
A brief introduction to the fundamental concepts of Erlang and Elixir
Ever since the first electronic systems have been created, engineers and developers have strived to provide solutions to guarantee their robustness and fault-tolerance. Thereof arose the understanding that developing and building a fault-tolerant system is not an easy task, because it requires a deep understanding of how the system should work, how it might fail, and what kinds of errors could occur. Indeed, it became obvious that successful error detection and management are essential for the accomplishment of fault tolerance. That is, once an error has occurred, the system might be able to tolerate it by replacing the offending component, using an alternative means of operation, or raising an exception. However, architectures relying on such approaches exhibited considerable complexity, and thus, resulted in unpredictable and less reliable systems. Consequently, the development of robust and error resistant systems has become an ongoing endeavor for engineers and software developers alike, who evermore intent to develop new approaches to solve this enduring problem inherent to complex systems.
The problem in a nutshell
In today’s ever-growing computer-dependent digital societies, reliability and availability have become increasingly important assets. In many scenarios where computers are used, defects or malfunctions can not only be a financial liability but may even have disastrous outcomes. Indeed, the effects of a computer system failure in a nuclear plant, space shuttle or airliner can have far-reaching consequences, not only for those directly involved but for the broader public itself. From this arises the needed for fault-tolerant computer systems that can tolerate errors by detecting failures and isolate defect modules so that the rest of the system can continue to operate correctly. A system is considered fault-tolerant when it continues to work predictably, even though an error occurred or things in its environment failed [2]. More importantly, fault tolerance has to be built into the system from the very beginning and should, therefore, be an integral part of its fundamental architecture.
Whatever can go wrong will go wrong at the worst possible time and in the worst possible way…
-Edward A. Murphy
Furthermore, from a statistical point of view and contrary to common beliefs, outages are seldom caused by hardware failures. In today’s modern computer systems, fault-tolerance masks most hardware failures, and the percentage of interruptions caused by hardware faults have become lesser and lesser in the past decades. On the other side, outages caused by software errors are increasing. According to a study on Tandem systems [3], the percentage of outages caused by hardware faults was 30% in 1985 but had decreased to 10% in 1989. However, outages caused by software faults increased in the same period, from 43% to a staggering 60%. Therefore, this article will focus on the software component and how fault resistant systems can be designed on a software level. More precisely, it will be discussed how fault-tolerance is handled by the Erlang language and its successor Elixir, which have both been designed to support concurrency, distribution, and error management. However, an encompassing representation of this topic would go far beyond the scope of this blog. Consequently, this article will only focus on the description of the fundamental architecture and core principles, to give the reader a brief overview of the inner working of these languages and their quite intriguing approach to fault management.
Do it the Erlang way
As aforementioned, this article should provide a general overview of both Erlang and Elixir, their basic architectural ![]() concepts, and how they operate as a development platform to build fault-tolerant systems. Many of those concepts will be presented in the context of Erlang whose architecture and abstractions build the very foundation of the Elixir core language. Consequently, all the fundamental design principles that will be described for Erlang can directly be translated to Elixir, which itself is considered an evolution of Erlang that allows writing cleaner, simpler, and more compact code [4].
concepts, and how they operate as a development platform to build fault-tolerant systems. Many of those concepts will be presented in the context of Erlang whose architecture and abstractions build the very foundation of the Elixir core language. Consequently, all the fundamental design principles that will be described for Erlang can directly be translated to Elixir, which itself is considered an evolution of Erlang that allows writing cleaner, simpler, and more compact code [4].
As a language, Erlang belongs to the family of pure message-passing languages being characterized by a concurrent process-based structure, having strong isolation between concurrent tasks [5]. It derives from a programming model that makes extensive use of fail-fast processes and is built upon the functional programming paradigm integrating the concepts of immutable objects as well as pattern matching [2]. Erlang was originally designed to program applications for telecommunication systems, especially telephone switches. More important, Erlang is not just a programming language but a full-blown development platform consisting of the language itself, its virtual machine, several frameworks, and a number of building tools [2].
One of the main goals of Erlang’s design was to provide a fault-tolerant software system that behaves reasonably in the presence of software errors [2]. To achieve this, Erlang programs are organized into hierarchical tasks that are designated to achieve a certain number of individual goals. This concept allows encapsulating code to simplify the detection of errors and to prevent their propagation to other parts of the system. To reach this kind of fault-isolation, Erlang makes use of the traditional notion of processes, common to most operating systems [2].
The concept of processes in Erlang
Everything is a process
In Elixir and Erlang, processes are used as fundamental architectural building blocks to construct complex systems. Processes are computational units that execute code concurrently with other processes at their own pace. Erlang processes lack shared memory and interact with other processes only by exchanging asynchronous messages. This concept is very similar to the actor model, a quite well-known mathematical model of concurrent computation [6]. Thus, rather than providing threads that share memory which inadvertently may lead to interference and unwanted side-effects, each Erlang process is executed within its own memory space and occupies its own heap and stack. Furthermore, the basic concept of Erlang processes derives from a paradigm called ‘Concurrency Oriented Programming’ [2]. It adheres to some fundamental principles that can be described as follows:
- Processes on the same machine must be completely isolated. A fault in one process should not affect others, except it is explicitly intended.
- Every process is identified by a unique process identifier (PID).
- State should not be shared among processes. Interactions between processes should only occur by sending messages using the process’ PID.
- Message passing is asynchronous and is assumed to be atomic.
- Messages should not contain pointers to data structures within processes but rather constants or PIDs.
- There is no guarantee that a message sent to a process will actually be delivered.
- A process should be able to detect a failure in other processes by receiving error messages stating the cause of failure.
The source code written in Erlang gets compiled into Bytecode which then runs inside the Erlang virtual machine called BEAM (Bjorn’s Erlang Abstract Machine). The virtual machine then parallelizes the concurrent programs by managing process isolation, distribution, and the overall performance of the system. BEAM also uses specific schedulers to distribute process execution over the available CPUs, and by this, optimizes concurrent program execution (figure 1).
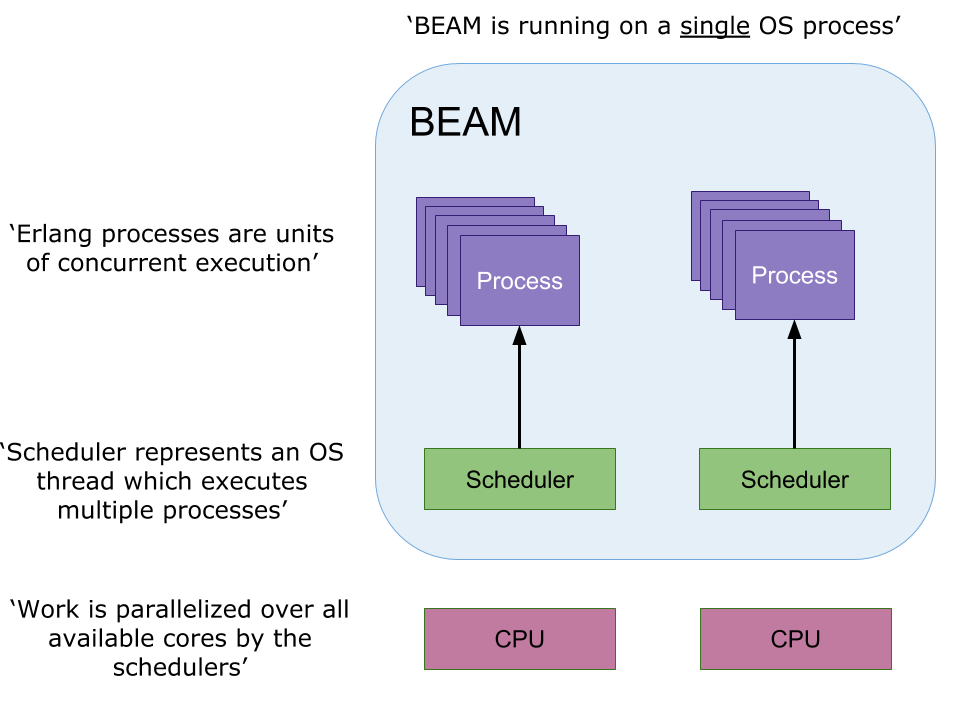
As indicated in figure 1, Erlang processes are not provided by the operating system but by the language’s runtime system using a lightweight threading model. Hence, Erlang processes are essentially user-space threads rather than operating system processes or kernel threads [7]. Whereas threads in several other programming languages and operating systems are concurrent activities that operate within the same memory space (and have countless opportunities to interfere with each other), Erlang’s processes can safely work under the assumption that nobody else will be messing around by changing their data from one moment to another. Consequently, processes can’t interfere with each other inadvertently, as is all too easy in most common threading models, leading to deadlocks and other unwanted side-effects. To put it in other words: ‘Erlang processes encapsulate state in a consistent and resource-efficient manner ‘. Indeed, as reported by Vinosky [8], a 2.33-GHz Intel Core 2 Duo MacBook Pro with 2 Gbytes of RAM can easily launch 1 million Erlang processes in 0.51 seconds. In contrast, using the same system and the C++ ‘pthreads’ library, only 7.044 threads can be launched in 1.3 seconds, ultimately resulting in quick exhaustion of computational resources.
Erlang’s approach to fault-tolerance
Fail fast and let someone else fix the problem
Compared to other programming languages, Erlang has a rather unique way of handling errors. A typical Erlang system consists of a large number of lightweight processes that interact with each other to complete a predetermined task. In that manner, it is not very uncommon when one of these processes dies. Indeed, the proposed way of programming is to let failing processes crash, and other processes detect the crashes and fix them. In this context, it is of utmost importance that crashing processes should not affect the operation of other processes or even provoke an overall system failure [7]. However, this begs the quite captivating question of how Erlang processes achieve failure detection and error management. The answer requires an understanding of several fundamental concepts that form the very foundation of Erlang’s architecture. Therefore, the following sections will try to provide sufficient insights into Erlang’s inner working by explaining the most important concepts and how they can be used to build robust and fault-tolerant systems.
Creating processes
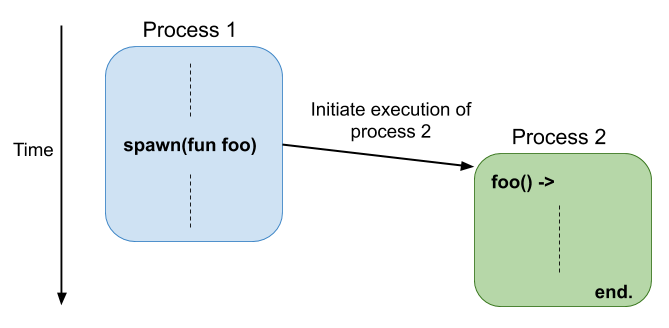
As mentioned previously, Erlang’s processes are not operating system threads. They are much more lightweight and provided by the Erlang runtime system which is capable of spawning hundreds of thousands of processes on a single system running on commodity hardware [7]. In a modern operating system, a typical thread usually reserves several megabytes of address space for its stack, and there is still the probability that it crashes if more stack space is used than is provided by the system. Erlang processes, on the other hand, are instantiated with only a few hundred bytes of stack space each, and they can grow or shrink dynamically as required. Erlang processes are created through the concept of “spawning”, which in its most simple form can be expressed as follows:
PID = spawn(fun Function)
This allows to create an Erlang process from any common function and concomitantly returns the unique PID of the newly created process [9]. The function body is now executed in parallel without affecting other processes unless explicitly programmed to do so. Hence, once spawned, a process will continue executing and remain alive until it eventually terminates (figure 2). If there is no more code to execute, a process will terminate normally. On the other hand, if a runtime error such as a ‘division by zero’ or a ‘case failure’ occurs, the process will terminate abnormally [7]. Especially the latter case will be of particular interest in the following sections where principles will be discussed on how Erlang handles errors.
Brief excurse into process communication
One of the central problems of concurrent systems, which all developers have to solve, is the way information is exchanged. Once a complex problem has been separated into different tasks, how should those independent tasks communicate with each other? Even though being a quite simplistic question, the solution has puzzled whole generations of developers, and many approaches have been brought forward over the recent years. Several of those have appeared as programming language features and some as separate libraries. Therefore, the most important should be introduced and discussed in this section.
Shared memory with locks
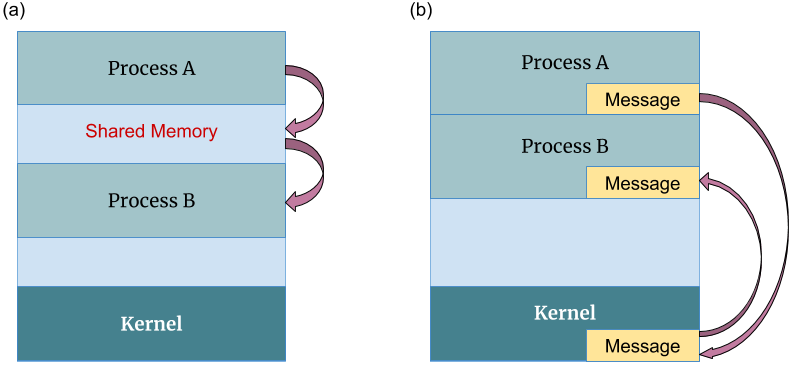
For quite some time now, shared memory has developed to become a mainstream technique for process communication (figure 5). Notwithstanding its popularity, it also provides numerous ways to get it wrong, having imbued generations of engineers with a deep fear of concurrency. The paradigm encompasses techniques for parallel read or write operations involving two or more processes accessing one or several distinct memory cells. Thus, to make it possible for a process to perform an atomic sequence of operations on those cells, there must be a way for the process to block all others from accessing the cells until all operations have been terminated. This can be achieved by using locks, a construct that allows granting restricted access to a resource for a single process at a time [10].

For the implementation of locks, support from the memory system in the form of special instructions on the hardware level is needed. In addition, for the successful usage of locks, a flawless collaboration between processes is important. Each process must make sure to ask for the lock before accessing a shared memory region, and the lock must also be released properly so that other processes can use it. The slightest failure can have devastating effects, making the usage of higher-level constructs such as semaphores, monitors, and mutexes necessary (figure 3). They are built on these basic locks and are provided as operating system calls or programming language constructs to make it easier to guarantee that locks are properly requested and returned. Even though this allows to evade the worst problems, locks still have a number of shortcomings:
- Locks can produce overhead even when the chances of collisions are low.
- They constitute points of contention in the memory system.
- They can make the process of debugging particularly difficult.
- Locking can also lead to priority inversion, convoying, deadlocking, and blocking due to thread failure.
Software Transactional Memory
Software transactional memory (STM) can be seen as a quite exotic, non-traditional method (figure 4). It has so far been implemented in the Haskell programming language, as well as in the JVM-based language Clojure. It’s an intriguing concept that allows treating memory in the same way as a traditional database, using transactions that decide what has to be written within a determined time frame. The idea is to avoid locking mechanisms, and instead, try to work in an optimistic way. Thus, a sequence of read/write accesses is handled as single operations, allowing one process to operate on a shared memory region, while other processes trying to access the same region will not succeed. The failing process will be instructed to try again after the updated content has been checked [11].
The model provides a quite clean solution that does not involve the complex requesting and releasing of locks. However, the catch is that failed transactions have to be repeated (and they could, of course, fail continuously). The method also produces a significant overhead for the realization of the transaction system itself, including sufficient additional memory to store the data intended to be written, until it’s decided which process will succeed. An optimal implementation would rely on hardware support for transactional memory, similar to the quite common virtual memory.

Futures, Promises, and similar
An alternative, more modern approach is the application of futures and promises. This concept has already been implemented in various contemporary languages like MultiLisp, Java, JavaScript, Haskell, and Concurrent Prolog. The principal concept is that a future is a result of a computation that has been outsourced to some other process, possibly on another CPU or even a completely different network. A future, in essence, is just a construct that can be handled like any other regular data object [12]. The main difference, though, is the standardized behavior for read-access, which requires the user to wait in case the value has not been calculated yet. Such an approach allows passing data between different segments of a concurrent system [13]. However, it also makes the program brittle should the responsible remote process or network fail for some reason. The section of code that tries to access the value of the promise may have no predefined action in case the value is missing, or the connection has failed. This problem can lead to undefined behavior or even a system crash which can often only be mediated through complex error management routines.
Message passing
The final concept to be presented in this section is based on processes that communicate with each other by exchanging system messages (figure 5). Every process effectively gets a separate copy of data in the form of a message on which it can operate without affecting the sender in any way. The only means to replay to the obtained information is for the receiver to send a message in the reverse direction. More importantly, communication always works in the same uniform and simple manner, whether both sender and receiver are on the same computer or reside within separated networks [14].
Principally, message passing can be performed either synchronously or asynchronously. Synchronously means that the sender has to wait until the message has been received by the communication partner. In contrast, sending an asynchronous message means that the sender can proceed immediately after transmitting the message. The asynchronous version is also called the “send-and-pray” method of communication because it allows the sender to confidently continue with its work while the message is being delivered. This is of particular advantage when the message has to be delivered over a slow network connection [15].
Just like all other methods described above, there are also drawbacks to this approach. Firstly, copying data blocks can be costly, especially for large data structures. Moreover, significant consumption of memory resources can occur if the sender also needs to keep a replica of the transmitted data. This results in the necessity for the programmer to consider such limitations by managing the size and complexity of the messages, which may not always be an easy task.
Process communication in Erlang
As already indicated, Erlang is characterized by purely relying on the message passing concept for process communication. Each process can receive messages through a mailbox from which they can then be extracted using pattern-matching constructions [16]. Given that message passing in Erlang is asynchronous, once a message is sent, the process can continue its operation. Messages are retrieved from the process’ mailbox selectively, so it is not necessary to handle messages in the order they were received. Such a concept allows to build more robust concurrent systems, particularly when processes are distributed across different computers, and the order in which messages are received will depend on ambient network conditions.
Communication between processes in Erlang is quite simple and straightforward. The basic operator used for sending messages is ‘!‘, pronounced “bang,” and it’s applied in the form:
Destination ! Message
In order for a process to receive a message, the ‘receive‘ operator is used having the following form:
receive [Pattern] -> Handler
The ‘receive’ expression is used to collect messages from the process’ mailbox. It allows specifying a set of patterns which are then associated with the corresponding handler code. In fact, the expression represents a loop that continuously scans the mailbox for messages that match any of the given patterns, and which blocks if no such message is found. This is actually the only blocking primitive in Erlang [16].
The description above depicts process communication using messages in its most basic form which can be implemented as seen in the following simplified “Ping-Pong” example:
run() ->
PID = spawn(fun ping),
PID ! self(),
receive
pong -> print(“PONG”) (Pattern-matching of literal ‘pong’)
end.
ping() ->
receive
From -> print(“PING”), (Pattern-matching of sender PID)
From ! pong
end.
start() -> spawn(fun run).
Even without knowing Erlang, it should be no difficult task to understand that the execution will result in the display of the two words “PING” and “PONG”. The more interesting aspect, however, is how Erlang handles concurrency by creating processes working in parallel, which interact with each other through simple message passing. The first is created when the program is initiated by calling the ‘start()’ function containing the‘spawn (fun run)’ expression, which will spawn a new process that executes the function body of ‘run()’. The function itself spawns another process that executes the function body of ‘ping()’. Hereafter, the PID of the process is used to send it a message containing the identifier of the calling process, which is generated calling ‘self()’. The called process then uses the passed PID to send a message back to the ‘caller’ itself. The message consists of the simple literal ‘pong’ which can be pattern matched by the ‘receive-block’ within the ‘run()’ function. This ultimately results in the display of the aforementioned message (figure 6).
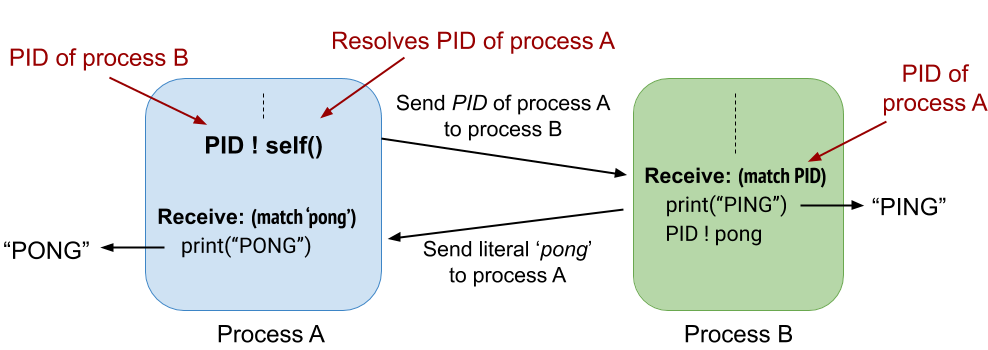
That essentially is Erlang’s process communication in a nutshell. It also illustrates how concurrency is handled by creating separate tasks (processes) that interact with each other only through message passing. Hence, every call to spawn yields a fresh process identifier that uniquely identifies the new child process running concurrently. This identifier can then be used to send messages to the child. All incoming messages are stored in the mailbox as they arrive, even if the receiving process is currently busy, and the messages are kept there until the process decides to check the mailbox. It can then search and retrieve messages from the mailbox at its convenience using the receive expression, as in the example (which takes the first available message).
Error handling
Let it crash !
Similar to several other programming languages, Erlang provides exception handling for catching errors in a particular piece of code. Hence, the evaluation of a function can either result in the production of a return value or in the generation of an exception. Exceptions can either be generated implicitly through the runtime system or explicitly through the ‘exit(X)’ primitive [17]. An exception occurring within a process may be caught and handled, or if not, results in exiting of the process. In the latter case, the Erlang system provides signaling mechanisms by which processes can let other processes know that they are exiting. These exit signals also contain an exit reason, which helps other processes to decide how to react to the signal [9]. Essentially there are three reasons why a process terminates:
- Normal exit – A normal exit means that the process has performed its work and terminates execution. The process then emits a signal stating a normal termination. Such signals can usually be ignored, but they are still emitted for the sake of interested processes.
- Exit caused by unhandled errors – This usually occurs when an uncaught exception is raised inside the process. In that case, an exit signal is sent that provides the exit reason in the form of a message containing the exception details.
- Forcefully killed – Processes can send exit signals with the reason kill, which forces the receiving process to terminate.
The recommended way of programming in Erlang, and in which it fundamentally differs from other languages, is to let failing processes crash and other processes detect the crashes and fix them. The idea is that the crash of one process does not affect any other process in the system [18]. To build fault-tolerant systems based on this concept, it is also necessary that processes can inform each other when and how they terminated. For this purpose, there is the possibility to link two processes together or to use a process monitor. Process linking allows to group processes in such a way that an error in any one of the processes may subsequently lead to the termination of all the other linked processes, forming an error-propagation chain. Process monitoring, on the other hand, allows individual processes to monitor the behavior of other processes [16].
The ‘Let it Crash’ philosopy
In comparison to other languages, Erlang was developed to provide a very unique approach to error management. Instead of pocking around desperately by trying to save a situation that may not be salvageable, Erlang follows the philosophy of “Let it crash”. Meaning, that everything should be terminated cleanly and restarted, while log files are created that capture the information allowing to recreate the incident. Such an approach can be a powerful recipe for fault tolerance and for creating systems that are possible to debug notwithstanding their complexity and error-proneness.
Linking processes
Erlang follows a unique concept of process linking for handling process failures in a quite reliable way (figure 7). Thus, when an Erlang process terminates due to an error, it generates an ‘exit signal’. This signal is broadcasted to all processes within the so-called ”link set” of the failing process [19]. If a process ’A’ wants to add a process ’B’ to its link set, it can do so by evaluating the primitive ‘link(PID B)’. Process links act in a symmetric way, meaning if ’A’ is linked to ’B’ then ’B’ will also be linked to ’A’ [7].
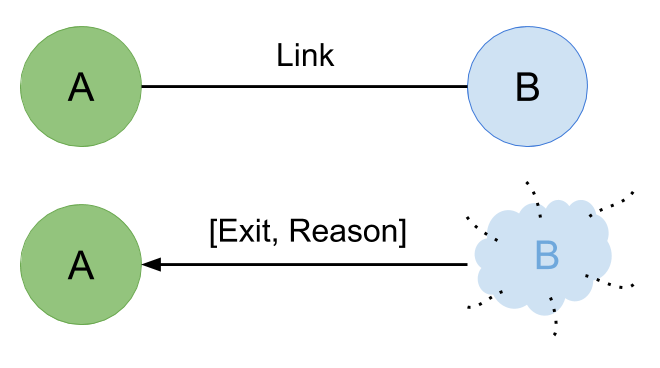
Thus, when an Erlang process dies unexpectedly, an exit signal is generated and broadcasted to all the other processes that are linked to it. By default, this causes the receiver to exit as well and propagate the signal to all other processes until all linked processes have terminated [19]. Relating to termination, this initiates a cascading behavior allowing a group of processes to function as a single application. In such a manner, a cleaning up of corrupt state can be performed, without the worry of finding and killing off any remnants before the restart of the entire subsystem. Hence, a process encapsulates all its state and can, therefore, terminate safely without jeopardizing the rest of the system. This is valid for a single process as well as for an entire group of interlinked processes. If one of the group fails, all collaborators also terminate, and the complex state that was created vanishes neat and easily, saving time and potential subsequent errors (figure 8).

Formalizing concurrency
Writing concurrent software is hard
In Erlang, a system is commonly divided into sections of either generic components which handle concurrency and recurring patterns, or plugins containing mostly sequential code that parametrizes the generic components [2]. Plugins often represent the application-specific implementation which communicates with the generic part via a simple, well-defined interface (figure 9). This makes concurrent code much more understandable despite the fact that it is often more difficult to analyze and understand because of its side-effects, issues of message passing or potential dead or live-lock problems. Therefore, abstracting out the more complex concurrent parts of a system into generic components allows writing reliable, highly efficient and well-tested code that is implemented once and reused whenever necessary. To this end, OTP (Open Telecom Platform) libraries have been built to formalize a considerable amount of design experience into workable libraries that provide a standardized way of performing the most common tasks needed to build reliable systems.
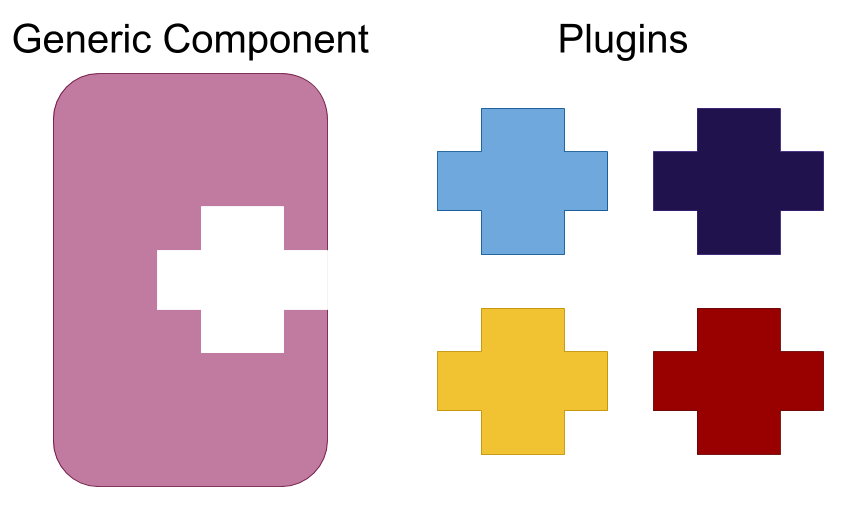
In Erlang, these formalizations of common patterns are called behaviors. The idea is to divide the code for a process in a generic part (a behavior module) and a specific part (a callback module) [7]. Some of the main reasons to use the OTP framework can be described in the following way:
- Stability: Programmers using OTP can focus on logic and avoid error-prone reimplementations that every real-world system needs: process management, servers or state machines.
- Productivity: OTP allows to write production-quality systems in a comparatively short time.
- Supervision: The framework provides an application structure that allows simple supervision and control of a running system.
- Reliability: The codebase on which the OTP framework was built is rock solid and has been intensively tested in countless real-life scenarios.
In summary, behaviors solve many of the challenges which accompany the programming of canonical, concurrent, fault-tolerant Erlang code. Hence, OTP libraries help to manage common problems like synchronous messaging, process initialization, process cleanup, and termination, but also provide hooks into larger OTP patterns and structures like code change and most importantly supervision trees.
The supervisor concept
As described above, Erlang allows creating structures of interconnected processes through linking. Once processes are linked, there is the possibility for selected processes to trap the ‘exit signals’ they received from other processes. This ‘special’ behavior of Erlang processes allows a process to override the default propagation of exit signals and become a so-called ’system process’. As a consequence, the processes can convert received exit signals from other processes into messages, which are then put inside the mailbox belonging to the process. When such a process receives an exit signal other than the kill signal, it will convert it into a simple message that can be caught by the receive block, allowing subsequent actions to be executed if necessary [9].
This concept of linking processes is a programming strategy that allows to set up groups of processes, which will all terminate if any of the processes fail. By forming a chain of transiently linked processes it is possible that one process assumes the role of a “supervisor“. This very process is set to trap exits and typically runs code that is different from that run by ordinary “worker processes”. If a failure occurs, the entire group will be terminated except the supervisor process which can receive messages informing it about the failures of the other processes in the group. The message itself describes the origin of the other processes’ failure allowing the trapping process to take specific actions if necessary. The ability to override the standard propagation of exit signals allows system processes to take a central role in error management by isolating subsystems that can be supervised and even restarted in case of failure. The main task of the supervisor is to monitor its children and take action in a predefined way when they terminate. The child process of a supervisor can either be a worker process or another supervisor [17].

The concept of supervision has been further expanded to create an OTP behavior called supervisor which exploits the characteristics of system processes to provide a reliable approach for system fault management. Hence, supervisors help to realize one of the most important design principles of Erlang applications allowing to link interdependent processes to form a supervision tree (figure 10). Supervisors are the workhorses that build the foundation of fault-tolerant, stable and reliable applications by starting, stopping, and monitoring their child processes. This is achieved by observing the child process’ behavior and keeping them performing their tasks while also restarting them whenever needed (figure 11). Thus, supervisors and supervision trees are at the heart of Erlang applications defining their basic structure and allowing them to perform the way they are supposed to in a fault-tolerant concurrent environment [7] [17].

Restart strategies
Once a child process crashes, the supervisor can execute one of the restart strategies depicted in figure 12 to reinitiate its operability. Their general behavior can be described as follows:
- one_for_one: Only the child that crashed will be restarted without affecting the other children in the tree. This is the default strategy that should be chosen when the processes within a branch are independent of each other.
- one_for_all: If one of the children in the branch crashes, all the other in the group will be terminated and restarted with it. This strategy should be chosen in the case of strongly interdependent processes.
- rest_for_one: Only the children started after the crashed process will be terminated and restarted. The strategy is a refinement of the ‘one_for_all’ strategy, assuming that the processes have been initiated in order of their dependency. This allows restarting only those processes that are dependent on the crashed one.
In the case that the restart limit is exceeded, the supervisor terminates itself and contemporaneously all the child processes while sending an ’Exit’ signal further up the supervision tree.

Layering processes for fault tolerance
Erlang allows the aggregation of related subsystems by layering them under a common supervisor. More importantly, layering allows defining different levels of working base states to which the system can revert to after a crash. In figure 13 a scenario is shown where two distinct groups of worker processes, A and B, are managed separately by their supervisor process. These two groups and their corresponding supervisors form a larger group C, under yet another supervisor higher up in the hierarchy. Assuming that group A, for example, provides multimedia data coming from a database and group B represents an implementation presenting the data. Even if an error in a process managing the multimedia stream would occur, causing it to crash, the other processes would not necessarily have to share the same fate.
That means, following the ‘let-it-crash‘ concept, the failing process will crash immediately without trying to fix the error, and because processes are isolated, none of the other processes are affected by the error. The supervisor of group A then detects that a process has failed and restores the base state specified for group A, allowing the system to continue from a known point. The advantage of this design is that group B might not even realize what happened to group A, especially if temporary outages could be managed through buffering. If group A continues to produce somehow sufficient data for the application to present, the system can continue to function successfully. Even if not, in the worst-case group B could still perform a complete reset to base state as a last resort, and the application could still behave reasonably.
To sum it up, Erlang allows creating subsystems that can be restarted individually in fractions of a second to keep the system running even in the presence of errors. It does so by isolating independent parts of the system and organizing them into a supervision tree. If group A continuously fails to restart, its supervisor might decide to initiate the group with other parameters, which could even include alternating the configuration of the database connection. If that will not solve the problem, it just could decide to quit and escalate the problem to the supervisor of layer C, which may then, as a last resort, decide to shut down both subsystems. Most importantly, an architecture based on this design would allow to restart or even shut down parts of a system because of occurring errors, while the rest could continue to function.

Elixir: The better Erlang
Elixir was designed as a modern multi-functional programming language to build large-scale distributed, fault-tolerant, scalable systems running on the Erlang virtual machine. It intends to provide a modernized approach for the development of Erlang-powered applications. Indeed, the language is a compilation of features from several other languages including Erlang, Clojure, and Ruby. Also, Elixir ships with a toolset that is aimed to simplify testing, project management, packaging as well as documentation building. Given that Elixir runs on the Erlang runtime platform, it has full access to all the libraries from the Erlang ecosystem [4].
The compiled Elixir source-code is BEAM-compliant bytecode that runs in any BEAM instance and can cooperate with pure Erlang code. Therefore, Elixir can use all the libraries from Erlang and vice versa. Elixir is semantically very close to Erlang code and, consequently, many language constructs can directly be translated. However, it provides more compact implementations of important standard libraries, adds a lot of syntactic sugar, and offers uniform tooling for creating and packaging systems. More importantly, Elixir offers many additional syntactical constructs that allow the developer to radically reduce boilerplate code and duplication. Consequently, noise from code can be reduced resulting in programs that are easier to write, understand, and maintain. Below an example of two different code snippets are shown that implement a simple server process which adds two numbers:
Erlang-based implementation
-module(add_server).
-behaviour(gen_server).
-export([start/0, sum/3, init/1, handle_call/3, handle_cast/2,
handle_info/2, terminate/2, code_change/3]).
start() -> gen_server:start(?MODULE, [ ], [ ]).
sum(Server, A, B) -> gen_server:call(Server, {sum, A, B}).
init(_) -> {ok, undefined}.
handle_call({sum, A, B}, _From, State) -> {reply, A + B, State}.
handle_cast(_Msg, State) -> {noreply, State}.
handle_info(_Info, State) -> {noreply, State}.
terminate(_Reason, _State) -> ok.
code_change(_OldVsn, State, _Extra) -> {ok, State}.
The Erlang example clearly shows how lengthy a piece of code can be that only performs a simple addition of two numbers. In all fairness, the computation is fully concurrent and would require some advanced programming techniques when replicated using other programming languages like Java or C#. Nevertheless, it is hard to read and contains a lot of repetitive boilerplate code.
Elixir-based implementation
defmodule AddServer do
use GenServer
def start do
GenServer.start(__MODULE__, nil)
end
def sum(server, a, b) do
GenServer.call(server, {:sum, a, b})
end
def handle_call({:sum, a, b}, _from, state) do
{:reply, a + b, state}
end
end
The code written in Elixir is not only much smaller but also easier to read and understand. Furthermore, the intention of the code is more obvious and clear, and it contains much less unnecessary noise. Thus, despite being much more compact, the code behaves at runtime exactly in the same manner as its Erlang counterpart while retaining the complete semantics. Thus, the examples show that Elixir demonstrates several features of a modern and attractive language that holds great potential for the future (figure 14).

Conclusion
The research on building fault-tolerant computer systems is still in its infancy. Given that ever more complex systems are getting designed and built, especially safety-critical systems, software-based fault tolerance may provide a viable approach to tackle the problem of system failures. However, to convince decision-makers, it is of importance to not only guarantee sufficient stability and robustness but also address the ever-increasing costs of building correct software systems. In this context, Erlang and Elixir may be attractive candidates because they provide architectural design concepts that have been battle-tested for decades now. Both are designed to efficiently build software systems that continue to function properly, even when unexpected errors appear. Even though the platform was initially designed for telecommunication systems, today it is used within a multitude of domains like database servers, real-time bidding services, collaboration tools, online payment systems, messaging tools, and online multiplayer games [21]. A very prominent example thereof would be ‘WhatsApp’ which, without any doubt, belongs to the most popular instant messaging applications today, with around 1.6 billion active users [22] [23].
One of the biggest problems of Erlang, however, is its demographic weakness. While many enterprises can recruit Java software developers directly from universities, there is comparatively little substance on the current market concerning Erlang developers. This not only aggravates the problem of providing sufficient company staffing but also generates risky dependencies on personal and individual service providers. Notwithstanding, its successor Elixir might provide the necessary traction to convince more companies to benefit from the Erlang system. Indeed, Elixir has already gained a large and dedicated community, especially among Ruby developers who are attracted by several familiar concepts the language offers. Thus, there is a good chance that more companies will decide to master the demographic risks and learn to benefit from the robustness, efficiency, and scalability of the Erlang ecosystem.
Outlook: The future of Erlang
Even though future developments are sometimes hard to predict, the Erlang ecosystem provides sufficient ground for improvements that could bring forth interesting new innovations. One important area of advancement will be Erlang’s support for massively multi-core processor architectures. The Erlang VM in its current state already supports multi-core architectures. However, a linear speedup can only be observed until the usage of about 20 cores, hereafter, the speedup drops to 50-60% when all cores of a 64 core machine are used [24]. There are already research projects sponsored by the European Union that aim to address this issue [25]. If successful, the Erlang VM could be able to efficiently handle a large number of cores while providing a relatively simple and robust approach to manage concurrency. Such a feature could be an important asset to make Erlang/Elixir an attractive development platform for future developers, especially for complex systems that demand high computational power.
Furthermore, Erlang’s architecture is still one of the main references for the development of other platforms in the field of distributed computing. One interesting emerging candidate, for example, is Akka, an open-source toolkit that makes use of the ‘Actor Model’ in combination with ‘Software Transactional Memory’ to raise the abstraction level and provide a solid platform to build reliable concurrent and scalable applications. It also embraces Erlang’s ‘Let it crash’ philosophy to handle occurring errors and failures [26]. Besides, there is Cloud Haskell, a development platform consisting of a set of libraries, allowing Erlang-style concurrent and distributed programming in Haskell [27]. It supports an expressive message-passing design which was shaped after Erlang’s process communication model. The platform is mainly used to develop software solutions for cluster computing, where high performance, reliability, and availability are essential.
References
[1] https://medium.com/swlh/how-lines-of-code-made-a-rocket-explode-77df73deb0a4
[2] Armstrong J., ‘Making reliable distributed systems in the presence of software errors‘. Ph.D. thesis, Stockholm: The Royal Institute of Technology, 2003.
[3] Gray J., Reuter A., ‘Transaction Processing: Concepts and Techniques‘. Morgan Kaufmann Publishers, 1993.
[4] Ballou K., ‘Learning Elixir’. Packt Publishing, 2015.
[5] Andrews G. R., Schneider F. B., ‘Concepts and Notations for Concurrent Programming’. In: ACM Computing Surveys, 15(1), pp. 3–43, 1983.
[6] Agha G., ‘Actors: A model of concurrent computation in distributed systems‘. In MIT Series in Artificial Intelligence, MIT Press, Cambridge, MA, 1986.
[7] Armstrong J., ‘Concurrency oriented programming in Erlang‘. Invited talk, FFG, 2003.
[8] Vinoski S., ‘Concurrency with Erlang‘. IEEE Internet Computing, 11(5), pp. 90-3, 2007.
[9] Armstrong J., ‘Erlang’. In: Communications of the ACM, 53(9), pp. 68–75, 2010.
[10] Hart T. E., McKenney P. E., Brown A. D., Walpole J., ‘Performance of memory reclamation for lockless synchronization’. Journal of Parallel and Distributed Computing, 67(12), pp. 1270-1285, 2007.
[11] Larus J., Rajwar R., ‘Transactional Memory’. Morgan and Claypool Publishers, 2007.
[12] Welc A., Jagannathan S., Hosking A., ‘Safe futures for Java‘. ACM SIGPLAN Notices, 40(10), pp. 439-453, 2005.
[13] Taveira W. F., de Oliveira Valente M. T., da Silva Bigonha M. A., da Silva Bigonha R., ‘Asynchronous remote method invocation in java’. Journal of Universal Computer Science, 9(8), pp. 761-775, 2003.
[14] Gentleman W. M., ‘Message passing between sequential processes: the reply primitive and the administrator concept’. Software: Practice and Experience, 11(5), pp. 435-466, 1981.
[15] Barry W., ‘Parallel Programming: Techniques and Applications Using Networked Workstations and Parallel Computers’. Second Edition, Pearson Education India, 2006.
[16] Armstrong J., Virding R., Wikström C., Williams M., ‘Concurrent Programming in Erlang’. Prentice-Hall, Second Edition, 1993.
[17] Larson J., ‘Erlang for concurrent Programming’. Communications of the ACM, 52(3), pp. 48-56, 2009.
[18] Armstrong J., ‘Programming Erlang: software for a concurrent world’. Pragmatic Bookshelf, 2013.
[19] Armstrong J., Virding R., Wikström C., Williams M., ‘Concurrent programming in ERLANG‘. Prentice-Hall, Second Edition, 1996.
[20] https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/
[21] Cesarini F., Thompson S., ‘Erlang Programming‘. O’Reilly Media, Inc., First Edition, 2009.
[23] Chechina N., Hernandez M. M., Trinder P., ‘A scalable reliable instant messenger using the SD Erlang libraries.‘ Proceedings of the 15th International Workshop on Erlang, ACM, 2016.
[24] Zhang J., ‘Characterizing the scalability of Erlang VM on many-core processors‘. Master Thesis, KTH Information and Communication Technology, Stockholm, Sweden, 2011.
[25] http://www.release-project.eu/
[26] https://akka.io/
Leave a Reply
You must be logged in to post a comment.