With the ever-increasing complexity of artificial systems that aid humans in their daily and work lives, their operation procedures have grown more complicated and the potential for mishandling is higher than ever before. In the IT world, modern systems that must serve hundreds of millions of customers simultaneously and reliably have grown so complex that no single person can grasp every detail of the software they co-created.
As IT security systems and procedures are also becoming more reliable and make attacking software harder than targeting their operators, humans are now an apparent weak link in the computing world. Consequentially, security breaches and system failures are nowadays regularly publicly blamed on human error in cases such as the recent British Airways IT chaos [1]. Moreover, a report by BakerHostetler found, that 32% of all security incidents are caused by Employee Action or Mistake and just over 10% of incidents involve phishing, making human error one of the main causes for security incidents [2].
When human error is such a prevalent issue in IT systems, we as future (or current) software designers, be it in the role of an architect, programmer, UX designer or something entirely different, must think about how we can solve this issue. This bares the question, what the actual issue entails. Is it humans’ fault? Or are our systems insufficient? Are they too reliant on humans? Should we strive to build entirely autonomous systems? Are our designs just not fitting humans?
To answer these questions let me start with explaining what we understand by human error and what its root causes are.
Human Error explained
Human error, or in this case the synonymous term erroneous action is commonly defined as “an action which fails to produce the expected result and which therefore leads to an unwanted consequence” [3]. This definition captures the essence of human error while hinting at the subjectivity of human error that is sometimes more explicitly stated, depending on who defines it. Another component of erroneous actions often emphasized is the fact, that the term is mostly applied after incidents. This makes human error more of a label than a factual concept which can be predicted.
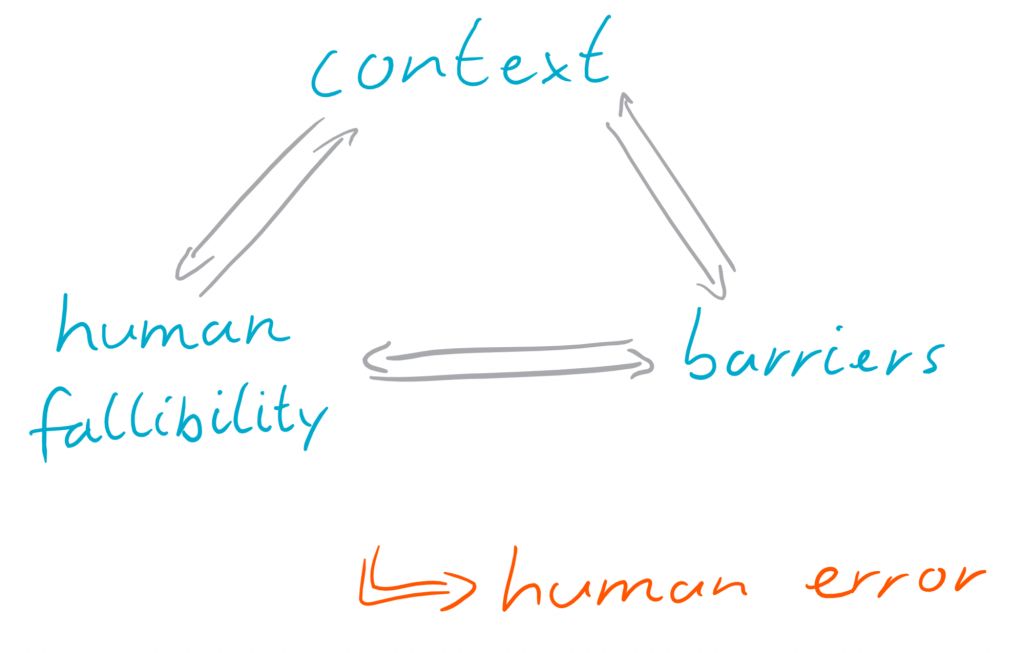
The roots of human error lie in the interaction of the context an action is performed in, human fallibility and the barriers installed against it. Context is the sum of all situational variables that affect how human performance variability brings adverse consequences. The interplay of context and the sensory, cognitive and motor limitations and the behavioural tendencies which form human fallibility is the main cause for human error. The barriers, designed to contain human error then indirectly affect it by changing the context and the perception of that [4].
Of these components, we can affect the context of human action through system design as well as install barriers that prohibit erroneous actions. To do this effectively, an understanding of human fallibility is needed. I won’t go into too much detail about the human mind here, but I will showcase some typical information processing and decision-making errors to illustrate human fallibility.
Human fallibility
Our Memory can be divided in two parts: Working memory is used when actively processing information to store details, like RAM in a computer. Long-term memory behaves similar to a hard-drive, in that its storage is slower but also closer to permanent. It works associatively allowing us to retrieve the correct memory for a set of cues in most cases. One problem with long-term memory is, that information that was frequently or recently used is loaded faster from it than rarely used information. This phenomenon is called the availability heuristic.
When assessing system input, weighing options or estimating po ssible outcomes of our actions we use a third resource besides the two kinds of memory introduced before: Attention. Attention is the brain’s processing resource that can be thought of as a kind of finite and flexible energy source. We can use more or less of it and even split it among tasks at will. The limited nature of attention together with the effort required to expend it causes humans to remain fixed on their first formed hypothesis and to underutilize subsequent information. This behavioural tendency is called cognitive fixation.
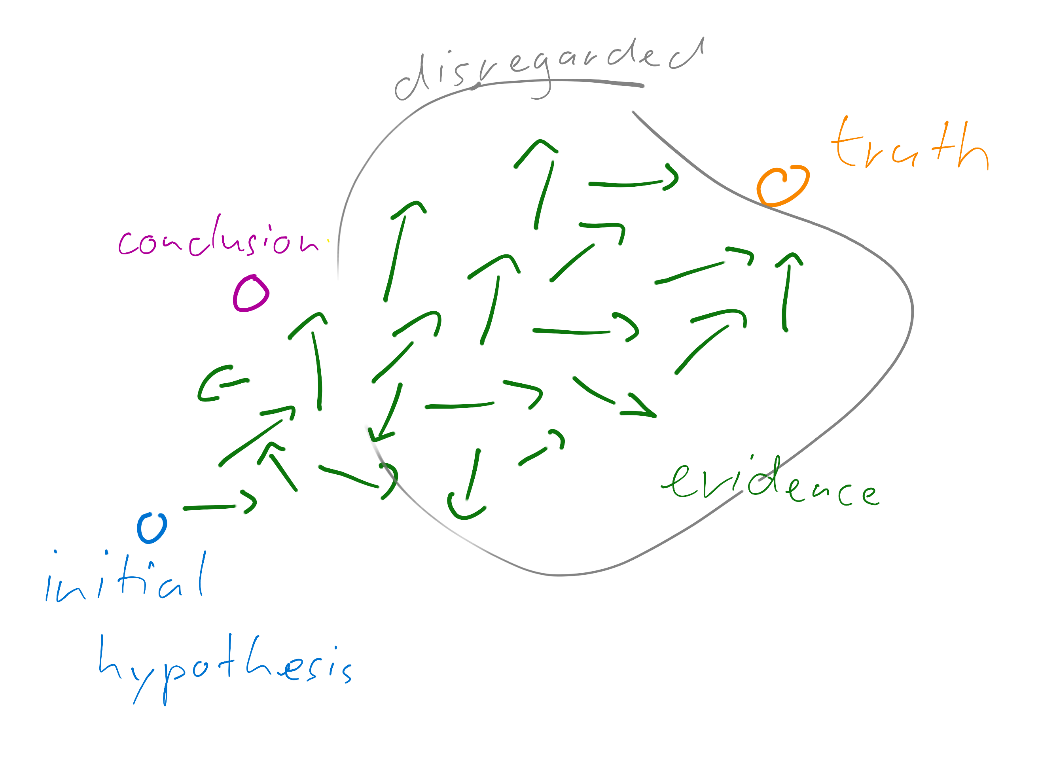
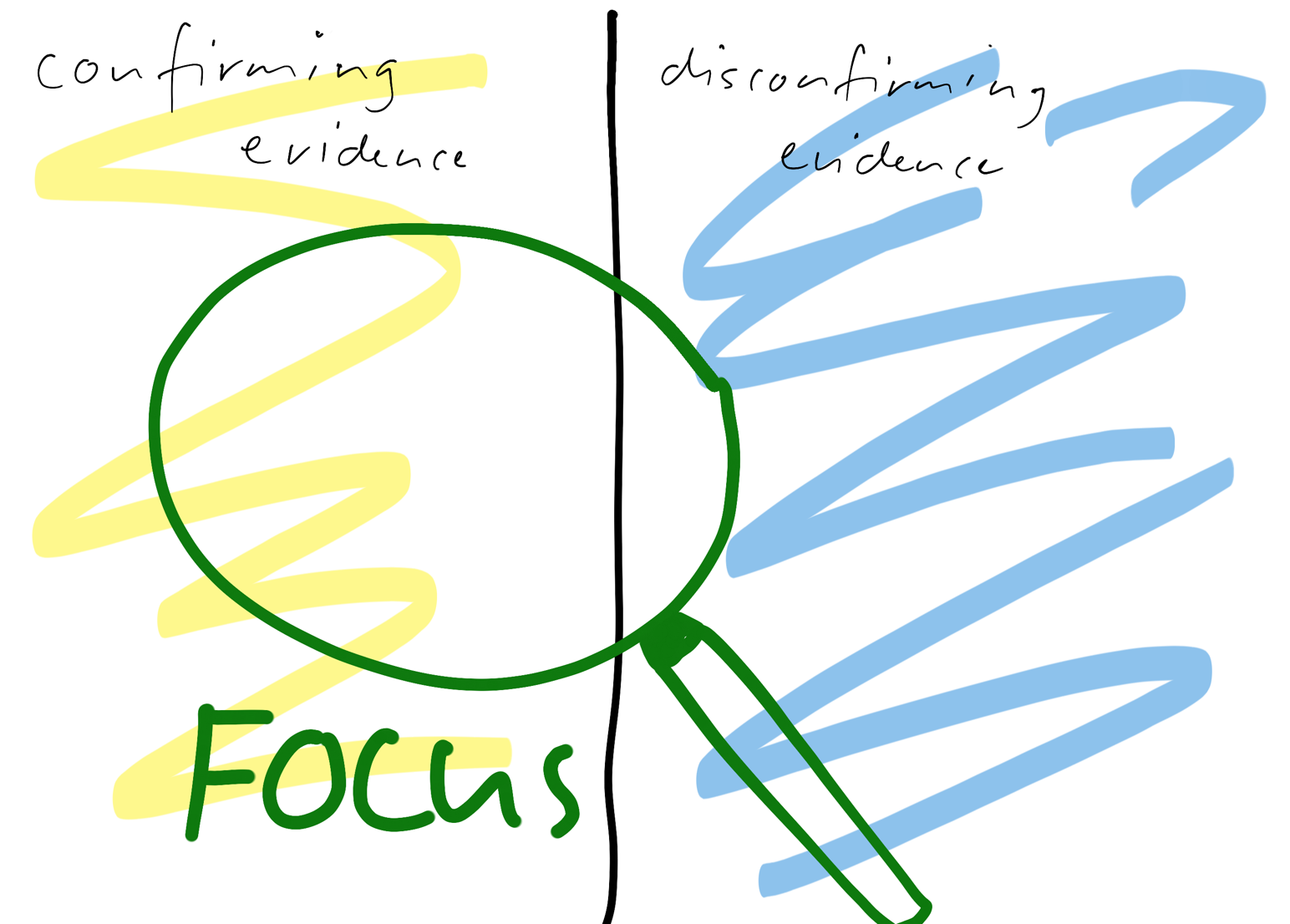
Other common errors lie in the estimation process, either of the importance of cues or in the consideration of information and evidence. One of those is weighing cues, which occur earlier, stronger than ones appearing later. Another one is the confirmation bias, the tendency to consider confirming evidence for a hypothesis and ignore disconfirming evidence. Finally, humans also tend to overestimate correlation by overemphasizing instances of co-occurrence of events and disregarding cases of single events occurring.
Dealing with human error
Now that we know what human error is and looked at some underlying causes I want to talk about how to address the issue of human error in IT systems. For that we will look at two recent cases of IT system failures that were publicly attributed to human error.
Amazon S3 service disruption (February 28th, 2017)
When the Amazon Simple Storage System (S3) team was debugging an S3 billing subsystem issue in February a command for removing servers from the cluster was entered with a wrong parameter. This caused a shutdown of more servers than intended, some of which handling metadata and location information of S3 objects, resulting in major parts of S3 being unavailable for two hours in one of Amazon’s largest regions.
In their post-mortem [5] Amazon addresses multiple causes for the disruption besides the wrong command parameter, such as the critical indexing subsystems taking longer to restart than expected and the restart not having been tested for many years. Even though the headlines in some popular media outlets highlighted the blame on human error, Amazon seemingly doesn’t blame its engineers. Instead they addressed these issues with organisational changes such as reprioritizing speed-up developments on the affected subsystems and through technical changes to the used tool. It now removes resources over time instead of instantly and prohibits execution of commands that would bring a system under its minimum capacity threshold.
To lower the risk of human error in these kinds of maintenance operations Amazon took the approach to increase the amount of automation in that process. Finding the appropriate level of automation is the main challenge in designing automated systems that involve human operators. Amazon here opted for a change that takes control from the engineers, which use the operations console, without losing the superior analytical capabilities the human operators provide in debugging systems. Their choice has two implications, tough: Firstly, it seems like Amazon would be willing to take all control from the engineers if their machines would be able to debug themselves, losing the human potential in their current system. And secondly, that change also prevents a test restart through that console which the post-mortem implies should have been done at one point in the near past.
Another possible choice they could have made is redesigning the system, so that critical operations must be approved by a second engineer unrelated in the current maintenance process. This would also ensure that nonsensical or dangerous command execution is at least hindered, but takes more expensive human resources than the solution they implemented. I still think they made a good decision, but when making similar design changes to software, we should always keep in mind that taking control from humans can be a waste of resources that might be more suitable for the given task and ultimately might lead to system operators losing the very skills they were intended to bring to the table.
Fatal Tesla Crash in Florida (May 7th, 2016)
What can happen when the interaction of (semi)autonomous systems and their human operators fail is best illustrated by the fatal Tesla crash on May of last year, that lead to an investigation [6] by the National Highway Traffic Safety Administration (NHTSA).
On May 7th, 2016, a Tesla Model S crashed into a tractor trailer on a highway intersection in Florida, leading to the death of its driver. Neither the driver nor Tesla’s Autopilot, which was active during the crash, took any braking action prior impact. While initial media reports stated, that the reflective side of the trailer might have been the root cause of Autopilot failing to act, the NHTSA report found, that braking for crossing path collisions is outside the expected performance of Autopilot.
The NHTSA report also lays out, that no current system for autonomous driving can prevent such a crash, and that Tesla’s official documentation such as the Model S manual explicitly states, that Autopilot is not a fully autonomous driving system. The manual additionally demands that drivers always pay full attention to the vehicle they are operating and warns, that “failure to follow these instructions could cause serious property damage, injury or death”. As consequence to the crash Tesla added a “strike-out” to Autopilot, which precludes the activation of it for drivers repeatedly ignoring the systems’ cues to pay attention until the vehicle has been restarted.
The Tesla crash is a prime example for human over reliance on automation. The driver did not pay attention for at least 7 seconds because he thought he doesn’t have to. There exist many videos on YouTube of other Tesla drivers that act similarly, using their smartphone or watching movies while their car is driving seemingly autonomously. Even Tesla CEO Elon Musk himself uploaded a video, where he can be seen removing his hands from the steering wheel while his Tesla car is driving.
Despite Tesla technically being right here per the NHTSA report, their aggressive marketing, starting with the name “Autopilot” for a system that still requires continual attention of the driver, most likely played a role in drivers irresponsibly leaving the operation of their vehicle to itself. On the other hand, many safeguards and warnings were installed and are continuously improved to prevent drivers from diverting their attention away from driving.
In this case the best path for improving Autopilot might be the one Musk already envisions, which is one of a fully autonomously driving car system. Other proposals include forcing drivers to retake control in potentially dangerous situations and allowing the car to operate itself otherwise. In that mode, the system would need to leave enough time for the human to get familiar with the situation first, tough, as context switching is an expensive operation in the human brain. This mostly defies the purpose of such a system, as emergencies could then require human intervention faster than a context switch would be possible, leaving the accident unhandled.
Conclusion
The interplay of IT systems and their human operators is very complex. Human performance variability and the context affect how human error arises, which has to be hindered by barriers or prevented through creating a more fitting context from the get-go. In practice, this requires both knowledge about human fallibility in general, and about the systems users in particular.
Modern approaches such as user-centred design might help in generating this knowledge, but finding the right degree of automation in a system is hard to find nevertheless. The Amazon case shows, that the lack of basic barriers can have adverse consequences. Installing them might also limit the possibilities of operators, tough, such as the lacking option of a full system restart in that case. The Tesla crash illustrates, how over reliance on automation caused a driver to ignore the installed barriers in form of warnings. The opposite concept, mistrust of automation, should also not be underestimated, as it might lead to the disuse of systems that increase safety and security for its users.
A fully autonomously driving car will most likely be safer than one driven by a human soon, but car companies will have to ensure, that the intermediate systems allow and force human intervention in critical situations in a way that doesn’t overstrain human capabilities until then. In the present time, where computers are still worse than humans in many fields such as natural language processing and image recognition, we should do our best to produce software that utilizes human potential to its maximum.
References
[1] BBC, “British Airways says IT chaos was caused by human error.” [Online]. Available: http://www.bbc.com/news/business-40159202. [Accessed: 01-Jul-2017].
[2] BakerHostetler, “Be Compromise Ready: Go Back to the Basics 2017 Data Security Incident Response Report,” 2017.
[3] E. Hollnagel, Human reliability analysis: Context and control. Academic Press London, 1993.
[4] J. Sharit, “Human Error and Human Reliability Analysis,” in Handbook of Human Factors and Ergonomics, John Wiley & Sons, Inc., 2012, pp. 734–800.
[5] Amazon, “Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region,” 2017. [Online]. Available: https://aws.amazon.com/de/message/41926/. [Accessed: 20-Jun-2017].
[6] NHTSA, “Failure Report Summary (Tesla Crash),” 2017.
Leave a Reply
You must be logged in to post a comment.