Anmerkung: Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst.
Inhalt
- Einleitung: Ultra-Hohe Verfügbarkeit & Die Neunen
- Engineering für 99,999 999 % Verfügbarkeit
- Fallstudie: Availability optimierte AWS Infrastruktur in der Praxis
- Fazit: Verfügbarkeit gezielt gestalten
- Quellen & weiterführende Ressourcen
1 · Einleitung: Ultra-Hohe Verfügbarkeit & Die Neunen
Ultra-Hohe Verfügbarkeit beginnt dort, wo ungeplante Unterbrechungen nur noch als Millisekunden pro Jahr messbar sind. Moderne Mainframes wie die IBM z16 erreichen bereits acht Neunen (99,999 999 %) – gerade einmal ≈ 0,32 s jährlicher Downtime – und nähern sich in Feldtests sogar der neun-Neunen-Marke (≈ 0,03 s). Der ökonomische Unterschied ist enorm: Laut der ITIC-Reliability-Survey 2024 verlieren 93 % der befragten Unternehmen pro Ausfallstunde ≥ 300 000 USD, fast 46 % sogar ≥ 1 Mio. USD. Jede zusätzliche “9” verringert die rechnerische Ausfallzeit um den Faktor 10 – und kann Millionen sparen. [1]
| Verfügbarkeit | Max. ungeplante Downtime / Jahr |
|---|---|
| 99 % (2 Nines) | 3 Tage 15 h |
| 99,999 % (5 Nines) | 5 min 15 s |
| 99,9999 % (6 Nines) | 31 s |
| 99,99999 % (7 Nines) | 3,15 s |
| 99,999999 % (8 Nines) | 315 ms |
Werte aus [1] und [6]
Die Spanne ab sechs Neunen macht deutlich, dass höchste Verfügbarkeit nicht mehr nur eine Frage einzelner Hardware-Komponenten sein kann. Stattdessen wird sie zum systemischen Qualitätsziel: Hardware-Redundanz, softwareseitige Fehlertoleranz und abgestimmte Betriebsprozesse werden entscheidend beim kosteneffizienten erreichen sehr hoher Verfügbarkeiten. Im folgenden schauen wir uns unterschiedliche Methoden und ein Architekturbeispiel zur Realisierung Ultra-Hoher Verfügbarkeiten an.
2 · Engineering für 99 ,999 999 % Verfügbarkeit
Um Verfügbarkeiten von acht oder sogar neun Neunen (99,999999 % bis 99,9999999 %) wirtschaftlich zu erreichen, genügt es meist nicht, sich allein auf Ultra-Hochverfügbare Hardware zu verlassen. Vielmehr ist oftmals ein systemischer Ansatz notwendig, der Hardware, Software, Redundanz, Virtualisierungstechnologien und operative Maßnahmen gezielt miteinander kombiniert. Die folgende Tabelle gibt einen Überblick über die wichtigsten Methoden und technischen Mechanismen auf den einzelnen Ebenen, die gemeinsam oder einzeln zu einer Ultra-Hohen Verfügbarkeit führen können:
| Ebene | Methode | Beispiel‑Techniken (Kurzbeispiele) | Typischer Uptime‑Zugewinn* | Quelle |
|---|---|---|---|---|
| Hardware | Fehler‑Isolation auf Board‑ und Chip‑Ebene, redundante Hardware-Komponenten | Hot‑Swap‑Steckplätze für Speicher/Festplatten/Kühlung/Netzteile; Telum‑Prozessor mit KI‑basiertem Fault‑Isolation | Hochwertige z16‑ und Power10‑Server erreichen acht bis neun Neunen (31 ms–315 ms/Jahr), wohingegen x86‑Server meist sechs bis sieben Neunen (31 s–3 s/Jahr) liefern. | [1] |
| Virtualisierung | Flexibles Verschieben & unabhängige Replikate von VMs | Live‑Migration & Wartung ohne Unterbrechung; Checkpoint‑/Rollback‑Mechanismen & differenzielle Snapshots; Redundanzmodelle | Virtualisierung eliminiert Ausfallzeiten während Wartungen und ermöglicht schnelle Failover; konkrete „Nines“‑Zugewinne hängen von Modell und Implementation ab (häufig Bruchteile eines Nines). | [5] |
| Architektur | Konsistente Mehrwege‑Schreibpfade durch Replikation & Konsens | State‑Machine‑Replikation (Lock‑Step); Checkpoint‑basierte Replikation; Quorum‑basierte Konsensverfahren (z.B. Paxos/Raft) für konsistente Quorum‑Speicher | Durch mehrere unabhängige Replikate steigt die effektive Verfügbarkeit (A_eff = 1 − ∏ (1 − A_i) ) zwei 99,9 %-Knoten ergeben 99,9999 %. | [5]; [2] |
| Betrieb / Self‑Healing | Automatisierte Wiederherstellung, kontinuierliches Testing & Incident‑Prozesse | Automatisierte Recovery‑Playbooks & Chaos‑Tests; Fault‑Injection‑Experimente und Local‑Fault‑Manager, die bei VM‑Fehlern Standby‑VMs aktivieren; KI‑gestützte Predictive‑Maintenance zur frühzeitigen Fehlererkennung | Self‑Healing & proaktive Wartung können Verfügbarkeit um ≈0,5 „Nine“ erhöhen; KI‑basierte Predictive‑Maintenance steigerte die Verfügbarkeit von 99,98 % auf 99,995 %. | [5]; [2];[3] |
* „Typischer Uptime‑Zugewinn“ ist eine grobe Größenordnung: ITIC vergleicht acht–neun‑Nines‑Systeme mit sechs–sieben‑Nines‑x86‑Servern (≈1–2 zusätzliche Neunen). Virtualisierung und Middleware‑Replikation verbessern die Verfügbarkeit, doch konkrete Werte hängen stark von Architektur und Implementation ab. Predictive‑Maintenance‑Studien quantifizieren einen Zugewinn von ca. 0,5 „Nine“.
Warum Redundanz allein nicht genügt
Redundanz ist eine Grundvoraussetzung für hohe Verfügbarkeit, doch allein reicht sie nicht aus. Die effektive Verfügbarkeit eines redundanten Systems berechnet sich aus der individuellen Ausfallrate der einzelnen Komponenten: Werden mehrere unabhängige Einheiten kombiniert, multiplizieren sich deren Ausfallwahrscheinlichkeiten, wodurch die Gesamtverfügbarkeit signifikant steigt. Zwei voneinander unabhängige Komponenten mit jeweils 99,9 % Einzelverfügbarkeit könnten dadurch gemeinsam bereits eine Gesamtverfügbarkeit von 99,9999 % („sechs Neunen“) erreichen. Würden drei unabhängige Systeme mit jeweils 99,95 % Verfügbarkeit kombiniert (entspricht jeweils rund 4 Stunden und 22 Minuten jährlicher Ausfallzeit), ließe sich theoretisch sogar eine Verfügbarkeit von etwa 99,999999875 % („acht Neunen“) erreichen. In der Praxis tritt dieser Idealzustand jedoch nur ein, wenn Fehler vollständig unabhängig voneinander sind. Schon einzelne gemeinsame Abhängigkeiten können die theoretische Verfügbarkeit drastisch reduzieren. Deshalb ist es entscheidend, Systeme physisch voneinander zu trennen und unabhängige Stromversorgungen sowie Netzwerkanbindungen zu gewährleisten. Auch regelmäßige Chaos-Tests, in denen gezielt Ausfälle simuliert werden, sind ein zentraler Baustein, um unerkannte Abhängigkeiten aufzudecken und zu beseitigen. [2]
Hardware als Startvorteil
Hochverfügbare Hardware bildet oft die technologische Grundlage für eine sehr hohe Systemverfügbarkeit. Beispielsweise erreichen moderne IBM-Mainframes der Z-Reihe (Modelle z13 bis z16) sowie IBM-Power10-Server Verfügbarkeiten zwischen acht und neun Neunen (ca. 31,56 ms bis 315 ms jährlicher Ausfallzeit). Diese Werte werden unter anderem durch spezialisierte Hardware-Komponenten wie Prozessoren mit integrierter KI-Unterstützung und umfangreiche Redundanz auf Komponentenebene ermöglicht. Hot-Swap-fähige Hardware erlaubt darüber hinaus einen unterbrechungsfreien Austausch defekter Komponenten im laufenden Betrieb. Demgegenüber verfügen günstigere Commodity-Server oft nicht über vergleichbare Funktionen, sodass zur Erreichung ähnlicher Verfügbarkeitswerte deutlich komplexere softwareseitige oder Architekturale Lösungen notwendig sind. [1]
Operative Methoden
Über die Hardware hinaus können auch operative Maßnahmen wesentlich dazu beitragen, eine hohe Systemverfügbarkeit sicherzustellen:
- Software-Rejuvenation adressiert die Problematik der Softwarealterung – einem Phänomen, bei dem Systeme über längere Laufzeiten hinweg an Stabilität verlieren. Durch geplante, präventive Neustarts kann der Softwarezustand regelmäßig aufgefrischt werden, um potenziellen Fehlverhalten vorzubeugen. Moderne Virtualisierungsverfahren ermöglichen solche Neustarts in der Regel ohne spürbare Unterbrechungen im Betrieb. [4]
- Dynamische Replica-Platzierung verbessert die Standortwahl für Replikate virtueller Maschinen. Hierbei kommen Echtzeit-Algorithmen zum Einsatz, die sowohl Leistungs- als auch Stabilitätsmetriken einzelner Rechenzentren auswerten. Auf dieser Basis werden Replikate gezielt in Infrastrukturbereiche mit erhöhter Zuverlässigkeit verlagert, wodurch das Ausfallrisiko reduziert und die Ressourcennutzung optimiert wird. [4]
- Monitoring und prädiktive Fehlererkennung stellen weitere zentrale Komponenten dar. Dabei werden polling-basierte Verfahren (regelmäßige Systemabfragen) mit push-basierten Mechanismen (Ereignismeldungen bei Zustandsänderungen) kombiniert. Diese ergänzenden Ansätze ermöglichen eine frühzeitige Identifikation von Anomalien und die Einleitung vorbeugender Maßnahmen, bevor sich Störungen manifestieren. [1]
3 · Fallstudie – Availability-optimierte AWS-Infrastruktur in der Praxis
AWS empfiehlt für hochverfügbare Systeme eine Kombination aus drei zentralen Prinzipien: fehlertolerante Architektur, automatisches Failover und reproduzierbares Deployment. Das Fundament bildet dabei der Betrieb über mehrere Availability Zones hinweg. Diese Zonen sind physisch voneinander getrennt, aber durch ein leistungsfähiges, niedrig-latentes Netzwerk verbunden. Dadurch ist es möglich, Daten synchron zu replizieren – zum Beispiel zwischen der primären und der Standby-Datenbankinstanz. Ein Application Load Balancer (ALB) sorgt dafür, dass Anfragen nur an gesunde Instanzen weitergeleitet werden – idealerweise verteilt über mehrere Zonen. So bleibt die Anwendung selbst bei einem Zonen-Ausfall erreichbar. Fällt die gesamte Region aus, kommt eine Warm‑Standby-Strategie ins Spiel: In einer zweiten Region läuft eine verkleinerte, aber vollständige Version des Stacks. Diese DR-Region kann im Notfall schnell hochskaliert werden. Die DNS‑Failover‑Funktion von Route 53 erkennt durch Health‑Checks, wenn die primäre Region nicht mehr erreichbar ist, und leitet den Verkehr automatisch um. Zusätzliche Dienste wie AWS Global Accelerator oder Latency‑Based Routing können dabei helfen, die Latenz weiter zu minimieren und die Nutzerverfügbarkeit zu maximieren. Um Konfigurationsunterschiede zwischen primärer und DR‑Region zu vermeiden, ist es sinnvoll auf Infrastructure-as-Code (z. B. mit Terraform) und Überwachungsdienste wie AWS Config zu setzten. [2]
AWS Beispielarchitektur
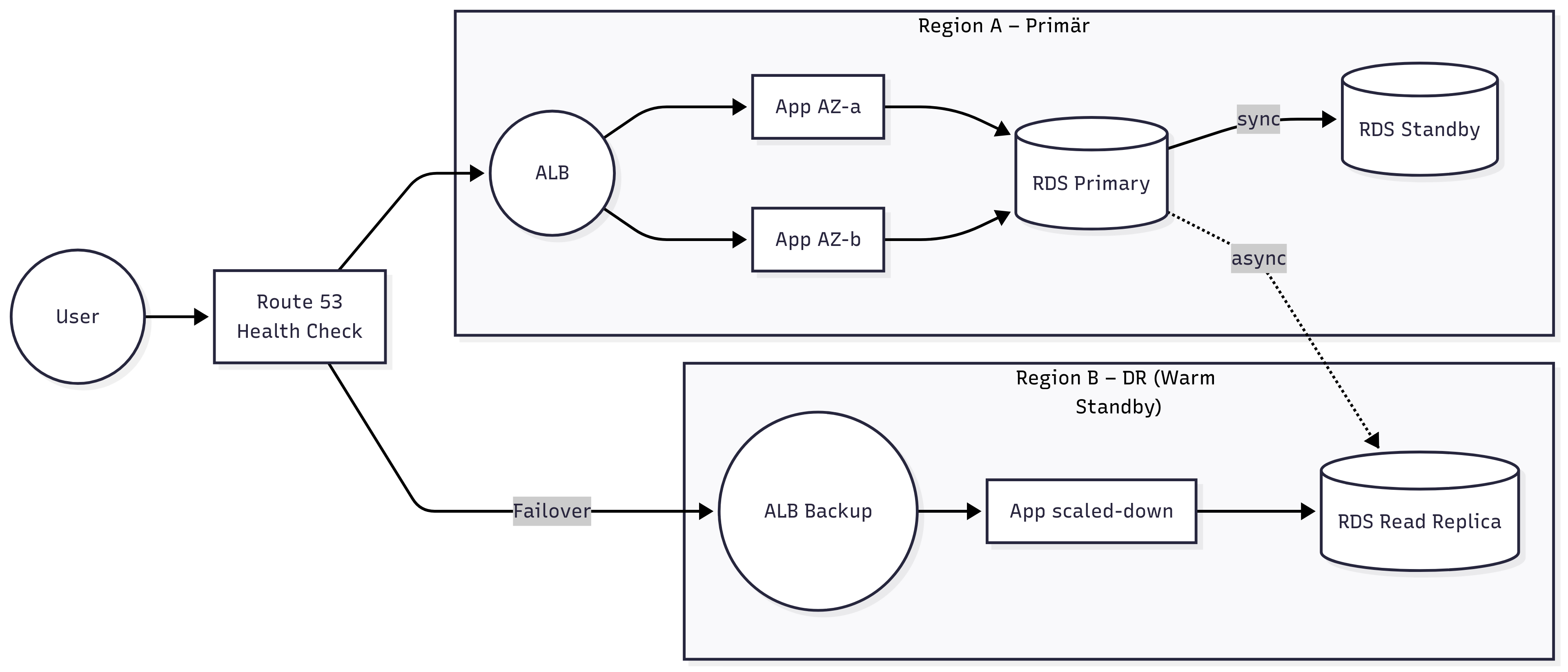
4 · Fazit: Verfügbarkeit gezielt gestalten
Ultra-hohe Verfügbarkeit muss nicht bei einzelnen Komponenten beginnen, sondern bei einem systemischen Architekturansatz: Erst das Zusammenspiel aus ausfallsicherer Hardware, konsistenter Replikation, intelligenter Virtualisierung und automatisierten Betriebsprozessen schafft die Grundlage acht oder mehr Neunen wirtschaftlich zu erreichen – also Ausfallzeiten im Millisekundenbereich. Doch solche Systeme sind teuer: Redundanz auf mehreren Ebenen, Ultra-Hochverfügbare Hardware, dynamische Replica-Platzierung, kontinuierliches Monitoring, Self-Healing-Mechanismen und Chaos-Tests steigern nicht nur die Verfügbarkeit, sondern auch Komplexität und laufende Betriebskosten. Predictive Maintenance, Software-Rejuvenation und konsensbasierte Datenpfade bieten zusätzliche Resilienz, erfordern jedoch Expertise und Ressourcen. Die Praxis zeigt: Redundanz allein reicht nicht aus. Gemeinsame Abhängigkeiten oder unerkannte Fehlerpfade können selbst bei mehrfach abgesicherten Systemen zum Ausfall führen. Deshalb ist es entscheidend, auch betriebliche Prozesse wie Wiederherstellungsstrategien, Failover-Automatisierung und Infrastruktur als Code (IaC) konsequent mitzudenken – wie etwa am Beispiel der mehrzonigen AWS-Architektur deutlich wird. Unternehmen stehen daher vor einer wirtschaftlichen Abwägung: Höhere Verfügbarkeit senkt das Ausfallrisiko, verursacht aber oft exponentiell steigende Kosten. Nicht jede Anwendung muss „acht Neunen“ erreichen. Stattdessen lohnt sich eine risikoorientierte Differenzierung – mit hoher Verfügbarkeit dort, wo der geschäftliche Schaden durch Ausfälle am größten ist. Verfügbarkeit wird so zur strategischen Frage: Nicht maximale Absicherung um jeden Preis, sondern zielgerichtete Robustheit – pragmatisch, wirtschaftlich und angepasst an den tatsächlichen Bedarf.
5 · Quellen & weiterführende Ressourcen
[1]: Information Technology Intelligence Consulting (ITIC). (2024): Global Server Hardware & Server OS Reliability Report. November 2024 edition.
[2]: Amazon Web Services. (2024, Nov 6): AWS Well-Architected Framework — Reliability Pillar (Whitepaper).
[3]: Devarajan, V. (2025): Advancing Data Center Reliability Through AI-Driven Predictive Maintenance. European Journal of Computer Science and Information Technology 13 (14), 102-114. DOI 10.37745/ejcsit.2013/vol13n14102114.
[4]: Mesbahi, M.; Rahmani, A.M.; Chronopoulos, A.T. (2018): High-Availability Techniques in Cloud Environments — A Survey. Human-centric Computing and Information Sciences 8 (20).
[5]: Endo, P.T. et al. (2016): High Availability in Clouds: Systematic Review and Research Challenges.
[6]: IBM Docs: The 9s — Availability Percentages Explained. https://www.ibm.com/docs/en/configurepricequote/10.0.0?topic=principles-9s
Leave a Reply
You must be logged in to post a comment.