Author: Silas Krause (sk295)
Project
Reading multiple and detailed articles can become a little bit tiring. Listening to the same content, on the other hand, is more comfortable, can be done while driving, and is less straining for the eyes.
Therefore I decided to use this lecture to create a service that converts an article to an audio file using a Text-to-Speech service.
Technical Architecture
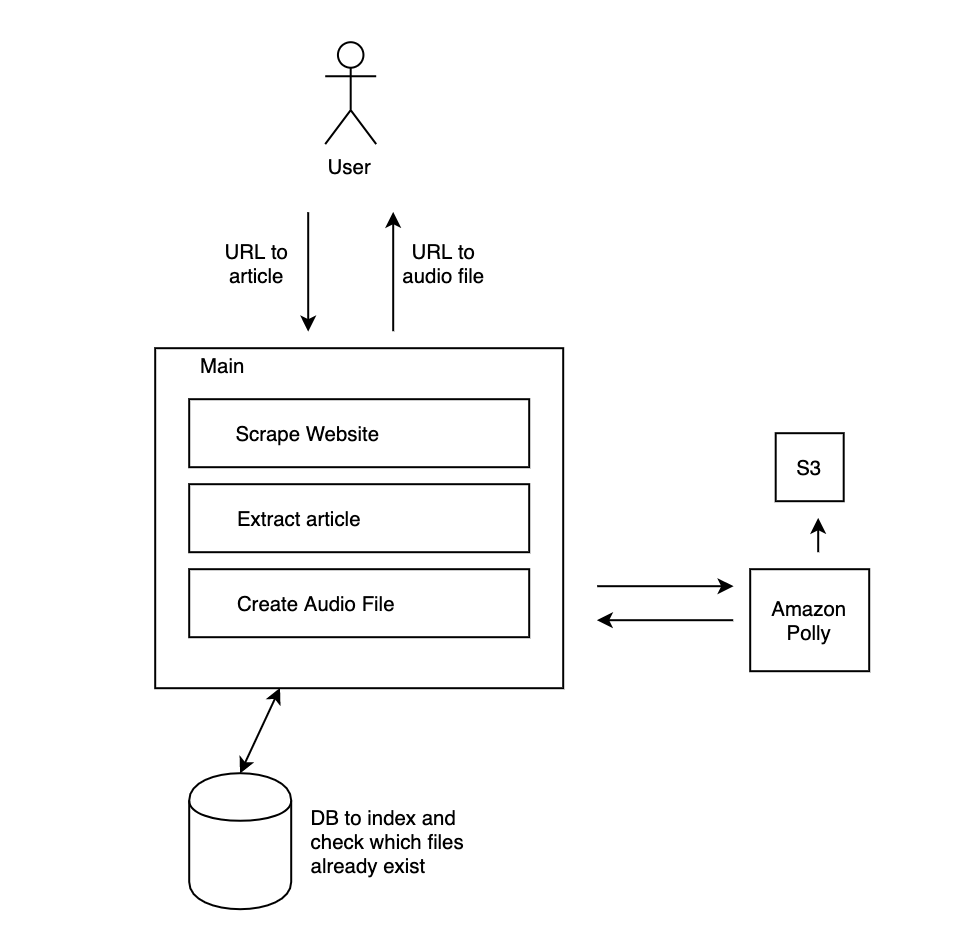
The input for the application is quite simple. The user only needs to provide a URL to the article. Then the main application fetches the contents of that URL and cuts out the unwanted markup. Then an audio file needs to be created. I chose the Amazon Polly TTS API and S3 as a file storage solution to try out Amazon Web Services.
To reduce multiple creations of the same article and load time, I intended to add a database that checks if there is already an audio file.
To interact with this application, I also needed a frontend that has an input field and dynamically renders the elements once the API endpoints send a response.
I built the app using NodeJS with the express because even though I do not have a lot of experience building backend applications, I know JavaScript well, and therefore I am familiar with node.
I decided to create three routes for my application. The index should serve the frontend. Additionally, I need two API endpoints, the first one to scrape the content from the URL, and the second one to generate the audio file.
Getting the content
Initially, I thought I could simply fetch the HTML from the source. I quickly discovered that some pages render the content on the client-side or have some kind of confirmation screen. That is why I needed a way to prerender the page. The best solution I found was Puppeteer. Puppeteer is a Headless Chrome Node.js API that runs Chromium headless and enables access to the rendered DOM. To reduce the load time, I blocked all third-party JavaScript.
Pruning the response to exclude everything but the content turned out to be a tedious task because every website structures their content differently. I ended up using unfluff, which is fine for most cases.
TTS
After the extraction, the text can be sent to the Polly API. At first, I was using the synthesizeSpeech method from the SDK. Aside from the parameters, this method accepts a callback function that can handle the response audio stream. That buffer can be stored in a file on the disk. While looking for a way to upload the audio file to S3 I found that there is a much simpler solution, which also eliminates the 3000 character limit of the synthesizeSpeech method. The Polly SDK also has an option to start a task using the method startSpeechSynthesisTask. This method excepts an additional parameter called ‘OutputS3BucketName’. After the task is completed. The output file is placed into the mentioned S3 bucket.
I really enjoyed seeing how this integration of different platform services simplifies the development.
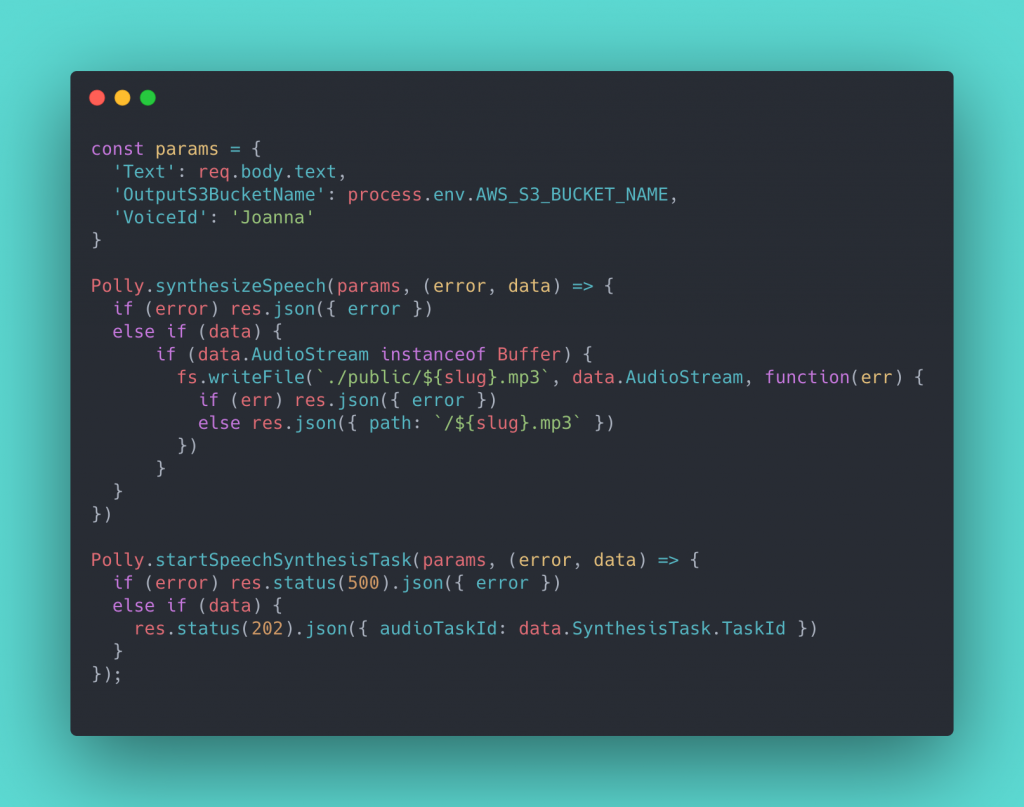
In hindsight, a real consumer application might want to synthesize small snippets and stream them subsequently. That would almost eliminate the wait time, since generating an audio file and loading it can take up a lot of time for impatient users. However, I did not choose this path because I intended to create a cache with my database.
The Response object from the startSpeechSynthesisTask method contains a link to the file, but there are two issues.
The first problem is that S3 files are not public by default. You need to complete three different steps to make them publicly available.
At first, you need to unblock all public access in the permissions. Then you need to enable public access for ‘list objects’ for everyone. After that, a pocket policy needs to be created. The policy generator luckily makes that quite easy.
Even when public access is enabled, the asset cannot be loaded immediately because the generation takes a couple of seconds. I needed to notify and update the frontend. Eventually, I solved this by starting an interval once the audio is requested. The interval checks if the task has been completed and renders an audio element after it is completed.

The authentification for AWS had to be done using the Cognito service by creating an identity pool.
Deployment
After the application was running successfully on my local machine, I had to deploy it. I chose the Platform-as-a-Service Platform on the IBM Cloud because I wanted to try out Cloud Foundry and I thought my simple express application was a good use case for this abstraction layer. I could have solved some parts of the app with a cloud function, but I do not need the control level of a virtual machine. Because Cloud Foundry requires a lot less configuration than a VM, it should be easy to deploy.
That is what I though.
I quickly ran into restrictions anyway. Except for the things I had to figure out due to my lack of knowledge of this platform, I had to spend a lot of time troubleshooting.
The biggest issue I faced was because of Puppeteer. At install time, the puppeteer package includes three versions of Chromium for Mac OS, Linux and Windows, which are all 150-250 MB large. The size exceeds the free tier limit and I had to upgrade. After that, I could not get Puppeteer running on the server, because the Ubuntu instance does not include all the debian packages that are necessary for running Chromium.
This really set me back. There is no way to install packages via sudo apt-get on PaaS and doing anything manually would eliminate the benefits of the simple deployment. I really thought I had reached the limits of Platform-as-a-Service until I discovered that you can use multiple buildpacks with cloud foundry. Even if they are not included on the IBM Cloud, by adding the Github repo.
buildpacks:
- https://github.com/cloudfoundry/apt-buildpack
- nodejs_buildpackThis allows you to add an apt.yml file to specify the packages you want to install.
Afterward, I was able to run my application.
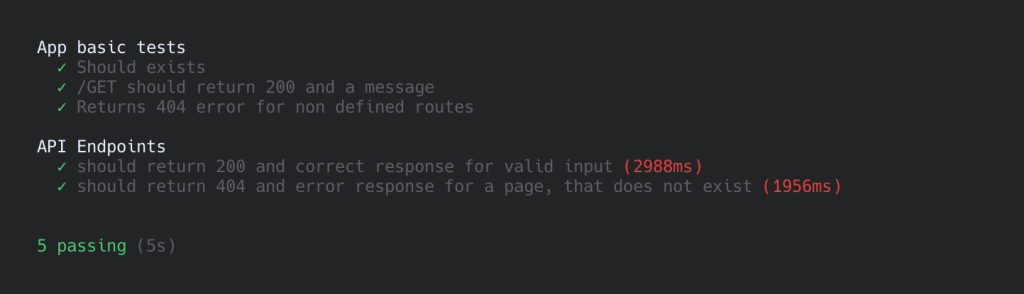
Tests
For tests, I chose to use mocha and chai. Except for a few modifications for the experimental modules I am using, this integration was straightforward. It uncovered a few error cases I was not considering before.
Conclusion
To sum up I can say that I learned a lot during this project, especially because a lot of things were completely new to me. But now I feel more confident to work with those tools and I want to continue to work on this project.
I can also recommend using cloud foundry. If you know how to deal with the restrictions and know your true environment conditions, it is pretty flexible and enjoyable to use.
Leave a Reply
You must be logged in to post a comment.