Ein Projekt von Kai Kustermann, Michael Litschko, Sarah Mauff und Sebastian Köpp
Einleitung
Im Sommersemester 2022 haben wir uns als 4-köpfige Gruppe dazu entschlossen, einen Google Geodata Visualizer zu erstellen. Das Projekt ist aus der Idee einer McDonald’s-Achievement-Card entstanden. Die Idee war eine Website, die dem Benutzer anzeigt, welche McDonald’s Filialen der Nutzer, gemäß den über seinen Google Account gesammelten Standortdaten, jemals besucht hat. Im weiteren Verlauf wurde die Kernidee, Standortdaten aus Google Accounts zu verarbeiten, insoweit verallgemeinert, als dass das Endprodukt daraus besteht, an einem bestimmten Tag den zurückgelegten Weg, die besuchten Orte und die gesamte Strecke – u. A. unterteilt in Verkehrsmittel – anzuzeigen.
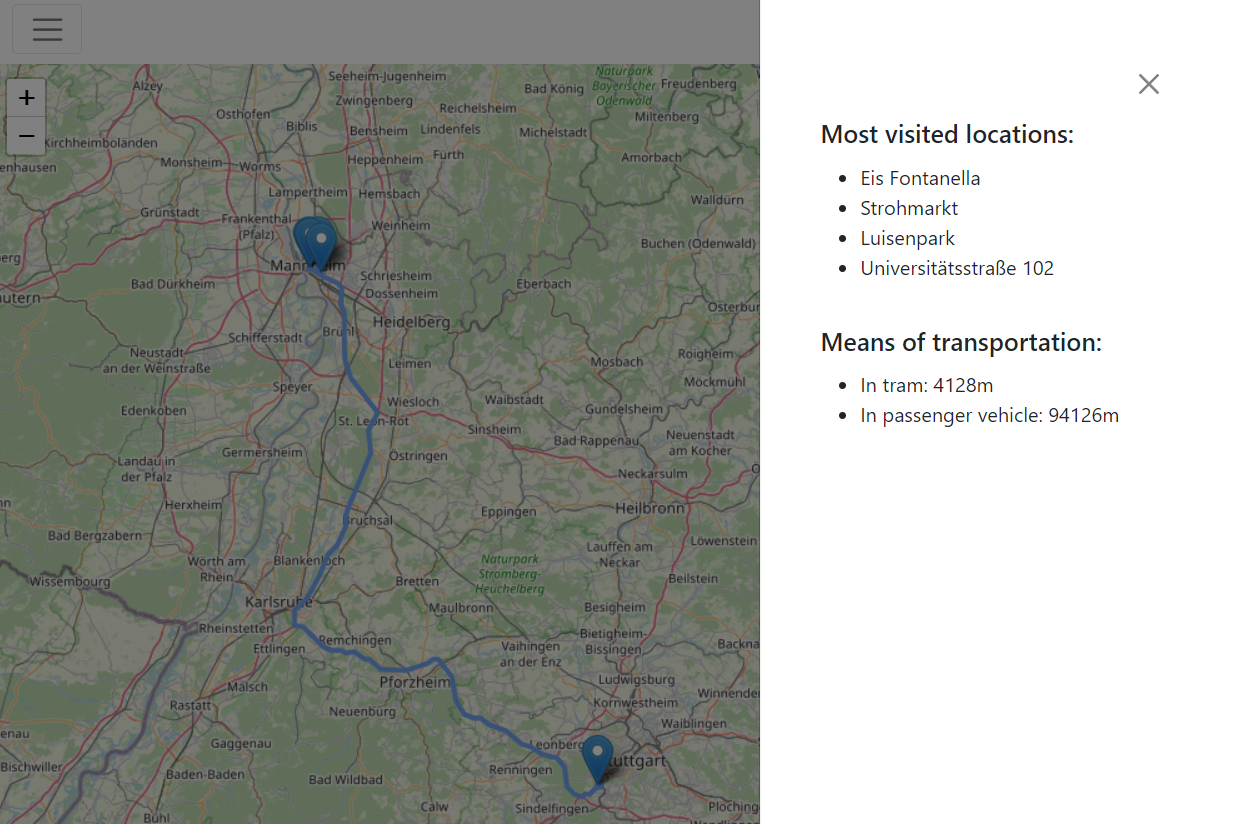
Zunächst lädt der Benutzer dazu seine lokal gespeicherten Standortdaten aus seinem Google Account hoch. Hier ist zu erwähnen, dass die Einstellung, Standortdaten zu erheben, über einen bestimmten Zeitraum eingeschaltet gewesen sein muss, sodass überhaupt verwendbare Daten existieren. Nach Hochladen der Standortdaten hat der Nutzer nun die Möglichkeit über Klick auf das linke Hamburger-Menu, seine Strecken und besuchte Orte nachzuverfolgen. Um die Auflistung abzurufen, klickt der Nutzer auf das rechte Hamburger-Menu. Dort sieht er nun auch die hauptsächlich genutzten Verkehrsmittel mit dem dazugehörigen Streckenanteil. Auch kann durch die Karte sowohl navigiert, als auch hinein- und herausgezoomt werden.
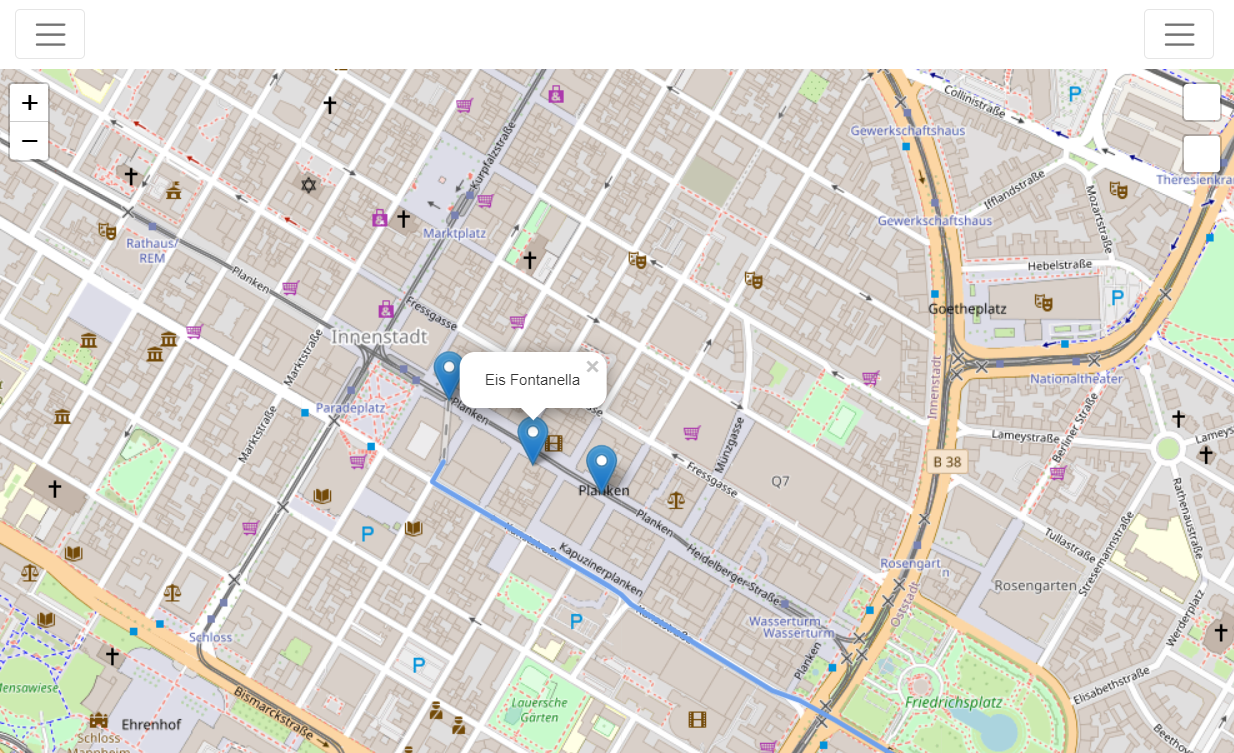
Die Website kann über https://miclit131.github.io/ aufgerufen werden.
Architektur
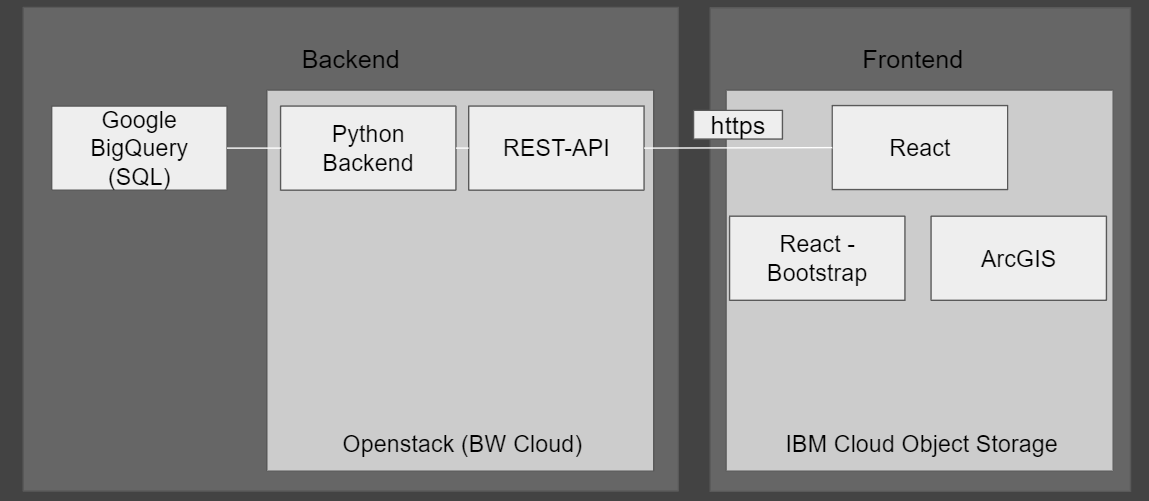
Die obige Grafik stellt unseren ersten Plan einer Architektur dar, den wir nach und nach geändert haben. Im Folgenden gehen wir darauf ein, warum wir uns für welche Technologien entschieden haben.
Vergleich von Technologien die zur Auswahl standen
- BW Cloud vs Serverless (FaaS)
BW Cloud ist ein IaaS System, basierend auf Openstack. Die Idee war es, dort unser Backend zu hosten, da wir bereits Erfahrungen damit im Team hatten. Allerdings ist der Aufwand, ein Backend in der BW Cloud zu hosten, sehr groß. Die IBM Functions sind dagegen sehr leicht einzurichten und es muss kein Server gehostet werden. Deswegen haben wir uns für die Functions entschieden. - Big Query vs Cloudant
Wir haben ein Tutorial gefunden, in dem Google Location Daten in Big Query gehostet wurden. An diesem wollten wir uns orientieren und unsere Datenbank auch in Big Query hosten. Wir haben uns schließlich dagegen entschieden, da wir keine relationalen Daten haben und somit eine nicht relationale Datenbank völlig ausreicht. Als nicht relationale Datenbank haben wir Cloudant genommen, da es ein IBM Service ist und somit mit den anderen Services, die wir nutzen, gut kombinierbar ist. - IBM Object Storage vs Github Pages
Github Pages ermöglicht es, statische Websites direkt aus einem Git Repository zu verwalten bzw. zu hosten. Jedoch gibt es hier Limits: Die Website darf nicht größer als 1 GB sein und die Bandbreite ist auf 100 GB pro Monat limitiert.
IBM Cloud Object Storage ermöglicht das Hosten von statischen Websites per Cloud Object Storage und den Build von cloud-nativen und serverlosen Apps mit Website.
Wir haben uns für Github Pages entschieden, da es die einfachere der beiden Optionen war und die Limitationen für unsere Zwecke voraussichtlich nicht relevant sind. - ArcGis vs react leaflet
ArcGis ist ein cloudbasiertes Tool zur Bereitstellung interaktiver Karten – allerdings ist es nicht kostenlos.
Leaflet ist eine funktionsreiche Open Source JavaScript Library – in unserem Fall für OpenStreetMap (inklusive Open Source Routing Machine).
Wir haben uns für Leaflet und OpenStreetMap entschieden, da es kostenlos ist.
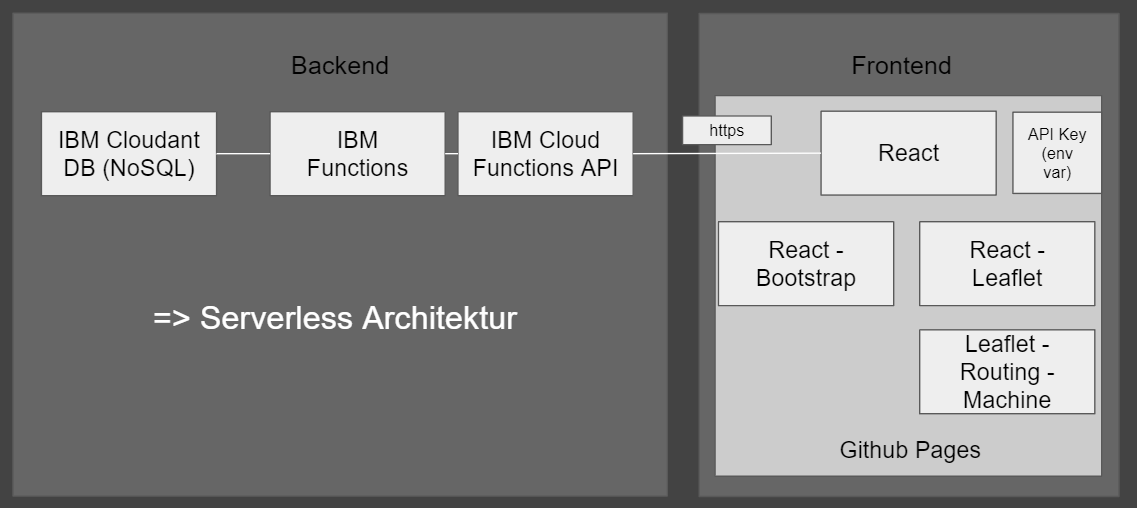
Obige Grafik stellt die endgültige Architektur unseres Projekt dar.
Hochladen der Daten
- In das Frontend werden die Daten hochgeladen
- Die Daten werden vom Frontend an eine API gesendet
- Die API spricht IBM Functions an, welche die Daten verarbeiten und in die Datenbank laden
Lesen von Daten
- Das Frontend sendet einen Request an die API
- Die API führt Functions aus
- Die Functions laden Daten aus der Datenbank mithilfe einer Query
- Die Daten werden von der API zurück an das Frontend gesendet
- Das Frontend stellt diese dar
Frontend
Im Frontend haben wir verschiedene Technologien verwendet. Zunächst basiert unser Programm auf React. Als CSS Framework haben wir uns für Bootstrap entschieden, da es einfache Dokumentationen bietet und schlussendlich als erstes funktioniert hat 😀 (siehe Punkt “Probleme”).
Um überhaupt eine Karte einbinden zu können, haben wir Leaflet verwendet – speziell react-leaflet. Leaflet ist eine Open Source Library für interaktive Karten – also sehr passend für unseren Use Case.
Da Leaflet selbst aber kein Kartenmaterial bereitstellt, haben wir eine Karte von OpenStreetMap eingebunden, was zu unserer Erleichterung sehr einfach ablief. Kleiner Funfact: OpenStreetMap ist ein Projekt aus dem Jahr 2004, welches zum Ziel hat, eine freie Weltkarte zu erstellen und allen zur Verfügung zu stellen.
Unser Anwendungsfall beinhaltet die Darstellung der zurückgelegten Strecken auf der Karte, weshalb wir einen Service für das Routing in Leaflet benötigten. Wir haben uns für Leaflet Routing Machine entschieden, eine Bibliothek für Leaflet, welche speziell für diesen Anwendungsfall erstellt wurde. In die Leaflet Routing Machine ist die Open Source Routing Machine als Standard integriert, es können aber viele weitere Routing Engines, wie TomTom Online Routing API, Esri oder GraphHoppper verwendet werden. Diese Routing Engines werden hauptsächlich dazu verwendet, um kürzeste Wege zwischen zwei Standorten zu bestimmen.
Aktuell verwenden wir den Demoserver der Open Source Routing Machine. Hier kann man in Zukunft Verbesserungen vornehmen und einen eigenen Server aufsetzen.
Zusammenfassend hatten wir trotz kleiner Anfangsschwierigkeiten schlussendlich Glück mit der Wahl unserer verwendeten Technologien im Frontend.
Backend
Zur Umsetzung unseres Backends haben wir uns für IBM Cloud Functions entschieden.
IBM Cloud Functions ist ein Service, über den man Code dezentral auf den Servern von IBM ausführen lassen kann (FaaS). Es gibt auch alternative FaaS Anbieter wie zum Beispiel AWS Lambdas. Wir haben uns aber für IBM entschieden, da unsere Datenbank auch ein IBM Service ist und somit die Kompatibilität der Funktionen und der Datenbank gewährleistet ist.
Unsere Applikation soll ein Frontend haben, welches Daten in eine Datenbank schreibt und diese liest. Das Backend könnte man klassisch über ein Backend lösen, das zusammen mit dem Frontend deployed wird. Stattdessen haben wir uns aber für ein Backend entschieden, welches in der Cloud gehostet wird. Dadurch können wir das Frontend komplett vom Backend abkoppeln. Wir müssen uns auch nicht um das Deployment kümmern, da dies bereits von IBM gemanagt wird. Zudem ist die Skalierung sehr gut.
Mit IBM Cloud Functions kann man den Code direkt in eine HTTPS-API integrieren, welche auch über die IBM Cloud gemanagt wird. Es gibt auch schon vorgefertigte API Calls zu anderen IBM Services, wie z.B. Cloudant, welches wir für unsere Datenbank benutzen. Somit müssen wir diese nicht selbst schreiben.
Unser Backend muss folgende Dinge können:
Auslesen der Google Location Data und umwandeln in Datenbankobjekte
Die JSON-Datei, die wir von Google bekommen, beinhaltet mehr Informationen als die, die wir benötigen. Wir werden nur die relevanten Daten in die Datenbank hochladen. Wir unterscheiden zwischen zwei Typen:
- Location: Ein einzelner Ort, der an einem Datum besichtigt wurde.
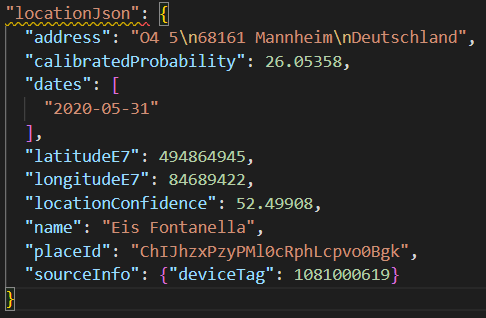
DielatitudeE7undlongitudeE7Felder sind die aufgezeichneten Koordinaten, über die wir die Location auf der Karte darstellen können - Path: Eine Route, die an einem Datum zurückgelegt wurde. Enthält auch Informationen über die Wahrscheinlichkeit des Transportmittels.
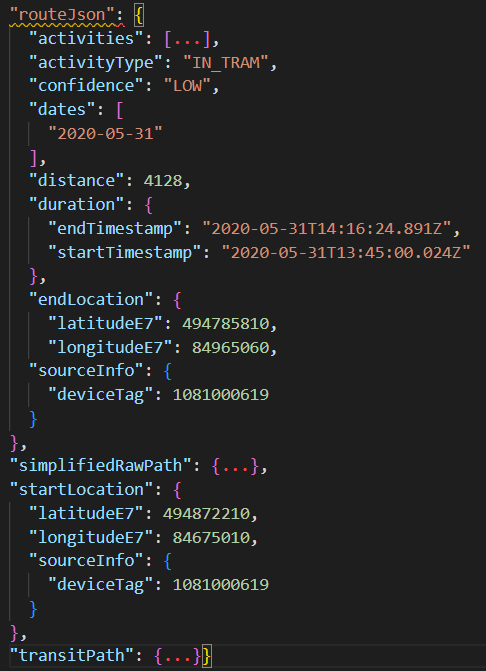
Die FelderstartLocationundendLocationwerden genutzt um eine Route über leaflet-routing-machine zu generieren. In den activities sind alle möglichen Fortbewegungsmittel mit ihrer jeweiligen Wahrscheinlichkeit enthalten. Dadurch können bei der Routenfindung unterschiedliche Wege bevorzugt werden.
Einzelne Objekte in die Datenbank hochladen
Dazu muss eine Verbindung mit der Datenbank hergestellt werden. Das Datenbankobjekt bekommt außerdem noch eine SessionID über die wir es später einem Nutzer zuordnen können. Zum Hochladen einzelner Objekte gibt es bereits eine von IBM bereitgestellte Funktion für Cloudant Datenbanken.
Hinzufügen von SessionID zum Objekt
Wenn wir Objekte in die Datenbank speichern, müssen wir immer eine SessionID mitgeben über die wir später auf die Objekte eines Nutzers zugreifen können. In dieser Aktion wird eine SessionID dem Objekt hinzugefügt.
Mehrere Objekte auf einmal in die Datenbank hochladen
Dies verläuft ähnlich wie die vorherige Aktion, mit dem Unterschied, dass mehrere Objekte auf einmal hochgeladen werden. Dafür mussten wir eine eigene Funktion schreiben, da wir die bereits bereitgestellte Funktion für Cloudant nicht verwenden konnten. Dazu nutzen wir die von IBM bereitgestellte Javascript Library für Cloudant.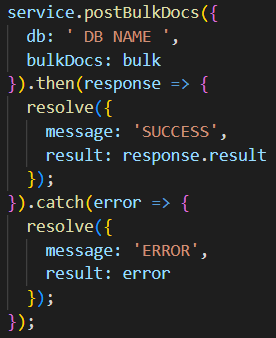
Datenbankabfrage von Objekten anhand von Datum und SessionID
Unser Frontend benötigt alle Locations und Paths für einen bestimmten Tag. Dazu können wir wieder eine bereits bereitgestellte Funktion verwenden. Dieser geben wir das Datum und die SessionID vom betroffenen Nutzer mit.
Aufbauen eines Query Objekts
Damit wir die vorherige Abfrage tätigen können, müssen wir ein Query-Objekt mitgeben. Dieses muss aus SessionID und Datum aufgebaut werden.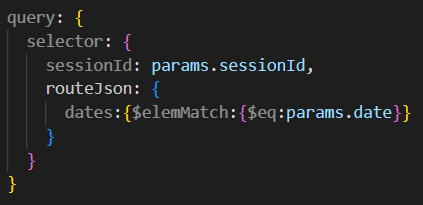
Bei den IBM Functions werden diese einzelnen Abschnitte als Aktionen definiert. Das ist einfach der Code mit einem Input und mit einem Output. Diese Aktionen können dann einzeln ausgeführt werden oder aber auch in Sequenzen hintereinander. Dabei ist der Output der vorherigen Aktion der Input der darauffolgenden.
Aus den obigen Aktionen können wir folgende Sequenzen erstellen:
- Auslesen der Google JSON → Hochladen mehrere DB Objekte
- Hinzufügen von SessionID → Hochladen eines einzelnen DB Objekten
- Aufbauen eines Query Objektes → Datenabfrage von DB Objekten
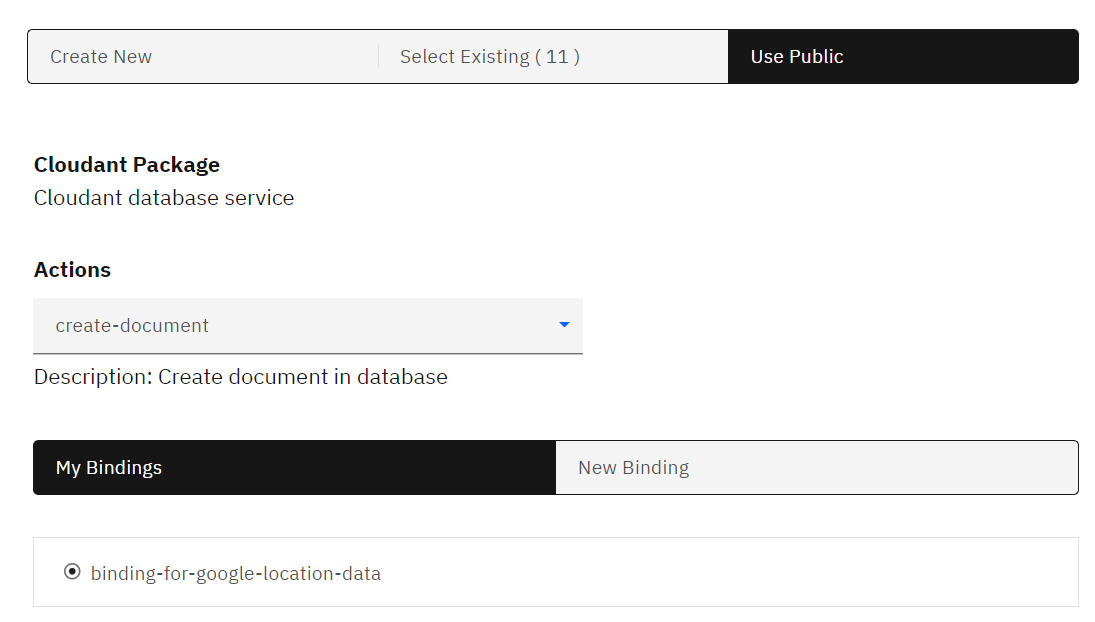
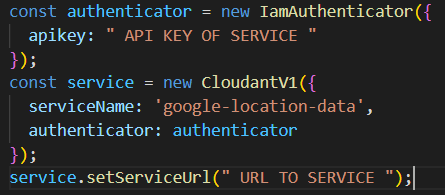
Um auf unsere Datenbank zugreifen zu können, müssen wir einen API Key erstellen.
Dieser wird entweder über die Cloudant Aktion mitgegeben, oder wir müssen den Schlüssel beim manuellen Aufbau der Verbindung mitgeben.
Das Ausführen von Aktionen in Sequenzen erleichtert das Austauschen von Code-Abschnitten. Wenn z.B. ein neuer Datenbank Service genutzt werden soll, tauscht man einfach die Aktion, die die Objekte auf die Datenbank schreibt, aus.
API
Damit wir unsere Sequenzen aus dem Frontend einfach über HTTP-Requests ansprechen können, müssen wir diese einem API Endpunkt zuordnen. Diesem API-Endpunkt können Parameter mitgegeben werden, die der Input für die erste Aktion in der angesprochenen Sequenz sind.
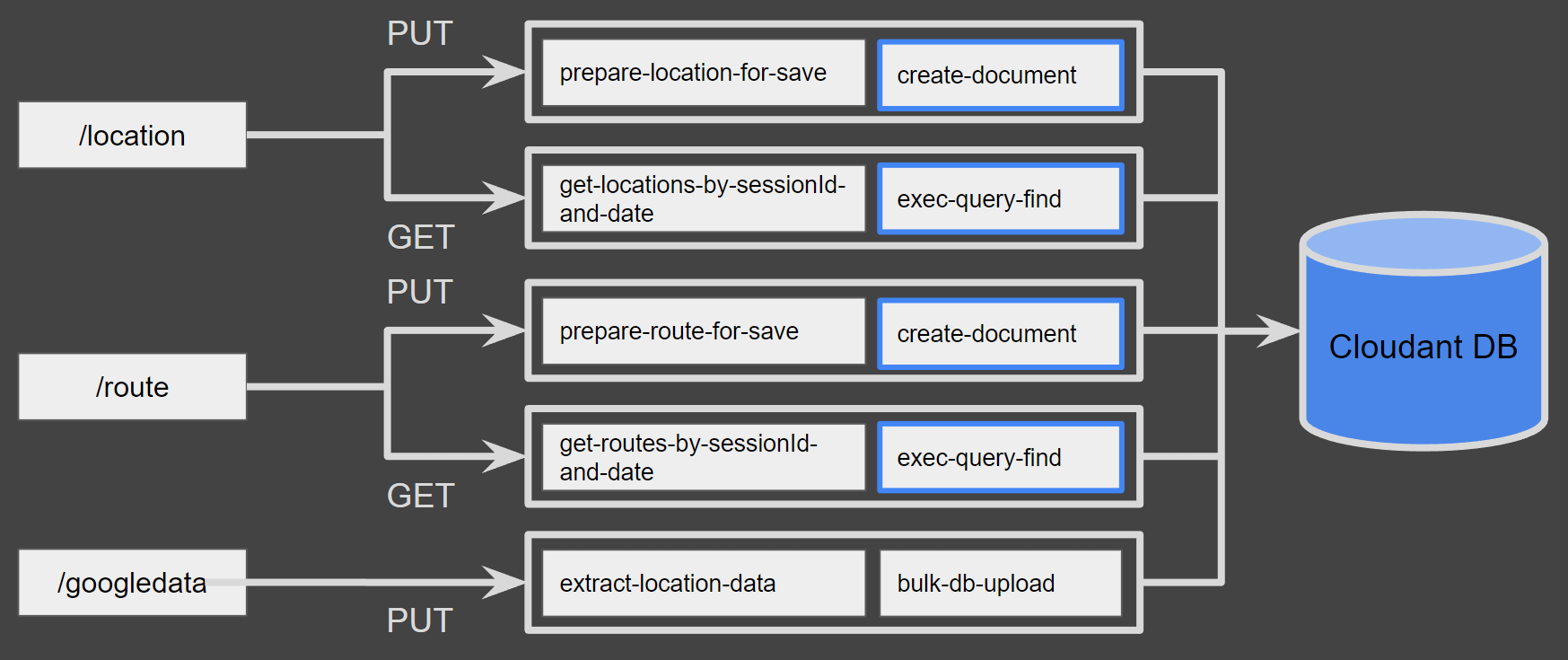
Die Aktion bulk-db-upload haben wir selbst geschrieben, da wir keine vorgefertigte Funktion gefunden haben. Allerdings gibt es in der Javascript Cloudant API eine Möglichkeit, mehrere Objekte auf einmal hochzuladen.

Testing
Durch das Testen von Software soll sichergestellt werden, dass diese die zuvor definierten Anforderungen erfüllt. Testing von Software kann auf verschiedenen Ebenen erfolgen. Neben E2E-Tests, welche die Software auf einem hohen Level aus Nutzersicht testen sollen, gibt es Integrationstests und Unit-Tests, welche die Qualität der Software auf tieferen Ebenen sicherstellen. Während auf allen Ebenen Testautomatisierungen umgesetzt werden können, sind diese vor allem auf den unteren Ebenen, also im Integrations- und Unit-Testing, zu finden. Im Zuge der vermehrten Nutzung von automatisierten Tests, sowie dem Aufstieg der agilen Entwicklungsmethodik ist in den letzten Jahren der Ansatz der testgetriebenen Entwicklung entstanden. Anders als in der klassischen Softwareentwicklung, werden dabei die Tests vor dem Programmcode geschrieben. Dies hat den Vorteil, dass eine sehr hohe Testabdeckung erreicht werden kann und Fehler frühzeitig in der Entwicklung entdeckt werden können. Die Vorteile von automatisierten Tests im Vergleich zu manuellen Tests sind, dass eine geringere Fehlerquote und eine höhere Testabdeckung mit demselben Aufwand erreicht werden können. Im Rahmen des DevOps-Gedankens kann durch die Integration automatisierter Tests in eine CI/CD-Pipeline zudem eine höhere Auslieferungsgeschwindigkeit erreicht werden. Im Umfeld von Cloud Projekten ist es von besonderer Bedeutung externe Cloud-Services, zu welchen eine Abhängigkeit besteht, zu testen.
In unserem Projekt haben wir sowohl Unit-Tests als auch Integrationstests in Form von API-Tests umgesetzt, um die Qualität der Software sicherzustellen. Das Backend, also die Cloud Functions, sowie die Interaktion der Functions mit der Cloudant Datenbank, wurden über API-Tests mithilfe der Open Source Javascript-Library Frisby getestet. Für die einzelnen Cloud Functions wurden keine Unit-Tests entworfen, da die Qualität dieser über das Testen der einzelnen API-Endpunkte sichergestellt wird. Mithilfe von Frisby ist es möglich, über den Testrunner Jest API-Tests durchzuführen. Die PUT-Methode sowie die GET-Methoden können mithilfe von Testdaten, die gleich wie die realen Daten aufgebaut sind, automatisiert getestet werden. Die Antworten der Endpunkte werden mithilfe von assertions der Bibliothek Frisby sowie der Bibliothek joi für die Datenvalidierung überprüft.
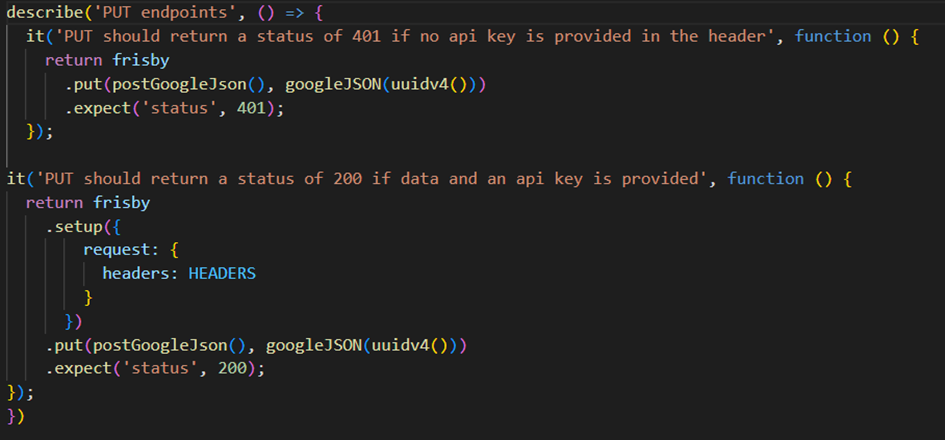
In der Abbildung sind beispielhaft zwei Testfälle für einen PUT-Endpunkt dargestellt. Im ersten Testfall wird überprüft, ob der HTTP-Statuscode 401 zurückgegeben wird, wenn im HTTP-Header kein valider API-Key angegeben wird. Im zweiten Testfall wird überprüft, ob bei einer validen PUT-Anfrage der Statuscode 200 zurückgegeben wird.
Neben API-Tests wurden zudem Unit-Tests für das Frontend entworfen, um einzelne UI-Komponenten zu testen. Diese wurden mit react-testing-library implementiert. React-Testing-Library ist eine leichtgewichtige Bibliothek, um React-Komponenten zu testen. Ziel ist es, die Komponenten auf ähnliche Art und Weise zu testen, wie der Endnutzer mit ihnen interagieren würde. Hierzu bietet die Bibliothek die Möglichkeit, direkt auf DOM-Elemente zuzugreifen.
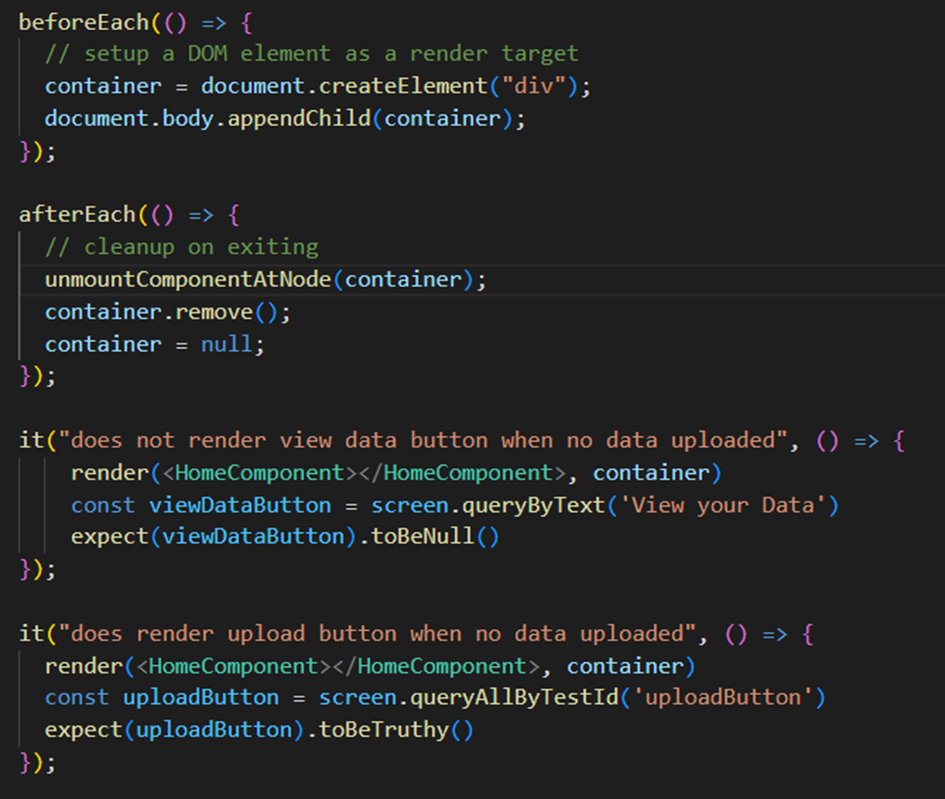
Beispielhaft sind zwei Testfälle der Komponente HomeComponent dargestellt. In der beforeEach-Funktion wird ein HTML-Element erzeugt, in welchem später die HomeComponent gerendert wird. Daraufhin wird der erste Testfall definiert, in welchem sichergestellt wird, dass kein Text „View your data“ dargestellt wird. Im zweiten Testfall wird überprüft, ob der Upload Button mit der TestId „uploadButton“ korrekt angezeigt wird. Tests ähnlicher Art wurden für verschiedene, wichtige Komponenten des Frontends entworfen, um das korrekte Verhalten der Komponenten sicherzustellen.
Deployment
Die grundlegende Idee war zunächst, dass Deployment und App getrennt voneinander betrachtet werden. Während sich ein Team um das Frontend kümmerte, befasste sich eine andere Gruppe um die Kubernetes-Umgebung. Hierzu wollten wir zu Beginn die bwCloud verwenden, welche auf OpenStack basiert, einem Tool zum Aufsetzen von VM-Maschinen. Hierbei mussten grundlegende Infrastruktur-Bestandteile eingerichtet werden. Hierzu gehörten Router, welche Floating-IP-Adressen freigeben, welche von der Cloud aus der Uni Mannheim heraus unseren Service öffentlich machen sollten. Zudem zählte dazu eine Verbindung zum externen Ingress Controller der VM von Kubernetes aus, welche nicht von der Firewall blockiert wurde. Des Weiteren mussten mehrere Nodes aufgesetzt werden, um die Struktur von Master und Worker Nodes umzusetzen. Zu all dem kam dann noch das Problem, dass wir mit OpenStack noch nicht gearbeitet hatten, aber Kubernetes aus einem bereits eingerichteten Netzwerk kannten, was zur Folge hatte, dass einfache Dinge Probleme bereiteten. Hierzu zählte zum Beispiel das Einrichten eines SSH-Zugriffs auf eine Openstack VM oder das Aufsetzen von Monitoring Tools und Kubernetes mit kubectl und CUDA GPU Support. Auch beim Debugging auf einer externen Maschine ohne Interface oder eingerichtetem Ingress mussten wir uns über Portforwarding, Kubernetes Event Logs und Curl-Befehle aushelfen. Die Fehlermeldungen von Kubernetes waren für uns teilweise ein wenig schwierig zu interpretieren. So kann ein ImagePullBackOff Fehler zum Beispiel sowohl an Credentials, falschen Settings oder Firewall-Regeln liegen.
Je mehr wir uns mit dem Thema auseinandersetzen, desto eher merkten wir, wie viel eigentlich zu einem funktionierenden Cluster bis hin zum bare metal Bereich gehört, welches wir aus anderen Vorlesungen kaum bis gar nicht kennengelernt hatten.
Da immer mehr Schwierigkeiten anfielen, entschieden wir uns vorerst dazu, das Frontend direkt über eine PaaS-Lösung, IBM Cloud, zu deployen. Das Backend und die Datenbank benötigen kein Deployment, da beides in der IBM Cloud läuft.
Der Plan war es, das react-basierte Frontend in eine statische Website mit einer index.html zu konvertieren und alle Ordner in ein Bucket im IBM Cloud Object Storage hochgeladen. Danach kann der Entrypoint für die Webseite eingetragen und die Website in der IBM Cloud gehostet werden. In den Einstellungen können nun die Sichtbarkeit und Sicherheitsvorkehrungen vorgenommen werden.
Bei dem Deployment des Frontends in IBM Cloud Object Storage kam es jedoch leider zu Problemen, da React-Anwendungen nicht ohne weiteres in eine statische Website umgewandelt werden können. IBM unterstützt im Object Storage nur Node.js und anderweitige Backend Frameworks, weshalb wir uns dann letztendlich nach dem Ausprobieren unterschiedlicher Lösungen für GitHub Pages entschieden haben.
GitHub Pages lässt nicht kommerzielle, statische Webseiten schnell deployen, in unserem Fall über npm-Befehle. Github Pages unterstützt neben React zum Beispiel Docker, Jerkyl und html. Es sollte beachtet werden, dass das Repository auf public gestellt werden muss, damit Github Pages funktioniert. Für das Deployment haben wir uns an diesen Guide gehalten https://www.c-sharpcorner.com/article/how-to-deploy-react-application-on-github-pages/ .
Bis auf die Struktur des Repository-Namen, mussten nur einige kleine Änderungen in der package.json vorgenommen werden, um die Webseite über npm run deploy, mit einer funktionierenden CI/CD zu veröffentlichen. Für Deployments für kommerzielle Zwecke sollte man jedoch die größere Cloud-Anbietern verwenden. Unsere Anwendung wird voraussichtlich aus Sicherheitsgründen nur bis zum 10.10.2022 unter https://miclit131.github.io/ erreichbar sein, da jede Webanwendung verwaltet werden sollte falls Schwachstellen auftreten (zum Beispiel in verwendeten Libraries und npm-Packages).
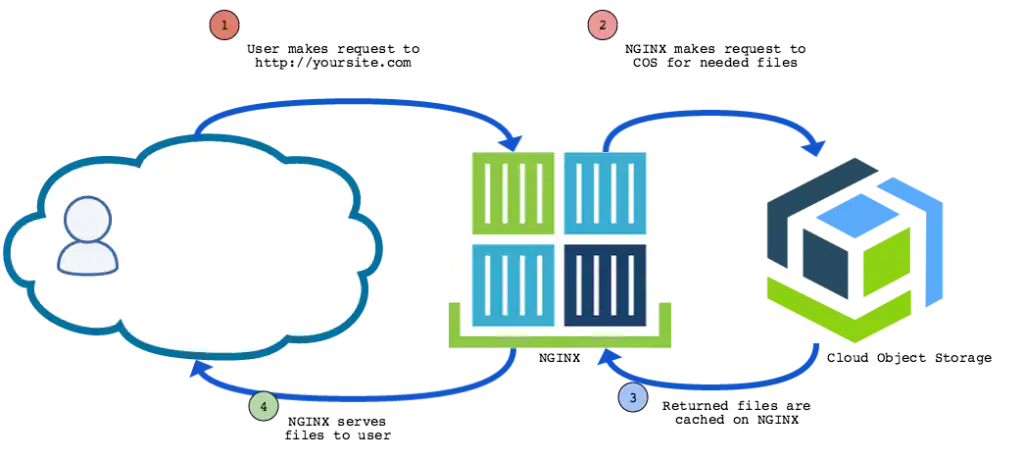
https://www.ibm.com/cloud/blog/static-websites-cloud-object-storage-cos
Über die Struktur sparen wir nun den ganzen Aufwand, eine Infrastruktur aufzubauen und erhalten mit nur wenigen Klicks eine öffentliche Webseite. Gerade für Start-ups ist ein Cloud Modell geeignet, da keine Serverkosten anfallen und nur die tatsächliche Nutzung gezahlt wird. Zudem wird kein größeres Infrastruktur Team benötigt, welches das Monitoring, Security und Einrichten übernimmt.
Probleme
- Material UI als CSS Framework: Wir planten, Material UI einzusetzen, da es eine gute Integration in React Apps versprach, jedoch funktioniert diese aus unbekannten Gründen nicht.
- Grenzen des kostenlosen Cloudant Plans:
Wir benutzen für unsere Datenbank den kostenlosen Plan von Cloudant, da es sich um ein Studentenprojekt handelt. Leider hat dieser Plan eine Limitierung von 5 Queries pro Sekunde. Damit stoßen wir an unsere Grenzen, da im schlechtesten Fall nur 5 Nutzer parallel unsere Seite nutzen können. - Frontend Deployment in IBM Cloud für dynamische Webseiten, kein React index.html support
Fazit / Lessons Learned
Während dem Projekt haben wir viele verschiedene Dinge gelernt. Durch den Architekturentwurf zu Beginn des Projektes konnten wir uns mit verschiedenen Technologien und Architekturmustern im Cloud-Umfeld auseinandersetzen. Während wir zuerst durch das Aufsetzen eines Kubernetes Clusters auf der IaaS-Ebene arbeiten wollten, entschieden wir uns letztendlich dafür, das Backend serverless zu gestalten. Hierbei lernten wir den Umgang mit der IBM Cloud, speziell den IBM Cloud Functions, sowie der nicht relationalen, verteilten Datenbank Cloudant kennen, welche von IBM als cloud-basierter Service bereitgestellt wird. Des Weiteren konnten wir den Umgang mit aktuellen Web-Technologien und Frameworks wie React und Bootstrap vertiefen und einiges in Richtung Routing und Kartendarstellung im Web-Umfeld lernen.
Leave a Reply
You must be logged in to post a comment.