Continuous Integration is an increasingly popular topic in modern software development. Across many industries the companies acknowledging the importance of IT and delivering value to their customers through great software prevail against their competitors. Many reports indicate that Continuous Integration is one of the major contributing factors to developing high quality software with remarkable efficiency. There are many excellent articles, talks and books explaining the principles of CI in theory. During the lecture System Engineering and Management, we had the opportunity to apply our abstract knowledge and gain our own experience by creating and operating a CI pipeline in an accompanying project. The following article covers the approach, major challenges and most important the lessons learned of our Continuous Integration endeavor. By pointing out relevant issues we want to raise awareness on our misconceptions and mistakes we committed so you can avoid them in the first place.
Let me first outline the underlying project called debts² to give you some context information before we focus on CI. The main goal was to build an application which facilitates managing expenses within a group of people. The Android App allows you to track your bills and synchronize them with all group members. Based on the receipts we calculate the debts among everyone and suggest who should pay next. Additional features like the automatic recognition of relevant information on scanned bills or choosing the location from Google Maps simplify keeping track of receipts.
The Android App communicates via HTTP with our backend based on Node.js and express. In matters of persistent storage, we deploy MongoDB and Minio. In addition to the app we provide a web administration interface based on Vue.js served by nginx web server. Webpack is used to bundle the JavaScript application with all its assets. Except the Android App all services run in Docker container orchestrated by docker-compose.
Continuous Integration
During the development process of many software projects it is common that the application is in an unusable and non-working state because no single team member is interested in running the entire application until the work of everybody else is finished. Hence the integration of changes as well as integration testing are delayed and there is no proof that the application will work in production. This results in time-consuming and unpredictable integration conflicts which pose an imminent threat to the success of the project.
Continuous Integration proposes a divide and conquer approach to mitigate the risks of deferred integration. Every developer is obliged to continuously integrate the changes and resolve conflicts as soon as they occur. Continuous Integration assures the quality of the project by building artifacts and running an automated test suite whenever changes are committed. Consequently, quality can be incorporated from the very beginning reducing costs of bug fixes and generally of change requests. This repetitive feedback fosters learning and allows to evolve software based on experience. Finally, Continuous Integration is a major milestone on the journey to reliably releasing code into production on demand, termed Continuous Delivery. The ability of frequent, low-risk releases is nowadays crucial for businesses to stay competitive and deeply incorporated in the Agile Manifesto.
“Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.” – Agile Manifesto
This entails that the project must meet the criteria of production quality from the very beginning and hence can be released on demand. Secondly, it is imperative to provide fast feedback during the development process to enable learning and eventually continuous improvement.
Building blocks of CI
In my opinion, Continuous Integration is composed of four essential building blocks required to enable constant production quality and fast feedback:
- Quality assurance
- Repeatability
- Discipline
- Acceptance
The ongoing assurance of quality by integrating and testing changes is obvious. Furthermore, a repeatable process to build and test the software is mandatory for QA to work effectively. Both aspects are covered in more detail in the following section. Unfortunately, it is quite easy to omit the less apparent factors discipline and acceptance because they are non-technical and concern the work ethic. You must not sacrifice the principles of CI because time pressure increases. In the end it is crucial that every team member accepts and sticks to the rules agreed upon because otherwise people will find ways to circumvent the procedures. Omitting or neglecting any of these four building blocks will render all efforts to increase the efficiency of your development process with CI ineffective.
Approach and challenges
Upon identifying the motives and essential building blocks of Continuous Integration, we can now focus on strategies and challenges concerning the quality assurance as well as repeatability of build and test results.
Quality assurance
When designing the quality assurance strategy, you can’t ignore the test pyramid. It is a well-known metaphor telling us to group software tests in buckets with respect to their granularity. It proposes to rely considerably more on highly isolated unit tests in favor of resource intensive end-to-end tests as depicted in the figure below.
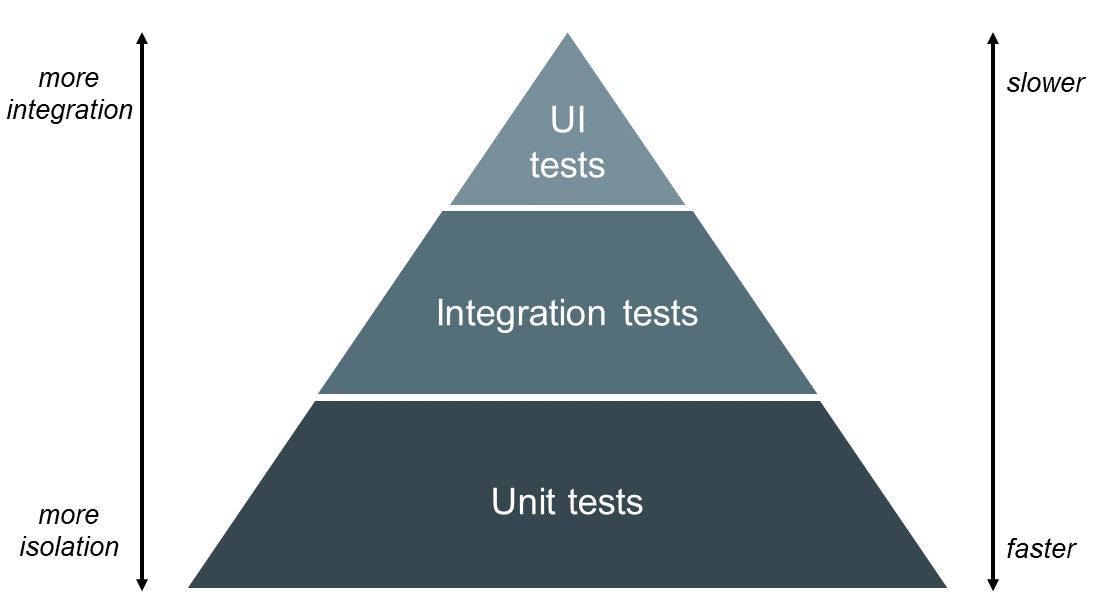
To provide fast feedback, we can benefit from lightweight unit tests since they are easy to write and can be executed within seconds. Leveraging the high degree of isolation facilitates locating erroneous lines of code. Despite the advantages of unit tests, proper quality assurance requires to test the interaction of components as well. Otherwise we could not detect timing problems, resource conflicts or mismatching interfaces between components. Furthermore, we need to ensure the quality of the application from the user’s perspective. But solely employing integration and end-to-end tests would decrease the immediacy of feedback and hence contradict the main principle of CI.
For the remainder of this section we concentrate on the strategies employed to assure the quality of our backend application. In our project debts² we intentionally relied mainly on API tests combined with a couple of unit test. Initially, we did not adhere to the single responsibility pattern hence it was unfeasible to write adequate unit test. Because of the time pressure we faced from the beginning of the project we thought that relying mostly on API tests would be a practical solution.
In terms of tooling we used for both test groups mocha as test runner, chai as assertion library, chai-as-promised as utility to deal with promises as return value and finally mochawesome to generate useful result reports. We decided to execute the unit tests during the build of the docker image to provide fast feedback and to abort the build if unit tests fail. To run the unit tests repeatedly without any change of the source code in-between, you need to artificially invalidate Docker’s layer-based cache. We use a build argument provided with the current time to bust the cache of the layer which executes the unit tests during the build. In contrast, the API tests ran in a separated container orchestrated by docker-compose to validate the entire backend application from an external perspective.
During the last three months we faced several challenges in our efforts to proper quality assurance with mostly API tests. To begin with, we can mention the poor testability of many parts of our backend application due to the following reasons:
- many error conditions are unfeasible to establish from the outside
- some external services don’t provide developer accounts
- responses depending on dynamic data like clocks or randomness
We learned that answering the following questions from the beginning can improve your QA:
- What’s our strategy to define test cases?
- What’s our desired coverage rate?
- In which manner do we group the tests in files?
- How do we organize our input and desired output for every test case?
- Do we replicate the data or derive the concrete instance for a testcase from a preset at runtime?
- Do we manipulate our persistent storage, or can we establish the required pre-conditions, e.g. with synchronous interfaces?
Failing to reckon the importance of a suitable strategy to organization test cases and data can entail fatal consequences. This brings us to the next question: How important is the quality of the tests itself? When we started to write tests we simply copied entire blocks of code sacrificing the Don’t-Repeat-Yourself principle for a higher velocity. As you can imagine, this strategy backfired after two months so that we were reluctant to modify our code. The changes in the code itself resulted in many adaptions of tests and utility functions, which was time-consuming and prone to errors. To adhere to the DRY principle, we refactored our tests by defining an object for every expected response using JavaScript prototypes. Every prototype has a function which executes the comparison statements of the actual and expected results. In a test case we call the function of the expected result object and provide the actual result.
The new structure rendered our tests more readable, easier to adapt and we were able to delete more than a thousand lines of redundant code. Additionally, having all possible responses gathered in one file facilitated writing the API documentation. In the end we learned that the tests need to comply to at least the same quality standards as the production code. This includes test data and utility methods as well.
Repeatability
Effective Continuous Integration requires in addition to adequate quality assurance repeatable build and test procedures. With the main goal of fast feedback in mind “repeatable procedures” encompass reproducible and reliable build artifacts as well as test results at a low processing time. In my opinion, the following four aspects are mandatory to achieve repeatability:
- Version control
- Production-like environment
- Independent build process
- Automation
Pervasive version control guarantees that every artifact required to build or run the application is available to everyone and that all changes are tracked. This includes besides the source code itself any configuration, script, test or utility file for both the application and infrastructure. To increase the immediacy of the feedback it is advisable to use production-like environments at any pre-production stage including the local machine of developers. With respect to repeatability, it is necessary that every environment is created automatically and reliably from versioned artifacts within minutes. Hence, we can destroy and recreate them on demand. Based on reproducible environments we need a platform independent build process. This means that every artifact can repeatedly be built with the same result regardless of the environment, e.g. local, staging, CI or production. Finally, profound automation is required to accelerate all procedures and remove error-prone, time-consuming manual steps.
Let’s see how we put these principles into practice: Git and GitLab are the tools of our choice for proper version control and management of merge requests. We use VirtualBox, Vagrant and a shell provisioning script to reproduce virtual machines for development and testing akin to the production environment. Vagrant leverages a declarative configuration file to describe the desired state of a VM. Docker is our vehicle to reliably build and run artifacts in form of containers regardless of the environment. Docker uses a declarative syntax as well and offers a great ecosystem.
As a central CI server, we installed Jenkins on a hosted VM with root access and created a new pipeline project. To execute the pipeline whenever changes are pushed to the master branch, we integrated the repository with Jenkins using GitLab’s webhooks. The picture below visualizes our pipeline in Jenkins.
Upon a build is triggered the current Jenkinsfile is loaded. This file is a declarative definition of our pipeline and stored in version control. Afterwards Jenkins installs the required tools like gradle to build the Android App. The checkout of the current commit on master is followed by the build stage in which we build our docker images and the Android App. During the build the source code is analyzed by linters and the unit tests are executed. As a post action the result reports are published using the declarative html publisher plugin.
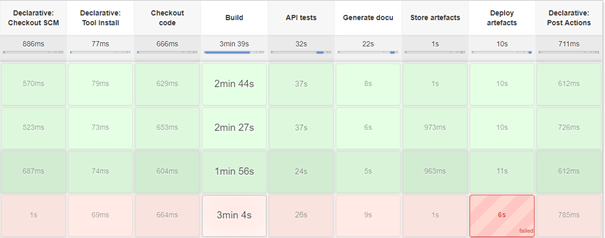
A successful build without failing unit tests is followed by integration tests, in our case the API tests. Therefore, we build the Docker image, execute tests within the separate container and conclude by publishing the result reports. In the next stage the documentation of our source code is generated automatically and subsequently published as well. JavaDoc is employed for the Android App and apiDoc to describe the API of our backend. The pipeline proceeds by storing the docker images in a registry and by archiving the generated Android apk file in Jenkins. After passing all quality assurance procedures we deploy our artifacts, except the Android App, into production. The pipeline concludes by sending a message with brief information on the current build to our Slack channel using the Slack notification plugin.
It was our first time to use Docker and its ecosystem apart from some playground projects thus we encountered a couple of challenges. At the beginning we struggled with size of our Docker images, especially for the web application. We use webpack, which is based on Node.js, to bundle the application but the final Docker image solely employs a nginx webserver to server the static files generated by webpack at build time. Installing Node.js, webpack with its numerous dependencies and nginx left us with huge images. To combat the image size, we applied the builder pattern. This pattern decreases the size of the final container by separating the build process from the production image using two Dockerfiles. The Dockerfile.build serves as build environment where we use a Node.js base image, install webpack with its dependencies and generate the static files at build time. Afterwards we create the container, extract the files and destroy it again. In the production Dockerfile we use a nginx base image and add the extracted static files during build time.
The builder pattern is an effective workaround to reduce the size of our images but requires two Dockerfiles, a shell script and the host as temporary storage. Fortunately, Docker addresses this problem with a feature called multi-stage build released in version 17.05. It allows to define multiple intermediary container in a single Dockerfile. Because you can easily copy sources between the container, it is a suitable replacement for the builder pattern. With the help of multi-stage builds, best practices recommended by Docker and by exploiting the layer-based cache we diminished the size of our images remarkably.
Despite the advantages Docker has its caveats. For example, it is not trivial to setup proper hot reloading to avoid cumbersome manual builds every time you change your code. Additionally, you need to get acquainted to the limited access you have to a container. Finally, we learned that our docker-compose cluster with four container is a minimal version of a distributed systems, which requires additional orchestration. Initially, we could not rely on the results from the API tests because occasionally tests failed due to a seemingly volatile database connection. Debugging revealed that although we defined a dependency from the backend to the MongoDB container, docker-compose does not guarantee that the actual process inside the container is started completely. To address this problem, we employed health checks for every service enabling docker-compose to reliably coordinate the startup of the cluster and beyond.
Lessons learned
Throughout our Continuous Integration endeavor we gained a lot of experience. Let’s recap the most important lessons learned and conclude with a roadmap summarizing the next steps.
Several occasions revealed that the reliability of build and test results is a key factor for effective Continuous Integration. Unreliable processes cause frustration and impede debugging. As mentioned earlier, mostly relying on API tests to ensure the quality of our backend application backfired. Many test cases could have been replaced with unit tests cutting the execution time at least by half. Additionally, a couple of bugs remained undetected until we conducted acceptance tests with real users towards to the end of the project. These defects can be attributed to missing unit as well as integration tests and entailed unplanned work. Some bugs, which were difficult to locate because of erroneous MongoDB statements, could have been discovered earlier with integration tests between backend and database. We learned that adhering to the test pyramid is advisable for proper quality assurance and fast feedback. Employing API tests to simulate realistic user scenarios composed of many subsequent steps was worth the effort. Otherwise it would have been unfeasible to manually conduct these time-consuming tests repeatedly. Despite every effort to ensure the quality of our artifacts, we can confirm the well-known saying: “tests don’t prove the absence of bugs”. Therefore, don’t create the illusion that your software is free of errors and focus instead on methods like Continuous Integration to decrease the time to repair. Martin Fowler summarizes the gist very well:
“Continuous Integration doesn’t get rid of bugs, but it does make them dramatically easier to find and remove.” – Martin Fowler
We assume that adopting a test first approach during the backend development improved the design of our code because we thought about the different input types and possible responses in advance. Despite the additional time required to define and write test cases, the benefit of a reasonable test suite was tremendous. It encouraged us to refactor our codebase several times because the chances of regressions were diminished.
Regardless of the software artifact we developed, the build time highly correlated with our velocity. Hence almost all efforts to reduce the build time paid off. Every second counts. In case of Docker, every instruction you omit or at least can be cached by Docker during build time enhances your efficiency. Reviewing the last three months, we underestimated the effort necessary to assemble and continuously operate the CI pipeline with its surrounding processes and tools. Additionally, the overall complexity of the entire project increased. Consequently, we had to establish a common understanding of the new instruments in our team and every single team member was obliged to engage oneself in this matter. In the end, we learned that it is mandatory to continuously improve the processes by adapting them to your needs and circumstances. Theory teaches us the basic concepts and principles of Continuous Integration but applying them to a concrete situation requires many iterations including feedback from every concerned party. Failing to continuously improve processes and tools will result in diminished acceptance by coworkers and thus a significantly strained velocity.
In retrospective, we are convinced that adopting a basic Continuous Integration approach advanced our collaboration mainly because of the shared project state within our group. Every team member had access to the latest artifacts allowing them to test their own development state against a specific version. Moreover, by continuously distributing information about our project’s health we increased transparency pursuing the idea of fast feedback. We are certain that our efforts affected the quality of our software positively and by incorporating feedback into our processes and software artifacts we enhanced our overall efficiency. To put it another way, despite the additional costs we benefited highly from Continuous Integration and encourage everyone to gain their own experience this matter.
As mentioned before, continuously improving tools and processes is compulsive to ensure competitiveness. Having said that, let me briefly outline our roadmap to further increase our velocity. To begin with, we intend to introduce a multi branch functionality to our CI pipeline to accelerate feedback. At the moment our pipeline is triggered by a push event on the master branch hence we can’t ensure the quality of feature branches until they are merged into master. In the future, the CI pipeline should be initiated by every push event and should decide according to the branch on test suites to execute and whether to release the artifacts into production. Furthermore, we need to enhance the versioning of artifacts. We expect that a consistent semantic versioning of our artifacts increases transparency and fosters collaboration. By enriching them during the build with a version number and information from the VCS we can precisely identify the origin of every artifact. With respect to security we plan to remove confidential information from version control. It is undesirable that credentials used in production reside in the repository granting every team member access to production systems. Moreover, using the same credentials during development might accidentally interfere with the production system. Finally, we want to decrease risk and impairment of deploys to production. The Canary Release constitutes a viable approach to update all nodes of a cluster with zero downtime by releasing the new software incrementally. This approach entails an advanced cluster management combined with automation to control the deploy process.
As you can see, Continuous Integration is composed of a variety of different aspects besides frequently checking changes into version control and running a test suite. It is a philosophy aiming to improve the efficiency of the entire software development process and thereby increasing the overall agility.
Related sources
- Humble and D. Farley. Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation. 1st. Addison-Wesley Professional, 2010
- Kim et al. The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. IT Revolution Press, 2016.
- http://agilemanifesto.org
- https://www.thoughtworks.com/continuous-integration
- https://martinfowler.com/bliki/CanaryRelease.html
- https://www.martinfowler.com/articles/continuousIntegration.html
- https://martinfowler.com/articles/practical-test-pyramid.html
- https://blog.alexellis.io/mutli-stage-docker-builds/
- https://docs.docker.com/develop/develop-images/multistage-build/
- https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
Leave a Reply
You must be logged in to post a comment.