bugs, bugs everywhere
A recent study found that 60-70% of vulnerabilities in iOS and macOS are caused by memory unsafety. Microsoft estimates that 70% of all vulnerabilities in their products over the last decade have been caused by memory unsafety. Google estimated that 90% of Android vulnerabilities are memory unsafety. An analysis of 0-days that were discovered being exploited in the wild found that more than 80% of the exploited vulnerabilities were due to memory unsafety.
(Gaynor, 2019)
Over the last 20 years, developing secure software has become increasingly important. To this day, we write a significant amount of code in languages with manual memory management. However, the Peter Parker principle states that “great power comes with great responsibility”. Many scoring systems classify, enumerate and rank prevalence of known vulnerabilities. In theory, developers should be aware of common programming mistakes leading to these bugs. Yet, the last 20 years are living proof that manual memory management is highly error-prone. Because most systems share memory between data and instructions, controlling small portions of memory can be enough to take over entire systems (Szekeres et al., 2013). The fight over attacking and defending the security measures on top of unsafe systems is often called the eternal war in memory.
In this blog post, I want to examine what properties make programming languages like C/C++ fundamentally unsafe to use. After that, I briefly discuss the inadequacies of our defense mechanisms. Last of all, I reflect on the sociopolitical implications arising from the continued use of unsafe languages.
table of contents
memory-safety
First, one must distinguish between memory-safe programs and languages. A program is considered memory-safe if all of its possible executions over all possible inputs are memory-safe (Hicks, 2014). While it is possible to write memory-safe programs using unsafe languages, it is the responsibility of the programmer to ensure that no memory corruptions occur. In contrast, a memory-safe language provides guarantees that all possible programs written it are memory-safe (Hicks, 2014). It can be concluded, that memory-safety is mainly about shifting responsibilities from the developer to the compiler.
spatial safety
Fundamentally, spatial safety is about respecting a program’s memory layout. It demands that pointer are only used to access memory that belongs to it. (Hicks, 2016) illustrates the concept of belonging by viewing pointers as triples (\(p\), \(b\), \(e\)). \(p\) is the memory address the pointer points to. It can be in-/ decremented using pointer arithmetic. The \(b\) refers to the base address of the memory region associated with the pointer. The extent \(e\) marks the end address of the region we are allowed to access. It is determined from the arguments passed to malloc or sizeof. \[b <= p <= e-sizeof(typeof(p))\] Dereferencing a pointer is spatially safe as long as \(p\) stays within the allotted memory region \(b\) to \(e\). If the program violates this condition, we have an out-of-bounds read/write.
example: null pointer dereference
<span id="cb1-1"><a href="#cb1-1" aria-hidden="true"></a><span class="dt">int</span> <span class="op">*</span>ptr <span class="op">=</span> NULL<span class="op">;</span></span>
<span id="cb1-2"><a href="#cb1-2" aria-hidden="true"></a><span class="op">*</span>ptr <span class="op">=</span> <span class="dv">1</span><span class="op">;</span></span>A null pointer is a value to indicates that a pointer does not refer to a valid object (Wikipedia contributors, 2021b). They are typically used to represent an “exceptional” state. Forgetting to check for invalid pointers may result in dereferencing a null pointer. Because these pointers do not refer to a meaningful object, the C standard specifies the resulting behaviour as undefined. To avoid arbitrary and potentially damaging behavior, most operating systems map the null pointer’s address to an unmapped memory location. Thereby, read/write access results in a segmentation fault that crashes the program. Although undesirable, crashes are often the best option, as they warn developer that something went wrong and prevent further exploitation.
example: buffer overflow
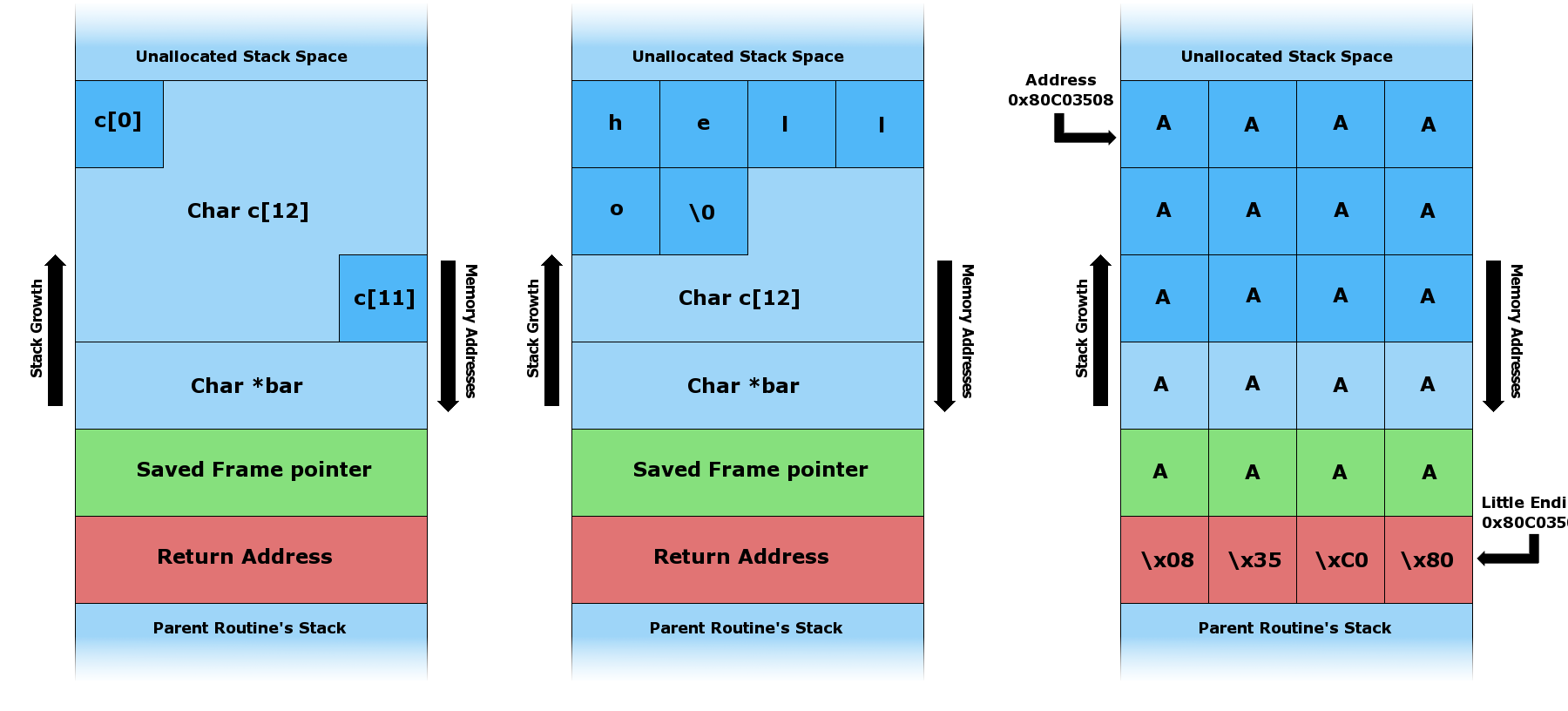
Every time a function is called, the operating system allocates a new stack frame in RAM. Every stack frame consists of: – a memory region for allocation of local variables – a saved frame pointer that references the memory address of the previous stack frame – a return address that specifies points to the next instruction fetched by the CPU after exiting the current function.
One example, could be a function that takes a user input and copies it into a character buffer. To achieve maximum performance, .strcopy() evades the overhead of bounds checking, copying bytes until reaching a terminating null character. It expects the programmer to check that the input fits into the target buffer. Without it, the routine will continue to copy bytes beyond the memory region belonging to the destination pointer. Buffer overflow attacks are a classic example of exploiting missing spatial safety. If a malicious agent overwrites the return address at the end of the stack frame, he/she might be able to hijack the control-flow and execute remote code. Additionally, out-of-bounds reads can be used to leak sensitive information from other memory regions.
temporal safety
So far, we considered the spatial component of memory-safety. With memory being limited, applications must free resources once they are no longer needed. Hence, memory is a construct evolving over time. With this new dimension comes a new class of vulnerabilities.
The best way to explain the concept of temporal safety is to classify memory regions. Undefined memory are regions that have never been allocated, were previously allocated but have been freed or are uninitialized (Hicks, 2014). Temporal memory-safety enforces that all memory dereferences are valid, thereby preventing access to undefined memory and use of dangling pointers (Payer, 2017).
example: use after free
<span id="cb2-1"><a href="#cb2-1" aria-hidden="true"></a><span class="co">// dereferencing a freed pointer</span></span>
<span id="cb2-2"><a href="#cb2-2" aria-hidden="true"></a><span class="dt">int</span> <span class="op">*</span>p <span class="op">=</span> malloc<span class="op">(</span><span class="kw">sizeof</span><span class="op">(</span><span class="dt">int</span><span class="op">));</span></span>
<span id="cb2-3"><a href="#cb2-3" aria-hidden="true"></a><span class="op">*</span>p <span class="op">=</span> <span class="dv">5</span><span class="op">;</span></span>
<span id="cb2-4"><a href="#cb2-4" aria-hidden="true"></a>free<span class="op">(</span>p<span class="op">);</span></span>
<span id="cb2-5"><a href="#cb2-5" aria-hidden="true"></a><span class="co">// ...</span></span>
<span id="cb2-6"><a href="#cb2-6" aria-hidden="true"></a>doProcess<span class="op">(</span>p<span class="op">);</span> <span class="co">// dereferenced memory no longer belongs to p</span></span>The most frequent exploitation of temporal unsafety are use-after-free (UAF) vulnerabilities. When an object is freed, the underlying memory is no longer associated to the object and the pointer is no longer valid (Payer, 2017). Yet, deallocation does not change the value of the pointer variable. If the program continuous to use the reference after its memory has been freed, a number of security risks arise.
The operating system may reallocate previously freed memory at any point in time. Therefore, read-access through a dangling pointer could leak sensitive data from unrelated objects. Writing to a dangling pointer can corrupt valid data structures, leading to undefined behavior (OWASP, 2021).
Another exploitation is heap massaging. Here, the attacker forces the program to allocate new data into the memory region of the dangling pointer. The mismatch between the expected and actual datatype causes the program to misbehave. This illustrates how memory-safety is tightly linked to the topic of type-safety (which we conver later).
example: double free
<span id="cb3-1"><a href="#cb3-1" aria-hidden="true"></a><span class="dt">char</span><span class="op">*</span> ptr <span class="op">=</span> <span class="op">(</span><span class="dt">char</span><span class="op">*)</span>malloc <span class="op">(</span>SIZE<span class="op">);</span></span>
<span id="cb3-2"><a href="#cb3-2" aria-hidden="true"></a><span class="co">// ...</span></span>
<span id="cb3-3"><a href="#cb3-3" aria-hidden="true"></a><span class="cf">if</span> <span class="op">(</span>abrt<span class="op">)</span> <span class="op">{</span></span>
<span id="cb3-4"><a href="#cb3-4" aria-hidden="true"></a>free<span class="op">(</span>ptr<span class="op">);</span></span>
<span id="cb3-5"><a href="#cb3-5" aria-hidden="true"></a><span class="op">}</span></span>
<span id="cb3-6"><a href="#cb3-6" aria-hidden="true"></a><span class="co">// ...</span></span>
<span id="cb3-7"><a href="#cb3-7" aria-hidden="true"></a>free<span class="op">(</span>ptr<span class="op">);</span></span>A double free is a type of use-after-free vulnerability, where we deallocate memory that already has been freed. To understand why this is problematic, one must understand how heap memory is managed at runtime. To keep track of allocations inside a memory pool, a memory manager uses a data structure called free list. For example, a doubly linked list maintains a set of nodes representing unallocated memory regions. Calling malloc searches the free list for a node that fits the requested allocation size. If the node has more space available than requested, it will be split, unlinked and the remaining chunk becomes a new node in the free list (Habeeb, 2020). Calling free deallocates the respective chunk in the heap, linking a new node into the free list. As this action is not idempotent, double frees corrupt a program’s free list. If the free list contains multiple nodes refering to the same memory region, new allocations could easily corrupt valid memory regions, resulting in undefined behavior.
type-safety
<span id="cb4-1"><a href="#cb4-1" aria-hidden="true"></a></span>
<span id="cb4-2"><a href="#cb4-2" aria-hidden="true"></a><span class="co">// no implementated semantic meaning for + operator between int and str </span></span>
<span id="cb4-3"><a href="#cb4-3" aria-hidden="true"></a><span class="dv">1</span> <span class="op">+</span> “foo”<span class="op">;</span></span>
<span id="cb4-4"><a href="#cb4-4" aria-hidden="true"></a></span>
<span id="cb4-5"><a href="#cb4-5" aria-hidden="true"></a><span class="co">// calling function with wrong data type (int instead of float)</span></span>
<span id="cb4-6"><a href="#cb4-6" aria-hidden="true"></a>scale<span class="op">(</span>circle<span class="op">,</span> <span class="dv">2</span><span class="op">);</span></span>
<span id="cb4-7"><a href="#cb4-7" aria-hidden="true"></a></span>
<span id="cb4-8"><a href="#cb4-8" aria-hidden="true"></a><span class="co">// undefined out of bounds access</span></span>
<span id="cb4-9"><a href="#cb4-9" aria-hidden="true"></a><span class="dt">char</span> buf<span class="op">[</span><span class="dv">4</span><span class="op">];</span> </span>
<span id="cb4-10"><a href="#cb4-10" aria-hidden="true"></a>buf<span class="op">[</span><span class="dv">4</span><span class="op">]</span> <span class="op">=</span> ‘x’<span class="op">;</span></span>Programming languages are defined by syntax and semantics. Syntax is the specification of what constitutes a formally correct program. Developer learn syntax rules to combine symbols into valid language constructs (e.g. expressions, control structures, or statements). Semantics deal with the computational meaning of syntactically valid source code. At its core, type-safety tries to close the gap where source code is syntactically valid, but semantically flawed (Hicks, 2014).
A type-sytem is a part of the compiler or interpreter to ensure that programs do not “go wrong” (Milner, 1978). A type-system is built on primitive, composite, and abstract data types that abstract memory storage. The type of a variable determines how to store and interpret its binary representation in memory. Additionally, types are used to attach semantics to a piece of data. The process of type-checking verifies that all operations are compatible with its type. If the type-system detects a violation, it throws a type-error to prevent undefined program behavior. What constitutes a type error depends on the strictness of the particular type-system. Some type-systems require explicit type declarations and conversions, while others are more liberal (e.g. type inference, implicit type casts, etc.). Different type-systems provide different guarantees, but all are integral in validating the correctness of programs.
Please note: Complex type systems can do much more than data abstraction and preventing illegal operations. For example, Rust uses the type system to enforce memory and thread-safety guarantees.
thread-safety
concurrency bugs
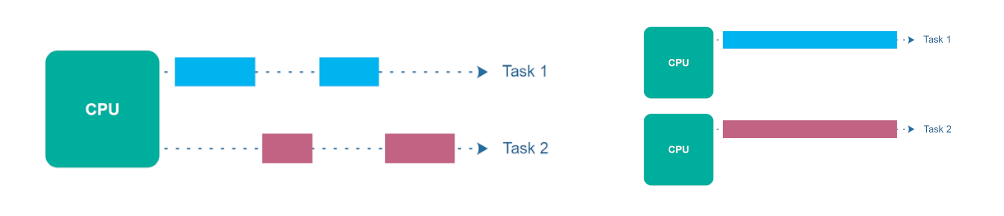
To leverage the computational power of modern multi-core systems, developers often turn to concurrency and parallelism. Parallelism is about the simultaneous execution of multiple things (Pike, 2012). Examples range from multi-threading on a single machine, to multi-processing and distributed systems. Concurrency structures a bigger computation by slicing it into independently executing things (Pike, 2012). If successful, concurrency enables us to deal with a lot of things at once (Pike, 2012).

Composing concurrent modules back together requires some form of communication, such as reading/writing to shared memory or by passing messages (MIT, 2021). Uncoordinated access to shared resources is dangerous, as unexpected and unwanted interactions between threads can affect program correctness (Hosfelt, 2019).
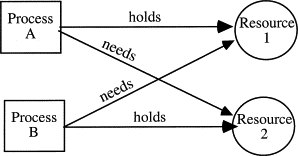
A deadlock is circular dependency between processes that hold locks to resources while waiting for others to release theirs. If the system is not able to detect and release these state, adversaries could deliberately trigger deadlocks to attack the availability of systems.
Your hardware is racy, your OS is racy, the other programs on your computer are racy, and the world this all runs in is racy. (Rustonomicon, 2021)
Race conditions are a fundamental part of computing and not necessarily malicious. Yet, the term mostly describes situations where non-deterministic timing causes a interlacing of operations, affecting the correctness of a program (Hosfelt, 2019). Data races arise when multiple parallel timelines (such as threads, processes, async callback chains) interfere with another by accessing the same memory location (and if at least one of them is a write) (Normand, 2019).
| Thread 1 | Thread 2 | Integer value | |
|---|---|---|---|
| 0 | |||
| read value | ← | 0 | |
| read value | ← | 0 | |
| increase value | 0 | ||
| increase value | 0 | ||
| write back | → | 1 | |
| write back | → | 1 |
Both are independent concepts, but there is considerable overlap in practice. The table shows how a combination of race condition and data race causes a lost update. Thereby we can infer that thread unsafety could be used to attack the integrity of systems (Hosfelt, 2019).
Thread-safe code coordinates the manipulation of shared data structures by synchronization via locks, semaphores or mutexes to prevent such unintended interaction. Unfortunately, developing concurrent code is hard, because humans think sequentially and read/write source code in a top to bottom flow (Frey et al., 2016). These natural biases lead to fallacy, that code is executed sequentially and independent of external influences. Besides being hard to reason about, concurrency bugs are notoriously hard to debug. By being a product of interaction, it is difficult to trace behavior back to its root cause in source code. Due to their time sensitive nature, the behavior of bugs tends to be nondeterministic, making them very difficult to reproduce. Running in debug mode, adding extra logging, or attaching a debugger affect relative timing between interfering threads, which may cause bugs to disappear.
example: time of check to time of use (TOCTOU)
<span id="cb5-1"><a href="#cb5-1" aria-hidden="true"></a><span class="co">// pass filepath as argument </span></span>
<span id="cb5-2"><a href="#cb5-2" aria-hidden="true"></a><span class="dt">int</span> main<span class="op">(</span><span class="dt">int</span> argc<span class="op">,</span> <span class="dt">char</span><span class="op">*</span> argv<span class="op">[])</span> <span class="op">{</span></span>
<span id="cb5-3"><a href="#cb5-3" aria-hidden="true"></a> <span class="dt">int</span> fd<span class="op">;</span></span>
<span id="cb5-4"><a href="#cb5-4" aria-hidden="true"></a> <span class="dt">int</span> size <span class="op">=</span> <span class="dv">0</span><span class="op">;</span></span>
<span id="cb5-5"><a href="#cb5-5" aria-hidden="true"></a> <span class="dt">char</span> buf<span class="op">[</span><span class="dv">256</span><span class="op">];</span></span>
<span id="cb5-6"><a href="#cb5-6" aria-hidden="true"></a></span>
<span id="cb5-7"><a href="#cb5-7" aria-hidden="true"></a> <span class="cf">if</span><span class="op">(</span>argc <span class="op">!=</span> <span class="dv">2</span><span class="op">)</span> <span class="op">{</span></span>
<span id="cb5-8"><a href="#cb5-8" aria-hidden="true"></a> printf<span class="op">(</span><span class="st">"usage: %s <file></span><span class="sc">\n</span><span class="st">"</span><span class="op">,</span> argv<span class="op">[</span><span class="dv">0</span><span class="op">]);</span></span>
<span id="cb5-9"><a href="#cb5-9" aria-hidden="true"></a> exit<span class="op">(</span><span class="dv">1</span><span class="op">);</span></span>
<span id="cb5-10"><a href="#cb5-10" aria-hidden="true"></a> <span class="op">}</span></span>
<span id="cb5-11"><a href="#cb5-11" aria-hidden="true"></a></span>
<span id="cb5-12"><a href="#cb5-12" aria-hidden="true"></a> <span class="co">// use syscall stat() to get information about this file</span></span>
<span id="cb5-13"><a href="#cb5-13" aria-hidden="true"></a> <span class="kw">struct</span> stat stat_data<span class="op">;</span></span>
<span id="cb5-14"><a href="#cb5-14" aria-hidden="true"></a> <span class="cf">if</span> <span class="op">(</span>stat<span class="op">(</span>argv<span class="op">[</span><span class="dv">1</span><span class="op">],</span> <span class="op">&</span>stat_data<span class="op">)</span> <span class="op"><</span> <span class="dv">0</span><span class="op">)</span> <span class="op">{</span> <span class="co">// <-- time of check</span></span>
<span id="cb5-15"><a href="#cb5-15" aria-hidden="true"></a> fprintf<span class="op">(</span>stderr<span class="op">,</span> <span class="st">"Failed to stat %s: %s</span><span class="sc">\n</span><span class="st">"</span><span class="op">,</span> argv<span class="op">[</span><span class="dv">1</span><span class="op">],</span> strerror<span class="op">(</span>errno<span class="op">));</span></span>
<span id="cb5-16"><a href="#cb5-16" aria-hidden="true"></a> exit<span class="op">(</span><span class="dv">1</span><span class="op">);</span></span>
<span id="cb5-17"><a href="#cb5-17" aria-hidden="true"></a> <span class="op">}</span></span>
<span id="cb5-18"><a href="#cb5-18" aria-hidden="true"></a> </span>
<span id="cb5-19"><a href="#cb5-19" aria-hidden="true"></a> <span class="co">// check if the file is owned by root, if yes print error</span></span>
<span id="cb5-20"><a href="#cb5-20" aria-hidden="true"></a> <span class="cf">if</span><span class="op">(</span>stat_data<span class="op">.</span>st_uid <span class="op">==</span> <span class="dv">0</span><span class="op">)</span></span>
<span id="cb5-21"><a href="#cb5-21" aria-hidden="true"></a> <span class="op">{</span></span>
<span id="cb5-22"><a href="#cb5-22" aria-hidden="true"></a> fprintf<span class="op">(</span>stderr<span class="op">,</span> <span class="st">"File %s is owned by root</span><span class="sc">\n</span><span class="st">"</span><span class="op">,</span> argv<span class="op">[</span><span class="dv">1</span><span class="op">]);</span></span>
<span id="cb5-23"><a href="#cb5-23" aria-hidden="true"></a> exit<span class="op">(</span><span class="dv">1</span><span class="op">);</span></span>
<span id="cb5-24"><a href="#cb5-24" aria-hidden="true"></a> <span class="op">}</span></span>
<span id="cb5-25"><a href="#cb5-25" aria-hidden="true"></a></span>
<span id="cb5-26"><a href="#cb5-26" aria-hidden="true"></a> <span class="co">// if not, open the file in readonly mode and do stuff</span></span>
<span id="cb5-27"><a href="#cb5-27" aria-hidden="true"></a> fd <span class="op">=</span> open<span class="op">(</span>argv<span class="op">[</span><span class="dv">1</span><span class="op">],</span> O_RDONLY<span class="op">);</span> <span class="co">// <-- time of use</span></span>
<span id="cb5-28"><a href="#cb5-28" aria-hidden="true"></a></span>
<span id="cb5-29"><a href="#cb5-29" aria-hidden="true"></a> <span class="co">// ...</span></span>
<span id="cb5-30"><a href="#cb5-30" aria-hidden="true"></a><span class="op">}</span></span>To an untrained eye, the implementation above looks plausible. However, the snippet (LiveOverflow, 2019) contains a race condition vulnerability, commonly called time of check to time of use (TOCTOU). Assuming isolated sequential code execution, the programmer expects that the file doesn’t change between checking for the ownership and opening it.
<span id="cb6-1"><a href="#cb6-1" aria-hidden="true"></a><span class="co">// winning the race</span></span>
<span id="cb6-2"><a href="#cb6-2" aria-hidden="true"></a><span class="co">// syscall SYS_renameat2 to swap two file paths</span></span>
<span id="cb6-3"><a href="#cb6-3" aria-hidden="true"></a><span class="cf">while</span> <span class="op">(</span><span class="dv">1</span><span class="op">)</span> <span class="op">{</span></span>
<span id="cb6-4"><a href="#cb6-4" aria-hidden="true"></a> syscall<span class="op">(</span>SYS_renameat2<span class="op">,</span> AT_FDCWD<span class="op">,</span> argv<span class="op">[</span><span class="dv">1</span><span class="op">],</span> AT_FDCWD<span class="op">,</span> argv<span class="op">[</span><span class="dv">2</span><span class="op">],</span> RENAME_EXCHANGE<span class="op">);</span></span>
<span id="cb6-5"><a href="#cb6-5" aria-hidden="true"></a><span class="op">}</span></span>Unfortunately for developers, hackers are in the business of identifying and violating expectations. The code snippet above is executed in parallel to the first code example. Using the SYS_renameat2 syscall, the attacker continuously swaps the file paths of two files, passing one of them to the program. If the timing is just right, the program calls stat() when the path refers to a file that passes the program’s security checks. If the adversary wins to race to swaps out file paths before time of use, he/she can inject any file-on-disk into the application.
layers of defense
After introducing memory-, type-, and thread-safety, it should be clear that developing secure code in unsafe languages is not trivial. Currently, there are three layers of defense.
language design
The first layer of defense is at the language level. One common approach is to address risks by limitation. Usually, modern safe programming languages rely on garbage collection (GC) to ditch the risks of manual memory management all together. For a majority of programming nowadays, this seems to be a reasonable choice. However, fields such as systems programming require low-level memory access, cannot afford performance overhead and nondeterministic runtime behavior (Szekeres et al., 2013). Another approach is are concepts like ownership to prove safety gurantees at compile time, avoiding many runtime costs.
C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do it blows your whole leg off.
Due to the vicious cycle of designing programming languages, C++ chose to extend an unsafe language. In (Stroustrup and Regehr, 2020) Bjrane Stoustup mentions, that once a programming language gains adoption, this results in a responsibility not to break code. Just think about the repercussions of breaking compatibility with billions lines of existing C/C++ code. This means that if you don’t get core language features right on the first try, you may have to live with suboptimal decisions for decades. The only option to rectify mistakes is to add a better version (e.g. smart pointers) to the language. However, without deprecation, you lose the mechanism to enforce these concepts. Now, language safety morphs from a technical into a communication issue. Millions of programmers must attend conferences and read guideline documents (Sutter and Stroustrup, 2021) to adopt the “modern” reincarnation of the language.
testing for security
The topic of language safety also affects the way we test software for security. Testing is an indispensable cornerstone in modern software development. With countless ways to test your software, it is important to choose strategies that deliver a high ROI, but also be aware of anti-patterns and blind spots.
peer review
Manual static testing is usually some variation of peer review. They are a great tool to combat developer tunnel vision and discuss abstract design decisions early in development. Following the motto “your strength is your weakness”, this social setting is fairly ineffective in uncovering language unsafety vulnerabilities. By nature, these bugs tend to be fairly complex, require security experience, time and high degrees of mental focus.
dynamic testing
With dynamic testing, we try to identify bugs by executing code and observing its behavior. A developer defines test cases, writes scripts and analyzes the test results. As most vulnerabilities result from bugs with error handling, unit testing is only informative with a sufficiently high degree of code coverage. A common mistake is to optimize for these quantifiable metrics, while misinterpreting their meaning (Leitner, 2017). Pointlessly testing for every edge in the control-flow-graph is tedious labor and provides a false sense of security. Code coverage helps to discover untested code, but is not a measurement of code quality (Fowler, 2012). To exclude a specific bug, you have to explicitly test for their absence. Therefore, language unsafty force developers to write more tests, which doesn’t scale well with the size of the codebase. Another strategy to alleviate some manual work and developer biases from the process of testing is fuzzing. Fuzz testing is a type of automated test that sends a wide range of inputs variants to all data interfaces of a program. The inputs are generated from known-to-be-dangerous values and random data. During execution, the program is monitored to see whether inputs are caught by error-handling or trigger unwanted behavior.
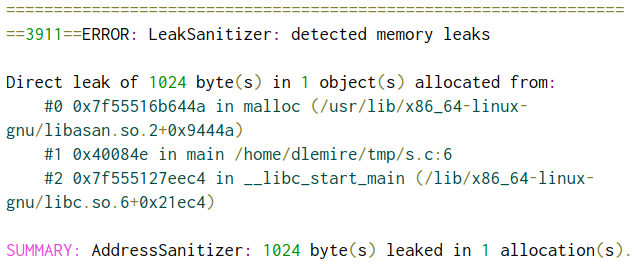
A program crash constitutes a clear indicator that a particular input has not been dealt with properly. Other vulnerabilities however are silent, making it difficult to distinguish from regular program behavior. To detect these cases, C/C++ compilers support instrumentation in the form of sanitizers. Sanitizers inject assertions into the application, track execution at runtime and report errors by deliberately crashing the program (Wikipedia contributors, 2021a). Sanitization should only be used during testing and debugging, as it comes with a considerable compute and memory overhead. (Wikipedia contributors, 2021a) list a series of sanitizers for different types of bugs:
- to detect memory related errors, such as buffer overflows and use-after-free (using memory debuggers such as AddressSanitizer),
- to detect race conditions and deadlocks (ThreadSanitizer),
- to detect undefined behavior (UndefinedBehaviorSanitizer),
- to detect memory leaks (LeakSanitizer), or
- to check control-flow integrity (CFISanitizer).
(Lemire, 2019) calls sanitizers a game changer and integral part in writing modern c++. Although fuzzing can be shockingly effective at discovering vulnerabilities, it can be a double-edged sword. It provides no guarantee that our software is safe, because “demonstrates the presence of bugs rather than their absence” (Wikipedia contributors, 2021a). Even with a capable fuzzing farm, fuzzing may take hours or days to complete. Additionally, the report provides little information on the cause of the detected bugs. Another downside with being “shockingly effective” is that as a dual-use tool, fuzzing can be utilized by adversaries as well.
operating systems
Language unsafety also affects the design of our operating systems. Post-hoc security mechanisms are often the last layer of defense. Prominent examples are Address space layout randomization (ASLR), Stack smashing protection (SSP) and Non-eXecutable (NX) to “protect” against buffer overflows.
ASLR mitigates buffer overflow attacks that overwrite the EIP register to a fixed memory address by adding randomizing the process’s memory layout.
SSP injects a secret value into every stack frame. If a malicious agent overwrites a routine’s return address, he/she will also alter the secret. Upon leaving a function, the current value is compared against the initial secret.
NX attempts to revoke the missing barrier between code and data. Memory pages containing code are tagged as executable and read-only, areas containing data as read/write and non-executable (Gisbert and Ripoll, 2014). The hardware is responsible for enforcing these policies when fetching instructions from memory.
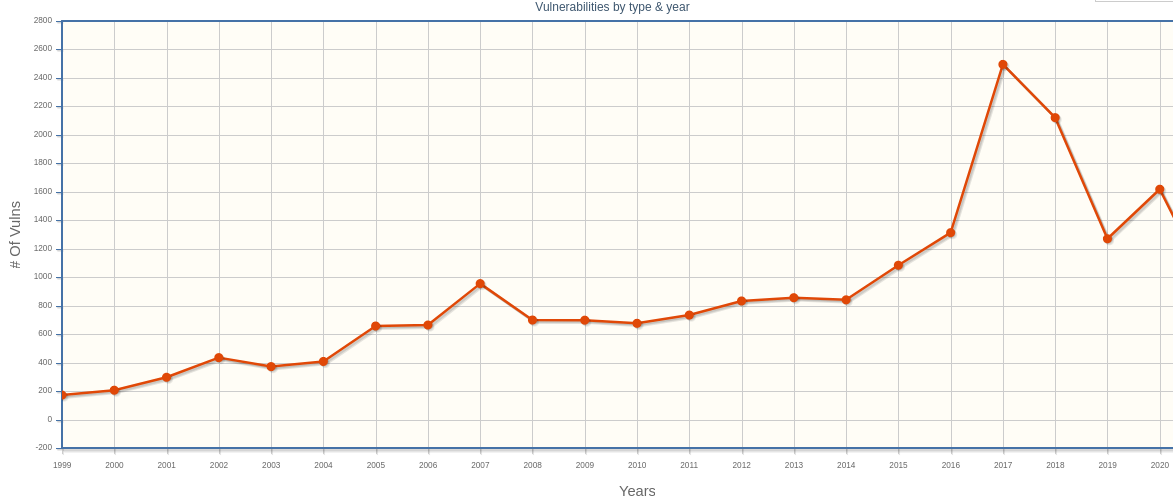
Post-hoc techniques merely increase the difficulty of exploitation rather than addressing the underlying issue of memory unsafety (Gisbert and Ripoll, 2014). According to (Gisbert and Ripoll, 2014), slight variations in the attack and weak implementations are the Achilles heel of these types of defense mechanisms. The CVE shows no reduction in the prevalence of overflow attacks, proving this strategy ineffective. The ongoing mentality to fix security issues inside the kernel is not sustainable in the long run (Lunduke, 2021). I believe these tools are symptomatic for optimizing around an issue that shouldn’t exist in the first place.
conclusion
[…] we’re in the midst of the greatest crisis of computer security in computer history. (Snowden, 2021)
In this article, we examined why producing safe programs using unsafe languages is hard. Bugs are highly prevalent even in the most professional code bases. However, most projects start as small internal or hobby projects. At early stages of development, resources are often highly constrained and primarily invested in adding functionality or address bug reports. Writing secure C/C++ absolutely requires a professional build pipeline to compensate for its lack of memory-, type-, and thread-safety. Without it, the project grows into a pile of insufficiently tested code. Treating security as an afterthought is a deadly fallacy. Finding vulnerabilities due to language unsafety is not an easy task, and many pull request were merged without proper review and discussion. The sheer scale of code makes it unlikely to combat the issue by manually writing tests. As a last resort, automated techniques like fuzzing are deployed and reveal a sea of bugs. Now it’s difficult to prioritize and there are usually not enough capable developers to cover all potential memory-, type-, and thread-safety vulnerabilities. If remaining vulnerabilities make it into production, post-hoc security mechanism have proven to be insufficient at catching and preventing their exploitation. Unfortunately, functional value is often the primary factor that drives adoption, as there are no metrics to measure the risks introduced by a dependency (Leitner, 2019). Most software nowadays is build on top of other software. If security is hard to get right, bugs may spread easily between software projects. This makes us highly vulnerable to supply chain attacks targeting the weakest link.
On top of that, technical weaknesses are amplified by bad organizational practices. Open-source contributions and use of dedicated security teams have the tendency to separate the entity that introduces a vulnerability from the one that fixes it. Without skin in fixing vulnerabilities, developer are desensitized to security issues, won’t be able to learn from their mistakes and repeat them in other projects (Leitner, 2017). Security must be an integral part of the development process. The only way to enforce this is if security issues prevent compilation. Another area for improvement is static analysis to inform developers about potential security hazards.

However, I fully acknowledge that the decision to develop in unsafe languages is most often a practical and economic choice. Regarding practicality, C/C++ has clear advantage of battle-tested libraries and interoperability with legacy systems. Still, every new line written in unsafe languages today, eventually becomes the legacy of tomorrow (Leitner, 2017). This ongoing mentality is what fuels our addiction for the last twenty years.
[…] are all happy to write code in programming languages that we know are unsafe, because, well, that’s what they’ve always done, and modernization requires a significant effort, not to mention significant expenditures. (Snowden, 2021)
I think Snowden hits the nail on the head. It is economically irrational to choose any other language, because it likely demands an investment on your part, rather than profiting from the work of others. Another problem is the vicious circle of adoption. Companies won’t invest in a technology unless there are enough trained developers to hire. Most companies cannot justify the cost of retraining on the job. On the other hand, most developers won’t learn a new language, if it doesn’t further their career. This stalemate significantly slows down the speed at which the ecosystems of emerging technologies mature.
Dennis Ritchie and Bjarne Stoustrup developed C/C++ at a time when digital warfare (government funded APTs) and a growing “insecurity industry” (legal and illegal for-profit hacking) were still science fiction rather than daily reality. Continuing the path of the last 20 years is nothing but an act of negligence. Unsafe programming languages are overwhelmingly used in critical infrastructure, industrial/financial applications and embedded devices. Moreover, the recent Pegasus scandal reveals how unsecure software affects journalists, human rights defenders and ultimately our democracy. They are a weapon in the hands of enemies that directly threatens our physical well-being. Therefore, they should be widespread interest in avoiding unsafe languages as much as possible. As much as we like to deny it, the choice of programming comes with a political responsibility.
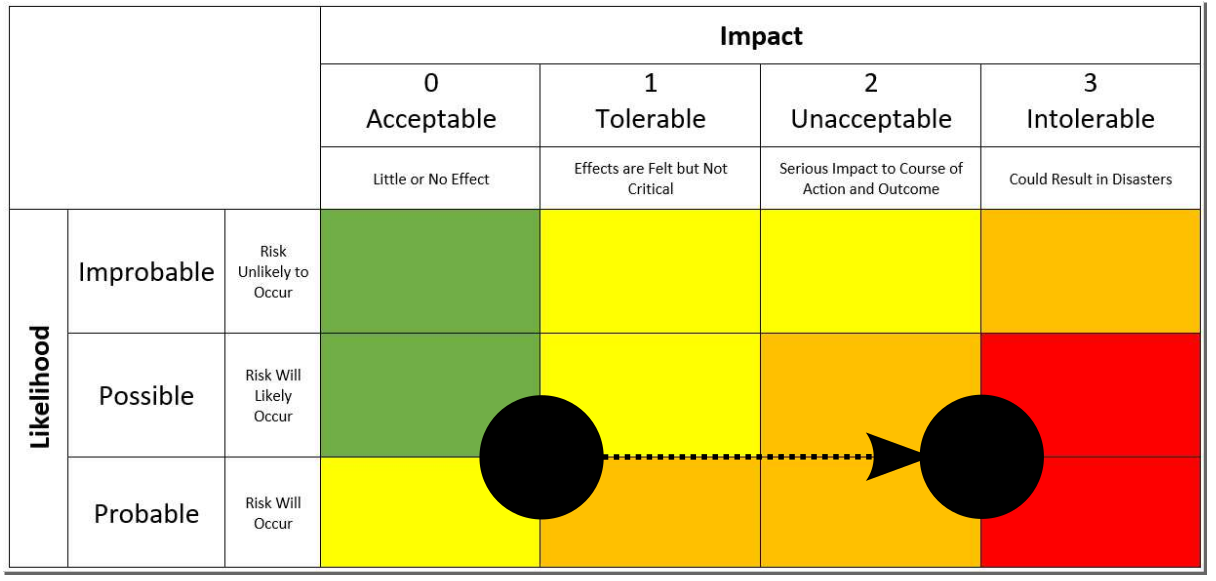
If you want to see change, you need to incentivize change. For example, if you want to see Microsoft have a heart attack, talk about the idea of defining legal liability for bad code in a commercial product. Where there is no liability, there is no accountability. (Snowden, 2021)
Personally, I believe that the only way to increase the traction of technical solutions is by causing a shift in the risk matrix. The software industries lack of liability for damages caused by its malformed products makes risks economically tolerable. To match the enormous risks carried by society, we must increase the industries skin in the game. I fully acknowledge that addressing technical issues with legal tools is always a slippery slope. Yet, to do it right, the push for regulation must come from within the developer community. Nobody likes to make his/her own job more difficult, but I strongly believe it’s a small price to pay.
Leave a Reply
You must be logged in to post a comment.