This blog aims to provide an overview about the topic of stream processing and its capabilites in a large scale environment. The post starts with an introduction to stream processing. After that, it explains how stream processing works and shows different areas of application as well as some common stream processing frameworks. Finally, this article will provide a performance comparison of several common frameworks based on benchmarking data.
Let’s begin with an introduction to stream processing.
Distributed stream processing engines are gaining popularity over the last years. Stream processing is a technology that can query continous streams of data in real-time and perform operations on the received data. It also goes by the name event-processing, Complex Event Processing, real-time-analytics or stream analytics. It allows to process data in real time as soon as it arrives in the system and can be used to quickly detect conditions in the received data. As an example imagine a temperature sensor that continously sends the temperature level. Once a certain temperature level is reached the system can trigger an alert based on the received data. [1]
At a more technical level the stream processing engines process data in a pipeline-like structure. Data gets processed in terms of a Directed Acyclic Graph (see below). The processing can chain various functions together but never go back to an earlier point in the graph. Depending on the processed data steps in the chain can be skipped.
The available frameworks approach this differently. Some frameworks let the developer define the graph explicitly, thus the coding is at a much lower level. In these frameworks like Apache Storm or Apache Samza the developer has full control over the code but it is possible to write inefficient code.
In other frameworks like Apache Flink or Apache Spark the developer can simply chain functions together and the framework constructs the graph. Thus the code is shaped in a very functional style as shown in the example code snippet below. The code snippet shows a simple application that counts words from an incoming stream for five seconds. [5]

On the contrary there is the “classic” approach of batch processing. Processing happens on blocks of data that have been collected and stored over a period of time. Depending on the size of the application this can be a huge amount of data with possibly millions of records.[1]
So why use stream processing instead of just processing the data in batches? And when?
Some data that has to be processed inside an application naturally comes as a never-ending stream of data. For example healthcare sensor data, traffic sensor data or almost all IOT devices produce events continously. These types of data are time-series data for which the time of arrival or the time at which the event occured is important. Stream Processing frameworks naturally fit this model of time-series data. Detecting patterns and anomalies within data streams becomes easy. Additionally, you can inspect multiple data streams at once. [1]
Processing constantly arriving streaming data in batches would require to stop data collection at some point, store the data and then process it. Then you’ll have to worry about aggregation across multiple batches. So using a framework that fits this model makes perfect sense. [1]
Now let’s look at some example usecases where streaming can be used beneficially:
Event-driven applications
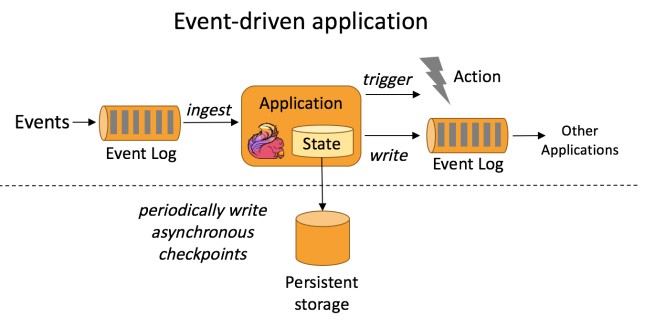
An event-driven application retrieves events from possibly multiple sources and performs operations on these events. Instead of writing data to a transactional database the data and state of the application are kept on the local system. By keeping the data on the local system the performance (latency and throughput) of the application is improved and possible network failure will be avoided. The application writes checkpoints periodically for fault-tolerance but this can happen asynchronously and does not impact performance. Examples for event-driven applications can be fraud detection, anomaly detection or rule-based alerting. [2]
The following image, taken from Apache Flink, illustrates how the architecture of an event-driven application is structured. (Apache Flink will be described later in this blog post)
Data Analytics Applications
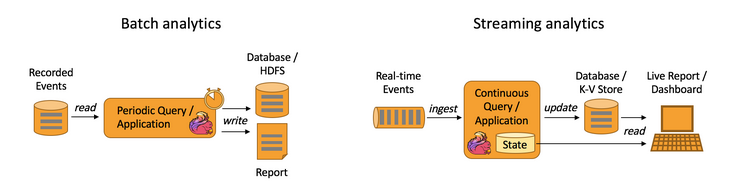
A data analytics application extracts insights from raw data. While this can also be done with batch processing it is a good usecase for a streaming application. The advantage of using a stream processing engine is the capability of using real-time-data and continously producing results. The results can be persisted to an external storage and/or shown in a live report in real time. As a result of using stream processing, the latency of processing events gets lowered. Examples for data analytics applications can be quality monitoring of telecommunication networks or analysis of product updates. [2]
The following image shows two architectures of data analytics applications using Apache Flink.
Now that we’ve seen an introduction to stream processing as well as some usecases. let’s look at what stream processing frameworks exist.
An overview about available frameworks
The history of stream processing began with Apache Hadoop’s batch processing engine and later shifted towards stream processing. By now, the following popular frameworks have implementations for stream processing:
- Apache Spark
- Apache Storm
- Apache Flink
- Apache Samza
- Apache Kafka
- Apache Apex
In the meantime stream processing was also made available as a managed service, for example Amazon Kinesis.
Let’s look a bit more into details for some of these frameworks. The blog post will briefly introduce some of the most popular streaming frameworks.
Apache Flink
Apache Flink is an open-source distributed stream processing engine. It can do stateful computations over bounded and unbounded streams. Unbounded streams equal streaming data that arrives endlessly as it is generated. The order of arrival is important to reason about completeness and must be preserved. Bounded streams are comparable to batch processing. They have a defined start and end. The order of arrival is neglectable because the finite data can always be sorted.
That way, Flink can process both input data types of streaming data and batch processing data. [9]
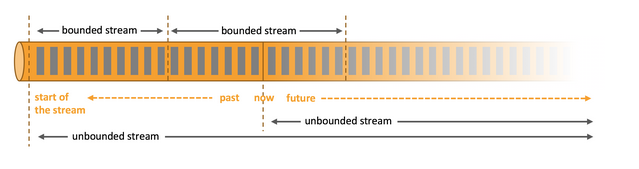
In Flink, workload is parallelized to multiple execution tasks that are distributed and run concurrently. It integrates with clusters like Kubernetes natively and can even be setup as a standalone cluster.[9]
Apache Storm
Apache Storm introduces itself as an open-source realtime computation system. It can process streams of unbounded data. [10]
Apache Storm has three abstraction types: spouts, bolts and topologies as can be seen in the architecture diagram below. Spouts are the sources of streaming data for the further data processing. They typically read from a queueing broker like Kafka but can also generate its own stream. Bolts process an input stream and produce any number of output streams. A topology unites it all and represents a network of spouts and bolts with their connections.[11]
Apache Spark
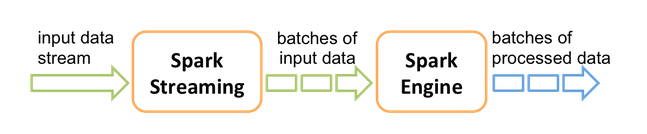
Apache Spark has a streaming component named Spark Streaming. It can consume streams of data by sources like Apache Kafka. It enables scalable, fault-tolerant processing of data in micro-batches. That means Spark divides the streaming data into small batch packages and then writes the results to an output stream of batches. You can then make use of the powerful other components of Spark like its machine learning library and apply it to the result data. [12]
Also tak a look into this blog article which provides a comparison on the coding perspective. It shows how a simple hello-word-like task is done in different stream processing frameworks
So far, we’ve got an overview about several frameworks and usecases. Next up is an overview about which criteria matter when designing a stream processing engine.
The important factors of a distributed stream processing engine
For a system that has to handle and process a continous flow of incoming data any downtime is fatal. If the system is unavailable or has performance issues data might be lost completely. That is because unlike a batch processing system data is not getting stored before processing but is rather processed immediately and stored afterwards. Therefore there is a number of factors that have to be considered when analyzing a stream processing engine. [6][7]
Thinking of stream processing in a distributed environment the following factors come into mind.
- Delivery Guarantees: No matter what happens, the incoming dataset or record will be processed. Even in the event of a system, network or application failure, the engine continues to process data. There are different types of delivery guarantees, namely:
- At-most-once
- At-least-once
- Exactly-once
While exactly-once is the desired state, it is really hard to achieve in a distributed system. Tradeoffs for performance will have to be made to ensure delivery guarantees.
- Peformance: Latency and throughput. Latency should be as low as possible and throughput as high as possible.
- Management of state: Storing state information allows operations on multiple streams like joining, transformations or aggregation operations. However, additional computational power is needed to keep the state updated and stored.
- Fault-tolerance: In case of a system or component failure the system should be able to recover. Ideally, it should start processing from the point it failed. This can be achieved by periodically saving checkpoints as we have seen in the Event-driven application example before. This also guarantees that all data will be processed and no records get lost.
- Scalability: The system should be able to deal with varying workload, frequencies and inconsistent size of incoming data.
- Windowing operations: Allows to extract a subset (e.g. by grouping events based on a time window) of an infinite data stream to view and process this subset separately. The window can be defined by event creation or processing time.
- Maturity of the framework: How long the framework has been in use and how big the community is. [6][7]
As a last step let us take a detailed look at the capabilities of existing frameworks and get some insights about how they scale upon a huge workload.
A benchmarking comparison
The following chapter uses benchmarking data out of two different sources to provide a comparison of the performance of the most popular frameworks.
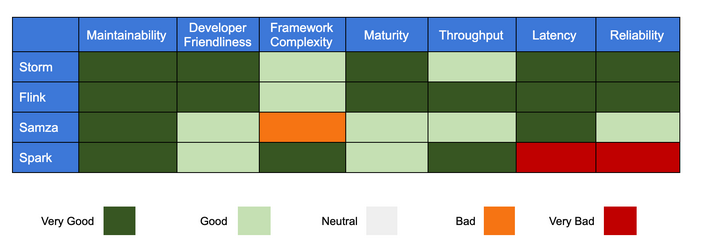
- The first source is a benchmarking comparison of Adobe for their Adobe Experience Platform. The Adobe Experience Platform handles more than 200k events per second. Adobe evaluated existing frameworks for stream processing to support the growing needs for real-time processing and growing amounts of data. They evaluated performance and reliability of the frameworks Storm, Flink, Samza and Spark. [3]
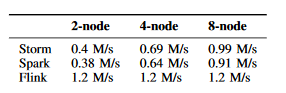
- The second source is a benchmarking published by TU Berlin. This benchmarking measures the performance of windowed operations (the basic operations of data analytics) of frameworks Apache Flink, Apache Storm and Apache Spark. The TU Berlin team used setups with multiple nodes to measure scaling and performance on different hardware setups. [8]
The two benchmarkings measure mainly latency and throughput of stream processing frameworks. The Adobe benchmarking also compares qualitative criteria while the TU Berlin benchmarking factors in skewed data and fluctuating workloads. For more information on the benchmarks of these two teams please head to their articles as listed in the references of this blog post.
The adobe benchmarking consists of multiple ‘load’ tests with one million events for every framework and then a three-day reliability test. The following table are the performance measurement results of Adobe benchmarking with data from [3]. The results were as follows :
| Throughput | 99th process latency* | Reliability | |
|---|---|---|---|
| Storm | 50-1500 events per second | < 30 ms | No crashes/failures |
| Flink | 600-1800 events per second | < 10 ms | No crashes/failures |
| Spark | 500-1700 events per second | 6-7 seconds | Crashes on every run |
| Samza | 185-815 events per second | 54 ms | No crashes, error log raised |
*A 99th percentile latency of x ms means that every 1 in 100 requests experiences x ms of delay.
The TU Berlin benchmarking consists of multiple experiments for windowed joins and windowed aggregations for streams. The tables shown below illustrate the performance measurements for throughput and latency. For further information please refer to this paper. [8]

Results of the benchmarkings
The benchmarking conducted by Adobe came to the following conclusion: Apache Flink is the best framework for their large-scale event processing neccesities. Apache Flink performs best in terms of latency and throughtput and proved to have the best reliability and did not crash at all during the conducted tests. Flink had an excellent ability of handling backpressure compared to other tested frameworks. Furthermore, Flink has a good community which will be useful in development and maintenance of their application.[3]
The following table shows their results for qualitative and quantitative benchmarking.
The TU Berlin benchmarking shows that each tested framework has a different set of usecases that they excel in. Overall Apache Flink has the best throughput and latency for different setups while Apache Spark manages skewed data and bound latency better than its competitors. Both Spark and Flink are very robust to fluctuating data. [8]
Conclusion
In this article we have got an overview about how stream processing works. We have seen some example usecases where using a stream processing engine is beneficial. Stream processing is a great tool to handle unbound streams of data that have to be processed with minimal latency or at best in realtime. Many applications with IOT devices or sensor technology can benefit from this approach. However, not all types of applications fit with stream processing. We got a brief introduction to several popular stream processing frameworks as well as some measurements on performance. Each framework has its own usecase in either performance or additional libraries like e.g. machine learning libraries that it provides.
References
[1]: https://medium.com/stream-processing/what-is-stream-processing-1eadfca11b97
[2]: https://flink.apache.org/usecases.html
[3]: https://medium.com/adobetech/evaluating-streaming-frameworks-for-large-scale-event-streaming-7209938373c8
[4]: https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html
[5]: https://blog.scottlogic.com/2018/07/06/comparing-streaming-frameworks-pt1.html
[6]: https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
[7]: https://developer.ibm.com/code/2018/03/21/stream-processing-brief-overview/
[8]: http://www.redaktion.tu-berlin.de/fileadmin/fg131/Publikation/Papers/Stream_Benchmarks_ICDE18-CRC.pdf
[9]: https://flink.apache.org/flink-architecture.html
[10]: https://storm.apache.org/index.html
[11]: https://storm.apache.org/about/simple-api.html
[12]: https://spark.apache.org/docs/latest/streaming-programming-guide.html
Leave a Reply
You must be logged in to post a comment.