In these times, applications require increasing robustness and scalability, since otherwise they will collapse under the burden of the vast number of users. Cluster managers like kubernetes, Nomad or Apache Marathon are a central factor of this resilience and scalability. A closer look at the insides of cluster managers reveals consensus protocols to be the crucial point. This blog post gives an overview of the most common consensus protocols and their workflows. Furthermore, the concept of a consensus protocol is questioned and potential improvements of the consensus protocols in cluster management are discussed.
Table of contents
- Motivation
- Consensus protocols
- Cluster manager
- Cluster management without a consensus protocol
- Discussion
List of figures
- Container Management Platforms Perferences
- Distributed System
- Concurrency
- State transition
- Consensus algorithm
- FLP impossibility
- Two-phase commit, fault-free execution, phase one
- Two-phase commit, fault-free execution, phase two
- Two-phase commit, with coordinator failure, phase one
- Two-phase commit, with coordinator failure, phase two
- Procedure ZooKeeper
- Performance test
Motivation
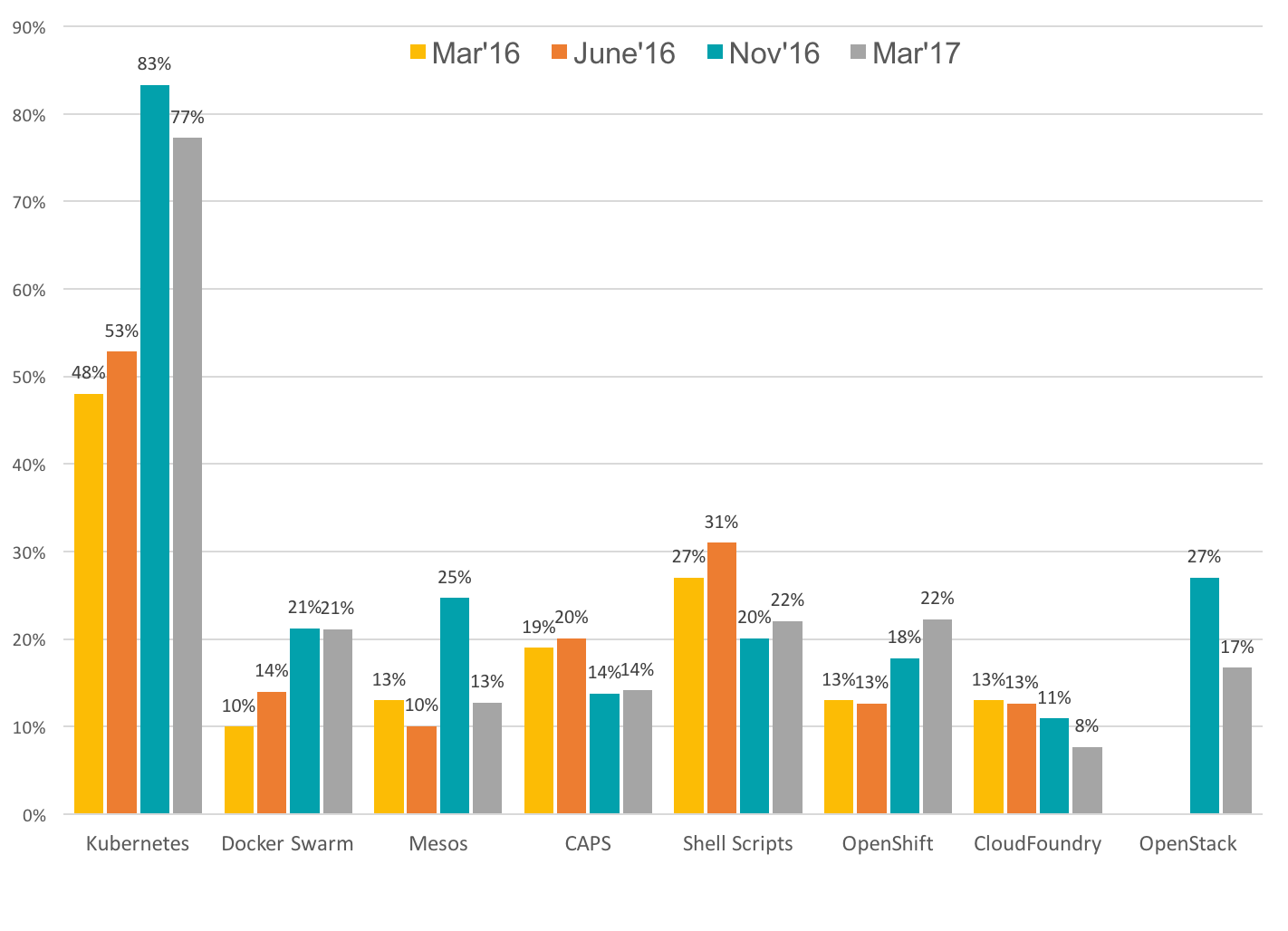
Container management platforms are the preferred choice when it comes to orchestrating containers with high availability, reliability and scalability. The diagram in Figure 1 shows the distribution of container management platforms from 2016 to 2017.
 |
|---|
In comparison to the other platforms, a clear trend towards kubernetes is evident. In order to understand why such a trend exists, it is necessary to look behind the scenes. Are there differences or similarities between these platforms in terms of consensus protocols? Is this a critical factor for the emergence of this trend? In order to clarify, a number of essential terms need to be addressed.
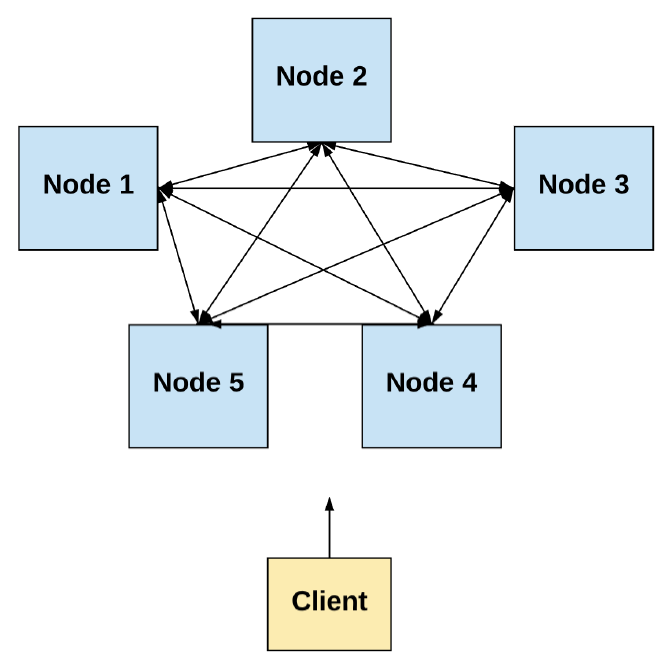
Distributed system
A distributed system includes a set of distinct processs sending messages to each other and coordinating to achieve a common objective.
Even a single computer can be viewed as a distributed system.
Memory units, input-output channels and the central control unit also represent separate proceses collaborating to complete an objective.
In this blog post the focus is on distributed systems where the processes are spatially distributed across computers [4].
 |
|---|
Properties of a distributed system
The following features are particularly important in relation to a distributed system.
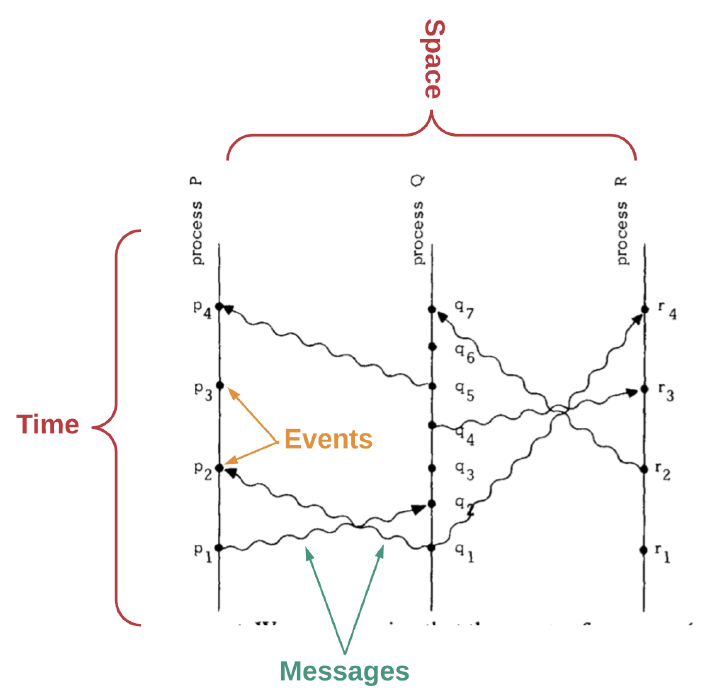
1. Concurrency
Nodes or Processes running simultaneously require coordination. As illustrated in Figure 3, this concurrency results in different events at certain points in time.
 |
|---|
2. Lack of global clock
The order of the events must be determined. However, there is no global clock that can be used to determine the order of events on the computer network.
The following two factors can be considered to determine whether an event happened before another.
- Messages are sent before they are received
- Every computer has a sequence of events
This results in a partial sequence of events of the system. In order to obtain a total sequence of the system's events, an algorithm is required which requires the communication of the computers in this system.
If an algorithm relies only on the order of events, abnormal behavior may occur.
Such abnormal behavior can be avoided by synchronizing physical clocks.
The coordination of independent clocks is rather complex and still clock drifts can occur.
The time and sequence of events are fundamental obstacles in a distributed system with spatially distributed processes [4].
3. Independent failure of components
A key aspect is the insight that components can be faulty in a distributed system.
It is impossible to have an error-free distributed system due to the large number of potential failures.
Faults can be divided into the following three groups.
- Crash-fail: The component stops immediately without warning.
- Omission: The component sends a message which does not arrive.
- Byzantine: The component behaves arbitrarily, it sometimes exhibits regular behavior but also malicious Byzantine behavior. This variant is irrelevant in controlled environments like data centers.
Based on this assumption, protocols should be designed to allow a system to have faulty components, yet achieve a common objective and provide a meaningful service.
Since every system has failures, a major consideration is the ability of the system to survive if its components deviate from normal behavior regardless of whether they are malicious or not.
Basically, a distinction is made between simple fault-tolerance and Byzantine fault-tolerance.
- Simple fault-tolerance: In systems with simple fault-tolerance, one assumes that components either exactly follow the protocol or fail completely. Arbitrary or malicious behavior is not considered.
- Byzantine fault-tolerance: In uncontrolled environments, a system with simple fault-tolerance is not particularly useful. In a decentralized system, where components are controlled by independent actors communicating on the public, unapproved Internet, malicious components must also be expected.
The BAR fault-tolerance extends the Byzantine fault-tolerance and defines the following three classes.
- Byzantine: Components that are malicious
- Altruistic: Components that always follow the protocol
- Rational: Components that only follow the protocol when it is convenient [4].
4. Message transmission
Messages are sent either synchronously or asynchronously.
- Synchronous: In a synchronous system, messages are assumed to be delivered within a fixed time window. Conceptually, synchronous messaging is less complex because it guarantees a response.
However, this variant is often impracticable in a genuine distributed system, with computers crashing, messages being delayed, or not arriving. - Asynchronous: In an asynchronous system, it is assumed that the network delays, duplicates, or sends out-of-order messages for an infinite amount of time.
Replicated State Machine
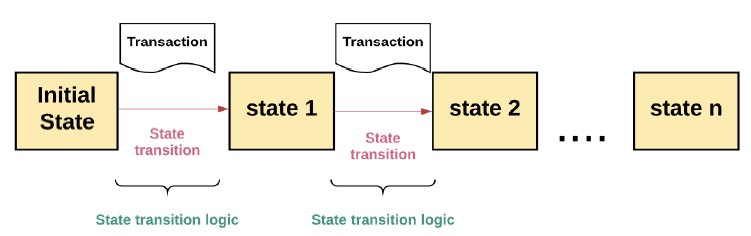
A replicated state machine is a deterministic state machine distributed across many computers, though acting as a single state machine. The state machine works even if an arbitrary computer fails.
A valid transaction in a replicated state machine results in a transition to another state.
A transaction represents an atomic operation on the database complying with the ACID principle.
 |
|---|
A replicated state machine is a set of distributed computers all starting with the same initial value.
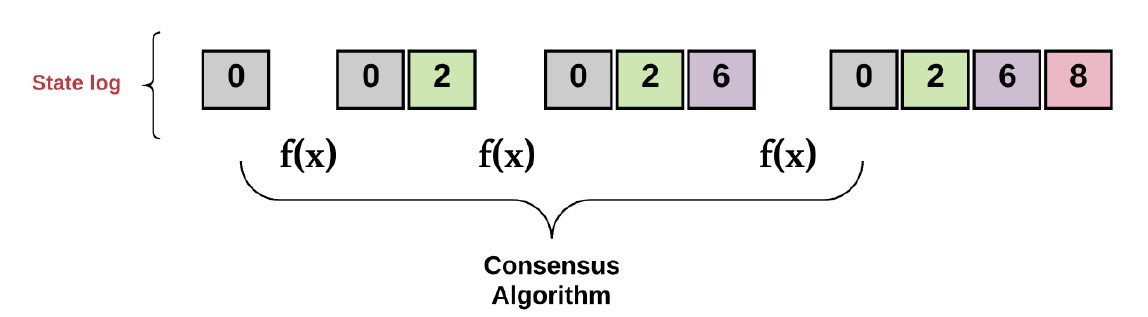
Each of the processes decides on the next value for each state transition, illustrated in Figure 4.
Achieving consensus implies the collective agreement of all computers on an output value based on the current value. A consistent transaction log thus is obtained for each computer in the system.
A replicated state machine must continuously accept new transactions in the log, even when:
- Some computers fail,
- The network fails to send messages reliably,
- No global clock exists to determine the order of events.
This is the fundamental intent of any consensus algorithm as depicted in Figure 5.
 |
|---|
A consensus algorithm achieves consensus when the following three conditions are satisfied:
- Agreement (or safety): All non-faulty nodes decide on the same output value.
- Validity: The value to be decided on must have been proposed by a node in the network.
- Termination (or liveness): All non-faulty nodes may decide on an output value.
Typically a consensus algorithm has three types of actors in the system.
- Proposers, often referred to as leaders or coordinators
- Acceptors or followers, are the ones who listen to the requests of the proposers and answer
- Learners, are the ones who learn the output value resulting from the vote
A consensus algorithm generally has the following procedure.
- Elect: In this phase the leader is selected. A leader makes the decisions and proposes the next valid output.
- Vote: All non-faulty components listen to the proposed value of the leader, validate it and propose it as the next valid value.
- Decide: All non-faulty components must come to a consensus on a correct output value, otherwise the procedure is repeated [4].
FLP impossibility
As described above, there are differences between synchronous systems and asynchronous systems. In synchronous environments, messages are delivered within a fixed time frame. In asynchronous environments, there's no guarantee of a message being delivered.
 |
|---|
Reaching consensus in a synchronous environment is possible due to assumptions about the maximum time required to deliver messages. In such a system, different nodes are allowed to alternately propose new transactions, search for a majority vote, and skip each node if they do not offer a proposal within the maximum time period.
In a fully asynchronous system there is no consensus solution that can tolerate one or more crash failures even when only requiring the non triviality property [4]
The FLP impossibility describes the property of being unable to accept a maximum message delivery time in an asynchronous environment. termination becomes much more difficult, if not impossible. This is necessary since termination conditions must be complied with in order to reach a consensus, meaning every node not having a fault must decide on an output value [4].
To circumvent the FLP impossibility there are two options.
- Use synchrony assumptions
- Use non-determinism
Consensus protocols
Consensus protocols can be distinguished into two basic approaches: Synchrony assumption and non-deterministic.
Approach 1: Use Synchrony Assumptions
If messages are sent asynchronously, termination cannot be guaranteed.
How can it be guaranteed that every non-faulty node will choose a value?
Due to asynchronicity, a consensus cannot be reached within a fixed time window.
This leads to the conclusion that consensus cannot always be reached.
One way to prevent this are timeouts. If there is no progress, the system waits until the timeout and restarts the process. Consensus algorithms like Paxos and Raft apply this method [4].
Simple fault-tolerance
The following section describes algorithms of the Simple fault-tolerance category. These differ from the Byzantine fault-tolerance algorithms in terms of either following the protocol or failing. Byzantine nodes may also exhibit malicious behavior.
Two-phase commit
The two-phase commit is the simplest and most commonly utilized consensus algorithm. As the name suggests, the algorithm consists of two different phases.
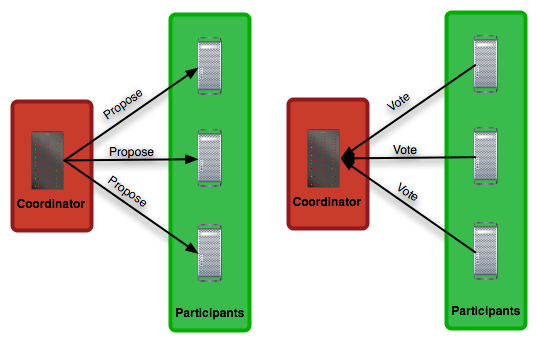
The first phase is the proposal phase. It involves proposing a value for each participant in the system and obtaining the answers as shown in Figure 7.
 |
|---|
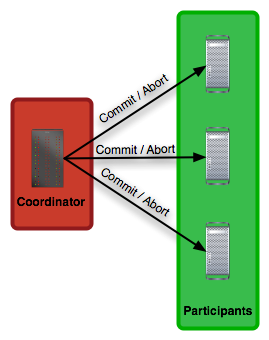
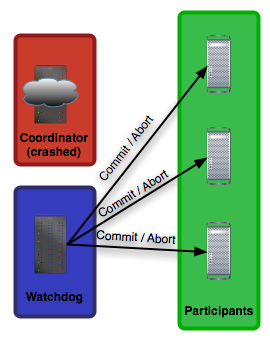
The second phase is the commit or abort phase. In this phase, the result of voting is communicated to all participants in the system. Also, it is transmitted whether to continue and decide or erase the log, as depicted in Figure 8.
The node proposing the values is referred to as the coordinator. The coordinator is not required to be selected by means of a special procedure. Each node may act as a coordinator and thus start a new round of the two-phase commit.
It is important that the nodes do not reach a consensus on what a value should be, but reach a consensus on whether or not to accept it.
 |
|---|
In phase 2 each node decides on the value proposed by the coordinator in phase 1 when and only when communicated by the coordinator. The coordinator sends the same decision to each node, so if a node is instructed to determine a value, they all do. Therefore the condition for agreement is satisfied.
The two-phase commit always aborts, except when each node approves. In all cases, the final value of at least one node was voted on. Thus the condition for validity is complied with.
Finally, termination is guaranteed if each node makes progress and finally returns its vote to the coordinator, who passes it on to each node. There are no loops in the two-phase commit, so there is no possibility to continue forever [5].
Crashes and failure
To understand the failures, it is necessary to consider each state the protocol may take and contemplate what occurs if either the coordinator or one of the participants crashes in this state.
In phase one, before messages are sent, the coordinator could crash, as illustrated in Figure 9. This is not too troublesome as it simply means that Two-phase commit is never started.
If a participant node crashes prior to starting the log, then no harm will result until the proposal message does not reach the crashed node, so this fault can be corrected later.
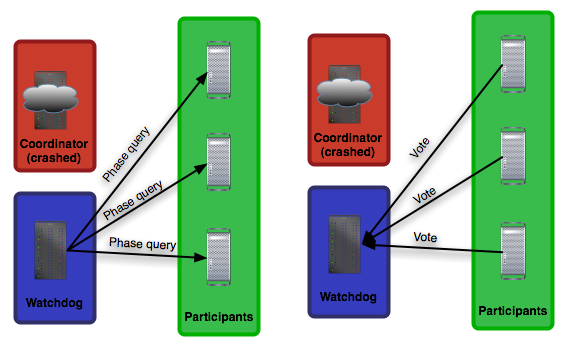 |
|---|
Therefore, the protocol is blocked on the coordinator and cannot make any progress. The problem of waiting for a participant to fulfill his or her part of the protocol cannot be completely resolved.
To counteract this, another participant can take over the coordinator's work once the coordinator is determined to have crashed. If a timeout occurs at a node, it can be forced to complete the protocol the coordinator started.
As in a phase 1 message, this node can contact all other participants and discover their votes. However, this requires persistence in each node.
It is also possible that only one node knows the result of the transaction. If the coordinator fails in phase 2 before all nodes are told to abort/transmit the decision, as shown in Figure 10.
 |
|---|
However, if another node crashes before the recovery node can end the protocol, the protocol cannot be restored to its original state.
The same applies to phase 2. If the coordinator crashes before the commit message has reached all participants, a recovery node is required to take over the protocol and safely complete it.
The worst-case scenario is when the coordinator is a participant himself and grants himself a vote on the result of the protocol. Then, if it crashes, both the coordinator and a participant are shut down, ensuring that the protocol remains blocked as a result of a single fault [5].
Paxos
The Paxos protocol consists of the following phases.
Phase 1: Prepare request
The proposer picks a new number n and sends a prepare request to all acceptors.
If all acceptors have a prepare request (prepare, n), they send a response (ack, n, n', v') or (ack, n, ,). In order for acceptors to respond with a promise, n must be greater than any number ever received before.
Acceptors now propose the value v of the proposal with the highest number they have accepted, if any. Otherwise, they reply with ^.
Phase 2: Accept request
When the proposer receives the responses of the majority of acceptors, it sends an accept request (accept, n, v) with the number n and the value v to the acceptors. The number n is the number from the phase 1 prepare request.
The value v is the highest numbered proposal among the responses.
If an acceptor receives an Accept Request (accept, n, v), it accepts the proposal unless it has already responded to a Prepare Request with a number greater than n. The value v is the highest numbered proposal among the responses.
Phase 3: Learning phase
Whenever an acceptor accepts a proposal, he answers to all Learners with (accept, n, v).
Learners receive (accept, n, v) from a majority of acceptors, decide v and send (decide, v) to all other Learners. Learners receive (decide, v) and the decided value v.
Each Distributed System contains faults. To counteract these, the decision is delayed in Paxos if a proposer fails. A new number is used to start in phase 1, even if previous attempts have not yet been completed.
Paxos is difficult to understand due to its many deliberately open implementation details.
Questions like: When to be certain if a proposer has failed? or Do synchronous clocks have to be used to set the timeouts? are some of these implementation details.
Leader election, failure detection and log management are also purposely kept open to ensure greater flexibility. However, exactly these design decisions are the biggest disadvantages of Paxos [4].
A Leader election mechanism in Paxos might be realized by a simple algorithm like the bully algorithm.
It starts by sending a server id to all nodes. If an id is received, a node sends a response containing the own id.
Next, a node checks if all responses have lower ids than its own. If this is the case the node is a the new leader.
If the id of a node is higher than a the received id, the node starts its own election.
The procedure of performing multiple Paxos decisions consecutively based on a log is called Multi-Paxos.
Raft
Unlike Paxos, Raft is designed with a focus on intelligibility.
For the first time, Raft introduced the concept of shared timeouts to deal with termination. If an error occurs in Raft, a restart is performed. Nodes wait at least one timeout period until they try to declare themselves leader again. This guarantees progress.
The shared status in Raft is typically represented by a replicated log data structure. Like Paxos, Raft requires a majority of servers that are available to operate correctly. In general, Raft consists of the following three elements.
- Leader election: If the current leader fails, a new leader must be elected. The leader is responsible for accepting client requests and managing the replication logs of other servers. Data always flows from Leader to other servers.
- Log replication: The leader synchronizes the logs of all other servers by replicating his own log.
- Safety: If a server commits a log entry with a particular index, other servers cannot set a different log entry for that index.
Raft servers can have the following three states.
- Leader: Typically only one leader exists, all other servers in the cluster are followers. Client requests from the followers are forwarded to the leader.
- Follower: A follower is passive. It only responds to requests from leaders or candidates, or forwards client requests.
- Candidate: A computer in this state wants to be elected as the new leader.
If a candidate wins an election to be leader, this leader remains for an arbitrary period of time, referred to as the term. Each term is identified by a term number, which is incremented after each term. Each server must persistently store the current term number.
Raft uses the remote procedure calls RequestVotes and AppendEntries.
RequestVotes are used by candidates during elections.
AppendEntries are used by leaders for replication log entries and as heartbeat [6].
Leader election
Leaders periodically send heartbeats to the followers. A Leader election is triggered when a follower does not receive a heartbeat from the leader for a certain period of time.
Next, the follower becomes a candidate and increments his term number.
He now sends RequestVotes to all other participants in the cluster, resulting in the following three options.
- The candidate receives the majority of votes and becomes leader.
- If another candidate receives an AppendEntries message, he must check whether the received term number is greater than his own. If the own term number is greater, the server remains in candidate state and the AppendEntries message is rejected. If the own term number is smaller, the server switches back to the follower state.
- Several servers became candidates at the same time and the vote did not give a clear majority decision. In this case a new election starts and one of the candidates times out [6].
Log replication
Client requests can initially be regarded as write-only. Each request consists of a command, which is ideally executed by the replicated state machine of all servers. A leader who receives a new client request adds it to his log in the form of a new entry. Each log entry contains a client-specific command, an index to identify the position in the log, and the term number to maintain a logical order.
To ensure consistency, a new log entry must be replicated in all followers.
The leader sends the AppendEntries message to all servers until all followers have replicated the entry securely. If all followers have replicated the entry, this entry can be considered committed together with all previous entries.
The leader stores the highest index of committed logs. This index is sent to the followers with every AppendEntries message, so they can check if their state machine is still in the correct order.
So if two different logs have the same index and the same term number, they store the same command and all previous log entries are identical.
If a follower does not find a suitable position for the log entry when receiving an AppendEntries message based on the index and the term number, it rejects that message.
By this mechanism the leader is certain that after a successful response of the AppendEntries request the log of a followers is identical to his own log.
In Raft, inconsistencies are resolved by overwriting the follower logs. First, the leader tries to find the last index matching the followers log. If found, the follower deletes all newer entries and adds new ones [6].
Safety
Raft ensures the leader of a term has all committed entries of all previous terms in his log. This is necessary in order for all logs to be consistent and for the state machines to execute the same commands.
During a Leader election, the RequestVote message contains information about the candidate's log. When a voter's log is more up to date than the candidate's log sending the RequestVote message, it does not vote for that candidate.
Choosing which log is more up to date is based on the term number and the length of the log. The higher the term number and the longer the log, the more up-to-date it is [6].
ZooKeeper Atomic Broadcast protocol (ZAB)
Like Raft, the ZooKeeper Atomic Broadcast protocol (ZAB) achieves high availability by distributing data across multiple nodes. This allows clients to read data from any node. Client writes are also forwarded to the leader. An important design criterion is the incremental assignment of each state change to the previous state. This results in an implicit dependency of the order of the states. Besides the guarantee of replication in order, ZAB defines procedures for Leader election and recovery of faulty nodes.
A term in Raft is defined in ZAB as an epoch of a leader. An epoch is also identified by a number generated by the leader.
The epoch number must also be larger than all previous epoch numbers.
A transaction represents a state change the leader propagates to his followers.
Furthermore, analog to the index in Raft, a sequence number is generated by the leader, which starts at the value 0 and increments.
The epoch number and the sequence number are important to ensure the order of the state changes.
Analogous to the replication log in Raft, each follower in ZAB has a history queue. In this queue all incoming transactions are committed in received order.
In order for ZAB to be executed correctly, the following prerequisites must be met.
- Replication guarantees reliable delivery, total and causal order.
- If a transaction is committed by a server, it may be committed to all servers.
- If a transaction A is committed by a server prior to a transaction B, all servers must commit transaction A prior to transaction B. If a transaction A is committed by a server prior to a transaction B, all servers must commit transaction A prior to transaction B.
- If a transaction A is committed by a server and another transaction B is sent, transaction A must be placed before transaction B. If a transaction A is committed by a server and another transaction B is sent, transaction A must be put before transaction B. If transaction B is committed by a server, transaction A must be entered before transaction B. If transaction B is committed by a server and another transaction B is sent, transaction A must be put before transaction B. When a transaction C is then sent, C must be put after B.
- Transactions are replicated as long as the majority of nodes are available.
- If a node fails and restarts, it must catch up on the missed transactions.
The general procedure outlined below is depicted in Figure 11.
When a leader receives a change update from a client, it generates a transaction with a sequence number and the epoch number. Afterwards, it sends this transaction to its followers. A follower adds this transaction to its history queue and confirms this to the leader via ACK. If a leader has received an ACK from the majority of the nodes, it sends a COMMIT for this transaction. A follower who accepts a COMMIT commits this transaction unless the sequence number received is greater than the sequence numbers in its history queue. This causes the follower to wait for COMMITs from previous transactions before committing.
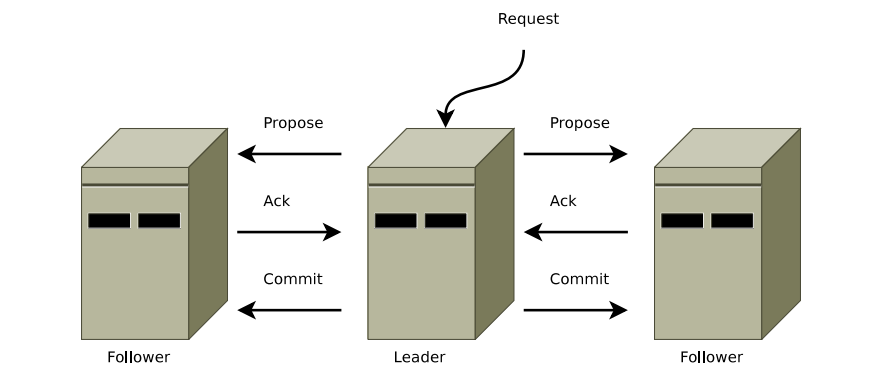 |
|---|
If the leader crashes, the nodes run a recovery protocol. Both to agree a common consistent state before resuming regular operation and to establish a new leader for transferring state changes.
Since nodes can fail and be restored, multiple leaders can emerge over time, allowing the same nodes to perform a node role more than once.
The life cycle of a node is defined in the following four phases. Each node performs an iteration of the protocol. At any time, a node can cancel the current iteration and start a new one by transitioning to phase 0.
phases 1 and 2 are especially important in terms of coordination for a consistent state for recovery after a failure [7].
0. Leader election phase
Nodes are initialized in this phase. No particular Leader election protocol must be used. As long as the leader election protocol is terminated and chooses a node which is available and the majority of the nodes have voted for it most likely. After termination of the Leader election, a node stores its vote to local volatile memory. When a node n voted for node n0, then n0 is called the prospective leader for n. Only at the beginning of phase 3 a prospective leader becomes an established leader, when it will also be the primary process [8].
1. Discovery phase
In this phase the followers communicate with their prospective leader so the leader collects information about the last transactions his followers have accepted. The intent of this phase is to determine the most recent sequence of accepted transactions between the majority of nodes. In addition, a new epoch is being established so previous leaders cannot make new proposals. Since the majority of followers have accepted all changes from the previous leader, there is at least one follower having all changes accepted from the previous leader in its history queue, meaning the new leader will have them too.
2. Synchronization phase
The synchronization phase completes the recovery part of the protocol and synchronizes the replicas in the cluster using the updated history of the leader from the discovery phase. The leader proposes transactions from its history to its followers. The followers recognize the proposals when their own history is behind the leader's history. If the leader receives approval from the majority of the nodes, it sends a commit message to them. At this point, the leader is established and no longer just a perspective leader.
3. Broadcast phase
If no crashes occur, the nodes remain in this phase indefinitely and send transactions as soon as a ZooKeeper client sends a write request.
To detect errors, ZAB employs periodic heartbeat messages between followers and their leaders. If a leader does not receive heartbeats from the majority of his followers within a certain timeout, he resigns leadership and switches to Leader election in phase 0. A follower also switches to phase 0 if it does not receive heartbeats from its leader within a timeout [7].
Byzantine Algorithms
A Byzantine fault-tolerant protocol should be able to achieve a common objective even in the event of node malicious behavior.
The paper "Byzantine General's Problem" by Leslie Lamport, Robert Shostak and Marshall Pease provided the first proof for the solution of the Byzantine General's problem: It revealed that a system with x Byzantine nodes must have at least 3x + 1 total node to reach consensus.
Byzantine nodes are the cause. If x nodes are faulty, then the system must function correctly after reconciliation with n – x nodes, since x nodes can be byzantine.
In order for the number of non-faulty nodes to exceed the number of faulty nodes, at least n – x – x – x > x is required. Therefore n > 3x + 1 is optimal.
However, the algorithm from the paper "Byzantine General's Problem" only works in synchronous environments.
Byzantine algorithms such as DLS and PBFT prodived for asynchronous environments are significantly more complex [4].
DLS Algorithm
The DLS algorithm was presented by Dwork, Lynch and Stockmeyer in the paper "Consensus in the Presence of Partial Synchrony" as a significant advancement of Byzantine algorithms.
It defines models to reach a consensus in a partially synchronous system. Partially synchronous lies between a synchronous and an asynchronous system, which is defined by the following two statements.
- There are fixed timeouts until messages are delivered, though these are unknown in advance. The aim is to reach consensus independently of the actual timeouts.
- The timeouts are known, yet they only apply at an unknown time. The goal is to design a system capable of achieving consensus regardless of when this time occurs.
The process of the DLS algorithm is based on rounds divided into "drying" and "lock-release" phases.
- Each round has a proposer and starts with each node giving a value it considers correct.
- The proposer suggests a value if at least n -x nodes have given this value.
- When a node receives the proposed value from the proposer, the proposer must lure and broadcast this information on the network.
- If the proposer learns from x + 1 nodes that they have lured the value, then they commiteted the value as the final value.
For the first time, DLS introduced the terms safety and liveness, which are equivalent to agreement and termination.
In addition to the DLS algorithm, there is also the Practical Byzantine Fault-Tolerance (PBFT) algorithm, available for use in asynchronous environments. However, due to the limited scope of this blog post, it is not discussed here [4].
Approach 2: Non-Deterministic
In addition to the option of using synchrony assumption to bypass the FLP impossibility, non-deterministic algorithms can also be used to achieve this.
Nakamoto Consensus (Proof of Work)
In traditional consensus algorithms, a function f(x) is defined so a proposer and a set of acceptors must all coordinate and communicate to decide on the next value.
Therefore, these algorithms often scale poorly, since each node must be aware of and communicate with every other node in the network. Using the Nakamoto Consensus, nodes do not agree on a value, but f(x) works in such a way that all nodes agree on the probability that the value is correct.
Instead of electing a leader and coordinating with all nodes, a consensus is reached on which node can solve a calculation puzzle the fastest. Nakamoto Consensus assumes that the nodes will use computational effort for the chance to decide the next block. This proof of work consensus is simpler than previous consensus algorithms, eliminating the complexity of point-to-point connections, leader choices, and square communication effort.
However, the Nakamoto Consensus requires time and energy to write a new block to solve the calculation puzzle [4].
Proof of Stake and Proof of Authority
In addition to reaching consensus on resources and mining power via PoW, the mechanisms Proof of Stake (PoS) and Proof of Authority (PoA) proceed differently.
The PoS mechanism operates with an algorithm that selects participants with the highest stakes as validators, assuming the highest stakeholders receive incentives to ensure a transaction is processed. Meanwhile, PoA uses identity as the only verification of the authority to be validated, so there is no need to use mining [10].
Cluster manager
Now, knowing the consensus protocols, a look with regard to the use of consensus algorithms in existing cluster managers is possible.
| Cluster Manager | Distributed key value store | Consensus Protocol |
|---|---|---|
| Google Borg | Chubby | Paxos |
| Kubernetes/Openshift | Etcd | Raft |
| Nomad | – | Raft |
| Docker Swarm | – | Raft |
| Apache Marathon based on Mesos | Apache Aurora | ZooKeeper |
| Kontena | Ectd | Raft |
| Amazon Elastic Container Service (ECS) | Consul | Raft |
As Table 1 illustrates, the tendency towards Raft is strong [11-14].
Surely this is due to the good comprehensibility and the many implementation requirements compared to Paxos. Although Paxos is used by Google, but rather historically in Borg. ZooKeeper is very similar to Raft and therefore a reasonable choice for Apache Marathon.
Cluster management without a consensus protocol
In contrast to a cluster management with consensus algorithm, the paper "Subordination: Cluster management without distributed consensus" proposes a cluster management without consensus algorithm.
In this paper cluster management is achieved by subdividing the nodes in the cluster via subordination. The main goal is to distribute the workload over a large number of nodes, similar to a load balancer. Cluster management without distrubuted consensus relies on the following conditions.
- Few frequented network configuration changes
- It is not intended for managing updates of a distributed database.
- The node performance and node latency must remain stable.
- A constant network traffic is assumed [15].
Node Mapping
A fundamental idea of this variant of cluster management is node mapping or the evaluation of nodes.
In general, node mapping is defined as a function that maps a node to a number. This allows nodes to be compared with each other.
Due to Amdahl's law: The higher the link performance, the higher the speedup.
Instead of including the node performance and latency separately in the mapping, the node performance and latency can be correlated. This means that only the ratio is included in the mapping [15].
Subordination Tree
In the subordination tree, each node is uniquely identified by a level and an offset. A distance can be calculated based on this.
To select a leader, a node evaluates all nodes in the network based on the mapping and calculates the distance. The node with the smallest distance and ranking is selected.
Level and Offset is only used for linear topologies (at a switch).
For non-linear topologies, latency is used for mapping.
Instead of maximizing performance, the main goal of the algorithm is to minimize network traffic per time unit if the leader is chosen and the number of nodes is unknown.
Due to the condition of low traffic changes to the network configuration, the algorithm could be initially executed and persisted when the cluster is installed.
The paper includes a performance and subordination tree test.
In the performance test, a full network scan was performed as a basis for comparison and a leader was determined.
The IP mapping was then performed by using the node mapping algorithm and a leader was determined. Figure 12 displays the result [15].
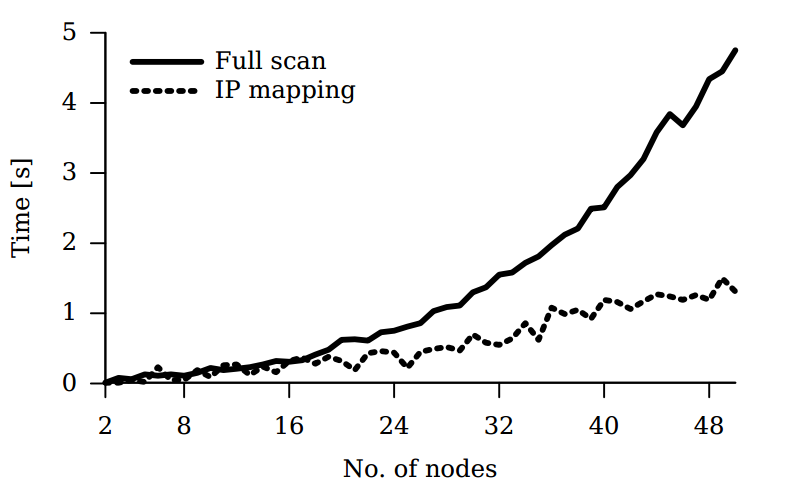 |
|---|
The subordination tree test examined whether the resulting trees reached a stable state. For 100-500 nodes the structure of the subordination tree was repeated in order to obtain meaningful results. After 30 seconds the test was aborted to define a temporal upper limit. The results reveal that a stable state was achieved well below 30 seconds.
Discussion
In conclusion, consensus algorithms are a central aspect of cluster management and distributed systems. Older protocols like Paxos have revealed their strengths and weaknesses over time. The experience gained has been incorporated into newer protocols such as Raft and ZooKeeper to improve understanding and robustness.
Byzantine consensus algorithms represent a particularly exciting application. Especially in times of increasing Internet crime and organized hacking, manipulated behavior of individual nodes in the public Internet must be assumed.
New technologies such as blockchain offer a new perspective on matters. For instance, a key-value store could possibly be developed using Proof of Stake or Proof of Authority as a consensus algorithm. This key-value store could be used in a public kubernetes cluster instead of Etcd. This would provide additional protection against Byzantine nodes. On the other hand, there are also incentives against cluster management with a consensus algorithm. The paper "Subordination: Cluster management without distributed consensus" shows a way to manage a cluster without a consensus algorithm.
However, this approach has many implicit conditions which cannot be guaranteed in a real distributed system. Another approach supporting this hypothesis is K3s, which shows that cluster management on a small scale is also possible without a consensus algorithm. K3s uses SQLite3 as database. However, it is possible to use Etcd3. The field of application is IoT, where often fixed IPs are assigned and therefore hardly any changes take place.
Ultimately, there is no generic solution. Currently a tendency to Raft in controlled data centers seems to exist. Nevertheless, depending on the application, a decision on whether to use cluster management with simple consensus, possibly Byzantine consensus or without consensus remains.
References
- Survey Shows Kubernetes Leading As Orchestration Platform
https://www.cncf.io/blog/2017/06/28/survey-shows-kubernetes-leading-orchestration-platform/
- The Techglider
Kartik Singhal – https://techglider.github.io/review/time-clocks-and-ordering-of-events-in-a-distributed-system/
- A Cursory Introduction To Byzantine Fault Tolerance and Alternative Consensus
Alexandra Tran-Alexandra Tran – https://medium.com/@alexandratran/a-cursory-introduction-to-byzantine-fault-tolerance-and-alternative-consensus-1155a5594f18
- Let's Take a Crack At Understanding Distributed Consensus
Preethi Kasireddy-Preethi Kasireddy – https://medium.com/s/story/lets-take-a-crack-at-understanding-distributed-consensus-dad23d0dc95
- Consensus Protocols: Two-phase Commit
Henry Robinson – https://www.the-paper-trail.org/post/2008-11-27-consensus-protocols-two-phase-commit/
- Understanding the Raft Consensus Algorithm: an Academic Article Summary
Shubheksha – https://medium.freecodecamp.org/in-search-of-an-understandable-consensus-algorithm-a-summary-4bc294c97e0d
- Architecture Of Zab – Zookeeper Atomic Broadcast Protocol
Guy Moshkowich – https://distributedalgorithm.wordpress.com/2015/06/20/architecture-of-zab-zookeeper-atomic-broadcast-protocol/
- ZooKeeper’s atomic broadcast protocol: Theory and practice, Andr´e Medeiros March 20, 2012
http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
- A simple totally ordered broadcast protocol, Benjamin Reed, Flavio P. Junqueira
http://diyhpl.us/~bryan/papers2/distributed/distributed-systems/zab.totally-ordered-broadcast-protocol.2008.pdf
- Proof Of Authority: Consensus Model with Identity At Stake.
POA Network- POA Network – https://medium.com/poa-network/proof-of-authority-consensus-model-with-identity-at-stake-d5bd15463256
- Consensus Protocol
https://www.nomadproject.io/docs/internals/consensus.html
- Raft Consensus in Swarm Mode
https://docs.docker.com/engine/swarm/raft/
- The Mesos Replicated Log
https://mesos.apache.org/documentation/latest/replicated-log-internals/
- The Developer Friendly Container & Microservices Platform
Kontena, Inc – https://www.kontena.io/
- Gankevich, Ivan & Tipikin, Yury & Gaiduchok, Vladimir. (2015). Subordination: Cluster management without distributed consensus. 639-642. 10.1109/HPCSim.2015.7237106.
Leave a Reply
You must be logged in to post a comment.