by Jan Kaupe (jk206)
Introduction
TeamSpeak³ is a Voice-over-IP application allowing users to connect to a server where they can join Voice Channels to communicate with each other.
Anyone can download and host own TS³ servers. Huge community servers have been established. However, these servers usually have way more Voice Channels than users, resulting in a decreased user experience.
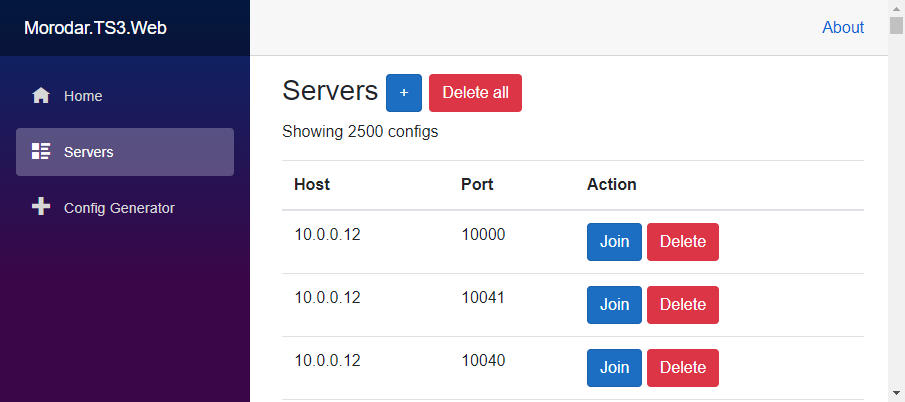
To resolve this issue, I created a proof-of-concept Bot which is able to create and delete Voice Channels on demand. This Bot can be managed via a Web Configuration Panel.
Used Technologies
The Bot is written in C# (ASP .NET Core 3.1) and uses these awesome libraries:
- jbogard / MediatR – Loose Coupling via Requests and Notifications
- dotnet / efcore – Object Database Mapper for .NET
- nikeee / TeamSpeak3QueryAPI – API wrapper for TS³ Query
- JamesNK / Newtonsoft.Json – JSON framework for .NET
- NLog – Logging platform for .NET
The Bot is being tested using the following tools/libraries:
- Docker – OS-Level virtualization which allows to create Containers
- dotnet / Docker.DotNet – Simplifies interaction with Docker Demons
- FluentValidation – Fluent validation library for .NET
- xUnit.net – Unit Testing Framework
Goals and Challenges
I’ve set three goals for myself and faced some time consuming challenges while realizing them because my expectations did not always match the reality.
I’ll give you a brief overview about those, before I explain them in detail:
- Goal: Managing multiple servers.
- Expectation: I simply use a Thread for each server, right?
- Reality: Race Conditions and Exceptions. Exceptions everywhere.
- Goal: Write real Integration Tests.
- Expectation: I can just spawn Docker Containers and use them, right?
- Reality: Container is not ready and won’t react to requests.
- Goal: Figure out the limits of the Bot.
- Expectation: Add servers until Bot crashes.
- Reality: Crashes. Fix thread-safety issues. Repeat. => Now never crashes?
Managing multiple Servers
Starting with a single Server
Before I could be able to manage multiple servers, I decided to manage a single server first.
So I started to study the ServerQuery documentation which is part of the TeamSpeak³ Server Download. It explains how to connect to the Query via Telnet and interact with the Query.
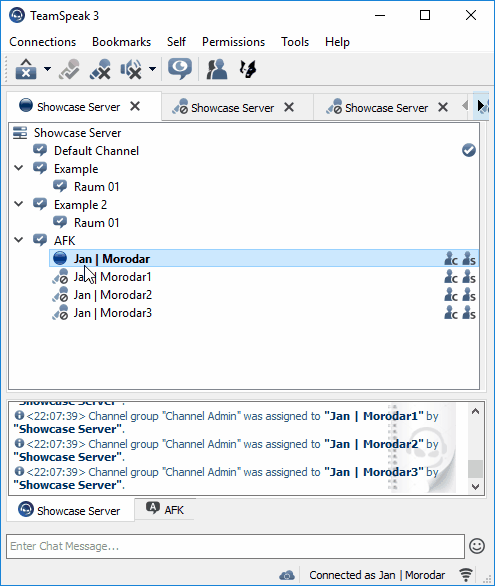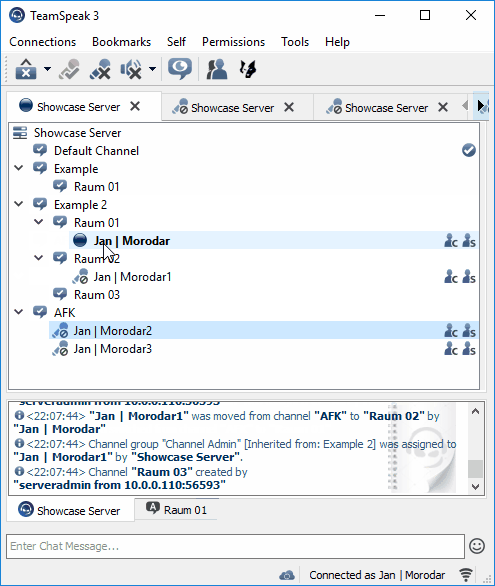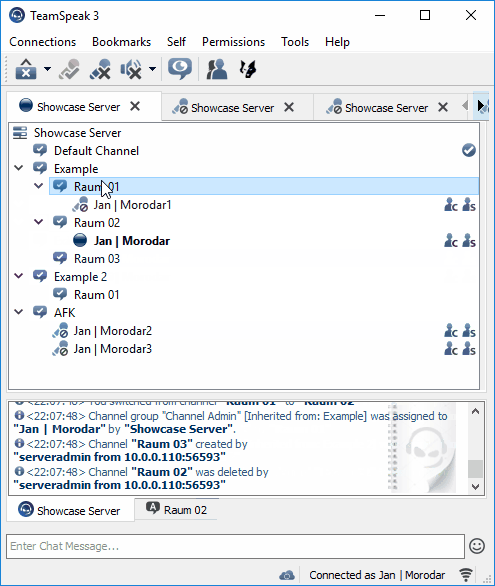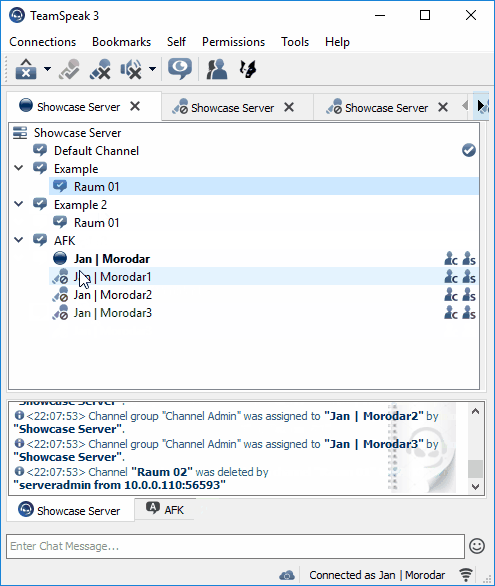
Next I tried some experiments with the library nikeee / TeamSpeak3QueryAPI. Soon, I was able to manage a single server as shown in Figure 2.
I realized that the library was not thread-safe so I had to clone and change it to prevent race conditions.
Refactoring required!
I first split my code into multiple methods and some classes. Then I tried to wrap all the code so I can start a thread for each server. Then I realized, that I just created code which was not maintainable nor testable.
Why?
Simply splitting code into methods and classes does not remove dependencies!
How to reduce Dependencies?
Onion Architecture to the Rescue!
I found this article – The Onion Architecture by Jeffrey Palermo. It explains how to establish multiple layers within your application and how to reduce dependencies by lose coupling.
So I started to split my code base into multiple projects:
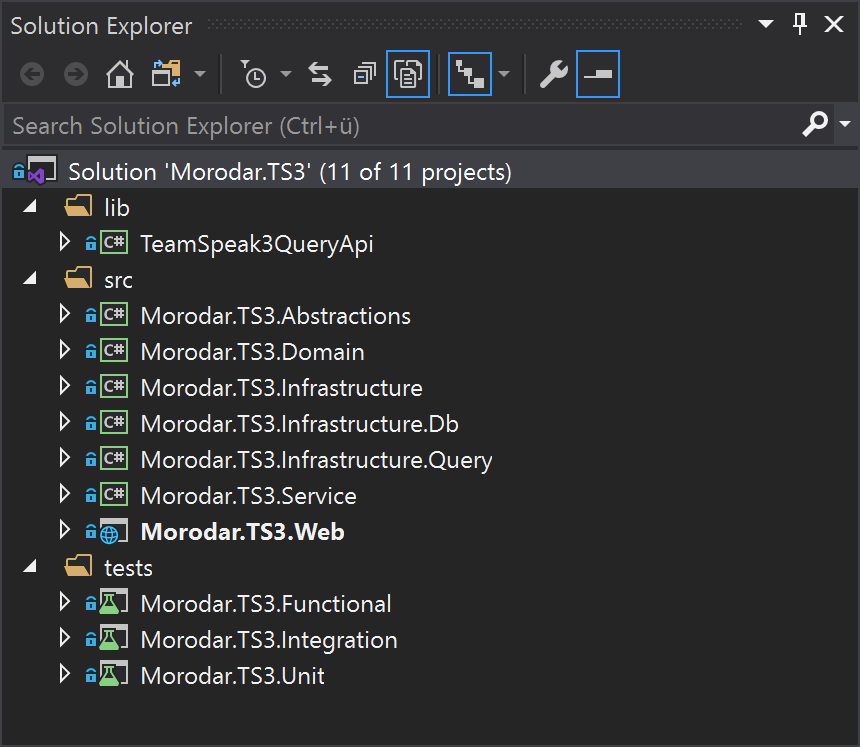
The following lower projects are allowed to reference upper projects but not vice versa:
- Domain – Contains application data classes (e.g. Channels)
- Abstractions – Contains Interfaces, Notification and Exception classes
- Service – Business logic (how to manage Channels)
- Infrastructure – How to access database (repository classes) and TS³ servers with basic operations
- Web – Frontend Code which mostly uses Service classes
After splitting the code into multiple layers I realized that this architecture helped me drastically to simplify writing Unit Tests:
The code above shows a test which stores a ServerConfig in an InMemoryDatabase using a ServerConfigRepository.
ServerConfigRepository does not know what to do with a ServerConfig but it can store it and retrieves it for you. Nothing more, nothing less.
I also realized that I could spot classes easier which need locking so that they can be thread-safe (usually Repositories were affected).
Why Threads? Use Async/Await!
Next, I figured out that the TS³ API uses infinite loops inside Tasks which can be canceled by a CancellationTokenSource. Inside the infinite loop, a TcpClient is used which listens for incoming messages by awaiting the next sent line.
Here a simplified example of the loop:
Thanks to async/await I can write asynchronous code which looks synchronous – Something I feel much more comfortable.
But awaiting an infinite Task does not make sense!
That’s right. So I don’t await it (see line 23 in the following code snippet). But I keep a reference to the object holding the CancellationTokenSource so I can stop it when I want to!
This is managed by the TsClientRepository:
The only thing left to do is to fill the repository with ServerConfigs. This is done when the Application is started:
(or a ServerConfig is added)
The Code above also demonstrates the Mediator-Pattern. It leverages louse-coupling. Some classes notice something and raise events. Other classes handle the raised events. A mediator decouples them. Thus the only dependency between them is the Mediator!
Writing real Integration Tests
When it comes to testing, we may use mocks as helpers. Mocking allows testing our Code without real connections/databases/files etc. But I didn’t want to mock a TS³ Server to test my Bot!
So I decided to use Docker and Docker.DotNet to create TS³ containers.
But I quickly realized that a lot of Code is required to create such container.
Fixtures to the rescue!
I want to write easy to create and simple tests. Using a custom fixture class which sets everything up for you is key.
In my case, the fixture has to do the following things
(after a lot of trial and error):
- Create DockerClient
- Check/Download TS³ Image (please use version tags!)
- Find available TCP Ports (so that the Bot can connect to it)
- Create the Container and mount available TCP Port
- Start the Container
- Finally, wait for the TS³ Server inside the container to spin up
Last one was tough. I created a helper class which polls the TS³ Server and expects a Welcome Message. If I don’t receive the welcome message within certain attempts, the test fails (since I then expect the setup to be wrong).
And when I receive the welcome message, the TS³ is ready to act as our test resource!
How to use it (line 5, 6 and 19):
Simple, right?
Thanks to using, the inner block is wrapped by a try/catch/finally which disposes the fixture. If the test fails, the container is guaranteed to be cleaned up and deleted!
Figure out the limits of the Bot
The Plan
Start, stop and delete hundreds of TS³ servers for each test on my machine using docker-compose.
I wrote a config generator to simplify that task. It generated the required docker-compose files and suited JSON files to later add them to my Bot via the Web Application.
When everything is setup, I started the Bot and the following should happen:
- Read ServerConfigs from database
- Create a TS3Client for each configuration
- Connect to the server and subscribe for changes
- “Manage” the ChannelsToManage which will result in creation of at least two channels in this scenario
- Keep the connection alive and wait for changes
What will be measured?
- Server configuration count ( = Connections the Bot will establish)
- Startup time (includes connecting to servers and channel creation)
- Response time after startup
(how long does it take to create additional channels?) - RAM usage after startup
Since I’ve added verbose logging, I could trace how long the Bot needs to fully spin up and how fast it reacts to changes on TS³ servers.
What problems did I encounter?
While testing, I had to change my code multiple times because of:
- Docker-Compose doesn’t like to start 500 containers at once
(split to 100 container configs and start each 100 manually) - Race conditions – Writing thread-safe code is not easy 😅
- Race conditions AGAIN – The TS³QueryAPI was not thread-safe too (Issue)
- I could “only” run 500 TS³ servers. The Bot could handle them without any issues (after previous problems have been resolved). So I decided to let the Bot connect to the server multiple times managing different channels. (Unrealistic scenario, but works for benchmarking purposes since more connections = more stress for the Bot)
- Then TS³ servers refused connections because of too many simultaneous connections at once. (only 5 query connections per IP are allowed which is not documented)
- Too much console logging and some other issues did slow down the bot drastically. After fixing them, the Bot got banned AGAIN because it was too fast. It triggered the “new query flooding system”.
How did Testing look like?
I uploaded a video demonstrating a benchmark test.
I spin up 500 TS³ Servers using docker-compose on my workstation. Then I used SSH to connect to a Debian LXC Container which will run the Bot. The LXC container had two cores running at 2GHz and 1 GB of RAM assigned.
The video illustrates how the Bot needs a lot CPU resources during startup. When switching channels, the reactions where delayed at the beginning. But the delay vanishes after the initialization procedure and the CPU is barely used.
The results
Not optimized
The table shows that the startup time takes much longer the more servers need to be managed. But when the Bot finished initialization response time seem to be pretty constant.
The channels per s shows the true limit of the servers. If user activity is higher than the channels per s, the server won’t be able to keep up!
(at least those values help to get a feeling about the possible capacity)
So I looked for reasons why the startup/managing part took so much time. Logging was the issue!
| Connections | Channels to create | Startup time | Channels per s | Response time | RAM Usage |
| 0 | 0 | 1s | – | – | 44 MB |
| 500 | 1000 | 21s | 47.6 | 125ms | 267 MB |
| 1000 | 2000 | 47s | 42.6 | 120ms | 265 MB |
| 1500 | 3000 | 68s | 44.1 | 122ms | 299 MB |
| 2000 | 4000 | 89s | 44.9 | 130ms | 309 MB |
| 2500 | 5000 | 103s | 24.3 | 127ms | 360 MB |
Somewhat optimized
After enabling lazy logging (caches, bulk writes log entries and keep the file open) and reducing console logging I achieved much better results!
Apparently, by having 5 connections to a TS³ server I trigger the “new query flooding system” too easily. The Bot has not been designed to establish multiple connections to a single server.
To prevent the flooding system, I delayed the startup by creating TS3Cliens slowly (100 at once and then wait short time before I add the next 100).
| Connections | Channels to create | Startup time | Channels per s | Response time | RAM Usage |
| 0 | 0 | 1s | – | – | 47 MB |
| 500 | 1000 | 2.5s | 400 | 166ms | 225 MB |
| 1000 | 2000 | 13s | 153.8 | 181ms | 237 MB |
| 1500 | 3000 | 9s | 333.0 | 192ms | 282 MB |
| 2000 | 4000 | 14s | 285.7 | 160ms | 319 MB |
| 2500 | 5000 | 20s | 250 | 194ms | 345 MB |
Response time seemed to increase because of lazy logging. So logging time spans seem to be inaccurate.
Due to slow TS3Client creation (which would not be required in “one connection per TS³ server”), Startup Times are higher than in reality.
Conclusion
Thanks to this project I could learn a lot about how to:
- Split the code into multiple Abstraction Layers
(But you should also not over engineer it) - Use the Mediator Pattern
(But you have to know how the communication flows works) - Use async / await and work with long running Tasks
- Find classes that need to be thread-safe faster
- Write classes thread-safe
- Write Integration Tests with Docker
Leave a Reply
You must be logged in to post a comment.