“Unbekannte infiltrieren Paketmanager npm und verseuchen Tools mit Schadcode” heißt es am 08.11.2021 auf heise online. Die Nutzeraccounts der Maintainer von coa und rc wurden gehackt und neue Versionen dieser Pakete hochgeladen (inklusive Malware). Zwar denken sich bestimmt viele bei coa und rc: “Aha toll”, aber spätestens bei React oder Angular sollte man hellhörig werden. Schließlich werden diese JavaScript-Frameworks Millionenfach genutzt. Und wer jetzt richtig geraten hat, ahnt schon: Beide dieser Frameworks nutzen diese Bibliotheken auf die ein oder andere Weise. Dieser Blockartikel beschreibt die Risiken von Software-Dependencies in Produktivsystemen und Wege, damit umzugehen.

Der Fall npm
Begriffserklärung: Dieser Artikel verwendet häufig die Begriffe Abhängigkeit/Dependency, Bibliothek/Library oder Paket/Package. Diese Begriffe werden im Kontext des Artikels gleichbedeutend verwendet und bezeichnen externe Software-Bausteine, die für die Erstellung neuer Software verwendet werden.
Wer schon einmal Software entwickelt hat, weiß, wie undurchsichtig Software-Dependencies sind. Ich benötige Package A, Package A benötigt wiederum Package B, C und D und ehe wir uns versehen, haben wir das ganze Alphabet abgearbeitet und unser Programm kann gerade einmal “Hello World” auf der Kommandozeile ausgeben.
Das folgende Bild zeigt die Dependencies und geschachtelten Dependencies einer neu erstellten React App und macht deutlich, dass es quasi unmöglich ist den Überblick über alle verwendeten Pakete und deren Ersteller zu behalten (Jeder Punkt stellt eine Dependency dar; das eigentliche Projekt und seine Dependencies sind gelb bzw. weiß hervorgehoben).
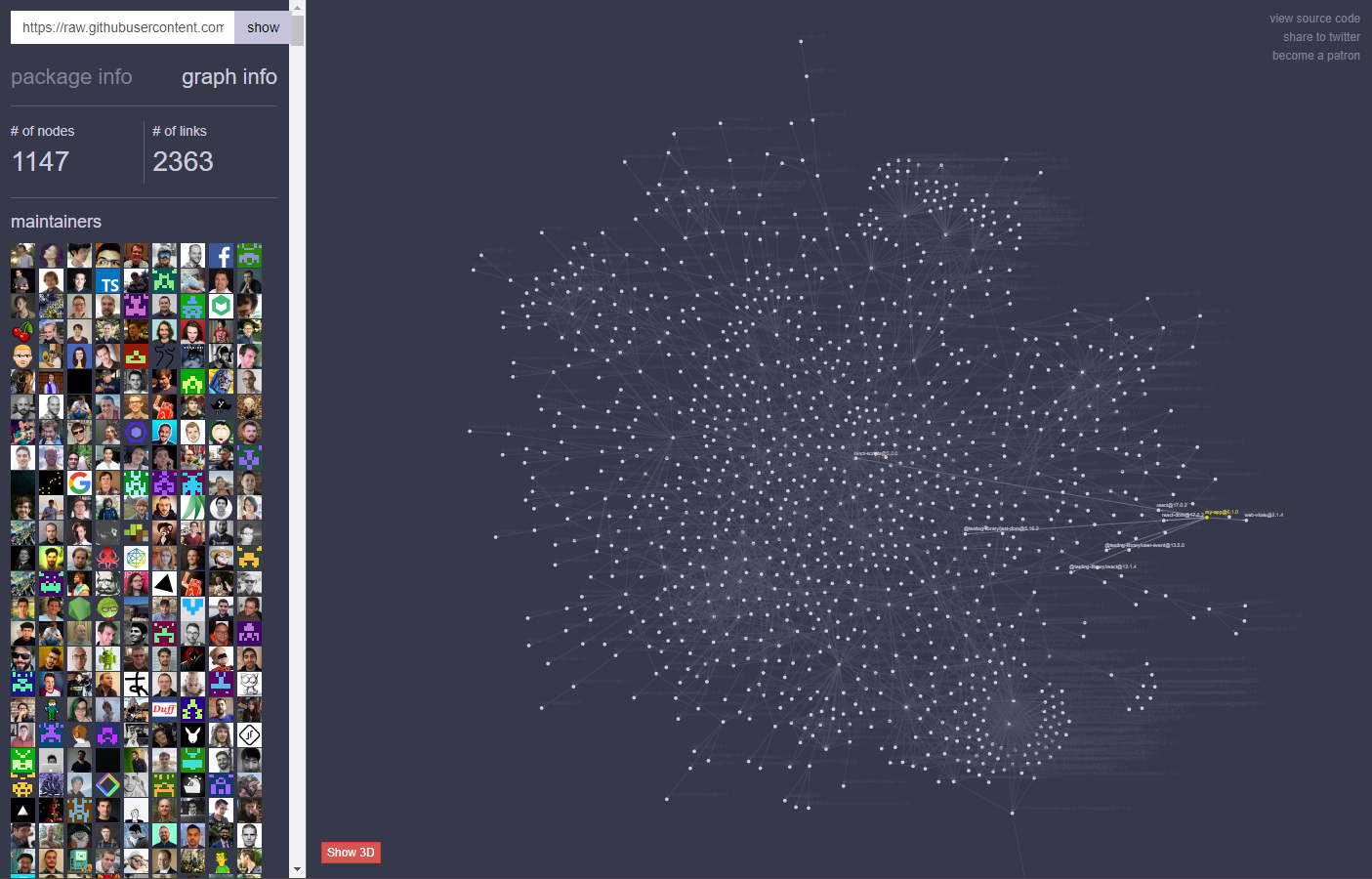
Im Fall von coa und rc war ich einer der ersten, der von diesem Problem erfahren hat. Zufällig habe ich in diesen ca. 2h versucht ein neues React-Projekt mit create-react-app anzulegen. Die Antwort von React war:
Error: Cannot find module '/Users/.../node_modules/coa/compile.js'Begriffserklärung: Bei npm handelt es sich um einen Paketmanager für JavaScript, ähnlich wie yarn, pip und im weiteren Sinn Maven. Die von npm bereitgestellten Packages werden dort von den Erstellern hochgeladen, versioniert und verwaltet. Nutzer können die dort liegenden Packages mittels “npm install” in ihre eigenen Projekte einbinden. Ein in npm angebotenes Package kann wiederum andere npm-Packages benötigen, um zu funktionieren.
Irgendwo in der Toolchain wurde auf das nicht existente Module compile.js im Package coa verwiesen. Im Github von create-react-app war die Diskussion schon im vollen Gange und recht schnell wurde klar: coa wurde kompromittiert. Genauso schnell begann die Diskussion, welche Folgen das haben könnte, denn bis dato wusste noch niemand, um welche Art Malware es sich handelt. Mittlerweile wissen wir, es handelt sich “nur” um den Qakbot-Trojaner, welcher beispielsweise Banking-Informationen von Privatnutzern auslesen soll.
Bei diesem Angriff handelt es sich weder um den ersten, noch um den letzten dieser Art. Erst im Monat vorher, wurde beispielsweise ua-parser-js mit demselben Trojaner kompromittiert. Und im Januar 2022 machte Marak Squires auf sich aufmerksam, als er seine eigenen, weit verbreiteten npm-Pakete faker und colors mit Schadcode versetzte, als Auflehnung gegen den Missbrauch von Open-Source Software.
Im Fall von faker und colors, waren die Ausmaße bereits verheerend. Die Bibliotheken haben zusammen fast 23 Millionen Downloads in einer Woche und über 21.000 Projekte, die auf diese Bibliotheken aufbauen. Von heute auf morgen können diese nicht mehr neu deployt werden. An dieser Stelle reden wir von einer Supply Chain Attacke. In diesen Fällen sind diese zwar nicht mit weitreichenden Folgen verbunden, sondern “nur” mit etwas Downtime. Im Vergleich dazu handelt es sich bei coa, rc und ua-parser-js um Supply Chain Attacken, die verheerende Ausmaße annehmen können.
Auswirkungen
Die möglichen Auswirkungen von solchen Attacken werden klar, wenn man sich über den Deployment-Prozess eines Unternehmens Gedanken macht. In modernen Softwareprojekten ist das Deployment (hoffentlich) automatisiert über sogenannte CI/CD Pipelines. Das bedeutet:
- Ich lade einen neuen Stand meines Quellcodes in die Versionsverwaltung des Projekts (Push).
- Eine Pipeline wird automatisch gestartet.
- In einem Testsystem wird der Build des Projekts ausgeführt (hierfür werden wieder alle Dependencies installiert)
- Tests werden ausgeführt
- Der Build wird in die Produktivumgebung geladen.
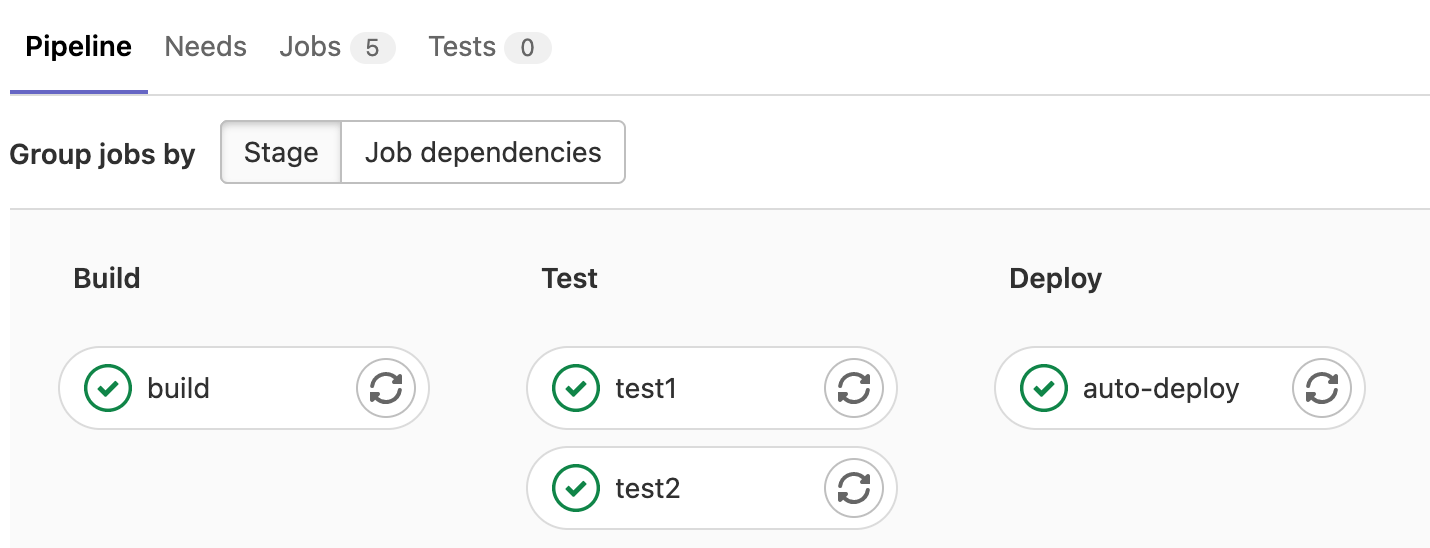
Ist in diesem Szenario eine kompromittiert Dependency enthalten, wird unter Umständen das ganze System infiltriert. Das könnte zum Beispiel dazu führen, dass sensible Daten mitgelesen oder geklaut werden. Sollte man so Zugriff auf Server erhalten, ist dieser anfällig für Remote Code Execution (RCE) Angriffe. Also ein Angriff, in dem ein Hacker Code auf dem Zielsystem ausführt. Das wird normalerweise durch Konfigurationen verhindert, könnte aber umgangen werden, wenn der Code Aufruf von innerhalb der Serverumgebung kommt.
Und selbst wenn nicht dieser Fall eintritt, kann eine fehlerhafte Dependency immer noch dazu führen, dass die konfigurierten Pipelines nicht mehr funktionieren und die Entwicklung zum Stillstand bringt (siehe Fall coa).
Letzten Endes sind die Auswirkungen davon abhängig, auf welchen Systemen die infiltriere Software landet.
Der erste Schritt, um sich abzusichern und in den meisten Fällen wohl auch gegangen wird, ist die Verwendung von Docker Containern oder VMs. Dadurch wird ein Neu-Deployment vereinfacht und (wahrscheinlich) verhindert, dass Zugriff auf unterliegende Systeme erlangt wird. In automatischen Build Pipelines ist das der Standard. Sich hierbei auf bewährte Systeme zu stützen, ist zwar erstmal gut, jedoch sollte man dem nicht blind vertrauen, wie der Fall von log4j 2021 gezeigt hat.
Das Problem mit Docker
Docker ist toll und hilft uns auf so vielen Ebenen, jedoch befürchte ich, dass es häufig leichtfertig verwendet wird. Es gibt viele Dinge, die beachtet werden müssen und Schritte, die man befolgen sollte, um sein. Ein paar Stichpunkte hierzu sind:
- Verwendung von Untrusted Images
- Verwendung von Multi-Stage Builds
- Leichtsinniges Volume-Mapping
Docker selbst klärt über die richtigen Schritte bei der Verwendung von Docker auf der eigenen Webseite auf und berichtet über Sicherheitslücken. Bei dem ersten Punkt landen wir wieder bei dem Anfang. Falsche Verwendung von Dependencies.
Punkt 2 ist elementar und sollte jeder Person, die mit Docker arbeitet, ein Begriff sein. Multi-Stage Builds helfen uns einerseits dabei, die Größe des finalen Images minimal zu halten und sorgen andererseits dafür, dass Dependencies nur in der Stage existieren, in der sie benötigt werden. (Und noch vieles mehr.)
Der dritte Punkt, kann alle bisherigen Schritte obsolet machen, denn gebe ich einem unsicheren Image die Möglichkeit auf den Host zu schreiben (an Orte an die er nicht soll), gebe ich auch einem möglichen Eindringling Zugriff auf das System. So könnte man sich beispielsweise über den Container Root-Rechte auf dem Host beschaffen. Darauf werde ich hier nicht weiter eingehen, da das schon genug andere vor mir getan haben (siehe trailofbits.com oder electricmonk.nl)
Es sind eine Menge “wenn-dann”s, die eintreten müssen, damit der Worst-Case eintritt, jedoch zeigt es auch, dass ein Eindringling mit recht wenig Aufwand (Hacken eines Accounts bspw. auf npm) Zugang zu einer Menge vertraulicher Daten oder sogar dem Host System erhalten kann.
Aus Versehen Open-Source?
Das folgende Bild zeigt die verschiedenen Lizenzen, der im oben visualisierten Abhängigkeiten einer neu erstellten React App.
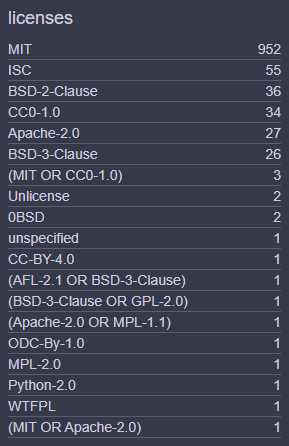
Das Problem hierbei ist, dass viele Entwickler sich keine Gedanken darum machen, welche Konsequenzen es haben kann Open-Source Software zu verwenden, wenn man die Lizenz nicht versteht. So gibt es zwar manche Lizenzen wie zum Beispiel die einmal verwendete WTFPL, welche einem buchstäblich alles erlaubt:
DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
[...]
0. You just DO WHAT THE FUCK YOU WANT TO.Andererseits gibt es aber auch Lizenzen wie die GNU Gerneral Public License (GPL), die Software, welche GPL-lizenzierte Software verwenden, verpflichten, diese ebenfalls und unter GPL zu lizenzieren. Ergo: Diese neue Software muss Open Source werden (Siehe copyleft).
Damit verbunden, sind auch Versions-Updates von Dependencies ein Problem, denn in ihnen kann die Lizenz verändert werden, sollten alle Entwickler einverstanden sein (siehe https://opensource.guide/de/legal/).
How to Dependency Management
Da wir jetzt alle enorm Panik um unseren Code mit 1 Million Dependencies haben, lohnt es sich Gedanken um die Lösung zu machen. Um zu vermeiden, dass unsere Software durch sich ändernde Dependency-Versionen kompromittiert wird, gibt es einige Wege sich zu schützen.
Schritt 1: Richtiger Einsatz von CI/CD und Docker
Zwar habe ich zuvor vor der falschen Verwendung von Build-Pipelines und Docker gewarnt, jedoch sind sie bei richtiger Verwendung zwei der wichtigsten Tools, um die Integrität unseres Systems sicherzustellen. Dieser Artikel soll keine Anleitung für die richtige Verwendung und Konfiguration von Build-Pipelines werden, das haben schon genug andere gemacht. Einen einfachen Einstieg auf praktischer Ebene bieten beispielsweise Gitlab CI/CD Pipelines oder GitHub Actions und als unabhängige Lösung natürlich Jenkins.
Für die etwas weiter gedachten theoretischen Aspekte lohnt sich ein Blick in das Google Buch Building Secure and Reliable Systems, in dem anschaulich verschiedene Ansätze, Muster und Prinzipien beim Bau von großen Systemen beschrieben werden.
Schritt 2: Verwendung von genauen Versionsnummern
Es ist einfach und intuitiv, eine Abhängigkeit in der neuesten Version zu installieren (@latest etc.). Man erhält die neuesten Security-Patches und den besten Funktionsumfang. Allerdings hat man so auch keinerlei Kontrolle darüber, sollte eine neue Software Malware enthalten.


Allerdings gibt uns auch das keine hundertprozentige Sicherheit. Gehen wir zum Beispiel nach dem Leitfaden von npm sollen wir die Versionsnummern ändern, sollten sich große Änderungen ergeben. Welche Änderungen wir als groß erachten, steht uns jedoch erst einmal frei (und dementsprechend auch möglichen Angreifern).
Um hier das Risiko möglichst gering zu halten, sollte Versionierung richtig verwendet werden. Dadurch wird einerseits in Konfigurationsdateien festgehalten, welche Veränderungen von Dependencies wir akzeptieren, und andererseits wird zu anderen Entwicklern kommuniziert, worauf geachtet werden muss. npm verwendet hierfür Semantik Versioning. Kurz zusammengefasst:
- 1.2.3: Wir befinden uns in Major Release 1, Minor Release 2 und Patch Release 3.
- Major Release: Enthält rückwärts inkompatible Veränderungen. Ein unbedachtes Update kann die Software kaputt machen. Ein Major Release mit Versionsnummer 0 bedeutet “unstable” und ist mit Vorsicht zu benutzen.
- Minor Release: Ist rückwärts kompatibel, kann aber neue Features enthalten (z.B. neue API-Funktionen)
- Patch Release: Ist rückwärts kompatibel, enthält aber Bugfixes, die ansonsten nichts an der Funktion ändern.
Möchte ich nun angeben, welche Änderungen der Dependencies ich als Nutzer akzeptiere, kann ich das über verschiedene Marker machen:
- >= 1.2.3 bedeutet so viel wie @latest, also alle Versionen größer gleich 1.2.3 wird akzeptiert (Egal ob sie kompatibel ist oder nicht).
- ^1.2.3 oder 1.x bedeutet, Minor-Releases werden akzeptiert.
- ~1.2.3 oder 1.2.x bedeutet, Patch-Releases werden akzeptiert.
Diese Syntax kann sich bei unterschiedlichen Package-Managern unterscheiden (z.B. Maven), die Funktionalität wird aber für gewöhnlich unterstützt.
Der nächste Schritt tiefer ins Rabbithole, ist die Betrachtung von verschachtelten Dependencies. Wie bereits erwähnt, benötigen auch die von uns verwendeten Bibliotheken wiederum andere Bibliotheken, um zu funktionieren (siehe Der Fall npm). Den Überblick zu behalten ist quasi unmöglich und dementsprechend auch, zu verstehen, wie geschachtelte Dependencies verwaltet werden und wie mit neuen Major-, Minor- und Patch-Releases umgegangen wird. Manche Package-Manager wie npm und yarn bieten uns sogenannte Lock-Files, in denen alle Versionen aller im Projekt enthaltenen Dependencies und Sub-Dependencies gelistet sind. Diese Dateien sind enorm wichtig, um die Reproduzierbarkeit unseres Programms zu garantieren und dafür zu sorgen, dass ein automatisierter Build das gewünschte Ergebnis produziert.
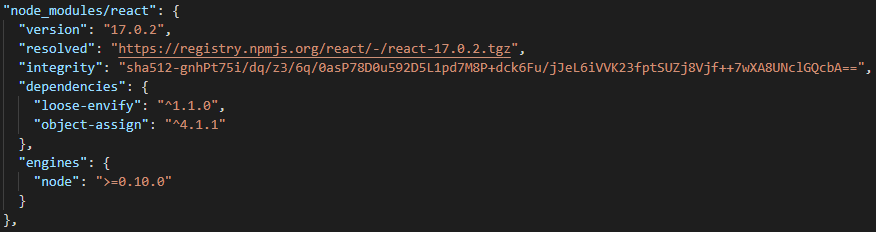
Im Bild sehen wir den Eintrag von des Package React im Lock-File einer React-App. Wir sehen neben der Versionsnummer außerdem die Punkte resolved, in dem beschrieben wird, von wo das Paket installiert und upgedatet wird und den Punkt integrity, welcher eine Checksum liefert, um die Echtheit des Pakets zu überprüfen.
Schritt 3: Mirror / Fork / Vendoring
Eine Möglichkeit sich vor ungewollten Veränderungen eines Pakets zu schützen ist sogenanntes Mirroring. Ich spiegel die von mir verwendeten Dependencies in einer eigenen Registry und lasse meine Programme nur noch von dort Pakete installieren. Diese Methode funktioniert für alle möglichen Arten von Dependencies, wie zum Beispiel Node-Modules (npm / yarn), Maven, Gradle oder auch Docker Images.
Aber wieso will ich meine eigene Registry für Dependencies, wenn es alles schon online vorhanden ist? Nun, neben den im Verlauf des Artikels bereits genannten Gründen:
- Was passiert, wenn eine korrumpierte Version hochgeladen wird?
- Was passiert, wenn sich die Lizenz ändert?
Folgen außerdem die Fragen:
- Was passiert, wenn die normale Registry nicht erreichbar ist?
- Was passiert, wenn der Besitzer der Dependency die Sichtbarkeit ändert?
Dazu kommt, dass in einem Dependency-Mirror auch Forks, also veränderte Versionen eines veröffentlichten Pakets bereitgestellt werden können, ohne diese veröffentlichen zu müssen. Das kann hilfreich sein, um sie an die Bedürfnisse des Unternehmens ideal anzupassen.
Außerdem bietet es den Vorteil, dass firmenintern geregelt werden kann, welche Pakete verwendet werden dürfen und welche nicht (Abhängigkeiten müssen genehmigt werden). Das klingt zwar zunächst lästig, bringt aber einiges an Sicherheit, gerade wenn unerfahrenere Entwickler an einem Projekt beteiligt sind.
Um also sicherzugehen, dass unsere Dependencies immer vorhanden und sicher sind, ist ein Mirror die beste Möglichkeit.
Am Beispiel von npm ist die Umsetzung recht einfach. Das Bild des Lock-Files zeigt im resolved-Feld auf die npm-Registry. Um diesen Link zu ändern, muss lediglich in der Konfigurationsdatei npmrc das entsprechende Feld angepasst werden. Um nun einen Mirror der npm-Registry zu erstellen, kann beispielsweise Verdaccio verwendet werden. Dabei handelt es sich um ein weit verbreitetes Tool für diesen Zweck und kann ohne viel Aufwand in einer modernen Serverumgebung gehostet werden.
Für die anderen genannten Dependency Manager / Registries existieren ebenfalls mehr oder weniger verbreitete Tools, um einen Mirror zu realisieren.
Schritt 4: Monitoring
Um das Lizenzproblem in Angriff zu nehmen, hilft es sich zu informieren, welche Lizenzen existieren und eine Whitelist mit akzeptierten Lizenzen zu erstellen. Da das schnell sehr unübersichtlich werden kann (siehe Aus Versehen Open-Source), kann es sich lohnen, hierfür externe Anbieter zu nutzen. GitLab bietet hierfür direkt ein Licence Complience Tool für seine CI/CD Pipelines an oder man setzt auf externe Anbieter wie Snyk. Diese Tools erlauben es automatisiert auf Lizenzprobleme testen zu lassen und bieten Hilfe bei Unklarheiten, sowie der Möglichkeit zur eigenen Konfiguration.
LinkedIn beschreibt in einem eigenen Blogartikel außerdem den Umgang mit Software-Dependencies in einem globalen Umfeld und beschreibt dabei eine neue Lösung, Probleme zwischen Software Dependencies zu erkennen und Schwachstellen zu überwachen.
Globale Schritte gegen das Problem
Die anfangs genannten Fälle haben neben Panik um die eigene Software auch die Frage aufgerufen, wer haftet, wenn Malware durch Software Dependencies verbreitet wird oder falsche Lizenzen verwendet werden. Der Package-Manager? Die Versionsverwaltung? Der Publisher? Ich selbst?
Letzten Endes ist diese Frage nicht geklärt, aber im Zweifel immer der Endnutzer. Zwar werden die Stimmen lauter, dass große Unternehmen hierfür zur Rechenschaft gezogen werden müssen, oder zumindest für eine schnelle Lösung für bereiten können, jedoch geht jeder Nutzer selbst durch die Verwendung von Drittsoftware ein Risiko ein, das er automatisch durch Akzeptieren der Lizenz in Kauf nimmt.
Um die Sicherheit bei der Verwendung von Software-Dependencies zu verbessern, findet schon seit längerem ein Umschwung statt. So unterstützt Maven schon lange Zeit das LATEST-Tag nicht mehr und genau aus diesen Gründen etablieren sich Systeme wie Docker, CI/CD etc.
Um das eigene Unternehmen in eine gute Position zu bringen, lohnt es sich, die in diesem Artikel beschriebenen Techniken umzusetzen und sich stets auf dem Laufenden zu halten. Um die Position nach innen und außen zu stärken ist es womöglich sinnvoll sich nach Qualitätssicherungsnormen wie ISO 9001 zertifizieren zu lassen.
Weitere Quellen
- https://www.heise.de/news/Unbekannte-infiltrieren-Paketmanager-npm-und-verseuchen-Tools-mit-Schadcode-6260153.html
- https://engineering.linkedin.com/blog/2018/09/managing-software-dependency-at-scale
- https://forums.swift.org/t/dependency-mirroring-and-forking/13902
- https://github.com/advisories/GHSA-g2q5-5433-rhrf
- https://github.com/advisories/GHSA-73qr-pfmq-6rp8
- https://github.com/veged/coa/issues/99
- https://vsupalov.com/docker-latest-tag/#:~:text=You%20should%20avoid%20using%20the,apart%20from%20the%20image%20ID.
- https://dl.acm.org/doi/pdf/10.1145/3277539.3277541
- https://github.com/facebook/create-react-app/issues/11620
- https://www.infoq.com/articles/securing-docker/
- https://www.tuvsud.com/de-de/dienstleistungen/auditierung-und-zertifizierung/iso-9001#:~:text=Die%20Basis%20daf%C3%BCr%20ist%20die,Dienstleistungsqualit%C3%A4t%20zu%20erf%C3%BCllen.
- https://www.youtube.com/watch?v=g-JgA1hvJzA
- https://www.ezequiel.tech/2020/05/rce-in-cloud-dm.html
- https://npm.anvaka.com/#/
Leave a Reply
You must be logged in to post a comment.