Next to the powerful Request / Response architecture exists another architecture, the event-driven one. How this architecture works, where the differences to Request / Response systems are and how transactions can be realized will be part of this article.
Events
There are three types of messages that can be used for communication in systems. They are:
- Commands
- Querys
- Events
The most common message type is the command. A command requests another participant to perform some sort of action. This message type is not idempotent because it changes state. Most of the time commands include a response containing some sort of data. Commands can be used in synchronous processes or in systems including an orchestration service or some sort of process manager. [9]
Besides commands, queries are the most used messaging type in for example request-response architectures. A query can be used if you want to get data. Queries are idempotent, so they are free of side effects but they always include some sort of response. [9]
In event-driven systems events are used to communicate between participants. An event can be described as a combination of a fact and a notification. More concrete, an event is a record of something that has happened, like a change of state that others will be notified about. This could be the bare notification or the notification combined with a state transfer. Events will be published right when they occur. There is no such thing as batching in the first place. They will be published to everyone that is interested and can add value to more than a single service.
Events are immutable, so they can’t be changed or deleted. If you want to revoke an event you have to publish a new event. Due to this it is very important that events have to be ordered. Other than commands, events don’t expect any further actions. This includes any sort of response.
That’s why they are built for loosely coupled systems. If another participant is interested in a specific event, they are free to subscribe and will be notified if the event occurs. If the participant is not interested, them just doesn’t subscribe. [1] [4] [5] [9]
Producers
The part of an event-driven system that publishes events is called producer. Producers are not aware of what will happen if they publish an event and they don’t wait for any response to a published event. Moreover they don’t know what function will be executed by whom. That’s why they don’t control the process flow in comparison to Request / Response systems. [3] [4]
Consumers
A consumer is the part of an event-driven system that receives the events and might process them. In the most basic system, producers broadcast events and everyone else receives these events. Dependent on the event the consumer might process the event immediately. There are three types of event processing [3]:
- Simple event processing
- Complex event processing
- Event stream processing
The easiest event consumption is the simple event processing. If a consumer uses this approach, events immediately trigger an action on the consumer side. [3]
If a consumer processes events with the complex event processing approach, the consumer processes a series of events. In this series they will look for patterns in the event data. In some case this will be done by the systems broker, that is responsible for forwarding events to all subscribers. The broker understands and monitors the relationship between the events. Within this process they could aggregate events or identify causality between them. This approach could be used for alerting mechanisms. [3]
The third approach is event stream processing. The heart of stream processing is the data streaming platform (might be included in the broker) that acts as a pipeline which receives events and feeds them into stream processors. The actual consumers are connected to the data streaming platform. They react to the process and transform the received data. [3] [4]
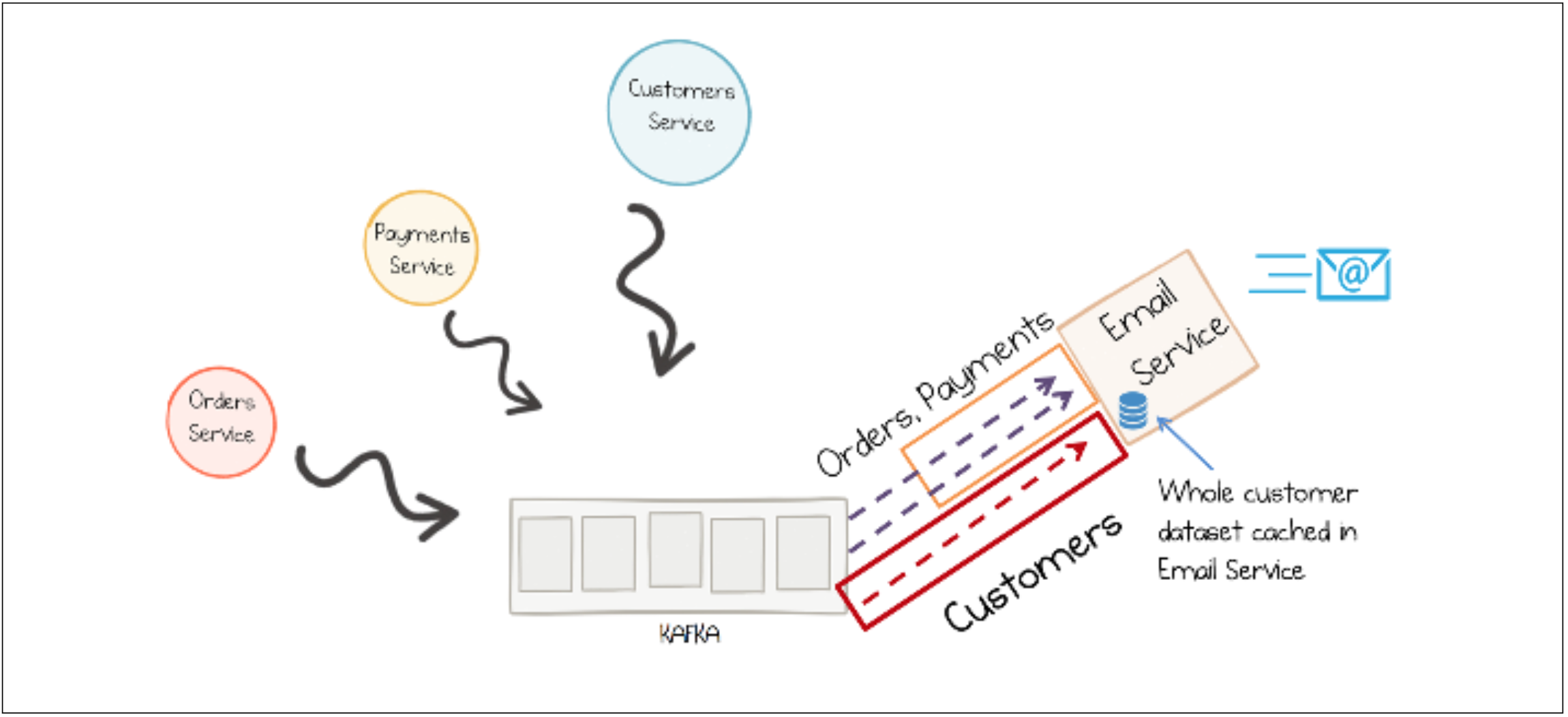
There is a stateless and a stateful stream processing. In a stateful system consumers listen to events and keep a copy of the data they might need to process incoming events. An easy example might be an email service that has to inform customers about orders or payments. In order to send these emails the service needs customer information like email addresses. If the email service was a stateful stream processor it would cache the customer data. The data would be received by events that were published by the customer service. (Figure 1) [9]
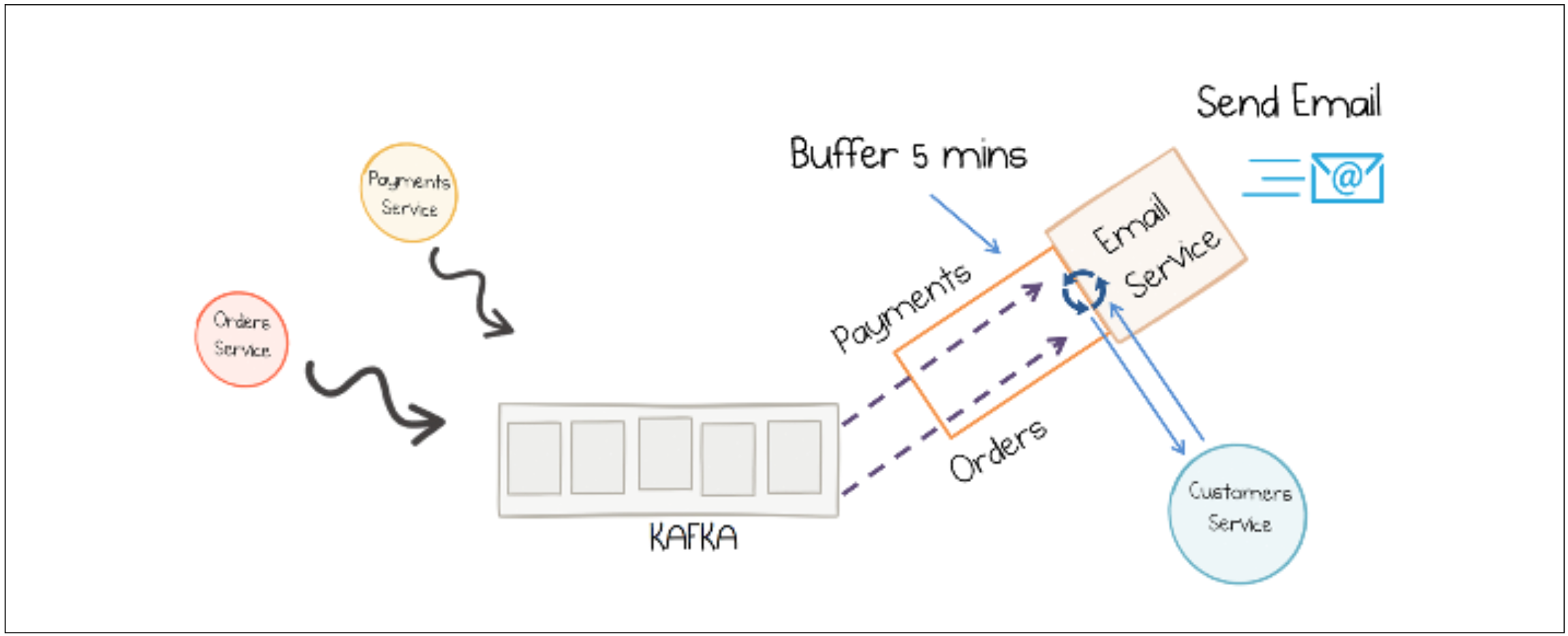
Stateless stream processors have to lookup reference data in another service at runtime. They don’t keep their own state copy. In our email service example the events published by the customers service would not be processed and cached. If the email service wants to inform a customer about its orders and payments, it will have to request necessary data from the customer service. (Figure 2) [9]
Event-driven architectures
We already learned that event-driven systems work with so called events, that will be published by producers and might get processed by consumers. The events will be delivered in real time.
There are two types of event-driven systems [3]:
- Publish / Subscribe
- Event streaming
In a Publish / Subscribe system a publisher can produce or publish events that can be consumed by other parties, if they subscribed to that specific event. The most Publish / Subscribe systems use some sort of messaging infrastructure that keeps track of the subscriptions. The messaging infrastructure is often called a broker. [3]
If a system uses the event streaming approach all messages will be written in a so called log. Due to that the log maintains the state of business entities. The collected events are strictly ordered and immutable. One of the benefits is the atomicity because writing an event is a single operation. The subscribed services can handle updating their own state in response to the event.
Another benefit is that all participants can read from every part of the stream. This enables participants to join at any time and to replay all events that happened in the past. This pattern is called event sourcing. [3] [6]
In the area of distributed computing the participants of an event-driven system most of the time are microservices. The biggest advantage of an event-driven architecture is that these microservices are loosely coupled. Coupling between the services is the measurement of the dependency between two components. The more assumptions are made, the more tightly coupled are services and there is less room for variation. These assumptions are for example very strict rules in the interaction protocol between the services. If coupling has to be reduced, a level of indirection has to be implemented and the interaction rules have to be simplified. [4]
If you decide to implement a new microservice that has to be integrated into an existing system, an event-driven architecture simplifies the process of integration. The microservice doesn’t need to know how to communicate with the other microservices. They just need to know how to publish events to the existing system and how to subscribe to events they are interested in. Besides this, the other microservices don’t need to know that there is a new service that might consume their events. They don’t get disturbed by a new service. That’s why it is very simple to add new and of course remove old services in an event-driven architecture. [9]
The communication pattern in event-driven systems is called event collaboration pattern. The key aspect of this pattern is that no single source (microservice) owns the whole process. If you want to perform some sort of action in a synchronous architecture, one service holds the state and requests other services to fulfil that action. This one service owns the whole process. Since event-driven systems work asynchronous no service can own the whole process.
In an event-driven system a process is described by a chain of events. That means that every service owns a subset of the actual process. The publication of an event triggers the next step in the chain, but the publisher is no longer aware of the next action that might happen. That also means that the business process is described by all services together. That includes the disadvantage that changes in the business logic have to be implemented in a lot of services. With a centralised and synchronous approach you just would have to do the changes in one service. All in all the centralised approach with some sort of orchestration service or process manager is more recommended for small systems. [5] [9]
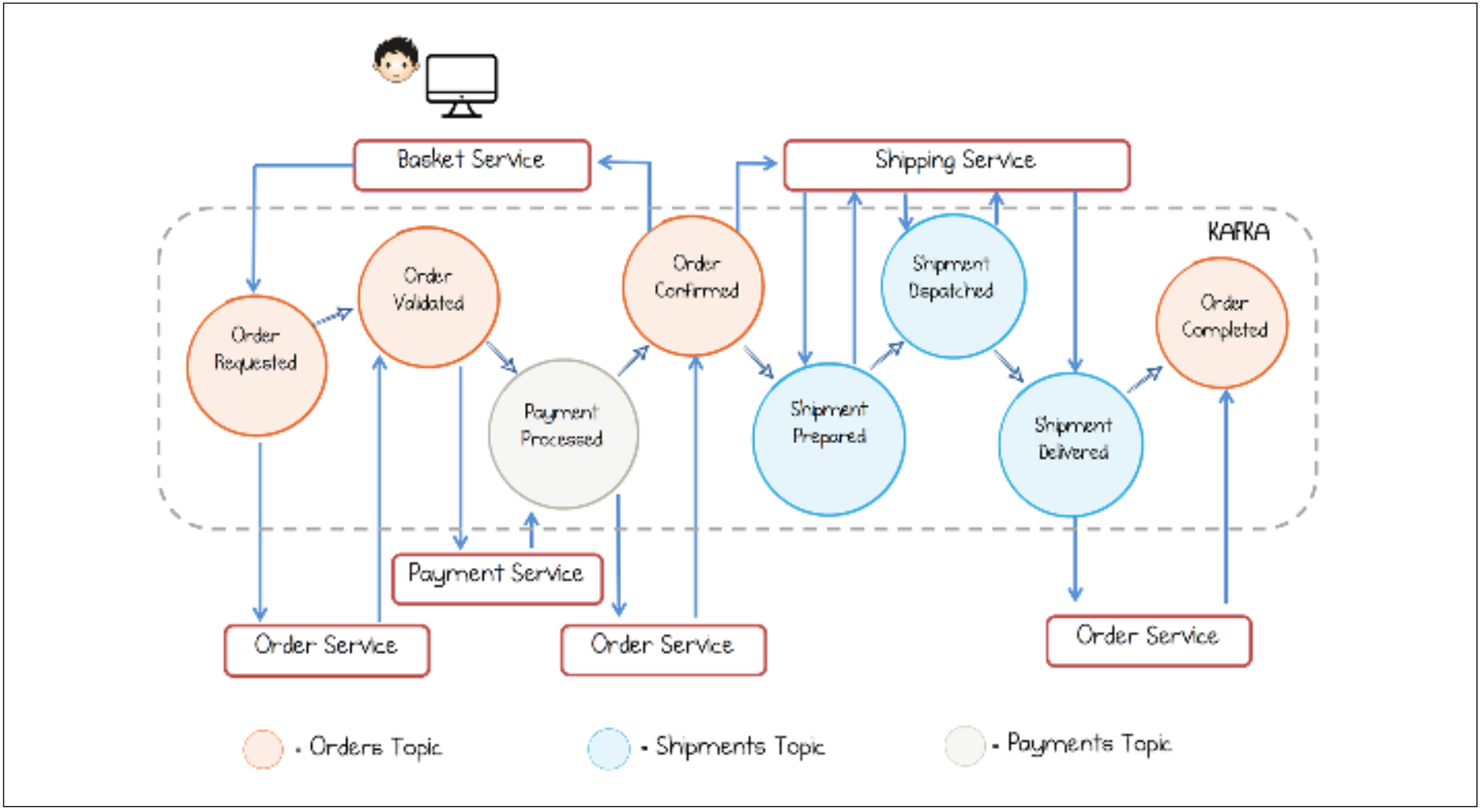
A process shared by several microservices is shown in figure 3.
Comparison: Request / Response architecture
One of the most asked questions is what is the difference between an event-driven approach and the classic Request / Response pattern.
The first and most obvious thing is the message type. Event-driven systems are communicating with so called events. In a Request / Response system the parties communicate most of the time through commands or queries. This implies that there is an answer in form of a response included. (Figure 4) An example for a Request / Response communication would be HTTP or RPCs.
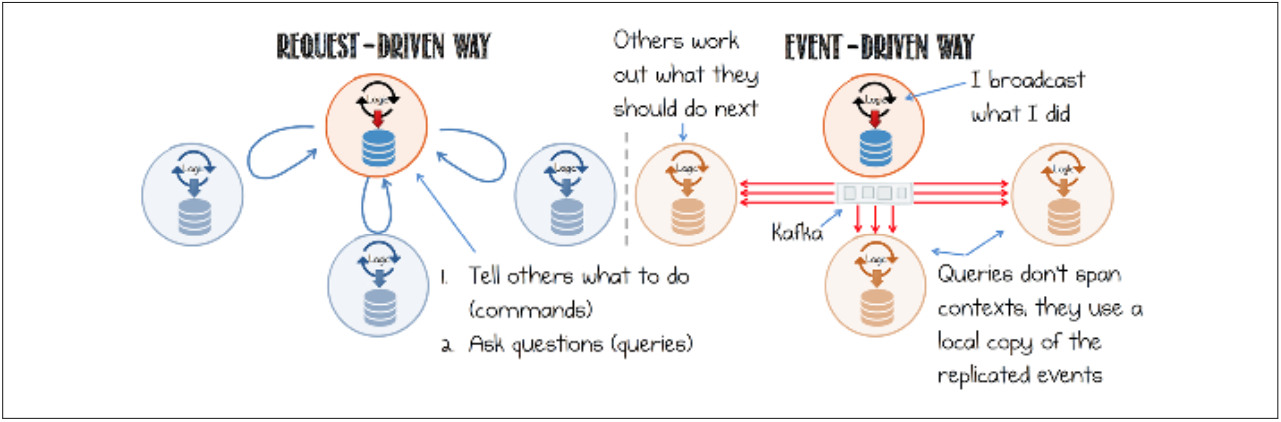
Of corse it is possible to implement a Request / Response based communication within an event-driven system, but then you might scrutinize the usage of an event-driven system. If you use the Request / Response pattern in an event-driven system the broker doesn’t contribute all that much. The broker has the task of forwarding the events to the various participants. If it is clear fright at the beginning who is to receive the message, the broker is not really necessary. Besides that event-driven systems use receiver driven routing and not producer driven routing. The producers don’t know if and what receivers exist that might process the published events.
With a Request / Response communication within an event-driven system there is no requirement for broadcasts (events are available to everyone) or a storage (log) as well. Furthermore, you would create a way more coupled system, that you are normally trying to avoid by using an event-driven architecture. Furthermore, plugging in additional services would result in changes for all services the new service wants to communicate with. [9]
Let’s take a look at an example that shows how to implement an order management system with the Request / Response pattern and the event-driven approach. Figure 5 shows the system with a communication based on requests and responses. If a user submits their order, the “Orders Service” requests the “Shipping Service” to ship the order. So as to do this, them has to request the “Customer Service” for the necessary customer data. [9]
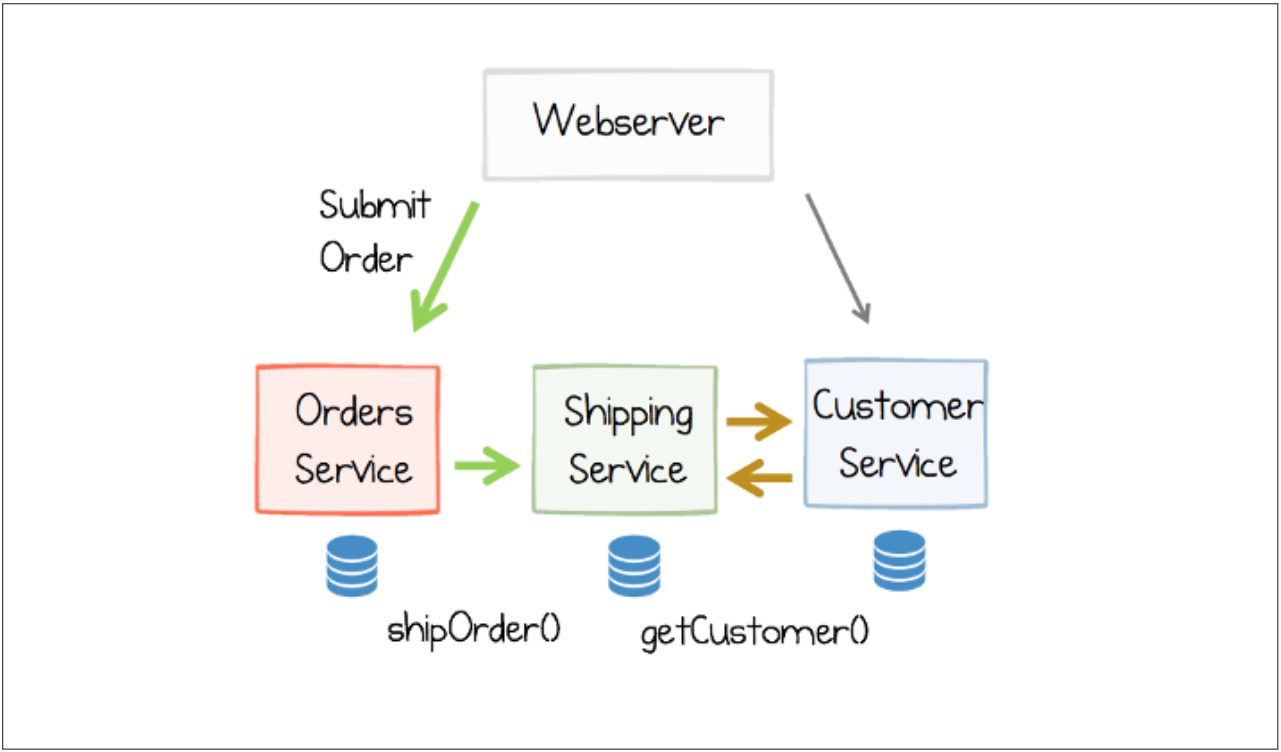
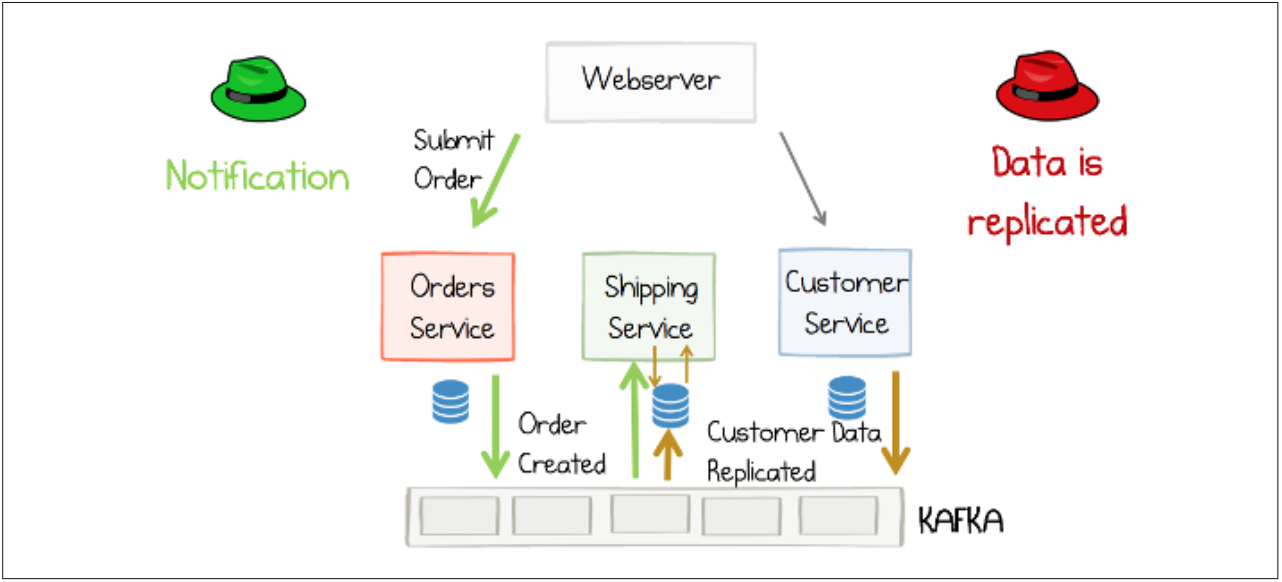
Figure 6 shows the order management using events instead of requests a responses. The user’s order is submitted to the “Orders Service” as well. This service now publishes and event called “Order Created”. In this case the systems broker is a Kafka broker, that broadcasts the event to all the event’s subscribers. In this example one of them is the “Shipping Service”. The for the shipping necessary customer data was received by events published by the “Customer Service”. Due to this the “Shipping Service” has its own replication of the customer data. This is a statefull service. [9]
An advantage of a Request / Response communication would be the call stack. Event-driven systems work, as described by the event collaboration pattern with shared processes. In event-driven systems you should understand the event chain that led to the problem first. With a call stack it is directly visible which service calls which actions. You have to admit that this issue is not that big, if your system is well documented and if you use a log to make the system observable.
Besides this event-driven systems have way more moving parts that may lead to further problems as well. One of them might be changes regarding the business logic that have to be implemented by a multiple services. That’s why debugging is not that simple as well. [4] [9]
Advantages
One of the main advantages is decoupling the producers and the consumers. From producer perspective it is no longer necessary to know who might do something with the data one service will publish. On the other side consumers don’t need to know who published the events they subscribed to. The only thing that matters is what happened in the system and what does it means for a specific service. This results in a shared process. The business logic is no longer implemented into one service that orchestrates other services to execute commands or queries. [5]
Besides this it is possible to achieve a single source of truth, which is the stream of events that is written into the log. This means that truth is no longer shared exclusively between services. In addition to the individual states of the services, there is now also the log as a backup. If the network delays and a service is not available for a moment, it is possible to resynchronise this service when it is online again.
ue to the centralized source of truth it is easier to debug the system too. All information necessary to decide which service might produce wrong data can be read from the event stream persisted by the log. [2] [5] [9]
Another advantage is that several services are able to consume the same data in parallel. That means that they can work parallel too. In a Request / Response system the services will work sequentially.
The services that process the events can be implemented with completely different technologies and use different data encoding as well. Due to the fact that event-driven systems include a broker that transfers the events to the consumers, services can use different encodings. The only requirement is that the broker has to be able to understand and translate all used encodings. [3] [5]
If the services are loosely coupled it is very easy to integrate services as mentioned before. They could be existing services that will be scaled or new ones. Completely new services might consume events that already exist and form them into something new. By consuming the events they do not affect the producer or any other consumer. [3] [5]
Due to the fact that the services in an event-driven system are decoupled they don’t have to worry about the health status of other services. This results in a more resilient system. If one service dies, all other services aren’t affected in the first place. They “just” don’t receive events that would have been published by the dead service. [5]
The services in an event-driven system don’t ask other services for data, they will be informed by the broker if there are new messages available. This way of message delivery is called push-based. Due to this, events will arrive directly at the recipient when they happen and not only when the recipient requests them. With push-based messages there is a reduction in network I/O as well, because services don’t have to poll continuously for new data. [5]
As mentioned, real-time processing is a big advantage. With an event stream it is possible to do analytics “on the fly”. Analyse the stream and do fraud detection, predictive analytics or track security treats are some examples. This enables machine learning and data science processes to be deployed to the production environment as well. The models can be constantly tested and improved that way, which leads to a faster and iterative development.
Besides this it is possible to make time critical decisions through the event stream. It is possible to change business solutions on the fly depending on the event stream. The data necessary to make decisions like that does not have to be persisted first. [5]
In summary you can say: “Using event-driven architectures, it is possible to build a resilient microservice-based architecture that is truly decoupled, giving increased agility and flexibility to the development lifecycle.” [5]
Disadvantages
With all the advantages of event-driven architecture, there are also some disadvantages. The first and most challenging is the delivery guarantee of an event-driven system. The three delivery guarantees are the following:
- At-least-once (duplicated writes)
- At-most-once (missing writes)
- Exactly-once
An example for the at-least-once semantics could be the following. A service pushes an event to the broker and the brokers acknowledgement times out. Due to this the service will retry the publishing, that will lead to a duplicate entry. [8]
The at-most-once semantics would be fulfilled if the service of the previous example would not retry to publish the event. This prevents duplicate entries but could lead to not published events at all. In this example the service doesn’t know if the push was successful or not. [8]
The most challenging delivery guarantee is the exactly-once guarantee. This semantics promises that an event will be delivered to a consumer exactly once. There are no missing events (at-most-once semantics) or duplicate entries (at-least-once semantics). In contrast to the exactly-once guarantee is the order of events. Due to retries, it can happen that the exact order is no longer observed. Therefore, you have to choose one of the two. [3] [8]
Another more general disadvantage is the system state. Due to the continuous evolution it is challenging to determine the actual system state. [4]
Furthermore it is not that easy to validate a service during the build-time. This could lead to problems. An example for this is an easy typo in an event name. Until the system is restarted and no events are received, no one will notice the error. Mike Fowler describes it as the architect’s dream but the developer’s nightmare. [4]
Transactions
This last chapter will once again deal with transactions. In Request / Response architectures it’s totally normal to work with transactions to guarantee consistence. As previously shown, event-driven systems are not built for services to communicate with each other beyond broadcasting events. This includes requests and responses that results in no direct transactions between services. Besides this the producers does not know who might process their published events.
This is why the aforementioned exactly-once guarantee is so important in event-driven systems if you want to get in the direction of transactions. The exactly-once semantics is only achievable if the services and the broker work together. [8]
To give an example of an exactly-once semantics, the following is a rough description of how exactly-once deliveries work in Apache Kafka.
The first problem is duplicated writing. In order to solve this problem you have to implement your producer to be idempotent.
o prohibit reprocessing of events, Kafka uses the read-process-write cycle. The cycle is atomic if the event is marked as consumed at the same moment as the result of the consumption is published.
Furthermore so called zombie instances can lead to problems as well. One of them is that more that one service might process the input. Therefore Kafka uses a combination of unique producer ids and epochs. The producer’s id enables to identify the same producer across process startups. The epoch variable will be increased by the producer by initializing a new transaction at the broker. If a zombie instance tries to publish events for an outdated epoch the broker can filter these events. [7]
The broker has to guarantee that the events will be written to the log once. Therefore Kafka uses a similar approach as TCP. Each batch of events that will be sent to the broker in a transaction will contain a sequence number. This sequence number will be stored together with the event to the log. Duplicated messages can be removed that way. [8]
In order for a consumer to be able to process transactional messages, a number of requirements must be met. The first one includes the publishing of all events included in the transaction have to be completed. After this a consumer can process the events but they don’t have to process all events included in the transaction. In addition, events included in a transaction that has not yet been completed or that have been canceled will not be processed. Another requirement is the atomic read-process-write cycle, which has already been described. [7]
Conclusion
Event-driven systems have great potential. There are a lot of advantages by using such a system. Especially the loose coupling of services stands out, which shows many advantages compared to Request / Response architectures.
In addition to all the benefits, it is important to realize what this means for system design. At its core, it is a completely different way of thinking. This also comes into play when considering transactions in event-driven systems. At this point, it becomes clear how important the broker and its functionalities are for the entire system.
Author: Max Merz — merzmax.de, @MrMaxMerz
References
[1] IBM cloud architecture center – Event-driven architecture: Overview – https://www.ibm.com/cloud/architecture/architectures/ eventDrivenArchitecture/
[2] Peter Bates – Debugging heterogeneous distributed systems using event-based models of behavior – https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.577.3640&rep=rep1&type=pdf
[3] doodlemania2, Udi Dahan, Dahanshri Kshirsagar, Adam Boeglin, Dan Vanderboom, Alex Buck, Marc Wilson, Jason Roberts and Christipher Bennage – Event-driven architecture style – https://docs.microsoft.com/en-us/azure/ architecture/guide/architecture-styles/event-driven
[4] Gregor Hohpe – Programming without a call stack – event-driven architectures – https://www.enterpriseintegrationpatterns.com/docs/EDA.pdf
[5] Grace Jansen and Johanna Saladas – Event-driven architectures: What are they and why use them? – https://developer.ibm.com/technologies/messaging/articles/advantages-of-an-event-driven-architecture/
[6] Mickael Maison – An introduction to event sourcing – https://developer.ibm.com/technologies/messaging/ articles/event-sourcing-introduction/
[7] Apruva Mehta and Jason Gustafson – Transactions in apache kafka – https://www.confluent.io/blog/transactions- apache-kafka/
[8] Neha Narkhede – Exactly-once semantics is possible: Here’s how apache kafka does it – https://www.confluent.io/blog/ exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
[9] Ben Stopford and Sam Newman – Designing event-driven systems – https://assets.confluent.io/m/7a91acf41502a75e/original/20180328-EB-Confluent_Designing_Event_Driven_Systems.pdf
Leave a Reply
You must be logged in to post a comment.