by Jannik Smidt (js343), Niklas Schildhauer (ns107) and Lucas Crämer (lc028)
Project idea
Montagsmaler is a multiplayer online game for web browsers. The idea is derived from the classic Pictionary game, where players have to guess what one person is painting. Basically, we have built the digital version of it, but with one big difference: Not the players are guessing, the image recognition service from AWS is guessing. The game’s aim is to draw as good as possible so that the computer (an AWS service) can recognize what it is. All players are painting at the same time the same thing and after three rounds they see the paintings and the score they have got for it.
Goal
At the beginning of the course, neither of us had any experience in cloud development. For this lecture we developed Montagsmaler exclusively from scratch. During the project, we have learned and tested new concepts and deepened our skills in software engineering and cloud computing. This article should give you a brief overview of our app, its challenges and the corresponding solutions during development.
Technical architecture
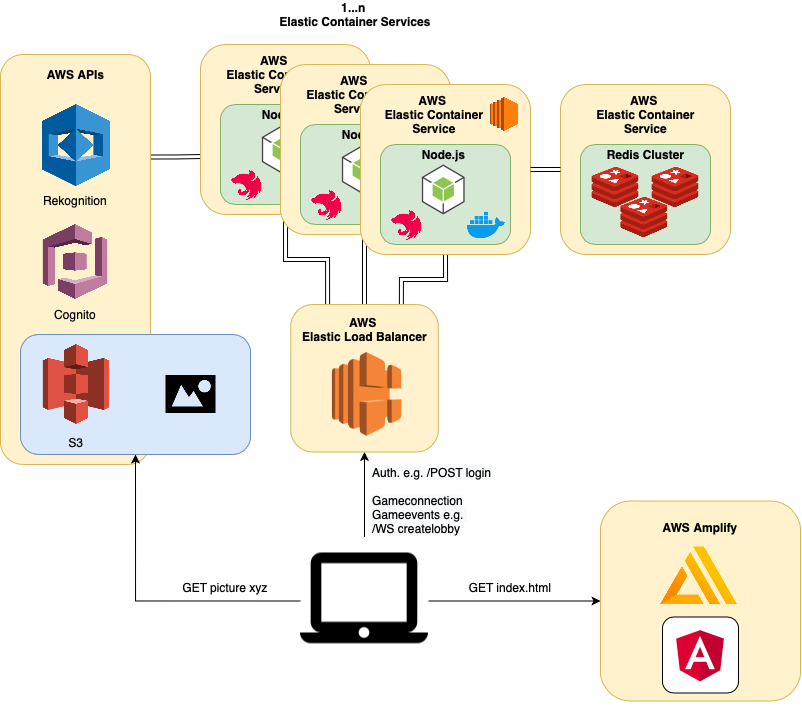
Cloud-Components
Amazon Cognito
Amazon Cognito is an AWS Service for user identification in the cloud. Cognito offers an API and SDKs for simple implementation for popular tech stacks.
We use Cognito for saving personal user data and handling the registration and authentication of the user accounts in our app. Cognito offers EMail verification for user accounts and state of the art token-based stateless authentication techniques.
Amazon S3
Amazon S3 is an object storage with a REST API. It offers high scalability, availability and fine granular access control. We use an S3 bucket to store the pictures which are saved during the games.
Amazon Rekognition
Amazon Rekognition is an AWS Service for computer vision tasks. Like Cognito Rekogniton offers an API and SDKs for simple implementation for popular tech stacks. We use Rekognition for labelling the pictures during a game after they were stored in the S3 bucket. These labels are then used to calculate a score for the picture which was submitted.
Amazon ElastiCache (Redis)
Amazon Rekognition is an AWS Service for Redis. We wanted to use it in our architecture for a redis cluster, but since we do not have permission to start even a single ElastiCache Instance, we could not use it at the end.
Amazon Elastic Container Service
Amazon Elastic Container Service is a highly scalable, container management service that makes it easy to run, stop, and manage containers on a cluster. We have one cluster and this cluster has one Elastic Container Service, which contains the core of our application the Montagsmaler API. Our application is continuously deployed with a Task Definition (more on that in CI-Components). This Task Definition deploys two docker containers. One container contains the Montagsmaler API. The other container contains a redis-server since we could not use the Amazon ElastiCache due to permission restrictions.
Amazon Application Load Balancer
We use an Amazon Application Load Balancer which routes all the traffic to the Elastic Container Service. We currently only have one cluster with one service instance, so it fulfills the role of a reverse proxy as of right now. We can not use TLS encryption since we do not have permission to access the AWS Certificate Manager, which is kind of a bummer since it leads to popular browsers refusing to store the HTTP-only cookie containing the refresh token since we can not enable “SameSite: Secure”, which is required.
Amazon Amplify
Amplify offers two products and functions: the Amplify Framework to create serverless backends and static web hosting. For us the static web hosting was interesting. We used it to host our angular frontend. It’s a simple tool which is connected to our github repository and automatically builds the master branch, when a new commit was made (more in CI-Components).
CI-Components
Github Actions
We use GitHub Actions for “continuous integration” of our application. We have an action which automatically tests and deploys the backend to AWS. This action is triggered on every push or pull request to the master.
Test
The action runs on a Ubuntu machine with a node installation. First it runs the unit tests and then it runs the e2e tests. If even one test fails the deployment stops and we get a notification via EMail.
Deploy to AWS
The deployment depends on the successful test. It does also run on a ubuntu machine. It starts with configuring the AWS credentials which are stored in the GitHub Secrets of our repository. Then it logs into the AWS Elastic Container Registry and builds the docker image to push it. On successful build and push the AWS Elastic Container Service Task Definition with the new image is rendered. Here we need an extra step since we do not have proper access to AWS IAM: Usually the URI of the credentials is put into the task definition, but we do not have permission to access this URI and our credentials are only valid for about three hours. That is why we take the credentials here also from GitHub Secrets and then insert them manually into the Task Definition using the shell and inplace substitution with sed. When the Task Definition is ready it is deployed to our AWS Elastic Container Service.
We used amplify’s static web hosting to provide the frontend. It would also have been possible to provide the frontend with an AWS S3 bucket. We chose Amplify because of its simple continuous workflows. Once we connected Amplify to Github, all we had to do was select our project, choose the master branch and adjust the build settings. Now the settings were ready and the frontend will be deployed to the master with every new commit. So the latest version is always hosted on AWS.
Montagsmaler-API
NestJS
The HTTP and Websocket API which forms the core of the application is built with NestJS. NestJS is a framework for building efficient and scalable Node.js server-side applications. It is heavily inspired by the architecture of the popular frontend framework Angular, while also taking lots of ideas from Spring. Like Angular it comes with built-in TypeScript support and it combines elements from Object Oriented Programming, Functional Programming and Functional Reactive Programming.
It makes heavy use of metaprogramming with TypeScript Decorators to provide an advanced modular architecture with dependency injection with the focus on separation of concerns and high testability.
NestJS provides full compatibility to popular express middlewares and libraries, but can be configured to use different HTTP Server frameworks at your desire. But it also provides a very rich ecosystem with idiomatic solutions for standard problems regarding configuration, pipes e.g. validation pipes, exception filters, authguards, websocket gateways etc.
The Game

Lobby
Before you can start the game you have to create a lobby. On creation each a UUID is assigned to each lobby, which players can use to invite their friends via an invitation link. Leaving/joining the lobby broadcasts an event to all lobby members. Initially joining the lobby returns the current state of the lobby. The lobby leader (the player who created the lobby or in the case he/she left the lobby the player who joined after and so on) has the permission to configure and start the game. You can configure a round duration between 30 to 300 seconds and up to 10 rounds. Starting the game broadcasts the LobbyConsumedEvent to all members, which contains data about the configured game so all players can join it. As a side effect it also deletes the lobby from the redis storage and it sets a timer to initialize the game loop. Lobbies get automatically cleaned up after two hours in case they are not started to prevent memory leaks.
Games
Games are driven by the game loop. The game loop emits static events based on the given configuration of the game. Consuming the lobby initializes a not started game. After a specific time is over the game starts by emitting the GameStartedEvent. The following RoundStartedEvent starts the game round. After the configured time the round is ended and the RoundOverEvent with the scores of all submitted images is emitted. Within that time frame one picture can be published by each player: An image of the picture is uploaded to an AWS S3-Bucket and then feeded into the AWS Rekognition API. Depending on the time the player needed to publish and the confidence of the expected label given by the Rekognition API a score for the image is determined. After the score is determined the ImageAddedEvent with the corresponding score and link to the uploaded image is emitted. This process repeats for the configured amount of rounds. After all rounds were played the GameOverEvent is emitted which contains the high score and links to all submitted images with the side effect of deleting the game and the saved events.
Security

Authentification
Authentication is required for playing the game. The registration requires EMail authentication.
All requests to the HTTP and Websocket API of the game are protected by validating the access token which is transmitted in form of a signed JWT. The refresh token which is used for refreshing the access token is an HTTP-Only Cookie. That makes it possible to store the access token only in memory on the client. These measures protect against common CSRF and XSS attacks.
The API has a middleware for request rate limiting and players are only able to start one game at the time so they have to wait until the previous game is finished before they can start a new one to protect against denial of service attacks.
The game itself also has more security mechanisms build-in regarding the game logic. Only lobby-leaders are allowed to start the game. The lobby-leader is the player who created the lobby, when he leaves the player who joined first becomes the next lobby-leader and so on. The players who are able to join the game are locked once the lobby is consumed, so players can not join a random game. Players can only submit their pictures within the start and the end of a round. This is ensured by a state machine. More on that in challenges.
Challenges
Distributed Gamestate
In single player games or gameservers which only run on one instance, the question where to store the gamestate does not arise. We however wanted that a player could connect to any server instance behind a load balancer and is still able to connect to any game properly. That is why the game state in the application had to be distributed. Since it is just a game and not a serious business application we do not require any specific delivery guarantees or consistency model for our distributed game state. If one in hundred games crashes due to an irrecoverable inconsistency in the game state we can live with that. What we are concerned about is performance. Latency can significantly impact the gaming experience. That is why one important aspect was low latency. The storage medium should also be able to horizontally scale out in the form of a cluster and it should support some kind of publish and subscribe mechanism which we can leverage to distribute events across the instances. With those requirements the choice fell on redis since it is an in-memory key-value store which focuses on performance and it offers a publish and subscribe mechanism. Redis also supports scaling out with Redis-Cluster. So we were settled on Redis. But there was another elephant in the room. In which way do we save the state on the redis? The game loop emits events which are distributed using build-in redis and publish and subscribe mechanism, which we extended to also save all events in order in a redis sorted set. So all the events of a game are saved in a sorted set per game. The maximum events per game can not get very large since there is a maximum amount of rounds which can be played. So having the game state itself saved in the redis and editing it with every event within a lock seems very expensive compared to just accumulating it from the events in the sorted set, which can be retrieved without any lock in a read only operation, whenever it is needed. That is why we settled on pure event sourcing for the game state. So for example whenever a player tries to submit a picture all the events of the game are retrieved from the sorted set and accumulated to the current game state using the state pattern. If the current state is RoundStarted and the player submits for this specific round and the player has not submitted for this round yet the submission is accepted and the picture is rated which leads to the following ImageAddedEvent. So the state is important for validating client events.
Race Conditions/Locking
Although event sourcing significantly reduced the amount of locks we need within the game logic there is still logic that can lead to race conditions and therefore the need of locks. For example while players are submitting a picture we need a mechanism that protects against a player submitting a picture twice which could be possible within the time frame of the AWS API calls which are used for giving a score to the picture since the ImageAddedEvent is emitted after this process was successful. This is a common race condition which can be prevented by putting a lock around the logic from retrieving the state to emitting the event. For locking we use the popular Redlock algorithm, which has its problems though which can lead to inconsistencies according to an article by Martin Kleppmann:

There is optimistic locking built into redis, but only on specific key value pairs using WATCH. This does not offer quite what we want and because as mentioned earlier unlikely inconsistencies are not the end of the world for our project we decided to stick with Redlock.
Serialization
Redis does only offer very primitive basic data types in the form of byte arrays and strings. The higher data types like the redis sorted set are just containers for those primitive data types. That means if you want to store objects in redis you need lots of serialization and deserialization which introduces new problems. One problem is that serialization, especially non-binary serialization, can be quite expensive. We ignored the expense of non-binary serialization in our app for the time being. One more problem, which was more important for us, is that the serialization for redis also introduces higher complexity for the programmer while dealing with the data since there is no (virtual) continuous chunk of memory accross the network and is unlike dealing with your data only within an operating system’s process. This results in no call-by-reference but only call-by-value, so if you introduce for example cyclic dependencies in your data objects you need some kind of special algorithm to deal with it. JavaScript has built- in JSON serialization. The problem with JSON serialization is, that it does not serialize to the actual class instance, but rather a plain JavaScript object which has the same data properties. That means it also deserializes to a plain JavaScript object and not to the class instance it once was and how should it, JavaScript is a prototype-based language and the object prototype is lost in the serialization process. We did not want to have constraints on the objects which are serialized nor annoying manual instantiation of an actual class instance from the object. That is why we created a small library which introduces a TypeScript Class Decorator @Serializable() for the classes you want to serialize and a function which deserializes and instantiates to the actual class instance. This helped to increase productivity while working with redis as an object store. Under the hood it makes use of TypeScript Decorators, ES6 Object functions and an algorithm for dealing with cyclic dependencies.


Websocket Interface
From the beginning it was clear that our application needed a websocket interface for bidirectional communication between client and server. Since NestJS provides Websocket support out of the box with socket.io server under the hood, it was the websocket server of choice. The biggest benefit of using socket.io is backwards compatibility with browsers which do not have native websocket support using a http ajax polling technique as a fallback, if no native websockets are available. In retrospect though I would choose a pure websocket API instead of socket.io since socket.io adds a bunch of overhead, the client on the frontend is pretty old fashioned and websocket support in browsers nowadays is really good. According to caniuse.com almost 98% of users use browsers which support native websockets (29.08.2020).
Nobody in our group had any experience with building a websocket API and even after building the application I am not really sure what is good and a bad practice. I tried implementing it with the events of the game in mind. I found it quite challenging and I do not think the API is particularly well designed, but it works. From doing research online it seemed like there are not a lot of guidelines yet. If anyone has good resources on that feel free to message me since I am genuinely interested. Authentication was another problem. The JWT containing the Access Token is sent as a query parameter of the websocket connection and is verified with every event, which was sent from the client. Authentication in websocket connections is still one of those big question marks in my head regarding Websocket APIs.
E2E-Testing
End-to-end tests are on top of the testing pyramid (https://martinfowler.com/articles/practical-test-pyramid.html). They are actually meant to test your entire, completely integrated system. In our case the e2e-Test of the Websocket API sets up a full Nest Application and connects to it via the node.js socket.io client in the Jest Testrunner, which then initializes a lobby with two members and goes through a whole game. The problem was that the Jest Tests have a timeout of 10 seconds, which means that a whole normal game can not be played within that time frame. To work around this, the service, which initializes the game loop, gets the value of a second in milliseconds injected in the form of a provider into the constructor. On the standard application this provider returns the constant value of 1000 milliseconds. All the time constants within the class are then calculated based on this constant. In the e2e test this provider is overwritten and the value is set to only 50 milliseconds. Using this trick a whole game can be played out in the e2e test within the time frame of 10 seconds. There were also some other sacrifices made regarding the complete integration: The AWS and Redis Providers are mocked and overwritten in the Nest Application for the e2e test.
Rekognition Service
A machine learning algorithm for object recognition in pictures requires the picture to include a background. This led to a problem in our drawing component, because the standard was that the drawing of the user was saved as PNG. This led to the drawing having a transparent background. The AWS Rekognition service identified in these pictures only “black” as an object, because the algorithm only considered the inside of the black lines of the drawing, not viewing it as a whole. To ensure that every picture has a background, the solution was to change the format from PNG to JPEG, because JPEG doesn’t support transparency. The library we used to implement a drawing canvas made it easy to change the format, but the new JPEG pictures were now all black. After some research we realized that the problem was that the previously transparent pixels were now saved as “fully black but transparent” pixels by the canvas. Resulting in the transparent pixel becoming black when turning non-opaque by the JPEG format. The solution to this problem was to manually change the background pixel to white instead of black. This change made us face another problem regarding the canvas visible to the user. The change in pixels resulted in aliasing problems or crashes in the HTML canvas. To avoid this from happening, we copied the existing content of the canvas in a new, invisible canvas, in which we applied the pixel-shift. In that way we ensured that the picture visible to the user receives no change while adding a white background to the copied picture.
Word Similarity
To ensure that the users of our game don’t always receive 0 points for their drawings if the AWS Rekognition service doesn’t identify the correct word, we had the idea to calculate the similarity of the other object names recognized by the service. To calculate the context similarity of words, we used the continuous bag of words model. The idea behind this model, is to calculate a vector representation of each word, based on the previous and following words. We decided to implement the code in python, based on the already existing machine learning libraries gensim and tensorflow. The main problem of this algorithm was its dependency on a very big dataset of text, e.g. a Wikipedia dump. The time it takes the code to load the model of a 4 to 20 GB dataset was too long for the AWS instances. Additionally, we would need an instance with a huge amount of RAM, which we couldn’t afford with the AWS student account.
As insurance that the user receives most of the time points, we hard coded similar words for every word a picture has to be drawn for.
Presentation of the Game
Sketches






Leave a Reply
You must be logged in to post a comment.