The rise of Machine Learning has led to changes across all areas of computer science. From a very abstract point of view, heuristics are replaced by black-box machine-learning algorithms providing “better results”. But how do we actually quantify better results? ML-based solutions tend to focus more on absolute performance improvements (measured by metrics) instead of factors like resilience and reproducibility. On the other hand, ML models have a significantly growing impact on humans. One can argue that the danger is negligible for applications like playing games but with direct impacts like self-driving in production, there comes a responsibility. This responsibility was strengthened not only by laws such as the EU General Data Protection Regulation (GDPR).
Nevertheless, the objective of this post is not to philosophize about the dangers and dark sides of AI. In fact, this post aims to work out common challenges in reproducibility for machine learning and shows programming differences to other areas of Computer Science. Secondly, we will see practices and workflows to create a higher grade of reproducibility in machine learning algorithms.
Background
Having a software engineering background, my first personal experience of programming in machine learning felt like going back in time. Many frameworks are evolved and highly used in practice (TensorFlow, keras, pytorch, …) but other’s are still in the early stages and evolve quickly. This fact shouldn’t be surprising regarding the short history of current ML implementations. However, the definition of frameworks differs from other areas of Computer Science. Tensorflow and others create an abstraction layer for the underlying mathematical operations and indeed simplify processes like training, optimizations and more. But for me, they are closer to a toolkit of operations than a cookbook with best-practices.
Especially scientific results are often implemented with the same toolkit but as a standalone project. For this reason, the grade of reusability of such implementations is often low. Research scientists are interested in the most recent publications but there is no baseline project which can be used for different approaches, models and datasets. It’s more about copying and pasting workflows, downloading datasets and hacking it together. However, the research in ML is now establishing programming paradigms which exist in other parts of computer science for decades. Further, I am thankful to anyone contributing to state-of-the-art implementations in the first place. Thus, we will move the scientific scope into the background from now on.
Taking a more practical approach into account, Jupyter notebooks are often used as a starting point to explore data and different approaches. They are a great tool to evaluate a proof-of-concept and to showcase initial findings. However, notebooks tend to be chaotic with increasing complexity. In certain aspects, we can compare the workflow to creating an MVP in software engineering. You can reuse the created MVP as a setup for the productive application, but you shouldn’t expect a clean and extensible architecture then.
A machine learning workflow
For a better understanding, the following figure shows a typical workflow and the components of development in Data Science:
- Load and preprocess data, bring it into an interpretable form for our ML model.
- Code a model and implement the block-box magic that empowers AI.
- Train, Evaluate and fine-tune the model over days, weeks or months.

After an initial implementation and similar to software lifecycles, we have the following steps:
- Deploy the program (model) to our dedicated infrastructure (Cloud, local).
- Use the model in production.
- Monitor the application and its predictions.
- Maintain the source code, implement new features and deploy new versions.
Frameworks like TensorFlow provide tools to read data, train models and evaluate them with different metrics. Further, approaches like TensorFlow Serving address the second part of the workflow to deploy models on infrastructure for production. Nonetheless, these tools don’t explicitly address reproducibility issues in ML. For a better understanding, the following section goes one step back by pointing out these challenges.
Challenges in ML reproducibility
In contrast to other fields of computer science, the results are non-deterministic. In other words, the same source code produces different results for the same dataset. Reasons mostly lie in implementation details such as random initializations of parameters or randomly shuffled datasets.
However, the baseline for collaboration in software engineering is a project environment where changes can be reproduced. There is not enough time in this blog post to discuss concepts like Versioning and Continous Integration, but in general, they lead to projects that are less error-agnostic due to automatic testing and deploying. Furthermore, contributors are able to comprehend changes and reproduce it on their environment (if guidelines and rules are followed).
Having the non-determinism in mind, the objective for ML is a process in which results can be produced having the exact same results. The following aspects address this issue:
- Versioning of models: Models should be versioned and any changes be transparent.
- “Results without context are meaningless.“ (https://www.pachyderm.io/dsbor.html). For reproducibility, the collection of metadata is essential. Running a model on a dataset and versioning it does not answer questions such as: Where did the data come from? How can we rerun the model with an updated dataset?
- A reproducibility flag should enable a mode in which features causing non-deterministic results such as random initialization are disabled.
Coming back to Jupyter notebooks as a baseline for ML projects, they are a nightmare from a versioning and reproducibility perspective. First, notebook cells can run in different orders which makes the results hard to understand. Secondly, the actual source of notebooks is illegible which basically means that one can’t understand changes between versions regarding the source code. So as software developer, just imagine checking out a version and searching for changes in the application because source differences are meaningless.
So, how in practice?
We have gained an intuition for challenges in ML development and learned that versioning and collecting metadata is crucial for reproducibility. We are now answering the question of how to address these issues with in practice.
Data versioning tools
Data version control (DVC) or datmo are open source production tools for model management. In other words, they are versioning tools similar to git but address additional data scientist needs. One fundamental need is the integration of large files from different data sources. Git is not made to handle large files and the source for machine learning data is often on a different source (Public Cloud, Customer’s infrastructure).
Thus, the Git Large File Storage (LFS) replaces large files such as data input files with text pointers inside Git and stores the data on a remote server. Going one step further, we don’t want the data as part of the tool but the entire workflow. For a better understanding, the following figure illustrates a very basic scenario for DVC.

We publish and check out the code using a remote hub (Gitlab, Github, …) just as usual. On top of this, we use DVC to publish and retrieve data versions using a different hub. This separation of code and data makes it possible to test different program versions on various data versions. This is particularly useful to reproduce a model’s performance over time in production (after collecting new data).
On top of this, the tools address the following features (not exclusively):
- Language- and Framework-agnostic: Implement projects in different languages (Python, R, Julia, ..) using different frameworks (TensorFlow, PyTorch, …)
- Infrastructure-agnostic: Deploy models to different environments and infrastructures (Google Cloud, AWS, local infrastructure)
However, the infrastructure-agnostic feature comes with a drawback. DVC or datmo lack pipeline execution features for build pipelines, monitoring or error handling. The philosophy of these tools is to be very generic without running servers. They are slim command line tools without user interfaces.
Pachyderm
In order to come closer to continuous integration, we need deployment pipelines and modular infrastructure. The goal is an automated processes of releasing new versions, testing it on a staging environments and deploying it to customers. The borders between infrastructure and programming are blurring and the same should apply to machine learning. The two keywords that pop up in every (modern) infrastructure are containers (docker) and Kubernetes. Say hi to Pachyderm.
Pachyderm runs on top of Kubernetes which makes it deployable to any service that supports Kubernetes (Google Cloud Platform, AWS, Azure, Local infrastructure). Further, it integrates git-like features to version code as well as data and it shares many of its names (repository, pipeline, …). With Pachyderm, we configure continuous integration pipelines with container images.
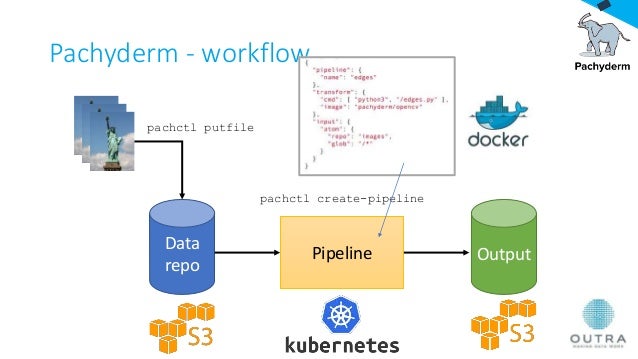
The above figure shows a baseline workflow in Pachyderm. Assuming that we already created a repository and coded our model, we put a file to our dedicated data storage. We then create pipelines whose configurations are written as JSON-files and can look as follows:
{
"pipeline": {
"name": "word-count"
},
"transform": {
"image": "docker-image",
"cmd": ["/bin", "/pfs/data", "/pfs/out"]
},
"input": {
"pfs": {
"repo": "data",
"glob": "/*"
}
}
}By executing the above configuration with the Pachyderm command line interface pachctl create-pipeline -f above_pipeline.json, we run the commands in cmd within the container created from an image defined in image. Further, we use remote storages like S3 or store it on the Pachyderm File System (pfs). PFS is a distributed filesystem which is, until a certain level, comparable to the Hadoop file system (HDFS) where MapReduce-Jobs are replaced by Pachyderm pipelines (see 8).
After creating the pipeline above, Pachyderm will launch worker pods on Kubernetes. These worker pods will remain up and running, such that they are ready to process any data committed to their input repositories.
KubeFlow: Distributed large-scale deployment
As described beforehand, Pachyderm let us create scalable and manageable ML pipelines on Kubernetes. Although Pachyderm can be parallelized in a map/reduce-style way, the pipelines mostly rely on single nodes and non-distributed training (multiple GPUs, but not multiple nodes). Having a different approach in mind, KubeFlow mainly focuses on standards to deploy and manage distributed ML on Kubernetes. It integrates tools like Distributed TensorFlow or TensorFlow Serving and further JupyterHub which improves the process of developing in teams on shared notebooks.
However, KubeFlow (as of now) lacks tools that orchestrate Data Science workflows as seen earlier (Data Preprocessing, Modelling, Training, Deployment, Monitoring, …). It leaves these responsibilities up to the developer. Since this blog post mainly focuses on reproducibility in Machine Learning, KubeFlow does not answer these questions satisfactory. Consequently, further concepts are out-of-scope for this post while not being less exciting for productive and large-scale ML engineering.
Nevertheless, reproducibility and productivity should go hand in hand. For this reason, KubeFlow and Pachyderm can be jointly used in practice. In such a scenario, Pachyderm would provide the reproducibility through pipelines and KubeFlow would bring with the ease of deployment and distributed framework integrations (see 67 for more details).
So what should I use?
After an introduction to tools such as DVC and Pachyderm, one last question remains: Which is the best tool in production? And as always the answer is – it depends. DVC can improve productivity in smaller teams to organize and version projects and link the source code to the data. However, for organizations willing to introduce a workflow, richly-featured tools such as Pachyderm are the way to go. Taking one step further, KubeFlow paves the way for large-scale and distributed applications.
From a different point of view, the discussion behind it could be seen as a discussion about Kubernetes itself. This is fairly more wide-reaching and asks fundamental questions such as: Can we pay someone to set up and maintain the Kubernetes Cluster? Are our applications and workflows complex enough (multiple nodes, not multiple GPUs) to justify the overhead of Kubernetes? Unfortunately, we can’t answer these questions in this blog post.
Wrapping it up
In Machine Learning, programs can have the same meaning and even speak the same language but output different results because context matters and implementations are full of (intended) randomness. Further, development in ML is very sensitive to changes and even small differences can have high impacts on the result. For reproducibility, we have to record the full story and keep track of all changes.
Frameworks such as DVC or Pachyderm help to keep track of not only the code but also the data. Furthermore, they use pipelines to reproduce results and simplify collaborative projects. This increases the reproducibility and corresponds to the responsibility in ML. On top of this, the tools are a first step towards the fulfillment of laws like the GDPR because results can at least be reproduced. However, these solutions are to some extent immature and evolve quickly (however, just like everything else in ML). It is still a long way to go to obtain practices in ML which are comparable to standards in software engineering.
Related Sources and further reading
- Collaboration Issues in Data Science (accessed: 25.02.19): https://github.com/iterative/dvc.org/blob/master/static/docs/philosophy/collaboration-issues.md
- Hold Your Machine Learning and AI Models Accountable (accessed 25.02.19): https://medium.com/pachyderm-data/hold-your-machine-learning-and-ai-models-accountable-de887177174c
- How to Manage Machine Learning Models (accessed: 25.02.19): https://www.inovex.de/blog/how-to-manage-machine-learning-models/
- Introducing Kubeflow – A Composable, Portable, Scalable ML Stack Built for Kubernetes (accessed: 26.02.19): https://kubernetes.io/blog/2017/12/introducing-kubeflow-composable/
- Machine-Learning im Kubernetes-Cluster (German, accessed: 25.02.19): https://www.heise.de/developer/artikel/Machine-Learning-im-Kubernetes-Cluster-4226233.html
- Machine Learning Workflow (accessed: 26.02.18): https://cloud.google.com/ml-engine/docs/tensorflow/ml-solutions-overview
- Pachyderm and Kubeflow integration (accessed: 26.02.18): https://github.com/kubeflow/kubeflow/issues/151
- Pachyderm File System (PFS, accessed: 26.02.18): https://docs.pachyderm.io/en/v1.3.7/pachyderm_file_system.html
- Provenance: the Missing Feature for Rigorous Data Science. Now in Pachyderm 1.1 (accessed 25.02.19): https://medium.com/pachyderm-data/provenance-the-missing-feature-for-good-data-science-now-in-pachyderm-1-1-2bd9d376a7eb
- Reproducibility in ML: Why It Matters and How to Achieve It (accessed: 25.02.19): https://determined.ai/blog/reproducibility-in-ml/
- Reproducible data science: review of Pachyderm, Data Version Control and GIT LFS tools (slides, accessed: 25.02.19): https://www.slideshare.net/joshlk100/reproducible-data-science-review-of-pachyderm-data-version-control-and-git-lfs-tools
- The Data Science – Bill of Rights (accessed: 25.02.19): https://www.pachyderm.io/dsbor.html
Leave a Reply
You must be logged in to post a comment.