Geschrieben von Steffen Köhler und Laurin Keim.
Einleitung
Bei dem vorliegenden Block-Post handelt es sich um den Zusammenschrieb eines Studentenprojekts mit dem Motto “Last effizient abarbeiten”. In diesem wurden verschiedene Vorgehensweisen, Protokolle und in gewissem Maße auch Hardware-Architekturen erarbeitet und nachvollzogen. Dabei wurden teilweise eigene Vorgehensweisen erdacht und anschließend mit bereits bestehenden Protokollen verglichen.
Während des Projekts kamen immer wieder neue Fragestellungen auf, deren Beantwortung zu neuen Themen und Fragen geführt haben. Die Themengebiete, die schlussendlich behandelt worden sind, lassen sich in groben Zügen in folgender Grafik aufführen.
 |
I/O-Boundaries
Möchte man Last effizient abarbeiten, so gilt es zunächst die grundsätzlichen Vorgänge in einem Rechner näher zu beleuchten, um diese Vorgänge anschließend so effizient wie möglich zu optimieren.
Führt man in einem Computer eine bestimmte Software aus, so wird diese zunächst in Maschinensprache übersetzt. Laut [44] ist ein Computer somit einfach ausgedrückt Software, die der Hardware sagt, was sie tun soll. Auf einem gängigen Computer läuft natürlich nicht nur ein einzelner Thread (Ausführungsstrang in der Abarbeitung eines Computerprogramms / unabhängiger Teil eines Prozesses. Eine genauere Beschreibung folgt im Abschnitt “Thread”). Neben den Anwendungen, die vom Nutzer bewusst gestartet wurden, läuft das Betriebssystem sowie unzählige, im Hintergrund laufende Anwendungen. Dabei werden diese Threads nicht parallel abgearbeitet. Stattdessen wechselt der Prozessor sehr schnell zwischen den Anwendungen hin und her, was eine gefühlte Parallelität ermöglicht.
Sämtliche Vorgänge, die Kommunikation mit externen System benötigen, können als I/O-Operationen bezeichnet werden. [43] Als Beispiele lassen sich hierbei der Aufruf eines Web-Services, die Interaktion mit einer Datenbank oder eben auch einfach die Interaktion mit dem File-System aufführen.
I/O-Bottleneck
Ausgehend von den gegebenen Informationen könnte man davon ausgehen, dass die CPU (Central Processing Unit) der begrenzende Faktor bezüglich der Geschwindigkeit eines Rechners ist. In den vergangenen Jahrzehnten hat sich jedoch die Leistung von Prozessoren in regelmäßigen Abständen verdoppelt [40]. Das Mooresche Gesetz besagt diesbezüglich genauer, dass sich die Komplexität integrierter Schaltkreise mit minimalen Komponentenkosten regelmäßig verdoppelt, je nach Quelle alle 12, 18 oder 24 Monate.
Mit dieser rasanten Verbesserung der Prozessorleistung konnten die Komponenten, welche für den Input bzw. den Output von Daten verantwortlich sind, nicht mithalten.
Laut [35] hat sich die CPU-Performance innerhalb der Jahre 2004-2008 etwa verzehnfacht. Im gleichen Zeitraum wurde die Memory-Bandbreite am Beispiel von Intel von 4.3 GB/s auf 40 GB/s angehoben, was ebenfalls in etwa einer Verzehnfachung entspricht. Im Gegensatz dazu wurde die Geschwindigkeit des PCIe-bus (Peripheral Component Interface express, eine interne Schnittstelle für Erweiterungskarten in Computer-Systemen) von 250 MB/sec pro Leitung auf 500 MB/sec pro Leitung erhöht, was einer Verdoppelung entspricht.
Diese Zahlen verdeutlichen, dass keine der Komponenten mit der rasanten Entwicklung der CPUs mithalten kann. Anders ausgedrückt ist der Datenzugriff grundsätzlich langsamer als die Datenverarbeitung.
Unterschiedlicher Quellen zufolge ist I/O in 80-90% aller Anwendungsfälle der begrenzende Faktor. Diese Problematik ist allerdings nicht alleine auf die Hardware zurückzuführen. Das Standard-Protokoll POSIX bietet hier im Grunde keine Optimierungsmöglichkeiten, worauf im folgenden Abschnitt kurz eingegangen werden soll.
POSIX – Portable Operating System Interface
POSIX steht für Portable Operating System Interface. Wie [11] zu entnehmen ist, handelt es sich dabei um eine standardisierte Programmierschnittstelle, welche die Schnittstelle zwischen Anwendungssoftware und Betriebssystem darstellt. Es basiert auf Unix-Betriebssystemen, da es als Herstellerneutral gilt.
POSIX ermöglicht es dem Programmier, Data-Streams zu öffnen und somit Daten zu lesen und zu schreiben. Es stehen also unter anderem Systembefehle wie read, write, open und close zur Verfügung, viel mehr Möglichkeiten bietet POSIX allerdings nicht. Somit gibt es keine Möglichkeiten den entsprechenden Daten Hinweise anzuhängen, die beispielsweise auf ein sequentielles Lesen der Datei hinweisen. Ebenso wäre es denkbar Daten entsprechend zu markieren, wenn sich vorher absehen lässt, dass diese überschrieben werden könnten. Mit diesen oder ähnlichen Verfahren könnte man den Datenverkehr durchaus effizienter gestalten, es gibt allerdings kein Standardverfahren welches diese Vorgänge ermöglicht.
I/O-Problematik – Austausch des kompletten Stacks?
Die Tatsache, dass I/O grundsätzlich von der CPU-Leistung übertroffen wird, lässt die Frage aufkommen, weshalb die Situation sich nicht längst geändert hat.
Die Antwort hierauf liegt in der Komplexität das Datenpfades. Die Verbesserung einer Komponente in der Struktur wie beispielsweise des PCIe-Busses ändert an der Gesamtperformance nichts. Solange auch nur eine Komponente der Struktur den Datenfluss bremst, hat man im gesamten System nichts gewonnen.
Alle einzelnen Komponenten auszutauschen ist wiederum äußerst schwierig, da keine Firma das gesamte System baut. Eine Architektur abseits des Standards wie PCIe oder SAS zu bauen ist schlichtweg zu kostspielig.
Eine der Komponenten, welche sich vergleichsweise einfach austauschen bzw. ergänzen lässt, ist die Festplatte. Auch im Consumer-Bereich wird beim Kauf neuer Hardware großer Wert auf SSD-Festplatten als Ergänzung oder Ersatz von herkömmlichen Festplatten gelegt. Der tatsächliche Performance-Gewinn soll im folgenden Kapitel durch ein eigenes Experiment überprüft und gemessen werden.
Experiment – HDD vs. SSD
Die Idee beim folgenden Experiment ist denkbar einfach. Genutzt wurde ein Computer, in dem sowohl eine HDD als auch eine SDD-Festplatte verbaut ist. Es sollen die gleichen Daten auf beide Platten geschrieben bzw. gelesen werden. Implementiert wurde dieser Test in C++. Die Zeiten werden dabei durch den folgenden Programmcode gemessen:
 |
Einfache Text-Dateien
Es wurden zunächst einfache Text-Dateien generiert, in denen sich zufällige Zahlenwerte befinden. Diese Dateien wurden einmal auf der SSD und einmal auf der HDD-Festplatte abgelegt. Wie der folgenden Tabelle zu entnehmen ist, wurde hinsichtlich der Anzahl der Dateien sowie der beinhalteten Zufallszahlen variiert. Es ergaben sich die folgenden Messungen:
| Anzahl Dateien | Anzahl Zufallszahlen pro Datei | Zugriffszeit HDD | Zugriffszeit SSD | Verhältniswerte |
| 100 | 10.000 | 293 ms | 308 ms | 105,12% |
| 100 | 100.000 | 3405 ms | 3546 ms | 104,14% |
| 1 | 10.000.000 | 2918 ms | 3319 ms | 113,74% |
Die Zugriffszeiten der SSD waren in diesem Experiment länger, als die der HDD-Festplatte. Dies widerspricht den Recherchen und unserer Erwartungshaltung. Offensichtlich wurden beim Experiment einige Faktoren nicht berücksichtigt.
Es wurde daher vermutet, dass die entsprechenden Daten bereits in irgendeiner Form gecached worden sind. Das Experiment wurde daher einige Male wiederholt. Unter anderem wurde die Messung direkt nach dem Neustart des Rechners durchgeführt, um ein Caching möglichst auszuschließen. Das Ergebnis der Messung hat sich jedoch nicht geändert.
Nach einigen weiteren Recherchen und Gesprächen sind wir auf den sogenannten Standby-Cache von Windows aufmerksam geworden. Es handelt sich hierbei um einen Speicherbereich im RAM, den Windows mit häufig verwendeten Daten füllt. Der Standby-Cache lässt sich unter Windows einsehen, indem man im Taskmanager auf “Ressourcenmonitor” klickt. Unter dem Reiter “Arbeitsspeicher” ist dann eine grafische sowie eine tabellarische Anzeige vorhanden, die Aufschluss über die im Arbeitsspeicher befindlichen Daten geben. In der vorliegenden Abbildung befinden sich aktuelle 3499 MB im Standby-Cache.
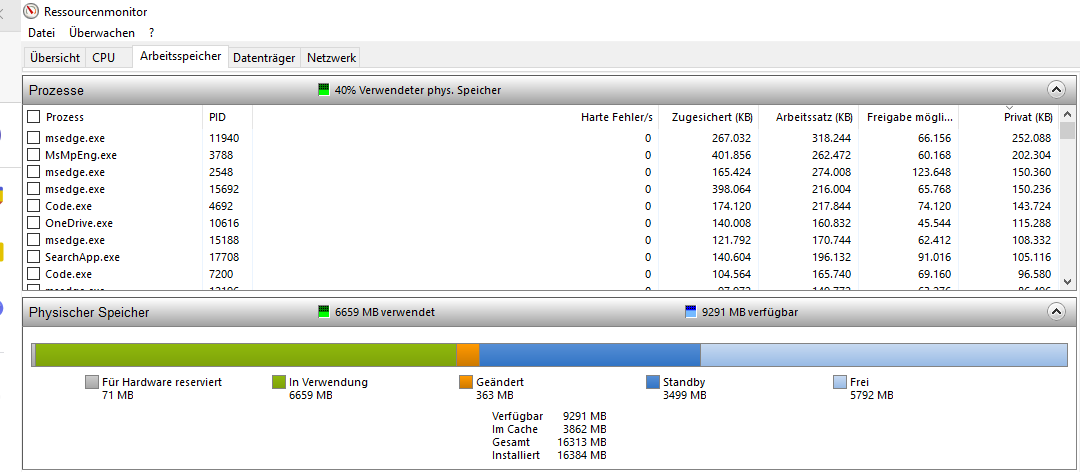 |
Standby-Cache leeren – Messvorgehen hinterfragen
Mithilfe eines Programms, welches sich unter [34] herunterladen und installieren lässt, wurde der Standby-Cache geleert.
Das Ergebnis lässt sich im Ressourcenmonitor erkennen:
 |
Nach erneuter Durchführung der Messung haben wir folgendes Ergebnis erhalten:
| Anzahl Dateien | Anzahl Zufallszahlen pro Datei | Zugriffszeit HDD | Zugriffszeit SSD | Verhältniswerte |
| 1 | 10.000.000 | 4590 ms | 4543 ms | 98,98 % |
Die Messergebnisse entsprechen erneut nicht den Erwartungen. Beide Zeiten sind in etwa gleich. Offensichtlich ist am grundsätzlichen Aufbau der Messung etwas nicht korrekt.
Um festzustellen, ob sich das Lesen der Textdatei überhaupt zur Messung eignet, wird im Folgenden die sich ergebende Bandbreite errechnet, welche die SSD aufgrund unserer Messung haben müsste. Das Ergebnis wird anschließend mit gängigen Werten verglichen, die von Herstellern angegeben werden. Bei einer korrekten Messung müssten sich die Werte stark ähneln.
Die Formel der Bandbreite lautet wie folgt:
C = D/t- Dateigröße D: 65 MB
- Zeit t: 4,5 s
- Bandbreite C: 14,4 MB/s
Die sich ergebende Bandbreite für beide Festplatten (die Zeiten waren in etwa gleich) entsprechen 14,4 MB/s. Normalerweise erreichen SSD Platten jedoch eine Bandbreite von etwa 550 MB/s. Offensichtlich war der Standby-Cache nicht das einzige Problem. Die Messung scheint grundsätzlich falsch zu sein.
Nach weiteren Recherchen und Gesprächen hat sich folgendes ergeben:
Durch das zeilenweise Lesen von Textdateien muss immer wieder das Betriebssystem nach Ressourcen gefragt werden. Dadurch entsteht ein enorm großer Overhead. Dieser lässt sich jedoch kaum exakt bestimmen, da das Betriebssystem die Ressourcen je nach Verfügbarkeit vergibt und dem Nutzer hier wenig bis gar keine Kontrolle gibt. Diesen Overhead herauszurechnen ist somit nahezu unmöglich.
Stattdessen soll der Overhead so gering wie möglich gehalten werden, indem statt Text-Dateien große Binärdateien gelesen und geschrieben werden.
Schreiben und lesen einer großen Binär-Datei
| Größe der Datei | Zeit HDD | Zeit SSD | Verhältnis | |
| Schreiben | 1 GB | 5842.89ms | 2873.9ms | 49,19% |
| Lesen | 1 GB | 5909.68ms | 2463.7ms | 41,69% |
Die Resultate der obigen Tabelle entsprechen schlussendlich unseren Erwartungen. Das Schreiben der Binärdatei auf eine SSD-Festplatte ist um etwa 50% schneller als die HDD. Beim Lesen ist ein Geschwindigkeitsgewinn von immerhin rund 40% messbar.
Dieses Ergebnis ist weit weniger lehrreich als die vorherigen Versuche, welche nicht das gewünschte Ergebnis erzielt haben. Die gescheiterten Experimente haben aufgrund verschiedener Recherchen zu einem großen Erkenntnisgewinn bezüglich der Optimierung und Speicherverwaltung von Betriebssystemen beigetragen.
CPU
Instruction Level Parallelism
Branchless Programming
Verzweigungsfreies Programmieren ist ein Programmier-Paradigma für Mikro-Optimierungen, bei welchem versucht wird, die Menge bedingter Sprung-Anweisungen zu minimieren, um einen Geschwindigkeits-Vorteil zu erlangen.
Heutige CPUs besitzen eine Instruktions-Pipeline [48], in welcher mehrere Instruktionen parallel abgearbeitet werden können. Instruktionen, welche später im Programm-Fluss vorkommen, können dabei bereits ausgeführt werden, während vorige Instruktionen noch auf Daten warten. Dies funktioniert reibungslos, wenn der zu nehmende Programm-Pfad eindeutig ist. Sollte es zwei mögliche Pfade geben, wie es bei bedingten Sprüngen der Fall ist, muss die CPU raten, welcher der beiden Pfade in die Pipeline geladen werden soll, da das Ergebnis der Bedingung noch nicht fertig berechnet ist, wenn die nächste Instruktion geladen werden soll. Sollte die CPU jedoch einen falschen Pfad in die Pipeline geladen haben, müssen alle Ergebnisse des Pfads verworfen, der Pipeline-Inhalt gelöscht und der andere Programm-Pfad geladen werden. Dieser Vorgang wird als Pipeline-Flush bezeichnet und benötigt vergleichsweise viel Zeit [48][47].
Um sogenannte Pipeline-Flushes zu vermeiden, muss beim Programmieren auf bedingte Sprünge verzichtet werden.
Beispiel
Im Folgenden ist links ein Programm-Abschnitt mit Verzweigungen und rechts entsprechend die verzweigungsfreie Version gegeben.
Hier wird sich die Eigenschaft zunutze gemacht, dass boolsche Ausdrücke beziehungsweise Werte auch Zahlen-Werte sind, auf denen arithmetische Operationen ausgeführt werden können. Hier muss jedoch beachtet werden, dass nicht alle Programmiersprachen die Möglichkeit bieten, arithmetische Operationen auf boolschen Werten auszuführen. Die Programmiersprache C unterstützt jedoch diese Möglichkeit.
| Verzweigungsbehaftet | Verzweigungsfrei |
| if (a < b) { x = a;}else{ x = b;} | x = a*(a<b) + b*(a>=b) |
Generell kann diese Variante wie folgt allgemein formuliert werden, was von [47] inspiriert wurde. c bedeutet ‘condition’, x ist ein beliebiger Wert.
| Verzweigungsbehaftet | Verzweigungsfrei |
| if (c0) { x = x0;}else if (c1){ x = x1;}…else { x = xN;} | x = x0*c0 + x1*c1 + … + xN*(!(c0&c1&…&cN-1)) |
Experiment
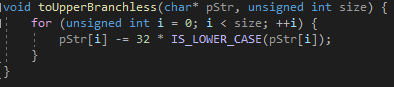
Um den Geschwindigkeitsvorteil von verzweigungsfreiem Programmieren zu messen, wurden zwei Algorithmen erstellt, welche in Tabelle 6 dargestellt sind. Einer mit Verzweigungen (links) und einer ohne (rechts). Der hier gewählte Algorithmus soll alle Kleinbuchstaben eines Strings in Großbuchstaben umwandeln.
Leider konnte hier aber kein Geschwindigkeitsvorteil gemessen werden, vielmehr war die verzweigungsfreie Variante langsamer. Dies liegt unter Anderem daran, dass der Compiler (MSVC 2019) trotz höchster Optimierungs-Stufe, die Konvertierung eines Integers zu einem Boolean nicht verzweigungsfrei generiert. Dadurch besitzt der in C geschriebene verzweigungsfreie Code im Assembly-Format trotzdem bedingte Sprünge, was aus Abbildung 5 ersichtlich wird. ‘IS_LOWER_CASE’ ist definiert als ((c) >= ‘a’ && (c) <= ‘z’).
| Verzweigungsbehaftet | Verzweigungsfrei |
 |  |
 |
Ein weiterer Versuch war, einen kleinen Code-Abschnitt in Assembly direkt zu schreiben, um die volle Kontrolle über die Assembly-Generierung zu behalten, was in Tabelle 7 dargestellt wird. Hierbei sollte der Algorithmus lediglich die Konvertierung eines Integers in einen Boolean durchführen.
Im Assembly-Code wird statt der Sprung-Anweisung eine bedingte Kopier-Instruktion ‘cmovnz’ verwendet, welche nur dann Operand 2 in Operand 1 kopiert, wenn das Zero-Flag gesetzt ist. Durch solche und ähnliche Instruktionen ist es unter Anderem möglich, in Assembly effektiv verzweigungsfrei zu programmieren.
Jedoch können hier anhand von Messungen leider auch keine deutlichen Laufzeit-Unterschiede erkannt werden. Vermutlich ist die CPU daher in der Lage, auch mehrere Programm-Pfade parallel in die Pipeline zu laden, sodass eine fehlerhafte Sprung-Vorhersage keine großen Performance-Verluste mit sich bringt.
| Verzweigungsbehaftet | Verzweigungsfrei | |
| Zeit (s) | 2.757 | 2.502 |
| Assembly |  |  |
Anwendungsgebiete
Zusätzlich zum Geschwindigkeits-Vorteil auf CPUs werden verzweigungsfreie Algorithmen auch auf GPUs verwendet, da dort mehrere Prozessor-Kerne mit einer Instruktions-Pipeline gekoppelt sind und daher dieselbe Instruktion echt parallel, aber mit verschiedenen Daten ausgeführt wird. Bei Verzweigungen wird daher nicht gesprungen, sondern jede Instruktion in der Verzweigung ausgeführt, was dazu führt, dass nicht alle Kerne immer ausgelastet sind. Mit verzweigungsfreiem Programmieren können alle Kerne alle Instruktionen sinnvoll verarbeiten [47].
Ein weiteres Anwendungsgebiet ist die Kryptographie. Hierbei spielt nicht die Geschwindigkeit die entscheidende Rolle, sondern das Laufzeit-Verhalten. Verzweigungsfreies Programmieren hat die Eigenschaft, dass nur ein Weg durch das Programm existiert. Ohne Berücksichtigung sonstiger Einflüsse besitzt das Programm dadurch eine konstante Laufzeit. Dies ist in der Kryptographie wichtig, da anhand ungleicher Laufzeiten bei verschiedenen Eingaben Hinweise zu verwendeten Algorithmen oder Schlüsseln entstehen, was die Sicherheit beeinträchtigt [47][55].
SIMD (Single Instruction Multiple Data)
SIMD aus der Flynnschen Klassifikation [7] beschreibt die Eigenschaft eines Prozessors, mehrere Daten in einer Instruktion echt parallel zu verarbeiten. Damit ist SIMD eine Möglichkeit, Parallelisierung auf Instruktions-Ebene zu realisieren. Um das echt-parallele Ausführen einer Instruktion auf mehrere Daten zu ermöglichen, besitzt der Prozessor mehrere Rechen-Einheiten. Somit können die Daten parallel durch mehrere Rechen-Einheiten geleitet werden. Zusätzlich besitzen SIMD-taugliche Prozessoren neben einem neuen Befehls-Satz auch spezielle Register, welche eine Gruppe aus gleich großer Daten enthalten können [7]. Zum Beispiel sind bei 8-Byte großen Registern folgende Konstellationen möglich:
| Anzahl Felder in Register | Daten-Größe pro Feld (Byte) |
| 1 | 8 |
| 2 | 4 |
| 4 | 2 |
| 8 | 1 |
Die erste SIMD-Implementierung von Intel war MMX [56] mit 8 Byte-Registern. Im Laufe der Zeit sind immer umfangreichere und komplexere Befehlssatz-Architekturen entstanden. Dabei sind die SIMD-Register immer größer geworden. Mit dem heute neusten Befehlssatz AVX512 [57] besitzen die SIMD-Register eine Größe von 512 Bit (64 Byte). Somit kann der Prozessor 64 1-Byte-Operationen oder 8 8-Byte-Operationen parallel ausführen, was einen extremen Performance-Gewinn ermöglicht.
Aktuelle Compiler können leider noch nicht automatisch feststellen, ob bestimmte Programm-Sequenzen mit SIMD effizienter abgearbeitet werden können. Daher müssen diese Instruktionen manuell im Programm-Code mittels intrinsischer Anweisungen oder direkt in Assembly eingefügt werden [58].
Cache und Cache-Strategien
Durch Parallelisierung und Pipelining auf Instruktions-Ebene kann die Abarbeitung von Programmen deutlich beschleunigt werden. Jedoch kann dieser Performance-Gewinn nicht genutzt werden, wenn die benötigten Daten für eine Berechnung noch nicht vorliegen. Dies ist zum Beispiel der Fall, wenn sich die Daten noch auf dem Hauptspeicher befinden und für die Berechnung zunächst geladen werden müssen.
Folgende Grafik zeigt eine stark vereinfachte Darstellung einer Hauptplatine, auf welcher die sogenannte Scott-CPU (welche zwar funktionstüchtig wäre aber nie gebaut worden ist) und der RAM (Random Access Memory) verbaut sind. [59]
 |
Die CPU und der RAM sind über den Adress-Bus sowie den Daten-Bus mit jeweils 8 Leitungen verbunden, was bedeutet dass es sich hier um ein 8-Bit-System handelt. Zusätzlich existiert der Control-Bus, mit dessen Hilfe dem RAM mitgeteilt wird, ob Daten gelesen oder geschrieben werden sollen.
Um eine genauere Vorstellung von den im RAM befindlichen Daten zu erhalten, wurde die folgende Tabelle erstellt.
| address | data |
| 01100010 | 10010110 (Instruction) |
| 10010100 | 10010100 (Number) |
| 11001110 | 10010110 (Instruction) |
| 10101100 | 10010011 (Address) |
| 00011001 | 10010110 (Instruction) |
| 10011001 | 10101101 (Address) |
| … | … |
Es lässt sich erkennen, dass der RAM Adressen und Daten beinhaltet. Mit Daten sind an dieser Stelle jedoch nicht nur Zahlenwerte gemeint (z.B. Variablen im Programm), sondern auch Instruktionen sowie weitere Adressen. Es lässt sich erahnen, dass sich im RAM ganze Programmabläufe wiederfinden lassen. Es muss an dieser Stelle betont werden, dass die CPU nur arbeiten kann, solange die eben beschriebenen Daten zu ihr gelangen.
Die Schreib- und Lesevorgänge sind in den folgenden Grafiken dargestellt. Möchte die CPU bestimmte Daten lesen, so sendet sie über den Adress-Bus eine bestimmte Adresse an den RAM (rote Leitungen) und aktiviert zudem das Enable-Wire des Control-Busses. Der RAM sendet daraufhin die an dieser Adresse befindlichen Daten über den Daten-Bus an die CPU. Ein Schreibvorgang geschieht in ähnlicher Art und Weise. Erneut sendet die CPU eine Adresse über den Adress-Bus, diesmal aktiviert sie jedoch das Set-Wire im Control-Bus. Über den Daten-Bus kann sie dann die entsprechenden Daten an den RAM senden, welcher die an dieser Adresse bereits befindlichen Daten überschreibt.
| Lese-Zugriff | Schreib-Zugriff |
 |  |
| CPU sendet Adresse über Adress-Bus an RAM und aktiviert zudem das Enable-Wire. Die Daten werden vom RAM an die CPU über den Daten-Bus zurückgeschickt. | CPU sendet Adresse über Adress-Bus an RAM und aktiviert zudem das Set-Wire. Die Daten werden von der CPU an den RAM über den Datenbus gesendet. Der RAM überschreibt die an der entsprechenden Adresse befindlichen Daten. |
Da der Hauptspeicher deutlich weiter entfernt ist, als die Register der CPU, benötigt der Strom deutlich länger, bis er zum Hauptspeicher und wieder zurück geflossen ist. Daher müsste die CPU warten, bis die Daten vom Hauptspeicher zur Verfügung stehen, was sehr ineffizient wäre.
Während CPUs nämlich üblicherweise eine Taktrate von 1 GHz – 4 GHz (Consumerbereich) aufweisen, ist der RAM mit einer Taktrate von 400 MHz – 800 MHz (bzw. 1600 MHz bei DDR3, 2133 MHz bei DDR4) deutlich langsamer getaktet [45]. Bei einer groben Überschlagsrechnung lässt sich erkennen, dass es etwa 200 CPU-Zyklen braucht, bis Daten vom RAM zur CPU gelangt sind.
Um den Weg zum Speicher und damit die Zugriffszeit zu verkürzen, wurden Cache-Speicher eingeführt. Dies sind kleinere Speicher, welche direkt auf dem CPU-Chip liegen und damit für die CPU deutlich schneller zugreifbar sind. Hierbei dient der Cache als Puffer-Speicher, um eine Teil-Kopie des Hauptspeichers zu halten [4].
Cache-Layer
Um den Speicher-Zugriff im Durchschnitt noch schneller zu machen, besitzen heutige Prozessoren meist nicht einen Cache-Speicher, sondern mehrere Cache-Schichten. Alle Caches liegen dabei nachwievor auf dem CPU-Chip, jedoch unterscheiden sich die Caches bezogen auf die Entfernung zum Prozessor und der Größe. Je höher die Cache-Schicht, desto größer, aber auch langsamer der Cache-Speicher, da mehr Transistoren verbaut sind und der Strom länger benötigt um den Speicher abzurufen. Ein Cache besitzt normalerweise nicht für einen einzelnen Wert im Speicher einen Eintrag, sondern für ganze Speicher-Blöcke, normalerweise in der Größe einer Speicher-Seite, genannt ‘Cache-Line’.
Caches lassen sich in 3 Schichten einordnen.
Es existiert der Level 1 Cache (L1 Cache), welcher nur von einer CPU genutzt wird. Dieser ist mit 2 KB – 64 KB der kleinste Cache, kann dafür aber mit der gleichen Geschwindigkeit wie die CPU arbeiten, was bedeutet dass hier Daten ohne zusätzlichen Zyklus gelesen und geschrieben werden können. [45]
Der Level 2 Cache (L2 Cache) ist mit 256 KB – 512 KB bereits etwas größer und kann, je nach Ausführung, nur von einem Kern oder aber von mehreren Kernen genutzt werden.
Zuletzt gibt es noch den Level 3 Cache (L3 Cache), welcher mit 1 MB – 8 MB am größten ist. Dieser Cache wird stets von allen Kernen geteilt, ist allerdings nicht in jedem System verbaut sondern tendenziell im höheren Preissegment vorzufinden. Benötigt die CPU bestimmte Daten aus einer Cache-Line, so wird zunächst überprüft, ob sich diese Daten im L1-Cache befinden. Wenn dem so ist, werden die Daten hiervon bezogen, ansonsten wird der L2- und L3-Cache nach demselben Muster überprüft. Befinden sich die Daten nicht in einem der Caches, so werden die Daten in diesem Fall aus dem RAM bezogen [45].
 |
Lokalitäts-Eigenschaften
Caches würden keinen Vorteil bringen, wenn die geladenen Daten nur einmal benötigt werden würden. Darüber hinaus wäre das Laden größerer Speicher-Bereiche unsinnig, wenn benachbarte Speicher-Stellen nicht benötigt werden würden.
Aus diesem Grund gibt es die Lokalitäts-Eigenschaften, welche ein typisches Muster in Bezug auf Speicher-Zugriffe gängiger Programme beschreiben. Dadurch ist gewährleistet, dass das Cachen sinnvoll ist. Es werden grundsätzlich zwei Arten von Lokalitäten unterschieden, welche aus [9] entnommen wurden:
| Lokalität-Art | Beschreibung | Beispiel |
| zeitlich | Aktuell zugegriffene Speicher-Bereiche werden in naher Zukunft mit hoher Wahrscheinlichkeit wieder benötigt. Daher eignet es sich, diese Speicher-Stellen zu puffern, um beim nochmaligen Zugriff die Daten schneller laden zu können. | Schleife |
| räumlich | Mit hoher Wahrscheinlichkeit werden Adressen in unmittelbarer Nachbarschaft zum aktuellen Zugriff angesprochen. Daher eignet es sich, direkt größere Speicher-Bereiche zu laden, um benachbarte Daten nicht auch vom Hauptspeicher laden zu müssen. | Sequenzieller Programmablauf |
k-Fach Satz-assoziativer Cache
Caches besitzen eine bestimmte Menge an Cache-Lines, welche in der Regel einem Vielfachen von Zwei entsprechen. Diese Cache-Lines können in sogenannte Sätze gruppiert werden. Das k in ‘k-Fach-Satz-Assoziativ’ steht hierbei für die Menge an Cache-Lines pro Satz. Je nachdem wie hoch das k ist, werden zwei verschiedene Sonderfälle an Abbildungen unterschieden, welche im Folgenden erläutert werden [4]. Unter ‘Abbildung’ wird bei Caches die Zugehörigkeit eines Speicher-Blocks aus dem Hauptspeicher zu einer Cache-Line verstanden.
| k | Typ | Beschreibung |
| 1 | Direkt Abgebildet | Jeder Speicher-Block ist exakt einer Cache-Line zugeordnet. |
| Anzahl Cache-Lines | Voll-Assoziativ | Kein Speicher-Block ist einer festen Cache-Line zugeordnet. |
Es kann festgehalten werden, dass bei steigendem k weniger Fehlzugriffe entstehen und damit eine höhere Performance erreicht werden kann. Je mehr Cache-Lines einem Speicher-Block zugeordnet werden können, desto variabler können diese je nach Laufzeit-Verhalten zugewiesen und länger nicht benötigte Speicher-Blöcke aussortiert werden.
Jedoch führt die höhere Flexibilität zu komplexerer Logik und damit mehr Transistor-Bedarf, was sich in Kosten, Platz- und Energiebedarf auswirkt. Zusätzlich wird mehr Speicher benötigt, da weniger Bits der Speicher-Adresse für die Indexierung und daher mehr Bits für den Cache-Line-Tag benötigt werden [4].
Hardware-Implementierung
Anhand der Speicher-Adresse, welche von der CPU angefragt wird, kann die Cache-Line ermittelt werden. Der Cache ist als Tabelle strukturiert. Im Folgenden sind die Bestandteile der Adresse angegeben:
 |
Der Offset wird bei der Selektierung der Cache-Line nicht berücksichtigt und entspricht lediglich dem Adress-Index innerhalb eines Speicher-Blocks. Alle Adressen mit gleicher Block-Adresse gehören zur selben Cache-Line. Der Satz-Index gibt die Tabellen-Zeile des Caches an, wobei jede Zeile einem Satz entspricht. Um Speicher-Blöcke zu unterscheiden, welche auf dieselbe Cache-Line abgebildet werden, wird der Tag der Speicher-Adresse in der Cache-Line abgespeichert und als Block-ID verwendet.
Jede Cache-Line besitzt zusätzliche Zustands-Bits, um zu erkennen, ob die angeforderten Daten im Cache vorhanden oder modifiziert sind [4].
Typische Bestandteile einer Cache-Line sind wie folgt:
| Spalte | Beschreibung |
| Validäts-Bit (V) | Gibt an, ob Eintrag noch gültig ist. Wenn nicht, muss der Cache-Block beim nächsten Zugriff neu geladen werden. |
| Dirty-Bit (D) | Gibt an, ob Eintrag vom eigenen Kern modifiziert wurde. Sollte der Speicher-Block ausgetauscht werden, muss dieser zurück geschrieben werden, wenn dieser modifiziert ist, um keine Daten zu verlieren. |
| Tag | Block-ID des Satzes. |
| Daten | Gepufferte Daten des Speicher-Blocks. |
Ein möglicher Cache-Zugriff kann dann wie folgt aussehen:
| Schritt | Beschreibung |
| 1 | Satz anhand von Index-Bits finden. |
| 2 | Gefundenen Satz anhand von Tag-Bits durchsuchen. Wenn Cache-Block nicht gefunden wurde, gibt es einen Fehlzugriff. |
| 3 | Block-Gültigkeit anhand von Validäts-Bit überprüfen. Wenn Block nicht valide, gibt es einen Fehlzugriff. |
| 4 | Ansonsten kann der Speicher direkt aus dem Cache geladen werden. |
Bei einem Fehlzugriff muss der Speicher-Block vom Hauptspeicher geladen werden und anhand von Ersetzungs-Strategien im Cache gespeichert und die angeforderten Daten an den Prozessor weitergeleitet werden [4].
Cache-Ersetzungs-Strategien
Sollte ein Satz mehrere Cache-Lines enthalten, können die Speicher-Blöcke freier auf die entsprechenden Cache-Lines zugewiesen werden. Wenn ein noch nicht gepufferter Speicher-Block geladen werden soll, und keine freien Cache-Lines in einem Satz mehr zur Verfügung stehen, muss entschieden werden, welche der Cache-Lines ersetzt werden soll. Hierfür existieren verschiedene Ersetzungs-Strategien [4], welche jeweils unterschiedliche Prioritäten besitzen. Ersetzungs-Strategien sollten anhand ihrer Priorität sortiert und angewendet werden, um bestmögliche Performance zu erlangen. Im Folgenden ist eine Beispiel-Priorisierung gegeben.
| Priorität | Beschreibung |
| 1 | Invalide Cache-Lines löschen |
| 2 | Nicht modifizierte Cache-Lines ersetzen, da das Zurückschreiben viel Zeit kostet. |
| 3 | LRU (Least Recently Used): Eintrag, welcher am Längsten nicht mehr verwendet wurde, kann ersetzt werden. Alternativ können auch zufällige Einträge ersetzt werden, was auch gute Ergebnisse bringt, aber deutlich weniger Transistoren benötigt. |
Parallelisierung
Parallelisierung wird dadurch erreicht, dass bestimmte Funktions-Einheiten dupliziert werden. Hierbei ist die Definition, was Funktionseinheiten sind, je nach Anwendungsgebiet und Abstraktions-Ebene unterschiedlich.
Im Bereich der Rechner-Architektur wird Parallelisierung zum Beispiel durch das Duplizieren der Prozessoren erreicht.
Auf Befehlssatz-Ebene werden Rechenwerke dupliziert, um mehrere Daten parallel bearbeiten zu können, wie im Kapitel ‘SIMD’ bereits erwähnt wurde.
Im Folgenden werden zwei verschiedene Multi-Core-Architekturen beschrieben.
Symmetric Multiprocessing (SMP)
Symmetrische Multiprozessor-Systeme kennzeichnen sich dadurch, dass die Kommunikation zwischen den Kernen sowie die Datenübertragung über einen zentralen Bus läuft. Dadurch können immer alle Kerne automatisch benachrichtigt werden, da jede Nachricht gebroadcastet wird.
SMP wird normalerweise nur bei kleineren Systemen mit bis zu circa 8 Kernen realisiert, da die Kommunikation über einen Bus läuft und daher bei steigender Teilnehmer-Anzahl die Latenz der Datenübertragung als auch die Bus-Auslastung immer größer wird.
Mögliche Lösungs-Ansätze für eine geringere Bus-Auslastung wären, mehrere Busse für die Kommunikation zu verwenden, was aber die Cache-Controller-Logik komplexer macht.
Aufgrund dessen sind SMP-Systeme nicht gut als skalierende Multiprozessor-Systeme geeignet [29].
Die folgende Abbildung soll ein SMP-System veranschaulichen.
 |
Cache-Kohärenz
Bei Multi-Prozessor-Systemen, wie sie in heutigen PC’s meistens verbaut sind, besitzt jeder CPU-Kern einen oder mehrere eigene private Caches. Solange jeder Kern einen anderen Prozess abarbeitet und dadurch keine Kommunikation erforderlich ist, funktioniert diese Art der Parallelisierung einwandfrei. Dies ist zum Beispiel dann der Fall, wenn einzelne voneinander unabhängige Prozesse parallel ausgeführt werden sollen. Threads innerhalb eines Prozesses müssen aber in der Regel synchronisiert werden, da hier Aufgaben auf verschiedene Threads verteilt und Endergebnisse wieder zusammengeführt werden müssen, was das Arbeiten auf dem selben Adressraum und das Abstimmen der Threads erfordert. Bearbeiten zwei Kerne denselben Speicher-Block, so müssen deren Caches aktualisiert werden, um nicht auf veralteten Daten zu arbeiten. Diese Problematik wird Cache-Kohärenz genannt und beschäftigt sich mit der Synchronisation der privaten Speicher der Kerne [5].
Mit Hilfe von Cache-Kohärenz-Protokollen ist es möglich, Cache-kohärente Systeme zu implementieren. Jedoch ist hierbei nur gewährleistet, dass die aktuellste Version des angeforderten Speicher-Blocks, welche in einem der Caches oder im RAM vorliegt, zurückgegeben wird. Dies bezieht sich aber ausschließlich auf Cache-Speicher, wie der Name bereits andeutet [5]. Register-Speicher, welche sich direkt im Prozessor-Kern befinden, sind davon ausgenommen. Dies ist auch richtig so, da die Register-Inhalte selbst nur temporäre Zustände wie Zwischen-Ergebnisse bestimmter Operationen enthalten. Zudem können die Prozessor-Kerne jeweils an unterschiedlichen Instruktionen beziehungsweise Programm-Pfaden arbeiten, sodass die Inhalte der Register von Kern zu Kern durchaus unterschiedliche Werte besitzen können, dürfen und auch müssen, um Parallelisierung auf Kern-Ebene zu ermöglichen.
Bus-Snooping
Hierbei handelt es sich um eine Möglichkeit, wie Cache-Kohärenz in symmetrischen Multiprozessor-Systemen umgesetzt werden kann. Jeder private Cache eines Kerns besitzt einen Cache-Controller, welcher am Bus lauscht und entsprechende Nachrichten anderer Kerne empfängt, verarbeitet und eventuell eigene Nachrichten auf den Bus gibt [17].
Abbildung 9 veranschaulicht dieses Verfahren anhand eines CPU-Kerns.
 |
Es werden zwei verschiedene Arten von Snooping-Protokollen unterschieden, welche sich im Verhalten bei Schreib-Aktionen unterscheiden.
Write-Invalidate-Protokolle invalidieren die Cache-Lines anderer Kerne. Dieser Invalidierungs-Vorgang muss nur einmal getätigt werden. Daher wird hier deutlich weniger Bus-Verkehr erzeugt [17]. Beispiel-Implementierungen sind MSI [24], MESI [22], MOSI [23] und MOESI [46], welche in den folgenden Abschnitten genauer betrachtet werden.
Write-Update-Protokolle aktualisieren den Datenbestand der anderen Cache-Lines jedes Mal bei einem Schreib-Zugriff. Daher wird hier deutlich mehr Bus-Last erzeugt. Ein Vorteil gegenüber dem Write-Invalidate-Protokollen ist jedoch, dass weniger Cache-Misses auftreten, da die Caches nicht invalidiert werden, was eine geringere Latenz bei Schreib/Lese-Zugriffen ermöglicht [17].
MSI / MESI / MOSI / MOESI
MESI, MOSI sowie MOESI sind Erweiterungen des Basis-Protokolls MSI. Jeder Cache eines Kerns ist mit einem Cache-Controller ausgestattet, welcher eine Verbindung zum privaten Cache sowie zum Daten-Bus der CPU besitzt. Somit registriert der Controller Aktionen des eigenen Kerns, als auch Aktionen anderer Kerne und kann dadurch entsprechend reagieren. Der Controller besitzt für jede Cache-Line einen bestimmten Zustand. Die Namen der Protokolle bestehen hierbei immer aus den Anfangsbuchstaben der entsprechenden Zustände. Folgende Zustände sind möglich und wurden aus [24],[22],[23],[46] entnommen.
| Block-Zustand | Beschreibung |
| Invalid | Speicher-Block ist invalide und muss neu geladen werden. |
| Shared | Speicher-Block nicht manipuliert und valide. |
| Modified | Speicher-Block manipuliert und valide. |
| Exclusive | Wie Shared, aber es existiert nur eine Kopie. Anhand dieses Zustands wird die Bus-Auslastung reduziert, da bei Schreib-Zugriffen keine Invalidierungs-Nachricht gesendet werden muss, da nur der eigene Cache eine Kopie des Speicher-Blocks hält. |
| Owned | Sollte ein anderer Kern den Speicher-Block anfragen, so kann der Cache dem anfragenden Cache seinen Cache-Line-Inhalt zusenden. Damit wird der Zugriff auf den Hauptspeicher verhindert, welcher deutlich länger dauern würde. |
Der Memory-Controller trifft nun anhand einer Eingabe, welche vom Kern oder vom Daten-Bus kommt, und des Zustands des adressierten Speicher-Blocks eine Entscheidung, tätigt eventuell eine entsprechende Aktion und wechselt den Zustand in einen entsprechenden Folgezustand.
Die Verhaltensweisen des MSI Protokolls sind in zwei Zustandsgraphen abgebildet [42].
Die folgende Grafik zeigt die Aktion der CPU (blau) sowie die Reaktion des eigenen Cache-Controllers (rot). Zudem wird dargestellt, in welchen Zustand der Cache-Controller den entsprechenden Speicher-Block nach Ausführung sein Aktion überführt.
 |
Um das MSI-Protokoll zu vervollständigen, bedarf es jedoch noch einer zweiten Grafik, die die Reaktion des Busses auf die Aktionen anderer CPUs darstellt. In diesem Fall werden also die Aktionen einer fremden CPU (blau) sowie die Reaktion des eigenen Cache-Controllers (rot) aufgezeigt. Zusätzlich lässt sich erkennen, in welchen Zustand der eigene Cache-Block nach der Aktion des Cache-Controllers überführt wird.
 |
Um auch die Erweiterungen des MSI-Protokolls darzustellen, wurde eine Zustands-Tabelle erstellt, welche in Tabelle 20 abgebildet ist.
Nachrichten-Arten
Bus-Nachrichten können sowohl Eingabe als auch Ausgabe des Cache-Controllers sein. Lese/Schreib-Aktionen der CPU sind ausschließlich Eingaben, da diese nur von einem Prozessor initiiert werden können.
| Nachrichten-Art | Leitung | Beschreibung |
| R | CPU | CPU will Block lesen. |
| W | CPU | CPU will auf Block schreiben. |
| Invalidate | Bus | Cache-Block muss invalidiert werden. |
| Read-Miss | Bus | Kern des anfragenden Cache will Speicher-Block lesen. |
| Write-Miss | Bus | Kern des anfragenden Cache will auf Speicher-Block schreiben. |
| Flush | Bus | Sende eigenen Block-Inhalt an anfragenden Cache. |
Übertragungs-Format
Das Übertragungsformat, mit welchem Memory-Controller-bezogene Daten über den Bus ausgetauscht werden, ist in der Regel gleich und könnte nach eigenen Überlegungen wie folgt aussehen.
| Nachricht-Bestandteil | Beschreibung |
| Aktion | Zum Beispiel Read-Miss oder Write-Miss. |
| Block-Adresse | Da der Zustand abhängig vom jeweiligen Speicher-Block ist. |
| Zustand | Eingabe | Ausgabe | Folge-Zustand | Beschreibung |
| S | W | Invalidate | M | – invalidiere alle anderen möglichen Kopien des Blocks |
| S | R | – | S | |
| S | Invalidate | – | I | |
| S | Write-Miss | – | I | |
| S | Read-Miss | – | S | – anderer Kern erhält Block von RAM |
| I | R | Read-Miss | S, E | – erhalte Block von RAM: E – erhalte Block von Cache: S – muss von anderen Cache-Controllern mitgeteilt werden |
| I | W | Write-Miss | M | – Speicher-Block aus anderem Cache oder RAM nachladen |
| I | Invalidate | – | I | |
| I | Write-Miss | – | I | |
| I | Read-Miss | – | I | |
| M | R | – | M | |
| M | W | – | M | |
| M | Invalidate | – | – | – nicht möglich, alle anderen Kerne sind invalidiert, wenn Zustand=M |
| M | Write-Miss | Flush | I | |
| M | Read-Miss | Flush | S, O | – eigenen Block in anfragenden Cache (und RAM, wenn MSI) kopieren – RAM-Zugriff durch anfragenden Kern verhindern |
| E | R | – | E | |
| E | W | – | M | |
| E | Invalidate | – | – | – nicht möglich |
| E | Read-Miss | – | S | – anderer Kern fragt selben Block an, daher existieren jetzt >1 Kopien |
| E | Write-Miss | Flush | I | |
| O | R | – | O | |
| O | W | Invalidate | M | |
| O | Invalidate | – | I | |
| O | Read-Miss | Flush | O | – RAM-Zugriff verhindern – Cache-Block zu anfragendem Kern kopieren |
| O | Write-Miss | Flush | I |
Distributed Shared Memory (DSM)
DSM-Systeme sind im Gegensatz zu symmetrischen Multiprozessor-Systemen eine skalierbare Lösung für Multiprozessor-Systeme. Hierbei ist der Cache-Speicher und die dazugehörigen Zustands-Informationen auf alle Teilnehmer aufgeteilt und alle Kerne können sich über ein Netzwerk direkt kontaktieren. Zusätzlich existiert pro Knoten für jeden Speicher-Block ein Verzeichnis (Directory), welches unter Anderem Informationen darüber enthält, welcher Teilnehmer eine Kopie des Speicher-Blocks hält.
Dies ist jedoch deutlich langsamer als ein SMP-System, da oft über mehrere Knoten hinweg kommuniziert wird. Da nun nicht mehr nur ein Übertragungs-Medium existiert und nicht mehr auf einen gemeinsamen Speicher zugegriffen werden muss, ist die Latenz und Auslastung nicht mehr abhängig von der Anzahl der Teilnehmer [20].
Ein Beispiel-Protokoll zur Wahrung der Cache-Kohärenz in DSM-Systemen ist das Directory-Protokoll [19], auf das im weiteren Verlauf dieses Artikels aber nicht weiter eingegangen wird.
DSM in Verbindung mit dem Directory-Protocol ist in folgender Abbildung für einen Teilnehmer visualisiert.
 |
Synchronisation
Sowohl bei Uni-Core als auch bei Multi-Core-Systemen können Programm-Stränge mit Hilfe verschiedener Threads gefühlt-parallel oder echt-parallel abgearbeitet werden. Daher wird in diesem Kapitel sowohl auf Single- als auch auf Multi-Core-Systeme Bezug genommen.
Cache-Kohärenz ermöglicht es, dass Caches synchronisiert werden. Jedoch ist die Progamm-Abarbeitung dadurch noch nicht Thread-sicher, da Caches nur beim Beschreiben aktualisiert werden und Instruktionen nicht-atomar ausgeführt werden.
Atomare Instruktion
Eine atomare Instruktion ist eine Instruktion, welche nicht von Threads des selben Kerns unterbrochen und nur von einem Kern gleichzeitig ausgeführt werden kann. Manche Instruktionen sind bereits an sich schon atomar, wie zum Beispiel Load/- und Store-Instruktionen (mov). Andere Instruktionen bestehen aus mehreren Teil-Schritten, wodurch die gesamte Instruktion zwischen den Teil-Schritten von anderen Threads unterbrochen werden kann. Unterbrechbare Instruktionen sind meist sogenannte Read-Modify-Write-(RMW)-Instruktionen [12]. Dies sind Instruktionen, welche bestimmte Daten vom Hauptspeicher oder Cache laden, diese manipulieren und anschließend wieder zurück schreiben. Man kann hier bereits erahnen, dass solche Instruktionen mindestens aus drei Teil-Schritten bestehen, wobei jeder Teilschritt für sich atomar ist [61].
Ein Beispiel einer unterbrechbaren Instruktion ist das Inkrementieren eines Wertes im Cache. In der folgenden Tabelle ist links die Anweisung in einer höheren Programmiersprache, in der Mitte die entsprechende Instruktion und rechts die Teilschritte angegeben.
| Anweisung | Instruktion (MASM) | Teil-Schritte (MASM) |
| ++x; | inc dword ptr [rcx] | mov edx,dword ptr [rcx]inc edxmov dword ptr [rcx],edx |
Wollen nun mehrere Threads gleichzeitig die Variable x inkrementieren, so können mehrere Threads denselben uninkrementierten Speicher-Wert aus dem Cache auslesen, ehe der aktualisierte Wert von einem der Threads wieder zurück in den Cache geschrieben werden kann. Dies ist eine klassische Race-Condition und tritt auf, wenn mehrere Threads versuchen, den selben Speicher-Bereich zu manipulieren. In der folgenden Tabelle ist dieser Ablauf nochmal genauer veranschaulicht.
| Instruktion | Thread1 | Thread2 | Cache |
| – | 0 | 0 | 7 |
| T1: mov edx,dword ptr [ecx] | 7 | 0 | 7 |
| T1: inc edx | 8 | 0 | 7 |
| T2: mov edx,dword ptr [ecx] | 8 | 7 | 7 |
| T2: inc edx | 8 | 8 | 7 |
| T2: mov dword ptr [ecx],edx | 8 | 8 | 8 |
| T1: mov dword ptr [ecx],edx | 8 | 8 | 8 |
Um solche Race-Conditions zu verhindern, können manche RMW-Instruktionen atomar ausgeführt werden. Dafür muss in Assembly ein ‘lock’-Prefix [38] vor die entsprechende Instruktion gesetzt werden. Im Falle der Inkrementations-Operation würde die Instruktion wie folgt aussehen: ‘lock inc dword ptr [ecx]’. Eine mögliche Implementierung einer solchen atomaren RMW-Instruktion in Hardware kann mit Hilfe eines Memory-Controllers realisiert werden. Die Daten werden in dem Fall erst gar nicht vom CPU-Kern geladen, sondern die Manipulation der Daten dem Memory-Controller überlassen. So findet die Instruktions Abarbeitung an einem zentralen Ort statt, um zu gewährleisten, dass die entsprechende Instruktion nicht gleichzeitig ausgeführt wird. Der Memory-Controller erhält vom CPU-Kern eine Anfrage zur Abarbeitung der entsprechenden atomaren Instruktion mit den dafür benötigten Parametern. Wird dieselbe Instruktion bereits für einen anderen Kern ausgeführt, so wird dem anfragenden Kern über einen BUSY-Interrupt mitgeteilt, dass die Anfrage gerade nicht verarbeitet werden kann und später nochmal eine Anfrage gestellt werden soll. Die Abarbeitung einer solchen Instruktion geschieht aber in der Regel so schnell, dass der Kern mit dem nächsten Versuch kaum warten muss. Ist der Memory-Controller mit der Bearbeitung der Anfrage fertig, wird das entsprechende Flag im internen Speicher gelöscht, sodass darauffolgende Anfragen anderer Kerne zur Abarbeitung atomarer Instruktionen wieder berücksichtigt werden können [31].
Atomare Instruktionen sind die kleinste Synchronisations-Primitive und können als solche alleinstehend zum Manipulieren einzelner Daten verwendet werden. Jedoch muss beachtet werden, dass das Ausführen atomarer Instruktionen verglichen an der nicht-atomaren Version der jeweiligen instruktion, deutlich länger benötigt, da nicht nur mit dem jeweiligen privaten Cache, sondern mit dem Memory-Controller kommuniziert werden muss, welcher selbst etwas Zeit zur Abarbeitung benötigt. Zusätzlich werden durch das Arbeiten auf dem geteilten Speicher jedes Mal die Caches invalidiert. Daher sollte das Ausführen atomarer Instruktionen so gut wie möglich minimiert werden.
Locking, Hierarchisches Locking
Sollten komplizierte Operationen mit größeren Datensätzen atomar ausgeführt oder die Anzahl atomarer Instruktionen reduziert werden, eignet es sich, einen größeren Programm-Abschnitt zu sperren, welcher dann nur von einem Thread gleichzeitig durchlaufen werden kann. Solche Programm-Abschnitte werden auch kritische Sektionen [62] genannt. Die Idee ist dabei, dass die Threads nur am Anfang der kritischen Sektion synchronisiert werden müssen, um abzuklären, welcher der Threads die kritische Sektion ausführen darf. Innerhalb der kritischen Sektion darf der einzelne Thread die kritischen Operationen nicht-atomar ausführen. Vor Verlassen der kritischen Sektion muss der Thread die Sektion wieder frei geben, sodass die anderen Threads auch die Möglichkeit haben, diese auszuführen. Dies bringt einen enormen Geschwindigkeits-Vorteil gegenüber dem Bestücken der kritischen Sektion mit atomaren Instruktionen [63].
Das Gruppieren logischer Programm-Bereiche, um diese gemeinsam zu locken und somit weniger Locking-Overhead zu erhalten, wird auch als hierarchisches Locking bezeichnet [63].
Locking-Implementierung
Beim Locking existieren generell zwei Aktionen. Die erste Aktion ist das Locken der kritischen Sektion. Hierbei muss der Thread testen, ob ein Flag-Bit, welches im geteilten Speicher liegt, gesetzt ist. Wenn es gesetzt ist bedeutet dies, dass sich bereits ein anderer Thread in der kritischen Sektion befindet und daher diese für den aktuellen Thread gesperrt ist. Sollte das Lock-Flag jedoch nicht gesetzt sein, so setzt der aktuelle Thread das Lock-Flag und beginnt mit der Ausführung der kritischen Sektion [63].
Da das Lesen, Vergleichen und gegebenenfalls Manipulieren des Lock-Flags atomar ablaufen muss, existieren entsprechende RMW-Instruktionen, welche atomar ausgeführt werden können. Eine davon ist die Test-and-Set-Instruktion [31]. Hierbei wird der alte Flag-Wert zurück gegeben und das Lock-Flag auf 1 gesetzt. Der eigentliche Vergleich kann dann nicht-atomar ausgeführt werden, da gewährleistet ist, dass nur ein Thread eine 0 lesen kann, sollte die kritische Sektion nicht gesperrt sein.
Ist die kritische Sektion gesperrt so existieren verschiedene Möglichkeiten, was der Thread tun soll.
Im einfachsten Fall versucht der Thread die kritische Sektion so lange zu locken, bis er erfolgreich war. Diese Art von Lock wird auch als Spin-Lock bezeichnet [65]. Spin-Locks sind sinnvoll, wenn ein Kontext-Wechsel mehr Zeit in Anspruch nehmen würde, als auf das Freiwerden der kritischen Sektion zu warten.
Stehen dem aktuellen Thread auch noch andere Aufgaben zur Abarbeitung zur Verfügung, und hängen diese nicht unmittelbar von der kritischen Sektion ab, so kann der Thread bei misslungenem Locking-Versuch zunächst die anderen Aufgaben abarbeiten. Somit kann der CPU-Kern optimal ausgelastet werden [10].
Sollte es keine anderen Aufgaben für den aktuellen Thread geben und die kritische Sektion länger blockiert sein, bietet es sich an, den Thread zu pausieren und einen Kontext-Wechsel einzuleiten, um einen anderen Thread abzuarbeiten und so die CPU möglichst gut auszulasten. Der pausierte Thread wird vom Betriebssystem wieder in die Warte-Schlange des Schedulers eingehängt, wenn die kritische Sektion wieder frei gegeben wird [63].
Die zweite Aktion, welche beim Locking notwendig ist, ist das Freigeben der kritischen Sektion. Hierbei muss lediglich das Lock-Flag wieder auf 0 gesetzt werden, was mit einer einfachen Store-Instruktion wie ‘mov’ implementiert werden kann, da diese bereits atomar ist [64].
Lock-Experiment
Mit Hilfe eines kleinen Experiments soll bestätigt werden, dass das Locken größerer Programm-Bereiche performanter ist, als das Verwenden entsprechender atomarer Instruktionen. Zusätzlich soll am Beispiel des Lockings gezeigt werden, dass alle höheren Synchronisations-Objekte höherer Programmiersprachen wie Mutexes, auf atomaren RMW-Instruktionen aufbauen.
Es sollen 8 Threads gestartet werden, von denen jeder eine geteilte Variable 300_000_000 Mal inkrementiert. Beim Locking wird die Variable entsprechend in der kritischen Sektion 300_000_000 Mal Inkrementiert, bevor der Thread die Sektion wieder frei gibt. Für die Implementierung des Lockings wurde die Bit-Test-and-Set-Instruktion (BTS) [36] des IA32-Befehlssatz verwendet, da diese die IA32-Variante der Test-and-Set-Instruktion ist. Die BTS-Instruktion setzt dabei ein einzelnes Bit auf 1 und legt den alten Bit-Wert im Carry-Flag ab. Mit Hilfe des zweiten Parameters kann der Bit-Offset des entsprechenden Bits angegeben werden.
Zu Beachten ist hier, dass das Locking nicht 8-Mal schneller als die nicht-gelockte Variante ist, sondern nur ca. doppelt so schnell. Dies ist darauf zurück zu führen, dass sich die Threads auch bei nicht-atomaren Instruktionen die Cache-Lines invalidieren, da die Cache-Kohärenz-Protokolle nachwievor aktiv sind, und somit eine größere Bus-Auslastung hervorgerufen wird, was die Gesamt-Performance reduziert.
Da die atomare BTS-Instruktion immer in den Speicher schreibt und damit die Cache-Lines anderer Kerne invalidiert werden, kann es bei einem Spin-Lock passieren, das sich die Kerne ihre Cache-Lines gegenseitig ständig invalidieren, während sie auf das Freiwerden der kritischen Sektion warten. Dadurch leidet die Gesamt-Performance des Systems, da der Daten-Bus unnötig ausgelastet wird und dadurch andere Benachrichtigungen länger benötigen um verarbeitet zu werden [30].
Um dies zu verhindern, gibt es die sogenannte ’Test & Test-and-Set’-Methodik [30]. Hierbei wird mit einer normalen Lade-Operation das Lock-Flag geladen und anschließend überprüft. Sollte das Flag gesetzt sein, wird das Flag nochmal geladen und überprüft, ob sich der Wert jetzt geändert hat. Sollte das Flag nicht gesetzt sein, so wird versucht die kritische Sektion mittels der Test-and-Set-Operation zu sperren.
Im Experiment wurde diese Methodik auch implementiert und sowohl die Variante mit, als auch die Variante ohne Test gemessen. Durch den zusätzlichen Test konnte ein Performance-Gewinn von ca. ⅓ gemessen werden. Zusätzlich zur Lock-Implementierung mittels Test-and-Set wurde die Lock-Funktionalität noch mit Hilfe der Compare-and-Swap-Operation [66] implementiert, um zu zeigen, dass verschiedene RMW-Instruktionen für die Lock-Implementierung herangezogen werden können. Zeitlich gibt es zwischen den beiden Implementierungen aber keine nennenswerten Unterschiede.
| Variante | Zeit (s) | Code (MASM) |
| ohne Synchronisation | 1.966 |  |
| mit atomarer Instruktion | 51.896 | 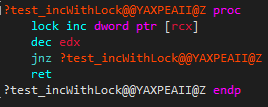 |
| Spin-Lock mit Test-and-Set | mit test: 4.537 ohne test: 6.676 |  |
| Spin-Lock mit Compare-And-Swap | mit test: 4.493 ohne test: 6.828 | 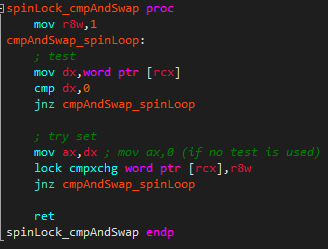 |
Blocking vs. Non-Blocking
Blocking und Non-Blocking bezieht sich auf die Eigenschaft einer Funktion, wenn diese eine Aktion ausführt, welche unter Umständen nicht sofort abgeschlossen werden kann. Ein Beispiel sind Locking-Funktionen, welche versuchen, eine bestimmte kritische Sektion zu sperren. Sollte die Sektion bereits gesperrt sein und das Lock ein Spin-Lock sein oder bei misslungenem Locking ein Kontext-Wechsel vollzogen werden, so handelt es sich um einen Blocking-Aufruf, da aus dieser Funktion erst wieder zurück gekehrt wird, wenn das Locking erfolgreich war. Die weitere Programm-Abarbeitung wird also blockiert. Dies ist wünschenswert, wenn der darauffolgende Programm-Code nur ausgeführt werden darf, wenn das Locking erfolgreich war oder allgemeiner gesagt, wenn eine bestimmte Bedingung eingetreten ist. Sollte die Anwendung aber weiterhin ansprechbar sein oder noch andere Aufgaben abarbeiten, so ist es besser, direkt eine Antwort von der Funktion zu erhalten. Anhand dem Rückgabe-Wert weiß die Anwendung, ob der Aufruf erfolgreich war oder nicht und kann dadurch entweder die aktuelle oder eine andere Aufgabe abarbeiten, um die Echtzeit-Eigenschaft zu bewahren. Solche Funktionen werden nicht blockierende Funktionen genannt. Am Beispiel vom Locking wird einfach ein boolscher Wert zurück gegeben, welcher angibt, ob das Locking erfolgreich war oder nicht, anstatt in einer Dauer-Schleife wie beim Spin-Lock zu verweilen [25]. Eine Beispiel Implementation eines Non-Blocking-Locks mit Hilfe von ‘Test & Test-and-Set’ ist wie folgt gegeben.
 |
Double-Checked-Locking-Pattern
Da Locking im Allgemeinen, bezogen auf die Performance, teuer ist, sollte es nur ausgeführt werden, wenn es notwendig ist. Daher gibt es das sogenannte Double-Checked-Locking-Pattern. Die Idee bei dem Pattern ist, dass das Locking nur ausgeführt werden soll, wenn eine bestimmte Bedingung, bezogen auf die Logik der Anwendung, eintritt, wie zum Beispiel wenn ein Array Elemente enthält, also nicht leer ist. Wenn die Bedingung eingetreten ist, kann versucht werden, die kritische Sektion zu locken. Bei erfolgreichem Locking muss jedoch nochmals getestet werden, ob die Bedingung noch erfüllt ist, da ein anderer Thread bereits in die kritische Sektion eingetreten sein könnte und daher die Bedingung evtl. gar nicht mehr erfüllt ist. Da zweimal getestet werden muss, nennt sich das Pattern ‘Double-Checked-Locking’ [21].
Ein typisches Anwendungsgebiet sind Singleton-Patterns, da hier nur das einmalige Erzeugen des Objektes gelockt werden muss. Das Erhalten der bereits existierenden Referenz kann ohne Locking ausgeführt werden [21].
Die Syntax sieht grob wie folgt aus:
if (<condition>){
lock();
if (<condition>) {<do work>}
unlock();
}
Dead-Lock
Im Zusammenhang mit Locking muss darauf geachtet werden, dass das Sperren und Freigeben kritischer Sektionen so strukturiert ist, dass es nicht passieren kann das zwei Threads jeweils auf die Freigabe der kritischen Sektion des jeweils anderen Threads warten. Dieses Szenario nennt man Dead-Lock, weil damit die weitere Programm-Abarbeitung nicht mehr möglich ist [6].
Synchronisations-Objekte
Aufbauend auf atomaren Instruktionen und Locking können verschiedene Synchronisations-Objekte implementiert werden, welche in verschiedenen Anwendungsgebieten in höheren Programmier-Modellen beziehungsweise Programmier-Sprachen Verwendung finden [10]. Im Folgenden Abschnitt werden zwei Mögliche Synchronisations-Objekte betrachtet.
Das erste ist das Mutex-Objekt, hierbei handelt es sich eigentlich nur um eine andere Beschreibung für das klassische Locking. Das Mutex repräsentiert hierbei intern ein Lock-Flag und bietet standardmäßig die Funktionen lock(), tryLock() und unlock() an. Mutex steht für ‘Mutual Exclusive’ (Gegenseitig Ausschließend). Damit ist die Charakteristik einer kritischen Sektion gemeint. Nur ein Thread gleichzeitig kann das Mutex besitzen [10].
Ein etwas komplexeres Objekt ist das Semaphore. Hierbei existiert kein Flag, welches angibt, ob eine Sektion gesperrt ist, sondern ein Zähler. Damit ist es möglich, dass mehrere Threads gleichzeitig eine bestimmte Sektion betreten können. Der Zähler gibt dabei an, wie viele Threads die Sektion erfolgreich locken dürfen. Erreicht der Zähler 0, so werden darauffolgende Threads in einer Queue abgelegt und pausiert. Das Semaphore-Objekt besitzt in der Regel 2 Funktionen. Eine zum Inkrementieren des Zählers und eine zum Dekrementieren. Wird der Zähler inkrementiert, wird zunächst geschaut, ob in der Queue ein Thread existiert. Wenn dem so ist, wird dieser aus der Queue entfernt und der Scheduler-Queue hinzugefügt. Der Zähler wird nur inkrementiert, wenn kein wartender Thread existiert [13].
Mit Hilfe von Semaphoren können Patterns wie das ‘Producer-Consumer’-Pattern implementiert werden, in welchem Threads auf Berechnungs-Ergebnisse anderer Threads warten. Die Producer-Threads können dann die Consumer-Threads durch das Inkrementieren des Semaphore-Zählers informieren, wenn neue Arbeit verfügbar ist [67].
Threads
Ein Thread kann als unabhängiger Teil eines Prozesses beschrieben werden. [49]
Als Prozess wird die Ausführung eines Programms bezeichnet, welches eine Eingabe erhält und auf Basis dieser Eingabe und des entsprechenden Programms eine Ausgabe liefert.
Ein Thread – auch Aktivitätsträger genannt – ist im eigentlichen Sinne ein Ausführungsstrang in der Abarbeitung eines Computerprogramms. Threads sind unabhängig von anderen Prozessteilen. Sie nutzen einen gemeinsamen Prozessspeicherbereich sowie einen eigenen User- und Kernel-Mode-Stack. Sie lassen sich priorisieren, zudem ist im Falle von Multi-Kern-System durch Threads echte Parallelität erreichbar. Steht nur ein Kern zur Verfügung lässt sich durch häufige Kontextwechsel eine gefühlte Parallelität erreichen.
Kontext-Wechsel
Auf handelsüblichen Computern laufen eine Vielzahl von Prozessen. Dabei handelt es sich sowohl um die vom Nutzer gestartete Anwendung sowie um Prozesse, die im Hintergrund laufen.
Geht man von einem Ein-Kern-System aus, so kann zu einem Zeitpunkt immer nur ein Prozess auf der CPU bearbeitet werden. Dennoch fühlt es sich für den Nutzer so an, als würden alle Anwendungen parallel laufen. Diese gefühlte Parallelität wird durch häufige und sehr schnelle Kontextwechsel erreicht.
Kontextwechsel können unter anderem durch einen hardwareseitigen Interrupt hervorgerufen werden. Es existiert diesbezüglich ein Hardware-Zähler, der nach einer gewissen Zeit einen Compare-Interrupt feuert. Das laufende Programm wird somit unterbrochen. Auf der CPU läuft nun das Betriebssystem welches somit die Kontrolle erlangt. [50]
Letzteres kann nun aufgrund des Prozess-Schedulers entscheiden, welcher Anwendung als nächstes Zeit auf der CPU zur Verfügung gestellt wird und wie lange. Diesbezüglich sollte natürlich unbedingt darauf geachtet werden, dass zu jedem Zeitpunkt ein Prozess auf der CPU läuft, um diese optimal zu nutzen. Benötigt eine Anwendung bestimmte Daten, die es über einen I/O-Request anfordert, so kann es in sehr einfachen Systemen während der Wartezeit zur Untätigkeit der CPU kommen. Diese Ressourcenverschwendung gilt es natürlich zu vermeiden.
In etwas komplexeren Systemen werden daher verschiedene Prozesse zur gleichen Zeit im Memory gehalten. Sobald eine Anwendung warten muss, beispielsweise auf das Eintreffen angeforderter Daten, kann auch ein softwareseitiger Interrupt vorgenommen werden. Durch einen syscall informiert die Anwendung die CPU, dass diese pausiert werden kann.
Es folgt ein Kontextwechsel. Die Wartezeit wird somit für eine andere Anwendung genutzt. Welche Anwendung das im einzelnen ist hängt dabei vom Scheduler ab.
Vorteile von Threads
Wie sich aufgrund des vorangegangenen Kapitels vermuten lässt, bringen Threads einige Vorteile mit sich.
Neben der bereits beschriebenen individuellen Rechenzeitzuteilung, was zu einer besseren CPU-Auslastung führt, lässt sich mithilfe von Threads auch die Programmstruktur vereinfachen. Besonders geeignet sind hier Serverprogramme, welche Client-Requests abarbeiten. Jedem Client kann hier ein Thread zugewiesen werden. Im Gegensatz zu Prozessen, bei denen ein Kontextwechsel vergleichsweise lange dauert, sind hier mithilfe von Threads sehr schnelle Kontextwechsel möglich.
Ein weiterer Vorteil von Threads ist die ermöglichte Parallelisierung im Kontext von Multikernprozessoren. Laufen verschiedene Threads auf verschiedenen, physisch existierenden Kernen, so wird echte Parallelisierung erreicht.
Es kann zudem eine architektonisch saubere Struktur von Programmen aufgezogen werden, indem man das Shared-Memory-Programmiermodell im Falle von Multikernprozessoren anwendet. Durch die Benutzung dieses gemeinsamen Speichers kann eine schnelle Interprozesskommunikation realisiert werden. Dabei gilt es allerdings, Raise-Conditions durch ein hinreichendes Maß an Synchronisation zu vermeiden.
Thread-Scheduling – Eigenes Experiment
Um die Performance eines Multi-Prozessor-Systems zu maximieren, bedarf es einer möglichst performanten Scheduling-Strategie. Im folgenden wurde ein Gedankenexperiment gemacht, welches in Teilen implementiert worden ist. Einen Überblick über die Strategie soll das folgende Bild geben.
 |
Die Grundidee besteht darin, bestehende Tasks zunächst in einer Main-Queue zu halten. Tasks, die sich innerhalb einer Gruppe befinden, können gleichzeitig ausgeführt werden. Sie sind also unabhängig voneinander, sodass während ihrer Abarbeitung keine weitere Kommunikation nötig ist.
Zusätzlich existieren verschiedene Task-Worker, die ihre eigene Task-Queue besitzen.
Ein Task-Worker kann nun überprüfen, ob sich mindestens ein Task in der Main-Queue befindet.
Befindet sich in der Main-Queue mindestens ein Task, so kann ein Task-Worker auf die Main-Queue ein Lock anwenden. Damit ist gewährleistet, dass kein anderer Task-Worker zum gleichen Zeitpunkt Tasks von der Main-Queue in die eigene Task-Queue übertragen kann. Der entsprechende Task-Worker muss zudem noch einen Lock auf seine eigene Task-Queue setzen. Die Begründung hierfür folgt in Kürze. Der entsprechende Task kann jetzt vom Task-Worker abgearbeitet werden. Befinden sich mehrere Tasks in der Main-Queue, so werden diese von den verschiedenen Workern in ihre jeweiligen Task-Queues übertragen und können somit zur gleichen Zeit verarbeitet werden, wodurch echte Parallelität entsteht.
Durch das Locking entsteht natürlich ein gewisses Maß an Overhead. Während die Main-Queue gelockt ist, können keine anderen Task-Worker auf die Main-Queue zugreifen. Es ist demnach sinnvoll, nicht nur einen Task, sondern direkt mehrere Tasks von der Main-Queue in die Task-Queue zu übertragen, um den Overhead zu verringern.
Stellt ein Task-Worker fest, dass sich aktuell keine Tasks in der Main-Queue befinden, ein anderer Task-Worker jedoch einige Tasks in dessen Task-Queue hat, so ist der Task-Worker in der Lage, Tasks von einer fremden Task-Queue in seine eigenen Task-Queue zu übertragen. Dies erhöht die Parallelität und erklärt zudem, warum beim Übertragungsvorgang aus der Main-Queue in die eigene Task-Queue letztere ebenfalls gelockt werden muss.
Selbstverständlich führt auch das “Klauen” von Tasks aus fremden Task-Queues zu einem Overhead, den es so gering wie möglich zu halten gilt. Das Übertragen eines einzelnen Tasks wäre in diesem Zusammenhang daher nicht sinnvoll. Der einfachste Ansatz, um dem Overhead entgegenzuwirken, ist die Einführung einer Mindestanzahl an zu übertragenen Tasks. Stellt ein Task-Worker fest, dass sich weniger Tasks in einer fremden Task-Queue befinden, wartet er einfach auf neue Tasks in der Main Queue.
Um die Scheduling-Strategie noch effizienter zu gestalten, wäre es sinnvoll, Informationen über die Komplexität und die damit verbundene Rechendauer einzelner Tasks zu erlangen. Ist die Mindestanzahl der zu übertragenden Tasks beispielsweise auf 5 gesetzt und ein Task-Worker hat gerade 4 Tasks in seiner Task-Queue, so wird ihm kein anderer Task-Worker Tasks abnehmen. Handelt es sich dabei jedoch um mindestens einen sehr aufwändigen Task, so sind alle anderen Task-Worker unter Umständen über eine lange Zeit inaktiv. Sinnvoller wäre es demnach, die Komplexität der einzelnen Tasks in die Entscheidung, ob Tasks von einem Task-Worker zu einem anderen Task-Worker übertragen werden, miteinfließen zu lassen.
Dies kann zum einen manuell geschehen. Der Programmierer gibt dabei die geschätzte Task-Dauer als Metrik mit an. Es könnten hier zwischen drei verschiedenen längen unterschieden werden, kurz, mittel und lang. Stellt nun ein Task-Worker fest, dass ein anderer Task-Worker einige lange Tasks in seiner Task-Queue hat, so würde sich das Locking sowie die Übertragung wahrscheinlich schon bei einem einzelnen Task lohnen. In ähnlicher Weise könnte anhand der Komplexität nun auch entschieden werden, wie viele Tasks ein einzelner Task-Worker aus der Main-Queue in seine eigenen Queue übernimmt.
Noch eleganter wäre es, die Komplexität einzelnen Tasks automatisch zu ermitteln und dem Programmierer diesen Schritt abzunehmen. Die Dauer eines Tasks muss hier beim erstmaligen Durchlauf ermittelt werden. Wird ein Task mehrfach ausgeführt oder lässt sich eine große Ähnlichkeit zwischen mehreren Tasks feststellen, kann zur Compilezeit eine Art Schlüsselwort übergeben werden, um dem Compiler die geschätzte Komplexität des jeweiligen Tasks mitzuteilen.
Zudem wäre eine Schätzung anhand der benötigten Instruktionen oder anhand des Parser-Baums denkbar.
Selbstverständlich gibt es mittlerweile zahlreiche Strategien, die üblicherweise eingesetzt werden. Eine Auswahl davon wird im nächsten Kapitel behandelt.
Thread-Scheduling-Strategien
Eine der gängigen Strategien, die unserem Experiment aus dem vorherigen Kapitel relativ nahe kommt, die das sogenannte Load-Sharing. [51] Es existiert eine globale Queue, in der die Threads gehalten werden. Sobald ein Prozessor keine Aufgabe mehr hat, übernimmt er einen Thread aus der Queue. Die Lastverteilung folgt hierbei einer relativ beständigen Strategie. Vorteile dieses relativ einfachen Vorgehens sind unter anderem die gleichmäßige Verteilung von Last auf die Prozessoren. Zudem wird bei dieser Strategie kein zentraler Scheduler benötigt. Da diese Strategie sehr viel von Einzel-Prozessor-Systemen übernimmt, kann die die globale Queue beim Load-Sharing in gleicher Weise aufgebaut werden wie bei beliebigen Schemata von Einzel-Prozessor-Systemen.
Eine weitere Strategie wird als so genanntes Gang-Scheduling bezeichnet. [52] Hier werden in erster Linie Threads gleichzeitig bearbeitet, die möglichst zum gleichen Prozess gehören. Gang-Scheduling ist vor allem für den Fall interessant, wenn zwei oder mehr Threads oder Prozesse miteinander kommunizieren müssen. Diese Strategie sorgt dann dafür, dass dies zum gleichen Zeitpunkt geschehen kann, ohne dass ein Thread auf den anderen warten muss um Daten zu senden oder zu empfangen, was zu Leerlaufzeiten führen würde.
Eine völlig andere Strategie stellt das Dedicated-Processor-Assignment dar. [53] Wenn das Scheduling einer Applikation stattfindet, wird hier jeder Thread einem Prozessor zugeordnet. Diese Zuordnung bleibt bestehen, bis die Applikation vollendet ist. Sollte ein Thread während des Programmablaufs untätig werden, da er aufgrund von I/O oder Synchronisation nichts tun kann, so bleibt die entsprechende CPU in dieser Zeit untätig.
Dies mag zunächst ineffizient erscheinen, schließlich werden die Thread-Scheduling-Strategien eingesetzt, um die Last möglichst effizient abzuarbeiten und Untätigkeiten zu vermeiden. Diese Strategie hat allerdings ihre Berechtigung, und zwar im Rahmen von Massiv-Parallelen-Systemen mit vielen tausend Prozessoren. In diesem Rahmen spielt die Nutzung eines einzelnen Prozessors keine allzu große Rolle mehr. Die Vermeidung von Overhead durch Prozess-Switching wiederum sorgt in diesem Fall für einen schnelleren Programmablauf. Nicht unerwähnt bleiben soll in diesem Zusammenhang das Dynamic-Scheduling. [54] Für manche Applikationen lassen sich System- und Sprachwerkzeuge zur Verfügung stellen, die es ermöglichen, die Anzahl der Threads dynamisch zu verändern. In diesem Fall kann das Betriebssystem die Last anpassen, um so die gegebene Anzahl an Threads in möglichst optimaler Weise auszulasten. Bei dieser Strategie sind sowohl das Betriebssystem als auch die Applikation selbst am eigentlichen Scheduling-Prozess beteiligt. Dabei ist die Aufgabe des Betriebssystems vorrangig, die jeweiligen Prozessoren in sinnvoller Art und Weise zu allokieren. Das Dynamic-Scheduling ist dem Gang-Scheduling und dem Dedicated-Processor-Assignment für Anwendungen überlegen, die von dieser Art des Schedulings gebrauch machen können.
Speicher-Allokatoren
Speicher-Allokatoren dienen dem Allokieren und Freigeben von Speicher-Bereichen des Heaps. Dabei verwalten die Allokatoren einen bestimmten Speicher-Bereich und geben davon Teile auf Anfrage an die Anwendung zur freien Verwendung raus. Benötigt die Anwendung den Speicher-Block nicht mehr, so gibt sie ihn an den Allokator zurück. Es existieren verschiedenen Arten von Allokatoren, welche jeweils für bestimmte Anwendungsgebiete geeignet sind. Da das Allokieren und Deallokieren von Heap-Speicher in Anwendungen oft verwendung findet, ist die Performance solcher Allokatoren entsprechend wichtig. Aber auch die Speicher-Effizienz spielt eine wichtige Rolle. Die Allokatoren können entsprechend ihrer Fähigkeiten in drei Gruppen eingeteilt werden. Allokatoren, mit welchen unterschiedlich große Speicher-Blöcke allokiert werden können, Allokatoren, mit denen Speicher-Blöcke in beliebiger Reihenfolge allokiert und deallokiert werden können, oder Allokatoren, mit welchen unterschiedlich große Blöcke in beliebiger Reihenfolge allokiert und deallokiert werden können [1].
General Purpose
Die letzte Eigenschaft erfordert eine deutlich komplexere Logik, was zu einer deutlich schlechteren Performance führt. Zudem müssen für jeden Speicher-Block sowohl Adresse als auch Größe gespeichert werden, um beim Freigeben eines Speicher-Blocks die Größe des freiwerdenden Bereichs bestimmen zu können. Ein weiterer Nachteil, was sich ebenfalls auf die Speicher-Effizienz negativ auswirkt ist, dass es zu Speicher-Fragmentierung kommen kann. Dabei entstehen durch das Allokieren und Deallokieren beliebig großer Speicher-Bereiche lücken die aber eventuell für weitere Allokationen nicht verwendet werden können, da diese zu klein sind. So kann die summe aller Lücken der angefragten Speicher-Block-Größe entsprechen, der Speicher aber nicht genutzt werden, da er nicht zusammenhängend ist. Um den Speicher besser auszunutzen kann dieser defragmentiert werden. Dabei werden die allokierten Speicher-Blöcke verschoben, um freie Lücken zu schließen und so mehr zusammenhängenden freien Speicher zu erhalten. Dies ist aber nur möglich, wenn die Zeiger auf die Speicher-Blöcke durch eine Indirektion für äußere Anwendungs-Komponenten zugreifbar sind, da die Speicher-Blöcke nach der Defragmentierung eventuell an einer anderen Speicher-Adresse liegen könnten und äußere Komponenten so auf eine falsche Adresse zugreifen würden.. Zudem erfordert Defragmentierung zusätzlich Rechenaufwand, welcher sich wiederum negativ auf die Performance auswirkt.Solche Allokatoren werden General-Purpose-Allocators genannt. Diese sollten eher bei allgemeinen und seltenen Allokationen verwendet werden.
Ein typischer General-Purpose-Allokator ist der malloc()/free() aus der C-Programmiersprache [1].
Stack
Muss die Allokations/- und Deallokations-Reihenfolge nicht variabel sein, so kann ein Stack-Allokator verwendet werden. Hierbei können unterschiedlich große Blöcke allokiert werden. Die Allokations/- und Deallokations-Reihenfolge muss jedoch dem LOFI-Prinzip entsprechen (Last-Out-First-In). Dadurch wird die Speicher-Fragmentierung von vornherein verhindert, was sich positiv auf die Speicher-Effizienz auswirkt. Zudem ist die Zugriffszeit O(1), da immer der zuletzt allokierte Block wieder frei gegeben wird und daher ein Suchen des freizugebenden Blocks nicht erforderlich ist.
Geeignet ist der Allokator für Initialisierungsvorgänge, bei dem unterschiedlich große Objekte, welche aber nur einmalig erzeugt werden müssen, erzeugt und später wieder in entgegengesetzter Richtung zerstört werden [1].
Pool
Mit Hilfe des Pool-Allokators können Blöcke gleicher Größe in beliebiger Reihenfolge allokiert und deallokiert werden. Dadurch wird der Speicher mit diesem Allokator ebenfalls nicht fragmentiert. Da alle Blöcke gleich groß sind, kann beim Allokieren beziehungsweise Freigeben des Speichers, die position durch einfache Berechnungen ermittelt werden, sodass auch hier die betroffenen Speicher-Blöcke nicht gesucht werden müssen, was einer Zugriffs-Zeit von O(1) entspricht.
Pool-Allokatoren werden immer dann verwendet, wenn viele Objekte eines bestimmten Typs benötigt werden. Dies ist zum Beispiel bei Projektilen in Computer-Spielen oder Physik-Simulationen der Fall [1].
Im Folgenden wurden Zeit/- und Speicher-Verbrauchs-Messungen durchgeführt, um festzustellen, wie groß die Performance-Unterschiede der einzelnen Allokatoren bezogen auf Zeit und Platz sind.
Experiment – Allocator
Speicher-Verbrauch
Die Speicher-Werte wurden aus dem Monitoring-Fenster von Visual-Studio entnommen. Der initiale Speicher-Verbrauch dieses Prozesses beträgt 1,4 MB. Der vorgenommenen Messung lässt sich entnehmen, dass der Pool/Stack-Allokator etwa 12% weniger Speicher als der General-Purpose-Allokator benötigt.
| Block-Größe(Byte) | Anzahl Blöcke | Angefragter Speicher (MB) | Pool (MB) | Stack (MB) | General Purpose (MB) |
| 256 | 10.000 | 2.441 | 3.9 | 4 | 5,2 |
| 1024 | 10.000 | 9.766 | 11,3 | 11,4 | 12,6 |
| 10.000 | 10.000 | 95.367 | 97 | 97,1 | 115,5 |
| 100.000 | 10.000 | 953.674 | 957 | 957,1 | 962,4 |
Es wurde erwartet, dass der benötigte Speicher des General-Purpose-Allokators bei größeren Speicher-Mengen-Anfragen deutlich schneller anwächst als beim Pool-/ und Stack-Allokator, da aufgrund der Speicher-Fragmentierung mehr Speicher ungenutzt bleibt. Je mehr Speicher belegt ist, desto mehr fragmentierten Speicher und daher auch zusätzlicher Speicher wird beim General-Purpose-Allokator benötigt. Jedoch konnte dies bei den Messungen nicht bestätigt werden.
Dies könnte daran liegen, dass alle allokierten Speicher-Blöcke die selbe Größe besitzen und daher ein besseres Ausnutzen des Speichers möglich ist. Um aussagekräftigere Messergebnisse zu erhalten, könnte eine umfangreiche Messung durchgeführt werden, welche sowohl unterschiedliche Block-Größen, als auch unterschiedliche Block-Mengen allokiert. Die Block-Größen könnten hierbei wiederum in unterschiedlichen Reihenfolgen allokiert werden. Dies wurde aber im Rahmen dieses Projekts nicht mehr durchgeführt.
Performance
Bei den eigenen Allokatoren, Pool und Stack, wurden zwei Messungen, einmal mit und einmal ohne Locking, durchgeführt. Dadurch sind die Ergebnisse aussagekräftiger, da Malloc, welcher als General-Purpose-Allokator verwendet wurde, standardmäíg Locking enthält. Die untere Messung in einem Feld entspricht immer der mit Lock().
Die Messung kam zustande, indem <Anzahl Blöcke>*<Block-Größe>-Große Speicher-Blöcke allokiert und danach wieder deallokiert wurden. Dieser Vorgang wurde 100 Mal wiederholt.
Je größer die zu allokierenden Speicher-Blöcke werden, desto schwieriger ist es für den General-Purpose-Allokator, passende freie Speicher-Bereiche zu finden. Dies kann anhand der Messungen auch sehr schön veranschaulicht werden. Die benötigte Zeit steigt immer schneller, je größer die Speicher-Blöcke werden.
Die Zeiten der eigenen Allokatoren verändern sich nicht, da deren Zugriffszeiten O(1) sind [1].
| Block-Größe (Byte) | Anzahl Blöcke | Pool (sec) | Pool Thread-sicher (sec) | Stack | Stack Thread-sicher (sec) | General Purpose |
| 256 | 10.000 | 0,125 | 0,352 | 0,353 | 0,601 | 0,641 |
| 1024 | 10.000 | 0,112 | 0,344 | 0,358 | 0,571 | 1,079 |
| 10.000 | 10.000 | 0,109 | 0,361 | 0,351 | 0,585 | 5,926 |
| 100.000 | 10.000 | 0,112 | 0,325 | 0,349 | 0,620 | 57,101 |
Quellen
[1] Gregory, Jason: Game Engine Architecture. Chapman and Hall/CRC, London: CRC Press, Taylor & Francis Group, 2018.
[2] “Asynchronous Messaging Patterns” – https://blogs.mulesoft.com/dev/design-dev/asynchronous-messaging-patterns/ – letzter Zugriff: 2021-02-27
[3] “In Praise of Computer Architecture: A Quantitative Approach Fourth Edition” – https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.1881&rep=rep1&type=pdf – letzter Zugriff: 2021-02-27
[4] “Cache” – https://de.wikipedia.org/wiki/Cache – letzter Zugriff: 2021-02-27
[5] “Cache-Kohärenz” – https://de.wikipedia.org/wiki/Cache-Kohärenz – letzter Zugriff: 2021-02-27
[6] “Deadlock (Informatik)” – https://de.wikipedia.org/wiki/Deadlock_(Informatik) – letzter Zugriff: 2021-02-27
[7] “Flynnsche Klassifikation” – https://de.wikipedia.org/wiki/Flynnsche_Klassifikation – letzter Zugriff: 2021-02-27
[8] “Lock” – https://de.wikipedia.org/wiki/Lock – letzter Zugriff: 2021-02-27
[9] “Lokalitätseigenschaft” – https://de.wikipedia.org/wiki/Lokalitätseigenschaft – letzter Zugriff: 2021-02-27
[10] “Mutex” – https://de.wikipedia.org/wiki/Mutex – letzter Zugriff: 2021-02-27
[11] “Portable Operating System Interface” – https://de.wikipedia.org/wiki/Portable_Operating_System_Interface – letzter Zugriff: 2021-02-27
[12] “RMW-Befehl” – https://de.wikipedia.org/wiki/RMW-Befehl – letzter Zugriff: 2021-02-27
[13] “Semaphor (Informatik)” – https://de.wikipedia.org/wiki/Semaphor_(Informatik) – letzter Zugriff: 2021-02-27
[14] “Streaming SIMD Extensions” – https://de.wikipedia.org/wiki/Streaming_SIMD_Extensions – letzter Zugriff: 2021-02-27
[15] “4 Design Patterns In Web Development” – https://dev.to/flippedcoding/4-design-patterns-in-web-development-55p7 – letzter Zugriff: 2021-02-27
[16] “Priority Queue pattern” – https://docs.microsoft.com/en-us/azure/architecture/patterns/priority-queue – letzter Zugriff: 2021-02-27
[17] “Bus snooping” – https://en.wikipedia.org/wiki/Bus_snooping – letzter Zugriff: 2021-02-27
[18] “Compare-and-swap” – https://en.wikipedia.org/wiki/Compare-and-swap – letzter Zugriff: 2021-02-27
[19] “Directory-based cache coherence” – https://en.wikipedia.org/wiki/Directory-based_cache_coherence – letzter Zugriff: 2021-02-27
[20] “Distributed shared memory” – https://en.wikipedia.org/wiki/Distributed_shared_memory – letzter Zugriff: 2021-02-27
[21] “Double-checked locking” – https://en.wikipedia.org/wiki/Double-checked_locking – letzter Zugriff: 2021-02-27
[22] “MESI protocol” – https://en.wikipedia.org/wiki/MESI_protocol – letzter Zugriff: 2021-02-27
[23] “MOSI protocol” – https://en.wikipedia.org/wiki/MOSI_protocol – letzter Zugriff: 2021-02-27
[24] “MSI protocol” – https://en.wikipedia.org/wiki/MSI_protocol – letzter Zugriff: 2021-02-27
[25] “Non-blocking algorithm” – https://en.wikipedia.org/wiki/Non-blocking_algorithm – letzter Zugriff: 2021-02-27
[26] “Comparison with AHCI” – https://en.wikipedia.org/wiki/NVM_Express#Comparison_with_AHCI – letzter Zugriff: 2021-02-27
[27] “Reactor pattern” – https://en.wikipedia.org/wiki/Reactor_pattern – letzter Zugriff: 2021-02-27
[28] “SIMD” – https://en.wikipedia.org/wiki/SIMD – letzter Zugriff: 2021-02-27
[29] “Symmetric multiprocessing” – https://en.wikipedia.org/wiki/Symmetric_multiprocessing – letzter Zugriff: 2021-02-27
[30] “Test and test-and-set” – https://en.wikipedia.org/wiki/Test_and_test-and-set – letzter Zugriff: 2021-02-27
[31] “Test-and-set” – https://en.wikipedia.org/wiki/Test-and-set – letzter Zugriff: 2021-02-27
[32] “Event Queue” – https://gameprogrammingpatterns.com/event-queue.html – letzter Zugriff: 2021-02-27
[33] “Concurrency vs Event Loop vs Event Loop + Concurrency” – https://medium.com/@tigranbs/concurrency-vs-event-loop-vs-event-loop-concurrency-eb542ad4067b – letzter Zugriff: 2021-02-27
[34] “Empty Standby List” – https://wj32.org/wp/software/empty-standby-list/ – letzter Zugriff: 2021-02-27
[35] “I/O Bottlenecks: Biggest Threat to Data Storage” – https://www.enterprisestorageforum.com/technology/features/article.php/3856121/IO-Bottlenecks-Biggest-Threat-to-Data-Storage.htm – letzter Zugriff: 2021-02-27
[36] “BTS — Bit Test and Set” – https://www.felixcloutier.com/x86/bts – letzter Zugriff: 2021-02-27
[37] “CMPXCHG — Compare and Exchange” – https://www.felixcloutier.com/x86/cmpxchg – letzter Zugriff: 2021-02-27
[38] “LOCK — Assert LOCK# Signal Prefix” – https://www.felixcloutier.com/x86/lock – letzter Zugriff: 2021-02-27
[39] “Investigating I/O bottlenecks” – https://www.mssqltips.com/sqlservertutorial/254/investigating-io-bottlenecks/ – letzter Zugriff: 2021-02-27
[40] “I/O Bottleneck” – https://www.techopedia.com/definition/30479/io-bottleneck – letzter Zugriff: 2021-02-27
[41] “Strategy Design Pattern” – https://www.youtube.com/watch?v=-NCgRD9-C6o – letzter Zugriff: 2021-02-27
[42] “4 2 3 MSI Write Invalidate Protocol” – https://www.youtube.com/watch?v=ctLdDiCDF28 – letzter Zugriff: 2021-02-27
[43] “5 – CPU vs I/O Bound Operations” – https://www.youtube.com/watch?v=On0k9VMN9bE – letzter Zugriff: 2021-02-27
[44] “CPU Bound vs. I/O Bound | Computer Basics” – https://www.youtube.com/watch?v=Wsv07g4ml8I – letzter Zugriff: 2021-02-27
[45] “Cache Memory Explained” – https://www.youtube.com/watch?v=Zr8WKIOIKsk – letzter Zugriff: 2021-02-27
[46] “MOESI protocol” – https://en.wikipedia.org/wiki/MOESI_protocol – letzter Zugriff: 2021-02-27
[47] “Branchless Programming: Why “if” is Slowww… and what we can do about it!” https://www.youtube.com/watch?v=bVJ-mWWL7cE – letzter Zugriff: 2021-02-27
[48] “Pipeline (Prozessor)” https://de.wikipedia.org/wiki/Pipeline_(Prozessor) – letzter Zugriff: 2021-02-27
[49] “Prozesse und Threads | #Betriebssysteme” https://www.youtube.com/watch?v=TGgUEamLvGs – letzter Zugriff: 2021-02-27
[50] “Introduction to CPU Scheduling” https://www.youtube.com/watch?v=EWkQl0n0w5M – letzter Zugriff: 2021-02-27
[51] “popular multiprocessor thread-scheduling strategies” https://www.sawaal.com/operating-systems-question-and-answers/explain-the-popular-multiprocessor-thread-scheduling-strategies_3393 – letzter Zugriff: 2021-02-27
[52] “Gang scheduling” https://en.wikipedia.org/wiki/Gang_scheduling – letzter Zugriff: 2021-02-27
[53] “Dedicated Processor Assignment : Thread Scheduling” https://www.youtube.com/watch?v=osNTAYqekl8 – letzter Zugriff: 2021-02-27
[54] “Dynamic Scheduling : Thread Scheduling” https://www.youtube.com/watch?v=uRDZRmHT8V4 – letzter Zugriff: 2021-02-27
[55] “Branch (computer sience)” https://en.wikipedia.org/wiki/Branch_(computer_science) – letzter Zugriff: 2021-02-27
[56] “MMX” https://de.wikipedia.org/wiki/Multi_Media_Extension – letzter Zugriff: 2021-02-27
[57] “AVX” https://de.wikipedia.org/wiki/Advanced_Vector_Extensions – letzter Zugriff: 2021-02-27
[58] “Intrinsische Funktion” https://de.wikipedia.org/wiki/Intrinsische_Funktion – letzter Zugriff: 2021-02-27
[59] “See How a CPU Works” https://www.youtube.com/watch?v=cNN_tTXABUA&t=212s – letzter Zugriff: 2021-02-27
[60] “Scalable Cache Coherence” https://www.youtube.com/watch?v=VlU41fxzbrU – letzter Zugriff: 2021-02-27
[61] “Atomare Operation” https://de.wikipedia.org/wiki/Atomare_Operation – letzter Zugriff: 2021-02-27
[62] “Kritischer Abschnitt” https://de.wikipedia.org/wiki/Kritischer_Abschnitt – letzter Zugriff: 2021-02-27
[63] “Lock” https://de.wikipedia.org/wiki/Lock – letzter Zugriff: 2021-02-27
[64] “x64 Assembly MultiThreading 3: Mutexes, SpinLocks and Critical Sections” https://www.youtube.com/watch?v=R8Ttz8bJ81o&list=PL0C5C980A28FEE68D&index=71 – letzter Zugriff: 2021-02-27
[65] “Spinlock” https://de.wikipedia.org/wiki/Spinlock – letzter Zugriff: 2021-02-27
[66] “Compare-and-swap” https://de.wikipedia.org/wiki/Compare-and-swap – letzter Zugriff: 2021-02-27
[67] “Erzeuger-Verbraucher-Problem” https://de.wikipedia.org/wiki/Erzeuger-Verbraucher-Problem – letzter Zugriff: 2021-02-27
Leave a Reply
You must be logged in to post a comment.