
In the course of attending the lecture “Secure Systems” I became aware of a blog post by Geoff Huston on how the Domain Name System (DNS) handles “no such domain name” (NXDOMAIN) responses and which possible attack vectors could result from this. His analysis showed how little effort is necessary to perform a Denial of Service (DoS) attack against random authoritative name servers. After a presentation on this subject I decided to delve a little bit deeper into this topic and I came across the fuss about the new DNS over HTTPS (DoH) protocol earlier this year. The juicy findings during my research inspired me to write an own blog post about it. As with any technology, there are two sides to every coin. It always depends on which perspective you take and what hidden agenda you may pursue. For that reason, this blog post is not intended as a critique of the DoH protocol itself, which can be a valued addition to the internet and appears to have helpful uses. Therefore, my focus was on how DoH might currently be implemented having regard to the overall context. Herein, I will not go into technical details of the DoH protocol and thus refer to the corresponding RFC 8484 containing all these information.
Worrying centralization on the Internet
Since its development in 1984, the DNS has become undoubtedly the most highly distributed global database on the internet. Every day, millions and millions of people are independently adding and changing records in this database in a loosely coupled system or using them to find their desired resources. Today, the World Wide Web is highly distributed as well, with countless systems connected and innumerable actors continuously publishing their content or accessing web resources by use of the underlying HTTP protocol and its encrypted version based upon Transport Layer Security (TLS). Both the DNS and HTTP protocols demonstrate vividly the basic architectural principles of the internet, such as loose coupling between different systems and layers, loose coordination between various entities that use a certain protocol and widely decentralized distribution of the protocol and associated systems.
But over the last ten years, there has been a noticeable tendency on the internet, where the majority of traffic was shifting more and more towards a few digital behemoths. In this context, the US network equipment provider Sandvine recently noted in its annually published “Global Internet Phenomena Report” that roughly 43% of the worldwide internet traffic is solely generated by applications and services of the six major tech companies Google, Netflix, Facebook, Microsoft, Apple and Amazon. Overall, Google leads with a total share of 12% as the top consumer of bandwidth on the internet and dominates in the percentage of connections as well. Close behind is Netflix with 11% as the single largest consumer of traffic downstream.
This previously described trend towards an intense centralization onto a small number of very large platforms led to intensive efforts to “re-decentralize the web”. Advocates of the effort to resist and turn back this increasing centralization of the internet include many leading figures such as Sir Tim Berners-Lee, better known as the “inventor of the World Wide Web”, or Vinton Cerf who is one of the “fathers of the internet”, as well as Brewster Kahle who became known as the founder of the US web traffic analysis company Alexa Internet.
While internet traffic to particular destinations is more and more concentrated, at the same time the individual physical destinations in these large platforms, more precisely the Points of Presence (PoPs) which form the so-called “Edge”, are highly distributed in order to provide optimal performance no matter where their users are located. But while these PoPs may be physically distributed, the administration, operation and control of every single server remain centralized. If you are wondering at this point how traffic distribution at the Edge works with DNS and other load balancing techniques, I would like to recommend you my other blog post on this subject.
Where there’s light, there’s shadow
Not for the first time today, is DNS quiet a fertile field of opportunity for both surveillance and access control. Because the protocol was developed at a time, when most of the actors within the network knew each other personally, encryption was not a top priority and in this totally unencrypted mode DNS operates by default until today. This means that queries and responses are available to everyone who has access to the physical layer. In this case, the protocol has no authentication, so that a network operator such as your Internet Service Provider (ISP) can intercept DNS queries to any IP address and provide a response on their behalf, without knowledge of the querier. In addition, every single transaction on the internet begins with a name resolution query using DNS. Thereby, DNS is an accurate and also chronological indicator of everything what we do on the internet. The fact that this is a totally unprotected and open protocol turns it into a huge minefield. It is hardly surprising that many service providers as well as states with a repressive political regime associated with extensive censorship use DNS for all kinds of purposes relating to both surveillance and access control.
First of all, it is useful in this context to look more particularly at the interaction between the user’s client and its possibly self-chosen recursive resolver, which often has been allocated instead by the ISP. This is an important piece of the puzzle, because at this point it is the only time as part of name resolution using DNS where the user’s IP address is contained in the query. Once the query is passed within the DNS infrastructure, it is no longer possible in this way to identify the user directly. At this point please note that a basic understanding of the principle of recursive name resolution is important in the paragraphs below. If you may have stumbled a bit, it would be advisable to take a quick look at the blog post of Cisco Systems on this subject before you continue reading.
Nevertheless in order to detect the user’s IP address as a service provider, a mechanism called EDNS Client Subnet (ECS) was standardized, which uses the EDNS0 extension. This attachment includes information about the IP subnet of the user’s client inside the DNS query sent by a recursive resolver. At this point it should be noted that the usage is always a balance between privacy and performance, as the latter is associated with user information leakage.
The rise of Content Distribution Networks (CDN), which typically operate multiple PoPs, has led to a technique where the assumed geolocation of the recursive resolver was a sufficiently good indication to locate the user’s client. However, the parallel growth of the use of open DNS resolvers like e.g. Google (8.8.8.8), Quad9 (9.9.9.9) or CloudFlare (1.1.1.1) ruined this assumption. This trend has caused issues on the CDN side including misdirected users and an extremely inefficient delivery of their content. The perceived “white knight” here was the abovementioned ECS mechanism, whereby the user’s IP address within the attachment survives recursive resolver hand-offs and can be used as a distinguishing label for local cached DNS queries.

As already mentioned at the beginning, DNS could be seen as a kind of an invariant distributed database. No matter who submits a name resolution query, the subsequent response will be always the same. Thus, ECS may be an indication that some actors pursue a hidden agenda and intend DNS to be inconstant in a way, such that the response may depend on the identity of the querier. Semantically a line is being crossed here, but more importantly, an obvious red line concerning privacy is being crossed too. Previously, authoritative name servers were not able to detect the user’s IP address and as well as its identity. By default, DNS queries do not disclose the original querier, but with ECS a name server has the ability to recognize the user’s client. This is a recipe for interception and eavesdropping on the server side, which allows a deeper look at the user’s interests by analyzing the domain names served.
Securing the transfer is only half the story
First of all, the TLS protocol ensures both that the communication between the user’s client and a server is encrypted and the server is operated under the authority of the named entity that the client wanted to connect to. In almost the same way as TLS is used to protect HTTP connections and ensures that the end point is an authorized agent of the named service. But this protocol can also be used in the context of DNS to protect the transfer between the user’s client and its recursive resolver. Since the standardization of DNS over TLS (DoT) an increasing number of recursive resolvers are available that support DNS in its encrypted version. There are implementations for all common DNS servers like e.g. Unbound or PowerDNS and also BIND which can be configured accordingly. So if you are ready to move off the beaten track and set up your own DNS resolution environment on your home network, you can bypass the recursive resolver provided by your ISP and use DoT which will hide your name resolution queries from prying eyes of your ISP and others.
For the sake of completeness, it has to be considered that this is a highly qualified form of privacy. It is far from being a solution for the butcher, the baker and the candlestick-maker. Adding DoT support to your network usually requires the installation of your dedicated DNS server, because many home routers such as those of the German manufacturer for consumer electronics AVM, which has a market share of more than 50% in Germany, do not support DoT until today. Moreover, the number of users willing to make such efforts in this respect is likely to be relatively small. A similar picture can be seen in Apple’s iOS, which has no possibility for the user to activate DoT within the operating system. Thus, the installation of some third-party app is necessary here as well. Only in Android since version 9 there is a DNS privacy option, which is relatively hidden and the probability that a user stumbles over it while swiping or tapping around on his device is very unlikely.
But the proper configuration of your client and an open DNS resolver, which supports client connections using DoT, is only half the story. The core issue in this context is: Who am I going to talk to? This is a crucial decision! While you are preventing others from looking over your shoulder at your DNS queries, you are still allowing your chosen recursive resolver a deep insight into your browsing activities. As mentioned before, there are several open DNS resolvers being provided by Google, Quad9 or CloudFlare.
Sharing your secrets with Google may sound a bit like supping with the devil and you do well to use a long spoon. That Google has an unbridled appetite for all kind of data is an open secret. Their advertisement platform is continuously generating extensive user profiles and they are masters of “surveillance capitalism”. In their defense, it has to be said that they clearly stated not to “…correlate or combine information…” from their public DNS service with “…any personal information that you have provided Google for other services…” However, this raises the question of how such unilateral commitments are enforced within the company? Google is not really known for permitting a compliance inspection by an independent third-party. While the previously quoted statement has a noble intent, how can a user be sure that they fully adhere to it?
Let us have a look at the situation from the user’s perspective. Once you leave the reservation and choose one of the abovementioned open DNS resolvers, you will also be leaving the safe haven of your local national regulatory framework. However, there are two sides to every coin. On the one hand you possibly circumvent what you experience as a bothering content control or a kind of censorship, but on the other hand you also circumvent any rights and protections you may have through the same national regulations. The core issue here is: If you leave any national jurisdiction, then who is left to keep a sharp eye that service providers adhere to their statements?
This is not only about trust in the service provider at the other end of the line. Even accessing such a privacy-oriented service may pose an issue. In the course of the standardization of DoT it has been specified that this service is using TCP port 853 instead of port 443 which is used to protect HTTP connections with TLS. In this context, it was not taken into account that any network operator is able to prevent users from making use of DoT by simply blocking all traffic to TCP port 853.
All in all, it can be noted here that DoT is specialized service which remains reserved for merely a few people. In addition, this service can easily be blocked and it may prevent surveillance on the physical layer, but in the end you share your whole browsing activities with the recursive resolver of your choice. There is no doubt that DoT is reliably protecting privacy during transfer, but after all you are stuck between a rock and a hard place and you can only choose to whom you expose yourself.
Is DoH merely old wine in new bottles?
What caused all the fuss at the 104th meeting of the Internet Engineering Task Force (IETF) in Prague at the end of March was a debate on a variant of this DoT approach named DNS over HTTPS (DoH). With respect to the transfer of DNS queries on the physical layer there is almost nothing wherein DoT and DoH differ from each other. To put it in a nutshell, they both transfer name resolution queries between a user’s client and its recursive resolver while these have been encrypted with TLS. Regarding to the transport layer the only difference between these two approaches is that the DoH protocol uses TCP port 443 and thereby the same port as the HTTP protocol in its encrypted version. At first glance, it may look like a cosmetic change but there are fundamental differences that exceed this simplistic protocol tweak and will become more obvious in the section, where Pandora’s Box is opened.
Another one bites the dust
A network operator such as your ISP usually pursues the goal to provide excellent network performance especially in respect to name resolution while protecting the security as well as privacy of their users. Furthermore, most of them offer filtering services based upon DNS, which are required for e.g. malware and security protection in enterprise networks or parental controls on your home network. Therefore, many operators are also interested in adding support for DoH and DoT respectively. As already mentioned at the beginning, concerning the discussed centralization on the internet, it does appear that a network operator will no longer be a part of the value chain for delivery of network services such as DNS resolution and related services.
Moreover, a name resolution using DoH which an ISP might provide to its users is probably not a recursive resolver that can be accessed by everyone on the internet and in fact a sequel of the current model, whereby the servers are protected by an Access Control List (ACL) to reduce possible abuse. This is in contrast to the open DNS resolvers, which are openly accessible from any network. In addition to that an ISP also typically has a direct and trusted relationship with its users which are normally bound by legal agreements including terms of service and a privacy policy. Depending on the country there are national regulations, such as the General Data Protection Regulation (GDPR) in Europe that may also control privacy, data collection and handling of data. All of those things would apply to any network operator providing name resolution using DoH as they do to conventional DNS resolution.
Strengthening centralization through DoH
As indicated above, the major problem with DoH is that it does not use the recursive resolver in your operating system for name resolution, regardless of whether it is self-chosen or not. Instead of that it uses a recursive resolver, which the developer of an application has approved. The companies Google and Mozilla, together with a market share of more than two-thirds in the web browser’s market, have presented first examples. In releases thus far, Mozilla’s Firefox has defaulted to the open DNS resolver CloudFlare and Google’s Chrome browser is using their own public DNS service. Who would have thought that? This further concentration of name resolution queries by DoH onto a few digital behemoths, that have a commercial intent, reinforces evermore the centralization of operation and control on the internet.
Now, if you continue these thoughts it will be just a matter of time before DoH is enabled by default. This means that there are merely a few big players, rather than a wide variety of recursive resolvers supporting DoH, which is in complete contradiction to the highly distributed nature of DNS today. While the web browser developers has so far turned DoH off by default and users have a chance to leave it so, the obvious long-term goal of these companies will be to enable DoH permanently at some point in the future. Thus, the current opt-in model seems to be the breeze before the storm.
The train might be unstoppable
The development of DoH so far reminds me inevitably of the American near-catastrophic movie “Unstoppable” from 2010 where Denzel Washington and Chris Pine are trying to stop a runaway freight train. Without telling too much, like almost any good Hollywood movie, there is a happy ending. However, in the context of DoH I still have some doubts…
Introducing a new protocol, such as Internet Protocol Version 6 (IPv6) in the past, requires a proper technical coordination within the community, extensive and transparent measurement as well as comprehensive technical discussions over several years and successive adoption. In this example, acceptance of IPv6 grew organically over time, which is partly due to the diversified and large number of parties that needed to independently take steps adopting those protocols. In contrast, there are significantly fewer major operating systems or web browsers than network operators and such.
The final outcome of this further centralization is that if only two web browser developers with such a high market share have implemented DoH, then the acceptance of DoH could increase quiet fast and outrun or even replace conventional name resolution using DNS. It would be unprecedented if a new protocol could be introduced so quickly and replace an established, well-engineered and highly distributed protocol like DNS at the end of the day. This dangerous potential of DoH alone demands for a lot of testing, discussion and broad approval of all parties on the internet worldwide. To illustrate this potential once again, if companies such as Google and Mozilla were implementing DoH in their web browsers or operating system, then adoption could occur abruptly and they would become the frequently used recursive resolvers with majority of name resolution queries on the internet.
In principle, it is of course positive, if new security related protocols are quickly accepted and driven by the actions of a few key players. Nevertheless, it is important to also concede that this may be simultaneously in contradiction with other goals for the design and operation of the internet, which requires thoughtful consideration of all the pros and cons as well as an extended discussion with all actors involved.
Unveiling Pandora’s Box
The introduction of DoH entails a variety of potentially significant risks to the overall security, stability and performance of the internet particularly with regard to the repeatedly named concentration of name resolution queries. Now, let us open Pandora’s box and see what is inside. Shall we?
Operational shift of the internet infrastructure
Shifting from a large number of highly distributed recursive resolvers towards a few centralized ones will probably have notable impacts on the administration, operation and control of the internet. The full impact in detail of such a distinct and abrupt change requires an extensive study by a range of parties across the internet.
Decreased stability and reliability
An intense centralization may raise the vulnerability of a system, because it will become a single point of failure and thus each individual failure can have serious impacts. This indicates that if the authoritative DNS infrastructure becomes more concentrated as a potential result of DoH, then it will have negative impacts on stability and reliability of the DNS as well. While not caused by DoH, there are several examples of extensive internet outages when very large platforms that provide DNS resolution experience technical faults or a cyber-attack, such as Dyn, which is now a subsidiary company of Oracle. In 2016 they became suddenly the victim of a Distributed Denial of Service (DDoS) attack, which also had massive impacts on e.g. Twitter, Spotify or SoundCloud, making uses of their network services. This attack demonstrates vividly how weaknesses in the DNS infrastructure and concentration of name resolution queries may affect the stability and reliability of the internet.
Increased vulnerability to cyber-attacks
Further concentration of name resolution queries by DoH could lead to a significant reduction in the number of recursive resolvers. As mentioned before, this results in a single point of failure on which attackers can focus, possibly altering the Return on Investment (ROI) required for a large-scale attack to succeed. Such threats may entail a huge impact of DDoS attacks as shown by the example of Dyn or a standard DoS attack against a small number of systems.
Loss of security threat visibility
Some users will experience a degraded ability or total loss of filtering services based upon DNS, a mechanism called “DNS sinkhole”, which is one of the primary and most efficient ways to protect a network against all kinds of malware and cyber-attacks. This is due to the fact, that a network, which is connected to the internet, can perform some degree of local policy control that remains local and does not spread beyond its administrative boundaries. That includes extensive monitoring and protection of a network’s security and all devices connected to it. In the course of time, one of the common and widespread practices is the usage of the DNS for monitoring, rectification or prevention of malware infections and other security issues. This approach is used in many cases, ranging from ISPs to enterprise networks. Sometimes a dedicated DNS server is operated inside the network, while otherwise it will be obtained externally as a cloud-based service.
To illustrate the impacts again, in many networks the Fully Qualified Domain Names (FQDN) of name resolution queries will be steadily checked for matches with lists of well-known malware command and control servers. In some cases when a match occurs, the network operator, or sometimes the owner of a device, will be notified of a malware risk. In other cases, the internal DNS servers are configured to rewrite the response for a query of a malware related FQDN, which provides a new IP address that points to a server alerting the user of a potential infection and providing an NXDOMAIN response to terminate the DNS query. This approach will fail, because name resolution using DoH is bypassing those servers that provide this functionality. In the end, this can lead to a lot of blind spots in an extremely critical field of security threat visibility.
Loss of content controls or rather parental controls
Similar to the abovementioned usage of DNS on enterprise networks for monitoring purposes and the prevention of security issues, it is also often employed at home to provide filtering services such as parental controls. Thanks to this mechanism, a parent can configure the corresponding service to prevent their children from accessing inappropriate or disallowed content on the internet. Now, let us imagine you have two children of elementary school age between 6 and 9 years old, so it is advisable to configure policies that block them from accessing any web resources on topics such as social media, gambling, drug abuse, pornography, etc. These services are often cloud-based and very popular, because they usually work independently of any device types or operating systems.
Also in this case the approach typically works by use of DNS response matching and rewriting, after which the user is redirected to a server alerting him of a malware risk or receives an NXDOMAIN response. But this approach will fail as well, if name resolution queries are bypassed, because of DoH. A possible proposal here is that a recursive resolver supporting DoH offers such services, but this is not a decision the user is being permitted to make. In addition the user can be totally satisfied with its current solution and does not want to take the time to set up a new solution or intends to use another service provider for this functionality. It seems there are no open DNS resolvers using DoH and offering a mature service for content control or rather parental control at the same time. Indeed, there are related solutions, but they appear very sparse and poor in customization as well as functionality and do not meet the standards that has established over the last two decades.
Moreover, it is very likely that a user intends to configure a dedicated DNS server, which provides functionalities such as parental controls, as many solutions do today. But this intention may become more complicated and different with DoH, because web browsers or other applications are overriding individual configurations of the user in the operating system.
Issues with Split-Horizon DNS
Through the mechanism Split-Horizon DNS, separate servers are used to provide different name resolution, depending on whether it is for an internal or an external network. It is necessary for security and privacy management and is often used in enterprise networks. Specifically, this means that there are domain names, which only should be resolved internally or point to special internal servers for internal users and are publicly accessible for users outside of the network.

A practical example would be that an enterprise provides a groupware service on premise, which is reachable via a private IP address of the CIDR block 192.168.0.0/16 and is accessible via the web browser at https://groupware.example.com. The FQDN is maintained solely on internal recursive resolvers and thus cannot be accessed using the authoritative DNS infrastructure on the internet. In the context of DoH this domain name will no longer be resolvable, because the internal DNS servers that can provide a valid response are no longer provided in the resolution path for a user on that network. The internal recursive resolver will be skipped and the name resolution query is directed instead to an open DNS resolver. At this point, of course you can criticize the use of Split-Horizon DNS as well as Network Address Translation (NAT), but regardless of whether this is good practice or not, it is frequently used and should be taken into consideration when developing a new protocol.
Leaking of internal data
As shown by the example above, when name resolution is separated through Split-Horizon DNS, querying an open DNS resolver using DoH will lead to a NXDOMAIN response. However, because the internal name resolution query was sent to the authoritative DNS infrastructure, the availability of that internal domain name has leaked outside of the network. At the same time, if a reverse DNS query of a domain name is performed that will leak private IP addresses as well. Even so, such a leak of IP addresses happens regardless of whether Split-Horizon DNS is used or not.
Possibility of reduced DNS server implementations
Another side effect of further concentration of name resolution queries due to DoH might be less DNS server implementations or at least a smaller number of them are responsible to handle the overall traffic, which can be seen as worrying. Simultaneously, this could also lead to a shift of traffic away from service providers developing proprietary solutions instead of using open source equivalent. Thus, it is likely that the impact of exploits in such DNS server implementations, which are used by a few digital behemoths, can have a huge impact on the internet worldwide.
Possibility of increased commercial usage of user data
As already mentioned at the beginning, the highly distributed nature of DNS today is decisive for the fact that there are merely a few data sets of user DNS queries with a global reference. Possible exceptions here are the open DNS resolvers, which receive billions of billions of queries each single day. But through the concentration of name resolution queries by DoH, very large data sets may arise, which carry the risk that service providers fall into temptation to use them commercially. In particular, this might apply if an open DNS resolver offers its service for “free”. But we probably all know the popular adage: “There is no such thing as a free lunch”. Originally, the “free lunch” refers to the tradition of western saloons providing a pretended free lunch to patrons who had purchased at least one drink. Many foods on offer were high in salt, so those who ate them ended up buying a lot of beer. This demonstrates vividly the idea that you never get anything for nothing.
Even if the abovementioned data sets are “anonymized” in a way, it is very likely that some service providers will have enough other data sets that a combination of them simply allows de-anonymization. Furthermore, a user may feel uncomfortable with sending their name resolution queries to an open DNS resolver using DoH, because they have no trusted relationship with him, which can be also problematic in the context of national regulations such as the GDPR.
Possibility of negative impacts on CDN localization
There is a risk for some CDNs through DoH that optimizing the delivery of their content is no longer possible in the way as it is today. As already mentioned at the beginning, a CDN realizes geolocation by accurately estimating the location of a user’s client, which normally uses the ECS mechanism. This information is used afterwards to dynamically generate DNS responses based upon the geographical location of a user. The primary goal of every CDN is to always direct the user to the nearest PoP in its region which caches the desired content.
Noticeable impacts of a misdirected user’s client might be slower access to web resources and more traffic traversing the backbone as well as suboptimal peering points in contrast to PoPs with direct interconnection between networks. At this time, it is very difficult to estimate the actual impacts on end user performance, because with Google and CloudFlare only two of the major open DNS resolvers even support DoH.
Abuse of DoH for malware command and control
As will be illustrated in more detail later by an example and with respect to the loss of security threat visibility, it is relatively obvious that DoH can now being used virtually as an undetectable command and control channel for malware. This is due to the fact that from the outside it looks like the HTTP protocol in its encrypted version and uses the same TCP port 443 as well. You could make assumptions in the opening TLS handshake, because the name of the server that a client wanted to connect to will be sent in clear text. But work on the extension to TLS named “Server Name Identification (SNI)” is in progress, and so it is likely that even this small loophole might be shut down at some point in the future. Now, if you add some padding like in TLS version 1.3, then even traffic analysis would not inevitably reveal what happens inside the connection.
Interruption of lawful DNS blockings
In an increasing number of countries, a network operator is forced by national regulations to realize a blocking of domain names. Some democratic countries have already implemented a corresponding national regulatory framework, but DoH may render this useless. This is a fact that should chasten national regulators, which is why they have to demand that recursive resolvers supporting DoH comply with all possible national regulations. Thereby, this is not about the basic issue whether a blocking of domain names is either reasonable, effective or could be easily circumvented. If companies operate in a particular country, it is usually expected to comply with the applicable laws and so network operators, providing name resolution using DoH, will have to define how to satisfy them. At this point it should be noted that this is not to be confused with some sorts of blockings, which are used by political regimes associated with extensive censorship for all kinds of purposes relating to both surveillance and access control.
Possible impacts on server-side performance and scaling
As already mentioned at the beginning, many new protocols such as IPv6 are introduced organically, which means the adoption or growth of the protocol runs relatively gradual. Therefore, all parties have a longer period of time to learn more about scaling and achievable refinements in performance. In addition, they are able to carefully examine and realize improvements in comparison with an abrupt migration, where the significant shift to a new protocol or system occurs in a very short time. With regard to the repeatedly named concentration of name resolution queries by DoH, a rapid change is very likely in this context. However, this raises the risk of instability and reduces the opportunity of actors involved in development and implementation to learn or make technical changes successively with relatively minimal impact on systems and users due to a high spreading in the case of an abrupt migration.
Increased exploiting against DNS engineers and administrators
Due to the described trend towards an intense centralization onto a small number of very large platforms, it is just a matter of time that attackers will realize the fact that merely a few people responsible for DNS engineering, as well as administration and operation, will control a key component of the internet. As a consequence thereof it is likely that a sneaky attacker would target exploits such as “spear-fishing” combined with social engineering techniques against this small number of actors in order to gain access to systems of the DNS infrastructure. During his active time in the 1980s and 1990s, the former hacker Kevin Mitnick certainly would have rubbed his hands at this sight.
DNS exfiltration on a new level
By pushing the client-side DNS queries into an encrypted HTTP connection, the internet itself has lost control of one end of the line and each application, including the variety of malware as indicated above, can use DoH and the DNS respectively as a command and control channel in a way that is virtually undetectable by the user’s client or a network operator. Much of today’s preventive measures against malware such as a DNS firewall, which prevents systems and users from connecting to known malicious web resources or protects against data exfiltration, are rendered useless by DoH. Thereby, it is not relevant whether a web browser has enabled DoH by default, because applications can send name resolution queries using DoH in a way that bypasses today’s counter-measures for DNS.
During my research for writing this blog post I stumbled over another post, which deals with an approach for DNS exfiltration over DoH. Techniques for exfiltration over an alternate protocol such as using the DNS as a hidden communication channel are by no means a new concept. Using DNS as such a hidden channel has many benefits if you consider the monitoring possibilities of a target. Through usage of a protocol that other technologies such as email or web browsing rely on, you might not typically expect DNS to be used for anything other than the resolution of domain names, as the name implies. Unfortunately, it is possible using an entirely legitimate protocol to communicate beyond network boundaries. But this technique still does not come without cost to an attacker, because a hidden communication via DNS is extremely slow in comparison with other options an attacker may have. Especially with regard to malware that uses the HTTP protocol in its encrypted version for the communication.
Many network operators have adjusted their monitoring to defend against this relatively old idea, which is employed by malware and attackers alike. The usage of Split-Horizon DNS, monitoring the size and rate of name resolution queries as well as the hostname labels inside a DNS query offers possibilities to detect and prevent tunneling an undesired connection. If you look at it from an attacker’s perspective, this raises the complexity when trying to stay under the radar and having a reliable communication channel back into the network at the same time. By optimizing the behavior of this connection it is possible to bypass detection, but this comes along with a speed tradeoff. Simply forbidding DNS queries to the outside of a network would obviously prevent the attack, but it is at the expense of usability. Luckily for defenders, monitoring of DNS is relatively simplistic since you only have to focus at the protocol level and apart from a few caching forwarders that are allowed to send name resolution queries to the authoritative DNS infrastructure.
Now, with DoH the deck will be reshuffled again. In principle, it is possible to achieve a DNS communication that is RFC compliant using an encrypted HTTP connection. It is virtually like a JSON-API to perform DNS queries. First, a simple HTTP GET request is made, followed by a response in JSON format, all via an open DNS resolver like Google. Right here, a sneaky attacker would frolic in delight. Using a legitimate and more often than not trusted domain names such as google.com to obfuscate your traffic to a VM instance on Google Cloud Platform (GCP) is not uncommon. This mechanism called “Domain Fronting” has established in some degree, where it has been used to circumvent blocking of domain names due to censorship as well as in some kinds of malware. If you disregard the possible intentions associated with Domain Fronting, by abusing DoH the same level of evasion can be achieved, albeit at the cost of a much slower rate but using a trusted domain name.
In the following, the boundary conditions and the possible attack scenario will be explained in detail with the purpose of not only demonstrating the potential of DoH as an exfiltration channel, but also to raise defender’s awareness so that monitoring and detection mechanisms can be developed. First of all, let us imagine you are the responsible operator of a network that has relatively good monitoring. You are also able to detect the usage of DNS as an exfiltration channel or rather do not allow name resolution queries to be sent to an open DNS resolver on the internet. Furthermore, you have a highly sophisticated firewall operating on the application layer, which enables web content classification and strictly blocks on that basis. The domain name google.com is on the whitelist and therefore https://dns.google.com may probably not be blocked.
Suddenly, a malware infection happens that uses DNS tunneling and some malicious code on a user’s client will be executed that periodically requests for commands to run. The responses of those commands are encoded as a series of DNS A record queries sent to an attacker controlled domain name and reconstructed on the server-side.
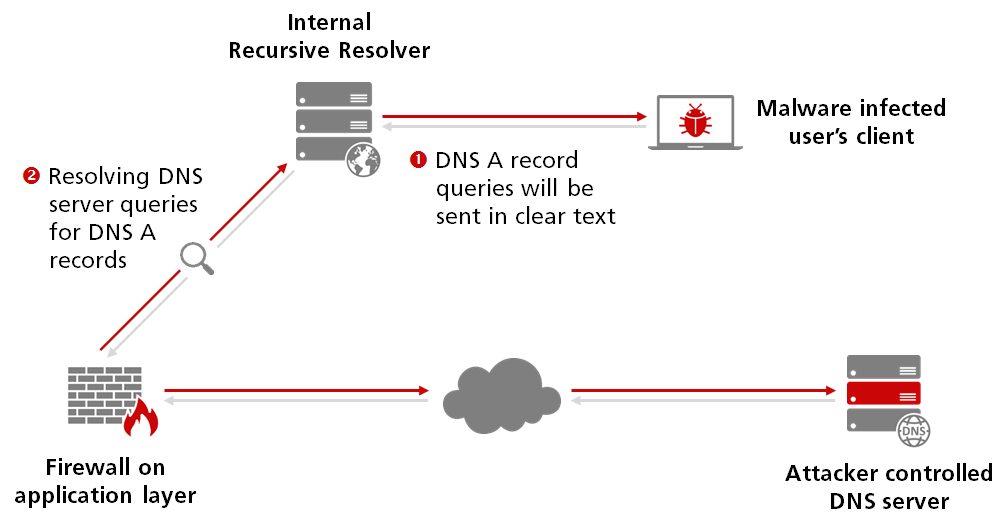
Now, the exact same idea will be transferred to simply use a recursive resolver supporting DoH for the same DNS queries. The queries themselves did not change, just the kind of transfer slightly differs that is used for sending a query and parsing the subsequently response.
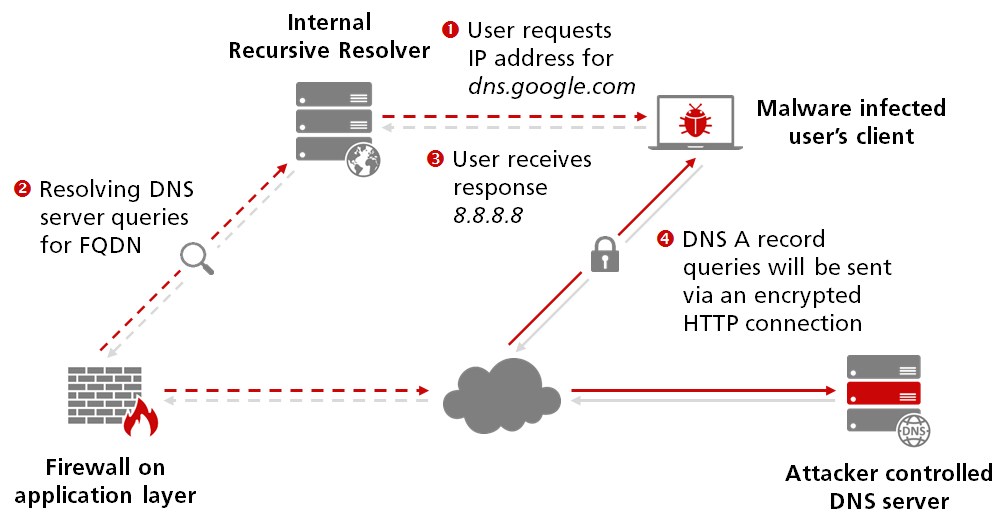
Unfortunately, you can no longer rely on the fact that DNS is a specific protocol, which could simply be monitored and filtered on a network, since we now have the additional complexity of an encrypted HTTP connection to an often trusted domain name such as google.com, smuggling the DNS queries undetected beyond network boundaries. Once a query was sent to an open DNS resolver using DoH like e.g. Google, they in turn use traditional DNS to perform name resolution and provide a response to the user’s client.
The future is still uncertain
Since the first announcement of global IPv4 address exhaustion on January 31st, 2011 when the Internet Assigned Numbers Authority (IANA) has allocated their last two unreserved /8 CIDR blocks to the Regional Internet Registry (RIR) for Asia-Pacific region, there has been established a massive use of IP address sharing practices. More than 20 billion devices are crammed into less than 4.3 billion IPv4 addresses. If we ever reach the other end of this dragging transition to IPv6 there is some hope that it is possible to restore IP address integrity, which is still relatively unlikely. But at the moment, the addresses are semantically messed up. At best in all this confusion of intensive address sharing, IP addresses are only non-persistent session tokens. But it seems that a single consistent namespace is what holds the internet together as a global coherent network.
But will this continue to be the case if the functionality of name resolution, which is indeed the crucial point of the namespace, will be shifted under the surface of the water? Or will the namespace preserve its consistency when there is no possibility to have a comprehensive overview? As already mentioned at the beginning, with respect to geolocation there are intensive efforts to use the DNS to route users to the nearest PoP by tailoring the response to suit the querier. However, with DoH there are various possibilities to go significantly further in customizing views of the namespace based upon the user’s identity and location as well as the application that they are running. Finally, this raises the question what happens to a consistent namespace, if the name resolution depends on who is making the query? Shame upon him who thinks evil upon it…
References and further reading
- Centralized DNS over HTTPS (DoH) Implementation Issues and Risks by Jason Livingood et al.
https://www.ietf.org/id/draft-livingood-doh-implementation-risks-issues-04.txt - DNS Privacy at IETF 104 by Geoff Huston
https://www.potaroo.net/ispcol/2019-04/angst.html - More DOH by Geoff Huston
https://www.potaroo.net/ispcol/2019-04/moredoh.html - Waiting for goDoH by Leon Jacobs
https://sensepost.com/blog/2018/waiting-for-godoh/ - Global Internet Phenomena Spotlight by Cam Cullen
https://www.sandvine.com/blog/netflix-vs.-google-vs.-amazon-vs.-facebook-vs.-microsoft-vs.-apple-traffic-share-of-internet-brands-global-internet-phenomena-spotlight - Decentralized Web Summit: Towards Reliable, Private, and Fun by Brewster Kahle
https://blog.archive.org/2016/06/16/decentralized-web-summit-with-tim-berners-lee-vint-cerf-and-polyfill/
Leave a Reply
You must be logged in to post a comment.