Month: March 2018
Continuous Integration & Deployment for a Cross-Platform Application – Part 2
In the first part we pointed out how we set up the infrastructure for our CI system. Now we would like to explain how we build a pipeline for our cross-platform application and what features of GitLab CI we made use of.
Supply Chain Management using Blockchain Technology – Hands-On Hyperledger (Part 2)
Implementation Model The model we’ve chosen is an attempt to implement one part of a large SCM business model. Since an example of shipping processes for single items does already exist on IBM’s platform ‘DeveloperWorks’, we focused on the ability to create and place composite orders.
Supply Chain Management using Blockchain Technology – Hands-On Hyperledger (Part 1)
Motivation Many of today’s supply chain management (SCM) solutions still involve enormous amounts of manual work. The procedures required for proper record keeping often rely on manual input, which makes them slow and prone to errors. Additional terms, such as price agreements, conditions that must be strictly adhered to, as well as penalties for neglection…
CI/CD with GitLab CI for a web application – Part 3
Hosting your own GitLab server Some users might have concerns regarding security using GitLab for a variety of purposes, including commercial and business applications. That is, because GitLab is commonly used as a cloud-based service – on someone else’s computer, so to speak. So setting it up for running it on your own server is…
CI/CD with GitLab CI for a web application – Part 2
GitLab Our first approach was to use the existing GitLab instance of HdM for our project. For them, a shared runner was already defined on which we could run our jobs, so we were able to focus on the CI process itself. This plan worked out at first. We simply defined build and test jobs,…
CI/CD with GitLab CI for a web application – Part 1
Introduction When it comes to software development, chances are high that you’re not doing this on your own. The main reason for this is often that implementing components like UI, frontend, backend, servers and more is just too much to handle for a single person leading to a slow development process. So, you have to…
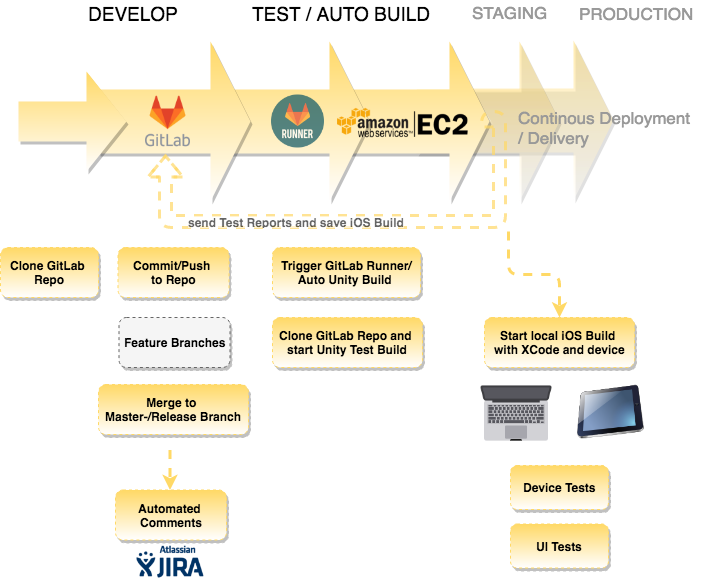
Continuous Integration Pipeline for Unity Development using GitLab CI and AWS
This blog entry describes the implementation of a Continous Integration (CI) pipeline especially adapted for Unity projects. It makes it possible to automatically execute Unity builds on a configured build server and provide it for a further deployment process if required.
Continuous Integration – Move fast and don’t break things
Continuous Integration is an increasingly popular topic in modern software development. Across many industries the companies acknowledging the importance of IT and delivering value to their customers through great software prevail against their competitors. Many reports indicate that Continuous Integration is one of the major contributing factors to developing high quality software with remarkable efficiency.…
- DevOps, Interactive Media, Mobile Apps, Scalable Systems, Student Projects, System Designs, System Engineering
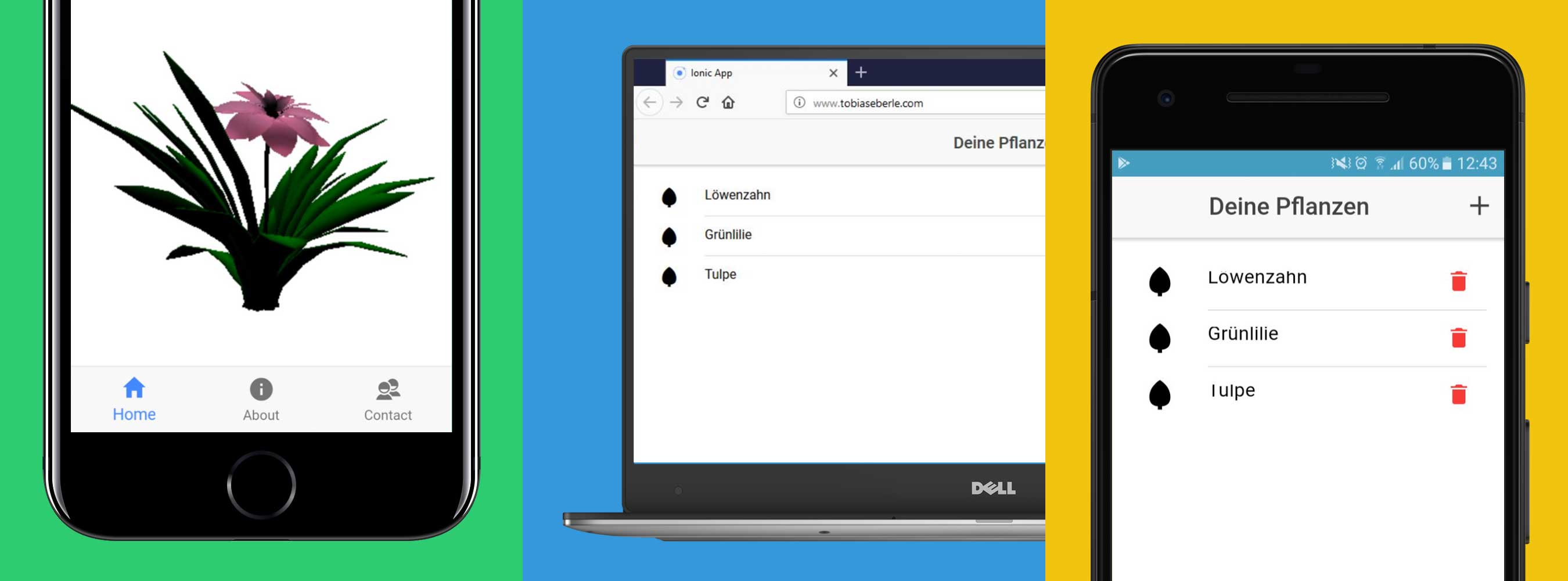
Continuous Integration & Deployment for a Cross-Platform Application – Part 1
When we started the project “Flora CI” for the lecture “System Engineering”, we planned to deal with Continuous Integration. As an important aspect of software engineering all of us have previously been involved in projects where code of developers had to be merged and builds had to be automated somehow. Anyway we felt we could…
Take Me Home – Project Overview
Related articles: ►CI/CD infrastructure: Choosing and setting up a server with Jenkins as Docker image ►Dockerizing Android SDK and Emulator for testing ►Automated Unit- and GUI-Testing for Android in Jenkins ►Testing a MongoDB with NodeJS, Mocha and Mongoose During the winter term 2017/2018, we created an app called Take Me Home. The purpose of the app is…
You must be logged in to post a comment.