This project was originally inspired by a talk Felipe Hoffa gave at the Github Universe conference last year. He talked about how we can analyse the code hosted on Github at a large scale to learn interesting things. I’m always excited about learning new programming languages, at the moment my favourite new langue is Elm, a small functional programming language for building web applications. After watching the talk I thought it would be nice to do this kind of analysis on all the public Elm code hosted on Github.
Initial Idea
The big question question is: Why isn’t it already possible to learn interesting things about the code hosted on Github? The problem is that Github works on the text level. All the code is just a huge collection of text files. It would be much more useful if we could operate on the structure which the text represents. Instead of searching for all files which contain the string “List.map” we could precisely search for all source files which actually contain a reference to the List.map function.
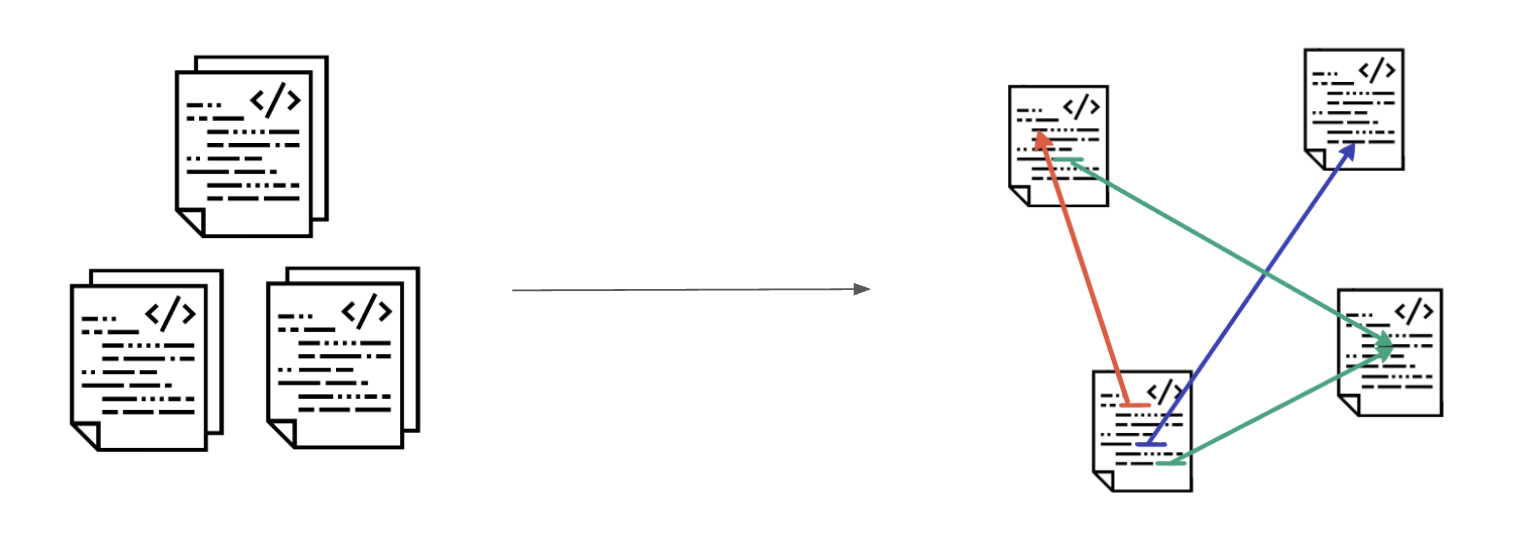
If we want to scale this approach to all the Elm files hosted on Github we need a few steps:
- Find all Elm repos
- Parse all the Elm files in each repos and extract the references
- Store the references and files in the db so they can be querried later
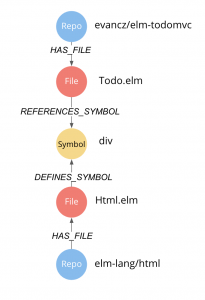
In my implementation I’ve limited myself to just storing which symbols a file defines and which symbols it references instead of storing the whole syntax tree of each file in the db. The resulting graph structure is represented in the graph below.
 I’m a notorious procrastinater (perfectly proven by the fact that I’m writting this blogpost on the day of the deadline), therefore I decided to submit my idea as a talk proposal for Elm Europe 2018 to give myself some accountability. I guess you could call this approach “talk driven development”. I was lucky and my talk got accepted by the conference.
I’m a notorious procrastinater (perfectly proven by the fact that I’m writting this blogpost on the day of the deadline), therefore I decided to submit my idea as a talk proposal for Elm Europe 2018 to give myself some accountability. I guess you could call this approach “talk driven development”. I was lucky and my talk got accepted by the conference.
Prototype for the conference talk
The focus of the prototype was to quickly get some results and see for which use-cases such a graph could be useful. I wrote a Node.js script which I ran on my local machine to import the data into a Neo4j Graph Database.
Example of the resulting dependency graph of the elm-todomvc repo:

In my talk, I’ve demonstrated some examples how you can use the graph
- get code examples for any library function
- check if a project is referencing any unsafe functions that can lead to runtime exceptions
The feedback was very positive, but the most commonly requested feature was to have a simple search interface for the graph that allows you to find code examples from other people to help you understand how to use a specific function.
Elm function search
I decided to take the lessons I’ve learned from my talk and turn the prototype into a practical application which allows people to search for code examples. I had to solve 2 problems to get there:
- Move the node.js script into the cloud
- Improve the robustness of the parser
Architecture
I build the crawler based on the AWS lambda architecture. The two steps fetching the repos and parsing each repo are two separate functions. The fetch repos function pushes a message for each new repo it finds to a worker queue which works as a buffer for the parsing jobs. The parse repo function is triggered for each repo in the queue. After the repo is parsed the function writes all the references it found to the database.
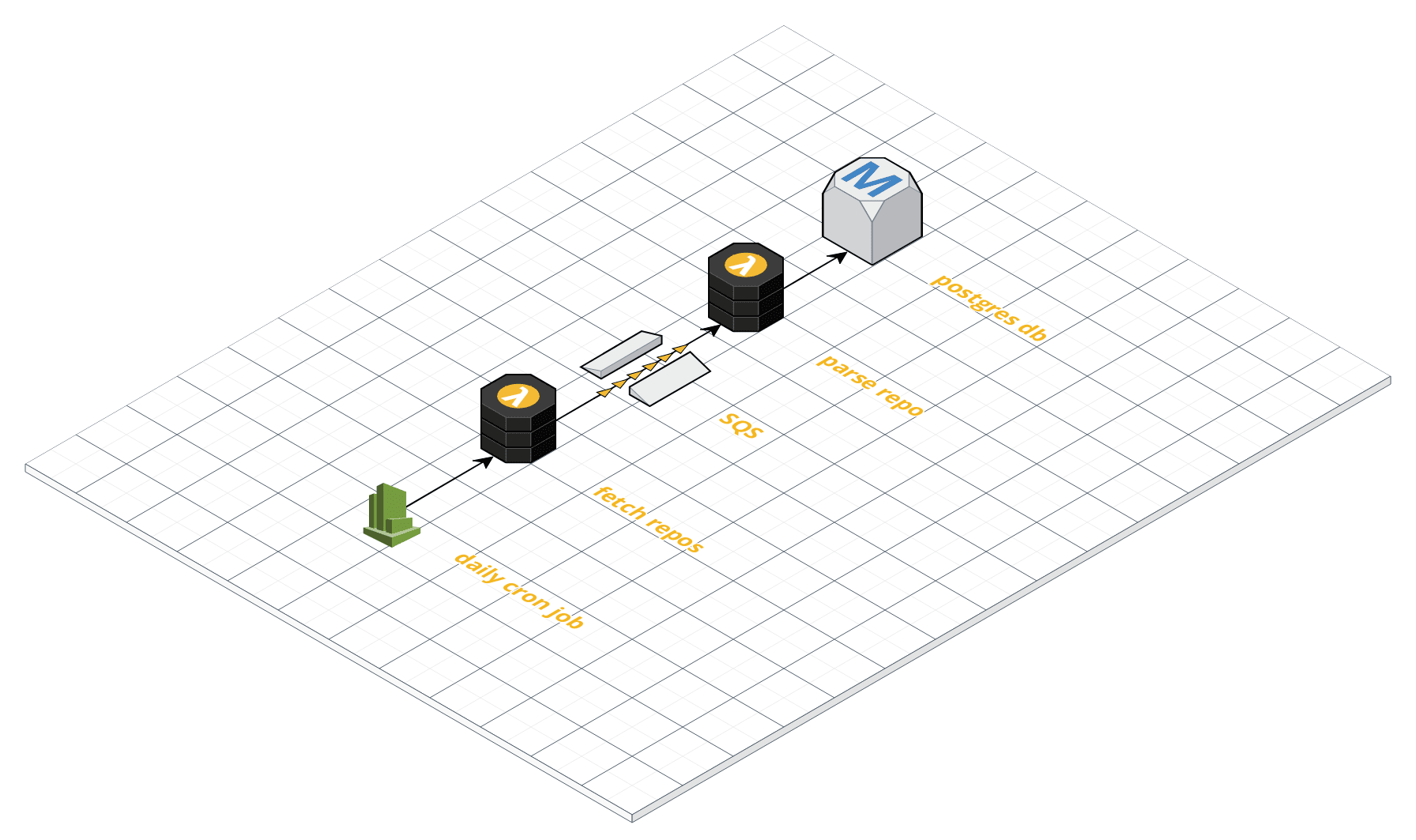 I’ve decided to switch to using Postgres instead of Neo4j. Because we’re just interested in finding matches code examples we don’t need the graph. Instead we can just store all the references in a simple table with one entry for each reference.
I’ve decided to switch to using Postgres instead of Neo4j. Because we’re just interested in finding matches code examples we don’t need the graph. Instead we can just store all the references in a simple table with one entry for each reference.knex.schema.createTable('references', (table) => {
table.increments('id').notNullable()
table.string('package').notNullable()
table.string('module').notNullable()
table.string('symbol').notNullable()
table.string('version').notNullable()
table.string('file').notNullable()
table.integer('start_col').notNullable()
table.integer('start_line').notNullable()
table.integer('end_col').notNullable()
table.integer('end_line').notNullable()
table.string('repo_owner').notNullable()
table.string('repo_name').notNullable()
table.string('commit_hash').notNullable()
table.foreign(['repo_owner', 'repo_name'])
.references(['repos.owner', 'repos.name'])
})The API server can then be implemented as a simple node services which acts as a thin layer between the frontend and the database. I’ve decided to use zeit.co to host the API server. Zeit is a startup that allows you to deploy Node.js applications to the cloud without any configuration. You can also scale up applications easily by running multiple instances of it which are automatically load balanced.
Fetching all repos
I had to go through several iteration to solve this problem because unfortunately Github doesn’t provide a direct API to get all repos of a specific programming language. Initially I used the Github Dataset which Filipe also used in his talk. The problem with that approach was that the dataset only contained repos where Github could detect an open source license. This meant that a lot of Elm repos where missing in the data set.
The Elm language itself also has a package repository which contains all the published Elm packages. But this again is just a fraction of all the public elm repos.
Finally I had another look at the Github search API which allows to use programming language as a filter criterion but with the caveat that you can only access the first 1000 results. But I figured out a trick to get around this restriction. I sort the repository by the timestamp when they were last updated then I fetch the first 1000 results. In the next batch I use the timestamp of the last result as an additional filter criterion to get only repos which haven’t been updated more recently. That way I can incrementally crawl all repos. It’s a little bit hacky, but it works.
Sending repos to worker queue
I’m using the serverless framework to setup my application. To connect the fetch repos function with the parse repo function I need to define a queue as an additional resource in my serverless.yml
RepoQueue:
Type: "AWS::SQS::Queue"
Properties:
QueueName: "RepoQueue"I also need to add the ACCOUNT_ID and the REPO_QUEUE_NAME to the environment of my lambda functions so I can address the queue I’ve defined previously
REPO_QUEUE_NAME:
Fn::GetAtt:
- RepoQueue
- QueueName
ACCOUNT_ID:
- Ref: 'AWS::AccountId'Before our lambda function can send messages I also need to add a new permission in the role statements.
iamRoleStatements:
- Effect: Allow
Action:
- sqs:SendMessage
Resource: arn:aws:sqs:*:*:*After I’ve setup the queue and added the correct permissions I can use the AWS SDK to send the fetched repos to the queue.
const AWS = require('aws-sdk')
const {REPO_QUEUE_NAME, ACCOUNT_ID} = process.env
// Create an SQS service object
const sqs = new AWS.SQS({apiVersion: '2012-11-05'});
module.exports = async ({ owner, name, stars, lastUpdated, license}) => {
return new Promise((resolve, reject) => {
sqs.sendMessage({
DelaySeconds: 10,
MessageBody: JSON.stringify({
owner,
name,
stars,
license,
lastUpdated
}),
QueueUrl: `https://sqs.us-west-1.amazonaws.com/${ACCOUNT_ID}/${REPO_QUEUE_NAME}`
}, (err, data) => {
if (err) {
reject(err)
return
}
resolve(data)
})
})
}Parsing repo
This step also took several iterations to get right. In my prototype I used a modified version of the Elm compiler which spits out all the symbols it discovered during compilation. Alex, who I met at the Elm Meetup in SF helped me with that. This worked well enough for the prototype but it wasn’t a stable solution. First of all I would need to maintain a fork of the compiler, which would be hard for me since I barely know any Haskell.
Next I tried to use the elm-ast library which is a Elm parser implemented in Elm. This looked promising at first and also had the benefit that I could easily run it in node directly because all Elm code compiles to Javascript. But I also ran into some some issues:
- the library didn’t cover all edge cases of the elm syntax. Some valid Elm files would lead to parsing errors.
- Positional information which maps the symbols back to the sourcefile was only rudimentarily implemented and had some bugs
- the performance was really slow. Sometimes it took up to several seconds to parse a single file.
Especially the performance issue combined with the fact that the repo wasn’t actively maintained made the elm-ast library not usable either
In the end I landed on the elm-format library. It’s a code formatting library that automatically formats your Elm code. Brian, who I met at elm Europe introduced me to Aaron the creator of the library. They were already working on adding a flag which export the syntax tree for a file, but the efforts have been pushed back because so far there hasn’t been really a concrete usecase for this. Araon also added positional information. This problem had only one drawback: The library was written in haskell, which meant I had to run custom binaries inside of AWS Lambda.
Running Haskell code inside of AWS Lambda
In principle you can run any binary inside of an AWS Lambda function. The problem is that the environment is an extremely trimmed down Linux. Most binaries depend on external libraries which are dynamically linked. If you run such a binary inside of a lambda function it won’t work because the external libraries are missing.
This was also the case with the elm-format binaries. I had to build the binaries myself with all the dependencies linked statically. For this I had to modify the cabal config file of elm-format
executable elm-format-0.19
ghc-options:
-threaded -O2 -Wall -Wno-name-shadowing
hs-source-dirs:
src-cli
main-is:
Main0_19.hs
build-depends:
base >= 4.9.0.0 && < 5,
elm-format
ld-options: -static // added static option
executable elm-format-0.18
ghc-options:
-threaded -O2 -Wall -Wno-name-shadowing
hs-source-dirs:
src-cli
main-is:
Main0_18.hs
build-depends:
base >= 4.9.0.0 && < 5,
elm-format
ld-options: -static // added static optionAfter that I build the binary from source.
stack install --ghc-options="-fPIC"
At first I tried to run it on my MacBook which didn’t work because MacOS doesn’t provide a statically linkable version for all libraries. I solved this problem by quickly spinning up a Linux VM on Digital Ocean and building elm-format there. This illustrates nicely that the cloud is not only useful for scalable deployments but can also help during development.
Writing results to the database
Finally we need a Postgres database which stores all the references. We can add this as another resource in our serverless.yml file. We also need to create a SecurityGroup for the Database which makes the database accessible. Right now I’m using hardcoded values for the credentials. A better solutions would be to use the AWS Systems Manager to store the credentials.
pgSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Acess to Postgres
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '5432'
ToPort: '5432'
CidrIp: 0.0.0.0/0
pgDB:
Type: "AWS::RDS::DBInstance"
Properties:
DBName: "elmFunctionSearch"
AllocatedStorage: 5
DBInstanceClass: "db.t2.micro"
Engine: "postgres"
EngineVersion: "9.5.4"
MasterUsername: "master"
MasterUserPassword: "test12345"
VPCSecurityGroups:
- Fn::GetAtt:
- pgSecurityGroup
- GroupId
DeletionPolicy: "Delete"We also need to add the credentials and the host of the db to our environment so we can access the database later
DATABASE_HOST:
Fn::GetAtt:
- pgDB
- Endpoint.Address
DATABASE_USER: "master"
DATABASE_SECRET: "test12345"
DATABASE_NAME: "elmFunctionSearch"Inside our application we can then construct a connection string to connect with the database
const {DATABASE_HOST, DATABASE_USER, DATABASE_SECRET, DATABASE_NAME} = process.env
const connectionString =
`postgres://${DATABASE_USER}:${DATABASE_SECRET}@${DATABASE_HOST}:5432/${DATABASE_NAME}`Final Result
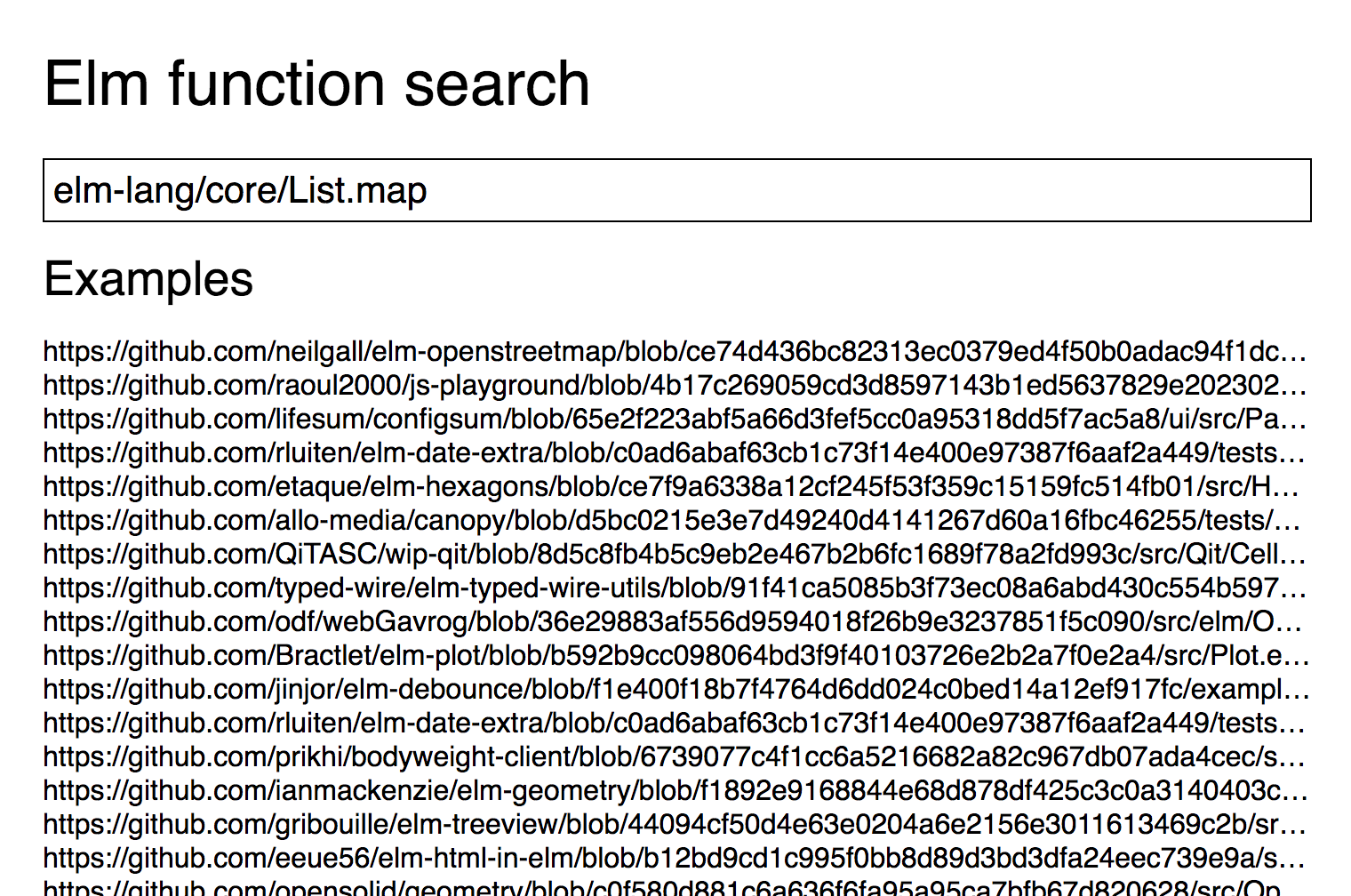
The search is very basic at the moment. The user can enter the name of a function.
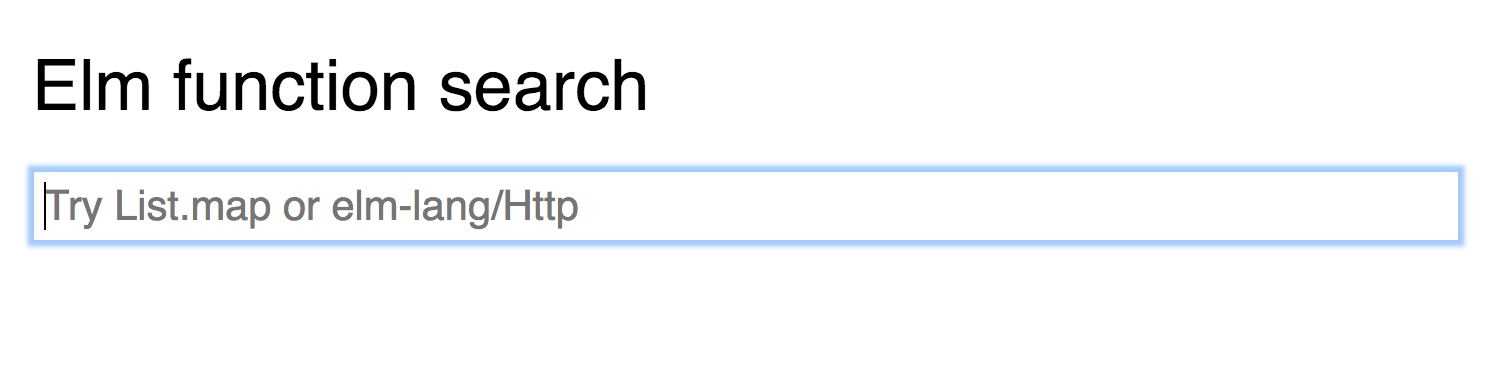
If there are multiple matching functions the user can select which package they meant.

The result is a list of links to github files which use the function
Leave a Reply
You must be logged in to post a comment.