Einleitung
Hast du beim Lernen auch schon einmal gelangweilt aus dem Fenster geschaut und die vorbeifahrenden Autos gezählt? Auf wie viele Autos bist du dabei genau gekommen und war diese Zahl vielleicht auch vom Wochentag oder der Uhrzeit abhängig?
In unserem Projekt haben wir versucht diese Frage zu beantworten.
Dafür haben wir mittels Maschinellem Lernen, auch als “Machine Learning” bezeichnet, ein Neuronales Netz trainiert, welches bei einer Videoaufzeichnung einer Kreuzung verschiedene Verkehrsteilnehmer erkennen kann.
Unser Ziel war es, durch eine Zählung bestimmen zu können, wie viele und welche Art von Fahrzeugen die Kreuzung in einem bestimmten Zeitraum passieren.
Problemstellung
Wie viele Autos passieren eine Kreuzung? Handelt es sich hauptsächlich um Autos oder gibt es auch andere Fahrzeuge, die die Kreuzung passieren und wie hoch ist die dadurch resultierende potentielle Lärmbelastung? Um all diese Fragen klären zu können, wäre es von Vorteil, wenn man wüsste, wie viele Fahrzeuge an der ausgesuchten Teilstrecke vorbeifahren. Wir haben probiert, genau das, nur mit Hilfe von Videos, herauszufinden.
Lösungsansatz
Wir entschieden uns, ein vortrainiertes Neuronales Netz auf Basis der YOLO-Architektur anzupassen und mit unseren Daten weiter zu trainieren. YOLO ist ein Echtzeit-Objekterkennungssystem, welches ein einzelnes Neuronales Netz auf ein komplettes Bild anwendet [1].
Vorverarbeitung der Bilder bzw. Videos
Nacht-Videos aussortieren und verteilen
Um das Projekt durchführen zu können, hatten wir einige Videoaufnahmen einer Kreuzung von Herrn Prof. Kriha erhalten. Die Aufnahmen zeigen eine Kreuzung, wie in Abbildung 1 zu sehen, welche zu unterschiedlichen Uhrzeiten gefilmt wurde. Wir entschieden uns, das Netz erst einmal mit Aufnahmen bei Tag zu trainieren, da die Fahrzeuge auf diesen Aufnahmen deutlicher zu erkennen sind und damit besser zuordenbar. Aus diesem Grund sortierten wir alle Nachtaufnahmen aus und verteilten die restlichen Videos auf alle Teilnehmer der Projektarbeit, um den Aufwand für das spätere Labeln der Bilder untereinander aufzuteilen.

Bilder aus Videos extrahieren
Da man das Neuronale Netz nicht mit Videoaufnahmen trainieren kann, mussten wir aus den Videos zunächst einzelne Bilder generieren. Dazu erstellten wir über 500 Screenshots, welche die verschiedenen Fahrzeuge an unterschiedlichen Positionen zeigen.
Labeln der Bilder
Um das Netz trainieren zu können, muss man die Bilder zunächst labeln. Hierfür verwendeten wir die Software “VGG Image Annotator” [2]. Direkt zu Beginn des Projektes einigten wir uns auf alle Fahrzeugtypen, die unser Netz erkennen sollte. Hierzu gehören:
- PKW
- LKW
- Traktor
- Motorrad
- Fahrrad
- Sonstiges (z. B. E-Scooter, Inlineskater)
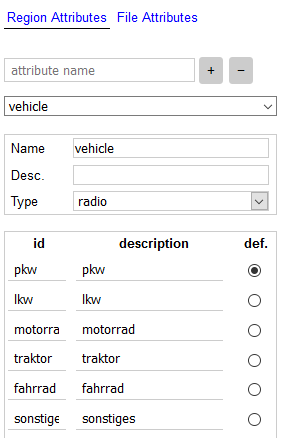
In der Software kann man verschiedene Labels anlegen, welche nach den Fahrzeugkategorien benannt sind. In Abbildung 2 sieht man, wie die verschiedenen IDs, also die Label-Kategorien, angelegt werden. Ein Objekt kann man kennzeichnen, indem man mit Hilfe der Software ein Rechteck auf das Objekt legt und die jeweilige Bezeichnung – durch Klicken auf den passenden Radiobutton – angibt. Die Positionen der Rechtecke werden dann zusätzlich zu den Bildern als CSV abgespeichert und können so später fürs Training verwendet werden.
Augmentation
Da es nicht möglich ist, für jedes Szenario in der realen Welt ein Bild zu kreieren, mit dem man später trainieren kann, behalfen wir uns hier der Bild-Augmentation, um den aktuellen Trainingssatz zu diversifizieren. Dabei werden alle Bilder auf eine quadratische Größe von 512 x 512 Pixel skaliert und der Kontrast normalisiert. Im Anschluss gibt es eine 50 prozentige Chance, dass ein Bild horizontal und/ oder vertikal gespiegelt wird. Bei diesen Arten der Augmentation muss man aufpassen, dass die Label-Rechtecke korrekt mit skaliert und -rotiert werden. In Abbildung 3 sieht man ein Beispiel eines augmentierten Bildes.

Der Datensatz wurde anschließend in einen Trainingssatz und einen Testsatz aufgespalten. Wie der Name bereits impliziert, wird der Trainingssatz lediglich zum Trainieren des Netzes verwendet. Den Testsatz bekommt das Netz während des Trainings nie zu sehen. Erst am Ende wird dieser zur Verifizierung und Bewertung der Ergebnisse verwendet.
Neuronales Netz
Ein Neuronales Netz ist ein Verbund von Neuronen, dessen Parameter durch Training angepasst werden. Übliche Trainingsziele sind die Klassifikation, Replikation oder allgemein die Abstraktion der Eingangsdaten. Besonders die Klassifikation spielt in unserem Fall der Objekterkennung eine besondere Rolle.
Architektur
Bei der Entscheidung, welche Netzarchitektur wir für unser Projekt verwenden wollten, gab es die Auswahl zwischen dem Region Based Convolutional Neural Network (R-CNN) und dem “You Only Look Once” Netz (YOLO). Ein R-CNN durchläuft ein Bild zweimal. Im ersten Durchlauf schlägt es “Regions of Interest” vor, welche im zweiten Durchlauf verfeinert und klassifiziert werden. YOLO geht einen völlig anderen Weg und schaut nur ein einziges Mal auf ein Bild. Dabei wird das Bild in Zellen unterteilt welche anschließend sogenannte Bounding Boxes vorhersagen, die ein Objekt umschließen sollen. Auch wird die “confidence” angeben, die zeigt, wie sicher das Netz ist, wirklich ein Objekt umschlossen zu haben. Parallel dazu erstellt jede Zelle eine Klassifikation. In unserem Fall wäre es die Unterscheidung, ob es ein PKW, LKW oder ein anderes Fahrzeug ist. Im letzten Schritt werden beide Ergebnisse miteinander vereinigt und es entsteht die finale Vorhersage (siehe Abbildung 4).
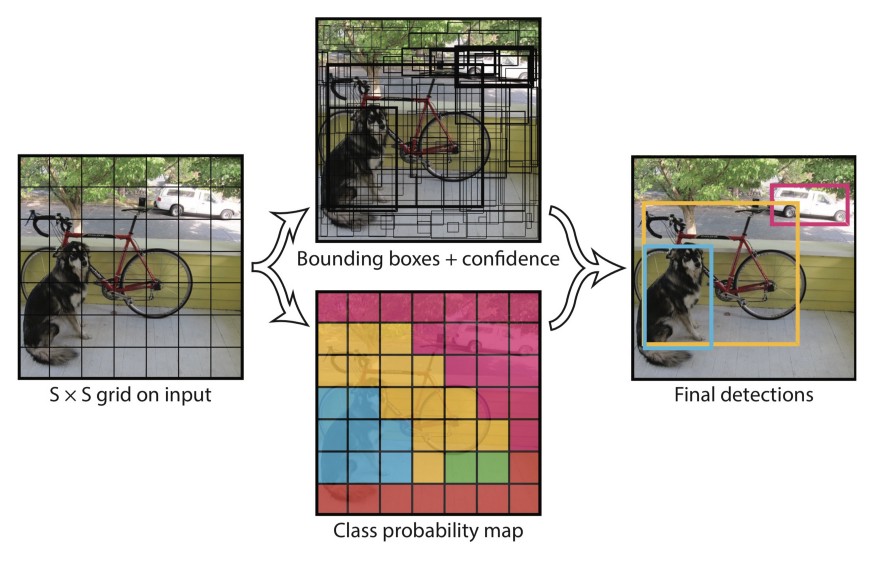
Wir haben uns für die YOLO Architektur entschieden, weil sie im Vergleich zum R-CNN schneller arbeitet, auch wenn sie nicht so präzise ist. Das zu analysierende Material sind Videos mit 25 Bildern pro Sekunde und wenn man es in Echtzeit verarbeiten wollte, ist die Geschwindigkeit wichtiger als die Genauigkeit.
Um nicht komplett von Null anzufangen, übernahmen wir eine YOLOV2-Implementierung mit bereits trainierten Gewichten basierend auf dem COCO Datensatz. Die letzte Schicht des Netzes wurde dann mit unseren eigenen Trainingsbildern trainiert.
Training
Das verwendete Netz, basierend auf der YOLO Architektur [4], wird überwacht trainiert. Während des Trainings erzeugt es für jede Bildeingabe eine Ausgabe pro erkanntem Objekt, welche aus den vier Koordinaten der Bounding Box und einem Label, das angibt, um was für ein Vehikel es sich handelt, besteht. Diese Ausgabe wird nun mit den zuvor gelabelten Rechtecken des Eingabebildes verglichen und ein Loss-Wert errechnet. Mittels Backpropagation werden der Gradient von jedem Neuron neu berechnet und die Gewichte angepasst. Nach jeder Wiederholung des Prozesses mit denselben Eingabebildern, sollte sich die Ausgabe den wahren Werten immer weiter annähern. Das Netz lernt.
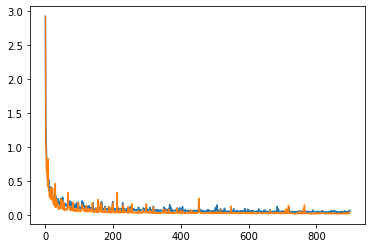
In Abbildung 5 ist ein Trainingsvorgang veranschaulicht. Die Y-Achse zeigt den Loss-Wert an, die X-Achse die Epochen. Eine Epoche ist ein gesamter Durchlauf mit allen Trainingsbildern. Der orange Graph zeigt den Loss-Wert der Testbilder mit den zum Zeitpunkt x errechneten Gewichten des Netzes an, während der blaue Graph für den Loss-Wert auf den Trainingsbildern steht. Man kann erkennen, dass der Loss in den ersten Epochen sehr schnell abnimmt und sich ab der 200. Epoche kaum noch verbessert.
Dem fertig trainierten Netz übergaben wir einige Testbilder, um zu sehen, ob es vernünftige Ausgaben liefern konnte. Wie in den Abbildungen 6 bis 9 zu sehen ist, kann das Netz verschiedene Vehikel erkennen und auch die Klasse richtig einordnen. Des Weiteren ist es in der Lage, verdeckte Objekte wie die Autos in Abbildung 7 und 8, welche teilweise von Pflanzen verdeckt werden, zu identifizieren.

Abbildung 6 
Abbildung 7 
Abbildung 8 
Abbildung 9
Es bleibt noch anzumerken, dass die Ausgabe der Rechtecke nicht ganz unseren Erwartungen entsprach. Zwar wurden die Vehikel mit großer Wahrscheinlichkeit erkannt und korrekt zugeordnet, jedoch waren die Bounding Boxen zu groß und entsprachen nicht unseren gelabelten Trainingsbildern. Dennoch konnten wir mit den Ergebnissen weiterarbeiten, weil nur der Mittelpunkt der Rechtecke für die Zählung wichtig ist. Diesen Mittelpunkt kann man aus den Eckpunkten des Rechtecks berechnen, dabei spielte es keine Rolle wie groß die Dimensionen sind.
Zählung der Fahrzeuge
Bevor wir beginnen konnten die vorbeifahrenden Fahrzeuge zu zählen, mussten wir in der Lage sein, ein bestimmtes Fahrzeug während des Vorbeifahrens zu tracken. Das ist nötig, da das neuronale Netz eigentlich keine Videos direkt verarbeiten kann. Stattdessen wird das Video in die einzelnen Bilder zerlegt und Bild für Bild verarbeitet. In einem ersten Schritt haben wir dabei jeweils die vorher erwähnten Mittelpunkte eines jeden erkannten Fahrzeugs in passender Farbe, je nachdem welcher Typ erkannt wurde, in jedes einzelne Bild gezeichnet und anschließend wieder zu einem Video zusammengesetzt. Das Ergebnis zeigt, dass das Netz in der Lage ist, ein Fahrzeug zu “verfolgen” wie in Video 1 zu sehen.
Um ein vorbeifahrende Auto als nur ein einziges Fahrzeug zu werten und zu zählen, verglichen wir die Mittelpunkte der erkannten Fahrzeuge zwischen zwei nachfolgenden Bildern eines Videos und ordneten diese, wenn möglich, einem bereits im ersten Bild erkannten Fahrzeug zu. Hierfür verwendeten wir einen Centroid (z. Dt. Schwerpunkt, hier der Mittelpunkt der erkannten Fahrzeuge) Tracking-Algorithmus [5]. Dieser ordnet Fahrzeuge auf einem neuen Bild zu bereits erkanntem Fahrzeugen zu oder registriert sie als neue Fahrzeuge. Dieser merkt auch, wenn Fahrzeuge wieder verschwunden sind und löscht diese aus den als “aktuell im Bild befindlich” registrierten Fahrzeugen.
Nachdem wir in der Lage waren, ein vorbeifahrendes Fahrzeug über den Zeitraum, in dem es im Video auftaucht, als ein einziges Fahrzeug zu werten, musste als nächstes festgelegt werden, wann wir ein Fahrzeug zählen. Zwar konnten wir Fahrzeuge relativ genau zuordnen, würde man jedoch einfach die Zahl aller einzigartig erkannten Fahrzeuge betrachten, so wäre die Zahl viel zu hoch. Das liegt daran, dass Fahrzeuge am Rand der Bilder teils nicht so gut erkannt werden oder z. B. lang genug von einem anderen verdeckt sind und anschließend als neues Fahrzeug registriert werden. Das lässt sich nicht wirklich verhindern. Auch werden bei großen Fahrzeugen manchmal fälschlicherweise zusätzlich Fahrzeuge erkannt (siehe Abbildung 10). So wird, auch wenn ein zusätzliches Fahrzeug nur in einem einzelnen Bild erkannt wurde, die Zahl der insgesamt erkannten Fahrzeuge hochgetrieben.

Es ergibt also Sinn, an einer Stelle zu zählen, an der alles gut sichtbar ist und das Netz sehr genau Fahrzeuge erkennt, damit diese möglichst genau gezählt werden. Dafür haben wir relativ mittig im Bild einen runden Bereich definiert, den die Fahrzeuge durchqueren müssen, um gezählt zu werden, siehe Abbildung 11.

Jedes erkannte Fahrzeug bekommt in unserem Tracking-Algorithmus dabei eine Variable, die den Status des Fahrzeug angibt. Dabei wird unterschieden zwischen “ist nicht im Kreis”, “ist im Kreis” und “war im Kreis”. Nach jedem Update, also nach jedem verarbeiteten Bild, wird für jedes in diesem Moment erkannte Fahrzeug überprüft, ob es sich im Kreis befindet und der Status entsprechend angepasst. Wechselt dieser dabei von “ist im Kreis” zu “war im Kreis”, dann wird das Fahrzeug gezählt, also beim Verlassen des Kreises. Um sicherzustellen, dass alle Fahrzeuge auch “durch den Kreis” fahren, liegt dieser zwangsweise an einer Stelle an, bei der Fahrzeuge von Pflanzen verdeckt werden können. Dies hat zur Folge, dass manche Fahrzeuge bereits nicht mehr erkannt werden, obwohl sie den Kreis noch nicht verlassen haben und folglich nie gezählt werden. Daraus folgte die Entscheidung, auch Fahrzeuge zu zählen, die verschwinden, während sie sich im Kreis befinden. Das führt dazu, dass im Schnitt zu viele Fahrzeuge erkannt werden, siehe Video 2. Allerdings ist in unseren Tests die Anzahl der gezählten Fahrzeuge dadurch sehr viel näher an der tatsächlichen Anzahl der vorbeifahrenden Fahrzeuge.
Sobald ein Fahrzeug gezählt wird, werden Informationen wie der genaue Zeitpunkt und die Art des Fahrzeugs in eine Liste geschrieben und zur Weiterverarbeitung als CSV-Datei gespeichert. Zur Veranschaulichung haben wir auch die Counter der verschiedenen Fahrzeuge mit in das Video eingefügt, siehe Video 3.
Ergebnis
Wir konnten die Ziele, welche wir uns am Anfang gesetzt haben, erfolgreich umsetzen. Das Netz ist in der Lage, verschiedene Verkehrsteilnehmer zu erkennen und zu kategorisieren. Zusätzlich wäre es performant genug, die Erkennung und Zählung in Echtzeit durchzuführen.
Die Klassifizierung der Fahrzeuge hat zwar generell funktioniert, aber wäre durch mehr gelabelte Bildern von nicht-PKWs vermutlich sehr viel besser gewesen. Eine weitere Sache, die sich im Nachhinein als suboptimal herausstellte, ist, dass wir bei Landwirtschaftsfahrzeugen jeweils nur das Zugfahrzeug labelten. Das führte dazu, dass das Netz Probleme hatte, Anhänger zu erkennen und oft zusätzlich mehrfach LKWs erkannte, siehe Abbildung 10.
Die Zählung wäre abgesehen von teils fehlerhafter Klassifizierung und dem Erkennen zusätzlicher nicht vorhandener Fahrzeuge, einfacher und potenziell genauer gewesen, wäre die Kreuzung aus einem anderen Winkel gefilmt worden. Der Umstand, dass ein für die Zählung relevanter Bildteil direkt an eine “Bildkante”, an der Fahrzeuge verschwinden, angrenzt, erschwert die genaue Zählung immens. Wenn Teile einer Pflanze im Kreis hingen, führte das oft dazu, dass ein Fahrzeug nicht mehr erkannt wurde, während es verdeckt war, dann aber erneut erkannt und anschließend aufgrund unsere Entscheidung im Bild, verschwindende Fahrzeuge zu werten, doppelt gezählt wurde.
Wie lässt sich das Projekt fortführen?
Nach dem Abschluss des Projektes gibt es noch eine Vielzahl an Möglichkeiten, das Projekt weiterzuführen. Zum einen kann man den gesamten Video-Datensatz des Netzes bearbeiten lassen, danach durchgehen und anschließend statistisch auswerten.
Es wäre auch möglich, das Netz mit dem Videomaterial einer anderen Straße zu trainieren. Oder unseren Datensatz mit nicht-PKWs zu erweitern und bspw. die nicht optimal gelabelten Traktoren zu ersetzen. Ein anderer Ansatz wäre, alle Fahrzeuge mit dem gleichen Label zu versehen und damit das Netz zu trainieren. Anschließend könnte man bewerten, wie sich das Ergebnis verändert.
Neben der YOLO-Architektur gibt es auch noch die Single Shot Detector-Architektur, welche eine ähnlich Performance bietet. Es wäre interessant herauszufinden, was für diese Problemstellung besser ist, sei es in Sachen Geschwindigkeit oder Präzision.
Referenzen
[1] https://deepdataocean.ai/de/deep-learning/yolo
[2] https://annotate.officialstatistics.org/
[3] https://towardsdatascience.com/yolo-you-only-look-once-real-time-object-detection-explained-492dc9230006
[4] https://github.com/jmpap/YOLOV2-Tensorflow-2.0
[5] https://www.pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/
Danke an alle Teammitglieder
- Niklas Henrich
- Florian Huynh
- Lukas Joraschek
- Anke Müller
- Leah Fuchs
Leave a Reply
You must be logged in to post a comment.