For the most of us, voices are a crucial part in our every-day communication. Whether we talk to other people over the phone or in real life, through different voices we’re able to distinguish our counterparts, convey different meanings with the same words, and – maybe most importantly – connect the voice we hear to the memory of a person we know – more or less.
In relationships lies trust – and whenever we recognize something that’s familiar or well-known to us, we automatically open up to it. It happens every time we make a phone call or receive a voice message on WhatsApp. Once we recognize the voice, we instantly connect the spoken words to that person and – in case of a friend’s or partner’s voice – establish our connection of trust.
But what if that trusty connection could be compromised? What if a voice could be synthesized by a third person in a way that makes it indistinguishable from the original one?
There are some very interesting studies that explore the possibility of “speech synthesis” in the matter of “speaker legitimacy” – the art of determining the authenticity of a voice heard. By the way, that doesn’t only affect us as humans. There are a number of systems that use a voice to recognize a person in order to grant access to sensitive data or controls – think about your digital assistant on your smart phone, for example.
Today, there are several ways to synthesize a voice – purely artificially or based on human input. To give you a quick overview: There is the articulatory approach, where basically the human speech apparatus is mimicked in order to modify a sound signal through different parameters, like the position of the tongue, lips or jaw. This approach is by far the most difficult to achieve due to the vast number of sensor measurements that have to be taken in several iterations of a speaker analysis. To this day, a complete speech synthesis system based solely on this approach doesn’t exist.
Another approach is the signal modelling approach. Where before, the signal was based on the question of “how does a human create it”, this approach raises the question “how the signal actually sounds” – so the acoustic signal itself is being modified here. This is basically done through applying several filters with specific settings in a specific order – the best results can mostly be achieved with a “convolutional neural network” (CNN), but there are many speech signals necessary for training the engine, and it comes with high computational cost.
The by far most successful way to create a realistic-sounding voice is by applying the approach of “concatenation”. Here, fitting segments of a existing, recorded (“real”) voice a taken and put together to create syllables, words and eventually whole sentences. Think about your GPS navigation system – it would probably take forever to record all the street names that exist in your country or region of language. But if you had just the right number of syllables in different pitches, they can be concatenated in a way where every possible combination of street names can be pronounced in a realistic way.
But how can all of this be used to attack me and my phone calls?
This rather shocking example is based on a study by D. Mukhopadhyay, M. Shirvanian, and N. Saxena. They tried to impersonate a voice by a threat model that includes three steps:
First, samples from the voice of a “target victim” are collected. That can be done in numerous ways, either through wiretapping phone calls, recording the victim in it’s surrounding or simply use voice samples shared on social media.
In a second step, an attacker speaks the same utterance of the victim into a voice morphing engine – that way, he receives a model of the voice of the victim. The engine now basically knows “what was said”, and “how did it sound”. That model can now be used by the attacker to speak any utterance, while the morphing engine is able to apply the model built before to make the attacker’s voice sound like the target victim.
Note that the term “voice morphing”: It is a technique where a source voice can be modified to sound like a desired target voice, by applying the respective different spectral features between the two voices. This process makes use of signal modelling and concatenation, that were mentioned before.
The image below illustrates the described threat model:

If you want to listen into a short sample of the result of a voice morphing software, watch this little video.
As shown in Phase III of the threat model, the fake utterance of Bob’s voice will be used to attack both a machine-based, as well as a human-based legitimacy detection capability.
The machine-based setup was targeting the “Bob SPEAR Speaker Verification System”, a Python-based open source tool for biometric recognition. Two different speech datasets (Voxforge – short 5 second samples in high quality, and MOBIO – longer samples of 7-30 seconds, recorded with basic laptop microphone) were used to train the engine, which was in this case the “Festvox” conversion system.
The results of this attack system were startling:

This data shows how the system responded to the original voices as well as the faked one’s. To clarify the overall accuracy of the system, for each dataset a “different speaker attack” as well as a “conversion attack” as made – the different speaker attack means that the voice used to authenticate itself was a completely different one on purpose. The conversion attack however is the attacker’s voice morphed into the original speaker’s one.
The “False Acceptance Rate” (FAR) shows that in both conversion attack scenarios the system granted access to more than 50% of the voices played back – enough to say that the system fails significantly against a voice conversion attack. It also shows that there is indeed a difference in the results based on the quality of the conversion samples.
Having tested the machine-based speaker verification it is kind of eagerly awaited to see how the human-based verification will perform.
For this setup, online workers from Amazon Mechanical Turk (M-Turk, a crowdsourcing marketplace) were recruited to give their voices to build a model for the attack. The setup consisted of two parts: A “famous speaker study”, and a “briefly familiar speaker study”. The former aimed for an attacker to mimic the voice of a popular celebrity – one that many participants knew and would be able to recognize more easily. For that scenario, the voices of Morgan Freeman and Oprah Winfrey were used by collecting samples from some of their speeches. The latter intended to re-create the situation where somebody received a call from a person he or she met just briefly before – like at a conference. The participants from both studies conducted the tests and were asked, after listening to each of the vocal samples, to state whether the voice they just heard belonged to one of the famous speakers – or in the second case, to one of the briefly familiar speakers. The results from both of these studies are shown below:

They show that the participants were a bit more successful in detecting a “different speaker” (an unknown voice), than verifying the original one – but the rate of successfully detecting a conversion attack was around 50%, which is not really a comforting value. The indicator “not sure”, that the participants were able to state shows, that they got confused. If this scenario should happen in real life, it is to be expected that this confusion could highly affect a person’s ability to verify a speaker’s identity.
With the briefly familiar speakers, the success rate of detecting a conversion attack was about 47%, which means that also over 50% of the users could not say for sure if an attack was present.
Let’s recap for a moment – we’ve seen that with modern means of technology it is rather easy and accessible to mimic a voice and trick people into believing that it is actually the real voice of a person familiar to them – with a possible success rate over 50%, depending on the quality of the samples used.
But why can we be tricked so easily? Isn’t there a way to sharpen our subconscious decision-making when it comes to speaker legitimacy detection?
Well, relating to the first question, another study by A. Neupane, N. Saxena, L. Hirshfield, and S. Bratt tried to find a biological relation to the rather poor test results.
In their paper – that describes a brain study based on the same tests from the studies described before – they try to find that relation.
Why a brain study? Previous studies have found differences in neural activation in the human brain in similar areas when users were viewing real and counterfeit items like websites and Rembrandt paintings.
In their study, Neupane and his team tried to confirm that some specific “and other relevant brain areas might be activated differently when users are listening to the original and fake voices of a speaker”.
To investigate this, they conducted the same tests, but monitored the users’ brain activities using a neuroimaging technique called “fNIRS” (Functional Near-Infrared Spectroscopy), by which activities in neural areas of interest can be inferred by examining changes between oxy-Hb and deoxy-Hb.
There are basically only a few neural activation areas of interest for this kind of scenarios. They are listed below:
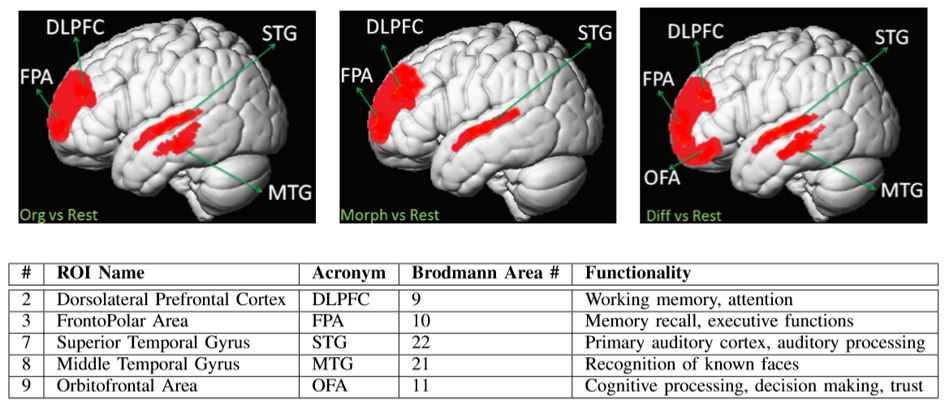
A Brain Study of Speaker Legitimacy Detection” by A. Neupane et al.
For brevity’s sake, only the applicable abbreviations are used furtherly.
You can see the three test runs where first the Original Speaker Attack is perceived, the second frame shows the Morphed Voice Attack and the third one the Different Speaker Attack. During the tests, the active regions around DLPFC, FPA and STG (working memory and auditory processing) show that the participants were actively trying to decide if the voice they heard was real or fake.
Following their hypothesis, the team tried to prove that there should be a difference in the Orbitofrontal Area (OFA), where the decision making and trust processes take place, especially when comparing the original speaker vs. the morphed voice.
But surprisingly, there were no such statistically significant differences! That suggests that the morphed voices may have sounded identical enough to the original voices to remain untroubled by skepticism on the part of the human brain. Further, a higher activation in FPA and MTG were observed when the participants were listening to the voice of a familiar speaker, compared to an unfamiliar speaker. This illustrates that the human brain processes familiar voices differently from the unfamiliar ones.
To sum up, here’s what we learned from all of that:
- Human voice authenticity can easily be breached
- People seem to detect attacks against familiar celebrities voices better than briefly familiar voices, but still an uncertainty of about 50% remains
- The brain study surprisingly shows that even though users put considerable effort in making real vs. fake decisions, no significant difference is found in neural areas of interest with original vs. morphed voices
Still wonder what that means for you?
Well, first, we should all be aware of the fact that a vocal impersonation of individuals is indeed possible, even with reasonable effort. That could target politicians as well as family members, friends or employees of your bank. Voice phishing via phone becomes a real threat, especially when an attacker is able to perform an attack where his or her voice can be morphed “on the fly” (without prior rendering or preparation of spoken statements).
It is also important to mention that the studies described were conducted with young and healthy participants. Imagining older people or people with hearing disabilities becoming victims of such attacks, the might perform even worse against those than the participants of the studies.
Finally, voice morphing technologies will probably advance faster in time than our brains evolve – our very own “biological weakness” remains.
Now, isn’t there anything we can do about that?
Probably the most important thing about all of these findings is to become aware of the possibilities of such attacks. It helps not to rely only on information given to you via phone, especially when it comes to handling sensitive information or data.
With social media becoming a growing part of your lives, we should nevertheless be wary about posting our audio-visual life online, especially not in a public manner, where samples of our voices become available to everyone.
A tip against voice phishing is to never call back to provided phone numbers. If the caller claims to be from your bank – look up the phone number online, it might be a much safer option.
Conclusively, voice is not the only way of biological identification that contains flaws – even though in our own perception it is kind of unique. Regardless, it should never be used solely to ascertain a person’s identity.
But even with security through strongly encrypted private keys, at some point in human interaction the link between machine and human needs to happen – and it is where we will continue find weak spots.
References
- “All Your Voices Are Belong to Us: Stealing Voices to Fool Humans and Machines” by D. Mukhopadhyay, M. Shirvanian, N. Saxena
- “The Crux of Voice (In)Security: A Brain Study of Speaker Legitimacy Detection” by A. Neupane, N. Saxena, L. Hirshfield, S. E. Bratt
- “Sprachverarbeitung: Grundlagen und Methoden der Sprachsynthese und Spracherkennung” by B. Pfister and T. Kaufmann
- https://krebsonsecurity.com/2018/10/voice-phishing-scams-are-getting-more-clever/
- http://www.koreaherald.com/view.php?ud=20190317000115
Leave a Reply
You must be logged in to post a comment.