If there is one statement that can be made about the current developments in the realm of distributed systems, it would probably be how most developers are turning away from a centralised, monolithic architecture and move towards a microservice architecture. This type of architecture proved itself as much more flexible and robust for the modern world where more and more software is offered as a cloud-based solution. By splitting up systems into smaller parts, they can be updated more easily and crashed services can be recovered faster. These services can be containerized with Docker, so quickly putting up and pulling down parts of the infrastructure became very easy. On most occasions it is simply less work to trash a running software instance and recreate it, than logging into the instance and trying to fix what is broken.
But how does software communicate in a system based on a microservice architecture? Here stream processors come into play. They form data pipelines between the individual services, can aggregate data from different sources and to a certain extent also store data. Apache Kafka, which was initially developed by LinkedIn, quickly became a major player in this sector after it became part of the Apache Software Foundation in 2012. At its core it works like a message queue, but the decentralized nature, as well as options for fault tolerance and redundancy, gave it an edge over other similar solutions. At the end of this blog post, Apache Kafka shall also be compared to RabbitMQ.
System Overview
Kafka calls the messages, which it stores and distributes, records. A record contains a key, a value and a timestamp. Records can be assigned to a specific topic which in turn contain several partitions. These are the individual message logs, where the records are appended to. To identify a specific record inside a partition, a sequential id is assigned to each record, which is called offset.
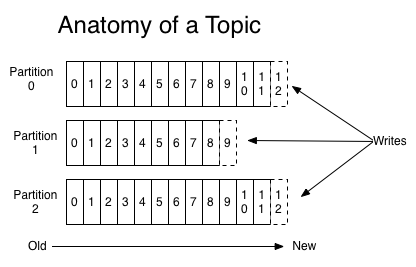
Producers are the data sources. They have to decide to which topic and which partition they want to write their records to. Their counterpart are the consumers. Each consumer declares a consumer group name. When a record gets added to a topic, it gets published to one consumer inside each consumer group. To have all consumers receive all records, they all need to declare a different consumer group. It is important to note that the order of records can only be guaranteed for a partition, but not over multiple partitions.
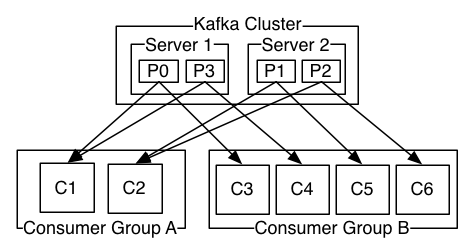
A Kafka Cluster can contain multiple servers which can also be divided over multiple datacenters. The individual partitions are split between these servers. To ensure fault tolerance, partitions can be replicated to a configurable number of other servers. One server remains the leader, which handles all incoming and outgoing requests. The other servers, where the partition is replicated to, are followers which only copy the changes of the leader. The leader role automatically transitions to another server, should the previous leader fail [1].
Use Cases
The maintainers of Apache Kafka list many potential use cases on their website. The main use case certainly is messaging. Like other message brokers, Kafka can help to buffer messages and separate data producers from the message processing side. The website mentions that Kafka has better throughput, built-in partitioning, replication and fault tolerance compared to most messaging systems. This makes it more reliable for large scale systems, which have to be split across multiple servers or datacenters.
Another major use case is log aggregation. Traditionally, log files which are produced by some service are collected through an automated system and copied to one central place, where they then get processed. By piping the log output directly into Kafka, the correct order of the log records is already guaranteed and adding or removing data sources is easy to handle. Compared to systems which are focused on log aggregation like Scribe or Flume, Kafka claims significantly reduced latency while maintaining high reliability [2].
Case Studies
Many big tech companies use Kafka for lots of different applications. For Netflix, it is a major part of their data pipeline. While being a video streaming company first and foremost, big data and data analysis is a large part of their success. Video viewing activities and UI activities, but also error logs and performance events are part of the event streams which flow through their pipeline [3].
We currently operate 36 Kafka clusters consisting of 4,000+ broker instances for both Fronting Kafka and Consumer Kafka. More than 700 billion messages are ingested on an average day.
Netflix Technology Blog [4]
With this, they can maintain a very high reliability. The daily data loss rate is less than 0.01% because removing all data loss from the system would be too costly. One reason for the data loss are outlier brokers. These servers might have slow response times or frequent TCP timeouts, which could be caused by an uneven workload or hardware problems. When a producer tries to send records to a broker without getting a confirmation, its local buffer could fill up at which point messages are dropped. Replication, which is built into Kafka, can mitigate this issue to a certain extent, but also leads to other problems like replication lag, where replication is slowed down by outliers. Their solution was to deploy multiple clusters, which can take over when the primary cluster seems to be struggling to keep up. For this, a reliable monitoring infrastructure must be also implemented [4].
Another case study comes from Pinterest. They used Kafka to reduce overdelivery of ads. Overdelivery means that advertisers run out of money, while their ads are still shown to site visitors. This can happen when the server that tracks the budget of an advertiser, reacts too slowly. Therefore, they wanted to track the so called inflight spend of each advertiser. This value measures the cost of ad insertions which have not yet been charged to the account of the advertiser. For this, they needed an event stream which was able to handle tens of thousands of events per second. They choose Kafka because it has a millisecond delay and since it is very lightweight [5].
Benchmarks
Jay Kreps of LinkedIn tested the performance of Kafka and published it in a blog post [6]. Since Kafka only stores a continuous data stream without having to return to previously written records, it can perform very fast and independent of the size of the already stored data. All data is written to the disk, so it persists, should the server crash. Kreps tested the read and write speeds and also took replication across multiple servers into account. For that, he set up the Kafka cluster on three servers.
Without replication, he was able to publish 821,557 records per second to Kafka using one producer thread. The records had a size of 100 byte. Achieving a higher throughput of MB/sec is easier when the records are of a larger size, therefore he chose a rather small size to put proper load on the system. By adding three replicas for each partition, the performance dropped slightly to 786,980 records per second. Since the replicas are just consumers to Kafka, the consumer API also has to be very efficient to allow this kind of load. This replication was asynchronous, meaning the Kafka cluster confirms the write operation immediately to the producer, without waiting for confirmation from the replicas. Using synchronous replication, the performance dropped significantly to 421,823 records per second. By adding more producers, he was able to send 2,024,032 records per second to the cluster.

Kreps also tested the claim that Kafka performs equally well regardless of the size of the already existing data. If a message broker would primarily store records in memory, the performance would decrease drastically once the memory is filled up and records had to be written to disk. Figure 3 shows that this is not the case for Kafka, since all records are immediately written to disk anyway. Besides some fluctuations, which are present during the entire run of the test, the general performance stays the same even after writing 1.4 TB. Another critical aspect for a message broker is the latency between publishing a message to the Kafka cluster and a consumer receiving it. The median value Kreps measured for this task was 2 ms.
Data Storage
The maintainers of Kafka mention how it also works to store data. Records do not get removed when they are read by consumers and stay on the disk until they get deleted after a configurable retention period. Therefore, logs or other data which gets created sequentially, could just stay in the Kafka cluster until it gets analysed or deleted when it is no longer relevant. But this might not always be the best course of action.
While performance and replication are the core advantages of Kafka, this can cause data consumption to become very expensive. Eran Levy mentions in his blog post that a data lake like Amazon S3 can be significantly cheaper than storing data within a Kafka cluster [7]. Apart from the higher cost for disk space, consumers also have to read entire records to access a single field inside. Depending on the use case, storing data in columnar storage can be more appropriate. If there are still services which rely on immediate notification when records get added to a topic, a real-time consumer obviously still has to exist.
Comparison to RabbitMQ
Another famous message broker is RabbitMQ, which implements the AMQP messaging protocol. While also being a publish/subscribe service, some fundamental changes make it different to Kafka. One major difference is that RabbitMQ will store messages in memory and only write them to the disk once the memory is filled up. At this point, the performance will drop dramatically. RabbitMQ also supports more complex ways to route data through the channels, while Kafka uses a simpler approach. Records can only be added to topics and the producer of the record has to specify the topic. Availability is mostly comparable since RabbitMQ also supports replication. RabbitMQ is programmed in Erlang, while Kafka is Java based and runs in a JVM. This can cause a higher error rate because of unsophisticated locking mechanisms and the garbage collection process [8].
The main difference lies in the philosophy of who is responsible to make sure that messages reach their intended target. Kafka puts this responsibility upon the message producers and consumers. They have to make sure that messages are published to the correct topic. The cluster remains simple and stupid. RabbitMQ is based upon a different design. The message broker contains the logic which routes all messages to the correct endpoint [9]. This in turn makes the producers and consumers simpler to manage. Because of this fundamental difference, it is impossible to say which one is better since this depends entirely on the use case.
Conclusion
Apache Kafka is a comparatively simple message broker, which handles high throughput very well. This is probably one of the reasons why it is so famous in its realm. Especially for applications which do not require a complex message routing logic, it can be the way to go. Writing all messages to disk immediately is another fundamental principle. This can prevent data loss, should the server suddenly die. Because records are linearly appended, the Kafka cluster can reach very high speeds for publishing messages. However, if the routing logic becomes to complex or one wants to further decouple the message handling logic from the producers and consumers, RabbitMQ might be the more fitting solution.
References
[1] Apache Software Foundation, “Apache Kafka Introduction,” https://kafka.apache.org/intro [Accessed 06 March 2019].
[2] Apache Software Foundation, “Apache Kafka Use Cases,” https://kafka.apache.org/uses [Accessed 06 March 2019].
[3] Netflix Technology Blog, “Evolution of the Netflix Data Pipeline,” 15 February 2016. https://medium.com/netflix-techblog/evolution-of-the-netflix-data-pipeline-da246ca36905 [Accessed 06 March 2019].
[4] Netflix Technology Blog, “Kafka Inside Keystone Pipeline,” 26 April 2016. https://medium.com/netflix-techblog/kafka-inside-keystone-pipeline-dd5aeabaf6bb [Accessed 06 March 2019].
[5] Pinterest Engineering, “Using Kafka Streams API for predictive budgeting,” 06 October 2017. https://medium.com/@Pinterest_Engineering/using-kafka-streams-api-for-predictive-budgeting-9f58d206c996 [Accessed 06 March 2019].
[6] J. Kreps, “Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines),” LinkedIn, 27 April 2014. https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines [Accessed 06 March 2019].
[7] E. Levy, “Apache Kafka with and without a Data Lake,” Upsolver, 13 September 2018. https://www.upsolver.com/blog/blog-apache-kafka-and-data-lake [Accessed 07 March 2019].
[8] P. Sinha, “A comparison between RabbitMQ and Apache Kafka,” MavenHive, 04 June 2018. https://blog.mavenhive.in/which-one-to-use-and-when-rabbitmq-vs-apache-kafka-7d5423301b58 [Accessed 07 March 2019].
[9] P. Humphrey, “Understanding When to use RabbitMQ or Apache Kafka,” Pivotal, 26 April 2017. https://content.pivotal.io/blog/understanding-when-to-use-rabbitmq-or-apache-kafka [Accessed 07 March 2019].
Leave a Reply
You must be logged in to post a comment.