Month: July 2018
- Cloud Technologies, Scalable Systems, Student Projects, System Architecture, Ultra Large Scale Systems
Building a fully scalable architecture with AWS
What I learned in building the StateOfVeganism ? By now, we all know that news and media shape our viewson these discussed topics. Of course, this is different from person to person. Some might be influenced a little more than others, but there always is some opinion communicated. Considering this, it would be really interesting…
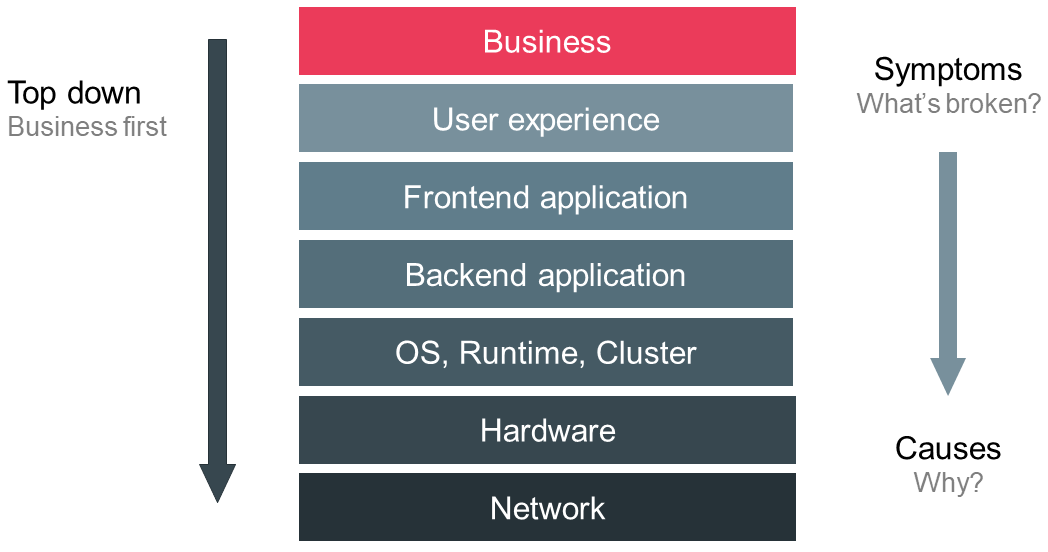
End user monitoring – Establish a basis to understand, operate and improve software systems
End user monitoring is crucial for operating and managing software systems safely and effectively. Beyond operations, monitoring constitutes a basic requirement to improve services based on facts instead of instincts. Thus, monitoring plays an important role in the lifecycle of every application. But implementing an effective monitoring solution is challenging due to the incredible velocity…
RUST – Safety During and After Programming
Summary about Rust and how RustBelt has achieved to prove its safety with mathematical concepts.