Note: This blog post was written for the lecture „Enterprise IT (113601a)“ during the winter semester 2025/26.
In artificial intelligence bigger isn´t always better. While large language models (LLMs) often dominate the spotlight, a new generation of more compact versions, often called tiny or small language models (TLMs), is rapidly emerging. As the name suggests, they are way smaller than LLMs and are especially designed for speed, privacy and affordability. Their smaller size makes it possible for them to run on local hardware, without requiring an internet connection. This makes them perfect for edge AI implementations such as offline assistants or mobile applications.
The aim of this article is to give an overview of tiny language models and some of the main techniques used to create them. Additionally, it examines the advantages and disadvantages of deploying such tiny models. Finally, the article presents some real-world examples of companies that have integrated TLMs into their environments.
1. Introduction to Language Models
A language model is a machine learning model designed to predict and generate natural human language. These models can be useful for tasks such as machine translation, speech recognition, and natural language generation. They encode statistical information about one or more languages. This information tells us how likely a word is to appear in a given context [1, p. 2].
For example in the sentence: “My birth month is ___”,the language model should be able to predict “July” more often than “strawberry”.
1.1 Large Language Models
As language models grow larger, they also become more complex. Early models were only able to predict the probability of a single word, while modern Large Language Models (LLMs) can predict the probability of sentences, paragraphs, or even entire documents [2]. Not only have model capabilities increased, but the interest in AI among consumers and enterprises has risen as well. According to an article published by “DataReportal” as of now there are over 1 billion monthly active users worldwide who use standalone AI tools [3].
In short, large language models are a category of deep learning models trained on enormous amounts of data. This makes them capable of understanding and generating natural language and other types of content [4]. Language models with more than 30 billion parameters are generally considered large [5], with the parameters being the weights the model learned during training, used to predict the next token in the sequence.
LLMs are built on a type of neural network architecture known as the “transformer”, which excels at processing word sequences and capturing patterns in text. This architecture was first introduced in the paper “Attention is All You Need” [6] and has since become foundational in deep learning.
LLMs are not without their problems. Because of the sheer amount of parameters that they have, powerful GPUs and other special hardware components are required to run the models efficiently. Ordinary people are usually not able to afford such costly components, which is why these computations are typically delegated to cloud environments and accessed remotely via HTTP [7].
2. What are Tiny Language Models?
In relation to language models, the term “tiny” is not clearly defined. In much of the literature, it overlaps with the term “small”. In this article, “tiny” refers to language models designed for specific tasks, which have less than a few billion parameters. The focus here is on models that can run on CPUs, embedded devices or modest GPUs.
Just like LLMs, Tiny Language Models (TLMs) are AI models capable of processing and understanding natural language. As the name suggests, TLMs are smaller and more efficient than LLMs. As such, they require less memory and computational power, making them ideal for resource-constrained environments such as edge devices and mobile apps, or even in situations AI has to be used without any network connectivity [8].
2.1 Model Architecture
Tiny language models are typically built on the same decoder-only transformer architecture as large language models [9]. This architecture relies on self-attention mechanisms to process input sequences in parallel, enabling efficient handling of language tasks. However, TLMs are designed with computational efficiency in mind and therefore contain far fewer parameters than LLMs. This reduction is achieved through several specialized techniques [10].
2.2 Model Optimization
TLMs are typically created by using techniques such as knowledge distillation, pruning, quantization and low-rank factorization to minimize model size and memory footprint [9]. The smaller the model has to be, the more aggressively these techniques have to be applied.
2.2.1 Knowledge Distillation
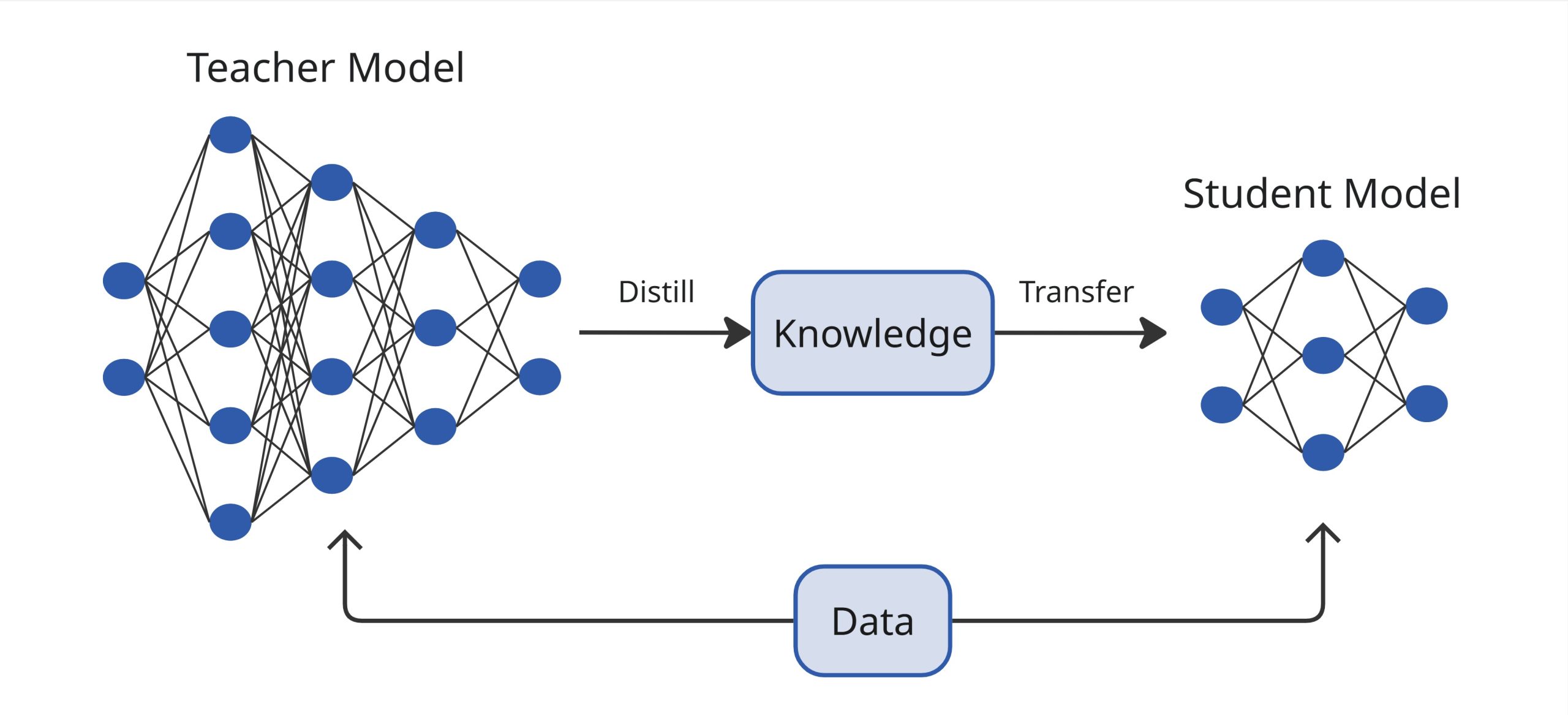
This technique involves training a smaller model, known as the “student” to replicate the behavior of a larger one, referred to as the “teacher” [11]. As shown in Figure 1, a small student model (TLM) learns to mimic a large teacher model (LLM) and leverage the knowledge of the teacher to obtain similar accuracy. Instead of learning directly from data, the student model learns from the soft targets or probabilities, which are produced by the teacher model [12]. The goal of this technique is to produce a compact model that performs nearly as well as the larger model but with far fewer parameters. A well known example is DistilBERT, a distilled version of BERT that reduces the original model size by 40% while retaining 97% of its language understanding capabilities and being 60% quicker [1, p. 395].
2.2.2 Pruning
Pruning is a model compression technique that reduces model complexity by removing less important weights or neurons, as illustrated in Figure 2, resulting in a model with fewer parameters [9]. There are two main types of pruning techniques:
- Structure pruning: Entire neurons, channels, or even layers are removed.
- Unstructured pruning: Individual weights are removed, typically based on their magnitude.
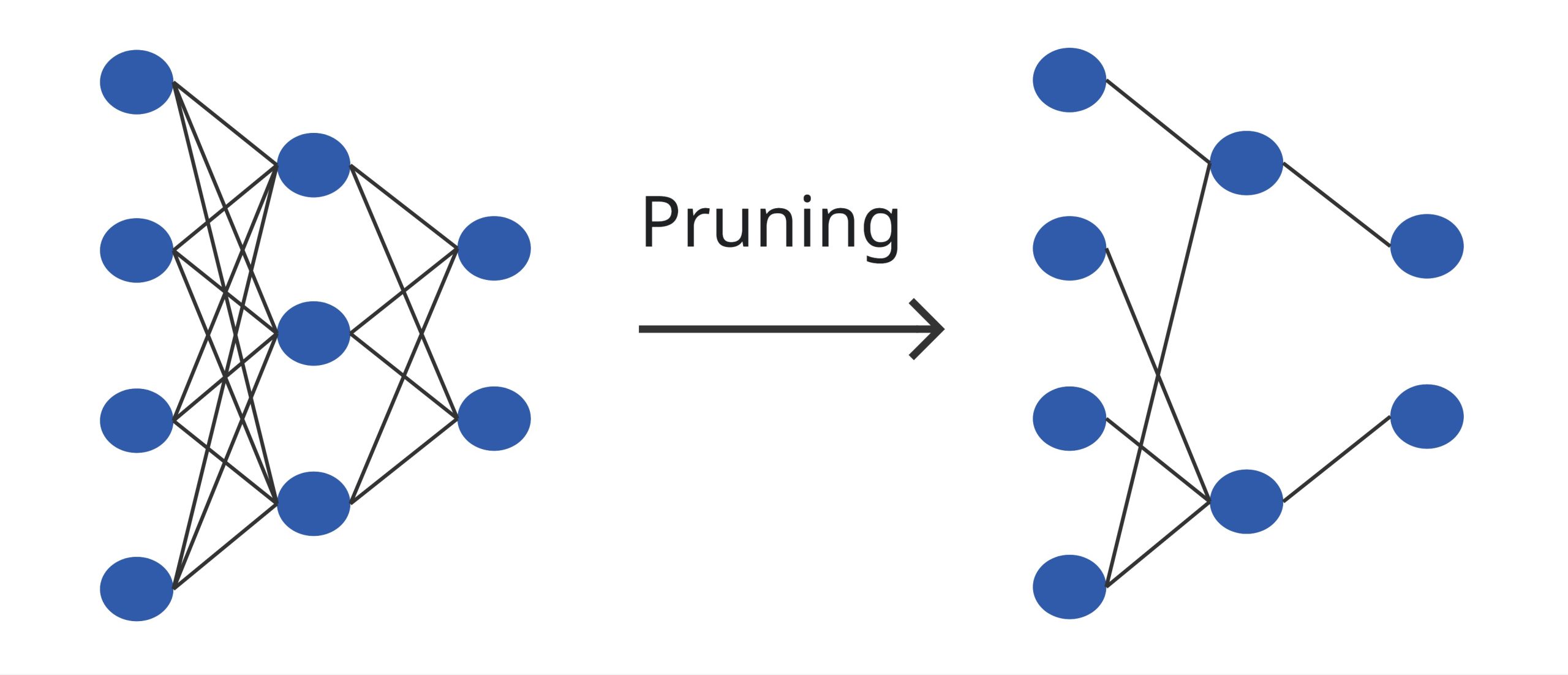
It is a very simple method, that reduces model size significantly, however in case of over-pruning, performance can degrade severely [7].
2.2.3 Quantization
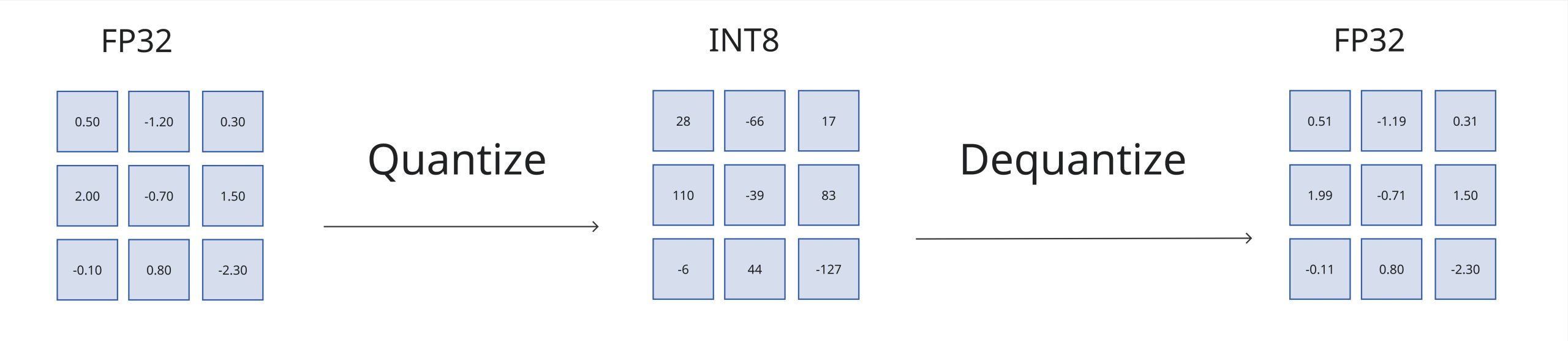
Reducing precision, also known as quantization, is a cheap and extremely effective way to reduce a model’s memory footprint [1, p. 328]. As Figure 3 shows, this is achieved by representing the weights and activations with low-precision data types like 8-bit integer instead of the usual 32-bit floating point. Quantization significantly reduces model size and inference times, however it requires specialized hardware that could recognize those low-precision formats [7]. The fewer bits needed to represent a model’s values, the lower the model’s memory footprint will be. A 1 billion-parameter model stored in a 32-bit format (FP32) requires about 4 GB for its weights, whereas storing the same model in a 8-bit format (INT8) reduces this to roughly 1 GB.
2.2.4 Low-Rank Factorization
Low-rank factorization compresses neural networks by breaking down large weight matrices into lower-dimensional ones. Because many weight matrices in deep models are highly redundant, they can be approximated with low-rank matrices while preserving most of the model´s accuracy [13].
2.3 Fine-Tuning
One compelling feature of TLMs is their adaptability through fine-tuning. Fine-tuning refers to the process of adapting a pre-trained model for a specific use case [14]. By training a TLM on domain-specific data, its performance in specific applications can be significantly improved. For tiny language models this technique is essential, especially if the goal is to specialize the model without extensive retraining.
2.4 TLM Evolution
The recent development of TLMs has been very fast, with many new models being released to meet the need for more efficient AI. Companies like Google, Meta, Microsoft, and IBM have been at the forefront of developing TLMs, with some being released to the public while others are kept private.

Figure 4 displays some of the main new TLMs or model families released from 2024 onwards. The year 2024 was a great year for TLM enthusiasts, as models like MobileLLM, Phi-3-Mini, and MiniCPM were released and were able to run on mobile phones and other low-power devices. In 2025 more tiny models were launched, such as Phi-4, Gemma-3, and IBM Granite 4.0 series, which are designed for higher accuracy and greater cost effectiveness.
3. Benefits
As already mentioned in the case of language models, bigger isn´t always better. What TLMs lack in size, they make up for through several key advantages.
- Resource efficiency: The computational requirements of TLMs are moderate to low. They can operate efficiently on single GPUs or CPUs. They are very compact and can fit within edge device memory, which is typically < 1 GB [9].
- Energy savings: TLMs are optimized for low-power settings. Their smaller computational footprint reduces hardware demands and energy use. This makes them very eco-friendly and are a great option for battery operated devices or systems in remote locations where power resources are limited.
- Cost-effectiveness: Because TLMs require far less infrastructure, the cost of running and maintaining them is significantly reduced.
- Latency: The latency of TLMs is low. They are optimized for <50 ms response times in edge environments [9]. Their ability to process tasks quickly makes them ideal for scenarios where delays are unacceptable.
- Customizability: The smaller size of the TLMs makes them ideal for fine-tuning, allowing developers to adapt the models to domain-specific needs. This enables enterprises, such as those in healthcare, robotics, or manufacturing to deploy TLMs that are adapted for certain specialized tasks.
- Privacy and security: Because these models can be deployed directly on devices, there is no need to send data to the cloud for processing. This on-device capability makes sure that sensitive data is handled locally, which reduces the overall security risks.
4. Limitations
Like large language models, TLMs face their own challenges and limitations. It is important for both enterprises and individual users to understand these in order to set up their environments according to their specific needs.
- Performance Ceiling: Because TLMs are typically fine-tuned for specific tasks, they tend to be less capable on complex problems that require broader knowledge. For tasks where deep reasoning is required, LLMs still have the edge.
- Limited generalization: The domain-specific focus that gives TLMs their efficiency also narrows their scope. Because they are trained on more specialized data, they often lack the broad knowledge of LLMs. This can make them struggle with open ended questions. To cover a wider range of knowledge, enterprises may have to deploy multiple tiny models, each fine-tuned for a specific domain. This could add extra complexity and financial costs to the AI stack.
- Special expertise required: Fine-tuning and maintaining TLMs demands specialized skills in machine learning, data preparation and model evaluation. Many organizations lack these kinds of expertise, which can slow-down the overall adoption of these models.
5. Opening new frontiers
Thanks to the recent advancements in compression and fine-tuning techniques, enterprises can now customize TLMs to meet their specific needs. These models can then be deployed across a wide range of domains:
- On-device AI and edge AI: TLMs are ideal for on-device applications, where computational resources are limited and privacy is a priority [15]. By running directly on devices like smartphones, smartwatches, IoT sensors, autonomous systems, or industrial machines, these models are able to perform tasks without the need of internet connectivity and cloud computing services. In edge AI environments, TLMs can be deployed on nearby devices like on routers, gateways, or edge servers to execute language-related tasks in real-time, reducing latency and the need for central servers [16]. The goal here is to keep intelligence close to where the data is located [17].
- Instant feedback settings: In cases where fast response times are essential, tiny language models are particularly useful because of their low latency. In applications like chatbots, live transcription services, or customer service automation, this reduced latency could provide instant feedback to the user [15].
- Resource limited environments: TLMs can also be applied in scenarios where computational power and bandwidth are limited [15]. In such cases, their lean build makes them deployable on small or affordable hardware, increasing accessibility for individuals or smaller enterprises. For example, companies can use the tiny models to process data collected from sensors embedded in machinery and analyze that data in real-time to predict maintenance needs [8].
6. Case studies
To present the practical relevance of tiny language models, the following case studies highlight how enterprises across different sectors are already deploying and benefiting from these models.
6.1 Apple Intelligence
Apple introduced a new generative AI system called Apple Intelligence at the Worldwide Developers Conference in 2024. This system was integrated into iOS 18, iPadOS 18, and macOS Sequoia and was free to all users with supported devices. To make this happen, Apple relied on a ~3 billion parameter on-device language model, supported by a larger model running on Apple´s servers [18]. This approach enables fast and private features like text-refinement, notification summarization, image generation and in-app automation. To run efficiently on consumer hardware, the on-device model used optimizations like low-bit quantization and low-rank factorization.
6.2 Siemens
In late 2024, Siemens Digital Industries Software and Microsoft demonstrated an industrial use case for TLMs by integrating Microsoft´s Phi-3 into Siemens NX X (software for product engineering) on Azure [19]. This enables engineers to ask natural language questions, access detailed technical information, and simplify complex design work. NX X´s new AI features enhance the platform´s existing capabilities by guiding engineers with best-practice recommendations, automating repetitive tasks through code generation, and detecting potential issues at an early stage.
6.3 Bayer
Another practical example of tiny language models being in use today comes from Bayer, which is a global enterprise operating across healthcare and agriculture. In 2024, the company´s Crop Science division developed „E.L.Y. Crop Protection“, which is a specialized small language model designed to support sustainable crop protection [20]. The model is built on internal agricultural knowledge and is trained on thousands of real-world questions derived from Bayer´s crop protection labels [21]. It provides farmers and other customers with instant access to important agricultural information related to Bayer products as well as general best practices.
7. Conclusion
Tiny language models are making AI more accessible. Unlike LLMs, which require a lot of computing power, TLMs are able to run and perform well with far fewer resources. This makes them very interesting for smaller companies or individual enthusiasts, who may not have huge budgets. Even for large enterprises there models should attract interest, because with their smaller footprint they can be deployed on a wide range of hardware, which wasn´t possible until now.
While LLMs have been a major innovation, their heavy computational and energy needs make them impractical in many situations. Tiny language models on the other hand, which are built on similar transformer foundations but optimized through compression techniques such as quantization, pruning, knowledge distillation, and low-rank factorization, demonstrate that strong language understanding and generation do not require massive parameter counts. Far more important is the model design and the targeted fine-tuning, which enable smaller models to rival the output quality of their larger counterparts.
As shown by the case studies, tiny language models are opening new frontiers in on-device and edge AI across sectors such as consumer technology, industrial software, agriculture, and many others. Although challenges still remain, such as failing to answer some broader complex questions, TLMs already offer an ideal solution for some domain-specific tasks where computational resources are limited or privacy is a concern. This shows that innovation in AI isn’t just about scaling up, but also about scaling smart.
References
[1] C. Huyen, AI Engineering. O’Reilly Media, USA, 2024.
[2] Google, “Introduction to Large Language Models,” Google for Developers, Aug. 25, 2025. [Online]. Available: https://developers.google.com/machine-learning/resources/intro-llms. [Accessed: Dec. 26, 2025].
[3] S. Kemp, “Digital 2026: more than 1 billion people use AI,” DataReportal, Oct. 15, 2025. [Online]. Available: https://datareportal.com/reports/digital-2026-one-billion-people-using-ai. [Accessed: Dec. 26, 2025].
[4] C. Stryker, “What are LLMs?”, IBM, Dec. 22, 2025. [Online]. Available: https://www.ibm.com/think/topics/large-language-models. [Accessed: Dec. 31, 2025].
[5] J. Bernabe-Moreno, “The power of small,” IBM, Nov. 18, 2025. [Online]. Available: https://www.ibm.com/think/insights/power-of-small-language-models?mhsrc=ibmsearch_a&mhq=small%20language%20models. [Accessed: Dec. 26, 2025].
[6] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30, 2017.
[7] R. O. Popov, N. V. Karpenko, and V. V. Gerasimov, “Overview of small language models in practice,” CS&SE@SW, pp. 164–182, 2024.
[8] R. Caballar, “What are small language models?”, IBM, Nov. 17, 2025. [Online]. Available: https://www.ibm.com/think/topics/small-language-models#692473875. [Accessed: Dec. 26, 2025].
[9] I. Lamaakal, Y. Maleh, K. El Makkaoui, I. Ouahbi, P. Pławiak, O. Alfarraj, M. Almousa, and A. A. Abd El-Latif, “Tiny language models for automation and control: Overview, potential applications, and future research directions,” Sensors, vol. 25, 2025, Art. no. 1318. doi: 10.3390/s25051318.
[10] DataScienceDojo, “Small language models: The future of efficient and accessible AI,” Data Science Dojo, Jul. 29, 2025. [Online]. Available: https://datasciencedojo.com/blog/small-language-models/. [Accessed: Dec. 29, 2025].
[11] V.-C. Nguyen, X. Shen, R. Aponte, Y. Xia, S. Basu, Z. Hu, J. Chen, M. Parmar, S. Kunapuli, J. Barrow, J. Wu, A. Singh, Y. Wang, J. Gu, F. Dernoncourt, N. Ahmed, N. Lipka, R. Zhang, X. Chen, and T. Nguyen, “A survey of small language models,” arXiv preprint arXiv:2410.20011, 2024. doi: 10.48550/arXiv.2410.20011.
[12] GeeksforGeeks, “Knowledge distillation,” GeeksforGeeks Machine Learning, Jul. 23, 2025. [Online]. Available: https://www.geeksforgeeks.org/machine-learning/knowledge-distillation/. [Accessed: Jan. 1, 2026].
[13] I. Lamaakal, C. Yahyati, I. Ouahbi, K. E. Makkaoui, and Y. Maleh, “A survey of model compression techniques for TinyML applications,” in Proc. 2025 Int. Conf. Circuit, Systems and Communication (ICCSC), Fez, Morocco, 2025, pp. 1–6. doi: 10.1109/ICCSC66714.2025.11135279.
[14] D. Bergmann, “What are small language models?”, IBM, Nov. 17, 2025. [Online]. Available: https://www.ibm.com/think/topics/fine-tuning. [Accessed: Dec. 28, 2025].
[15] Microsoft, “What are small language models (SLMs)?”, Microsoft Azure, Apr. 2025. [Online]. Available: https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-are-small-language-models. [Accessed: Dec. 31, 2025].
[16] Singh, Awadhesh. “Super Tiny Language Models”. LinkedIn. Published: 06/14/2024. Available at: https://www.linkedin.com/pulse/super-tiny-language-models-awadhesh-singh-nustc. Accessed: 12/26/2025.
[17] Sherrylist, “Understanding small language models (Part 2),” Microsoft Developer Community Blog, Nov. 18, 2025. [Online]. Available: https://techcommunity.microsoft.com/blog/azuredevcommunityblog/understanding-small-language-modes/4466170. [Accessed: Dec. 31, 2025].
[18] Apple, “Introducing Apple’s on-device and server foundation models,” Apple Machine Learning Research, Jun. 10, 2024. [Online]. Available: https://machinelearning.apple.com/research/introducing-apple-foundation-models. [Accessed: Jan. 1, 2026].
[19] Siemens Digital Industries Software PR Team, “Siemens and Microsoft bring AI-enhanced NX X to Azure for advanced product engineering,” Siemens, Nov. 13, 2024. [Online]. Available: https://news.siemens.com/en-us/nx-x-microsoft-azure/. [Accessed: Jan. 1, 2026].
[20] Bayer, “Solving global agri-food challenges through emerging technology,” Bayer Global, Nov. 13, 2024. [Online]. Available: https://www.bayer.com/en/agriculture/article/genai-for-good. [Accessed: Jan. 1, 2026].
[21] S. Thomas, “Microsoft introduces new adapted AI models for industry,” Microsoft Blog, Nov. 13, 2024. [Online]. Available: https://blogs.microsoft.com/blog/2024/11/13/microsoft-introduces-new-adapted-ai-models-for-industry/. [Accessed: Jan. 1, 2026].
[22] Renesas, “DRP-AI extension pack (pruning tool),” Renesas, Nov. 12, 2024. [Online]. Available: https://www.renesas.com/en/software-tool/drp-ai-extension-pack-pruning-tool?srsltid=AfmBOoqCOoWOqpRm-hz1htW4oX9wfXSRkUiZZzGUP8aqngzP3R7LfUY2. [Accessed: Jan. 1, 2026].
[23] M. Grootendorst, “A visual guide to quantization,” Maarten Grootendorst Newsletter, Jul. 22, 2024. [Online]. Available: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization. [Accessed: Jan. 1, 2026].
[24] Z. Lu, X. Li, D. Cai, R. Yi, F. Liu, X. Zhang, N. Lane, and M. Xu, “Small language models: Survey, measurements, and insights,” arXiv preprint arXiv:2409.15790, 2024. doi: 10.48550/arXiv.2409.15790.
List of Figures
Figure 1 – Knowledge Distillation. Adapted from [12].
Figure 2 – Pruning. Adapted from [22].
Figure 3 – Quantization. Adapted from [23].
Figure 4 – TLM Evolution. Adapted from [24]. Data from Hugging Face and Artificial Analysis.
Leave a Reply
You must be logged in to post a comment.