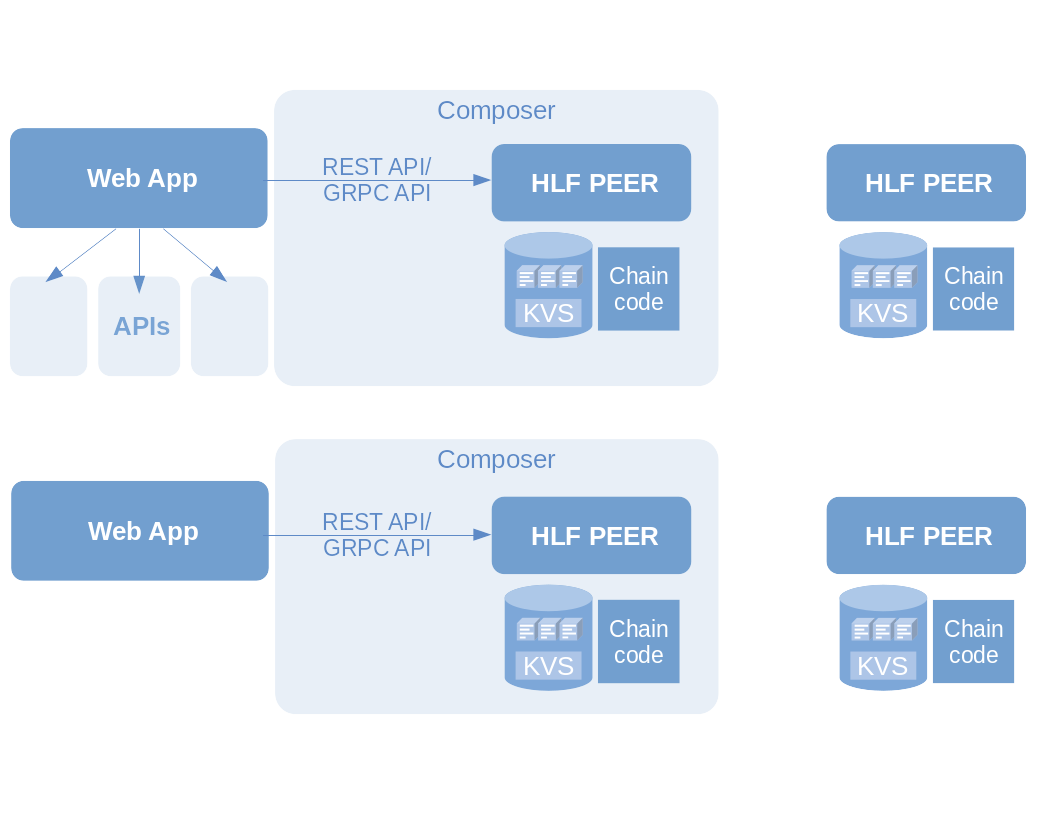
Composer on Fabric
Hyperledger Composer provides a very handy set of abstractions. Without Composer, we would have had two options: Managing our network and model by entering everything into obscure config files by hand, feeding the PKI with manually generated cryptomaterial and getting lost in the directory trees half the time – or building an application to do it for us.
Composer manages all that for us, at the cost of narrowing down our project focus to building business-specific applications. Specifically, Composer facilitates the following aspects:
- Modelling, coding and testing, e.g. via Composer Playground
- Deployment of created business networks to a running HLF
- Abstraction from the MSP through identity cards
- Interfacing with the network’s peers through REST or GRPC
CTO – Composer’s Modelling Language
In Hyperledger Composer, developers are enabled to implement the resources for their business model using the specific modelling language CTO. All resources, i.e. type definitions, must reside in a .cto file and always require a namespace.
The language features common primitive types that can be used for definitions of resources. Most of the resources can be modelled using an object oriented design.
Keywords for custom resource types are as follows:
- Participant
- Asset
- Transaction
- Concept
- Event
- Enumeration
The first three in the list are stereotypes for class definitions and serve particular purposes. Members of the network are modelled as participants, items with perceivable value that can be exchanged between members are modelled as assets. Transactions represent the type of objects that are associated with actual chaincode, that is, modifications of the ledger’s state.
All of these require an identifying field, in order to build relationships, i.e. reference other instances of these specific definitions.
Concepts are similar to the other classes, but rather treated as value objects. They cannot be referenced directly and do not have an identifying field.
Events are the mechanism used to generate notifications for external applications whenever changes occur or certain conditions are met. They will be triggered through chaincode, i.e. when transactions are issued.
Enumerated types (enums) are used to represent named integer values.
An asset definition might look like this:
asset LineItem identified by lineItemID
{
o String lineItemID
--> Order order
--> Product product
o Double unitPrice
o Integer unitCount
--> Terms additionalTerms
}An instance of a line item will be identified by its ID, as the very first line suggests. A leading ‘o’ declares a field that holds a value directly. The arrow ‘–>’ indicates that we’re referencing another resource using its ID.
Additional supported features include arrays, relationships, field decorators and field validators. Detailed information can be found in the documentation of the CTO modelling language.
Explorer on Fabric
Explorer is a handy way to visualize your blockchain. It allowed us to check if the transactions we made were properly created and tied up into blocks. It also provides meaningful information about the network in a way that is easily consumable.
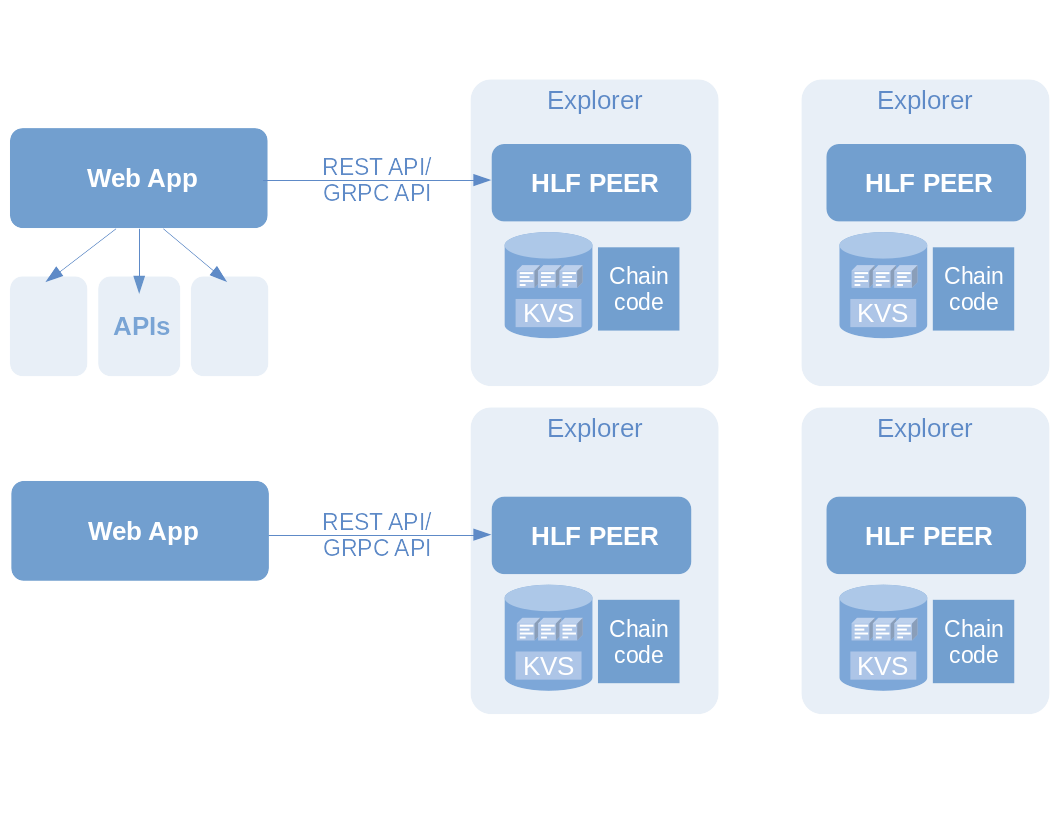
Caveat
This is how our setup really looks like. There is currently only one single member in our network, because SOLO does not allow multiple user access.
A working orderer, like Kafka or PBFT could be added down the line.
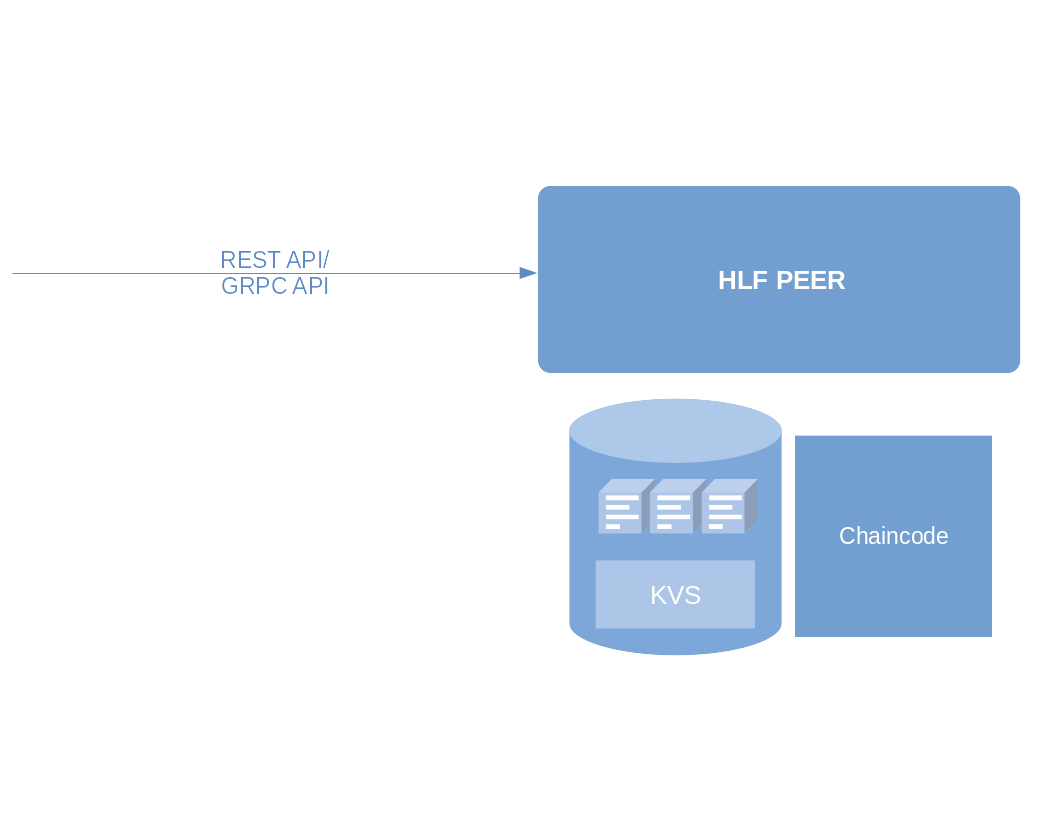
We still built our model with multiple access in mind, each operation we show could be replicated on another machine, that would get added to the network, be managed through the ordering and membership services and get their interface of choice installed on their peers.
In the second part of the blog post, we will take a closer look at our model as well as the setup and deployment workflow.
Leave a Reply
You must be logged in to post a comment.