Table of Contents
- What you will not read about
- Introduction
- Why do we want it?
- Why Language Models in APR?
- What may the future bring?
What you will not read about
Many times before and in plenty of other articles, the how’s and why’s behind the transformer architecture and the attention mechanism have been discussed. To me, it’s clear, that the original paper Attention is all you need (Ashish Vaswani 2017) might as well be one of the most influential papers in the history of deep learning, thus far. That said, a summary of the functionality cannot be provided here, since this would go beyond the limits of this article. Intentionally, it has been written, such that only basic prior knowledge in the field is necessary, to grasp the gist of this article. Nevertheless, especially with the importance of the underlying architecture for the mentioned models, reading up on the topic is worthwhile. Following are two resources, that may explain to you the most important parts or provide you a deep dive into the topic:
- Comprehensive summary of the original paper:
- Deep dive into the nitty-gritty details:
Introduction
New research from Rollbar, the leading continuous code improvement platform, indicates that the overwhelming majority (88%) of developers feel that traditional error monitoring falls short of their expectations. The December survey of 950 developers also reveals that fixing bugs and errors in code is developers’ No. 1 pain point. (Black 2021) This is the first paragraph of a research summary by businesswire and I think many of us would agree with the last statement. The study states further, that 32% of developers spend up to 10 hours a week to fix bugs and some others exceed even that. It is also suggested by the study, that respondence to errors affects productivity, moral and even quality of life.
Why do we want it?
The incentive to automate fixing of bugs is clear, if we look at those statements. With bug fixing taking up to a quarter of an average working week for a third of developers, it is quite obvious why companies would want such assistance. Leaving the lost potential of the coding workforce aside, we all can think of a scenario in which we spend hours upon hours to find a bug in our code, that may end up being just a missing semicolon. For those lucky people not knowing what I’m talking about: “May the force be with you.” – Yoda.
Why Language Models in APR?
Programming code can be described as a sequence of commands that a computer can understand. The instructions in code can involve various operations like control flow (conditionals, loops, etc.), data manipulation, calls to predefined functions… That we all learned in the first week of our first semester.
The limitations on potential results of the execution are almost limitless. Hardware limitations aside, what stops programmers from solving a problem may only be their understanding of the problem, its complexity or the creative challange of finding a solution. (Heck, we even wrote code that resulted in a language model that very well may be capable of writing a text, as the one you are reading right now, given you asked the correct questions to create it.) Going back to the very beginning of this chapter. Natural Language (NL) could be described very similarly. Both follow three important aspects:
- Syntax: NL and PL have strict rules that govern the structure and organization of their expressions.
- Comprehension: Reviewing lines of PL or reading a sentence of NL, both require comprehension of the read expressions, to make sense of them.
- Communication: Both, NL and PL are means of communication. They convey information, express ideas and enable the transmission of instructions or concepts, from one entity to another.
Because of the structural similarities, Large Language Models (LLM) have been adjusted and trained with that thought in mind or fine-tuned to fulfill the task of automated error detection and correction, also called Automated Program Repair (APR). Even tough there are plenty of other approaches to solve APR ((Asha Kutsa 2019), (Matsumoto and Nakamura 2021), (K K Sharma 2014), …), especially with the point of comprehension in mind, LLM’s are deemed to be advantegeous in that field.
Nowadays, there are multiple well-trained LLM’s capable of providing assistance in bug-fixing and offering ideas to improve code correctness or readability. For this article though, we will focus on two: ChatGPT v4 (OpenAI 2023) and CodeBERT (Zhangyin Feng 2020).
CodeBERT vs. ChatGPT
CodeBERT is specialized in processing and enhancing various aspects of programming code, aiming to comprehend, generate, and improve code-related tasks like summarization, completion, and translation. In contrast, ChatGPT’s primary objective lies in enabling natural language interactions and generating human-like responses in diverse conversational scenarios. Although ChatGPT can understand code, its core purpose centers around facilitating interactive and coherent conversations with users.
Notably, CodeBERT could just be downloaded from huggingface, e.g. provided by Microsoft. The same cannot be said about the model of ChatGPT.
CodeBERT
Source considered: (Chunqiu Steven Xia 2022)
BERT (Bidirectional Encoder Representations from Transformers) architecture is highly relevant in LLM as it pioneered pre-training and fine-tuning, leading to remarkable performance in various natural language processing tasks. Utilizing this architecture, the researchers introduce AlphaRepair. A cloze-style APR approach, leveraging large pre-trained models.
Goals
The aim is to directly generate patches for software bugs without the need for fine-tuning on historical bug fixes, overcoming the limitations of existing learning-based APR techniques and achieving improved performance on real-world systems in multiple programming languages. Similar to the paper (Dominik Sobania 2023), researchers used, together with other datasets, the QuixBugs dataset (Derrick Lin 2017) to conclude its capability. For comparability, we will focus on their evaluation using the QuixBugs dataset.
Training
Pre-training:
CodeBERT is a pre-trained language model that was trained on a large corpus of publicly available source code from diverse open-source projects. By using a hybrid objective combining the concepts of masked language modelling (MLM) and replaced token detection, it learned to predict masked tokens in code snippets, gaining a deep understanding of code semantics and structures. This makes CodeBERT a powerful multilingual, bidirectional LLM.
Fine-tuning:
Different from ChatGPT, CodeBERT didn’t undergo any kind of specific fine-tuning for the purposes of the researchers’ paper. While they mention, that fine-tuning on the specific task of APR, their goal was to evaluate the zero-shot capability of CodeBERT base model.
Targeted Use Case
The original paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, as the name suggests, mostly cared about natural language. CodeBERT’s aim on the other hand was to “[…] turn a buggy code into a fixed version.”; (Chunqiu Steven Xia 2022), page 2. An important idea to point out is, that they don’t try to model what a repair should look like, but rather figure out what is intended to be there in the first place, given the surrounding context information.
Success and Service
The researchers splitted the questian in success into three:
- How does AlphaRepair compare against state-of-the-art APR tools?
AlphaRepair outperforms state-of-the-art APR tools in perfect fault localization, generating correct fixes for 74 bugs and fixing the unique bugs (14). It handles challenging cases that other tools struggle with, introducing a promising direction for Automated Program Repair. - How do different configurations impact the performance of AlphaRepair?
The ablation study on AlphaRepair evaluated different components’ impact on its performance. It found that using template mask lines and encoding the buggy line significantly improved the number of correct patches. Additionally, the patch re-ranking strategy proved effective in prioritizing higher-ranked correct patches. - What is the generalizability of AlphaRepair for additional projects and multiple programming languages?
AlphaRepair demonstrates impressive generalizability for additional projects and multiple programming languages. It outperforms other baselines on Defects4J 2.0, achieving the highest number of correct patches (36, 3.3X more than the top baseline). AlphaRepair’s multilingual repair capability is showcased on the QuixBugs dataset, achieving the highest number of correct patches in both Java and Python, making it a versatile and robust tool. It solves 28 of 30 Java bugs and 27 of 32 in Python.
The researchers state multiple times, that the importance lays in the underlying understanding of the model for code. With the MLM in place, the model didn’t learn fix bugs persée. Rather, the model was trained to inherently understand code and being able to predict what is supposed to be there, given the surrounding context. Thus, it was never primed, to focus only on the task of APR specifically, which is what they highlight for its generalizability.
ChatGPT
Source considered: (Dominik Sobania 2023)
Goals
The goal of this work is to quantify the ability of the standard ChatGPT model, in terms of its ability to identify and fix errors in code. The researchers used the QuixBugs dataset (Derrick Lin 2017) to conclude its capability.
Training
ChatGPT was trained using a two-step process: pretraining and fine-tuning
Pre-training:
ChatGPT was pretrained on a vast and diverse corpus of publicly available internet text to learn grammar, syntax, and a broad understanding of language. To handle this large-scale pretraining, it uses a variant of the Transformer architecture called GPT, which employs self-attention mechanisms for generating coherent responses by understanding word relationships.
Fine-tuning:
After pretraining, ChatGPT undergoes fine-tuning on a more specific dataset tailored to the target tasks or domains. This process refines the model’s language understanding and generates relevant responses by learning from human feedback, resulting in improved performance through iterative training. Unfortunately, the datasets used for fine-tuning the resulting model are not publicly disclosed. So, we don’t really know which goals the fine-tuning aimed for.
Targeted Use Case
The overall target use case of ChatGPT is to provide an AI-powered conversational agent that can engage in human-like conversations with users. ChatGPT is designed to understand and generate natural language responses in a wide range of conversational contexts. From translations of natural language, to customer support, ChatGPT is capable of providing assistance, with various degrees of freedoms and success.
Success and Service
Since the main topic of this article is APR, this next section will be dedicated to this solely, leaving out potential other successes ChatGPT is, or may be capable of.
As mentioned in the subchapter Training for ChatGPT, we don’t know on which or what kind of datasets the model has been trained on specifically. Neither do we know, which use cases have been covered in the fine-tuning process. If, e.g. the human-in-the-loop fine-tuning also contained the creation of code snippets. Thus, every chat about comparing the models in regard to their training will, inevitably, result in speculation.
We will jduge the results of ChatGPT based on the results presented in (Dominik Sobania 2023). Tested were 40 of the problems, present in the QuixBugs. The researchers compare multiple state-of-the-art models for APR against the same problems. Evaluated were the following works, vs the current state – at that time – of ChatGPT: Codex (H. Ye and Monperrus 2021), CoCoNut (T. Lutellier and L. Tan 2020), Standard APR (J. A. Prenner and Robbes 2022).
| Benchmark Problems | ChatGPT | Codex | CoCoNut | Standard APR |
|---|---|---|---|---|
| Sum | 19 | 21 | 19 | 7 |
For ChatGPT, they prefixed all their requests by the following preamble: “Does this program have a bug? How to fix it?”. Of the 40 given problems in the QuixBugs dataset, ChatGPT was able to solve 19, within 4 tries respectively. If one of the 4 tries resulted in a correct solution, the problem is considered solved. Taking a closer look at the results (page 4), we’ll notice, that only two benchmark problems are solved in all 4 runs. That is Bucketsort and Flatten. These results can lead to the interpretation that the model appears to have a high variance in its capability to succeed in the benchmark problems. Thus, rerunning the same request may be beneficial, in case of an erroneous output. Other than that, it’s not surprising, that ChatGPT solved about the same number of problems as the best-performing model Codex. This is due to the underlying similarities of the models, since they originate from the same family of language models (see: (OpenAI 23AD)).
Upon closer inspection, the faulty responses are often close to the correct solution. Furthermore, ChatGPT often proposed a complete reimplementation, which was correct. But only patches fixing the erroneous part have been considered a correct solution.
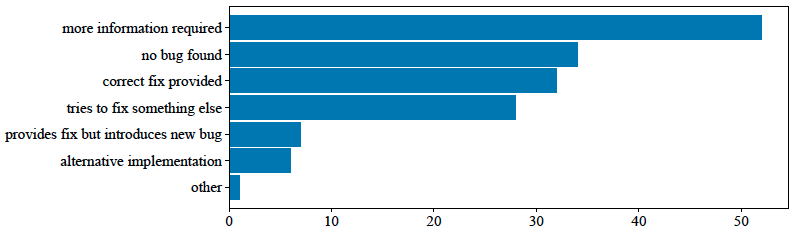
Interesting to point out here is an attempt of classification, by the researchers, to categorize the types of answers ChatGPT gave, when it was not able to solve the issue first try. The researchers categorized the outputs as follows, and kept track of their frequency in the figure above.
- More information required: Asks for more information on the program behaviour to identify the bug.
- No bug found: Does not find a bug and states the program is working correctly.
- Correct fix provided: Provides the correct fix for the correct bug.
- Tries to fix something else: Does not find the intended bug and tries to fix or advise on something else that is not really a bug or adjusts for edge cases.
- Provides fix but introduces new bug: Provides the correct fix for the target bug but introduces a new bug somewhere else.
- Alternative implementation: Does not fix the bug but gives a working alternative implementation.
- Other: Every other answers given, not categorizable with the above.
The vast majority of their categorization falls into the More information required class, with the second most occurrence being No bug found. For both of these cases, it can be beneficial to exploit the chatting capability of the model, to serve enhanced information in subsequent steps that may lead to a correct identification and fix of the original error.
For two of the problems, they followed this idea and denoted their conversation in the paper. The chosen problems were GDC (find the greatest common divisor) and BITCOUNT (count the number of bits mandatory to represent a given scalar). Unfortunately, the denotation of the conversation about the BITCOUNT problem is a misleading and not sufficiently documented. But, the version for GDC is:
# Request (1):
Does this program have a bug? How to fix it?
def gdc(a, b):
if b == 0:
return a
else:
return gdc(a % b, b)
# Response (1):
This is the Euclidean algorithm for finding the greatest common divisor (GCD)
of two integer s, a and b. It appears to be implemented correctly. If you are
experiencing issues with this program, it is likely that the problem lies
elsewhere in your code. Without more information about the bug you are experiencing,
it is difficult to say how to fix it.
# Request (2):
No, the function is not correct. E.g., for the input a = 4 and b = 5 I get the
following error message: "RecursionError: maximum recursion depth exceeded in comparison".
# Response (2):
The issue is that the function calls itself recursively, and in some cases,
it never reaches the base case (b == 0), causing it to recurse indefinitely.
The base case of the gcd algorithm is when the remainder is zero, but in this
implementation, it's when b is zero. For example, when a=4 and b=5, gcd(4, 5) is called,
which then calls gcd(4 % 5, 5) which is gcd(4, 5). This causes an infinite loop.
You can fix this by swapping the parameters in the recursive call.
def gdc(a, b):
if a == 0:
return b
else:
return gdc(b % a, a)
This way, if a is zero, the function returns b (which is the gdc of a and b),
otherwise it calls itself with the new values of b % a and a. As spoiled before, the conversational agent is capable of syntax, comprehension and communication (see: Why Language Models in APR?) greatly benefits from the ability to ask for more information and being able to link the responses in natural language to the code-snippet of discussion.
In total, combined with first try solutions and given more information, 31 of the 40 problems in the QuixBugs dataset can be solved. (For the curious ones, the unsolved problems are the following: kheapsort, lcs-length, lis, longest-common-subsequence, rpn-eval, shortest-path-lengths, to-base, topological-ordering, wrap).
What may the Future bring?
For the future, we have a couple of open points. First and foremost:
When is code correct? Reading through all the papers for the research of this blog entry, it turned out, that the different researchers had greatly varying definitions of correctness. Some being very strict, while others took quite loose approaches in defining their target use cases. A great improvement for the field would be a commonly agreed upon definition of tasks, that is held up for evaluation of datasets.
Datasets As it is with deep neural networks of any form, lots of quality data usually does the job. For fine-tuning, we would greatly benefit from more quality data and an easier data collection process. As of now, the data is scraped from open-source code bases, going through the commits and identifying the fixes for an existing bug. Other hopes may even include fixes in different magnitudes of performance.
Context Size Increasing the context size for input tokens to the models would come with plenty of potential. The initial ChatGPT4 model had context size of 8000 (8k), nowadays, it’s 32k tokens for the paid version. That roughly related to 24k words, as a tokens length typically is $3/4$ of an English word. Anthropic even released a model with a context size of 100k. Just imagine a world in which you would just pass the path to a project to such an artificial intelligence (AI), and you may ask it to find security problems in the code.
A Programmers Dream Following is my personal interpretation on the topic and outlook on potential future usages of such techniques, in the context of APR. What is about to come does not comprehend any specific paper or mentions in Future Works paragraphs and solely based on what I would want this topic to progress to. That said, let’s dream:
I could think of a scenario in which programming, to a certain extent, has become a mundane task. To some degrees, it already is, right? We tend to reinvent the wheel sporadically. May it be for the sake of improving existing code or infrastructure or simply not being aware, that exactly what you’ve needed is already implemented in a C-library, accessible via a simple python call. Now imagine: We could just write a short, but precise essay-like text in natural language, that describes what we are about to program. That essay may be interpreted by an AI, that is capable to comprehend the text, given the context it is used in and outputs you a skeleton for the project you plan to realize.
Hierarchical structure, inherent to your project’s idea, is already implemented. The setup follows a state-of-the-art approach in regard to Design Patterns and applies those according to your needs. Inheritance for complex class structure is applied as needed, without you having to define that.
Given that, you can really concentrate on the minute particulars of your implementation. The specific algorithm you’ve always wanted to implement, that will shake the very foundations of the world. Ok, maybe not that groundbreaking, but you get the point.
Implementing a context manager in Python shouldn’t be necessary for setting up a connection to a data storage, such as a database. The purpose is to ensure that developers using it don’t need to worry about transactionality or basic tasks like closing the connection when it’s no longer required. Most of us know how to achieve this and plenty have implemented that specific functionality (and I’m willing to bet on that) more than once, throughout their carrier. Maybe, we could also receive tips for potential improvements, on the fly, while implementing said functionality. If you already imported Pandas and run a loop over a DataFrame, probably there is a way to avoid the need for a loop entirely, simply by using a highly used, well tested library, that you anyway use somewhere in your script. Or the AI could point out, that you may run into problems with all your pointer action in C, because you violated the basic idea of a Singleton. Programming could benefit invaluably from such a system.
Given a system that is aware of the entire project’s code, the context it is supposed to be used in, the machine it will run on, …, you name it – it could point you to flaws or improvements in your implementation, that you simply cannot grasp. Especially if you didn’t write all the code in the project. But the AI might, because it knows every line, every class and every possible permutation of interactions between the objects.
Ressources
Asha Kutsa, Garima Coudhary, Pauline Joseph. 2019. “Error Detection and Correction Using Machine Learning Concepts.” International Journal of Research in Engineering. https://www.ijresm.com/Vol.2_2019/Vol2_Iss5_May19/IJRESM_V2_I5_31.pdf.
Ashish Vaswani, Niki Parmar, Noam Shazeer. 2017. “Attention Is All You Need.” 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 15.
Black, Sara. 2021. “Rollbar Research Shows That Traditional Error Monitoring Is Missing the Mark.” https://www.businesswire.com/news/home/20210216005484/en/Rollbar-Research-Shows-That-Traditional-Error-Monitoring-Is-Missing-the-Mark.
Chunqiu Steven Xia, Lingming Zhang. 2022. “Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-Shot Learning.” https://arxiv.org/pdf/2207.08281.pdf.
Derrick Lin, Angela Chen, James Koppel. 2017. “QuixBugs: A Multi-Lingual Program Repair Benchmark Set Based on the Quixey Challenge.” https://jkoppel.github.io/QuixBugs/quixbugs.pdf.
Dominik Sobania, Carol Hanna, Martin Briesch. 2023. “An Analysis of the Automatic Bug Fixing Performance of ChatGPT.” https://arxiv.org/pdf/2301.08653.pdf.
H. Ye, T. Durieux, M. Martinez, and M. Monperrus. 2021. “A Comprehensive Study of Automatic Program Repair on the QuixBugs Benchmark.” Joirnal of Systems and Software 171.
J. A. Prenner, H. Babii, and R. Robbes. 2022. “Can OpenAI’s Codex Fix Bugs? An Evaluation on QuixBugs.” Proceedings of the Third International Workshop on Automated Program Repair.
K K Sharma, Indra Vikas, Kunal Banerjee. 2014. “Automated Checking of the Violation of Precedence of Conditions in Else-If Constructs in Students’ Programs.” https://ieeexplore.ieee.org/abstract/document/7020271.
Matsumoto, Yutaka Watanobe, Taku, and Keita Nakamura. 2021. “A Model with Iterative Trials for Correcting Logic Errors in Source Code.” https://www.mdpi.com/2076-3417/11/11/4755.
OpenAI. 23AD. “Model Index for Researcheres.” https://platform.openai.com/docs/model-index-for-researchers.
———. 2023. “GPT-4 Technical Report.” https://arxiv.org/pdf/2303.08774.pdf.
T. Lutellier, L. Pang, H. V. Pham, and L. Tan. 2020. “CoCoNuT: Combining Context-Aware Neural Translation Models Using Ensemble for CoCoNut: Combining Context-Aware Neural Translation Models Using Ensemble for Program Repair.” ACM SigSoft International Symposium on Software Testing and Analysis.
Zhangyin Feng, Duyu Tang, Daya Guo. 2020. “CodeBERT: A Pre-Trained Model for Programming and Natural Languages.” https://arxiv.org/pdf/2002.08155.pdf.
Leave a Reply
You must be logged in to post a comment.