Heutzutage erzeugen die meisten Systeme und Anwendungen Logging-Daten die für Sicherheits- und Überwachungszwecke nützlich sind, z. B. für die Fehlersuche bei Programmierfehlern, die Überprüfung des Systemstatus und die Erkennung von Konfigurationsproblemen oder sogar Angriffen. Treten Ereignisse innerhalb einer Anwendung auf, werden diese von integrierten Protokollierungsfunktionen erfasst und mit zusätzlichen Metadaten aufgezeichnet. Mit dem Wachstum von Microservice-Anwendungen ist die Protokollierung für die Überwachung und Fehlerbehebung dieser Systeme wichtiger als je zuvor.
Besitzt man beispielsweise nur einen kleinen Webserver, ist es evtl. noch möglich die erzeugten Logs täglich zu kontrollieren. Nur wie sieht es aus wenn mitten in der Nacht etwas passiert? Oder beim Betrieb eines großen verteilten Systems? Wie können diese Daten zentral gesammelt und sinnvoll genutzt werden? Hier kommen Log-Aggregation-Systeme ins Spiel, welche bei den Anforderungen an die Beobachtbarkeit und den Betrieb jedes großen, verteilten Systems unterstützen.
In diesem Blogpost möchte ich auf den relativ neuen und immer populärer werdenden Logging-Stack Grafana Loki eingehen. Wie ist es aufgebaut? Wo sind die Unterschiede zu beispielsweise ELK (Elasticsearch, Logstash und Kibana). Was macht es so besonders und warum ist es für große Firmen wie Red Hat interessant, welche in ihrer neuesten Version OpenShift 4.10 Grafana Loki Support anbieten werden?
Die Idee der Log-Aggregation ist nicht neu, es gibt viele SaaS-Anbieter und Open-Source-Projekte, die zueinander in Konkurrenz stehen. Bei der Log-Aggregation handelt es sich um eine Softwarefunktion, die Log-Daten aus der gesamten IT-Infrastruktur in einer einzigen zentralen Plattform zusammenführt, wo sie überprüft und analysiert werden können. Fast alle bestehenden Lösungen können zusätzliche Funktionen unterstützen, z. B. Datennormalisierung, Log-Suche und komplexe Datenanalyse.
Grafana Loki ist eine Kombination aus mehreren Komponenten, die zu einem vollwertigen Logging-Stack zusammengestellt werden können. Das Loki-Projekt wurde 2018 bei Grafana Labs gestartet. Es wurde in Golang geschrieben und ist eine Open Source Software, welche unter der AGPLv3-Lizenz veröffentlicht wurde. Loki ist ein horizontal skalierbares, hochverfügbares, mandantenfähiges Log-Aggregation System nach dem Vorbild von Prometheus. Es entstand aus der Motivation heraus, die drei Komponenten der Observability (Beobachtbarkeit) Metriken, Logs und Tracing so einfach wie möglich in einem Dashboard zu vereinen, um eine schnelle und unkomplizierte Fehlerermittlung zu ermöglichen. Damit ein nahtloser Wechsel zwischen den Komponenten stattfinden kann, werden die gesammelten Events mit denselben Metadaten wie bei den Prometheus-Daten versehen. Hierunter fallen zum Beispiel Namespace, Servicename und Instanz-IP. [1]
Spricht man von Grafana, so ist in der Regel eine Dashboarding-Lösung für time-series Daten gemeint. Grafana unterstützt über 40 Datenquellen. Im Kontext Monitoring und Logging ist es als Dashboard Lösung für Prometheus Daten bekannt. [2]
Prometheus ist eine Open Source Monitoring- und Alerting-Lösung. Es zeichnet Echtzeitmetriken in einer Zeitreihendatenbank auf, welche in Grafana visualisiert werden können. [3]
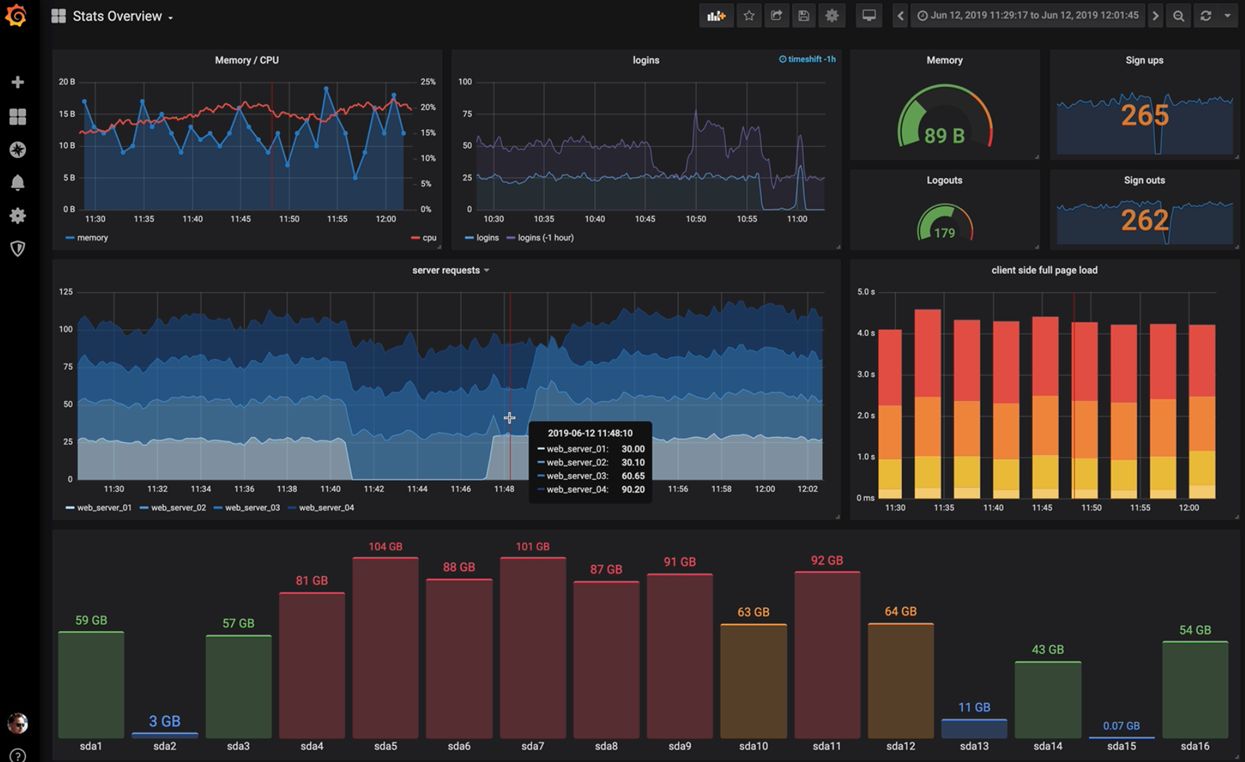
Funktionsweise
Indexierung
Loki verfolgt bei der Speicherung der Logdaten einen Ansatz, bei dem nur ein kleiner Teil der Metadaten jeder Logline indiziert werden. Eine Speicherung derselben Logdaten in Loki benötigt weit weniger Speicherplatz, als dies beispielsweise bei Elasticsearch, welcher im ELK-Stack zum Einsatz kommt, der Fall wäre.
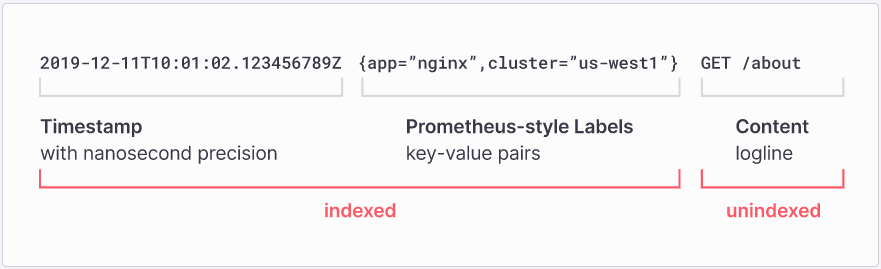
Anhand des folgenden Log-Ausschnittes erfolgt ein direkter Vergleich zwischen Elasticsearch und Loki, welcher den Unterschied der beiden Indizierungsansätze verdeutlicht.
10.185.248.71 - - [09/Jan/2015:19:12:06 +0000] 808840 "GET /inventoryService/purchaseItem?userId=20253471&itemId=23434300 HTTP/1.1" 500 17 "-" "Apache-HttpClient/4.2.6 (java 1.5)"Elasticsearch
Elasticsearch analysiert den gesamten String, einschließlich der Felder mit hoher Kardinalität wie itemID oder userID, und speichert alle Werte in einem großen Index.
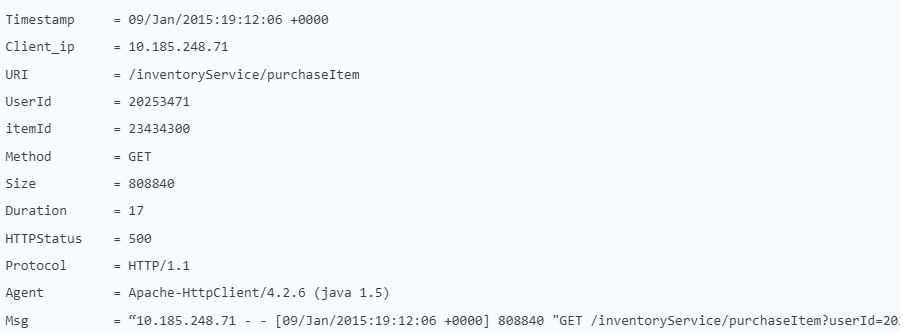
Dies führt oft dazu, dass der Index meist größer ist als die eigentlichen Logdaten. Der Ursprung hiervon liegt in der Architektur von Elasticsearch. Es baut auf dem Lucene-Suchmaschinenprojekt auf, welches für Szenarien mit geringem Schreib-/Leseaufwand konzipiert ist. Hierbei dauert das Schreiben länger, was jedoch das lesen und suchen vereinfacht und verschnellert. Bei Logs ist jedoch meist das Gegenteil der Fall. Hier wird viel geschrieben jedoch nur selten gelesen. [6]
Grafana Loki
Beispiel dafür, wie Loki typischerweise die Logzeile indiziert:
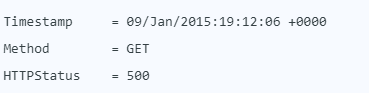
Loki indiziert nur einige wenige Felder, sodass der Index sehr klein ist. Die erzeugten Logs können mittels Filter wie Zeitspanne und indizierten Feldern (Labels), sowie durch den Einsatz von Teil-String-Suche oder regulären Ausdrücken, abgefragt werden.
[5],[6]
Log-Kollektoren
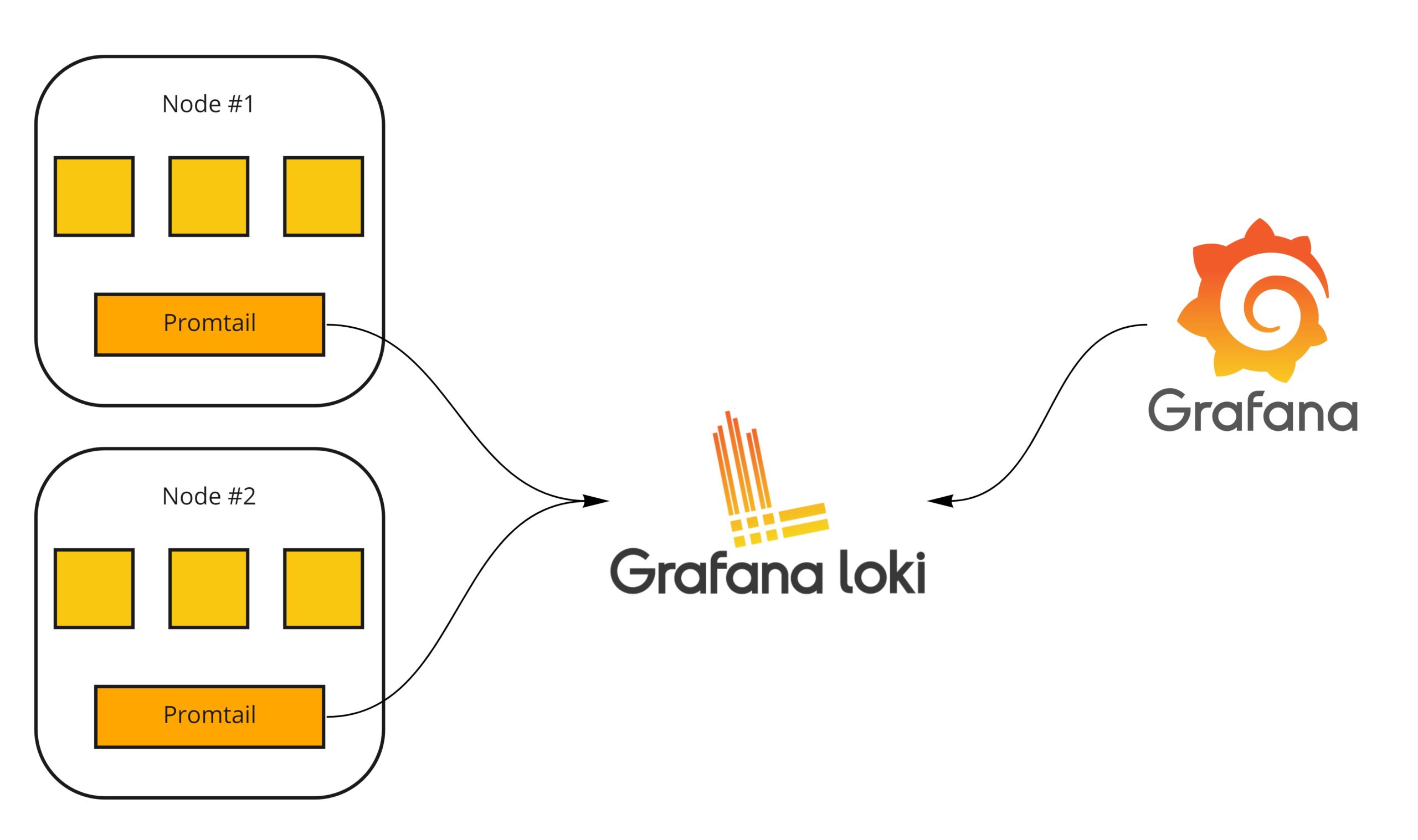
Promtail ist ein Log-Kollektor, welcher speziell für Loki entwickelt wurde. Dieser ist in Golang geschrieben und wird typischerweise als Daemonset in einem Kubernetscluster ausgerollt. Promtail ist jedoch nicht ausschließlich für Kubernetes-Nodes. Es kann ebenfalls auf einer lokalen Maschine ausgerollt werden. Installatiospakete werden auf der Grafana Loki Github-Seite angeboten.
Damit Promtail Logdaten an Loki senden kann, benötigt es Informationen über seine Umgebung. Zur zur leichteren Identifizierung von Services können ebenfalls Labels mitgegeben werden. Sie werden an die Log-Zeilen angehängt. [7]
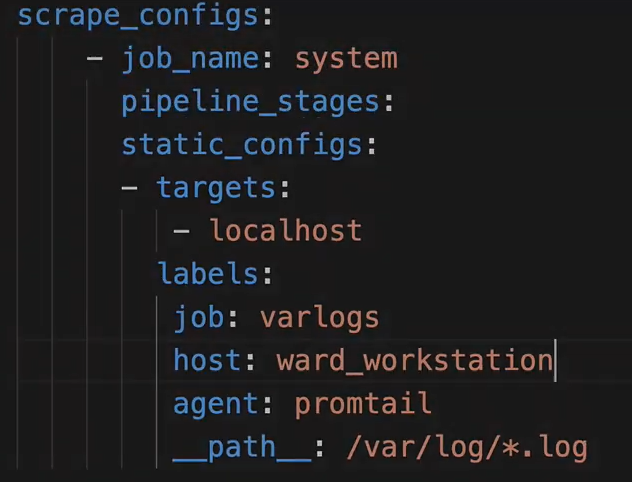
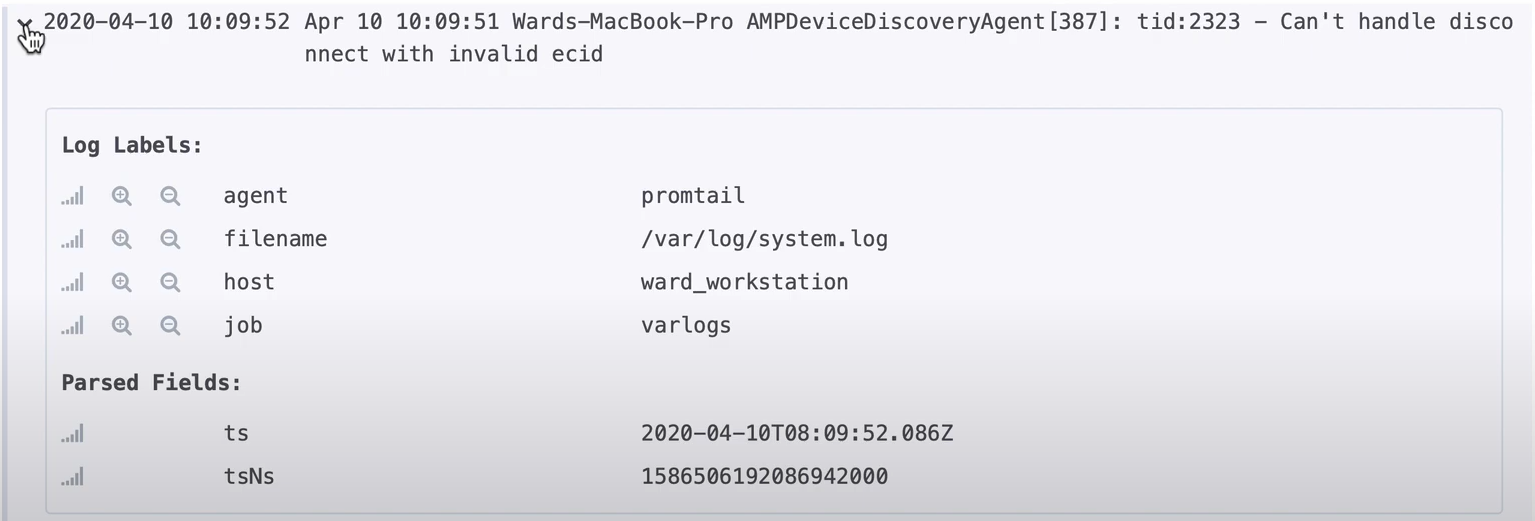
Neben Promtail können auch andere Tools wie Logstash (verwendet im ELK-Stack) verwendet werden. Promtail sendet Logs in Batches an Loki.
Komponenten
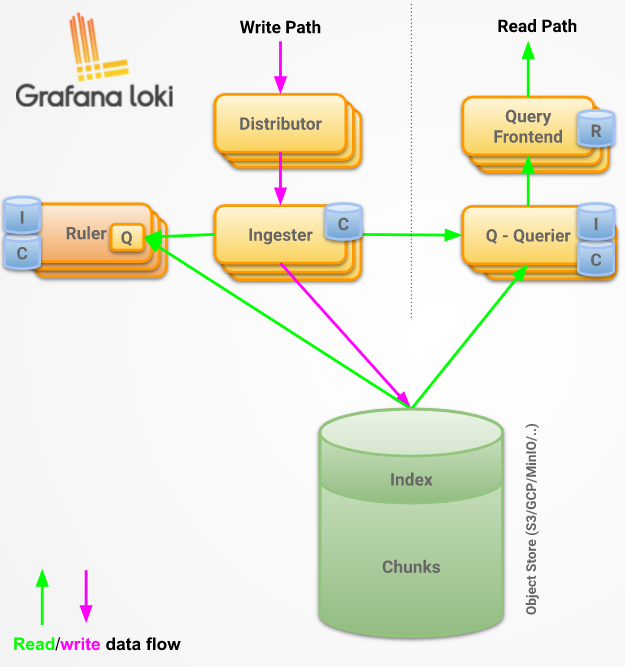
Wie bereits erwähnt, besteht die Loki Anwendung aus mehreren Komponenten-Microservices. Dem Distributor, sowie dem Ingestor, dem Ruler, Querier und Query-Frontend.
Distributor
Der Distributor ist für die Verarbeitung eingehender Streams der Log-Kollektoren verantwortlich. Ein Stream ist eine Sammlung von Logs die einem Mandanten und eindeutigen Labels zuordenbar sind. Die Distributoren von Loki verwenden Consistent Hashing in Verbindung mit einem Replikationsfaktor, um zu bestimmen, welche Instanz des Ingestor-Service den Stream erhalten soll. Ein Stream wird dazu mit der Mandanten-ID, sowie dem Labelset gehasht. Um Consistent Hashing zu erreichen, wird ein Hash-Ring verwendet. Dabei registriert sich jeder Ingestor mit einer Reihe von Tokens und ihrem jeweiligen Status im Ring. Ingestoren mit dem Status JOINING und ACTIVE können Schreibanforderungen empfangen. Ein Ingestor mit dem Status ACTIVE und LEAVING empfängt Leseanforderungen. Bei einer Hash-Suche (Lesende oder Schreibende Anfragen) werden nur die Ingestor beachtet, die sich im richtigen Status befinden.
Um die Hash-Suche durchzuführen, finden Distributoren den kleinsten geeigneten Token, dessen Wert größer ist als der Hash des Streams. Wenn der Replikationsfaktor größer als eins ist, wird der gehashte Stream dem nächstfolgenden Token (Ingestor) im Uhrzeigersinn zugeordnet. [9]
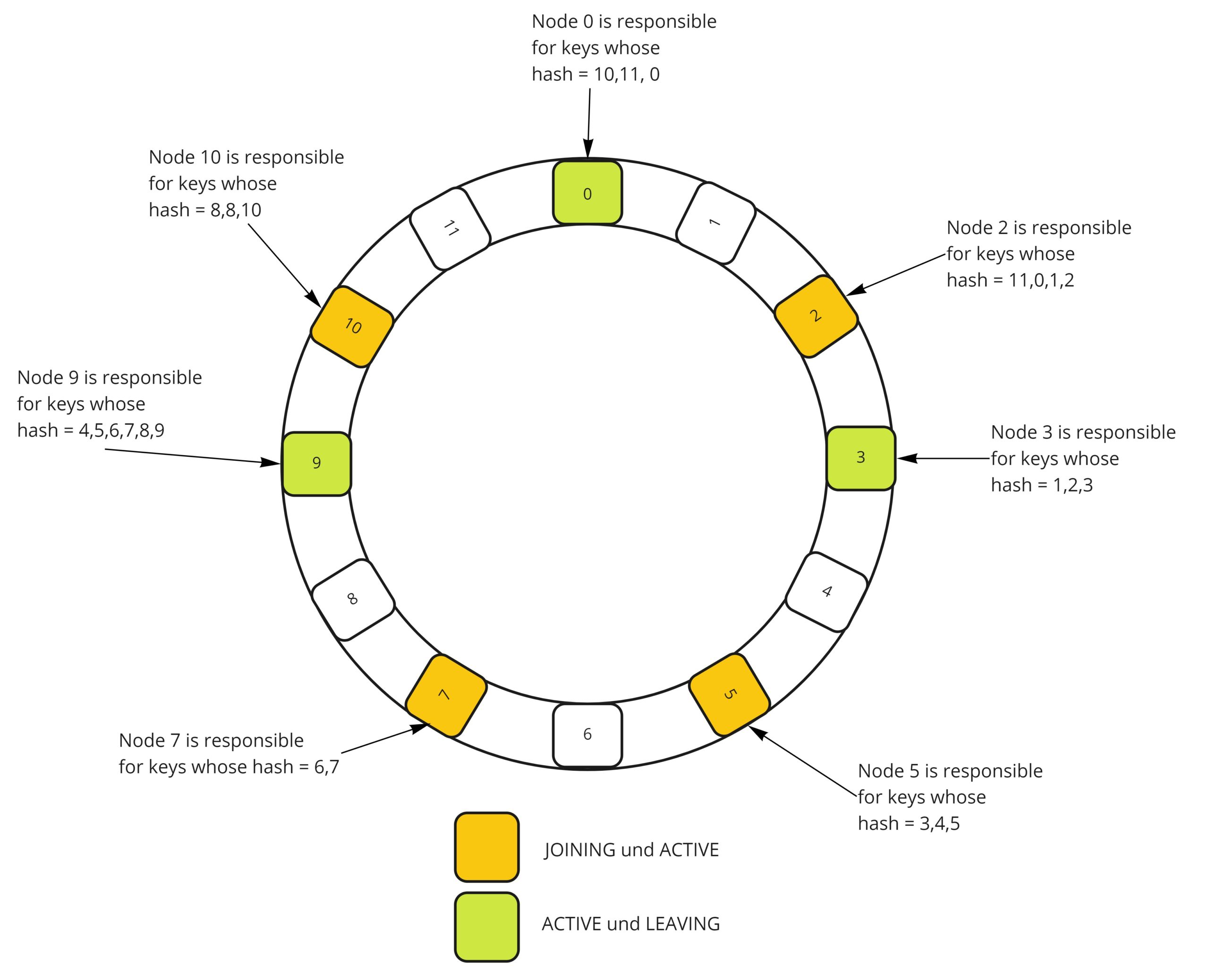
Ingestor
Der Ingestor ist verantwortlich für das Speichern von Logdaten. Diese werden bei Loki in ein einziges Objektspeicher-Backend, wie DynamoDB, S3, Cassandra oder ähnliche, geschrieben. Hierzu werden die eintreffenden Streams im Arbeitsspeicher in Chunks (Blöcke) unterteilt und in einem konfigurierbaren Intervall an das Speicher-Backend gesendet.
Sobald ein Ingestor ausgerollt wurde, kann er unterschiedliche Zustände einnehmen. Diese können PENDING, JOINING, ACTIVE, LEAVING oder UNHEALTHY sein. Die ausführlicherere Erläuterung der jeweiligen Status sind in der zugehörigen Dokumentation festgehalten.
Stürzt ein Ingestor ab oder wird abrupt beendet, können alle noch nicht gespeicherten Chunks im Arbeitsspeicher verloren gehen. Loki verwendet hierzu das Write Ahead Log Prinzip (WAL) um nach einem Neustart die Persistenz bestätigter Daten zu gewährleisten.
Hierzu werden eingehende Daten aufgezeichnet und im lokalen Dateisystem gespeichert. Beim Neustart werden die Daten aus dem Protokoll neu eingespielt, bevor sich der Ingestor selbst als bereit für nachfolgende Schreibvorgänge registriert. Beim Herunterfahren oder beim Verlassen des Hash-Rings wartet ein Ingestor standardmäßig darauf, ob ein neuer Ingestor seine Aufgaben übernimmt. Ist dies nicht der Fall, werden die noch nicht gespeicherten Logs an den Langzeitspeicher gesendet. Andernfalls findet eine Übergabe statt. Bei der Übergabe werden alle Token und In-Memory-Chunks, die dem verlassenden Ingestor gehören, an den neuen Ingestor übergeben. Bevor ein Ingestor dem Hash-Ring beitreten, wartet dieser im PENDING Status auf eine Übergabe. Nach einer konfigurierbaren Zeitüberschreitung werden Ingestoren im PENDING Zustand, die keine Übertragung erhalten haben, dem Ring normal beitreten und einen neuen Satz von Tokens einfügen. [9]
Ruler
Die Ruler-Komponente ist dafür verantwortlich, eine Reihe konfigurierbarer Abfragen kontinuierlich auszuwerten und auf der Grundlage des Ergebnisses, Aktionen auszuführen. Es gibt zwei Haupttypen von Regeln die die Ruler-Komponente unterstützt: Alerting Rules und Recording Rules. Diese können selbst konfiguriert, jedoch kann auch auf vorgefertigte Sets zurückgegriffen, werden (s. Beispielkonfiguration). [10]
Query Frontend
Das Query Frontend ist ein optionaler Dienst der die Api-Endpunkte für Leseanfragen bereitstellt. Ist ein Query Frontend vorhanden, sollten eingehende Abfragen an das Frontend und nicht an die Queriers geleitet werden. Der Querier-Dienst wird weiterhin innerhalb des Clusters benötigt um die eigentlichen Abfragen auszuführen. Das Frontend führt intern einige Anpassungen an die Abfragen durch und hält diese in einer internen Warteschlange. Größere Abfragen werden beispielsweise in mehrere kleinere Abfragen aufgeteilt. Diese können dann parallel auf nachgelagerten Queriers ausgeführt werden. Das Frontend fügt die Ergebnisse nach Bearbeitung wieder zusammen. Dies verhindert Speicherüberläufe bei großen Abfragen in einem einzelnen Querier. Zudem können Ergebnisse schneller geliefert werden. Das Query Frontend ist zudem in der Lage Abfrageergebnisse zwischenzuspeichern (Caching) und diese bei nachfolgenden Abfragen erneut zu verwenden. [9]
Querier
Der Querier verarbeitet Abfragen mithilfe von LogQL. Dies ist eine Abfragesprache mit der er in der Lage ist auf Protokolle im Langzeitspeicher, sowie auf In-Memory-Daten der Ingestoren, zuzugreifen. Die Abfrage kann direkt im Grafana erfolgen, welches die Logs visualisiert. [9]
Zusammenfassung und Vergleich zum ELK-Stack
Der ELK-Stack verwendet Logstash als Log Kollektor. Im Vergleich hierzu verwendet Grafana Loki standardmäßig Promtail – kann aber auch mit anderen Log-Kollektoren wie Fluentd oder Logstash arbeiten. Als Dashboard im ELK-Stack wird Kibana eingesetzt. Verwendet man fürs Monitoring Prometheus mit Grafana wird mit Loki kein zusätzliches Dashboard benötigt, da dieses ebenfalls Grafana nutzt. Statt einem Objectstore (Loki) wie S3 oder Cassandra verwendet der ELK-Stack das ressourcenhungrige Elasticsearch. Hierbei werden die Logs als unstrukturierte JSON-Objekte gespeichert. Loki macht keine Volltextindexierung sondern speichert lediglich die Metadaten. Ein direkter Vergleich zwischen dem ELK-Stack, Splunk (ein weiteres Log-Aggregation-System) und Loki zeigt einen deutlich geringeren Speicherbedarf bei Loki.
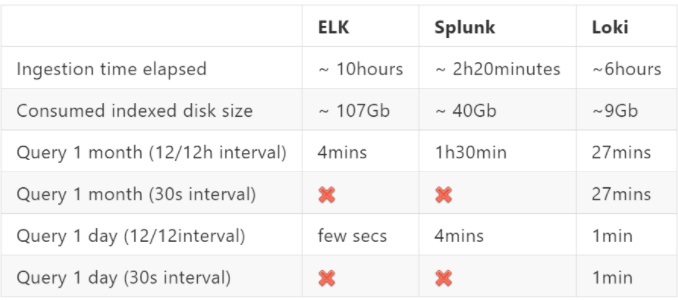
Loki stellt somit eine echte Alternative zu bereits bestehenden Systemen dar.
Quellenangaben
[1] – https://grafana.com/blog/2018/12/12/loki-prometheus-inspired-open-source-logging-for-cloud-natives/
[2] – https://grafana.com/grafana/
[3] – https://prometheus.io/
[4] – https://geekflare.com/de/kubernetes-monitoring-tools/
[5] – https://grafana.com/oss/loki/
[6] – https://grafana.com/blog/2020/05/12/an-only-slightly-technical-introduction-to-loki-the-prometheus-inspired-open-source-logging-system/
[7] – https://grafana.com/docs/loki/latest/clients/promtail/
[8] – https://grafana.com/go/webinar/getting-started-shipping-logs-to-grafana-loki/
[9] – https://grafana.com/docs/loki/latest/fundamentals/architecture/
[10] – https://grafana.com/docs/loki/latest/rules/
[11] – https://crashlaker.medium.com/which-logging-solution-4b96ad3e8d21
Leave a Reply
You must be logged in to post a comment.