Motivation

The idea for this project occurred to me while I was listening to my sister share her vision for her recently started blog: To create a platform where writers of different ethnicity can publish texts in their native languages and exchange their stories with people from all over the world. Conquering the language barrier and making the texts available at least in the three most prominent languages – German, English and Arabic – requires the involvement of translators who are fluent in at least two of the demanded languages. Anyone who has ever attempted to make a translated text sound natural knows that this is no easy feat and can take up to many hours of finding the perfect balance between literal translation and understandable text.
This is where I saw room for improvement. Nowadays, machine translation tools have reached a decent level of fluency, despite not being able to capture the intricacies of different linguistic styles. Combining them with people who have a basic understanding of the source language can help speed up the process and reduce the effort considerably.
Project
I decided to use a web application as the interface between the users – the authors and translators – and the machine translator module. Since I wanted to concentrate on the language translator itself, I created a simple frontend with HTML, CSS and JavaScript and used the Python framework Flask for the backend. The application’s functionality includes the following:
- Registering: The user registers on the website by leaving their name, email address and first language. Furthermore, they can state their role as an author, a translator, or both. This determines whether they will be able to submit texts and correct machine translations.
- Submitting texts: As previously stated, users with the author role can submit their texts, which will then be passed to the translator module to be translated to the target language – in this case, English. The text’s source language can either be specified by the author or will be automatically identified by the translator module.

Passing the submitted text to the translator module while specifying which model to use - Correcting machine translations: This step is crucial for the comprehensibility of the translated text, as well as the fluency. Translators can view the machine translated text alongside the original version and correct it when necessary. For this task to work, the translator needs to have a good understanding of the target language, whereas a basic understanding of the source language suffices to grasp the meaning of the text. Admittedly, this might not be true for highly complex texts, in which case the translator has to be fluent in both the source and the target language.
- Saving corrected versions: The corrected translation is saved along with the original text and can then be forwarded to an administrator of the blog.
For the database that manages the users and texts I chose to use a simple SQLite database with the SQLAlchemy toolkit due to its straightforward interoperability with the Flask framework. The machine translator on which I based the translator module is the IBM Watson Language Translator, specifically the Python SDK of the Watson Developer Cloud.
IBM Watson Language Translator
The IBM Watson Language Translator is part of the Watson Developer Cloud, a collection of cloud services, applications and tools which utilise different aspects of Artificial Intelligence. As the name suggests, it is used to translate text from one language to another, offering support for more than ten languages. Apart from being able to produce translations, the Watson Language Translator can also identify an even larger number of languages from a given text.
As mentioned earlier, different domains of text have different requirements concerning their translation. This also holds true for different languages. For this reason, the Watson Language Translator offers three different types of pre-trained models for the use in fields with specific linguistic characteristics:
- The dialog domain can be used for everyday language such as text messages and colloquial speech, which can be helpful when building multi-language service chat bots.
- The news domain is used for news-specific language and can for example be applied to translating Twitter posts.
- The patent domain was trained for technical and legal terminology and can be used for such texts.
Customising the IBM Watson Language Translator
Since the posts which are published on the blog in question cannot be mapped to any of these domains as they are mostly poems and short stories, I had to find a different method. Luckily, this method is already included in the Watson Language Translator since it offers ways to train a customised model which can be done for any domain, provided that a large amount of data is available for use. The three possible ways to do this are explained here:
- Use of a forced glossary: A forced glossary is a dictionary which contains pairs of words or expressions in the source and target language respectively, which overwrites the internally used dictionary. This is done by inputting the pairs into a file with the TMX data format.
- Use of a parallel corpus: The parallel corpus is similar to the forced glossary, but differs in the aspect that the dictionary used here does not overwrite but add to the pre-existing dictionary.
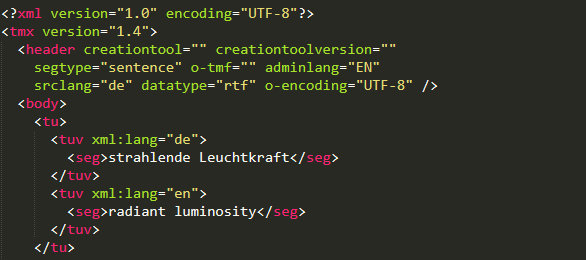
Exemplary usage of a parallel corpus - Use of a monolingual corpus: A monolingual corpus refers to a plain text in the target language and the desired linguistic style which helps improve the style of the translations, so that they sound more natural and fluent.
For my particular application, the monolingual corpus seemed to be the most fitting way to add to the quality of the translations. This is due to the reason that the texts mostly use prosaic and poetic language which is quite different to what the pre-trained domains are targeting. The use of dictionaries in this case is of little avail as the words themselves do not require a translation different to the one provided. This would be mainly useful for proper names which do not need to be translated, and other similar cases.
Lessons learnt
Shortly after beginning this project, it became clear to me that working with the IBM Watson Language Translator was rather challenging. Several issues arose which I could only partly solve in the course of the project.
The issue I found most disadvantageous to my progress was the fact that the option to use a monolingual corpus for the customisation of a translator module had been disabled for the latest version of the Watson Language Translator. This left me with using either a dictionary or the pre-trained models which did not perform poorly per se, but which also did not help to improve the translations’ linguistic style.
Due to the sparse documentation of and the lack of sample projects using the Watson Language Translator, I found it difficult to identify the reasons for errors in my code and had to improvise more than once. This made the customisation of the model unnecessarily cumbersome and made me rethink the choice to use this particular service in the first place.
In retrospect, I would have liked to try out other cloud services with translator functionality, such as the Google Cloud Translation API, which appears to offer a number of sophisticated and established language services.
The other main difficulty I had while trying to customise the model was the realisation that training a good model requires a very large amount of useful data which has to be specific to the domain in question. Acquiring this much data, as well as transforming it into the correct shape for processing, is definitely not an insignificant aspect of any Machine Learning based application. Unfortunately, achieving useful results within the scope of this project was not possible; however, the change to a different translator service and access to a larger text corpus might provide a solution in the future.
Leave a Reply
You must be logged in to post a comment.