
I. Was ist der Dönerguide?
Kurz gesagt: Ein studentisches Webprojekt zwischen Hunger, Daten, KI und Architekturentscheidungen.
Problem
Die Suche nach dem besten Dönerladen, der den eigenen Anforderungen entspricht ist oft gar nicht so einfach. Besonders in einer Stadt wie Stuttgart existieren hunderte Dönerläden, mit stark unterschiedlicher Qualität, Preisen, Öffnungszeiten und Angeboten. Klassische Plattformen wie Google Maps liefern zwar viele Ergebnisse, beantworten aber selten die eigentlichen Fragen der Nutzer:innen:
- Wo finde ich jetzt einen guten Döner in meiner Nähe?
- Welcher Laden bietet vegetarische oder vegane Optionen?
- Wo bekomme ich einen günstigen Döner unter einem bestimmten Preis?
Bewertungen sind häufig subjektiv, inkonsistent oder beziehen sich auf völlig unterschiedliche Kriterien. Gleichzeitig fehlen strukturierte Filtermöglichkeiten für genau die Eigenschaften, die für Döner-Fans wirklich relevant sind, wie etwa Fleischanteil, Wartezeit oder Preis-Leistungs-Verhältnis.
In unserer Projektidee entstand deshalb ein klares Szenario:
„Ich möchte einen veganen Döner für maximal 6 €, der gerade geöffnet ist und Kartenzahlung akzeptiert.“
Mit bestehenden Plattformen lässt sich eine solche Anfrage kaum effizient beantworten. Genau hier setzt unser Dönerguide Stuttgart an.
Die Lösung
Der Dönerguide Stuttgart ist eine spezialisierte Web-Anwendung, die sich vollständig auf die Suche und Bewertung von Dönerläden konzentriert. Genau richtig für Menschen, die genaue Vorstellungen von ihrem perfekten Döner haben oder einfach nur den nächsten Dönerladen mit der besten Bewertung finden möchten.
Die Anwendung kombiniert dabei mehrere Ansätze:
- strukturierte Daten aus der Google Maps Places API
- eine interaktive Kartenansicht
- umfangreiche Filtermöglichkeiten
- sowie eine KI-gestützte Analyse von Dönerbildern
Dadurch entsteht eine Suche, die nicht nur Orte auflistet, sondern echte Entscheidungsunterstützung bietet. Nutzer:innen können Dönerläden anhand konkreter Kriterien entdecken, statt sich durch unstrukturierte Bewertungen zu arbeiten.
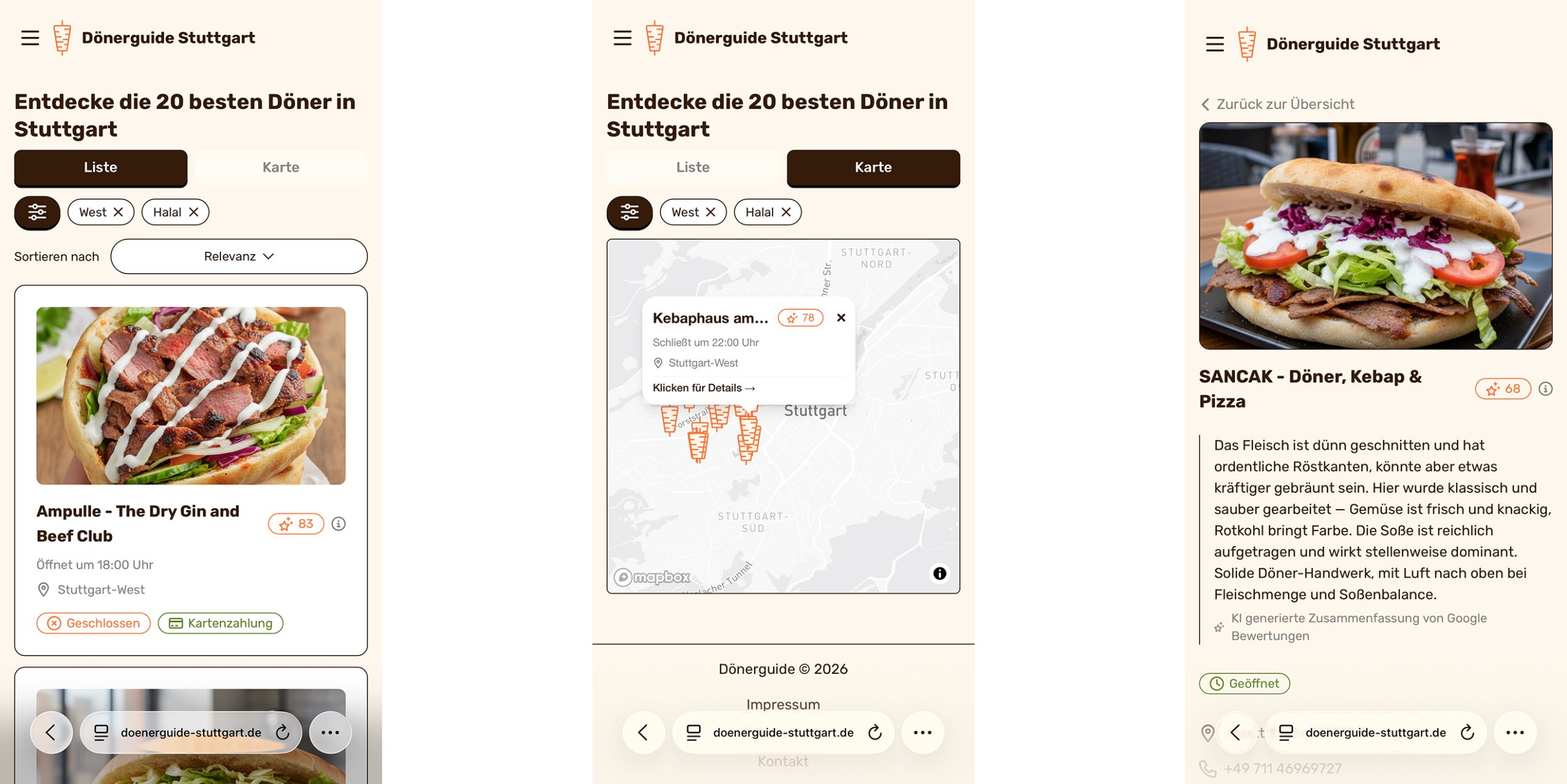
Features – Was den Dönerguide besonders macht
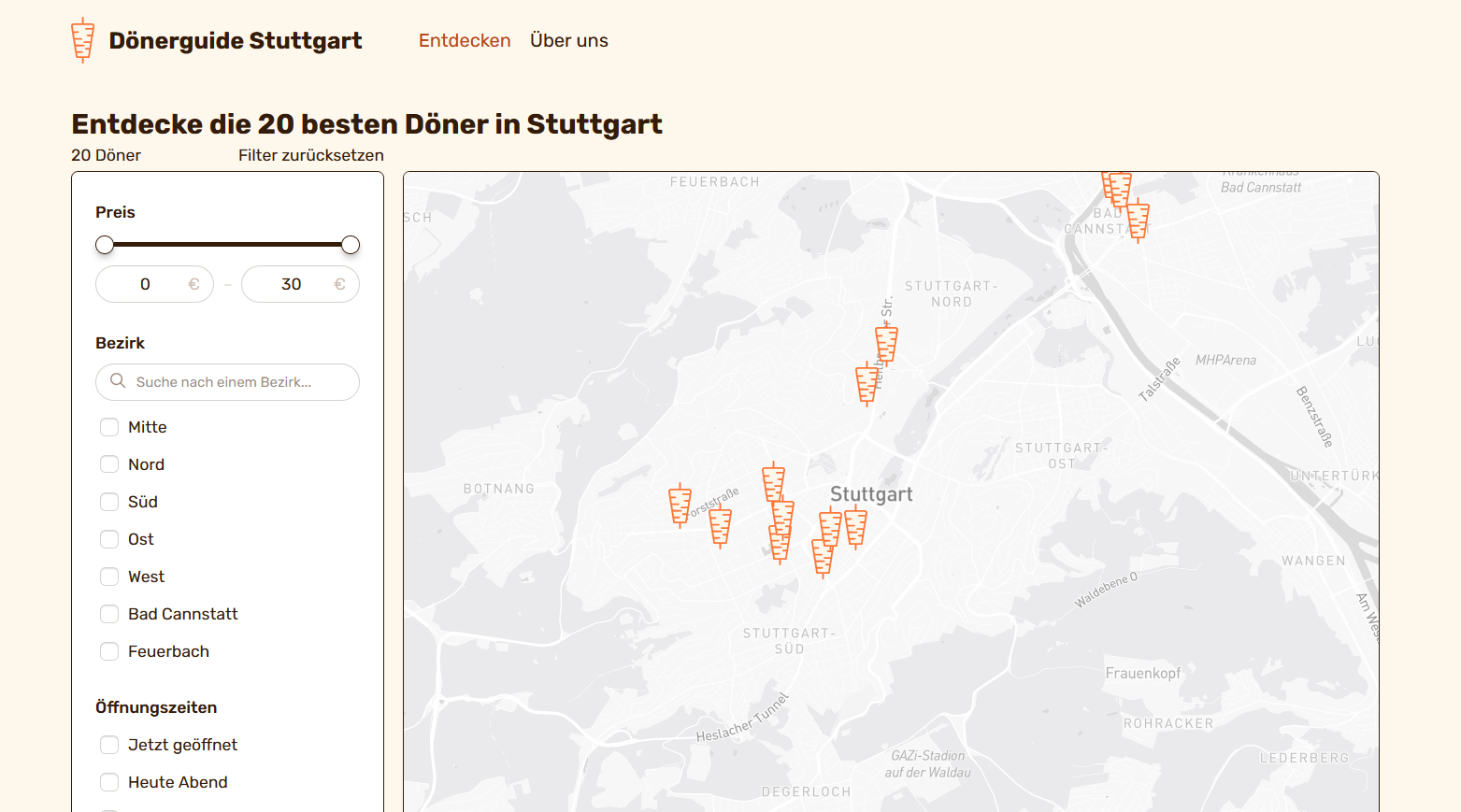
Filterbare Döner-Suche
Im Zentrum der Anwendung steht eine dynamische Übersicht aller Dönerläden in Stuttgart. Diese kann nach verschiedenen Kriterien gefiltert werden, wie Preis, Bewertung, vegetarische Optionen, Zahlungsmethoden, Wartezeit oder dem Stadtbezirk. So lassen sich sehr spezifische Anforderungen direkt abbilden.
Kartenintegration
Alle Ergebnisse werden zusätzlich auf einer interaktiven Karte visualisiert, wodurch Nutzer:innen neben der Liste eine Übersicht der verschiedenen Standorte der Dönerläden haben.
KI-gestützte Dönerbewertung
Ein besonderes Alleinstellungsmerkmal ist die automatisierte Analyse von Dönerbildern. Eine KI-Pipeline bewertet Bilder anhand mehrerer Kriterien, darunter der Geschmackseindruck, Belag, Verhältnis der Zutaten und die Gesamtqualität. Aus diesen Faktoren entsteht ein strukturierter Score, der eine vergleichbare Bewertung zwischen verschiedenen Läden ermöglicht.
Damit ergänzt die KI klassische Nutzerbewertungen um eine objektivierbare Perspektive.
II. Architektur
Der Dönerguide besteht aus zwei klar getrennten Verantwortlichkeiten: einer KI-Datenpipeline, die automatisch Dönerläden findet, Bilder analysiert, Bewertungen und Bilder für die Dönerläden generiert, und einer API, die diese Daten für das Frontend bereitstellt.
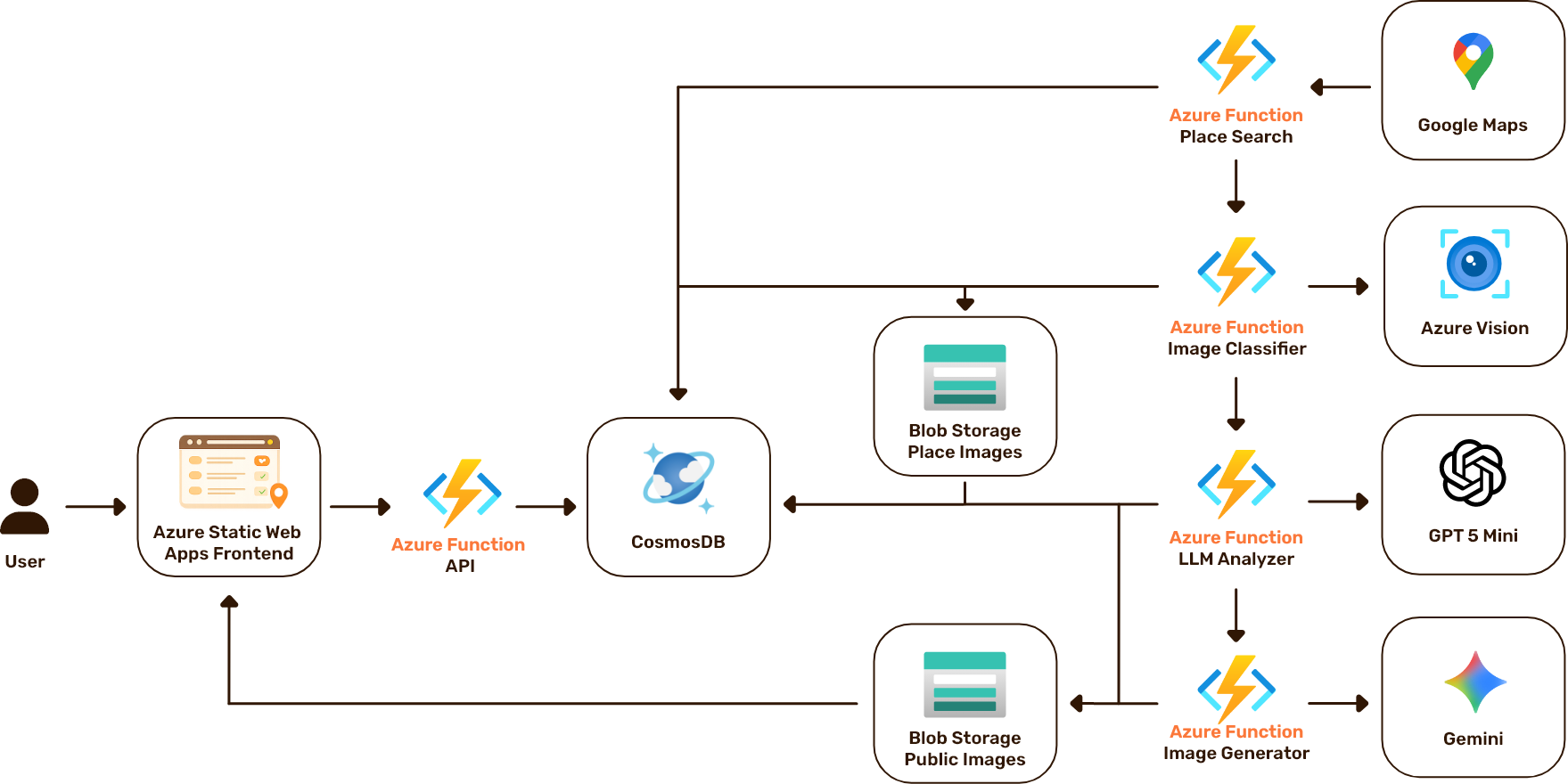
Als Alternative haben wir einen Monolithen in Betracht gezogen, z.B. eine Express-Anwendung mit eingebautem Scheduler, die Aggregation und API in einem Docker-Container vereint. Aus zwei Hauptgründen haben wir uns gegen diese Variante entschieden: Die Pipeline hätte die API-Performance beeinflussen können, und der Container hätte durchgehend laufen müssen, obwohl die Pipeline nur alle 15 Minuten ausgeführt wird.
Stattdessen entschieden wir uns für einen lose gekoppelten Ansatz mit Azure Functions und Azure Service Bus. Jede Function übernimmt eine einzige Aufgabe und kommuniziert ausschließlich über Queues, ohne direkte Abhängigkeiten zwischen den Functions. Das ermöglicht Zero Scaling (Kosten entstehen nur bei Ausführung), automatisches Circuit-Breaker-Verhalten über die Dead-Letter-Queue sowie unabhängige Entwicklung und Deployment pro Function.
Diese Architektur bringt auch Nachteile mit: Die API-Function hat messbare Cold Starts beim ersten Request, das verteilte System ist aufwändiger zu debuggen als ein einzelner Prozess. Dazu mehr im Abschnitt Learnings.
Frontend
Wenn man ein Projekt wie den Dönerguide Stuttgart startet, stellt man sich am Anfang immer die gleiche Frage: „Welches Werkzeug nehmen wir eigentlich?“ Wir wollten eine Lösung, die modern ist, Spaß macht und vor allem performant läuft. Hier ist der Deep Dive in unsere Frontend-Entscheidungen.
Das NextJS Frontend

Für das „Gesicht“ unserer Anwendung haben wir uns auf das bewährte Trio aus NextJS, TypeScript und DaisyUI verlassen.
- Warum NextJS? Ganz ehrlich: Wir hatten bereits Experten für dieses Framework im Team. Das hat uns den Start enorm erleichtert. Andere Frameworks wie Angular fühlten sich für unser Vorhaben einfach zu überdimensioniert an. Und bei Svelte? Da hatten wir Bauchschmerzen wegen des (noch) fehlenden direkten Supports für Azure. NextJS passte also am besten.
- Statisch, aber oho: Unser Frontend ist zwar statisch gebaut, füttert sich aber dynamisch mit Daten über einen REST-API-Endpoint von unserem Döner-Backend. So bleibt die Seite blitzschnell, zeigt aber immer die aktuellsten Döner-Rankings an.
Karten-Chaos: Von Google Maps zu Mapbox
Ein Highlight unserer App ist die Karte, auf der ihr alle Dönerläden in Stuttgart findet. Ursprünglich wollten wir Google Maps nutzen. Aber als wir das Preisschild von 100 Dollar pro Monat für den passenden API-Key sahen, sind wir fast vom Stuhl gefallen.
Die Rettung? Mapbox! Es basiert auf OpenStreetMaps, ist deutlich budgetfreundlicher und hat einen riesigen Vorteil: Wir konnten unser eigenes Design direkt in die Karte integrieren. Damit sieht die Map genauso schick aus wie der Rest der App.
Hosting mit Azure Static Web Apps
Beim Hosting haben wir keine Experimente gemacht. Da unser komplettes Backend sowieso in der Azure-Cloud lebt, war es nur logisch, auch das Frontend über Azure Static Web Apps laufen zu lassen. Alles aus einer Hand macht die Pipeline einfach viel entspannter.
Die Struktur der App haben wir dabei bewusst schlank gehalten:
- Main Page: Filtern, Suchen, Liste anschauen oder direkt auf der Karte den nächsten Snack finden.
- Store Pages: Die Detailansichten für jeden einzelnen Dönerladen.
- Der Rest: Kontakt, Datenschutz und Impressum.

Backend & Infrastruktur
Der Dönerguide läuft vollständig auf Azure. Fünf Functions bilden das Rückgrat der Anwendung: Der Suchdienst läuft mit einem Timer (Cron)-Trigger und findet Dönerläden über die Google Maps API. Die Bildklassifizierung verarbeitet die Fotos der Läden mit Azure Computer Vision, klassifiziert diese in Essen und Ambiente und speichert sie in einem Blob Storage Container. Der LLM-Bewertungsgenerator erstellt auf Basis der klassifizierten Bilder KI-Bewertungen über Azure OpenAI mit GPT-5 mini. Der Bildgenerator erstellt mit Nano Banana synthetische Bilder zu den Läden über die Google Gemini API. Die API ist die einzige Function mit einem HTTP-Trigger und liefert die aufbereiteten Daten an das Frontend.
Die Functions kommunizieren ausschließlich über Azure Service Bus. Drei Queues verbinden die Pipeline: Die erste übergibt neue Läden an die Bildklassifizierung, die zweite klassifizierte Bilder an den Bewertungsgenerator, die dritte Bild-Prompts an den Bildgenerator. Durch diese Entkopplung hat jede Function nur Kenntnis von ihrer eigenen Queue, Daten werden über Messages mit minimalen Informationen weitergegeben und können nicht bei der übertragung verloren gehen
Als Datenbank haben wir uns für die Azure CosmosDB entschienden, unter anderem wegen des Pay-as-you-go-Modells, der automatischen Skalierung und des flexiblen Dokumentenmodells, das schnelle Iteration ohne striktes Schema-Management ermöglicht.
Alle Azure-internen Dienste (CosmosDB, Service Bus, Blob Storage) werden über Managed Identity angebunden, ohne Credentials im Code. Externe API-Keys (Google Maps, Google Gemini) werden im Key Vault verwaltet.
Für Monitoring hat jede Function eine eigene Application-Insights-Instanz; ein zentraler Log Analytics Workspace ermöglicht übergreifende Auswertung. Das Next.js-Frontend läuft als Azure Static Web App mit Custom Domain über Cloudflare DNS.
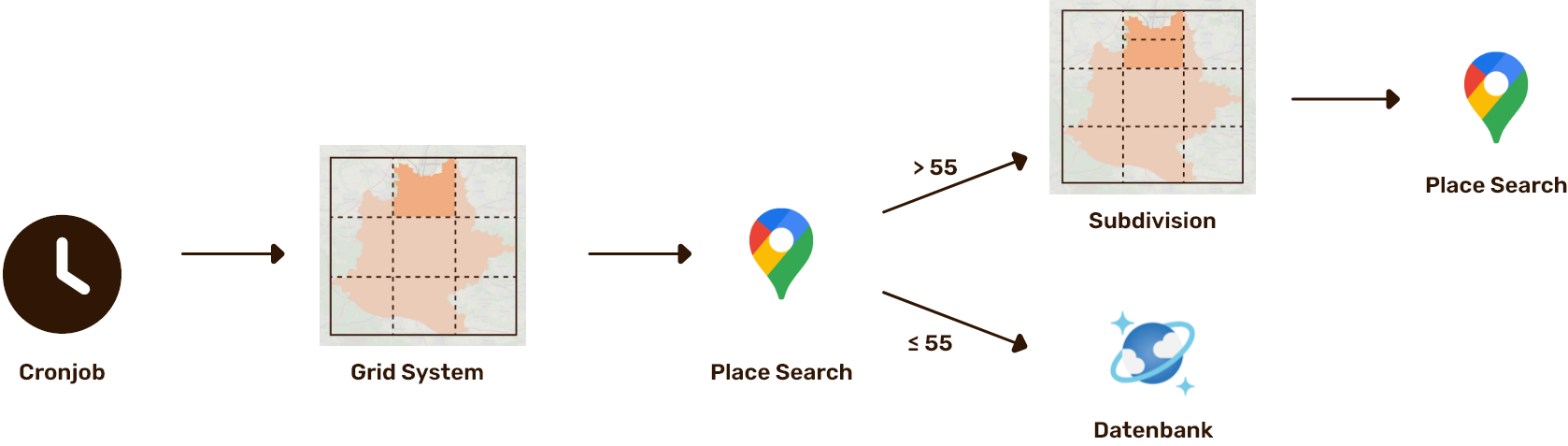
Place Search Algorithmus
Die Google Places API liefert pro Suchanfrage maximal 60 Ergebnisse. Stuttgart hat aber deutlich mehr als 60 Dönerläden. Eine einzelne Suche über das gesamte Stadtgebiet liefert dadurch unvollständige Ergebnisse. Deswegen wird ein Algorithmus benötigt, der das Stadtgebiet systematisch in kleinere Bereiche zerlegt, um möglichst alle Läden zu finden.
Die Place Search ist eine Timer-getriggerte Azure Function, die alle 16 Stunden ausgeführt wird. Pro Durchlauf wird genau eine Zelle des Grids verarbeitet. Gefundene Dönerläden werden in CosmosDB gespeichert, neue Fotos per Azure Service Bus an die KI-Pipeline (Image Classifier) weitergeleitet. Die Zellen des Grids werden ebenfalls in CosmosDB abgespeichert, sodass der Fortschritt zwischen den Funktionsaufrufen erhalten bleibt. Die Place Search bildet damit den ersten Schritt in unserer Pipeline: Place Search → Datenbank → KI-Analyse → Frontend.
Unsere Lösung
Google Places API
Wir nutzen die Google Places API (New) mit dem Text-Search-Endpoint, um Dönerläden zu finden und alle relevanten Daten abzufragen, darunter Name, Standort, Öffnungszeiten und Fotos. Als Suchanfrage wird “Döner” übergeben.
Die API liefert maximal ~20 Ergebnisse pro Seite, über ein nextPageToken können bis zu 3 Seiten abgerufen werden. Daraus ergibt sich das harte Limit von ~60 Ergebnissen pro Suchbereich.
Grid-Erstellung
Das Stuttgarter Stadtgebiet wird anhand einer GeoJSON-Datei der Stadtgrenze in eine Bounding Box gesetzt und dann in ein kilometerbasiertes Grid aufgeteilt (~7 km Zellseitenlänge). Zellen, die außerhalb der Stuttgarter Stadtgrenze liegen, werden dabei verworfen, um unnötige API-Anfragen zu sparen.
Adaptive Verarbeitung (Splitting)
Pro Durchlauf fragt die Place Search Function die Google Places API für genau eine Zelle ab. Enthält eine Zelle 55 oder mehr Ergebnisse, wird sie gesplittet.
Das Splitting erfolgt als Binary Split. Dabei wird die Zelle entlang ihrer längeren Seite in zwei Hälften geteilt. Die neu entstandenen Zellen werden ebenfalls gegen die Stadtgrenze geprüft. Eine maximale Splitting-Tiefe von 10 und eine minimale Zellgröße von 50 m verhindern endloses Splitten.
Zellen-Merging (Post-Scan-Optimierung)
Nach einem vollständigen Durchlauf aller Zellen werden diese daraufhin untersucht, welche benachbarten Zellen zusammengeführt werden können. Zwei Zellen müssen dafür eine vollständige gemeinsame Kante teilen und ihre kombinierte Ergebnisanzahl darf 40 nicht überschreiten. Das Merge wird nur durchgeführt, wenn es tatsächlich API-Requests einspart.
Architekturentscheidungen
Warum Text Search statt Nearby Search?
Die Google Places API bietet zwei Suchendpoints: Text Search und Nearby Search. Text Search erlaubt eine semantische Suchanfrage wie “Döner”, wodurch gezielt Dönerläden gefunden werden. Nearby Search kann dagegen nur mit vordefinierten Typen filtern, was für unseren Anwendungsfall zu unflexibel ist.
Darüber hinaus lässt sich bei Text Search der Suchbereich als Rechteck definieren, während Nearby Search ausschließlich kreisförmige Bereiche (Mittelpunkt + Radius) unterstützt.
Text Search ermöglicht die semantische Suche nach “Döner” und erlaubt den Suchbereich als Rechteck zu definieren.
Warum ein rechteckiges Grid als Suchstrategie?
Für die räumliche Zerlegung gibt es zwei Optionen: kreisförmige Suchbereiche oder ein rechteckiges Grid. Radiusbasierte Suche klingt intuitiv, aber entweder überlappen sich die Kreise oder es entstehen Lücken.
Ein rechteckiges Grid hat dieses Problem nicht. Jede Koordinate gehört zu genau einer Zelle, wodurch eine lückenlose Abdeckung entsteht. Zusätzlich lässt sich ein rechteckiges Grid entlang der längeren Achse halbieren, wobei die entstehenden Kinderzellen direkt wieder als Suchbereiche verwendet werden können.
Ein rechteckiges Grid deckt das Stadtgebiet lückenlos ab und die Zellen lassen sich einfach teilen.
Warum Binary Split statt Quadtree?
Ein Quadtree teilt jede Zelle gleichmäßig in vier Rechtecke. Bei jedem Split entstehen dadurch vier neue Zellen und vier zusätzliche API-Requests. Das Problem dabei: In der Praxis hat häufig nur ein Teil der Zelle eine hohe Ergebnisdichte, die restlichen Rechtecke wären unnötig.
Mit einem Binary Split teilen wir dagegen entlang der längeren Achse und erzeugen nur zwei neue Zellen. Dadurch passt sich das Grid besser an die Form des Gebiets an, da jede Zelle wiederholt entlang ihrer längsten Seite geteilt wird.
Der Binary Split ist sparsamer als ein Quadtree und passt sich durch die Aufteilung besser an die tatsächliche Ergebnisdichte des Gebiets an.
Warum Split-Threshold bei 55 statt 60
Das API-Maximum liegt bei 60 Ergebnissen. Die API führt eine relevanzbasierte Suche durch und liefert nicht bei jeder Anfrage exakt dieselben Ergebnisse. Eine Zelle mit 58 Ergebnissen könnte in Wirklichkeit mehr Läden enthalten, abhängig vom Ranking der API.
Durch das Splitten bei 55 teilen wir solche Zellen auf. Die beiden kleineren Anfragen liegen jeweils weit unter dem Limit und liefern zusammen zuverlässiger alle Ergebnisse.
Früher splitten für vollständige Daten.
Warum werden Grid-Zellen in der Datenbank persistiert?
Die Persistenz der Zellen ermöglicht, dass sich das Grid über mehrere Durchläufe hinweg optimiert: Splitting und Merging passen die Zellen schrittweise an die tatsächliche Ergebnisdichte an und reduzieren so die Anzahl der API-Aufrufe. Ohne Persistenz würde man jedes Mal von vorne anfangen und dieser Fortschritt ginge verloren.
Die Datenbank speichert die Optimierungen des Grids.
Warum Timer-Trigger mit 16-Stunden-Intervall statt Batch-Verarbeitung?
Azure Functions sind für kurzlebige Ausführungen ausgelegt. Ein vollständiger Batch-Durchlauf über alle Zellen würde das Execution-Timeout überschreiten und ist damit in einer Serverless-Umgebung nicht praktikabel. Der Timer-Trigger mit einer Zelle pro Ausführung löst dieses Problem.
Zusätzlich verteilt der Timer-Trigger die API-Requests gleichmäßig über die Zeit und vermeidet so Rate Limiting. Schlägt ein Durchlauf fehl, wird nur diese eine Zelle beim nächsten Mal erneut verarbeitet.
Das 16-Stunden-Intervall ergibt sich direkt aus unserer Anforderung von 14 Tagen pro vollständigem Durchlauf, was für einen Döner-Guide mit geringer Änderungsrate ausreicht. Bei ~20 Zellen entspricht das einer Ausführung alle 16 Stunden.
Der Timer-Trigger macht die Place Search serverless-kompatibel.
III. Challenges
Challenge: State Management im Frontend
Die Explore Seite ist das zentrale Interface unseres Dönerguides: Benutzer können nach Preis, Stadtteil, Score, Soßenmenge, Fleischanteil oder Eigenschaften wie halal bzw. vegetarisch filtern und die Ergebnisse zusätzlich sortieren. Was zuerst wie eine einfache Filterliste aussah, stellte sich im Frontend schnell als State Management Challenge heraus.
Ausgangssituation: UI, URL und Backend müssen synchron bleiben
Für eine gute User Experience wollten wir drei Anforderungen gleichzeitig erfüllen:
- Direktes UI Feedback: Filter (z. B. Slider oder Checkboxen) sollen sich sofort aktualisieren.
- Persistenter Zustand über die URL: Filter und Sortierung sollen bei Reload, Navigation oder Bookmark erhalten bleiben.
- Kontrollierte Backend Requests: Interaktionen wie das Bewegen eines Sliders dürfen nicht dazu führen, dass ständig neue API Calls an das Backend geschickt werden.
Diese drei Ziele stehen in einem gewissen Spannungsverhältnis: Bindet man die UI direkt an die URL, wirkt sie träge. Hält man alles nur lokal, gehen Navigation und Persistenz verloren.
Lösung: Trennung von UI State und URL State
Unser Ansatz war eine klare Aufgabentrennung zwischen zwei States:
- Der URL State (
urlParamsübernuqs) wird debounced aktualisiert und repräsentiert den persistenten Zustand der Seite. - Der UI State (
uiFilters,uiSort) wird direkt durch Nutzerinteraktionen aktualisiert und steuert die sichtbare Oberfläche.
Im Hook sieht diese Trennung so aus:
// URL state
const [urlParams, setUrlParams] = useQueryStates(exploreParsers)
// UI state (instant feedback)
const [uiFilters, setUiFilters] = useState(urlFilters)
const [uiSort, setUiSort] = useState(urlParams.sort)Beispiel: Interaktion mit dem Preis Slider
Bewegt ein Nutzer den Preis Slider, wird zunächst nur der UI State aktualisiert:
const handleFiltersChange = () => {
setUiFilters(filters) // sofortiges UI Update
updateFiltersDebounced(filters, uiSort) // verzögertes URL Update
}Der Slider reagiert dadurch direkt. Die URL hingegen wird erst nach kurzer Inaktivität synchronisiert:
const DEBOUNCE_MS = 300
const updateFiltersDebounced = async (newFilters, sort) => {
window.setTimeout(async () => {
await setUrlParams(newFilters, sort)
}, DEBOUNCE_MS )
}Zieht man den Slider beispielsweise von 6 € auf 10 €, passieren mehrere UI Updates, aber nur ein URL Update nach Ende der Interaktion. Dadurch bleibt die Oberfläche flüssig, während der persistente Zustand konsistent gespeichert wird.
Fetch-Trigger über den URL-State
Der eigentliche Daten Fetch hängt bewusst am URL State, nicht an der UI Interaktion. Sobald die URL aktualisiert wird, synchronisieren wir UI und Daten:
useEffect(() => {
setUiFilters(urlFilters)
setUiSort(urlParams.sort)
void fetchData(urlFilters, urlParams.sort)
}, [urlParams, urlFilters, fetchData])Die Update Kette lautet somit:

Sortierung behandeln wir bewusst anders
Im Gegensatz zu Slidern wird die Sortierung nicht schrittweise verändert, sondern einmalig ausgewählt (Dropdown). Deshalb wird die URL hier ohne Verzögerung aktualisiert.
const handleSortChange = async (newSort) => {
setUiSort(newSort)
setUiFilters(filters)
updateFiltersImmediate(filters, newSort)
}Stale Requests verhindern (Race Conditions)
Wenn Filter schnell wechseln oder das Backend langsam antwortet, können Responses in falscher Reihenfolge zurückkommen. Damit die alten Daten nicht die neuen überschreiben, vergeben wir für jeden Request eine ID und stellen sicher, dass nur die letzte Anfrage übernommen wird.
const requestIdRef = useRef(0)
const fetchData = async (filters, sort) => {
const currentRequestId = ++requestIdRef.current
const payload = await fetchPlaces(filters, sort)
if (currentRequestId !== requestIdRef.current) return // veraltete requests ignorieren
setStores(payload.items)
}Challenge: Page Indexing von Slug-URLs für Azure
Ein Fehler ist bei uns furchtbar lange unter dem Radar geblieben: Wir hatten das Problem, dass einige unserer Stores nicht korrekt angezeigt wurden. Stattdessen bekamen die Nutzer einen unschönen Azure 404 Error zu sehen.
Das sah dann etwa so aus:https://doenerguide-stuttgart.de/ChIJryPzk07bmUcRsC6cdRmB7Jk -> Azure 404
Wir konnten es erst gar nicht glauben. Die API funktionierte einwandfrei und wir hatten sogar eine eigene Dönerguide-Errorpage entworfen, auf die bei fehlenden Daten verlinkt werden sollte. Lokal trat dieser Fehler natürlich nicht auf.
Nach viel Recherche fiel uns auf: Im Deployment-Log tauchten nur die Links auf, die auch tatsächlich funktionierten. Dort wurden lediglich 20 Routen geloggt, obwohl wir eigentlich hunderte Stores in unserer Datenbank haben und anzeigen wollen.
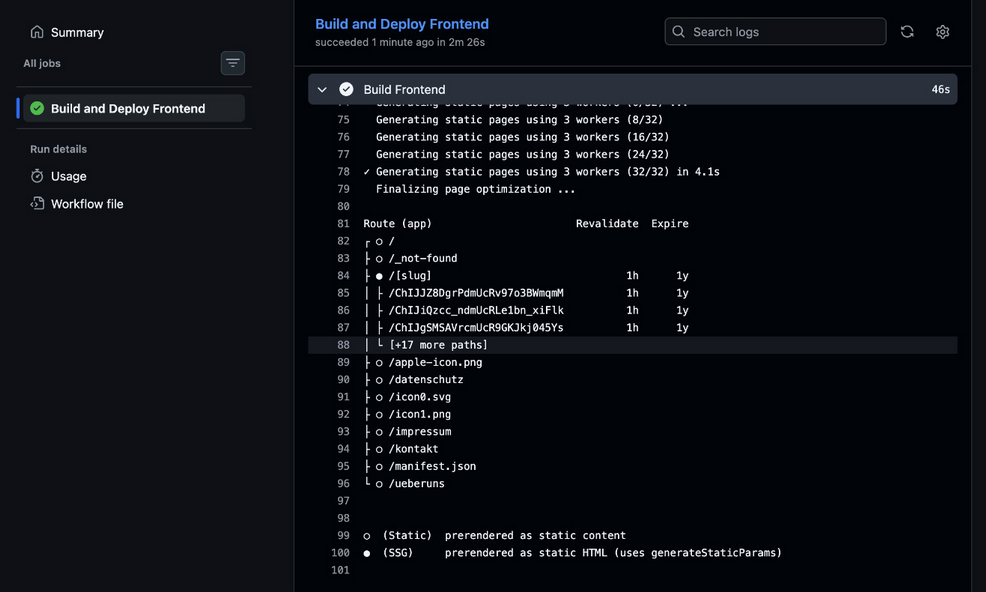
Es stellte sich heraus: Eine Azure Static Web App muss beim Deployment quasi “wissen”, welche statischen Links sie bereitstellen soll. Ansonsten zeigt Azure seinen eigenen 404-Fehler an.
Die Lösung: generateStaticParams
In NextJS gibt es eine feine Funktion für statische Webseiten, die genau dieses Problem löst. Wir mussten NextJS dazu bringen, bereits beim Build-Prozess alle IDs unserer Stores abzufragen und als Parameter zu definieren.
Im Code nennen wir diese IDs slug und die Läden places.
Die Lösung sah dann so aus:
export async function generateStaticParams() {
// Alle verfügbaren Plätze von der API abrufen
const data = await fetchPlaces('limit=2000')
const places = data.items || []
// Jede Slug-ID an NextJS (und damit an Azure) übergeben
return places.map((place: StoreBase) => ({
slug: place.slug,
}))
}Diese Definition sorgt dafür, dass Azure beim Deployment die kompletten Metadaten vom NextJS-Frontend erhält.
Challenge: Deployment
Beim Deployment der Infrastrukturkomponenten hatten wir zwei unerwartete Probleme.
Das erste betraf das Zusammenspiel von Terraform und dem Deployment-Prozess, der Functions. Bei jeder Infrastrukturänderung hat Terraform das Function-Deployment überschrieben, da deployment-relevante Felder nicht als ignore_changes markiert waren. Betroffen waren die Felder WEBSITE_RUN_FROM_PACKAGE, WEBSITE_ENABLE_SYNC_UPDATE_SITE und site_config[0].application_stack. Als Workaround haben wir zunächst ein automatisches Redeployment aller Functions in die Infrastruktur-Pipeline eingebaut. Die saubere Lösung war, diese Felder in Terraform als `ignore_changes` zu markieren, sodass Infrastruktur und Deployment klar getrennt sind.
Das zweite Problem betrifft das Azure-Tooling generell. Die Azure/functions-action für GitHub Actions erfüllt ihren Zweck, bietet aber weniger Flexibilität als das Deployment anderer Anbieter, bei denen sich Functions direkt über Terraform deployen lassen. Beim Frontend zeigte sich dasselbe Muster: Die Azure/static-web-apps-deploy-Action ließ sich nicht ausreichend an unsere Build-Anforderungen anpassen. Wir bauen das Frontend deshalb separat mit npm und nutzen die Action nur noch für das reine Deployment.
Challenge: Docker Setup unter ARM
Für die lokale Entwicklung emulieren wir die Azure-Infrastruktur vollständig per Docker. Auf Apple Silicon M-Chips sind wir dabei auf zwei Kompatibilitätsprobleme gestoßen.
Das erste war schnell gelöst: Der Service Bus Emulator benötigt Microsoft SQL Edge als Datenbank, welche keinen ARM-Support hat. Als Ersatz konnten wir mssql/server:2022-latest verwenden.
Das zweite Problem war aufwändiger in der Fehlersuche. Die Azure Functions liefen in Node.js-Containern, die natürlich auch für ARM verfügbar sind. Was wir nicht wussten: Die Azure Functions Dependency enthält ein Installationsskript, das bei der Installation die Functions Runtime aus dem Internet nachlädt. Auf ARM schlägt dieses Skript fehl, weil keine ARM-Runtime verfügbar ist. Der entscheidende Punkt dabei: kein Fehler, kein Log. Die Functions starteten einfach nicht.
Um die Ursache zu finden, haben wir den node_modules-Ordner zwischen einer Linux-x86-Installation und der M-Mac-Installation verglichen. Die Functions Runtime hat auf ARM gefehlt. Beim genaueren Untersuchen der Dependency, fanden wir das Installationsskript und sahen, wie es den Download-Link für die Runtime dynamisch zusammengebaut hat. Der Link existierte für ARM schlicht nicht.
Die Lösung: platform: linux/amd64 in compose.yaml erzwingt x86-Emulation, Docker lädt die korrekte Runtime und alles läuft. Tradeoff ist eine spürbar schlechtere Performance durch die Emulation.
Challenge: Place Search Algorithmus Optimierung
Der Place Search Algorithmus wurde über mehrere Iterationen hinweg optimiert. Jede Änderung war durch eine beobachtete Ineffizienz motiviert. Das Ziel war immer dasselbe: die Anzahl der API-Requests reduzieren, ohne die Abdeckung des Stadtgebiets zu verlieren. Die folgenden Abschnitte beschreiben die drei zentralen Herausforderungen und wie wir sie gelöst haben.
Ausgangslage: Das erste Grid
Die erste Version nutzte vier fest kodierte Koordinaten als Bounding Box um Stuttgart und teilte diese in ein fixes 4×4-Grid mit 16 gleichmäßigen Zellen auf. Die Zellgröße war dadurch eine Konsequenz der 4×4-Aufteilung. Außerdem waren die Zellen in Ost-West-Richtung geometrisch verzerrt, weil ein Grad Längengrad bei 48°N nur rund 73 km entspricht, aber ein Grad Breitengrad immer ~111 km. Gab es in einer Zelle mehr als 55 Ergebnisse, wurde sie in zwei Kinderzellen gesplittet. Für alle Zellen innerhalb der Bounding Box wurde die API angefragt.
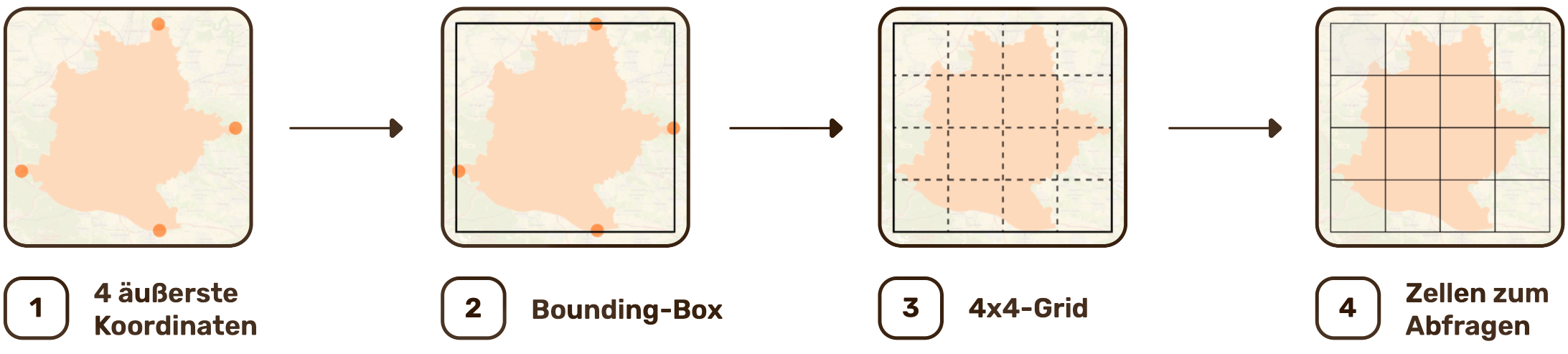
Herausforderung 1: Unnötige Anfragen außerhalb der Stadtgrenze
Problem: Die Eckzellen der Bounding Box lagen teilweise vollständig außerhalb des Stuttgarter Stadtgebiets. Diese Zellen lieferten keine Ergebnisse, kosteten aber trotzdem jeweils einen API-Request.
Ursache: Die Bounding Box ist ein Rechteck, Stuttgart ist ein unregelmäßiges Polygon. Die Ecken eines Rechtecks um ein unregelmäßiges Gebiet enthalten Flächen ohne Relevanz.
Lösung: Wir haben die GeoJSON-Stadtgrenze Stuttgarts als Multipolygon hinterlegt. Bei der Grid-Erstellung wird jede Zelle mit booleanIntersects aus Turf.js gegen dieses Polygon geprüft. Nur Zellen, die tatsächlich mit dem Stadtgebiet überlappen, werden ins Grid aufgenommen. Derselbe Filter wird auch beim Splitting angewendet: Wenn eine Kindzelle nach dem Split außerhalb der Stadtgrenze liegt, wird sie verworfen.
Ergebnis: Zwei Eckzellen des 4×4-Grids wurden entfernt. Dadurch sank die durchschnittliche Anzahl der API-Requests von 26 auf 24, was einer Ersparnis von 8 % entspricht.
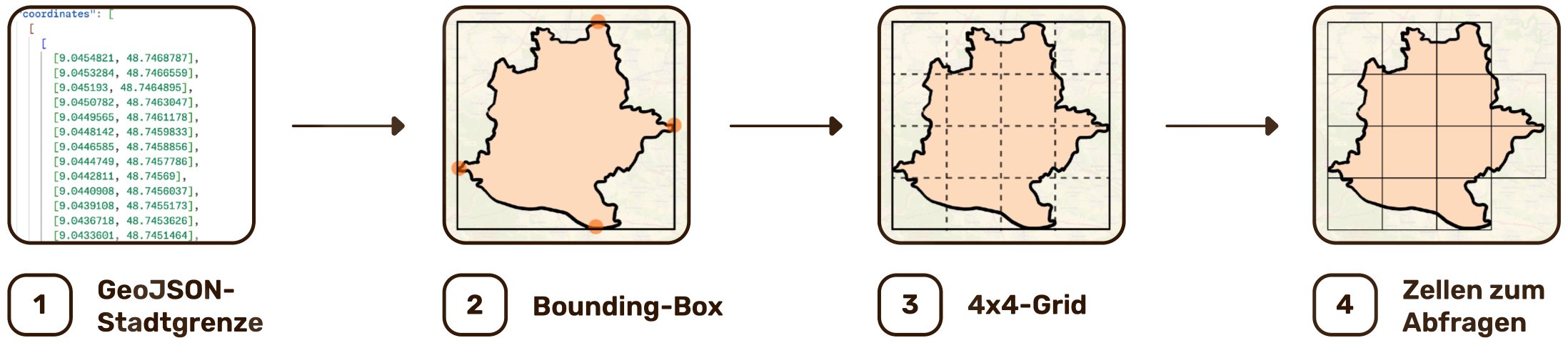
Herausforderung 2: Starres Grid ohne konfigurierbare Zellgröße
Problem: Die Zellgröße war nicht auf das Stuttgarter Stadtgebiet abgestimmt. Das 4×4-Grid erzeugte 16 Startzellen, ohne Rücksicht darauf, ob diese Größe für die tatsächliche Ergebnisdichte sinnvoll ist. Eine zu kleine Zellgröße bedeutet mehr Startzellen und damit mehr API-Requests von Anfang an, eine zu große führt zu mehr Splits. Deswegen musste die richtige Größe gefunden werden. Zusätzlich war das Grid geometrisch verzerrt: Die Zellen waren in Ost-West-Richtung schmaler als in Nord-Süd-Richtung.
Ursache: Die Grid-Erstellung war hardcoded auf 4×4. Dadurch war die Zellgröße eine Konsequenz der Aufteilung. Die geometrische Verzerrung entstand, weil die Zellgrenzen in Grad-Koordinaten berechnet wurden: Bei 48°N entspricht ein Grad Längengrad nur rund 73 km, ein Grad Breitengrad dagegen ~111 km.
Lösung: Wir haben auf ein kilometerbasiertes Grid umgestellt. Die Zellgröße ist jetzt ein konfigurierbarer Parameter. Die Anzahl der Zeilen und Spalten ergibt sich automatisch aus der Bounding Box und der gewählten Zielzellgröße. Wir rechnen nun Kilometer in Grad-Koordinaten um und korrigieren dabei die Verzerrung, die durch die Erdkrümmung entsteht. Auch der Split-Algorithmus vergleicht Seitenlängen jetzt in Kilometer.
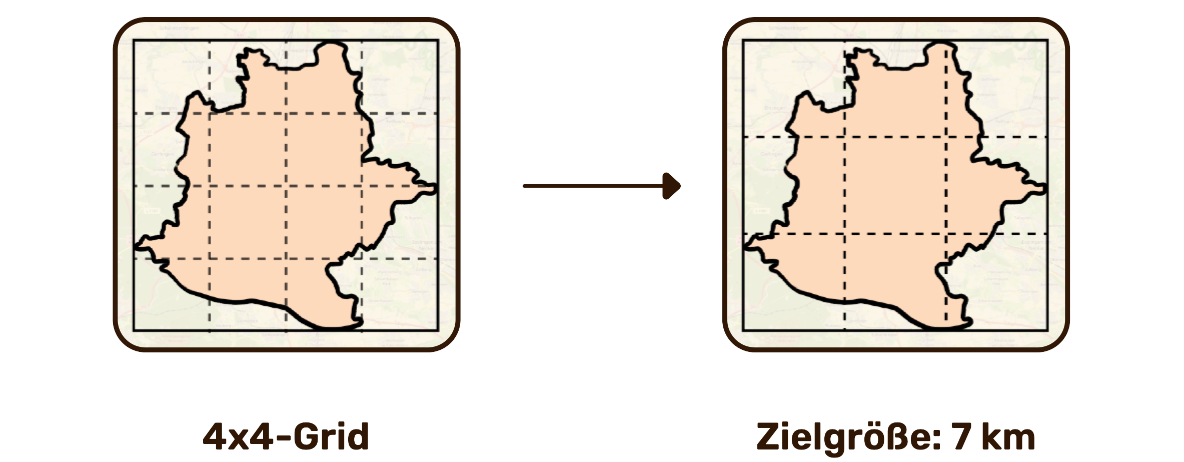
Ergebnis: Die Zellgröße wurde zum steuerbaren Parameter. Verschiedene Werte konnten per Benchmark verglichen werden. Eine Zielzellgröße von 7 km ergab ein 3×3-Grid mit 9 Zellen statt 16. Das sind 7 Startzellen weniger. Gleichzeitig sind die Zellen geometrisch korrekt und der Split erfolgt entlang der tatsächlich längeren Seite. Dadurch sank die durchschnittliche Anzahl der API-Requests von 24 auf 20, was einer Ersparnis von 23 % gegenüber dem Original entspricht.
Herausforderung 3: Sparse Zellen nach dem Splitting
Problem: Nach einem vollständigen Scan-Durchlauf hatten manche benachbarte Zellen nur wenige Ergebnisse. Beispielsweise könnte eine Zelle 8 und ihre Nachbarzelle 10 Ergebnisse enthalten. Jede dieser Zellen benötigt mindestens einen API-Request, obwohl sie zusammen nur 18 Ergebnisse hätten und damit unter dem Limit von 20 pro Anfrage liegen. Also werden zwei Requests verbraucht, obwohl einer genügt hätte.
Lösung: Nach dem Scan werden benachbarte Zellen durch einen Merging-Algorithmus zusammengeführt. Ein Merge muss vier Bedingungen erfüllen:
- Die Zellen müssen eine vollständige gemeinsame Kante teilen.
- Die kombinierten Ergebnisse dürfen 40 nicht überschreiten.
- Der Merge muss tatsächlich API-Requests einsparen.
- Die resultierende Zelle darf nicht größer als 15 km Seitenlänge sein.
Die Kernidee: Ein Merge wird nur durchgeführt, wenn er tatsächlich API-Requests einspart. Da die Google Places API maximal 20 Ergebnisse pro Request liefert, braucht eine Zelle mit 8 Ergebnissen einen Request und eine mit 10 Ergebnissen ebenfalls einen, zusammen also zwei. Merged man beide, hat die neue Zelle 18 Ergebnisse, die in einem einzigen Request abgedeckt werden. Der Merge spart also einen Request. Anders bei 18 und 7 Ergebnissen: Zusammen sind das 25, was immer noch zwei Requests erfordert. In diesem Fall findet kein Merge statt. Merges werden iterativ durchgeführt, wobei zusammengeführte Zellen erneut als Kandidaten für weitere Merges gelten.
Ergebnis: Durch das Merging sank die durchschnittliche Anzahl der API-Requests von 20 auf 19,5, was einer Gesamtersparnis von 25 % gegenüber dem Original entspricht.
Einschränkung: Bei einer Basiszellgröße von 7 km ist der Effekt des Mergings begrenzt. Sparse Zellen entstehen vor allem am Stadtrand, wo Zellen nur teilweise mit dem Stadtgebiet überlappen und deshalb wenige Ergebnisse liefern. Bei 7 km großen Basiszellen gibt es jedoch nur wenige solcher Randzellen, sodass das Merge-Potenzial gering bleibt. Mit kleineren Basiszellen würden mehr Randzellen entstehen und damit auch mehr Merge-Kandidaten, allerdings steigt dann auch die Gesamtzahl der Startzellen, was den Vorteil wieder aufheben kann.

Ergebnisse
Die drei Optimierungen wurden mit einem eigenen Benchmark-Skript gegen die echte Google Places API gemessen. Der Benchmark führt alle Strategien unter identischen Bedingungen aus und zählt die tatsächlichen API-Requests.
| Strategie | Ø API-Requests | Ersparnis |
|---|---|---|
| Original (4×4-Grid) | 26 | |
| Stadtgrenze nutzen | 24 | 2 (8 %) |
| Konfigurierbare Zellgröße (7 km) | 20 | 6 (23 %) |
| Zellen zusammenführen | 19,5 | 6,5 (25 %) |
Über 10 Benchmark-Läufe ergibt sich eine Reduktion von 26 auf 19,5 Requests, also etwa 25 %. Die Einsparungen setzen sich aus drei Quellen zusammen: weniger Startzellen durch die Stadtgrenze-Filterung, eine optimierte Zellgröße durch das konfigurierbare kilometerbasierte Grid und gelegentliche Merges von sparse Zellen nach dem Scan.
Challenge: Performance-Optimierung von Functions
Unsere Architektur nutzt Azure Functions, dessen Lebenszyklus in mehreren aufeinanderfolgenden Phasen abläuft. Wenn die Funktion nach längerer Inaktivität erstmals aufgerufen wird, kommt es zu einem sogenannten Cold Start. In dieser Phase wird der Code zunächst geladen und anschließend ausgeführt. Nach dieser initialen Ausführung wird die Funktion jedoch nicht sofort wieder abgeschaltet, sondern bleibt für etwa 10 bis 20 Minuten “warm” im Arbeitsspeicher (RAM) erhalten, um auf nachfolgende Anfragen verzögerungsfrei reagieren zu können. Erfolgen in diesem Zeitfenster keine weiteren Aufrufe, wird die Instanz beendet. Ein wesentliches Merkmal dieses Modells ist die effiziente Ressourcennutzung, da stets nur die reine Ausführungszeit vom eingehenden Request bis zur finalen Response gemessen und abgerechnet wird.
Das Problem: Unser Frontend benötigte bei jedem Seitenwechsel oder beim Sortieren 5 bis 7 Sekunden Ladezeit. Der Grund war nicht der Cold Start, sondern ein ineffizientes Datenmanagement in der “Warm”-Phase. Jeder Klick löste eine komplett neue Abfrage an die CosmosDB aus. Dadurch verschlechterte sich die User Experience und es wurde bei jedem Request unnötig Rechenkapazität verschwendet.
Die Lösung Wir haben den RAM der Azure Function, der nach dem ersten Aufruf ohnehin bestehen bleibt, strategisch genutzt, um dieses Problem zu beheben:
- In-Memory Caching: Wir speichern die Datenbank-Rohdaten in einer globalen Variablen. Solange die Funktion “warm” ist, werden nachfolgende Requests, wie Pagination oder Sortierung, direkt aus dem Arbeitsspeicher bedient. Das verhindert einen komplett neuen Aufruf an die Datenbank.
- HTTP Cache-Control: Zusätzlich senden wir einen Cache-Control-Header mit dem Wert „max-age=60” an das Frontend. Wenn ein Nutzer auf eine zuvor besuchte Seite navigiert, lädt der Browser die Daten aus seinem lokalen Cache, was die Ladezeit deutlich reduziert.
Challenge: Prompt-Engineering
Am Anfang unserer Prompt-Engineering Reise beschränkten sich unsere Bewertungstexte auf das Aussehen des zu bewertenden Döner. Es fehlte das Menschliche, die Persönlichkeit, die echte Google Maps-Reviews ausmacht.
Das Problem war offensichtlich: Unsere generierten Bewertungen waren viel zu generisch, um als authentische Texte von echten Menschen durchzugehen. Doch wie schafft man es, dass KI-generierte Bewertungen unterschiedlich klingen, so als würden verschiedene Menschen schreiben?
Die Lösung: Personas im Prompt Engineering
Die Antwort fanden wir in einem Konzept namens “Persona Prompting”. Statt der KI einfach zu sagen “Bewerte diesen Döner”, erschaffen wir detaillierte Charaktere mit eigenen Persönlichkeiten, Präferenzen und Schreibstilen. Diese Personas geben der KI einen Kontext und eine “Rolle”, in die sie schlüpfen kann.
Warum funktioniert das? Die Wissenschaft dahinter
Forschungsergebnisse zeigen, dass Persona Prompting besonders effektiv für offene, subjektive Aufgaben wie kreatives Schreiben ist [1]. Döner-Bewertungen sind genau das: subjektive, offene Aufgaben, bei denen es um Meinungen zu Geschmack, Atmosphäre und Service geht.
Ein weiterer Vorteil: Bei Restaurant-Reviews werden sowohl explizite Faktoren (Geschmack, Portionsgröße, Preis, Servicequalität) als auch implizite Persönlichkeitsmerkmale aus dem Schreibstil extrahiert. Personas helfen der KI, diese verschiedenen Ebenen natürlich miteinander zu verweben.
Unsere drei Personas: Vielfalt durch unterschiedliche Perspektiven
Wir haben uns für drei grundlegend verschiedene Reviewer-Typen entschieden, die unterschiedliche Zielgruppen und Bewertungsperspektiven repräsentieren:
Sasha (45) – Der traditionsbewusste Experte
Sasha ist unser Qualitätsprüfer mit türkischen Wurzeln und jahrelanger Gastronomie-Erfahrung. Er kennt die traditionelle Zubereitung in- und auswendig und bewertet mit kritischem, aber fairem Blick.
Sarah (28) – Die Food-Bloggerin mit Auge fürs Detail
Sarah ist unsere enthusiastische Food-Bloggerin, die Döner mit viel Liebe zum Detail und einem Auge für Ästhetik bewertet. Sie denkt in Instagram-Perspektiven: “Würde ich das fotografieren?”
Marco (35) – Der pragmatische Stammkunde
Marco ist unser Alltags-Experte, der 2-3 Mal pro Woche Döner isst. Er bewertet pragmatisch mit Fokus auf Preis-Leistung und vergleicht ständig mit seinem Stammladen.
Unsere Personas werden in dem Bewertungsteil unserer KI-Pipeline zufällig ausgewählt. Sie werden anschließend mit einem Basisprompt kombiniert, um diesselbe Grundstruktur im Ergebnis bei allen Personas zu gewährleisten.
Vor der Verwendung von Personas
“bewertungstext”: “Der Döner wirkt insgesamt sehr appetitlich und gut gefüllt;
die Fleischscheiben zeigen sichtbare Röstaromen und wirken saftig.
Die Zutaten sehen frisch aus — knackiger Salat, Rucola und eine gebratene Paprikascheibe
sorgen für schöne Farbakzente, dazu ist die Soße cremig sichtbar. Schwächen sind eine
leicht ungleichmäßige Soßenverteilung und eine ungewöhnlich große, runde Kartoffel in der
Mitte, die den Biss lokal ungleich macht. Das Fladenbrot ist stabil und hält die Füllung gut,
die saubere Präsentation und das helle Ambiente unterstützen den positiven Gesamteindruck.”,
“score_geschmack”: 8, “score_belag”: 8, “score_verhaeltnis”: 7, “score_gesamt”: 86
Nach der Verwendung von Personas
“bewertungstext”: “Für den Preis passt das hier ganz gut.
Viel Fleisch und schön saftig, Gemüse ist frisch und die Portion macht satt — bei meinem Stammladen krieg ich
zwar manchmal noch ne Spur mehr Raffinesse, aber hier stimmt das Preis-Leistungs-Verhältnis.
Schwäche ist die Soße: eher sparsam und ungleichmäßig verteilt, das macht den Döner teils etwas trocken.
Insgesamt kann man das locker als Alltagsessen empfehlen, hab schon bessere gesehen, aber auch deutlich schlechtere.”,
“score_geschmack”: 7,”score_belag”: 7,”score_fleischanteil”: 8,”score_soßenanteil”: 6,”score_gesamt”: 71
IV. Learnings
Frontend
Wir haben während der Entwicklung gemerkt, wo unsere Entscheidungen richtig waren und wo wir uns beim nächsten Mal vielleicht ein bisschen Arbeit gespart hätten.
NextJS: Der Gewinner
NextJS hat sich als phänomenal praktisches Framework herausgestellt. Die Routing-Struktur ist so intuitiv, dass wir uns oft gefragt haben: „Das war’s schon?“. Ohne zu tief in die Nerd-Details zu versinken: NextJS hat uns während der Programmierung immer wieder mit echten „Das ging aber schnell!“-Momenten überrascht.
Innerhalb des Teams hatten wir eine coole Mischung: Einige von uns brachten echtes Expertenwissen zum Framework mit, während der Rest des Teams heiß darauf war, ein modernes Tool zu lernen. Diese Synergie hat perfekt funktioniert. Die Lernkurve war steil, aber dank der guten Dokumentation und Struktur von NextJS extrem belohnend.
DaisyUI: Hätten wir auch weglassen können
Manchmal greift man im Eifer des Gefechts zu Tools, die man am Ende gar nicht so dringend braucht. DaisyUI war bei uns so ein Fall. Rückblickend hätten wir es auch weglassen können.
Versteht uns nicht falsch: Es ist ein tolles Plugin, aber uns hat es im Endeffekt kaum mehr als eine vorgefertigte Farbpalette geliefert. Spätestens als wir für unsere Filter komplexere UI-Elemente brauchten, wie zum Beispiel doppelseitige Slider für die Preis- oder Bewertungsauswahl, stieß DaisyUI an seine Grenzen. Diese Komponenten mussten wir dann selbst bauen.
Fazit hier: Pures Tailwind CSS hätte für unsere Anforderungen völlig ausgereicht und das Projekt noch ein Stück schlanker gehalten.
Backend & Infrastruktur
Rückblickend war unsere Architektur für den tatsächlichen Use Case überdimensioniert. Die Anwendung muss nicht massiv skalieren, und unsere KI-Pipeline hätte auch als einzelner Container zuverlässig funktioniert.
Ein einfacherer Alternativstack hätte ausgereicht: ein Docker-Container mit Cron-Trigger für die Pipeline und ein Always-on-Container für die API. Damit wäre das Deployment auf ein versioniertes Container-Image reduziert worden und mehrere der späteren Pain Points wären gar nicht erst entstanden: weniger Abhängigkeit von Azure-spezifischem Tooling, keine Cold Starts der API, und keine ARM-Inkompatibilitäten rund um den Service-Bus-Emulator bzw. Workarounds wie ignore_changes in Terraform.
Das Kernlearning ist weniger Azure-spezifisch: Komplexität sollte man dann hinzufügen, wenn man sie wirklich braucht, nicht auf Vorrat. Lieber simpel starten und bei Bedarf gezielt skalieren.
Der entscheidende Punkt: Die KI-API-Kosten (OpenAI, Gemini) waren deutlich höher als der Rest der Infrastrukturkosten. Die geringfügig höheren Infrastrukturkosten eines Always-on-Containers wären also irrelevant gewesen.
Place Search Algorithmus
Externe Constraints für die Architektur beachten: Die 60-Ergebnisse-Grenze der Google Places API hat uns gezwungen, die Architektur entsprechend auszurichten. Ohne dieses Limit wäre kein Grid, kein Splitting und kein Merging nötig gewesen. Auch auf Detail-Ebene war das API-Verständnis wichtig. Wir hatten zunächst locationBias verwendet, bis uns auffiel, dass nur locationRestriction eine harte Grenze definiert.
Einfaches Grunddesign mit gezielter Verfeinerung: Da in der Innenstadt mehr Ergebnisse zu erwarten sind, wollten wir dort kleinere Zellen verwenden und außen größere. Das Problem dabei war, dass sich unterschiedlich große Zellen nicht nahtlos aneinanderfügen lassen, sodass man mit Overlap arbeiten muss. Der Overlap führt aber zu doppelter Abdeckung und macht es schwieriger, die richtige Größe zu finden. Ein einheitliches Grid mit adaptivem Splitting war robuster.
Optimieren braucht Messbarkeit: Jede Änderung war durch eine konkret beobachtete Ineffizienz motiviert. Ob eine Änderung tatsächlich eine Verbesserung war, zeigte erst der Benchmark gegen die echte API. Ohne die wiederholbare Messung unter identischen Bedingungen wären die Einsparungen nur Vermutungen geblieben.
Serverless erzwingt inkrementelle Verarbeitung: Azure Functions haben ein Execution-Timeout, wodurch eine einzelne Ausführung nicht unbegrenzt laufen kann. Das hat uns dazu gezwungen, die Verarbeitung inkrementell zu denken. Jede Ausführung übernimmt genau eine Zelle, der aktuelle Zustand wird in der Datenbank gespeichert und beim nächsten Aufruf weitergeführt.
KI-Pipeline und Images
Durch Probleme in der Google API-Schnittstelle sind fehlerhafte Einträge in unserer Datenbank gelandet. Neben unseren Döner des Vertrauens finden sich nun auch verschiedene andere Restaurants auf unserer Webseite. Diese besitzen keinen erkennbaren Score-Unterschied durch unsere Bewertung.Die KI bewertet also Nicht-Dönerläden genauso wie echte Dönerläden, ohne dies zu erkennen.
Bevor die Bewertungstexte durch die KI generiert werden, gibt es keine weitere Überprüfung, ob das Restaurant tatsächlich Döner anbietet oder die mitgelieferten Bilder von Dönern sind. Die KI hat somit keine Plausibilitätsprüfung vor der Bewertung und geht immer davon aus, dass es sich um Dönerbilder handelt. Dadurch sucht sie selbst bei anderen Speisen nach Dönermerkmalen und interpretiert diese entsprechend. Hinzu kommt, dass wir aus Kostengründen keine Bilderbeispiele als Referenz mitliefern, wodurch alles, was entfernt nach Essen aussieht, als Döner interpretiert wird.
Daraus lernen wir, dass unsere Pipeline vor der Bewertung eine strikte Input-Validierung braucht. Dabei müssen die Bilder erstmals einen Precheck bestehen um bewertet zu werden. Anschließend könnte man einen Confidence-Threshold in der Ausgabe hinzufügen. Die KI kann damit ausdrücken mit welcher Sicherheit es sich um einen Döner handelt.
V. Fazit
Der Dönerguide diente uns als praktisches Szenario, um das Zusammenspiel von moderner Cloud-Infrastruktur und künstlicher Intelligenz zu testen. Auch wenn die gewählte Serverless-Architektur für den produktiven Einsatz eher großzügig dimensioniert war, bot sie die Möglichkeit, technologische Grenzen auszutesten und Praxiserfahrung mit dem Azure-Stack zu sammeln. Dabei demonstrierte der Einsatz verschiedener KI-Modelle und Prompting-Strategien, wie unstrukturierte Daten effizient in Formate wie KI-Reviews übersetzt werden können. Letztlich vereinte das Projekt theoretische Konzepte wie State-Management und automatisierte Daten-Pipelines erfolgreich in einer funktionalen Anwendung.
Quellen:
[1]Bui, N., Nguyen, H.T., Kumar, S., Theodore, J., Qiu, W., Nguyen, V.A., & Ying, R. (2025). Mixture-of-Personas Language Models for Population Simulation. In Findings of the Association for Computational Linguistics: ACL 2025 (pp. 24761-24778). https://arxiv.org/abs/2504.05019
Leave a Reply
You must be logged in to post a comment.