Ausfälle 2020
Wie bereits dargestellt, hatten nicht nur die Menschen, sondern auch die ULS-Systeme erhöhte Belastungen durch die Pandemie. So stiegen täglicher Nutzerzahlen bekannter Videokonferenzsysteme wie Microsoft Teams (75 Mio auf 115 Mio) oder Zoom (10 Mio auf 300 Mio) innerhalb weniger Monate rapide an und sorgen für eine dementsprechend kurzfristig notwendige Skalierung. Auch auf Kollaborationstools wie Slack oder gängige Cloud Anbieter wie AWS, Microsoft Azure oder Google wirkte sich dieser Nutzerzuwachs aus, weshalb es im vergangenen Jahr vermehrte Ausfälle verschiedener ULS-Systeme gab. Diese Ausfälle werden von den betroffenen Unternehmen in sogenannten “Post-Mortem”-Berichten beschrieben und analysiert. Vier dieser Berichte des Jahres 2020 werden im Folgenden zusammengefasst und in die zuvor beschriebenen Muster eingeordnet.
Azure – März 2020
Zu erheblichen Problemen in Europa und Großbritannien kam es für die Benutzer der Microsoft Cloud-Computing-Plattform Azure zwischen dem 24. und 26. März 2020. Durch die Lockdowns und das stark ansteigende Home-Office in Europa, nahm die Anfrage virtueller Windows und Linux Maschinen (VMs) derart zu, dass es bei den zu verarbeitenden Pipeline-Jobs, die dem Benutzer eine VM zur Verfügung stellen, zu erheblichen Verzögerungen von bis zu 9 Stunden kam. Jeder dieser Pipeline-Jobs stellt in der Regel eine neue, virtuelle Maschine aus dem gehosteten Agent-Pool bereit. Diese Anzahl der bereitzustellenden VMs stieg während der Rush-Hours auf ca. 30.000 Anfragen pro Stunde, wodurch das maximale Limit des Agent-Pools erreicht wurde. Da bei einer fehlerhaften Zuweisung jedoch versucht wurde, die Zuweisung erneut durchzuführen, verlangsamte sich die Zeit des Hochfahrens eines neuen Agents im Pool erheblich. Die Gesamtzahl der Agenten im Pool war zu gering, um die Anzahl der Anfragen zu bedienen, trotzdem wurde aber weiterhin versucht, VMs bereitzustellen. Dies wiederum führte zu Warteschlangen und der beschriebenen Pipeline-Verzögerung, welche erst nach 2 Tagen und durch folgende Anpassungen beseitigt wurde.
Durch die Verwendung von ephemeren OS-Disks, die bei Linux VMs zukünftig die VM-Allocations-/Deallocation Operationen pro Pipeline-Job durch eine Re-Image-Operation ersetzen, wurde dieses Problem bei Linux VMs behoben. Da dies bei Windows VMs so nicht möglich ist, wurden hier größerer Azure-VMs und verschachtelte Virtualisierungen eingeführt, um die erhöhte Nachfrage zu bewältigen. Jedoch zeigt der Ausfall die Wichtigkeit von Monitoring und wie die von Laura Nolan beschriebenen Muster auch in Kombination dazuführen, dass Systeme ausfallen. Das Erreichen der VM-Kapazität (Hitting Limit) führte durch dann Auftretendes Thundering Herds zum verlangsamten Hochfahren der Agents (Spreading Slowness), die wiederum das gesamte System über Tage beeinträchtigten.
Mehr Infos zum Outage: Azure Post-Mortem Bericht [14]
Slack – Mai 2020
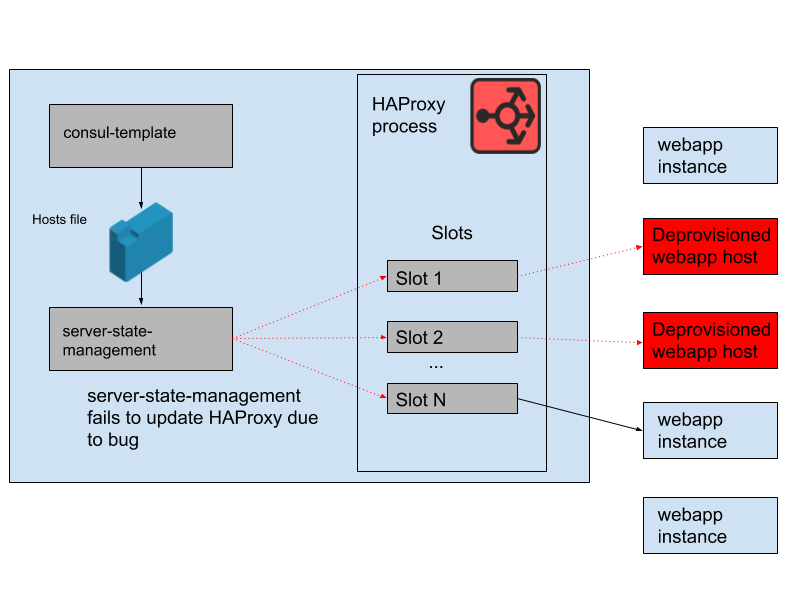
Als “Terrible, Horrible, No-Good, Very Bad Day” beschreibt die Kollaborationsplattform Slack den 12.05.2020, welcher einen stundenlangen Ausfall der Plattform herbeiführen sollte. Grund dafür war ein Bug in der von Slack entwickelten Schnittstelle (server-state-management), welche die Synchronisation zwischen Hostliste und den HAProxy (High Availability Proxy) Instanzen steuert (siehe Abbildung 2). Diese HAProxy Instanzen (auf verschiedene AWS Availability Zones verteilt) sind Slots, die wiederum durch WebApp Instanzen belegt werden, um je nach Bedarf mit Auto-Scaling zu Skalieren. Durch das vervielfachte Home-Office, sowie einer am Vormittag durchgeführte und innerhalb kurzer Zeit zurückgerollten Konfigurationsänderung, trat ein hoher Bedarf an WebApp Instanzen auf, wodurch dieser Bug zum großen Problem werden sollte. Durch fehlerhafte Programmlogik der Schnittstelle versuchte diese zuerst einen Slot für neue Webapp-Instanzen zu finden, ehe sie veraltete Slots freigab, die von nicht mehr laufenden Webapp-Instanzen belegt waren. Dieser Bug trat bis zu diesem “Terrible, Horrible Day” nicht auf, da in allen Phasen des Auto-Scalings freie Slos verfügbar waren. Durch den erhöhten Traffic führte dies zur vollständigen Belegung alle verfügbaren Instanzen und die laufenden HAProxy-Instanzen konnten ihren Status nicht aktualisieren. Dadurch wurde die Liste der Backends im HAProxy-Status immer älter und führte am Nachmittag, als durch das AutoScaling weitere, noch nicht veraltete Slots reduziert wurden, zum Ausfall.
Durch einen Neustart der HAProxies wurde das Problem zwar schnell behoben, jedoch hätte dafür vorgesehenes Monitoring, welches ebenfalls nicht geplant funktionierte, diesen Ausfall verhindern müssen. Auch an diesem Fall zeigt sich, dass die Kombination aus Black-Swan-Mustern häufig für Ausfälle der IT-Systeme verantwortlich ist. Im Beispiel Slack wird das Limit der maximalen WebApp Instanzen erreicht (Hitting Limit) und führt dazu, dass ein Bug den eigentlichen Ausfall auslöst. Das AutoScaling, welches die letzten verfügbaren und nicht veralteten Slots am Nachmittag reduzierte, sollte dann zum Ausfall des bis dahin schon beeinträchtigen Systems führen (Autonomous Interactions).
Mehr Infos zum, ebenfalls von Laura Nolan veröffentlichten, Outage-Bericht: Slack Post-Mortem [15]
AWS – November 2020
Auch Cloud-Marktführer AWS blieb von Vorfällen im Jahr 2020 nicht verschont und musste einen gravierenden Outage (ca 17 Stunden) vieler AWS Dienste am 26. November hinnehmen. Grund dafür war eine Kapazitätserweiterung der Front-End-Fleets einiger Kinesis-Server, die die Echtzeitverarbeitung von großen Streams bei AWS ermöglichen. Diese Server werden von vielen AWS-Services (z.B. DynamoDB, EC2, Aurora, Cognito ) für die Verarbeitung der Streams verwendet, wodurch AWS-Kunden wie Autodesk, AdobeSpark oder Flickr durch den Ausfall nicht uneingeschränkt verfügbar waren. Das Front-End des Kinesis-Servers übernimmt dabei die Authentifizierung sowie die Drosselung und verteilt den Workload der Stream-Verarbeitung über einen Datenbankmechanismus (Sharding) auf einem Back-End-Cluster. Dieses Back-End-Cluster sind die “Workhorses” des Kinesis-Dienstes und sorgen für die Verteilung, den Zugriff und die Skalierbarkeit der Stream Verarbeitung. Für die Kommunikation zwischen den Servern erstellt jeder Front-End-Server Threads, die für jeden anderen Server in der Front-End-Fleet auf den Servern angelegt werden. Bei jeder Kapazitätserweiterung erfahren die Server, die bereits Mitglieder der Fleet sind, dass neue Server hinzukommen und richten die entsprechenden Threads ein. Durch das Erweitern zusätzlicher Server in den Front-End-Fleets wurde die maximale Anzahl Threads, die die Betriebssystemkonfiguration zuließ, überschritten. Dadurch konnte der Cache der Front-End-Server nicht korrekt gebildet werden, wodurch die Server nutzlose Shardmaps speicherten. Dadurch wurde es für die Front-End-Server wiederum unmöglich, Anfragen an die Back-End-Cluster weiterzuleiten, wodurch die “Workhorses” keine Streams mehr verarbeiten konnten und die Kineses-Dienste nicht mehr funktionierten.
Die zusätzliche Front-Fleet-Kapazität wurde zur Lösung des Problems anschließend wieder entfernt, wodurch die die Caches wieder korrekt gebildet werden konnten. Die betroffenen AWS Dienste erholten sich nach und nach und waren nach ca. 17 Stunden wieder vollständig verfügbar. Durch dass Auslösen der Thread-Grenze des Betriebssystem, kann dieser Ausfall der Kategorie “Hitting Limit” zugeordnet werden.
Mehr Infos zum Ausfall: Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region
Google – Dezember 2020
Nur 3 Wochen nachdem mit AWS ein “Big-Player” der Cloud Anbieter die beschriebenen Kinesis-Probleme hatte, legte auch Internetrieße Google nach und vermeldete am 14. Dezember einen knapp einstündigen Ausfall vieler seiner Dienste (u.a. YoutTube, Gmail, GoogleDrive). Verantwortlich dafür waren Probleme mit Googles User-ID-Service, der die Authentifizierungsdaten für Tokens (OAuth-Tokens) und Cookies verwaltet und dabei Anfragen ablehnt, wenn veraltete Daten festgestellt werden. Eine Migration dieses User-ID-Services auf ein neues Quota-System, führte hier durch die automatisierte Ressourceverwaltung Googles zum Fehler. Da ein Teil des Services auf dem alten System bestehen blieb, wurde von diesem alten System fälschlicherweise ein Quota = 0 durch Googles automatisierte Ressourceverwaltung festgelegt, da auf diesem System keine Anfragen eingingen. Dienste mit Quota = 0 hindern den Paxos-Leader, der über das gleichnamige Paxos-Protokoll die Aktualisierung der Kontodaten steuert, neue Daten zu übermitteln. Dadurch erkannte die Mehrzahl der Leseoperationen veraltete Daten, was wie beschrieben, zur Ablehnung der Anfragen führte. Der User-ID-Service konnte dadurch nicht angefragt und die Dienste, die diesen benötigen, demnach nicht zur Verfügung gestellt werde.
Das Problem wurde von Google dadurch gelöst, dass die automatisierte Quota-Erzwingung deaktiviert und der Dienst dadurch wiederhergestellt werden konnte. Da diese automatisierte Ressourceverwaltung für den Service-Ausfall verantwortlich ist, kann der Ausfall dem Muster Automation Interactions zugeordnet werden.
Mehr Infos zum Outage: Google Cloud Infrastructure Components Incident #20013
Übersicht
Folgende Übersicht ordnet die beschriebenen Ausfälle in die sechs von Laura Nolan definierten Muster der Black-Swans ein:
| Hitting Limit | Spreading Slowness | Thunder. Herds | Autom. Interact. | Cyber Attacks | Depend. Problems | |
| Azure | X | X | X | |||
| Slack | X | X | ||||
| AWS | X | |||||
| X |
Nach diesen Mustern geordnete Präventionsmaßnahmen, um solche Black-Swans in IT-Systemen zu vermeiden, werden auf Seite 3 des Blogeintrags thematisiert.
Leave a Reply
You must be logged in to post a comment.