Cloud computing has so much potential that the possibilities seem to be endless. Without knowing much about it the cloud looks like a magic place for many people.

To give you a more detailed explanation we sum up the design process of our cloud application step by step in the following blog post. Without giving too much away, it can be said that we still put our trousers on one leg at a time ;-).
Infrastructure Design – Step by Step
The following blog post gives you an impression how we designed and launched a web application using the cloud provider Bluemix. We tried to focus on a web application independent from a specific software implementation. Of course you can’t keep this level of abstraction during the implementation process but for now a more abstract point of view is sufficient while designing the application.
First of all we created our local development environment. In web development it’s state of the art to use a MVC architecture to build an application. For now it’s enough to consider that there will be a model realized by a database service like MySQL and a business logic realized by using a script language like PHP. The business logic also creates views delivered to the user.
On our local development environment we have very limited resources so it’s quite common to run everything on one webserver like nginx or Apache.
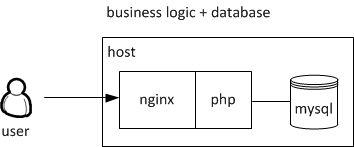
For some reasons it can make sense to „physically“ separate the business logic (controller) from the database (model). So the infrastructure will look more like this:
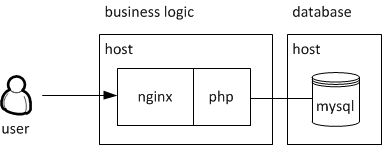
On the left a server is running the business logic connecting to a host on the right providing some database functionalities. E.g. for loading any kind of user data like credentials for login, user posts and so on. At this point you may say no big deal and you’re absolutely right. But this simple separation lays the foundation for later horizontal scaling. To point this out we give you a brief overview about scaling.
In general there are two ways to scale an application:
- horizontally
- vertically
Horizontal scaling increases the amount of nodes like adding some additional servers executing the business logic. Users will be spread to this webservers by a load balancer randomly. As long as the same business logic is distributed to all servers it doesn’t matter which one processes the user request because any of them is doing exactly the same implying all kind of data is stored in the database.
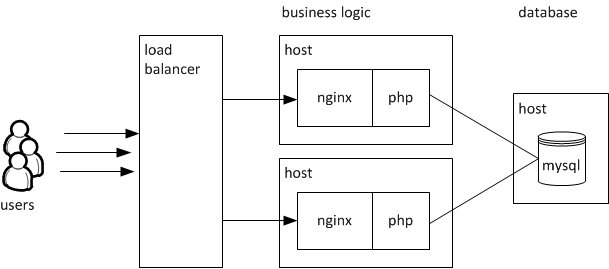
Horizontal scaling is nearly unlimited as long as you have the hardware capabilities to spawn more servers. This is also the point where cloud computing becomes really interesting.
In contrast vertical scaling is adding more power to a single resource like increasing cpu power, ram or hard disk space. In virtual environments that can be achieved quite easy with a couple of mouse clicks but is always limited to a physical (hardware) maximum.
Of course it can make sense to use both, horizontal and vertical scaling to combine the given advantages.
We can easily scale the business logic dependent from the required performance now, however there is still a bottleneck. As soon as the database is queried from the web servers all calls end up on the database server.
Now you may start thinking about the scalability of the database server. Vertical scaling is certainly an option until you reach the hardware maximum. But horizontal scaling is not much fun as soon as the business logic starts to manipulate data. Then you need to make sure the databases will be synchronized and able to handle merge conflicts. Not much fun at all. So how to deal with it? Unfortunately there is no standardized solution to solve this. From this point we need to take a closer look at the application to implement.
As an idea for your thought you could try to split data from different functionalities into separate databases. E.g.: separate databases for user data, messaging, configurations and so on. Beyond this you could also implement caches like redis or memcached to minimize load on the databases.
If you really want to go big you could also start implementing an additional API layer that is responsible for all database operations and build a database cluster behind. In this case you should be aware of the CAP theorem.
In our case we implemented a social network application (HumHub) for different user groups. We decided to use a separate database for each user group and scale the database servers vertically depending on the amount of users and database calls.
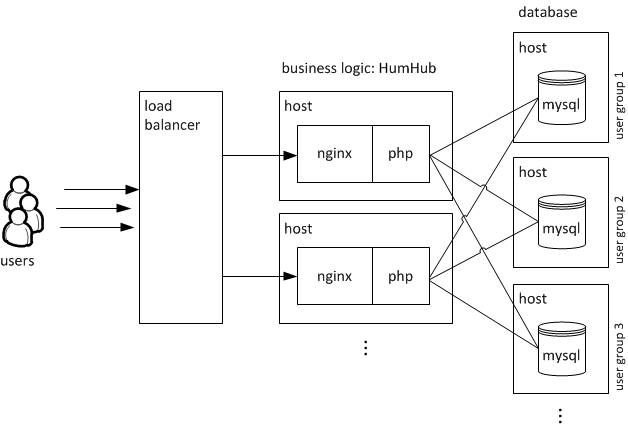
The next blog post introduces a Configuration Tool we created to manage the registration of new user groups. It gives you an impression how we deploy database services in Bluemix and what tools we use.
Written by Natali Bopp, Andreas Gold, Jonas Häfele, Merle Hiort, Martin Kopp, Christian Lang, Anna Poth und Eric Weislogel.
Leave a Reply
You must be logged in to post a comment.