Haben Sie sich jemals gefragt wie Ihre Lieblings-Apps und Spiele rund um die Uhr verfügbar bleiben? Im folgenden Blogeintrag betrachten wir die Technologien und Strategien, die eine so hohe Zuverlässigkeit ermöglichen und weshalb das für heutige Unternehmen so wichtig ist.
Was bedeutet 99.999999% Verfügbarkeit?
Eine Verfügbarkeit von 99,999999% bedeutet, das ein Unternehmen im Schnitt eine Ausfallzeit von 315 Millisekunden pro Jahr hat. Was hat es jedoch mit so einer geringe Ausfallquote auf sich? Was muss erreicht werden um so eine hohe Zuverlässigkeit zu erlangen?
| Verfügbarkeit | Ausfallzeit pro Jahr |
|---|---|
| 98 % | 7,3 Tage |
| 99 % | 3,65 Tage |
| 99,5 % | 1,83 Tage |
| 99,9 % | 8,76 Stunden |
| 99,99 % | 52,6 Minuten |
| 99,999 % | 5,26 Minuten |
| 99,9999 % | 31,5 Sekunden |
| 99,99999 % | 3,16 Sekunden |
| 99,999999 % | 315 Millisekunden |
Es ist klar zu erkennen wie sich die Ausfallzeiten mit steigender Verfügbarkeit verringern. Die Erreichung einer Verfügbarkeit mit acht Neunen ist mit enorm hohem Aufwand verbunden. Um dies umzusetzen, ist es sowohl technisch als auch finanziell keine leichte Aufgabe.
Bedeutung für Unternehmen
Wirtschaftliche Vorteile
Vor allem die Kundenzufriedenheit und der damit verbundene Service ist für heutige Unternehmen enorm wichtig. Jedes Unternehmen möchte die maximale Leistung für ihre Kunden bieten. Eine hohe Verfügbarkeit bringt somit auch eine hohe Zufriedenheit der Kunden mit sich. Für die Benutzer bedeutet dies, das sie jederzeit auf ihre persönlichen Daten zugreifen können, was sich positiv auf das Image des Unternehmens auswirkt. Außerdem ist hohe Verfügbarkeit essenziell für eine Umsatzsteigerung. Ein Unternehmen mit einer hohen Zuverlässigkeit sorgt somit zu gleich für einen guten Umsatz und hohe Verkaufszahlen. Ausfallzeiten könnten Kunden abschrecken, weshalb es wichtig ist diese zu vermeiden.
Vermeidung von Ausfallkosten
Gerade für Unternehmen ist es entscheidend eine hohe Verfügbarkeit der Server zu gewährleisten, um mögliche Ausfallkosten zu vermeiden. Jedes Unternehmen möchte so viel Umsatz wie möglich machen. Ausfallzeiten sorgen jedoch dafür das bestimmte Dienste nicht mehr verfügbar sind. Direkte Kosten entstehen beispielsweise durch Kunden welche Aufgrund von Ausfallzeiten keinen Zugang mehr auf bestimmte Dienste haben. Damit verbunden ist nämlich der Verlust von Einnahmen. Des weiteren können hohe Kosten durch Notfallmaßnahmen wie Reparaturen, IT-Support und möglicherweise sogar für Entschädigungen an betroffene Kunden anfallen. Als indirekte Kostenfaktoren kann man die Beeinträchtigung der Produktivität der Mitarbeiter zählen. Sollte es zu einem Ausfall kommen, muss daran gearbeitet werden, das Problem schnellstmöglich wieder zu beheben. Dadurch geht kostbare Arbeitszeit verloren, welche eigentlich für die Arbeit an laufenden Projekten benutzt werden würde.
Wettbewerbsvorteil
Natürlich ist das Image nicht nur gegenüber der Kunden wichtig, sondern auch gegenüber anderen Unternehmen. Eine hohe Verfügbarkeit fällt auf und sogt für ein positives Bild. Dies sorgt für großes Interesse und stärkt das Vertrauen der Kunden. Gerade verlässliche und verfügbare Dienste sind den Kunden enorm wichtig. Oft werden Unternehmen untereinander verglichen. Genau aus diesem Grund ist es entscheidend die Erwartungen und Wünsche der Kunden so gut es geht zu erfüllen. Wenn Verbraucher sich auf auf die Dienste eines Unternehmens verlassen können, lockt dies weitere Verbraucher an. Ein Unternehmen kann so mehr Umsatz machen und sich eine Vorteil gegenüber der Konkurrenz schaffen.
Heutige Sicht
Die Verwendung von Online-Diensten nahm in den letzten Jahren enorm zu. Menschen aus aller Welt nutzen diese Dienste, weshalb Unternehmen immer mehr Wert auf die Hochverfügbarkeit legen um den Erwartungen der Kunden gerecht zu werden. Die Verwendung von Onlineplattformen ist in so gut wie jedem Bereich wiederzufinden. Sei es beim Verkauf von Produkten, bei der Kommunikation oder bei der Bereitstellung bestimmter Software. Kunden erwarten, dass jederzeit und überall auf Dienste zugriffen werden kann. Um so entscheidender ist die Aufrechterhaltung der Verfügbarkeit für Unternehmen, da sonst möglicherweise das Risiko besteht, Kunden zu verlieren. Aus diesem Grund investieren Unternehmen immer mehr in die technische Entwicklung und die damit verbundenen Maßnahmen zur Erreichung hoher Verfügbarkeit.
Organisatorische und technologische Maßnahmen zur Erreichung hoher Verfügbarkeit
Die Abgrenzung von Hardware, Software und organisatorischen Maßnahmen ist schwierig, da sie oft zusammenarbeitend fungieren. Einige Maßnahmen haben beispielsweise einen Hardwarepart und einen Softwarepart. Im Folgenden werden diese Methoden deshalb als ein Ganzes betrachtet um ein besseres Verständnis über die Funktionen dieser zu bekommen.
REdundanz
Redundanz ist eine der wichtigsten Faktoren im Bereich der Ausfallsicherheit. Sie ist eine essenzielle Maßnahme zur Gewährleistung der Hochverfügbarkeit. Durch die Bereitstellung zusätzlicher Ressourcen sorgt man für Ersatz, falls die Hauptressourcen nicht mehr funktionieren. Für Server heißt das, dass diese mehrere Systeme und Komponente haben, welche ein und dieselbe Funktion übernehmen. Somit kann sichergestellt werden, dass es keine Unterbrechungen im gesamten System gibt. Die Server und die damit verbundenen Dienste bleiben dadurch verfügbar.
Es gibt verschiedene Möglichkeiten die Ausfallsicherheit zu gewährleisten:
- Hardware-Redundanz: Die Verwendung mehrer Hardware-Komponenten
- Server-Redundanz: Load Balancing
- Virtuelle und Softwarebasierte Redundanz: Virtuelle Maschinen und Container
- Geografische Redundanz: weitere Standorte der Server oder Verwendung von Cloud Diensten
Diese vier Möglichkeiten sind die wichtigsten und am häufigsten eingesetzten Methoden zur Erreichung von Redundanz. Sie dienen dazu, die Server sicherer zu machen und Ausfallzeiten zu verringern.
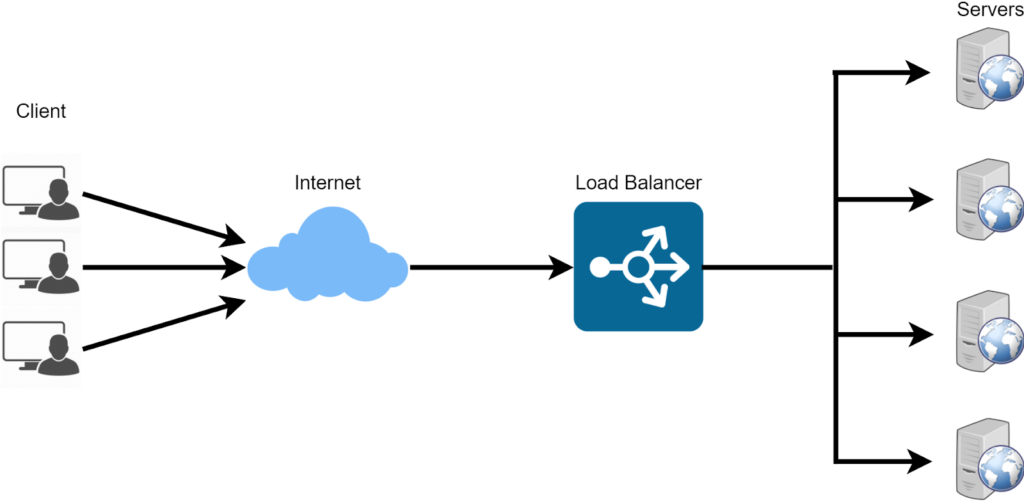
Load Balancing
Load Balancing oder auch Lastverteilung genannt, ist eine weitere effektive Möglichkeit die Verfügbarkeit so hoch wie möglich zu halten. Hier wird, wie der Name schon verrät, der Netzverkehr auf verschiedene Gruppen von Servern verteilt. Grundsätzlich wird diese Maßnahme verwendet, um sicherzustellen, dass ein einzelner Server nicht überlastet wird. Die Anfragen der Benutzer werden somit auf mehrere Server verteilt. Es wird zwischen verschiedenen Lastverteilern unterschieden, die sich in der Funktion, der Komplexität aber auch in den Art der Speicherung unterscheiden.
- Hardwarebasiert: Hier ist ein spezielles physisches Gerät vorhanden, welches dafür sorgt, die Lasten gleichmäßig zu verteilen. Dieser Load Balancer ist zwischen Benutzer und Server positioniert, und leitet jegliche Daten an den entsprechenden Server weiter. Virtualisierungsfunktionen erlauben die Verwendung mehrerer Instanzen eines virtuellen Load Balancers auf einem einzigen Gerät.
- Softwarebasiert: Diese Art von Lastverteiler funktioniert prinzipiell wie der hardwarebasierte Lastverteiler. Der grundlegende Unterschied ist jedoch, dass hier eine spezielle Anwendung auf den Server läuft welche die Verteilung übernimmt. Im Normalfall laufen diese auf virtuellen Maschinen oder sogenannten White-Box-Servern. Im Gegenteil zu den hardwarebasierten Lastverteilern, bieten der virtuelle Lastenausgleich eine höhere Flexibilität. Beispiele hierfür sind Nginx, HAProxy oder der Apache Traffic Server.
- Cloudbasiert: Bei einem cloudbasierten Load Balancing werden spezielle Cloud-Dienste verwendet um den Datenverkehr gleichmäßig auf die Server zu verteilen. Bekannte Beispiele hierfür sind Amazon Elastic Load Balancing (ELB), Google Cloud Load Balancing, Azure Load Balancer oder der IBM Cloud Load Balancer. Diese Technik hat den Vorteil, dass sie flexibel, anpassungsfähig und eine der schnellsten Methoden ist.
- DNS-Lastenverteilung: Die letzte Strategie um eine gleichmäßige Verteilung auf den Servern zu ermöglichen ist die DNS-Lastenverteilung. Indem unterschiedliche IP-Adressen für denselben Domain-Namen zurückgegeben werden, kann auf diese Weise eine ausgeglichene Datenverteilung gewährleistet werden. Die Wahrscheinlichkeit einer Überlastung eines einzelnen Servers kann damit verringert werden.
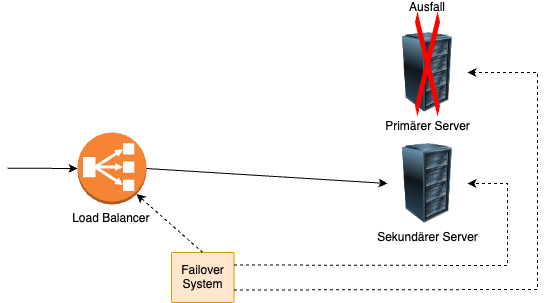
Failover-Systeme
Failover-Systeme sind enorm wichtig im Bereich der Ausfallsicherheit und für die Gewährleistung einer Hochverfügbarkeit in einer IT-Infrastruktur. Sie dienen grundsätzlich dazu die Ausfallsicherheit zu erhöhen und die damit verbundene Ausfallquote zu verringern. Die meisten Services und Komponenten eines Servers sind per Failover gesichert. Sollte es zu einem Ausfall kommen, übernimmt automatisch ein Ersatzsystem des Servers die Aufgaben des ausgefallenen Systems. Aus diese Weise kann die Kontinuität des Dienstes gewährleistet werden. Das Grundprinzip eines Failover-Systems basiert auf der Redundanz, des Monitoring und der Automatisierung. Idealerweise gibt es von jeder Komponente ein Backup, welches die Systeme absichert. Durch ein kontinuierliches Überwachen der internen Prozesse können Anomalien festgestellt und behoben werden. Sobald ein Problem auftritt, wird sofort automatisch von dem Backup-System Gebrauch gemacht, sodass es dadurch nicht zu einem Ausfall kommt. Bekannte Systeme sind hier das IBM PowerHA oder auch Red Hat Cluster Suite.
Monitoring und Wartung
Damit es erst gar nicht zu Ausfällen kommt, ist das Überwachen und Warten der Server zwingend nötig. Mit speziellen Monitoring-Tools werden Systeme kontinuierlich überwacht, um somit mögliche Probleme zu vermeiden. Es werden ständig neue Daten gesammelt um die Leistung der Server zu verbessern und somit eine höhere Verfügbarkeit zu gewährleisten. Proaktivität spielt eine sehr wichtige Rolle, sodass man auf Unregelmäßigkeiten bereits reagieren kann bevor es zu schwerwiegenden Ausfällen kommt. Ebenso wichtig ist die Wartung dieser Systeme. Eine fortlaufende Überwachung allein reicht nämlich nicht aus um die Verfügbarkeit hochzuhalten. Regelmäßige Software-Updates, Hardware-Überprüfungen und die Optimierung von Systemressourcen ist essenziell um die Effizienz innerhalb eines Unternehmens zu steigern. Solche Maßnahmen minimieren das Risiko von plötzlichen Ausfallzeiten und dienen außerdem zur Verbesserung der IT-Infrastruktur.
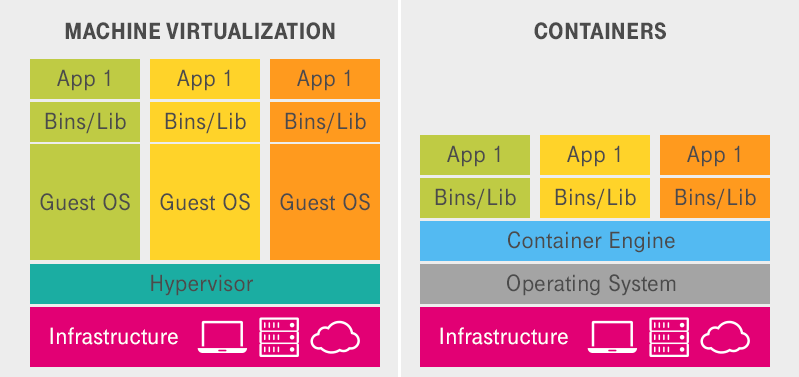
Virtualisierung und Containerisierung
Die Flexibilität und Skalierbarkeit von IT-Infrastrukturen sind wichtige Aspekte um hohe Verfügbarkeit zu gewährleisten. Um dies umzusetzen, werden Virtualisierungstechnologien und Container wie Docker oder Kubernetes verwendet. Indem man Mithilfe von Virtualisierung physische Server in mehrere virtuelle Maschinen unterteilt, können diese unabhängig voneinander betrieben werden. Ein einziger physischer Host kann also viele weitere VM’s betreiben. Dies führt zu einer effizienteren Ressourcennutzung und erleichtert das Management von Anwendungen und Diensten, da VMs leicht verschoben, kopiert oder skaliert werden können. Virtuelle Maschinen arbeiten mit einer isolierenden Methode, das heißt unterschiedliche Betriebssysteme können gleichzeitig betrieben werden. Dadurch wird außerdem auch das Risiko von Sicherheitsvorfällen verringert.
Bei der Containerisierung werden Anwendungen und ihre Funktionalitäten in sogenannte Container verpackt. Sie werden oft auf der bekannten Containerplattform Docker genutzt. Sie gelten als sehr leichtgewichtig und portabel, wodurch sie die Komplexität der Bereitstellungen reduzieren. Entwicklern ist es damit möglich, gewisse Dienste in verschiedenen Umgebungen auszuführen um so ressourcenschonender zu arbeiten. Die Skalierung, Bereitstellung, sowie der Betrieb wird von dem Open-Source-Orchestrierungstool Kubernetes automatisiert. Dieses Werkzeug wird vor allem in größeren Umgebungen verwendet, um eine bessere Containerverwaltung zu gewährleisten. Da Container sich den selben Kernel teilen, verbrauchen sie weniger Ressourcen als virtuelle Maschinen. Außerdem sind sie den VM’s in Schnelligkeit überlegen. Sie brauchen wesentlich weniger Zeit um zu starten, da sie keine komplette Bootsequenz durchlaufen müssen. Zudem bieten Container eine sehr hohe Sicherheit und Stabilität aufgrund der Isolierung der verschiedenen Anwendungen.
Bei beiden Methoden sticht die ressourcensparende Arbeitsweise heraus. Durch die Kombination von Virtualisierung und Containerisierung kann eine effizientere und sicherere Umgebung geschaffen werden. Auf Änderungen kann schneller reagiert werden und das Unternehmen kann sich dynamischer anpassen. Durch die stark isolierte Arbeitsweise von virtuellen Maschinen und Containern, wird somit auch die Ausfallsicherheit gestärkt, sollte ein Teil des Dienstes ausfallen.
Herausforderungen und Kosten
Das Anstreben einer Verfügbarkeit von 99,999999% ist eine sehr komplexe und kostenintensive Aufgabe. Es müssen zahlreiche Faktoren berücksichtigt werden, um eine fast ununterbrochene Verbindung zu gewährleisten. Im folgenden wird erläutert, welche Herausforderungen und Kosten damit verbunden sind.
Komplexität
Es ist technisch sehr schwierig viele verschiedene Hardware sowie Softwarekomponenten so zu verbinden, dass alles reibungslos und ohne Probleme funktioniert. Oft benötigt es Expertenwissen um dies umzusetzen. Vor allem das Verwalten von sensiblen Daten und das Bewahren der Datenkonsistenz ist keine leichte Aufgabe. Ebenso erfordert das Implementieren und Verwalten von Automatisierungsprozessen spezielle Fachkräfte. Es sind jedoch nicht nur die technischen Faktoren, die das Gewährleisten einer Hochverfügbarkeit beeinträchtigen. Die Koordination innerhalb eines Teams ist zusätzlich ein wichtiger Faktor zur Verringerung der Ausfallquote. Um eine nahtlose und effektive Redundanzstrategie zu garantieren, müssen alle Teams des Unternehmens gut miteinander arbeiten. Damit verbunden sind oft strenge Prozesse zum Einhalten von Wartungen, Updates oder Notsituationen, denn gerade diese Bereiche sorgen für eine bessere Ausfallsicherheit.
Risiken
Das Anstreben einer Hochverfügbarkeit bringt jedoch auch einige Risiken mit sich. Oft sind es Risiken, welche kaum zu vermeiden sind und immer vorhanden bleiben. Es gilt diese Risiken zu minimieren um somit die Sicherheit zu erhöhen. Auch wenn Unternehmen bereits alle Faktoren beachtet haben, kann es immer zu unvorhersehbaren Ausfällen kommen. Dazu gehören Naturkatastrophen, welche ganze Servereinrichtungen zerstören, aber auch großflächige Stromausfälle. Hier kann es dann sogar so weit kommen, dass nicht einmal ein zweiter Standort hilft, den Ausfall zu kompensieren. Des Weiteren könnte es zu unerwarteten Hackerangriffen kommen, welche gezielt die kritischen Systeme angreifen, sollten diese nicht ausreichend abgesichert sein.
Kosten
Grundsätzlich unterscheidet man zwischen zwei großen Kostenfaktoren. Zum einen bringt Hochverfügbarkeit hohe Implementierungskosten mit sich. Unternehmen legen viel Wert auf Hardware und Software. Das Einrichten von redundanten Komponenten wie Server, Festplatten oder Netzteilen, bringt sehr hohe Kosten mit sich. Da im Falle eines Ausfalles eine andere Komponente übernehmen soll, benötigt man doppelte Geräte. Lizenzgebühren für Monitoringsoftware oder Failover-Systeme sind zusätzliche anfallende Kosten. Ein großer Kostenfaktor ist ebenfalls das Betreiben mehrerer Rechenzentren an verschiedenen Orten, um die damit verbundene Redundanz zu gewährleisten. Jedoch fallen nicht nur im technischen Bereich einige Kosten an. Sämtliche Wartungen und Updates erfordern sehr viel Zeit und Personal. Ein Unternehmen sollte auch in diesem Bereich investieren. Stromkosten sind ebenfalls nicht zu unterschätzen. Ein hochleistungsfähiger Server erfordert enorm viel Strom und Kühlung damit es nicht zu Überhitzen oder sogar Ausfällen kommt.
Fazit
Eine Hochverfügbarkeit von 99,999999% bedeutet, dass ein Dienst praktisch ständig online ist. Es ist klar zu erkennen, dass sehr viele Faktoren entscheidend zur Erreichung dieser Zeiten sind. Sowohl technische als auch organisatorische Maßnahmen müssen getroffen werden damit die Ausfallzeiten so gering wie möglich gehalten werden. Für Unternehmen ist es unglaublich schwierig alle Faktoren zu berücksichtigen und vor allem den Erwartungen der Kunden gerecht zu werden. In der heutigen Zeit wird weltweit immer mehr Gebrauch von Onlinediensten gemacht. Mit verschiedenen Maßnahmen wie redundante Systeme, Load Balancern, Failover Systemen aber auch Virtualisierungs- und Containerisierungsmethoden, kann die Hochverfügbarkeit prozentual erhöht werden. Es erfordert sehr viel Zeit und Kosten ein so großes System zu errichten, doch sobald es einmal funktioniert und überwacht wird, steigen die Umsätze und die Zufriedenheit der Kunden.
Was wäre, wenn ein Dienst niemals ausfallen würde und immer online wäre? Geht das? Es würde bedeuten, dass ein System eine Verfügbarkeit von 100% hat. Leider ist das in der Realität nahezu unmöglich. Zu viele Faktoren spielen in die Funktion eines Servers mit ein und könnten die Laufzeit beeinflussen. Hardwarefehler, Softwarefehler aber gerade auch menschliche Fehler beeinträchtigen die Zuverlässigkeit täglich. In der heutigen Entwicklung gibt es jedoch Maßnahmen, welche die Zuverlässigkeit noch mehr steigern können. Ein sehr beliebtes Thema ist die künstliche Intelligenz. Diese wird in einigen Unternehmen, wie beispielsweise IBM, bereits eingesetzt. Durch Einsatz von KI könnten Fehler frühzeitig erkannt und durch Automatisierung selbständig korrigiert werden. Es wird viel Wert auf Automatisierung und Autonomisierung gelegt. Dadurch können Systeme ohne menschliche Hilfe fungieren und sich notfalls sogar selber reparieren. Es wird versucht noch bessere Algorithmen und Systeme zu schaffen die gegen Fehler oder Angriffe gewappnet sind. Auch hier gibt es bereits erste Ansätze im Bereich des Quantencomputings (z.B. bei der IBM). Es ist trotzdem nicht möglich alle Risiken auszuschließen. Deshalb fokussieren sich Unternehmen darauf, gegen unerwartete Ausfälle gerüstet zu sein und Pläne für eine Hochverfügbarkeit zu schaffen.
You must be logged in to post a comment.