
Hypes help to overlook the fact that tech is often reinventing the wheel, forcing developers to update applications and architecture accordingly in painful migrations.
Besides Kubernetes one of those current hypes is Serverless computing. While everyone agrees that Serverless offers some advantages it also introduces many problems. The current trend also shows certain parallels to CGI, PHP and co.
In most cases, however, investigations are limited to the problem of cold boot time. This article will, therefore, explore Serverless functions and their behavior, especially when scaling them out and will provide information on the effects this behavior has on other components of the architecture stack. For example, it is shown how the scaling-out behavior can very quickly kill the database.
Introduction
In order to really understand Serverless, it must be analyzed where it came from. The technology was made possible by the long-lasting transition to cloud computing. However, with the emergence of Serverless, cloud computing itself must be considered degraded to a very early stage. Because Serverless reveals one thing, developments so far were many things but not cloud-native. In fact, developers have tried to design environments they were already familiar with – or more explicitly, they have recreated the local environments in the cloud [1, p. 3].
This may be the transition phase to a cloud-native world, allowing software, design and know-how to be migrated step by step. During this phase virtualization of the physical environment can be observed, the abstraction level, on the other hand, remains the same or changes only slightly. This explains the current success of platforms such as the Google Compute Engine or Amazon EC2, where developers still deal with virtual network devices, operating systems and virtualized physical machines.
But even since the advent of the cloud, there have been some services with different levels of abstraction. For example, the Google App Engine released in 2008. Which requires services to be divided into a stateless compute tier and a stateful storage tier [2, p. 2] – which in turn comes very close to the concept of Serverless.
The most significant distinction is made in terms of elasticity, whereas in Infrastructure-as-a-Service (IaaS) the resource elasticity has to be managed at the virtual machine-level in Function-as-a-Service (FaaS) it’s administered by the cloud provider [3, p. 159].
Characteristic and Definition
Serverless computing means that it is an event driven programing where the compute resource needed to run the code is managed as a scalable resource by cloud service provider instead of us managing the same. It refers to platforms that allow an organization to run a specific piece of code on-demand. It‘s called Serverless because the organization does not have to maintain a physical or virtual server to execute the code. […] pay for the usage and no overhead of maintain and manage the server and hence no overhead cost on idle and downtime of servers.
Jambunathan et al. [4]
From this, it can be concluded that if there is no use, no resources are provisioned and therefore no costs arise. In order to have the possibility to remove resources during a non-usage period, it is absolutely necessary that the resources can be made available again quickly enough. From the developer’s point of view, the deployable artifact contains only the code and its direct dependencies, i.e. no operating system and no docker image. Payment is peruse and started instances are ephemeral.
It is absolutely necessary to draw a distinction from PaaS. Services such as Heroku, Google App Engine and AWS Beanstalk have existed for a long time and offer a similar level of abstraction. Roberts argues that PaaS offerings are generally not designed to scale freely depending on occurring events. So for Heroku, operations would still manage individual machines (so-called dynos) and define scaling parameters on a machine-based level [5].
The invoicing also takes place on the machine level and not on the actual usage. In other words, instances are held up and resources will not be raised in parallel with the current demand. Serverless and FaaS allow to react with very short-lived instances absolutely fine-granular and parallel to rising/declining demand whereas PaaS scaling more leads to a – if set in a graph – staircase shaped increase in costs/resources.
Facilitators
As a result of digitization, companies are increasingly using digital systems to handle their business processes. They expect fail-safe, resilient systems at all times and thus increase the pressure on further development. This section is dedicated to the question of what improvements have enabled Serverless in its current form, with special attention paid to the developments that occurred after 2008 – the year the Google App Engine was released.
While there was only moderate progress with CPU and memory, strong progress could be detected in the storage segment. Especially due to the further spread of SSDs. The Situation was similar with the network. Particularly within the data centers and between their replication zones, the connection has improved rapidly [6].
In many cases, the improved network allows separating storage and computing tier from each other. While this introduces more distance, therefore latency and reliance on the network, this also leads to the opportunity of scaling computing and storage tiers independently from each other.
Without this development, Serverless, which is designed as a stateless-tier, would not be possible at all. While distributed systems in interaction with relational databases had problems with regard to replication, performance and thus throughput, NoSQL systems arose. These could easily be replicated and as a result provided the required data throughput – if necessary worldwide.
The next two important milestones were Docker and the Dev-Ops movement among other things leading to faster delivery. No less important was the trend towards microservices. This is also where the first cloud-native specific characteristic occurs, from now on it is easier to scale horizontally than vertically. The foundation for Serverless was then established with Infrastructure-as-Code and low-latency provisioning [6].
Behavior of Serverless Environments
Szenarios
This chapter will be preceded by a scenario. The application of a company has fully adopted Serverless. The stateless client in form of a Single-Page-Application (SPA) communicates with a REST API consisting of functions deployed on AWS Lambda. For any endpoint, there is a dedicated function, in order to reduce the size of the artifacts and therefore the cold-boot time [7]. As a result, the application consists of 250 independent stateless functions – so-called nano-services. In order to further reduce the boot times, one of the more powerful machines was selected as runtime – since it has been proved that higher memory and CPU allocation also result in shorter boot times [7]. A PostgreSQL instance running on AWS RDS serves as the database.
During the scenario, the application experiences a sudden increase in load. In the previous period, there was only a low load. Depending on how the provider scales the functions, many effects can occur that in the worst case completely paralyze the system.
Booting & execution states
Lloyd et al. have further investigated the various execution states. These also provide insight into how the execution context is structured – especially with regard to isolation [3, p. 163].
Provider-cold – occurs if the function’s code was altered. This requires the cloud operator to actually rebuild the enveloping artifact.
VM-cold – can be seen if there is no active instance of a runtime that has the artifact present. So the boot time is extended by the required transfer time for the artifact. This can occur not only after a provider cold event but also in the process of horizontal scaling whereby a new VM might serve as runtime.
Container-cold – the artifact has already been transferred to the executing machine, is cached there, and therefore the boot time is limited to the actual boot time of the artifact.
Warm – the artifact is provisioned and has the capacity to accept more incoming traffic.
In addition to the start time, the function’s life-span is also relevant. Here it becomes clear that instances with more system resources are dismantled more quickly [3, p. 166].
Concurrency
As research to this article two functions were deployed on AWS Lambda. The aim of the investigation is to see how functions scale on a sudden increase in load. The first function will serve as analyze target. It reads the property btime from /proc/stat and returns it to an incoming HTTP request. The procedure is similar to that of Loyd et al. In addition, one UUID is created for each started instance and returned along the btime value.
The second function contains a simple logic that triggers N concurrent requests to the first function and returns the result as a list once all requests returned a result.
The collected data then provides information about how many instances of a function are started in parallel – via UUID – and whether they run on different host systems – the boot time expressed via btime is used for this. The assumption is made that no machine starts at exactly the same time. In terms of configuration, the timeout was set to 15 seconds, the memory limit to 128MB and the source code was written in JavaScript.
In order to ensure that the exact effects could be precisely controlled, a static value within the code was incremented before the test. This leads to a completely new artifact being built: the already covered provider-cold start. In the test run, 150 requests were sent to the function at an interval of 5 seconds. The resulting numbers can be taken from Fig. 1.
Especially remarkable is the number of instances during the first interval. Since no function has yet reached the warm state and the runtime environment cannot make any assumptions about whether a single instance can handle the traffic, AWS did the only correct thing: Provide a separate instance for each request.
This, of course, reveals another problem: For each request of the first interval either a Provider-cold, VM-cold or Container-cold start is adding latency to the response time.
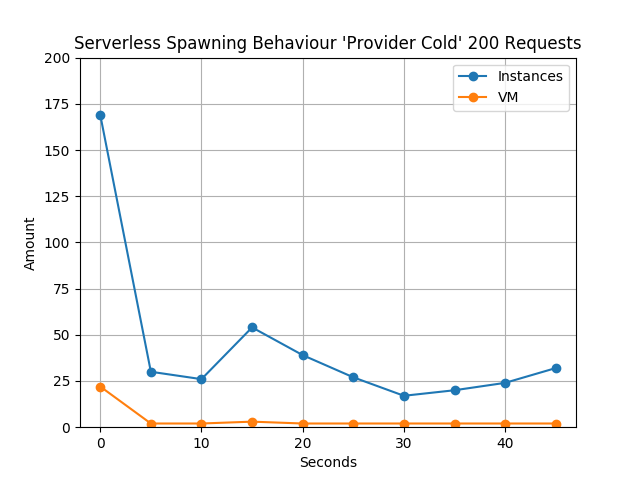
There is a small difference between the absolute number of 200 requests and the 169 instances provided. This can be explained by the fact that even if all requests are started at the same time, they are not necessarily executed immediately. Therefore, instances are already reused for the last 31 requests of the first interval. All instances are distributed among 22 VMs. It is noteworthy that in the second interval AWS has already drastically reduced the number of addressed instances and VMs.
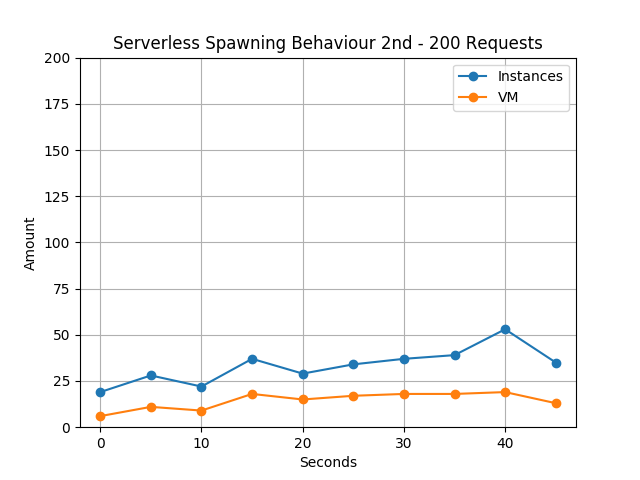
The execution was repeated in a 2nd batch five minutes after completion of the first test. Following the findings of Lloyd et al., sufficient warm instances should still be available after this period. Fig. 2 points out that AWS now scales the functions much more cautiously and, as expected, starts with fewer instances and then expands them. This corresponds to a build-up scenario to be able to scale quickly. This is also supported by the fact that the number of machines tends to increase to up to 19 – quite contrary to the behavior in Fig. 1, where after the first interval only two VM instances were used. If further scale out would be required, the previously scaling to more machines enables AWS to accomplish more Container- instead of VM-cold starts and thus reduce boot time.
In order to better control the concurrency and resulting problems, it is possible to limit the out-scaling per function in the AWS management console. The default value of 1,000 is quite high. The mandatory fixed value also reveals the danger of a too restrictive configuration which endangers availability and performance.
Stateful Stateless Services
APIs, microservices and Serverless functions are rarely really stateless. As an example, you can list the connection pool to a database or any state that is stored in memory and remains there after a task such as processing a request has been completed.
Especially the concept of connection pooling is interesting to save latency. If connections to the database are kept open, future communication can take place without establishing a new connection [8]. This is especially relevant when it comes to APIs and the database because often several single queries are necessary in order to fulfill a request.
What actually is changing through Serverless is the lifespan of this volatile state. As well as the number of dedicated functions forming some sort of API. An example given, when previously two instances of one API server would stay online for n-days and have the resulting state. In a Serverless environment, there are multiple instances of multiple functions for the same job. The state is therefore divided into smaller, more volatile increments.
To come back to the example of the connection pool, here is a problem: Not all components scale with the same elasticity as Serverless. Connections to the database are usually limited [9], the provision of databases is usually mapped to machine instances, billed and scaled accordingly. The effect of the previously called nano-services – more smaller functions with more instances, resulting in more short timed microstates, intensifies this problem.
If one relates this to the results of Chapter Concurrency, it quickly becomes clear that this scaling behavior may introduce issues for parts of the application that are not Serverless and therefore not scale freely. Quickly leading to situations like having to many connections too the database.
Impacts on the Ecosystem
This leads to the obvious conclusion that in order to really benefit from the advantages of Serverless, all components of a system should exhibit similar elasticity and scale accordingly. If only the elasticity of the computing tier is improved, this can lead to minor cost savings, but not take full advantage of Serverless. While the data tier does not necessarily have to be implemented in a Serverless manner, it must be able to scale proportionally with the upstream tiers.
The influence of Serverless is great in the sense that existing systems are not designed for this type of elasticity. Only a few databases provide support for spawning additional instances – during ongoing operation. Especially hard for relational databases that include a lot of the required data inside the memory storage.
But there are already first developments, e. g. FaunaDB with support to run as Serverless database [10]. With Aurora, AWS already has a product on offer that offers sufficient elasticity [11]. This is rather surprising as Aurora API is compatible with PostgreSQL and MySQL, therefore it is no wonder that there are a lot of different restrictions to work with [12].
If with the data tier, another critical component in the architecture of an application is used as FaaS, latency problems can potentiate especially during the fan-out scenarios.
This indicates that it is nowhere near the only way. Other concepts, on the other hand, require even greater rethinking. If gone one step further, the data access in Serverless functions could be removed – waiting times should always be avoided in Serverless anyway. Instead all required data could be part of the event that leads to the invocation of the function. Apache Kafka or AWS SNS offer a wonderful template fur such application flows. The small size of the artifact plays an additional role here, instead of having to transport the data to the function, the artifact can be carried to the data (e. g. run on top of S3) – or to the user (edge computing).
In addition to databases, there are already a number of Serverless services – especially in the portfolio of cloud providers. Examples include S3 storage – where the developer does not manage physical or virtual machines – and other services with similar abstraction, such as Amazon’s Simple Queue Service. These, however, illustrate a tactic of the cloud providers: Own – proprietary – offerings are usually very easy to use because they correspond to a Serverless architecture, thereby disrupting existing open source solutions. While on AWS queues can also be realized with Redis, developers have to define the cluster size on the base of physical machines. If the elasticity required for Serverless cannot be set at all, over provisioning must be used.
Conclusion
The biggest danger of Serverless is the resulting lock-in effect. Since not only the FaaS offer itself is used but possibly proprietary components with high elasticity. A real lock-in relationship occurs not just through the mere use of a single service, but when these are used in complex interaction to fulfill the business case. Here free software lags a bit behind and cloud providers understandably promote their own solutions. For example, developers can directly connect to AWS DynamoDB when creating a lambda – another service that already scales in the required elasticity [13].
Serverless also raises a number of new questions. In the by now widespread microservice architecture it has become very obvious, who owns which data and to which advantages or disadvantages this leads. For nano-services, these rules do not necessarily apply. Especially the question who owns the data will surely keep programmers busy for a long time. The latencies are also – at least still – worrying. But since this problem gets the most attention, one can assume that there will be continuous improvements.
Nevertheless, Serverless must be granted tremendous potential. It allows developers to focus on code again – at least after the architectural issues have been resolved. Complexity cannot be resolved, but Serverless shifts some parts to the responsibility of the Cloud providers.
It remains to be seen whether the little problems can be ironed out in the next few years with optimization. Especially for the scaling behavior, many parameters have to be considered, this could be a wonderful application for prediction, possibly with machine learning.
At the present time, however, no recommendation can be made to fully rely on Serverless. The lock-in effects are too risky, the necessary changes to existing code do not justify the slight cost savings in operation. Most of the costs are likely to occur during development and not during operation, a problem that Serverless does not deal with at all.
Nevertheless, the use of serverless today already makes sense. Especially for tasks that can be accomplished without further delays. And in indeed, when executing parallelizable tasks like applying machine learning models or when editing images, excessive Serverless is already set here [14].
References
[1] E. Jonas, J. Schleier-Smith, V. Sreekanti, C.-C. Tsai, A. Khandelwal, Q. Pu, V. Shankar, J. Menezes Carreira, K. Krauth, N. Yadwadkar, J. Gonzalez, R. A. Popa, I. Stoica, and D. A. Patterson, “Cloud programming simplified: A berkeley view on serverless computing,” EECS Department, University of California, Berkeley, UCB/EECS-2019-3, Feb. 2019.
[2] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D. A. Patterson, A. Rabkin, I. Stoica, and M. Zaharia, “Above the clouds: A berkeley view of cloud computing,” EECS Department, University of California, Berkeley, UCB/EECS-2009-28, Feb. 2009.
[3] W. Lloyd, S. Ramesh, S. Chinthalapati, L. Ly, and S. Pallickara, “Serverless computing: An investigation of factors influencing microservice performance,” vol. 0, pp. 159–169, Apr. 2018.
[4] B. Jambunathan and K. Yoganathan, “Architecture decision on using microservices or serverless functions with containers,” 2018.
[5] M. Roberts, “Serverless architectures.” https://martinfowler.com/articles/serverless.html, 2018.
[6] A. Cockcroft, “Evolution of business logic from monoliths through microservices, to functions.” https://read.acloud.guru/evolution-of-business-logic-from-monoliths-through-microservices-to-functions-ff464b95a44d, Feb-2017.
[7] M. Shilkov, “Serverless: Cold start war.” https://mikhail.io/2018/08/serverless-cold-start-war/, 2018.
[8] “SQL server connection pooling (ado.net).” https://docs.microsoft.com/en-us/dotnet/framework/data/adonet/sql-server-connection-pooling, 2017.
[9] V. Tkachenko, “MySQL challenge: 100k connection.” https://www.percona.com/blog/2019/02/25/mysql-challenge-100k-connections/, 2019.
[10] C. Anderson, “Escape the cloud database trap with serverless.” https://fauna.com/blog/escape-the-cloud-database-trap-with-serverless, 2017.
[11] A. AWS, “Amazon aurora serverless.” https://aws.amazon.com/de/rds/aurora/serverless/.
[12] J. Daly, “Aurora serverless: The good, the bad and the scalable – jeremy daly.” https://www.jeremydaly.com/aurora-serverless-the-good-the-bad-and-the-scalable/, 2018.
[13] N. V. Hoof, “Create a serverless application with aws lambda and dynamodb.” https://ordina-jworks.github.io/cloud/2018/10/01/How-to-build-a-Serverless-Application-with-AWS-Lambda-and-DynamoDB.html#dynamodb, 2018.
[14] G. Inc., “Building a serverless machine learning model.” https://cloud.google.com/solutions/building-a-serverless-ml-model.
Leave a Reply
You must be logged in to post a comment.