Abstract
Since the beginning of Big Data, batch processing was the most popular choice for processing large amounts of generated data. These existing processing technologies are not suitable to process the large amount of data we face today. Research works developed a variety of technologies that focus on stream processing. Stream processing technologies bring significant performance improvements and new opportunities to handle Big Data. In this paper, we discuss the differences of batch and stream processing and we explore existing batch and stream processing technologies. We also explain the new possibilities that stream processing make possible.
1 Introduction
A huge amount of information is generated everyday by social media, e-mails, sensors, instruments and enterprise applications, to mention a few resources. This amount of data brings a lot of challenges according to volume, velocity and variety. In the past two years, 90% of all data was created and the amount of data will double every two years. This data comes in a variety of formats and types, each of it requires a different way to process the generated data [9].
Batch processing was the most popular choice to process Big Data. The most notable batch processing framework is MapReduce [7]. MapReduce was first implemented and developed by Google. It was used for large-scale graph processing, text processing, machine learning and statistical machine translation. MapReduce can process large amounts of data but is only designed for batch processing. Today’s demands rely on real-time processing of Big Data that will finish in seconds [19]. For this demand, various stream-processing technologies have been developed. In this paper we will focus on Apache Spark Streaming [22] and Apache Flink [6], which are the most famous tools for stream processing [12].
In this work we will explain the concepts of batch processing and stream processing in detail while introducing the most popular frameworks. After that we introduce new opportunities that stream processing provides to face today’s issues where a response is needed in seconds.
2 Related Work
Big Data analysis is an active area of research but comparisons of Big Data analysis concepts are difficult to find. Most research papers focus on comparing stream processing frameworks on performance. In this work we will focus on open source technologies. There are widely used proprietary solutions like Google Millwheel [1], IBM InfoSphere Streams [3] and Microsoft Azure Stream Analytics [8] we won’t discuss in this paper.
Lopez, Lobato and Duarte describe and compare the streaming platforms Apache Flink, Apache Spark Streaming and Apache Storm [15]. The work focuses on processing performance and behaviour when a worker node fails. The results of each platform are analysed and compared.
Shahrivari compares the concepts between batch processing and stream processing [19]. In detail, the work compares the performance of MapReduce and ff Apache Spark Streaming with different experiments.
Unlike the mentioned papers, we will focus on the difference between batch processing and stream processing and discuss the new opportunities of stream processing instead of comparing performance measurements.
3 Batch Processing
Batch jobs run in the background without any interaction from an operator. In Theory a batch job gets executed in a specific time window between the end of a workday and the start of the next workday to process millions of records which will take hours to execute. This time window will increase with availability requirements. Batch processing is still used today in organisations and financial institutions [10].
Individual batch jobs are usually organized into calendar periods. Common batch schedules are daily, weekly, and monthly batches. Weekly and monthly batch schedules are mostly used for technical tasks like backups, integrity checks or disk defragmentation. Functional tasks should be executed on a daily schedule. Typically jobs on a daily basis are, data processing and transferring. Organizing the batch schedule can save effort in the development cycle. To categorize a job, a simple rule of thumb is to determine if it has to do a functional or a technical task. To reduce batch execution time, performing jobs in parallel is a key factor [10].
There are two different architectures of how batch jobs should be executed: As scripts or as services. The major differences are logging and control. Batch jobs that will run as a service usually report their status through log files and can be controlled over a control panel which is provided by the system. Batch jobs that are triggered over the command line, report their progress through streams and an appropriate exit code. The batch scheduler will terminate the job if it’s necessary [10].
3.1 MapReduce
MapReduce is a programming model that enables processing and generating large amounts of data. The model defines two methods: map and reduce.

The map function takes a key/value pair as input to generate an intermediate set of key/value pairs. The reduce function takes an intermediate key and intermediate values associated to that key, as input and returns a set of key/value pairs [7]. Figure 1 illustrates the MapReduce programming model of a real-world use case.
4 Stream Processing
Stream processing refers to real-time processing of continuous data [14]. A stream processing system consists of a queue, a stream processor and real time views [16].
In a system without a queue, the stream processor has to process each event directly. This approach cannot guarantee that each event gets processed correctly. If the stream processor dies, there is no way to detect the error. A cluster would be overwhelmed by the incoming amount of data it has to process. A persistent queue helps to address these issues. Writing events to a persistent queue before processing the data will buffer the events and it allows the stream processor to retry an event when it fails [16]. An example for a modern queue system is Apache Kafka [13].
The stream-processor processes incoming events in the queue and then updates the real time views. There are two models of stream-processing that have emerged in the recent years: Record-at-a-time and micro-batched [16].
Record-at-a-time stream processing The record-at-a-time processing model processes tuples independently of each other, updates the internal state and sends out new records in response. This leads to inconsistency, when different nodes process different data that arrive at different times. The model handles recovery through replication which requires twice the amount of hardware. This is not optimal for large clusters [22]. To be scalable with high throughput, the systems run in parallel across the cluster [16].
Micro-batch stream processing The micro-batch stream processing approach processes the tuples as discrete batches. A batch is processed in a strong order until completion before moving on to the next batch. To know if a batch has been processed before, each batch has its own unique identifier that always stays the same on every replay [16].
4.1 Apache Spark Streaming
Apache Spark Streaming is an extension to the Apache Spark cluster computing engine. It was developed to overcome the challenges of the record-at-a-time processing model. Spark Streaming provides a stream programming model for large clusters called discretized streams (D-Streams). In D-Streams, streaming computation will be treated as a series of deterministic batch computations on small time intervals [22].
To generate an input dataset for an interval, the received data during that interval is stored reliably across the cluster. To generate new datasets as a response, after each interval the datasets are processed via deterministic parallel operations. To avoid replication by using lineage, the new datasets will be stored in resilient distributed datasets (RDDs) [21]. A D-Stream allows users to manipulate grouped RDDs through various operations [22].
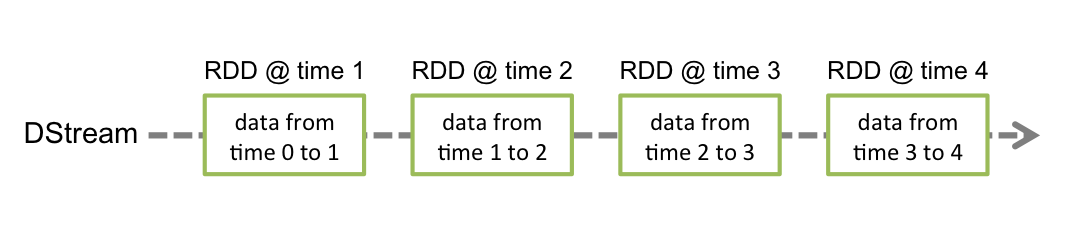
D-Stream provides consistency, fault recovery and integration with batch systems to bring batch processing models to stream processing. Apache Spark Streaming lets users mix together streaming, batch and interactive queries to build integrated systems [22].
4.2 Apache Flink
Apache Flink is a stream-processing framework and an Apache top-level project. The core of Apache Flink is a distributed streaming data-flow engine which is optimized to perform batch and stream analytics [6]. The distributed streaming data-flow engine executes programs called dataflow graphs which can consume and produce data [4].
Dataflow graphs consists of stateful operators and data streams. The stateful operators implement logic of producing or consuming data. Data streams distribute the data between all operators. On execution Dataflow graphs parallelize operators into one or more instances called subtasks and split streams into one or more stream partitions [6].

Apache Flink is a high-throughput, low-latency streaming engine and optimized for batch execution using a query optimizer [6]. Dataflow graphs are optimized to be executed in a cluster or cloud environment [20].
5 Stream Processing Opportunities
Batch processing is still needed for legacy implementations and data analysis where no efficient algorithms are known [6]. Nevertheless, stream processing offers new opportunities to face issues where the result is needed in seconds instead of hours or days.
5.1 Machine Learning
Machine learning for Big Data is dominated by online machine learning algorithms. In streaming there is a need for scalable learning algorithms that are adaptive and inherently open-ended [11]. This makes online machine learning optimal for stream processing where the algorithm has to adapt new patterns in the data dynamically.
Apache Flink Apache Flink brings together batch processing and stream processing. This makes Apache Flink very suitable for machine learning [11]. Apache Flink provides the machine learning library FlinkML. FlinkML supports the PMML standard for online predictions [5].
Apache Spark Apache Spark provides a distributed machine learning library called MLlib. MLlib provides distributed implementations of learning algorithms that can serve (but not limited to) linear models, naive Bayes, classification and clustering. MLlib can be integrated with other high-level libraries, for example Apache Spark Streaming. Apache Spark Streaming enables the development of online learning algorithms with MLlib on realtime data streams [17].
Detecting cases of fraud is an ongoing area of research. A study from 2016 estimated, that credit card fraud is responsible for over 20 billion dollars in loss worldwide [18]. It is important to detect credit card fraud immediately after a financial transaction has been made. Today, credit card fraud can be detected with supervised or unsupervised machine learning models [2]. For an instant detection, online machine learning on realtime data stream serves the needed technology to face this issue.
6 Conclusion
This paper explains the two data analysis concepts batch processing and stream processing. Since realtime analysis is needed to face the issues of today’s demands, batch processing is still being used for legacy implementations and data analysis where no efficient algorithms are known. Stream processing offers new opportunities to handle big data and response with an immediate result to the user.
References
[1] Tyler Akidau, Alex Balikov, Kaya Bekiroglu, Slava Chernyak, Josh Haberman, Reuven Lax, Sam McVeety, Daniel Mills, Paul Nordstrom, and Sam Whittle. Millwheel: Fault-tolerant stream processing at internet scale. In Very Large Data Bases, pages 734–746, 2013.
[2] Bart Baesens, Veronique Van Vlasselaer, and Wouter Verbeke. Fraud Analytics Using Descriptive, Predictive, and Social Network Techniques: A Guide to Data Science for Fraud Detection. Wiley Publishing, 1st edition, 2015.
[3] Chuck Ballard, Kevin Foster, Andy Frenkiel, Bugra Gedik, Michael P. Koranda, Deepak Senthil, Nathanand Rajan, Roger Rea, Mike Spicer, Brian Williams, and Vitali N. Zoubov. Ibm infosphere streams: Assembling continuous insight in the information revolution. IBM Redbooks publication, 2011.
[4] Ilaria Bartolini and Marco Patella. Comparing performances of big data stream processing platforms with ram 3 s (extended abstract).
[5] Andr´as Bencz´ur, Levente Kocsis, and R´obert P´alovics. Online machine learning in big data streams. 02 2018.
[6] Paris Carbone, Asterios Katsifodimos, † Kth, Sics Sweden, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. Apache flink TM : Stream and batch processing in a single engine. IEEE Data Engineering Bulletin, 38, 01 2015.
[7] Jeffrey Dean and Sanjay Ghemawat. Mapreduce: A flexible data processing tool. Commun. ACM, 53, 01 2010.
[8] Charles Feddersen. Real-time event processing with microsoft azure stream analytics. Jan 2015.
[9] Mugdha Ghotkar and Priyanka Rokde. Big data: How it is generated and its importance.
[10] Dave Ingram. Design – Build – Run: Applied Practices and Principles for Production-Ready Software Development. Wrox, 2009.
[11] W. Jamil, N-C. Duong, W. Wang, C. Mansouri, S. Mohamad, and A. Bouchachia. Scalable online learning for flink: Solma library. In Proceedings of the 12th European Conference on Software Architecture: Companion Proceedings, ECSA ’18, New York, NY, USA, 2018. Association for Computing Machinery.
[12] J. Karimov, T. Rabl, A. Katsifodimos, R. Samarev, H. Heiskanen, and V. Markl. Benchmarking distributed stream data processing systems. In 2018 IEEE 34th International Conference on Data Engineering (ICDE), pages 1507–1518, April 2018.
[13] Jay Kreps. Kafka : a distributed messaging system for log processing. 2011.
[14] Anuj Kumar. Architecting Data-Intensive Applications. Packt Publishing, 2018.
[15] M. A. Lopez, A. G. P. Lobato, and O. C. M. B. Duarte. A performance comparison of open-source stream processing platforms. In 2016 IEEE Global Communications Conference (GLOBECOM), pages 1–6, Dec 2016.
[16] Nathan Marz and James Warren. Big Data: Principles and best practices of scalable realtime data systems. Manning Publications, 2015.
[17] Xiangrui Meng, Joseph Bradley, Burak Yavuz, Evan Sparks, Shivaram Venkataraman, Davies Liu, Jeremy Freeman, DB Tsai, Manish Amde, Sean Owen, and et al. Mllib: Machine learning in apache spark. J. Mach. Learn. Res., 17(1):1235–1241, January 2016.
[18] David Robertson. The nilson report, issue 1096. Oct 2016.
[19] Saeed Shahrivari. Beyond batch processing: Towards real-time and streaming big data. Computers, 3, 03 2014.
[20] Daniel Warneke and Odej Kao. Nephele: Efficient parallel data processing in the cloud. In Proceedings of the 2nd Workshop on Many-Task Computing on Grids and Supercomputers, MTAGS ’09, New York, NY, USA, 2009. Association for Computing Machinery.
[21] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauly, Michael J. Franklin, Scott Shenker, and Ion Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Presented as part of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), pages 15–28, San Jose, CA, 2012. USENIX.
[22] Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, and Ion Stoffi ica. Discretized streams: An e cient and fault-tolerant model for stream processing on large clusters. In Proceedings of the 4th USENIX Conference on Hot Topics in Cloud Ccomputing, HotCloud’12, pages 10–10, Berkeley, CA, USA, 2012. USENIX Association.
[23] Dataflow Programming Model. https://ci.apache.org/projects/flink/flink-docs-release-1.2/concepts/programming-model.html
[24] Discretized Streams (DStreams). https://spark.apache.org/docs/latest/streaming-programming-guide.html#discretized-streams-dstreams
Leave a Reply
You must be logged in to post a comment.